Snowpark Migration Accelerator : Nouvelle exécution de l’outil SMA¶
Pour illustrer les limites de l’outil, analysons une charge de travail moins adaptée. Nous allons utiliser l’outil sur une base de code qui n’est peut-être pas un candidat idéal pour la migration.
Exécution sur la deuxième base de code¶
Vous pouvez réexécuter l’outil en utilisant l’une ou l’autre de ces méthodes :
Fermez et rouvrez l’outil Snowpark Migration Accelerator (SMA). Vous pouvez soit ouvrir le projet que vous venez de créer, soit en créer un nouveau.
Cliquez sur le bouton « RETRY ASSESSMENT » en bas de la fenêtre de l’application, comme le montre l’image.
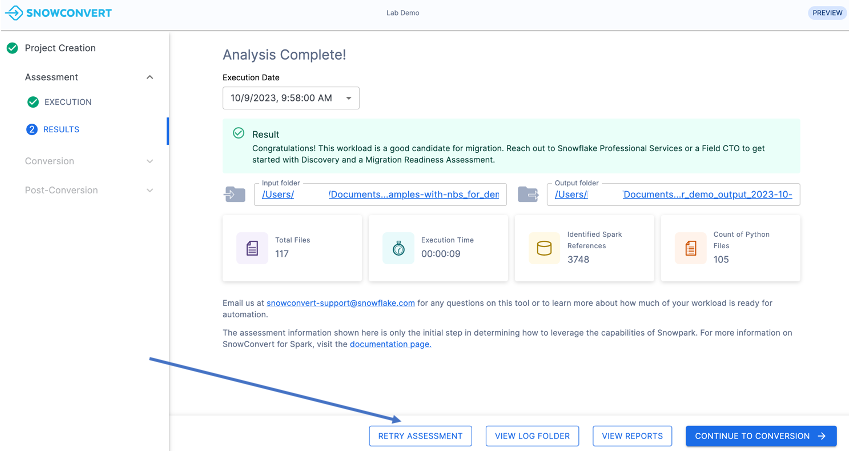
Pour cet atelier, sélectionnez la première option. Quittez l’application SMA et répétez les étapes précédentes de la section « Exécution de l’outil ». Cette fois, lors de la sélection du dossier d’entrée, choisissez le répertoire contenant la base de code « needs_more_analysis ».
Après avoir répété les mêmes étapes, vous reviendrez à l’écran « Analyse terminée ». Cette fois, vous remarquerez un message différent dans le panneau des résultats.
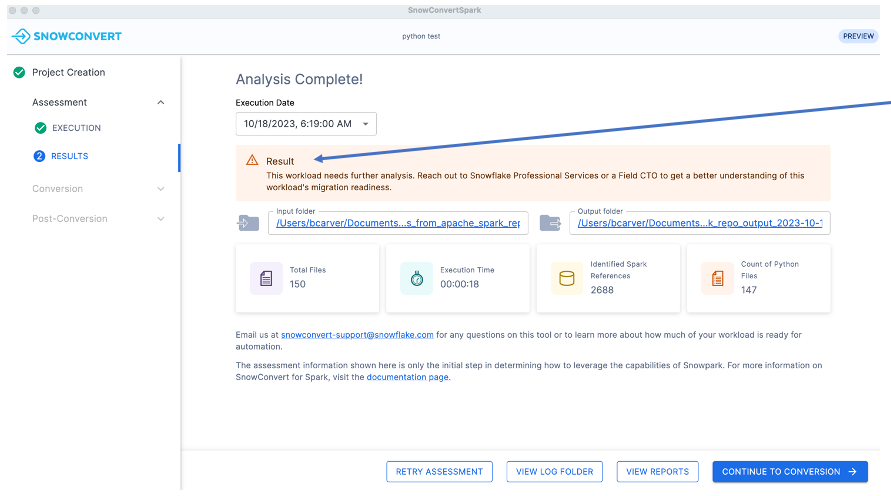
Un score de préparation faible (inférieur à 60 %) n’exclut pas automatiquement une charge de travail de la migration. Une analyse supplémentaire est nécessaire pour procéder à une évaluation correcte. Tout comme dans notre exemple précédent, il y a plusieurs autres facteurs que nous devons évaluer avant de prendre une décision finale.
Considérations¶
Lorsque vous examinez un résultat « nécessite une analyse plus approfondie », rappelez-vous que nous avons précédemment évalué les migrations abouties sur la base de trois facteurs clés : le score de préparation, la taille de la base de code et les importations tierces. Examinons ces mêmes facteurs pour les cas nécessitant une analyse supplémentaire.
Code possible qui n’a pas pu être analysé :¶
Si vous constatez de nombreuses erreurs d’analyse (lorsque l’outil ne comprend pas le code d’entrée), votre score de préparation sera plus faible. Bien que cela puisse signifier que le code contient des modèles inconnus, il est plus probable qu’il y ait des problèmes avec le code exporté ou que le code ne soit pas valide dans la plateforme d’origine.
L’outil affiche les informations relatives à la précision de plusieurs manières. La méthode la plus simple consiste à vérifier la marge d’erreur indiquée dans la section Résumé de la première page du rapport.
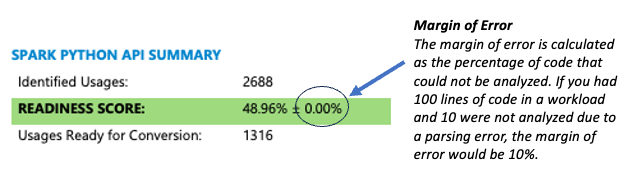
Si le pourcentage d’erreurs d’analyse est élevé (supérieur à 5 %), procédez comme suit :
Vérifiez que votre code source s’exécute correctement dans la plateforme d’origine
Contactez l’équipe de l’outil Snowpark Migration Accelerator pour identifier la cause des erreurs d’analyse.
Pour vérifier qu’il n’y a pas de problèmes d’analyse dans votre code, consultez le Résumé des problèmes de Snowpark Migration Accelerator à la fin du rapport. Accordez une attention particulière au code d’erreur SPRKPY1001. Si cette erreur apparaît dans plus de 5 % de vos fichiers, cela signifie que certains codes ne peuvent pas être analysés. Tout d’abord, vérifiez si le code problématique fonctionne dans votre environnement source. Si cela fonctionne, contactez l’équipe Snowpark Migration Accelerator pour obtenir de l’aide.
Bibliothèques Spark non prises en charge¶
Un score faible indique que votre base de code contient des fonctions qui ne sont pas encore prises en charge par Snowpark. Soyez particulièrement attentif si vous voyez de nombreuses instances de Spark ML, MLlib, ou de fonctions de diffusion, car il s’agit d’indicateurs clés de machine learning et d’opérations de diffusion dans votre code. Actuellement, Snowpark a une prise en charge limitée de ces fonctions, ce qui peut avoir un impact sur vos plans de migration.
Taille¶
Un score de migration faible n’indique pas toujours une migration complexe. Tenez compte du contexte de votre base de code. Par exemple, si vous avez un score de 20 % mais seulement cinq références sur 100 lignes de code, vous aurez un petit projet gérable qui peut être migré manuellement avec un minimum d’effort.
Si vous avez une large base de code (plus de 100 000 lignes de code) avec seulement quelques références Spark, une partie du code peut ne pas nécessiter de conversion. Il peut s’agir de bibliothèques personnalisées créées par votre organisation. Dans de tels cas, une analyse supplémentaire serait nécessaire pour déterminer quel code nécessite une conversion.
Dans cet exemple, la taille est gérable. Le projet contient 150 fichiers, la plupart contenant des références Spark API, et moins de 1 000 lignes de code.
Résumé¶
Dans cet exemple, le score de préparation est faible en raison de l’utilisation intensive des bibliothèques ml, mllib et de diffusion Spark, plutôt qu’en raison de problèmes liés à des bibliothèques tierces ou à des incohérences de taille. Compte tenu de ces complexités, nous vous recommandons :
D’envoyer un e-mail à sma-support@snowflake.com pour obtenir des conseils
De poser vos questions sur les forums de la communauté Snowflake sur la migration Spark
Ces ressources vous aideront à mieux comprendre les défis liés à votre charge de travail spécifique.