クエリ履歴でクエリのアクティビティをモニターする¶
アカウント内でのクエリのアクティビティをモニターするには、以下を使用できます。
Snowsight の Query History と Grouped Query History のページ。
SNOWFLAKE データベースの ACCOUNT_USAGE スキーマの QUERY_HISTORY ビュー、 AGGREGATE_QUERY_HISTORY ビュー。
INFORMATION_SCHEMA 内のテーブル関数の QUERY_HISTORY ファミリー。
Snowsight の Query History ページを使用して、次のことができます。
アカウント内のユーザーによって実行される個別またはグループ化されたクエリを監視します。
パフォーマンスのデータなど、クエリの詳細を表示する。場合によっては、 クエリの詳細を利用できません。
クエリプロファイル内で実行されたクエリの各ステップを詳しく見る。
クエリ履歴ページでは、過去14日間にSnowflakeアカウントで実行されたクエリを調べることができます。
ワークシート内では、そのワークシートで実行されたクエリの履歴を表示することができます。クエリ履歴を表示 をご参照ください。
Snowsightのクエリ履歴を確認します。¶
Snowsight の Query History ページにアクセスするには、次を行います。
Snowsight にサインインします。
ナビゲーションメニューで Monitoring » Query History を選択します。
Individual Queries または Grouped Queries にアクセスしてください。グループ化されたクエリの情報については、 Snowsightのグループ化されたクエリ履歴表示を使用します。 をご参照ください。
Individual Queries のためには、 フィルターして 最も関連性の高い正確な結果を表示します。
リストの一番上に Load More ボタンが表示されている場合は、ロード可能な結果がまだあることを意味します。Load More を選択するか、リストの一番下までスクロールすると、次の結果セットを取得できます。
クエリ履歴の表示に必要な権限¶
自分が実行したクエリの履歴はいつでも表示できます。
他のクエリの履歴を表示するには、アクティブなロールが Query History で他に表示される内容に影響します。
アクティブなロールが ACCOUNTADMIN ロールの場合、そのアカウントのすべてのクエリ履歴を表示できます。
アクティブなロールに MONITOR または OPERATE 権限が付与されているウェアハウスでは、そのウェアハウスを使用している他のユーザーが実行したクエリを表示できます。
アクティブなロールに SNOWFLAKE データベースに対するGOVERNANCE_VIEWER データベースロールが付与されている場合 、SQLを使用してACCOUNT_USAGE ビューを直接クエリするのに十分であり、また:ui:
Grouped Queriesをクエリ履歴内で表示することもできます。 ただし、このロールだけでは、他のユーザーが Snowsight で:ui:Individual Queriesを表示する機能を付与することはできません。すべてのユーザークエリ(グループ化および個別の両方)を表示するには、ロールが ACCOUNTADMIN または SNOWFLAKE データベース上で IMPORTEDPRIVILEGES が付与されている必要がありますまたは、次の2つの権限が IMPORTEDPRIVILEGES に代わることもできます。あなたのアクティブなロールに SNOWFLAKEデータベースの READER_USAGE_VIEWER データベースロールが付与されている場合、あなたのアカウントに関連付けられたリーダーアカウントの全ユーザーのクエリ履歴を表示することができます。SNOWFLAKE データベースロール をご参照ください。
クエリ履歴の使用に関する考慮事項¶
アカウントの Query History を確認する際には、以下の点を考慮してください。
セッション のデータ保持ポリシーにより、7 日以上前に実行されたクエリの詳細には User の情報は含まれません。ユーザーフィルターを使用すると、個々のユーザーが実行したクエリを取得できます。クエリ履歴をフィルターする をご参照ください。
構文エラーまたは構文解析エラーによって失敗したクエリについては、実行された SQL ステートメントの代わりに
<削除済み>が表示されます。適切な権限を持つロールが付与されている場合、 ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR パラメーターを設定してクエリテキストの全文を表示することができます。フィルターと Started 列および End Time 列は現在のタイムゾーンを使用します。この設定は変更できません。セッションに TIMEZONE パラメーターを設定しても、使用されるタイムゾーンは変わりません。
クエリ履歴をフィルターする¶
クエリ履歴リストは以下の方法でフィルターをかけることができます。
クエリのステータス。例えば、長時間実行されているクエリ、失敗したクエリ、キューに入れられたクエリを特定します。
クエリを実行したユーザー。例えば:
All。クエリ履歴を表示できるすべてのユーザーが表示されます。
サインインしたユーザー(デフォルト)
アカウント内の個々のSnowflakeユーザー(あなたのロールに他のユーザーのクエリ履歴を表示できる場合)。
クエリが実行された期間(最大14日)。
その他のフィルター。次が含まれます。
SQL Text。例えば、 GROUP BY のような特定のステートメントを使用するクエリを表示します。
Query ID。特定のクエリの詳細を表示します。
Warehouse。特定のウェアハウスを使用して実行されたクエリを表示します。
Statement Type。DELETE、 UPDATE、 INSERT、または SELECTなど、特定のタイプのステートメントを使用したクエリを表示します。
Duration。例えば、特に長時間実行されるクエリを特定するためです。
Session ID。特定のSnowflakeセッション中に実行されたクエリを表示します。
Query Tag。QUERY_TAG セッションパラメーターを通して設定された特定のクエリタグを持つクエリを表示します。
Parameterized Query Hash フィルターで指定されたパラメーター化されたクエリハッシュ ID に従ってグループ化されたクエリを表示します。詳細については、 パラメーター化されたクエリのハッシュの使用(query_parameterized_hash) をご参照ください。
Client generated statements。ウェブインターフェイスなど、クライアント、ドライバー、またはライブラリによって実行された内部クエリを表示します。例えば、ユーザーが Warehouses Snowsight に移動するたびに、Snowflakeはバックグラウンドで SHOW WAREHOUSES ステートメントを実行します。このフィルターが有効になっていると、前述のステートメントが表示されます。お客様のアカウントには、クライアントが作成したステートメントに対して請求は行われません。
Queries executed by user tasks。ユーザータスクによって実行された SQL ステートメントや呼び出されたストアドプロシージャを表示します。
Show replication refresh history。リモートリージョンやアカウントへの 複製 リフレッシュタスクの実行に使用されるクエリを表示します。
ほぼリアルタイムの結果を表示したい場合は、 Auto Refresh を有効にします。Auto Refresh が有効な場合、テーブルは10秒ごとに更新されます。
デフォルトでは Queries テーブルに次の列が表示されます。
SQL Text。実行されたステートメントのテキスト(常に表示されます)。
Query ID。クエリの ID (常に表示されます)。
Status。実行されたステートメントのステータス(常に表示されます)。
User。ステートメントを実行したユーザー名を表示します。
Warehouse。ステートメントを実行するために使用されたウェアハウスを表示します。
Duration。ステートメントを実行するのにかかった時間を表示します。
Started。ステートメントの実行が開始された時間を表示します。
それ以上の結果がある場合、テーブルをソートすることはできません。テーブルをソートした後、リストの一番上で Load More を選択すると、新しい結果がデータの最後に追加され、ソート順は適用されなくなります。
より具体的な情報を表示するには、 Columns を選択して、次のようにテーブルから列を追加または削除することができます。
All。すべての列を表示します。
User ステートメントを実行したユーザーを表示します。
Warehouse をクリックすると、ステートメントの実行に使用されたウェアハウスの名前が表示されます。
Warehouse Size。ステートメントの実行に使用されたウェアハウスのサイズを表示します。
Duration をクリックすると、ステートメントの実行にかかった時間が表示されます。
Started をクリックすると、ステートメントの開始時刻が表示されます。
End Time。ステートメントの終了時刻を表示します。
Session ID。ステートメントが実行されたセッションの ID を表示します。
Client Driver。ステートメントの実行に使用されたクライアント、ドライバー、ライブラリの名前とバージョンを表示します。Snowsight で実行されたステートメントは
Go 1.1.5を表示します。Bytes Scanned。クエリの処理中にスキャンされたバイト数を表示します。
Rows。ステートメントが返す行数を表示します。
Query Tag。クエリに設定されたクエリタグを表示します。
Parameterized Query Hash を使用すると、フィルターで指定されたパラメーター化されたクエリハッシュ ID に従ってグループ化されたクエリを表示することができます。詳細については、 パラメーター化されたクエリのハッシュの使用(query_parameterized_hash) をご参照ください。
Incident。トラブルシューティングまたはデバッグで使用された、インシデントの実行ステータスがあるステートメントの詳細を表示します。
クエリに関する追加の詳細を表示するには、テーブルでクエリを選択して Query Details を開きます。
Snowsightのグループ化されたクエリ履歴表示を使用します。¶
Snowsight の Grouped Query History 表示を使用して、重要で頻繁に実行されるクエリの使用状況とパフォーマンスを監視できます。このグラフ表示は、 AGGREGATE_QUERY_HISTORY ビュー に記録された情報に基づいています。実行されたクエリは、 パラメーター化されたクエリハッシュ ID によってグループ化されます。経時的なキー統計の監視や、各グループに属する個々のクエリへのドリルダウンが可能です。
この表示には、Snowflakeに対するすべてのクエリが含まれますが、少数の異なるステートメントを高いスループットで繰り返し実行する Unistoreワークロード の監視と分析に特に便利です。ハイブリッドテーブル を含むワークロードでは、個々のクエリを見てパフォーマンスを監視することは困難です。
例えば、ワークロードは、ユーザー ID によってのみ異なり、非常に高速に実行され、個別に分析することが不可能な速度で繰り返される、非常に類似した何千ものポイントルックアップクエリとインサートで構成されているかもしれません。このような質問に答えるには、これらの演算子を集約したビューが不可欠です。
私のアカウントまたはワークロードで、どのグループ化クエリ(または パラメーター化されたクエリ)が最も総時間またはリソースを消費していますか?
パラメーター化されたクエリのパフォーマンスは、時間の経過とともに大きく変化していますか?
パラメーター化されたクエリにはどのような問題がありますか?ロックしますか?キューがありますか?コンパイルに時間がかかりますぁ?
パラメーター化されたクエリはどのくらいの頻度で成功または失敗しますか?1%未満ですか、それともそれ以上ですか?
グループ化されたクエリ履歴の使用方法¶
Snowsight の Grouped Query History にアクセスするには、次のようにします。
Snowsight にサインインします。
ナビゲーションメニューで Monitoring » Query History » Grouped Queries を選択します。このページでは、クエリを共通の パラメーター化されたクエリハッシュ ID でグループ分けして表示します。
注釈
個々のクエリは Grouped Queries リストにすぐには表示されません。AGGREGATE_QUERY_HISTORY 表示の記録からリストを更新する際の待ち時間は、最大180分(3時間)になることもありますが、リストへの入力はもっと速く行われることがよくあります。
任意のグループ化されたクエリを選択すると、そのパラメーター化されたクエリ・ハッシュのパフォーマンス統計が表示されます。Snowsight には、実行されたクエリの総数、失敗したクエリの数、待ち時間(p50、p90、p99)、および1分あたりの実行数が表示されます。ページの下部には、ハッシュの一部として実行された個々のクエリのサンプルが表示されます。特定の詳細を見るには、各クエリを選択します。
例えば、直近1日では、このグループで約540件のクエリが実行され、総実行時間は約3時間でした。
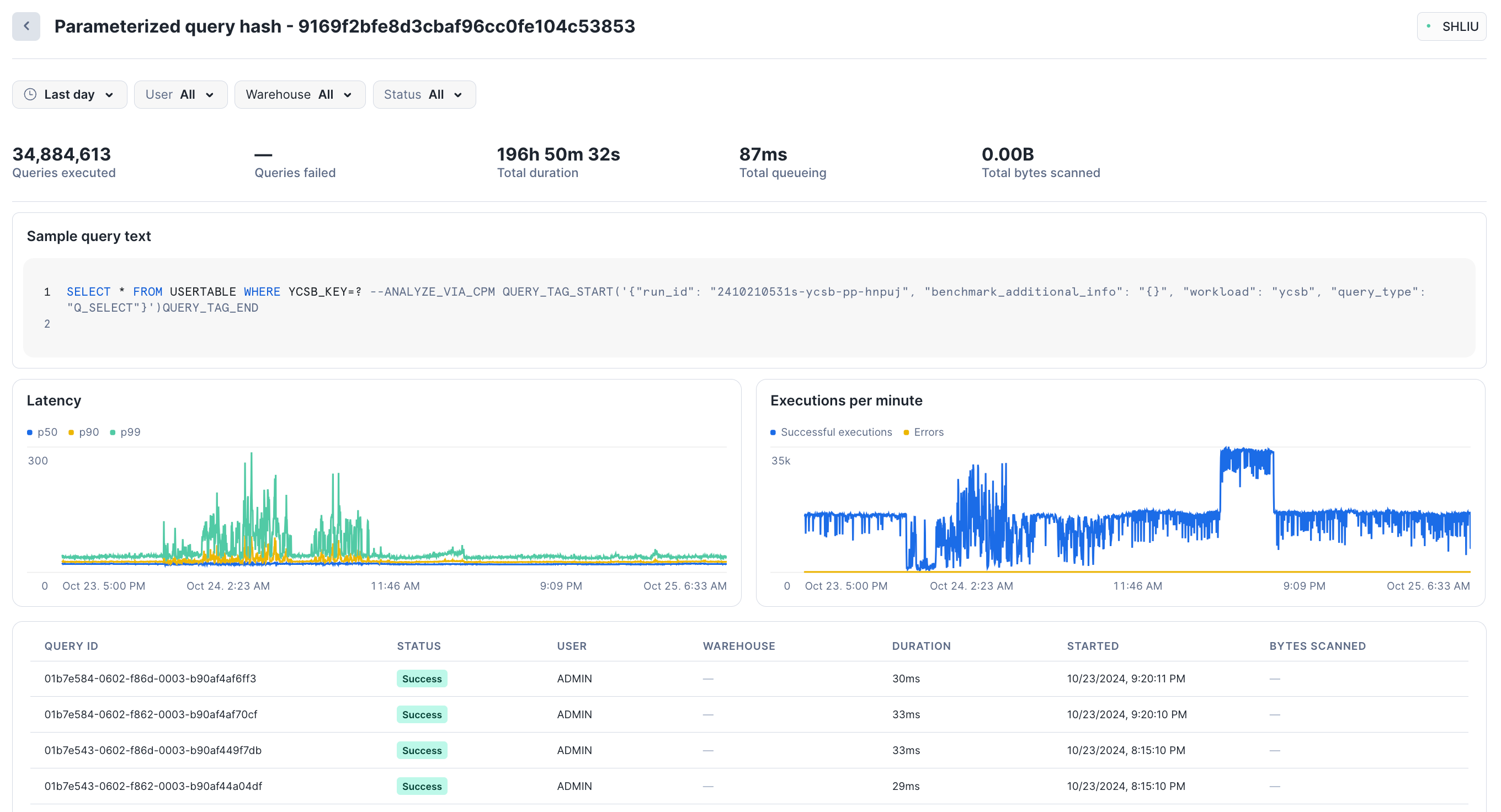
:ui:`Parameterized query hash`ビューでは、``Failed``や``Successful``といったステータスでクエリをフィルターできます。:ui:`Grouped Queries`ビューと:ui:`Parameterized query hash`ビューの両方で、日付範囲、ユーザー、ウェアハウスによるフィルターを使用できます。日付範囲は、最大でグループ化されたクエリ履歴の過去14日間までに制限されています。過去14日間よりも前に実行されたクエリに関する情報は取得できません。
なお、一部のウェアハウスはSnowflakeによって管理される内部ウェアハウスであり、:ui:`Warehouse`フィルターには表示されません。同様に、SYSTEMユーザーは:ui:`User`フィルターに表示されません。
フィルターを使用する代わりに、フィルター処理後の結果を返す集計クエリを実行できます。:doc:`/sql-reference/account-usage/aggregate_query_history`もご参照ください。
個々のクエリのリスト¶
または、:ui:`Individual Queries`も参照できます。ハイブリッドテーブルに対して作成できるクエリの量が非常に多いため、この表示はUnistoreワークロードが実行するクエリのすべてを反映しているわけではありません。この動作に関する詳細については、:ref:`label-query_history_usage_notes_acct_usage`のハイブリッドテーブルセクションをご参照くださいSnowflakeでは、Unistoreワークロードを持つすべてのユーザーが:ui:`Grouped Queries`ビューのモニターから開始することを推奨します。
グループクエリ履歴の表示に必要な権限¶
ユーザーは実行したクエリの履歴をいつでも表示できます。ユーザーのアクティビティロールは、どのクエリが表示されるかに影響します。以下のいずれかがTrueであれば、 Grouped Queries と Individual Queries の両方を表示できます。
あなたのアクティビティロールは ACCOUNTADMIN です。
あなたのアクティブロールは、 SNOWFLAKE データベース上の IMPORTED PRIVILEGES に付与されています (他のロールが SNOWFLAKE データベースのスキーマを使用できるようにする を参照)。
あなたは GOVERNANCE_VIEWER データベースのロール を持っています。
これらのロールや権限を持っていない場合は、 Individual Queries のみを見ることができます。アクセス権限の詳細については、 クエリ履歴でクエリのアクティビティをモニターする をご参照ください。
特定のクエリの詳細とプロファイルを確認する¶
Query History でクエリを選択すると、クエリの詳細とプロファイルを確認できます。
Snowflake Native App から編集されたクエリプロファイルデータ¶
Snowflake Native App Framework では、以下のコンテキストで クエリプロファイル からの情報をマスキングされます。
アプリのインストールやアップグレード時に実行されるクエリ。
アプリが所有するストアドプロシージャに由来するクエリ。
アプリが所有する非セキュアビューまたは関数を含むクエリ。
これらの型の各クエリに対して、 Snowsight はクエリプロファイルツリーを完全に表示する代わりに、クエリプロファイルデータを単一の空のノードに折りたたみます。
クエリの詳細を確認する¶
特定のクエリの詳細を確認し、成功したクエリの結果を表示するには、クエリの Query Details を開きます。
クエリの実行に関する情報については Details を確認でき、詳細には次が含まれています。
クエリのステータス。
ユーザーのローカルタイムゾーンでのクエリ開始時刻。
ユーザーのローカルタイムゾーンでのクエリ終了時刻。
クエリの実行に使用されるウェアハウスのサイズ。
クエリの期間。
クエリ ID。
クエリのクエリタグ(存在する場合)。
ドライバーのステータス。詳細については、 View the Snowflake client version をご参照ください。
クエリの送信に使用されたクライアント、ドライバー、ライブラリの名前とバージョン。例えば、 Snowsight を使用して実行されたクエリの場合、
Go 1.1.5です。セッション ID。
クエリの実行に使用されたウェアハウスと、クエリを実行したユーザーが Query Details タブ上にリストされます。
SQL Text セクションでクエリの実際のテキストを確認します。SQL テキストにカーソルを合わせてワークシートでステートメントを開くか、ステートメントをコピーします。クエリが失敗した場合は、エラーの詳細を確認できます。
Results セクションでは、クエリの結果が表示されます。表示できるのは最初の10,000行の結果のみで、クエリを実行したユーザーのみが結果を表示できます。Export Results を選択すると、結果のフルセットを CSV 形式のファイルとしてエクスポートします。
クエリプロファイルを確認する¶
Query Profile タブでは、クエリ実行プランを調べて、実行の各ステップに関する詳細を理解できます。
クエリプロファイルは、クエリのメカニズムを理解するための強力なツールです。特定のクエリのパフォーマンスや動作について詳細を知りたい場合は、いつでも使用できます。SQL クエリ式の典型的な間違いを見つけて、潜在的なパフォーマンスのボトルネックと改善の機会を特定できるように設計されています。
このセクションでは、クエリプロファイルのナビゲーションと使用方法の概要を提供します。
インターフェイス |
説明 |
|---|---|
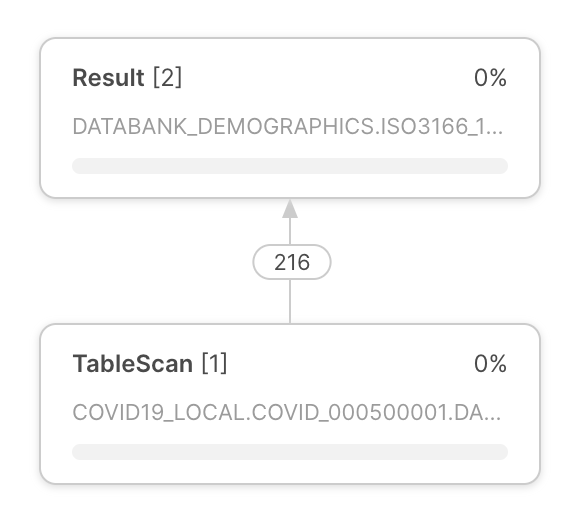
クエリ実行プラン |
クエリ実行プランは、クエリプロファイルの中央に表示されます。 クエリ実行プランは、行セット演算子を表す演算子ノードで構成されています。 演算子ノード間の矢印は、ある演算子から出て別の演算子に流れる行セットを示します。 |
演算子ノード |
各オペレーターノードには、次が含まれます。
|

クエリプロファイルナビゲーション |
クエリプロファイルの左上隅にあるボタンを使用して、次を実行します。
注釈 ステップは、クエリがステップで実行された場合にのみ表示されます。 |

情報ペイン |
クエリプロファイルでは、さまざまな情報ペインが提供されます。ペインは、クエリ実行プランに表示されます。表示されるペインは、クエリ実行プランの焦点によって異なります。 クエリプロファイルには、次の情報ペインが含まれています。
ペインで提供される情報の詳細については、 クエリプロファイル参照情報 をご参照ください。 |
Snowflake Native App からマスキングされたクエリ履歴データ¶
Snowflake Native App に関連するクエリでは、以下のコンテキストで query_text``クエリ履歴 ``error_message:doc:` から </user-guide/ui-snowsight-activity> と ` フィールドがマスクキングされます。
クエリは、アプリがインストールまたはアップグレードされたときに実行される。
アプリが所有するストアドプロシージャの子ジョブから発生するクエリ。
これらの状況では、 Snowsight のクエリ履歴のセルは空白になります。
クエリプロファイル参照情報¶
このセクションでは、各情報ペインに表示できるすべての項目について説明します。情報ペインの正確な内容は、クエリ実行プランのコンテキストによって異なります。
プロファイル概要¶
ペインは、どの処理タスクがクエリ時間を消費したかについての情報を提供します。実行時間は、クエリの処理中に「時間が費やされた場所」に関する情報を提供します。費やした時間は、次のカテゴリに分類できます。
Processing --- CPU によるデータ処理に費やされた時間。
Local Disk IO ---ローカルディスクアクセスによって処理がブロックされた時間。
Remote Disk IO ---処理がリモートディスクアクセスによってブロックされた時間。
Network Communication ---処理がネットワークデータ転送を待機していた時間。
Synchronization ---参加しているプロセス間のさまざまな同期アクティビティ。
Initialization --- クエリ処理の設定にかかった時間。
Hybrid Table Requests Throttling --- ハイブリッドテーブルに格納されたデータの読み書きのために、 スロットリングリクエスト に費やされた時間。
クエリインサイト¶
クエリ実行のパフォーマンスに影響する条件がある場合、このペインはそれらの条件に関する洞察を提供します。各インサイトには、クエリのパフォーマンスがどのように影響するかを説明し、次のステップのための一般的な推奨を提供するメッセージが含まれています。
詳細については、 クエリサイトを使用したパフォーマンスの向上 をご参照ください。
注釈
これらのインサイトには、 :doc:`/sql-reference/account-usage/query_insights`をクエリすることでアクセスできます。
統計¶
詳細ペインで提供される主な情報源は、次のセクションにグループ化されたさまざまな統計です。
IO --- クエリ中に実行される入出力操作に関する情報。
Scan progress ---これまでに特定のテーブルについてスキャンされたデータの割合。
Bytes scanned ---これまでにスキャンされたバイト数。
Percentage scanned from cache ---ローカルディスクキャッシュからスキャンされたデータの割合。
Bytes written ---書き込まれたバイト数(例: テーブルへのロード時)。
Bytes written to result --- 結果オブジェクトに書き込まれたバイト数。たとえば、
select * from . . .は、選択範囲の各フィールドを表す表形式の結果のセットを生成します。一般に、結果オブジェクトは、なんであれクエリの結果として生成されるものを表し、 Bytes written to result は、返される結果のサイズを表します。Bytes read from result --- 結果オブジェクトから読み取ったバイト数。
External bytes scanned ---ステージなどの外部オブジェクトから読み取ったバイト数。
DML ---データ操作言語(DML)クエリの統計:
Number of rows inserted ---1つまたは複数のテーブルに挿入された行の数。
Number of rows updated ---テーブルで更新された行の数。
Number of rows deleted ---テーブルから削除された行の数。
Number of rows unloaded ---データのエクスポート中にアンロードされた行の数。
Pruning ---テーブルのプルーニングの影響に関する情報:
Partitions scanned ---これまでにスキャンされたパーティションの数。
Partitions total ---特定のテーブル内のパーティションの総数。
Spilling ---中間結果がメモリに収まらない操作のディスク使用量に関する情報:
Bytes spilled to local storage ---ローカルディスクに流出したデータの量。
Bytes spilled to remote storage ---リモートディスクに流出したデータの量。
Network ---ネットワーク通信:
Bytes sent over the network --- ネットワーク経由で送信されたデータの量。
External Functions --- 外部関数の呼び出しに関する情報。
次の統計は、 SQL ステートメントによって呼び出される各外部関数について表示されます。同じ SQL ステートメントから同じ関数が複数回呼び出された場合は、統計が集計されます。
Total invocations --- 外部関数が呼び出された回数。(行が分割されるバッチの数、再試行の数(一時的なネットワークの問題がある場合)などにより、 SQL ステートメントのテキスト内にある外部関数呼び出しの数とは異なる場合がある。)
Rows sent --- 外部関数に送信された行数。
Rows received --- 外部関数から受信した行数。
Bytes sent (x-region) --- 外部関数に送信されたバイト数。ラベルに「(x地域)」が含まれている場合、データは複数の地域に送信されています(請求に影響する可能性あり)。
Bytes received (x-region) --- 外部関数から受信したバイト数。ラベルに「(x地域)」が含まれている場合、データは複数の地域に送信されています(請求に影響する可能性あり)。
Retries due to transient errors --- 一時的なエラーによる再試行の数。
Average latency per call --- Snowflakeがデータを送信してから返されたデータを受信するまでの呼び出し(コール)あたりの平均時間。
HTTP 4xx errors --- 4xxステータスコードを返した HTTP リクエストの合計数。
HTTP 5xx errors --- 5xxステータスコードを返した HTTP リクエストの合計数。
Latency per successful call (avg) --- 成功した HTTP リクエストの遅延平均。
Avg throttle latency overhead --- スロットリングが原因の速度低下による、成功したリクエストごとの平均オーバーヘッド(HTTP 429)。
Batches retried due to throttling --- HTTP 429エラーが原因で再試行されたバッチの数。
Latency per successful call (P50) --- 成功した HTTP リクエストの遅延の50パーセンタイル値。成功したすべてのリクエストの50%で、完了までにかかった時間がこの時間未満。
Latency per successful call (P90) --- 成功した HTTP リクエストの遅延の90パーセンタイル値。成功したすべてのリクエストの90%で、完了までにかかった時間がこの時間未満。
Latency per successful call (P95) --- 成功した HTTP リクエストの遅延の95パーセンタイル値。成功したすべてのリクエストの95%で、完了までにかかった時間がこの時間未満。
Latency per successful call (P99) --- 成功した HTTP リクエストの遅延の99パーセンタイル値。成功したすべてのリクエストの99%で、完了までにかかった時間がこの時間未満。
Extension Functions --- 拡張関数の呼び出しに関する情報。
Java UDF handler load time --- Java UDF ハンドラーのロードにかかった時間。
Total Java UDF handler invocations --- Java UDF ハンドラーが呼び出された回数。
Max Java UDF handler execution time --- Java UDF ハンドラーの実行にかかった最大時間。
Avg Java UDF handler execution time --- Java UDF ハンドラーの実行にかかった平均時間。
Java UDTF process() invocations --- Java UDTF プロセスメソッド が呼び出された回数。
Java UDTF process() execution time --- Java UDTF プロセスの実行にかかった時間。
Avg Java UDTF process() execution time --- Java UDTF プロセスの実行にかかった平均時間。
Java UDTF's constructor invocations --- Java UDTF コンストラクター が呼び出された回数。
Java UDTF's constructor execution time --- Java UDTF コンストラクターの実行にかかった時間。
Avg Java UDTF's constructor execution time --- Java UDTF コンストラクターの実行にかかった平均時間。
Java UDTF endPartition() invocations --- Java UDTF endPartitionメソッド が呼び出された回数。
Java UDTF endPartition() execution time --- Java UDTF endPartitionメソッドの実行にかかった時間。
Avg Java UDTF endPartition() execution time --- Java UDTF endPartition メソッドの実行にかかった平均時間。
Max Java UDF dependency download time --- Java UDF 依存関係のダウンロードにかかった最大時間。
Max JVM memory usage --- JVM によって報告されたピークメモリ使用量。
Java UDF inline code compile time in ms --- Java UDF インラインコードをコンパイルする時間。
Total Python UDF handler invocations --- Python UDF ハンドラーが呼び出された回数。
Total Python UDF handler execution time --- Python UDF ハンドラーの実行にかかった合計時間。
Avg Python UDF handler execution time --- Python UDFハンドラーの実行にかかった平均時間。
Python sandbox max memory usage --- Pythonサンドボックス環境によるピークメモリ使用量。
Avg Python env creation time:Download and install packages --- パッケージのダウンロードとインストールを含む、Python環境の作成にかかった平均時間。
Conda solver time --- Pythonパッケージの解決でCondaソルバーの実行にかかった時間。
Conda env creation time --- Python環境の作成にかかった時間。
Python UDF initialization time --- Python UDF の初期化にかかった時間。
Number of external file bytes read for UDFs --- UDFs 用に読み取られた外部ファイルのバイト数。
Number of external files accessed for UDFs --- UDFs 用にアクセスした外部ファイル数。
「一時的なエラーによる再試行」などのフィールドの値がゼロの場合、フィールドは表示されません。
最も高額なノード¶
ペインには、クエリの合計実行時間(またはクエリが複数の処理ステップで実行された場合は、表示されたクエリステップの実行時間)の1%以上持続したすべてのノードがリストされます。ペインには、実行時間の降順でノードがリストされ、ユーザーは実行時間の観点から最もコストの高い演算子ノードをすばやく見つけることができます。
属性¶
次のセクションでは、最も一般的な演算子タイプとその属性のリストを提供します。
データアクセスおよび生成演算子¶
- TableScan:
単一のテーブルへのアクセスを表します。属性:
Full table name --- スキャンされたテーブルの完全修飾名
Table alias ---存在する場合は、テーブルエイリアスを使用
Columns ---スキャンされた列のリスト
Extracted variant paths --- VARIANT 列から抽出されたパスのリスト
Scan mode --- ROW_BASED または COLUMN_BASED (ハイブリッドテーブルのスキャン にのみ表示)
Access predicates --- テーブルスキャン中に適用されるクエリからの条件
- IndexScan:
ハイブリッドテーブル上の セカンダリインデックス へのアクセスを表します。属性:
Full table name --- インデックスを含むスキャンされたテーブルの完全修飾名
Columns --- スキャンされたインデックス列のリスト
Scan mode --- ROW_BASED または COLUMN_BASED
Access predicates --- インデックススキャン中に適用されるクエリからの条件
Full index name --- スキャンされたインデックスの完全修飾名
- ValuesClause:
VALUES 句で提供される値のリスト。属性:
Number of values ---生成された値の数。
Values ---生成された値のリスト。
- ジェネレーター:
TABLE(GENERATOR(...))構造を使用して記録を生成します。属性:rowCount ---指定されたrowCountパラメーター。
timeLimit ---指定されたtimeLimitパラメーター。
- ExternalScan:
ステージオブジェクトに保存されているデータへのアクセスを表します。ステージから直接データをスキャンするクエリの一部になりますが、データロード演算子(つまり、 COPY ステートメント)にも使用できます。
属性:
Stage name ---データが読み取られるステージの名前。
Stage type ---ステージのタイプ(例: TABLE STAGE)。
- InternalObject:
内部データオブジェクト(例:Information Schemaテーブルや以前のクエリの結果)へのアクセスを表します。属性:
Object Name ---アクセスしたオブジェクトの名前またはタイプ。
データ処理演算子¶
- フィルター:
記録をフィルタリングする操作を表します。属性:
Filter condition -フィルターの実行に使用される条件。
- 参加する:
特定の条件で2つの入力を結合します。属性:
Join Type ---結合のタイプ(例: INNER、 LEFT OUTER など)
Equality Join Condition ---等価ベースの条件を使用する結合の場合、要素の結合に使用される式がリストされます。
Additional Join Condition ---一部の結合では、不平等ベースの述語を含む条件が使用されます。それらはここにリストされています。
注釈
等しくない結合述部は、処理速度を大幅に低下させる可能性があるため、可能であれば回避する必要があります。
- 集計:
入力をグループ化し、集計関数を計算します。GROUP BYや SELECT DISTINCTなどの SQL 構造を表すことができます。属性:
Grouping Keys --- GROUP BY が使用される場合、これはグループ化する式をリストします。
Aggregate Functions ---各集計グループに対して計算された関数のリスト(例: SUM)。
- GroupingSets:
GROUPING SETS、 ROLLUP 、 CUBEなどの構造を表します。属性:
Grouping Key Sets ---グループ化セットのリスト
Aggregate Functions ---各グループに対して計算された関数のリスト(例: SUM)。
- WindowFunction:
ウィンドウ関数を計算します。属性:
Aggregate Functions ---計算されたウィンドウ関数のリスト。
- ソート:
特定の式の入力を順序付けます。属性:
Sort keys ---ソート順を定義する式。
- SortWithLimit:
ソート後に入力シーケンスの一部、通常は SQL の
ORDER BY ... LIMIT ... OFFSET ...構築の結果を生成します。属性:
Sort keys ---ソート順を定義する式。
Number of rows ---生成された行数。
Offset ---生成されたタプルが発行される順序付けられたシーケンス内の位置。
- フラット化:
VARIANT 記録を処理し、場合によっては指定されたパスでそれらをフラット化します。属性:
input ---データをフラット化するために使用される入力式。
- JoinFilter:
クエリプランでさらに結合の条件に一致しない可能性があると識別できるタプルを削除する特別なフィルタリング操作。属性:
Original join ID ---除外できるタプルを識別するために使用される結合。
- UnionAll:
2つの入力を連結します。属性:なし。
- ExternalFunction:
外部関数による処理を表します。
DML 演算子¶
- 挿入:
INSERT または COPY 操作のいずれかにより、テーブルに記録を追加します。属性:
Input expressions ---挿入される式。
Table names --- 記録が追加されるテーブルの名前。
- 削除:
テーブルから記録を削除します。属性:
Table name ---記録が削除されるテーブルの名前。
- 更新:
テーブル内の記録を更新します。属性:
Table name ---更新されたテーブルの名前。
- マージ:
テーブルで MERGE 操作を実行します。属性:
Full table name ---更新されたテーブルの名前。
- アンロード:
ステージ内のテーブルからファイルにデータをエクスポートする COPY 操作を表します。属性:
Location - データが保存されるステージの名前。
メタデータ演算子¶
一部のクエリには、データ処理操作ではなく、純粋なメタデータ/カタログ操作であるステップが含まれます。これらのステップは、単一の演算子で構成されています。例は次のとおりです:
- DDL およびトランザクションコマンド:
オブジェクト、セッション、トランザクションなどの作成または変更に使用されます。通常、これらのクエリは仮想ウェアハウスによって処理されず、一致する SQL ステートメントに対応するシングルステッププロファイルになります。例:
CREATE DATABASE | SCHEMA | ...
ALTER DATABASE | SCHEMA | TABLE | SESSION | ...
DROP DATABASE | SCHEMA | TABLE | ...
COMMIT
- テーブル作成コマンド:
テーブルを作成するためのDDL コマンド。例:
CREATE TABLE
他の DDL コマンドと同様に、これらのクエリはシングルステッププロファイルになります。ただし、 CTAS ステートメントで使用する場合など、マルチステッププロファイルの一部にすることもできます。例:
CREATE TABLE ... AS SELECT ...
- クエリ結果の再利用:
前のクエリの結果を再利用するクエリ。
- メタデータベースの結果:
データにアクセスすることなく、メタデータのみに基づいて結果が計算されるクエリ。これらのクエリは、仮想ウェアハウスでは処理されません。例:
SELECT COUNT(*) FROM ...
SELECT CURRENT_DATABASE()
その他の演算子¶
- 結果:
クエリ結果を返します。属性:
List of expressions - 生成された式。
クエリプロファイルによって特定される一般的なクエリの問題¶
このセクションでは、クエリプロファイルを使用して特定およびトラブルシューティングできる問題の一部について説明します。
「爆発」結合¶
SQL ユーザーのよくある間違いの1つは、結合条件を提供せずにテーブルを結合する(「デカルト積」になる)、または1つのテーブルの記録が、別のテーブルからの記録と複数一致する条件を提供することです。このようなクエリの場合、 Join 演算子は、消費するよりも大幅に(多くの場合、桁違いに)タプルを生成します。
これは、 Join 演算子によって生成された記録の数を調べることで確認できます。通常、 Join 演算子が多くの時間を消費することにも反映されます。
ALL なしの UNION¶
SQL では、2組のデータを UNION または UNION ALL 構造のいずれかと組み合わせることができます。それらの違いは、 UNION ALL は単純に入力を連結するのに対し、 UNION は同じことを行いますが、重複排除も行います。
よくある間違いは、 UNION ALL のセマンティクスで十分な場合に UNION を使用することです。これらのクエリは、クエリプロファイルに UnionAll 演算子として表示され、余分に Aggregate 演算子が追加されます(重複排除を実行します)。
大きすぎてメモリに収まらないクエリ¶
一部の操作(例: 巨大なデータセットの重複排除)では、操作の実行に使用されるサーバーで使用可能なメモリ量が中間結果を保持するのに十分でない場合があります。その結果、クエリ処理エンジンはローカルディスクへのデータの スピル を開始します。ローカルディスクスペースが十分でない場合、スピルしたデータはリモートディスクに保存されます。
このスピルは、クエリのパフォーマンスに大きな影響を与える可能性があります(特に、リモートディスクがスピルに使用される場合)。これを軽減するには、以下をお勧めします:
より大きなウェアハウスを使用する(操作に使用可能なメモリ/ローカルディスクスペースを効果的に増やす)、または
小さいバッチでデータを処理します。
非効率なプルーニング¶
Snowflakeは、データに関する豊富な統計を収集し、クエリフィルターに基づいてテーブルの不要な部分を読み取らないようにします。ただし、これを有効にするには、データストレージの順序をクエリフィルター属性と関連付ける必要があります。
プルーニングの効率は、 TableScan 演算子の スキャンされたパーティション と パーティションの合計 統計を比較することで確認できます。前者が後者のごく一部である場合、プルーニングは効率的です。そうでない場合、プルーニングは効果がありません。
もちろん、プルーニングは、大量のデータを実際にフィルターするクエリにのみ役立ちます。プルーニング統計にデータ削減が示されていないが、 TableScan の上に多数の記録を除外する Filter 演算子がある場合、これはこのクエリに対して異なるデータ編成が有益であることを示す可能性があります。
プルーニングの詳細については、 Snowflakeテーブル構造について をご参照ください。