Snowpark Migration Accelerator: Running the SMA Again¶
To demonstrate the limitations of the tool, let’s analyze a less suitable workload. We’ll run the tool on a codebase that may not be an ideal candidate for migration.
Running on the Second Codebase¶
You can rerun the tool using either of these methods:
Close and reopen the Snowpark Migration Accelerator (SMA). You can either open your previously created project or create a new one.
Click the “RETRY ASSESSMENT” button at the bottom of the application window, as shown in the image.
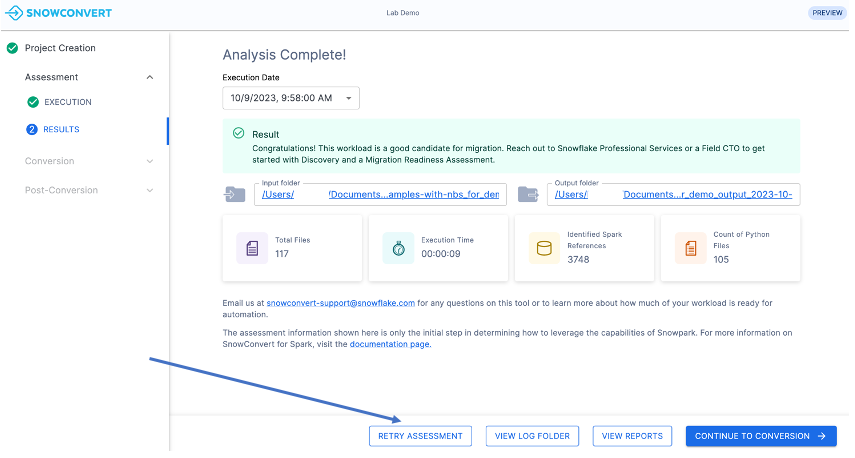
For this lab, select the first option. Exit the SMA application and repeat the previous steps from the “Running the Tool” section. This time, when selecting the input folder, choose the directory containing the “needs_more_analysis” codebase.
After repeating the same steps, you will return to the “Analysis Complete” screen. This time, you will notice a different message in the result panel.

A low Readiness Score (below 60%) doesn’t automatically disqualify a workload from migration. Additional analysis is needed to make a proper assessment. Just like in our earlier example, there are several other factors we need to evaluate before making a final decision.
Considerations¶
When reviewing a “needs more analysis” result, remember that we previously evaluated successful migrations based on three key factors: the Readiness Score, codebase size, and third-party imports. Let’s examine these same factors for cases requiring additional analysis.
Possible code that could not be analyzed:¶
If you see numerous parsing errors (where the tool cannot understand the input code), your readiness score will be lower. While this could mean the code contains unfamiliar patterns, it’s more likely that there are issues with the exported code or the code is not valid in the original platform.
The tool displays accuracy information in multiple ways. The easiest method is to check the margin of error shown in the summary section on the first page of the report.
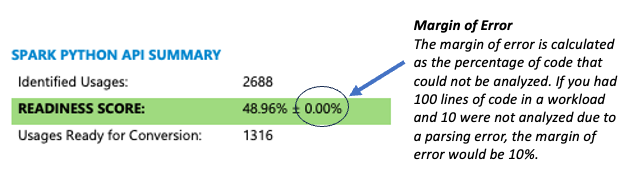
If the percentage of parsing errors is high (above 5%), follow these steps:
Verify that your source code runs correctly in the original platform
Contact the Snowpark Migration Accelerator team to identify the cause of the parsing errors
To check if there are parsing issues in your code, review the Snowpark Migration Accelerator Issue Summary at the end of the report. Pay special attention to error code SPRKPY1001. If this error appears in more than 5% of your files, it indicates that some code cannot be parsed. First, verify that the problematic code works in your source environment. If it does work, reach out to the Snowpark Migration Accelerator team for assistance.
Non-Supported Spark Libraries¶
A low score indicates that your codebase contains functions that Snowpark does not yet support. Pay special attention if you see many instances of Spark ML, MLlib, or streaming functions, as these are key indicators of machine learning and streaming operations in your code. Currently, Snowpark has limited support for these features, which may impact your migration plans.
Size¶
A low migration score may not always indicate a complex migration. Consider the context of your codebase. For example, if you have a score of 20% but only five references across 100 lines of code, this represents a small, manageable project that can be manually migrated with minimal effort.
If you have a large codebase (over 100,000 lines of code) with only a few Spark references, some of the code might not need conversion. This could include custom libraries created by your organization. In such cases, additional analysis would be needed to determine what code requires conversion.
In this example, the size is manageable. The project contains 150 files, with most containing Spark API references, and less than 1,000 lines of code.
Summary¶
In this example, the readiness score is low due to extensive use of Spark’s ml, mllib, and streaming libraries, rather than issues with third-party libraries or size inconsistencies. Given these complexities, we recommend:
Contacting sma-support@snowflake.com for guidance
Posting your questions in the Snowflake Community forums on Spark Migration
These resources will help you better understand the challenges in your specific workload.