オープンフロー BYOC コストとスケーリングの考慮事項¶
Snowflake Openflow BYOC には、インフラストラクチャ、コンピューティング、データインジェスションなど、複数の領域でコストの考慮事項があります。Openflowのスケーリングには、これらのコストを理解することが含まれます。 以下のセクションでは、一般的なOpenflow BYOC コストについて説明し、Openflow BYOC ランタイムのスケーリングと関連コストの例をいくつか示しています。
Openflow BYOC コスト¶
Openflowを使用すると、次のタイプのコストが発生します。
コストカテゴリ |
説明 |
|---|---|
Openflow(Snowflakeの請求書に**Openflowコンピューティング BYOC**として表示) |
コストは、「bring your own cloud(BYOC)」環境内でコネクタランタイムが使用する仮想 CPU コア(vCPU)の数に基づきます。アクティブなランタイムに対してのみ請求されます。Openflow管理プロセスに使用されるコンピューティングは、この特定の請求から除外されます。クレジットは最短60秒で、秒ごとに請求されます。 VCPU の使用とスケーリングの影響については、Openflow BYOC スケーリング をご参照ください。 1時間あたりの vCPU ごとのレートに関する情報は、Snowflakeサービス利用表 のテーブル1(g)をご参照ください。 さらに、Account Usage スキーマの METERING_DAILY_HISTORY および METERING_HISTORY ビューは、クエリを使用して Snowflakeでのコンピューティングコストの調査に関する詳細は、コンピューティングコストの調査 をご参照ください。 |
インフラストラクチャー (BYOC 構成の場合のみ) |
BYOC デプロイメントにのみアプリケーションを適用し、Openflow を実行するためにお客様の環境でプロビジョニングされた基になるインフラストラクチャの対価をクラウドプロバイダー (例えば AWS) に直接お支払いいただきます。これには主にコンピュートコスト(コネクタを実行するためにプロビジョニングするランタイムとランタイムを管理するためのコスト)、ネットワークコスト、ストレージコストが含まれ、 CSP の請求書に表示されます。 EC2 のコンピュート要件は以下の図の通りです。 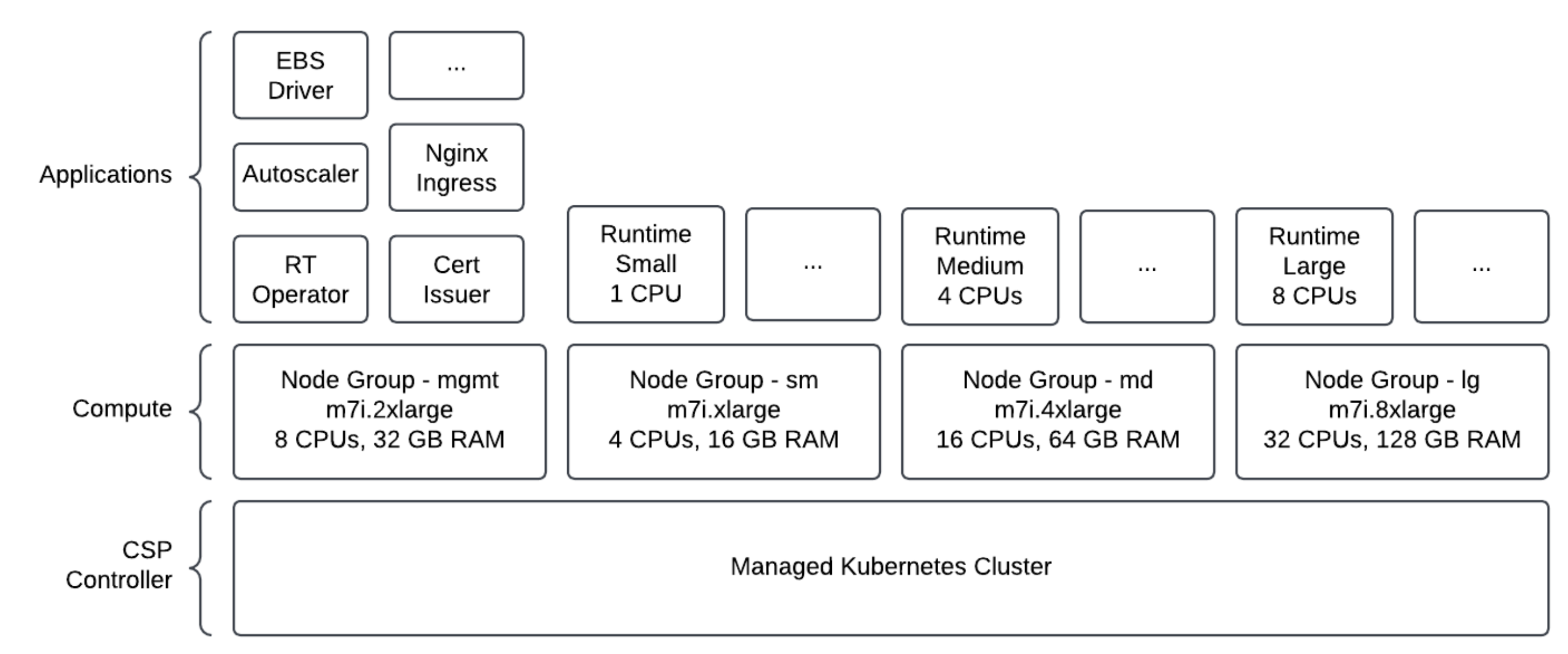
|
インジェスチョン |
データ量に基づく、SnowpipeやSnowpipe Streamingなどのサービスを使用したSnowflakeへのデータロードに対するコスト。Snowflakeの請求書には、それぞれの取り込みサービスの項目として表示されます。一部のコネクタは標準のSnowflakeウェアハウスを必要とする場合があり、追加のウェアハウスコストが発生します。たとえば、データベース CDC コネクタは、初期スナップショットと増分変更データキャプチャ(CDC)にSnowflakeウェアハウスを必要とします。MERGE 操作をスケジュールして、コンピューティングコストを管理できます。 |
テレメトリー・データ・インジェスト |
Openflowデプロイにログとメトリックを送信し、Snowflake内のイベントテーブルにランタイムを送信することに対して発生する、標準のSnowflake料金。テレメトリーデータの GB あたりのクレジットレートは、Snowflakeサービス利用表 のテーブル5で確認できます。 |
Openflow BYOC スケーリング¶
コストを効果的に管理するには、選択するランタイムとスケーリング動作が重要です。Openflowは、それぞれ独自のスケーリング特性を持つさまざまなランタイムタイプをサポートしています。
ランタイムのタイプと関連コスト¶
次のテーブルは、様々なランタイムのスケーリング動作と関連コストを示しています。
ランタイム |
アクティビティ |
Snowflakeコスト |
クラウドコスト |
|---|---|---|---|
ランタイムなし |
なし |
コストなし |
データプレーンのコンピューティングとストレージ |
小規模のランタイム1(1vCPU):newline:`.`(最小1最大2) |
1時間アクティブ . ランタイムは2にスケールしない。 |
1ランタイム x 1ノード x 1 vCPU x 1時間 = 1 . 合計 = 1 vCPU 時間 |
データプレーンのコンピューティングとストレージ |
小規模のランタイム2(1 vCPU)(最小/最大=2):newline:`.`大規模のランタイム1(8 vCPU)(最小/最大=10) |
小規模:2つのノードが1時間アクティブ . 大規模:10のノードが1時間アクティブ |
2ランタイム2 x 2ノード x 2 vCPU x 1時間 = 4 vCPU:newline: |
データプレーンのコンピューティングとストレージ |
中規模のランタイム1(4vCPU) :newline:`.`(最小 =1 最大=2) |
最初の20分間、1つのノードを実行 . 20分後、2つのノードにスケール . 40分後、ノード1つにスケールバック . 合計1時間 . |
20分 = 1/3時間 . 1ランタイム x 1ノード x 4 vCPUx 1/3時間 = 1 1/3 .`1ランタイム x 2ノード x 4 vCPUx 2/3時間 = 2 1/3 :newline:.`1ランタイム x 1ノード x 4 vCPUx 1/3時間 = 1 1/3 . 合計 = 5 1/2 vCPU 時間 |
データプレーンのコンピューティングとストレージ |
中規模のランタイム1(4vCPU):newline:`.`(最小/最大=2) |
最初の30分間、2つのノードを実行 . 最初の30分後に一時停止。 |
30分 = 1/2時間 . 1ランタイム x 2ノード x 4 vCPUx 1/2時間 = 4 . 合計 = 4 vCPU 時間 |
データプレーンのコンピューティングとストレージ |
EC2 インスタンスタイプへのランタイムのマッピング¶
ランタイムタイプ(Tシャツサイズ)を選択すると、ランタイムPodが関連する EC2 ノードグループ(次のテーブルで説明されているリソースを持つ {key}-sm-group、{key}-md-group、または {key}-lg-group)でスケジュールされます。
ランタイム型 |
vCPUs |
利用可能なメモリ(GB) |
EC2 インスタンス型 |
EC2 ノードグループ |
EC2 ノード - CPUs |
EC2 ノード - メモリ(GB) |
|---|---|---|---|---|---|---|
S |
1 |
2 |
m7i.xlarge |
{key}-sm-group |
4 |
16 |
中 |
4 |
10 |
m7i.4xlarge |
{key}-md-group |
16 |
64 |
L |
8 |
20 |
m7i.8xlarge |
{key}-lg-group |
32 |
128 |
選択したランタイム型は、毎秒に消費されるコアの数(vCPUs)に影響します。CPU 消費に基づき、ランタイム作成中に設定される最大ノード設定まで、追加のPodをスケジュールする必要がある場合に、Openflowは基礎となる EC2 ノードグループをスケーリングします。
EKS ノードグループは、最小サイズ0ノード、最大サイズ50ノードで構成されています。必要なサイズは、ランタイムの必要な CPU とメモリに応じて動的に調整されます。
お客様は、ランタイムをホストする基礎となるノードに対して、クラウドサービスプロバイダーから請求されます。基になる EC2 インスタンスは、それぞれのサイズの最初のランタイムがスケジュールされるときに作成されます。
Openflow BYOC ランタイム消費の計算例¶
- ユーザーはOpenflow から BYOC デプロイをリクエストしてから、Openflowエージェントとデプロイをインストールします
ユーザーはランタイムを作成していません。0 vCPUs が割り当てられているため、Openflowのソフトウェアコストはかかりません。
ユーザーは、Openflow BYOC デプロイのプロビジョニングされたコンピューティングとストレージに対して、クラウドサービスプロバイダーから請求されます。
Openflow消費の合計 = 0 vCPU 時間
- ユーザーが、最小ノード = 1、最大ノード = 2の小規模のランタイムを1つ作成します。ランタイムは1時間に1ノードのままです。
小規模のランタイム1 = 1 vCPU
Openflow消費の合計 = 1 vCPU 時間
- ユーザーは、それぞれ最小/最大2ノードの小規模ランタイムを2つと、最小/最大10ノードの大規模ランタイムを1つ作成します。これらのランタイムは1時間アクティブです
2ノードで小規模のランタイム2つ = 2ランタイム x 2ノード x 1 vCPU = 4 vCPUs
10ノードで大規模のランタイム1つ = 1ランタイム x 10ノード x 8 vCPU = 80 vCPUs
Openflow消費の合計 =(4 vCPU+ 80 vCPU)x 1時間 = 84 vCPU 時間
- ユーザーは、ノード1つの中規模ランタイムを1つ作成します。20分後、2ノードにスケーリングします。20分後、1ノードにスケールダウンし、さらに20分間実行されます。
中規模のランタイム1つ = 4 vCPUs
20分 = 1/3時間
(1ノード x 4 vCPUx 1/3時間)+(2ノード x 4 vCPU x 1/3時間)+(1ノード x 4 vCPU x 1/3時間)
4/3 vCPU 時間 + 8/3 vCPU 時間 + 4/3 vCPU 時間
Openflow消費の合計 = 16/3 vCPU 時間、つまり約5.33 vCPU 時間
- ユーザーは2ノードの中規模ランタイムを1つ作成し、30分後に一時停止します
中規模のランタイム1つ = 4 vCPU
30分 = 1/2時間
Openflow消費の合計 =(2ノード x 4 vCPU x 1/2時間)= 4 vCPU 時間