Snowflake Notebooks でコードを開発し、実行します。¶
このトピックでは、 Snowflake Notebooks で SQL、Python、Markdown のコードを書いて実行する方法について説明します。
ノートブックセルの基本¶
このセクションでは基本的なセル操作について紹介します。ノートブックを作成 すると、3つのセル例が表示されます。これらのセルを変更したり、新しいセルを追加することができます。
新しいセルを作成する¶
Snowflake Notebooks は3種類のセルをサポートしています: SQL、Python、Markdown。新しいセルを作成するには、既存のセルにカーソルを合わせるか、ノートブックの一番下までスクロールして、追加したいセルタイプのボタンのいずれかを選択します。

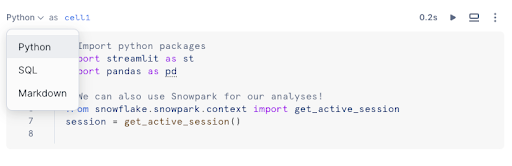
以下のいずれかの方法で、既存のセルの言語を変更してください。
言語ドロップダウンメニューを選択し、別の言語を選択します。
セルの編集¶
編集の競合を防ぐため、一度に1人のユーザーしかセルを編集できません。他のユーザーがアクティブなセルを編集しようとすると、通知が表示されます。セルが編集可能になるのは、60秒間操作がない場合です。
セルを移動する¶
セルを移動するには、マウスを使ってドラッグ&ドロップするか、アクションメニューを使います。
(オプション1)移動する既存のセルにマウスを合わせます。セルの左側にある
 (ドラッグ&ドロップ)アイコンを選択し、セルを新しい場所に移動します。
(ドラッグ&ドロップ)アイコンを選択し、セルを新しい場所に移動します。(オプション2)垂直省略記号
 (アクション)メニューを選択します。次に、適切なアクションを選択します。
(アクション)メニューを選択します。次に、適切なアクションを選択します。
注釈
セル間でフォーカスを移動させるには、Up、:kbd:`Down`を使用します。
セルを削除する¶
セルを削除するには、ノートブックで次の手順を実行します。
垂直省略記号
(その他のアクション)メニューを選択します。Delete を選択します。
Delete をもう一度選択して確定します。
また、 キーボードショートカット を使用してセルを削除することもできます。
PythonとSQLセルを使用する際の注意点については、 ノートブックを実行する際の注意点 をご参照ください。
Snowflake Notebooks でセルを実行する¶
Snowflake Notebooks でPythonと SQL セルを実行するには、次を行うことができます。
シングルセルを実行: コードの更新を頻繁に行う場合は、このオプションを選択してください。
Macキーボードで:kbd:
CMD+ Return を押すか、またはWindowsキーボードで:kbd:CTRL+ Enter を押します。 または Run this cell only を選択します。
または Run this cell only を選択します。
ノートブック内のすべてのセルを順番に実行: ノートブックを提示または共有する前にこのオプションを選択すると、受信者に最新の情報が表示されます。このオプションは、ノートブックのすべての SQL と Python コードセルを上から下へ実行します。いずれかのセルでエラーが発生した場合、実行は停止し、それ以降のセルは実行されません。この動作はスケジュールノートブックにも当てはまります。例えば、10個のセルを持つノートブックを実行し、セル2で SQL 構文エラーが発生した場合、ノートブックはセル2の後で実行を停止します。
Macキーボードで:kbd:
CMD+ Shift + Return を押すか、またはWindowsキーボードで:kbd:CTRL+ Shift + Enter を押します。Run all を選択します。
セルを実行して次のセルに進む: セルを実行して次のセルに進むにはこのオプションを選んでください。
Macキーボードで:kbd:
Shift+ Return を押すか、またはWindowsキーボードで:kbd:Shift+ Enter を押します。セルの垂直省略記号
(その他のアクション)を選択し、 Run cell and advance を選択します。
上記すべてを実行:以前のセルの結果を参照するセルを実行する場合、このオプションを選択します。
セルの垂直省略記号
(その他のアクション)を選択し、 Run all above を選択します。
以下すべて実行:後続のセルに依存するセルを実行する場合、このオプションを選択します。このオプションは、現在のセルとそれに続くすべてのセルを実行します。
セルの垂直省略記号
(その他のアクション)を選択し、 Run all below を選択します。
あるセルが動作しているとき、他の実行要求はキューに入れられ、アクティブに動作しているセルが終了すると実行されます。
セルの折りたたみと展開¶
ノートブックの上部にあるセル表示オプションを選択することで、ノートブックの表示範囲をコントロールできます。
垂直省略記号
(その他のアクション)メニューを選択します。Show/hide all を選択し、適切なオプションを選択します。
すべて表示: 各セルのコードと結果の両方を表示します。
コードのみを表示: 結果を非表示にし、コードセルのみを表示します。
結果のみを表示: コードを隠し、出力のみを表示します。
すべて隠す: すべてのセルのコードと結果を折りたたみます。
これらのオプションは次のような場合に役立ちます。
あなたはコードを読んだり、結果を確認したりすることに集中したいのです。
あなたは自分のノートブックを発表または共有しています。
大容量ノートブックをより効率的に操作する必要があります。
重複セル¶
セルを複製することは以下のことに役立ちます。
クエリや関数のバリエーションをテストします。
作業バージョンを上書きせずにデバッグ。
異なる出力を並べて比較。
元のコードを失うことなく、コードを再利用したり、既存のセルを変更したりすること。
ノートブックのセルを複製します。
複製するセルから、垂直の省略記号
(その他のアクション) メニューを選択します。Duplicate を選択します。
セルのコピーが元のセルのすぐ下に表示されます。
セル ミニマップ¶
セル・ミニマップはノートブックの右サイドバーに表示され、ノートブック内のすべてのセルのコンパクトでドラッグ可能なリストを提供します。ミニマップの各項目は、コードまたはテキストセルに対応し、セルの表示順を反映します。
現在のセル: 選択されているセルがミニマップで強調表示されます。
並び替え: ミニマップの項目をドラッグ&ドロップすると、ノートブックのセルの順序をすばやく変更できます。
ナビゲーション: ミニマップのセル名をクリックすると、そのセルに直接ジャンプします。
この機能は、大容量のノートブックをナビゲートし、コンテンツをより効率的に再編成するのに便利です。
パラメーター付きノートブックの実行¶
EXECUTE NOTEBOOK コマンドを使用してノートブックを実行する場合、ノートブックに引数を渡すことができます。ノートブックのPythonのセルでは、コマンドライン引数を保持する組み込みのPythonリストである sys.argv 変数を使ってこれらの引数にアクセスできます。
ノートブックに引数を渡すことで、ノートブックの動作をカスタマイズすることができます。できること:
ノートブック実行をパーソナライズまたはカスタマイズします。
複数の入力に同じノートブックを再利用します。
自動化またはタスクのスケジューリングをサポートします。
例¶
ノートブックのPythonのセルでは、 sys.argv 変数を使って引数にアクセスできます。
ノートブックに渡されたすべての引数を表示¶
ノートブックに渡された引数の完全なリストを出力します。
ノートブックがこのコマンドで実行された場合:
出力は次のとおりです。
各引数を出力する¶
ループ処理して、各引数を個別に出力します。
出力は次のとおりです。
特定の引数にアクセスする¶
2番目の引数にアクセスします。
出力は次のとおりです。
コンマ区切り値を含む引数の解析¶
引数に値のコンマ区切りリストが含まれている場合は、個々の値に分割できます。
出力は次のとおりです。
値をループすることもできます。
キーと値のペアを含む引数を抽出する¶
引数にキーと値のペアが含まれている場合(例: key=value)の値を抽出します。
出力は次のとおりです。
単一文字列の代替構文¶
セッション変数 を引数の値に変換し、そのセッション変数をノートブックに渡すことができます。
パラメーター化された実行からの結果を表示¶
EXECUTE NOTEBOOK を使用してトリガーされたノートブックの実行結果を表示する方法:
Snowsight にサインインします。
ナビゲーションメニューで Projects » Notebooks を選択します。
Calendar アイコンを選択します。
View run history を選択します。
ノートブックの実行を見つけて、結果を開きます。
その実行結果を含んでいる、読み取り専用のノートブックが開きます。
メモ¶
sys.argvには、 EXECUTE NOTEBOOK 経由で渡された文字列のみが含まれます。文字列のみがサポートされています。別のデータ型(整数など)が渡された場合、 NULL として解釈されます。詳細については、 EXECUTE NOTEBOOK をご参照ください。
セルステータスを検査する¶
セルが表示する色によって、セルの実行状態が示されます。このステータスの色はセルの左の壁と右のセルナビゲーションマップ の2箇所に表示されます。
セルステータスの色:
青い点:セルは修正されましたが、まだ動作していません。
赤:現在のセッションでセルが実行され、エラーが発生しました。
緑:セルは現在のセッションでエラーなしに実行されました。
動いている緑 - 現在セルが実行されています。
灰色:セルは前のセッションで実行され、表示される結果は前のセッションのものです。前回のインタラクティブセッションのセル結果は7日間保存されます。インタラクティブセッションとは、スケジュールや EXECUTE NOTEBOOK SQL コマンドによって実行されるものではなく、ユーザーが Snowsight 形式でノートブックを実行することを意味します。
グレーの点滅: Run All を選択すると、セルは実行待ちの状態になります。
注釈
マークダウンのセルにはステータスが表示されません。
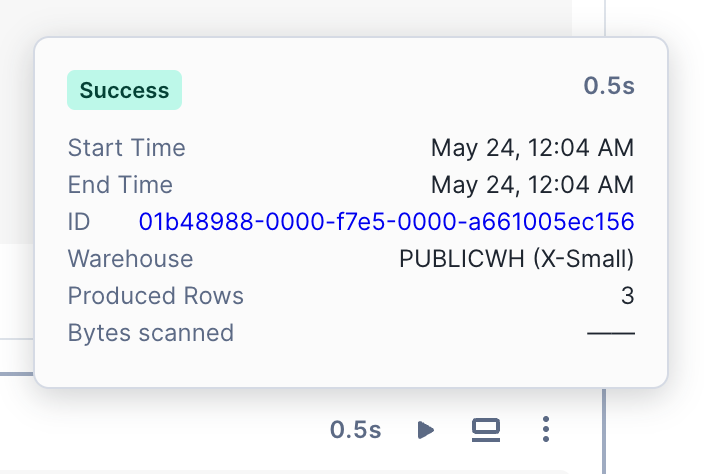
セルの実行が終わると、実行にかかった時間がセルの上部に表示されます。このテキストを選択すると、開始時刻、終了時刻、総経過時間などのランの詳細が表示されます。
SQLセルには、クエリの実行に使用されたウェアハウス、返された行、クエリIDページへのハイパーリンクなどの追加情報が含まれます。
実行中のセルを停止¶
現在実行中のコード・セルの実行を停止するには、セルの右上にある Stop を選択します。Notebooksページの右上にある Stop を選択することも可能です。細胞が動いている間、 Run all は Stop になります。
これにより、現在実行中のセルと、それ以降に実行がスケジュールされてい るすべてのセルの実行が停止されます。
キーボードのショートカット¶
Snowflake Notebooks は、様々なキーボードショートカットをサポートし、開発プロセスを加速します。
また、右下のキーボードアイコンを選択し、 Keyboard shortcuts を選択すると、キーボードショートカットのリストが表示されます。
タスク |
MacOS |
Windows |
|---|---|---|
すべてのセルを実行 |
CMD + Shift + Return |
CTRL + Shift + Enter |
選択したセルを実行します。 |
CMD + Return |
CTRL + Enter |
選択したセルを実行し、次のセルに進みます。 |
Shift + Return |
Shift + Enter |
セル間を移動します。 |
Up および:kbd: |
Up および:kbd: |
すべてのセルを停止 |
ii |
ii |
セル内を検索します。 |
CMD + f |
CTRL + f |
セルを上に移動 |
CMD + SHIFT + Up 矢印 |
CTRL + SHIFT + Up 矢印 |
セルを下に移動 |
CMD + SHIFT + Down 矢印 |
CTRL + SHIFT + Down 矢印 |
現在選択されているセルの上にセルを追加します。 |
a |
a |
現在選択されているセルの下にセルを追加します。 |
b |
b |
現在選択されているセルを削除します。 |
dd または DELETE |
dd または DELETE |
SQL またはPythonのセルをMarkdownのセルに変換します。 |
m |
m |
セルをコードセルに変換します。
|
y |
y |
キーボードショートカットを表示 |
Shift + ? |
Shift + ? |
さらに、ワークシートで使うのと同じキーボードショートカットも使えます。キーボードショートカットでタスクを実行する をご参照ください。
Markdownでテキストをフォーマット¶
ノートブックにMarkdownを含めるには、Markdownセルを追加してください:
キーボードショートカット を使用し、 Markdown を選択するか、 + Markdown を選択します。
Edit markdown 鉛筆アイコンを選択するか、セルをダブルクリックして、Markdownを書き始めます。
有効なMarkdownを入力して、テキストセルをフォーマットすることができます。入力すると、Markdown構文の下にフォーマットされたテキストが表示されます。
書式付きテキストのみを表示するには、 Done editing チェックマークアイコンを選択します。

注釈
マークダウンのセルは現在、HTMLのレンダリングをサポートしていません。
Markdownの基本¶
このセクションでは、Markdownを使い始める上での基本的な構文について説明します。
ヘッダー
ヘディングレベル |
Markdown構文 |
例 |
|---|---|---|
最上位 |

|
|
第2レベル |

|
|
第3レベル |

|
インラインテキストの書式設定
テキスト形式 |
Markdown構文 |
例 |
|---|---|---|
斜体 |

|
|
太字 |

|
|
リンク |

|
リスト
リストタイプ |
Markdown構文 |
例 |
|---|---|---|
順序付きリスト |

|
|
順序なしリスト |

|
コードの書式設定
言語 |
Markdown構文 |
例 |
|---|---|---|
Python |
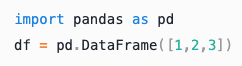
|
|
SQL |

|
画像の埋め込み
ファイルタイプ |
Markdown構文 |
例 |
|---|---|---|
画像 |

|
これらのMarkdownの例を示すノートブックについては、ビジュアルデータストーリーノートブックの Markdownセル セクションをご参照ください。
セル出力の理解¶
Python セルを実行すると、ノートブックにはセルからの出力が以下のタイプで結果に表示されます。
ログ、エラー、警告、print() ステートメントからの出力など、コンソールに書き込まれるすべての結果。
DataFrames は Streamlitのインタラクティブ・テーブル・ディスプレイ、
st.dataframe()で自動的に印刷されます。サポートされている DataFrame 表示タイプには、pandas DataFrame、Snowpark DataFrames、Snowpark Tables があります。
Snowparkの場合、印刷された DataFrames は、
.show()コマンドを実行することなく、熱心に評価されます。非インタラクティブモードでノートブックを実行する場合など、 DataFrame を熱心に評価したくない場合、Snowflake では、 DataFrame print ステートメントを削除して、Snowpark コード全体のランタイムを高速化することを推奨しています。
可視化は出力でレンダリングされます。データの可視化について詳しくは、 Snowflake Notebooks のデータを可視化する をご覧ください。
さらに、SQLクエリの結果に Python でアクセスしたり、その逆も可能です。Snowflake Notebooks の参照セルと変数 をご参照ください。
セル出力制限¶
10,000行または DataFrame 出力の8 MB のいずれか低い方のみがセル結果として表示されます。しかし、 DataFrame はすべて、ノートブックセッションで使用可能です。例えば、 DataFrame 全体がレンダリングされなくても、データ変換タスクを実行することができます。
各セルにつき、20 MB の出力のみが許可されています。セル出力のサイズが20 MB を超えると、出力は落とされます。そのような場合は、内容を複数のセルに分割することを検討してください。
Snowflake Notebooks の参照セルと変数¶
ノートブックのセルで前のセルの結果を参照できます。たとえば、 SQL セルの結果やPython変数の値を参照したい場合は、以下のテーブルをご参照ください。
注釈
参照のセル名は大文字と小文字を区別し、参照先のセル名と正確に一致する必要があります。
PythonのセルでSQLの出力を参照する:.
参照セルタイプ |
現在のセルタイプ |
参照構文 |
例 |
|---|---|---|---|
SQL |
Python |
|
SQL の結果テーブルをSnowpark DataFrame に変換します。
セルを参照して、SQLの結果にアクセスできます。 結果をpandas DataFrame データフレームに変換します。 |
SQLコードの変数を参照します。
重要
SQL コードでは、 string 型のPython変数のみを参照できます。Snowpark DataFrame やpandas DataFrame などのPythonネイティブ DataFrame 形式は参照できません。
参照セルタイプ |
現在のセルタイプ |
参照構文 |
例 |
|---|---|---|---|
SQL |
SQL |
|
例えば、 |
Python |
SQL |
|
例えば、 Python変数を値として使用 変数 Pythonの変数を識別子として使う場合 Python 変数が列やテーブル名のような SQL 識別子を表す場合: Python の変数が列やテーブル名 ( 値として使用される変数(引用符付き)と識別子として使用される変数(引用符なし)を必ず区別してください。 注意:Python DataFrames の参照はサポートされていません。 |
ノートブックを実行する際の注意点¶
ノートブックは発信者権限を使用して実行されます。その他の留意点については、 ノートブックのセッションコンテキストの変更 をご参照ください。
Pythonライブラリをインポートしてノートブックで使うことができます。詳細については、 ノートブックで使用するPythonパッケージをインポートする をご参照ください。
SQLセルでオブジェクトを参照する場合は、指定したデータベースまたはスキーマのオブジェクト名を参照するのでない限り、完全修飾オブジェクト名を使用する必要があります。ノートブックのセッションコンテキストの変更 をご参照ください。
ノートブックの下書きは3秒ごとに保存されます。
ノートブックのバージョンを管理するために Gitの統合 を使用することができます。
アイドルタイムアウト設定を構成し、設定に達するとノートブックセッションを自動的にシャットダウンすることができます。詳細については、 アイドルタイムと再接続 をご参照ください。
Notebooksのセル結果は、Notebooksを実行したユーザーにのみ表示され、セッションをまたいでキャッシュされます。ノートブックを開き直すと、 Snowsight を使ってユーザーが最後にノートブックを実行したときの過去の結果が表示されます。
BEGIN ... END (Snowflakeスクリプト) は、SQL セルでサポートされていません。代わりに、Pythonのセルで Session.sql().collect() メソッドを使用してスクリプトブロックを実行します。SQL クエリを即座に実行するために、
collectの呼び出しでsql呼び出しをチェーンします。次のコードは
session.sql().collect()メソッドを使用してSnowflakeスクリプトブロックを実行します。