SnowConvert AI - Configurações de conversão Oracle¶
Configurações gerais de conversão¶
Conversão de objetos¶
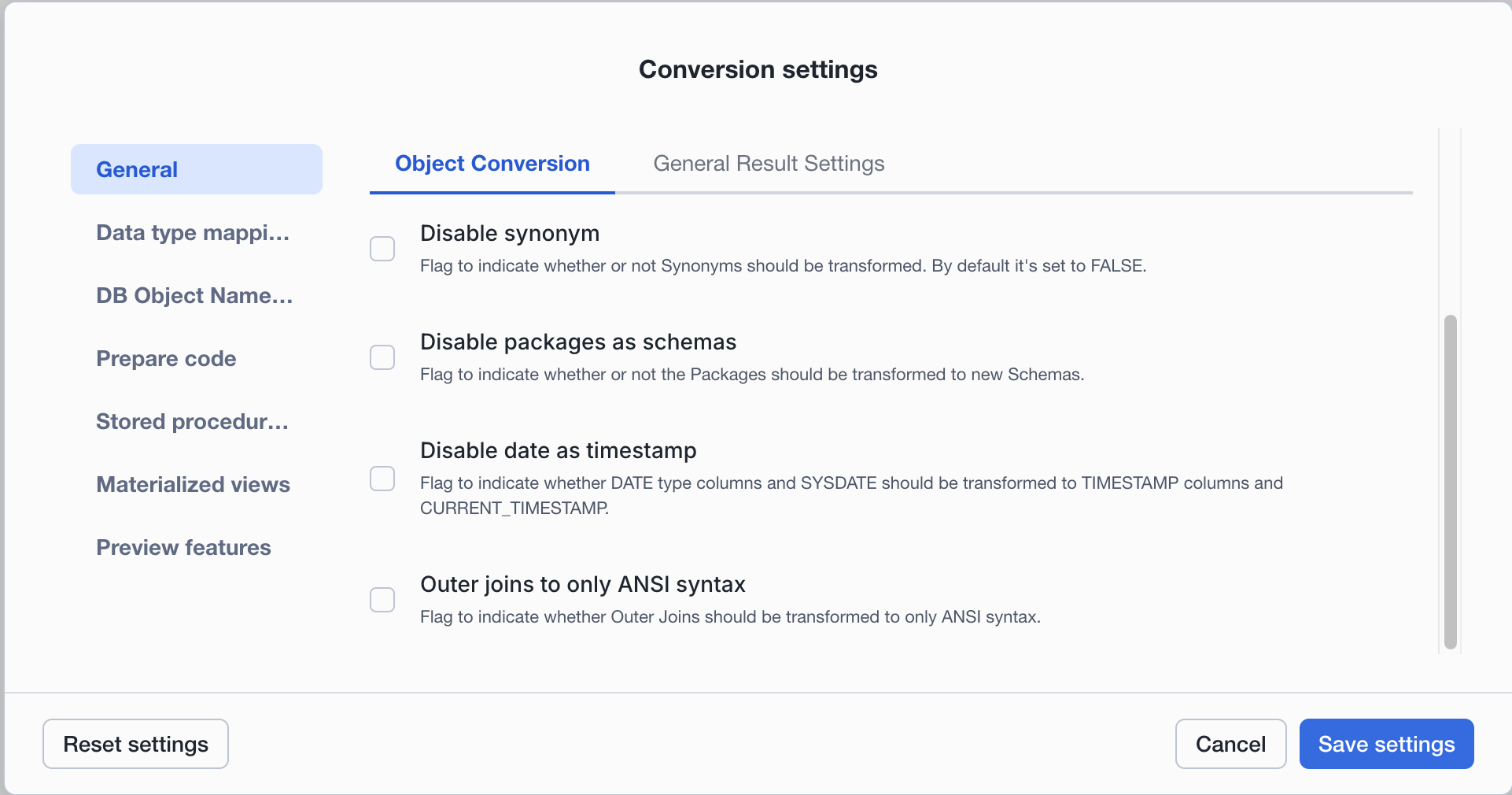
Transform Synonyms: Sinalizador para indicar se os sinônimos devem ou não ser transformados. Por padrão, ele é definido como true.
Transform Packages to new Schemas: Sinalizador para indicar se os pacotes devem ou não ser transformados em novos esquemas.
Verifique a nomenclatura do procedimento de ativação e desativação do sinalizador:
Entrada
Padrão de saída
Saída com parâmetro disablePackagesAsSchemas
Transform Date as Timestamp:
Sinalizador para indicar se SYSDATE deve ser transformado em CURRENT_DATE ou CURRENT_TIMESTAMP. Isso também afetará todas as colunas DATE que serão transformadas em TIMESTAMP.
Entrada
Padrão de saída
Saída com parâmetro disableDateAsTimestamp
Transform OUTER JOINS to ANSI Syntax: Sinalizador para indicar se junções externas devem ser transformadas apenas para a sintaxe ANSI.
Data type mappings¶
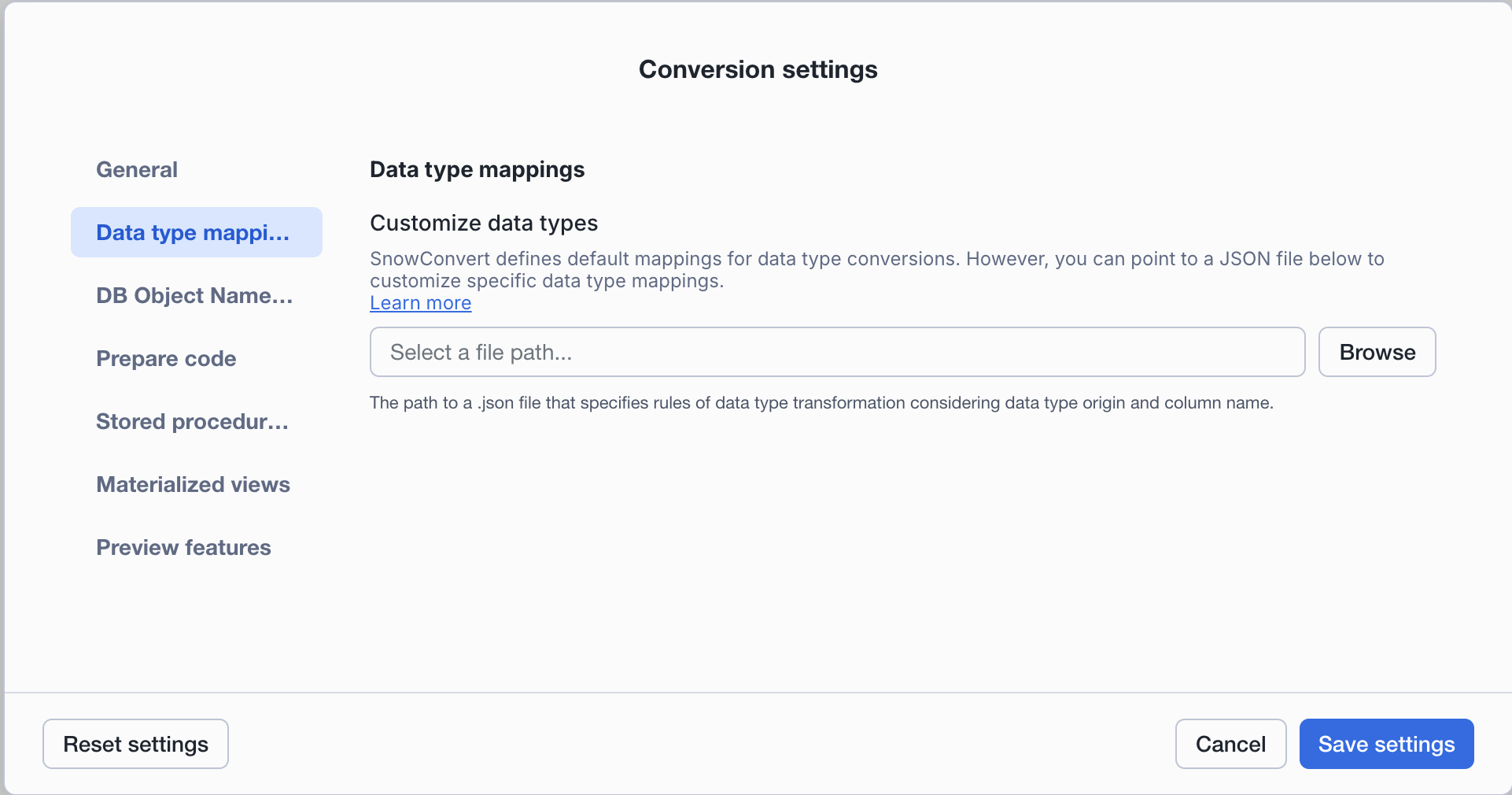
SnowConvert defines default mappings for data type conversions. However, you can point to a JSON file to customize specific data type mappings.
Customize data types: You can upload a JSON file to define specific data type transformation rules. This feature allows you to customize how data types are converted during migration.
Supported transformations include:
NUMBERto customNUMBERwith specific precision and scaleNUMBERtoDECFLOATfor preserving exact decimal precision
When you upload a data type customization file:
SnowConvert AI applies your transformation rules during conversion
Numeric literals in
INSERTstatements targeting customized columns are automatically cast to the appropriate typeA TypeMappings Report is generated showing all data type transformations applied
JSON Structure:
The JSON file supports three ways to specify data type changes:
Method |
Scope |
Use Case |
|---|---|---|
|
Global |
Transform all occurrences of a specific data type |
|
Global |
Transform columns matching a name pattern (case-insensitive substring match) |
|
Table-specific |
Transform specific columns in specific tables |
Aviso
Use column name patterns carefully. The projectTypeChanges.columns rules only apply to columns with NUMBER data types, but they match by name pattern without considering the precision or scale of the original NUMBER type. This means a pattern like "MONTH" will transform all matching NUMBER columns to the target type, regardless of their original precision (e.g., NUMBER(10,0), NUMBER(38,18), or NUMBER without precision). Always review the TypeMappings Report after conversion to verify that the transformations were applied correctly.
Priority order: When multiple rules apply to the same column, SnowConvert AI uses this priority (highest to lowest):
specificTableTypeChanges(most specific)projectTypeChanges.columns(name pattern)projectTypeChanges.types(global type mapping)
Example JSON configuration:
Download template: Copy and save the JSON structure above as your starting point.
Example transformation:
Given the following Oracle input code:
Oracle¶
And a JSON customization file with:
"NUMBER": "NUMBER(11, 2)"inprojectTypeChanges.types"NUMBER(10, 0)": "NUMBER(18, 0)"inprojectTypeChanges.types"MONTH"pattern targetingNUMBER(2,0)inprojectTypeChanges.columnsSALARYcolumn targetingNUMBER(15, 2)inspecificTableTypeChangesfor EMPLOYEES table
The output will be:
Snowflake¶
Column |
Original Type |
Transformed To |
Rule Applied |
|---|---|---|---|
employee_ID |
NUMBER |
NUMBER(11, 2) |
|
manager_YEAR |
NUMBER(10, 0) |
NUMBER(18, 0) |
|
manager_MONTH |
NUMBER(10, 0) |
NUMBER(2, 0) |
|
salary |
NUMBER(12, 2) |
NUMBER(15, 2) |
|
Guia de resultados gerais¶
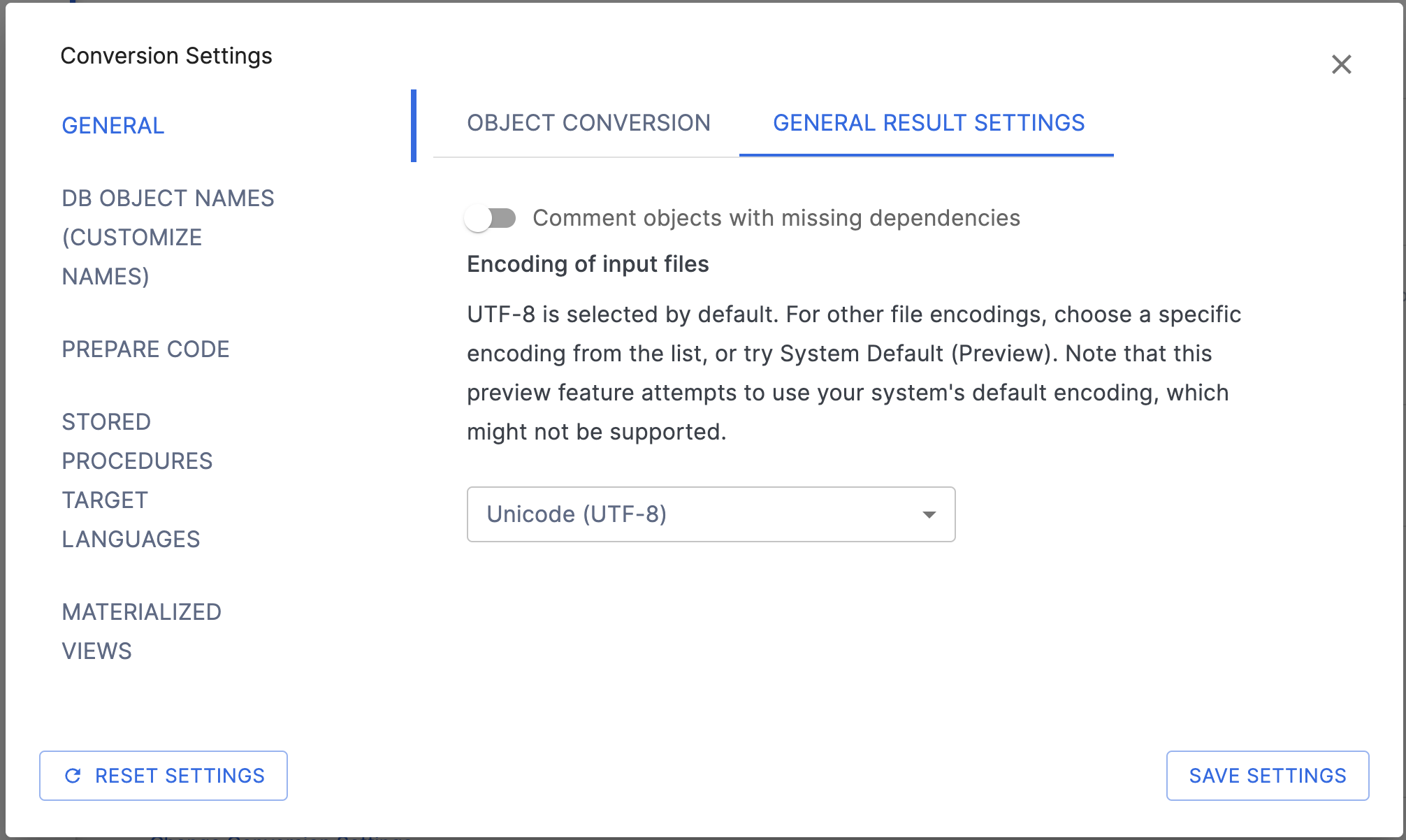
Objetos de comentário com dependências ausentes: este sinalizador indica se o usuário deseja comentar os nós com dependências ausentes.
Definir a codificação dos arquivos de entrada: verifique as Configurações gerais de conversão para obter mais detalhes.
Nota
Para revisar as configurações que se aplicam a todas as linguagens compatíveis, acesse o seguinte artigo SnowConvert AI - Configurações gerais de conversão.
Configurações de nomes de objetos DB¶
.png)
Schema: O valor da cadeia de caracteres especifica o nome do esquema personalizado a ser aplicado. Se não for especificado, será usado o nome original do banco de dados. Exemplo: DB1.myCustomSchema.Table1.
Database: O valor da cadeia de caracteres especifica o nome do banco de dados personalizado a ser aplicado. Exemplo: MyCustomDB.PUBLIC.Table1.
Default: Nenhuma das configurações acima será usada nos nomes dos objetos.
Preparar configurações de código¶
.png)
Descrição¶
Preparar meu código: sinalizador para indicar se o código de entrada deve ser processado antes da análise e da transformação. Isso pode ser útil para melhorar o processo de análise. Por padrão, ele é definido como FALSE.
Divide os objetos de nível superior do código de entrada em vários arquivos. As pastas seriam organizadas da seguinte forma:
Cópia
Exemplo¶
Entrada¶
Saída¶
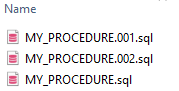
Assuma que o nome dos arquivos corresponde ao nome dos objetos de nível superior nos arquivos de entrada.
Dentro da pasta “nome do esquema”, deve haver tantos arquivos quantos objetos de nível superior no código de entrada. Além disso, é possível ter cópias de alguns arquivos quando vários objetos de nível superior do mesmo tipo têm o mesmo nome. Nesse caso, os nomes dos arquivos serão enumerados em ordem crescente.
Requisitos ¶
Para identificar objetos de nível superior, uma tag deve ser incluída em um comentário antes de sua declaração. Nosso script Extração gera essas tags.
A tag deve seguir o seguinte formato:
Você pode seguir o próximo exemplo:
Configurações de taxa de conversão¶
.png)
Nessa página, você pode escolher se a porcentagem de código convertido com êxito é calculada usando linhas de código ou usando o número total de caracteres. A taxa de conversão de caracteres é a opção padrão. Você pode ler toda a documentação sobre a taxa na página de documentação.
Configurações de linguagens de destino de procedimentos armazenados¶
.png)
Nessa página, você pode escolher se os procedimentos armazenados serão migrados para JavaScript incorporados no Snow SQL ou para o Snowflake Scripting. A opção padrão é Snowflake Scripting.
Redefinir configurações: a opção de redefinição de configurações aparece em todas as páginas. Se você tiver feito alterações, será possível redefinir SnowConvert AI às suas configurações padrão originais.