Snowpark Migration Accelerator: SMA 다시 실행하기¶
도구의 제한 사항을 설명하기 위해 덜 적합한 워크로드를 분석해 보겠습니다. 마이그레이션에 적합하지 않을 수 있는 코드베이스에서 도구를 실행해 보겠습니다.
두 번째 코드베이스에서 실행¶
다음 방법 중 하나를 사용하여 도구를 다시 실행할 수 있습니다.
Snowpark Migration Accelerator(SMA)를 닫았다가 다시 엽니다. 이전에 생성한 프로젝트를 열거나 새 프로젝트를 생성할 수 있습니다.
이미지와 같이 애플리케이션 윈도우 하단의 “RETRY ASSESSMENT” 버튼을 클릭합니다.
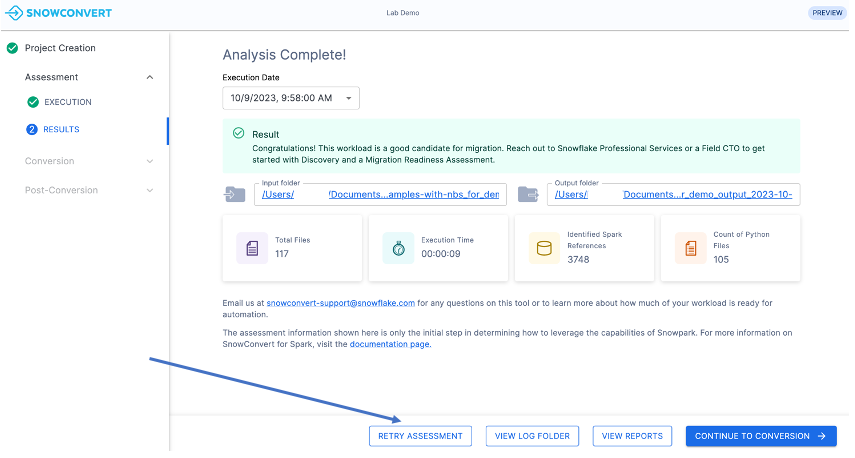
이 실습에서는 첫 번째 옵션을 선택합니다. SMA 애플리케이션을 종료하고 ‘도구 실행하기’ 섹션에서 이전 단계를 반복합니다. 이번에는 입력 폴더를 선택할 때 “needs_more_analysis”코드베이스가 포함된 디렉터리를 선택합니다.
동일한 단계를 반복하면 “Analysis Complete” 화면으로 돌아갑니다. 이번에는 결과 패널에 다른 메시지가 표시됩니다.
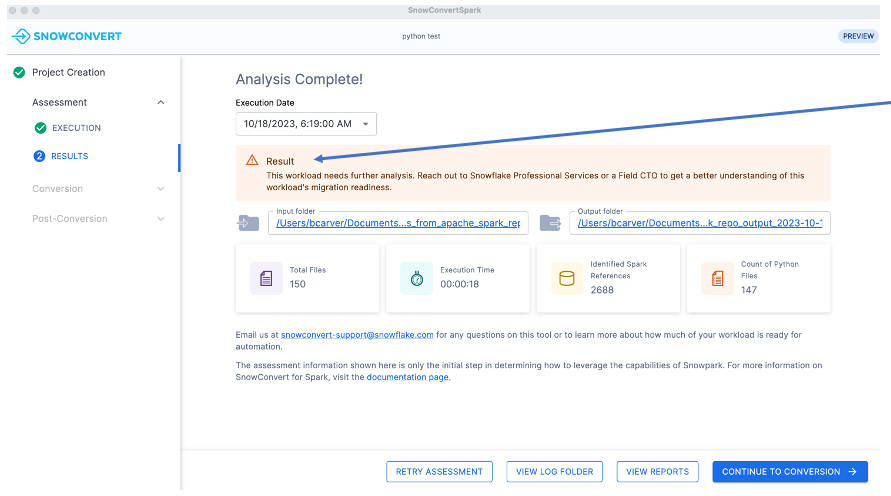
준비도 점수가 낮다고 해서(60% 미만) 워크로드의 마이그레이션 자격이 자동으로 박탈되는 것은 아닙니다. 적절한 평가를 하려면 추가 분석이 필요합니다. 앞의 예시와 마찬가지로 최종 결정을 내리기 전에 평가해야 할 몇 가지 다른 요소가 있습니다.
고려 사항¶
“추가 분석 필요” 결과를 검토할 때는 이전에 준비도 점수, 코드베이스 크기, 서드 파티 가져오기라는 세 가지 주요 요소를 기준으로 성공적인 마이그레이션을 평가했다는 점을 기억하십시오. 추가 분석이 필요한 케이스에 대해 이와 동일한 요소를 살펴 보겠습니다.
분석할 수 없는 가능한 코드입니다.¶
구문 분석 오류가 많으면(도구가 입력 코드를 이해할 수 없는 경우) 준비도 점수가 낮아집니다. 이는 코드에 익숙하지 않은 패턴이 포함되어 있을 수도 있지만, 내보낸 코드에 문제가 있거나 원래 플랫폼에서 코드가 유효하지 않을 가능성이 더 높습니다.
이 도구는 정확도 정보를 여러 가지 방식으로 표시합니다. 가장 쉬운 방법은 보고서 첫 페이지의 요약 섹션에 표시된 오차 범위를 확인하는 것입니다.
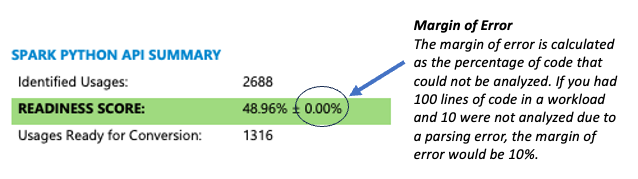
구문 분석 오류 비율이 높은 경우(5% 이상) 다음 단계를 따르십시오.
소스 코드가 원래 플랫폼에서 올바르게 실행되는지 확인합니다
구문 분석 오류의 원인을 식별하려면 Snowpark Migration Accelerator 팀에 문의하십시오
코드에 구문 분석 문제가 있는지 확인하려면 보고서 마지막에 있는 Snowpark Migration Accelerator 문제 요약을 검토하십시오. 오류 코드 SPRKPY1001 에 특히 주의하십시오. 이 오류가 파일의 5% 이상에서 나타나면 일부 코드를 구문 분석할 수 없다는 뜻입니다. 먼저 문제가 있는 코드가 소스 환경에서 작동하는지 확인합니다. 작동하는 경우 Snowpark Migration Accelerator 팀에 문의하여 도움을 받으십시오.
지원되지 않는 Spark 라이브러리¶
점수가 낮으면 코드베이스에 Snowpark가 아직 지원하지 않는 함수가 포함되어 있음을 의미합니다. 코드에서 머신 러닝 및 스트리밍 작업의 핵심 메트릭인 Spark ML, MLlib 또는 스트리밍 함수의 인스턴스가 많이 보이는 경우 특히 주의하십시오. 현재 Snowpark는 이러한 기능을 제한적으로 지원하므로 마이그레이션 계획에 영향을 미칠 수 있습니다.
크기¶
마이그레이션 점수가 낮다고 해서 항상 복잡한 마이그레이션을 의미하는 것은 아닙니다. 코드베이스의 컨텍스트를 고려하십시오. 예를 들어, 점수가 20%인데 코드 100줄에 참조가 5개뿐인 경우, 이는 최소한의 노력으로 수동으로 마이그레이션할 수 있는 관리하기 쉬운 소규모 프로젝트에 해당합니다.
Spark 참조가 적은 대규모 코드베이스(100,000라인 이상의 코드)가 있는 경우 일부 코드는 변환이 필요하지 않을 수 있습니다. 여기에는 조직에서 생성한 사용자 지정 라이브러리가 포함될 수 있습니다. 이러한 경우 변환이 필요한 코드를 결정하기 위해 추가 분석이 필요합니다.
이 예제에서는 크기가 관리 가능한 수준입니다. 이 프로젝트에는 150개의 파일이 포함되어 있으며, 대부분 Spark API 참조가 포함되어 있고 코드의 길이가 1,000라인 미만입니다.
요약¶
이 예제에서는 서드 파티 라이브러리나 크기 불일치 문제보다는 Spark의 ml, mllib 및 스트림 라이브러리를 광범위하게 사용했기 때문에 준비도 점수가 낮습니다. 이러한 복잡성을 고려할 때 다음과 같이 권장합니다.
안내가 필요한 경우 sma-support@Snowflake.com으로 문의
이러한 리소스는 특정 워크로드의 문제를 더 잘 이해하는 데 도움이 됩니다.