SnowConvert AI – Oracle-Konvertierungseinstellungen¶
Allgemeine Konvertierungseinstellungen¶
Objektkonvertierung¶
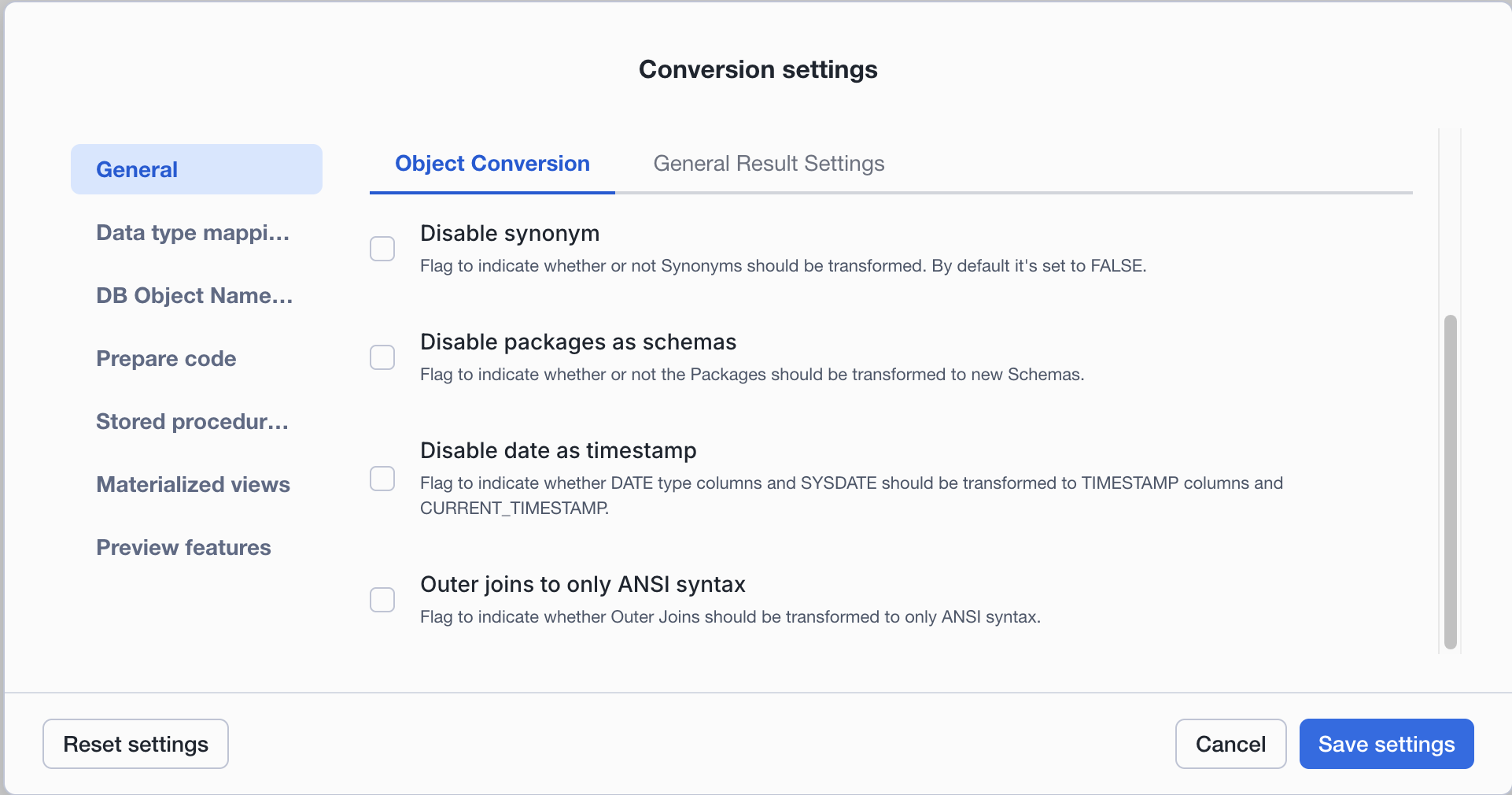
Transform Synonyms: Flag, das angibt, ob Synonyme transformiert werden sollen. Standardmäßig ist es auf true festgelegt.
Transform Packages to new Schemas: Flag, das angibt, ob die Pakete in neue Schemas transformiert werden sollen.
Bitte überprüfen Sie die Benennung der Prozedur zum Aktivieren und Deaktivieren des Flags:
Eingabe
Ausgabestandard
Ausgabe mit Parameter disablePackagesAsSchemas
Transform Date as Timestamp:
Kennzeichen, das angibt, ob SYSDATE in CURRENT_DATE oder CURRENT_TIMESTAMP umgewandelt werden soll. Dies betrifft auch alle Spalten DATE, die in TIMESTAMP umgewandelt werden.
Eingabe
Ausgabestandard
Ausgabe mit Parameter disableDateAsTimestamp
Transform OUTER JOINS to ANSI Syntax: Flag, das angibt, ob Outer Joins nur in die ANSI-Syntax transformiert werden sollen.
Data type mappings¶
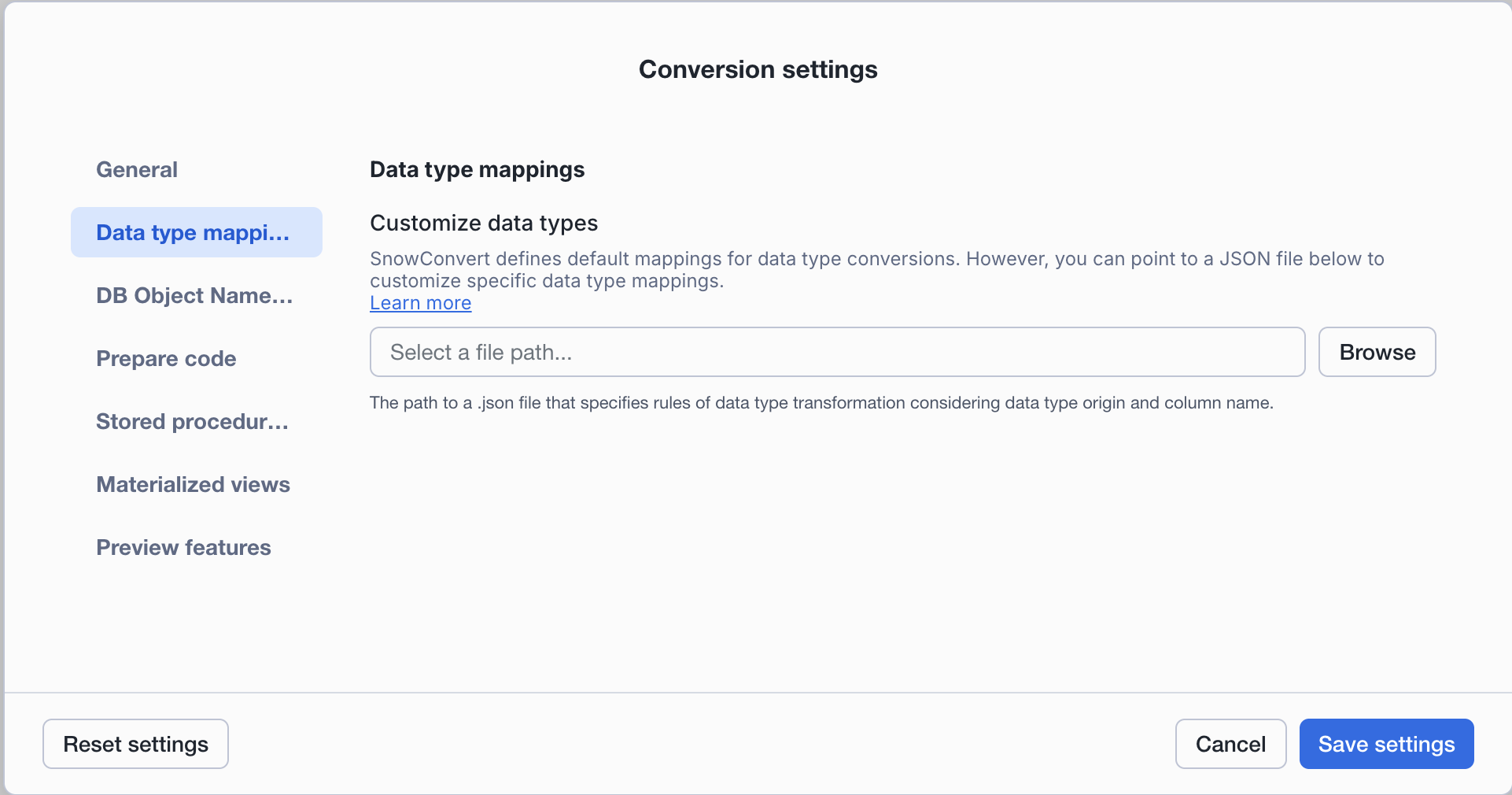
SnowConvert defines default mappings for data type conversions. However, you can point to a JSON file to customize specific data type mappings.
Customize data types: You can upload a JSON file to define specific data type transformation rules. This feature allows you to customize how data types are converted during migration.
Supported transformations include:
NUMBERto customNUMBERwith specific precision and scaleNUMBERtoDECFLOATfor preserving exact decimal precision
When you upload a data type customization file:
SnowConvert AI applies your transformation rules during conversion
Numeric literals in
INSERTstatements targeting customized columns are automatically cast to the appropriate typeA TypeMappings Report is generated showing all data type transformations applied
JSON Structure:
The JSON file supports three ways to specify data type changes:
Method |
Scope |
Use Case |
|---|---|---|
|
Global |
Transform all occurrences of a specific data type |
|
Global |
Transform columns matching a name pattern (case-insensitive substring match) |
|
Table-specific |
Transform specific columns in specific tables |
Warnung
Use column name patterns carefully. The projectTypeChanges.columns rules only apply to columns with NUMBER data types, but they match by name pattern without considering the precision or scale of the original NUMBER type. This means a pattern like "MONTH" will transform all matching NUMBER columns to the target type, regardless of their original precision (e.g., NUMBER(10,0), NUMBER(38,18), or NUMBER without precision). Always review the TypeMappings Report after conversion to verify that the transformations were applied correctly.
Priority order: When multiple rules apply to the same column, SnowConvert AI uses this priority (highest to lowest):
specificTableTypeChanges(most specific)projectTypeChanges.columns(name pattern)projectTypeChanges.types(global type mapping)
Example JSON configuration:
Download template: Copy and save the JSON structure above as your starting point.
Example transformation:
Given the following Oracle input code:
Oracle¶
And a JSON customization file with:
"NUMBER": "NUMBER(11, 2)"inprojectTypeChanges.types"NUMBER(10, 0)": "NUMBER(18, 0)"inprojectTypeChanges.types"MONTH"pattern targetingNUMBER(2,0)inprojectTypeChanges.columnsSALARYcolumn targetingNUMBER(15, 2)inspecificTableTypeChangesfor EMPLOYEES table
The output will be:
Snowflake¶
Column |
Original Type |
Transformed To |
Rule Applied |
|---|---|---|---|
employee_ID |
NUMBER |
NUMBER(11, 2) |
|
manager_YEAR |
NUMBER(10, 0) |
NUMBER(18, 0) |
|
manager_MONTH |
NUMBER(10, 0) |
NUMBER(2, 0) |
|
salary |
NUMBER(12, 2) |
NUMBER(15, 2) |
|
Registerkarte „General Results“¶
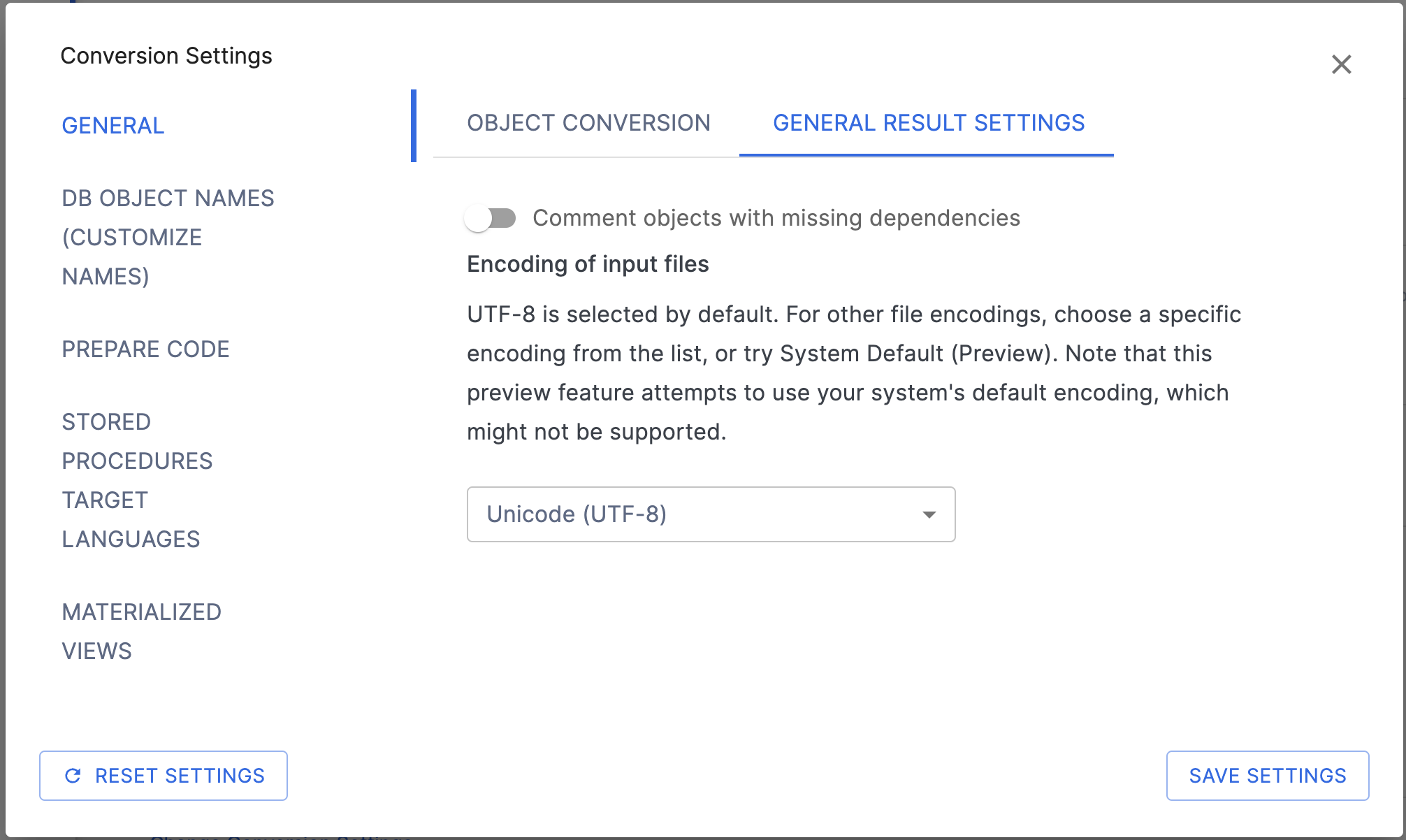
Comment objects with missing dependencies: Dieses Flag gibt an, ob Benutzende einen Kommentar zu Knoten mit fehlenden Abhängigkeiten abgeben möchten.
Set encoding of the input files: Weitere Details dazu finden Sie unter Allgemeine Konvertierungseinstellungen.
Bemerkung
Die Einstellungen, die für alle unterstützten Sprachen gelten, finden Sie in dem folgenden Artikel.
DB Objects Names Settings¶
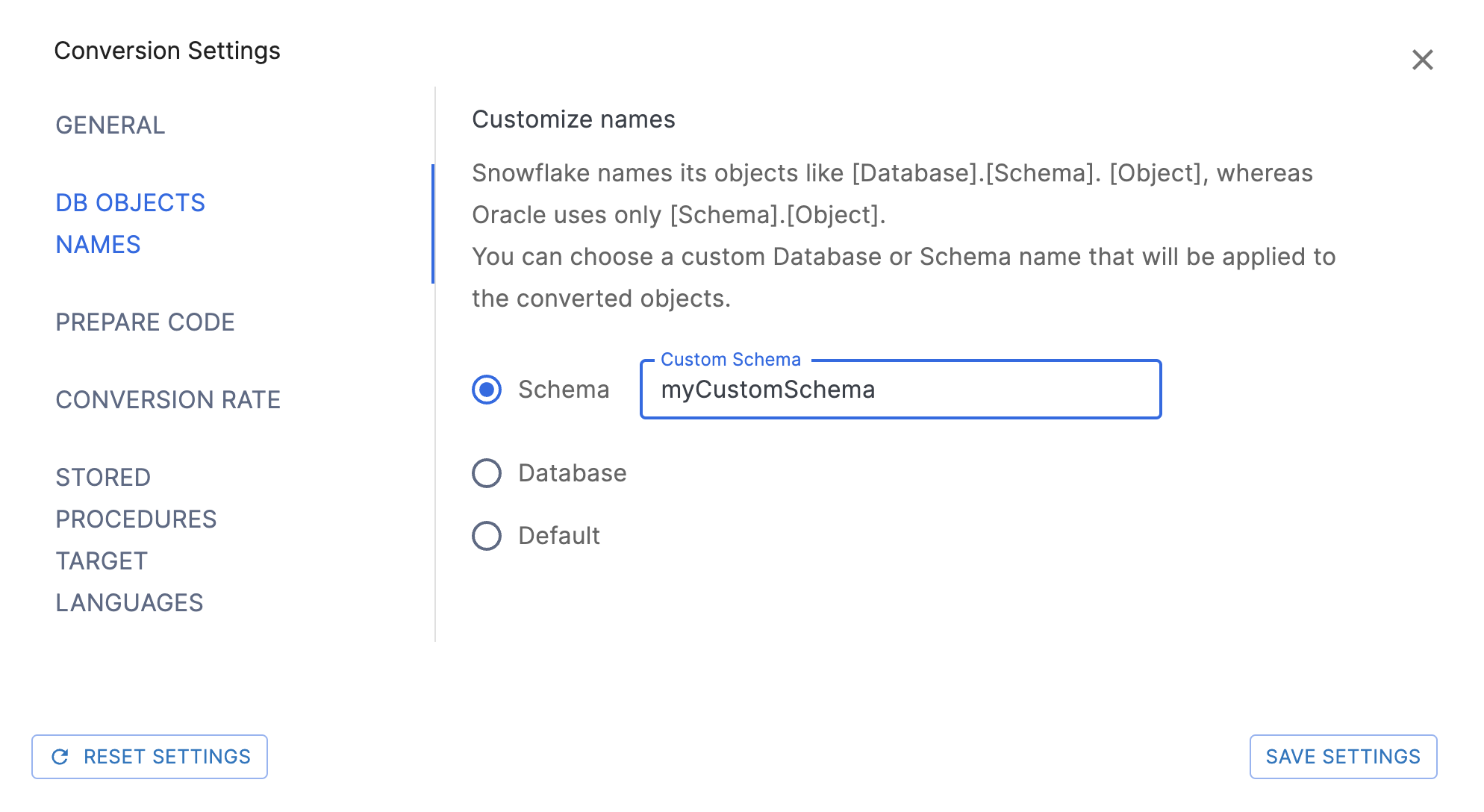
Schema: Der Zeichenfolgenwert gibt den benutzerdefinierten Schemanamen an, der angewendet werden soll. Wenn er nicht angegeben ist, wird der ursprüngliche Datenbankname verwendet. Beispiel: DB1.myCustomSchema.Table1.
Database: Der Zeichenfolgenwert gibt den Namen benutzerdefinierten Datenbanknamen an, die angewendet werden soll. Beispiel: MyCustomDB.PUBLIC.Table1.
Default: Keine der oben genannten Einstellungen wird in den Objektnamen verwendet.
Prepare Code Settings¶
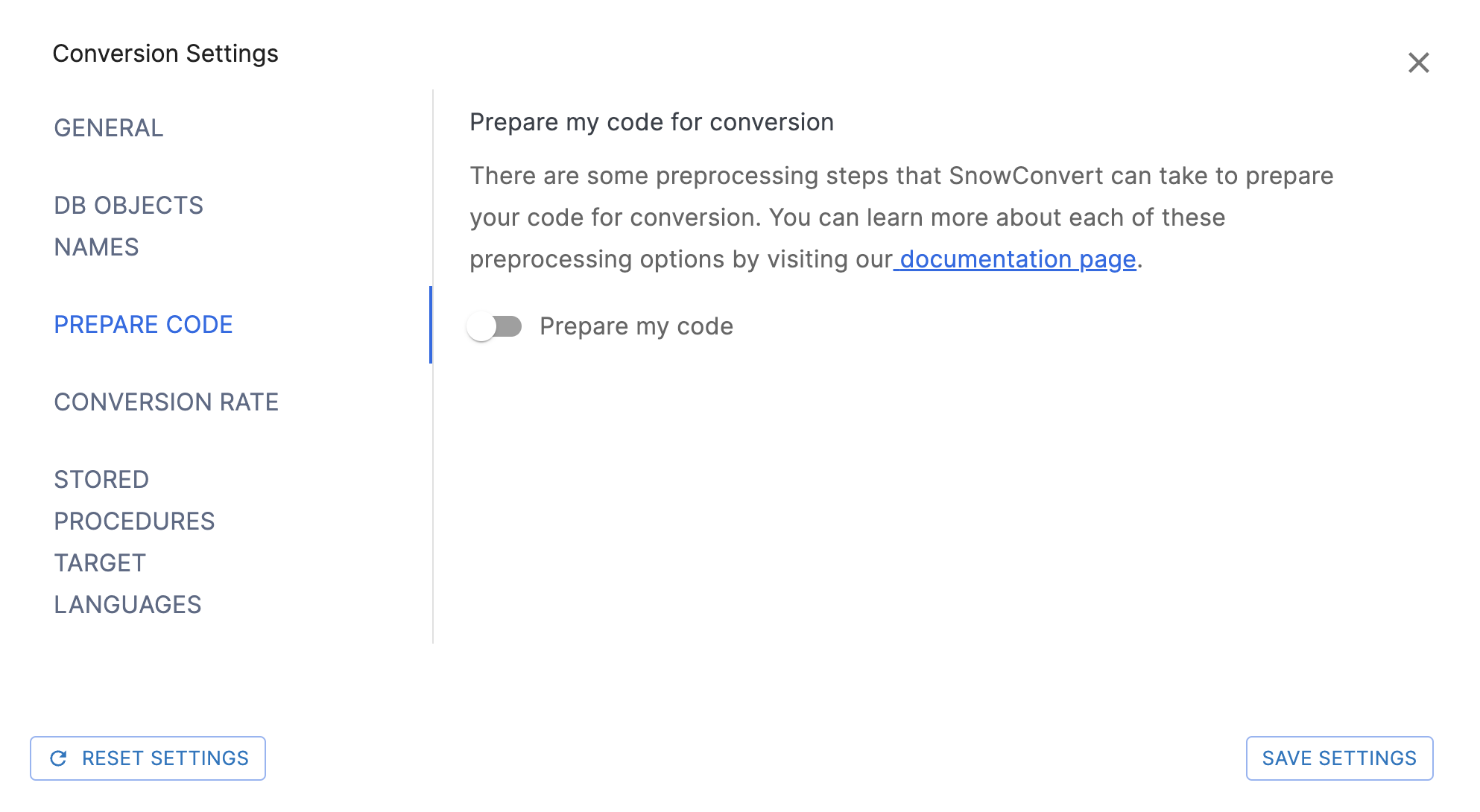
Beschreibung¶
Prepare my code: Flag, das angibt, ob der Eingabecode vor dem Parsen und Transformieren verarbeitet werden soll. Dies kann nützlich sein, um den Parsing-Prozess zu verbessern. Standardmäßig ist das Flag auf FALSE festgelegt.
Teilt die Eingabecode-Objekte der obersten Ebene in mehrere Dateien auf. Die darin enthaltenen Ordner wären wie folgt organisiert:
Kopieren
Beispiel¶
Eingabe¶
Ausgabe¶
Es wird davon ausgegangen, dass der Name der Dateien dem Namen der Objekte der obersten Ebene in den Eingabedateien entspricht.
Innerhalb des Ordners „schema name“ sollten sich so viele Dateien befinden, wie es Objekte der obersten Ebene im Eingabecode gibt. Außerdem ist es möglich, dass einige Dateien mehrfach vorhanden sind, wenn mehrere Objekte desselben Typs auf oberster Ebene denselben Namen haben. In diesem Fall werden die Dateinamen in aufsteigender Reihenfolge aufgeführt.
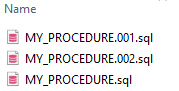
Anforderungen ¶
Um Objekte der obersten Ebene zu identifizieren, muss vor ihrer Deklaration ein Tag in einen Kommentar eingefügt werden. Diese Tags werden von unseren Skripten für die Extraktion erzeugt.
Das Tag sollte das folgende Format haben:
Sie können dem nächsten Beispiel folgen:
Conversion Rate Settings¶
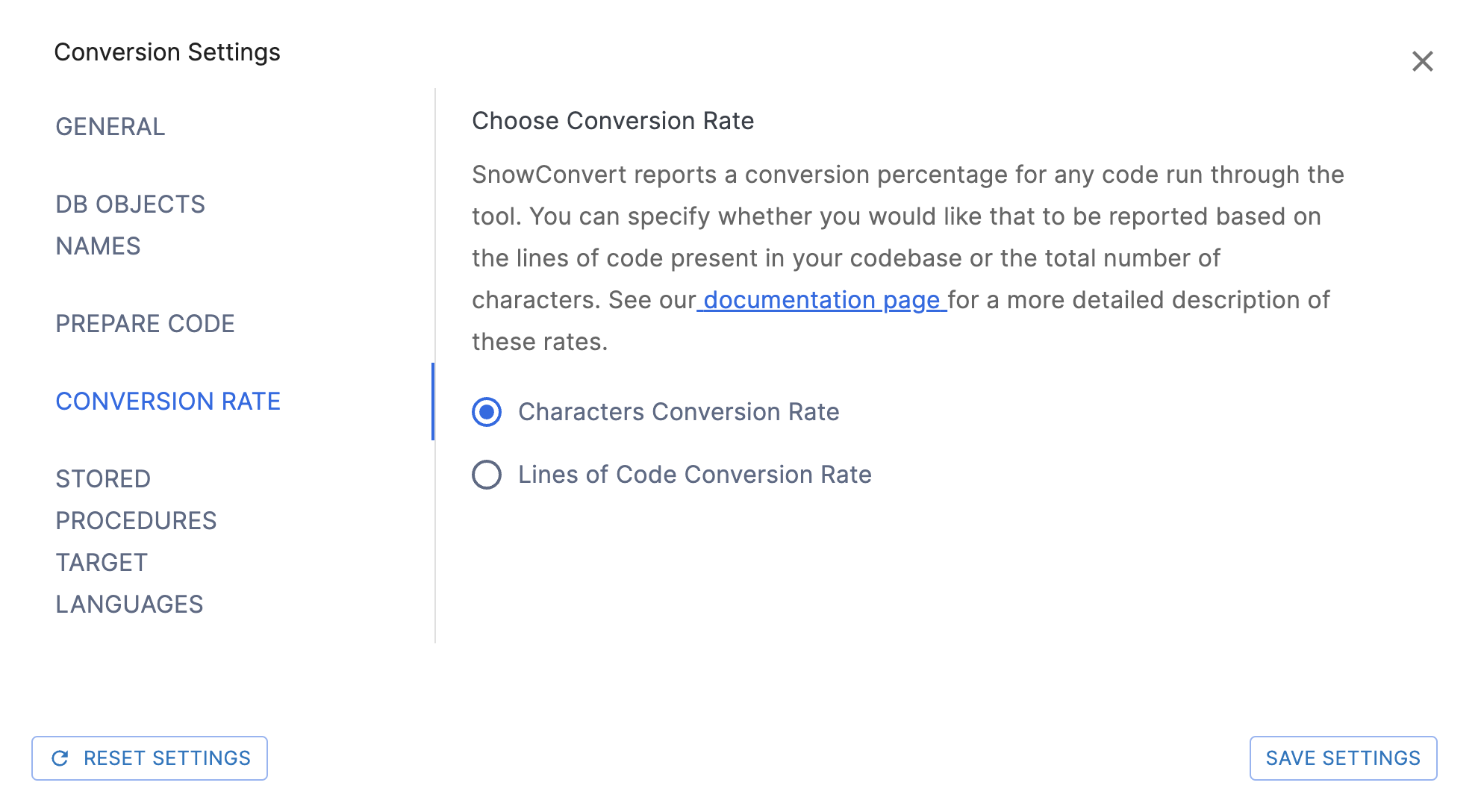
Auf dieser Seite können Sie wählen, ob der Prozentsatz des erfolgreich konvertierten Codes anhand der Codezeilen oder anhand der Gesamtzahl der Zeichen berechnet werden soll. Character Conversion Rate ist die Standardoption. Sie können die gesamte Dokumentation der Konvertierungsraten auf der Dokumentationsseite einsehen.
Stored Procedures Target Languages Settings¶
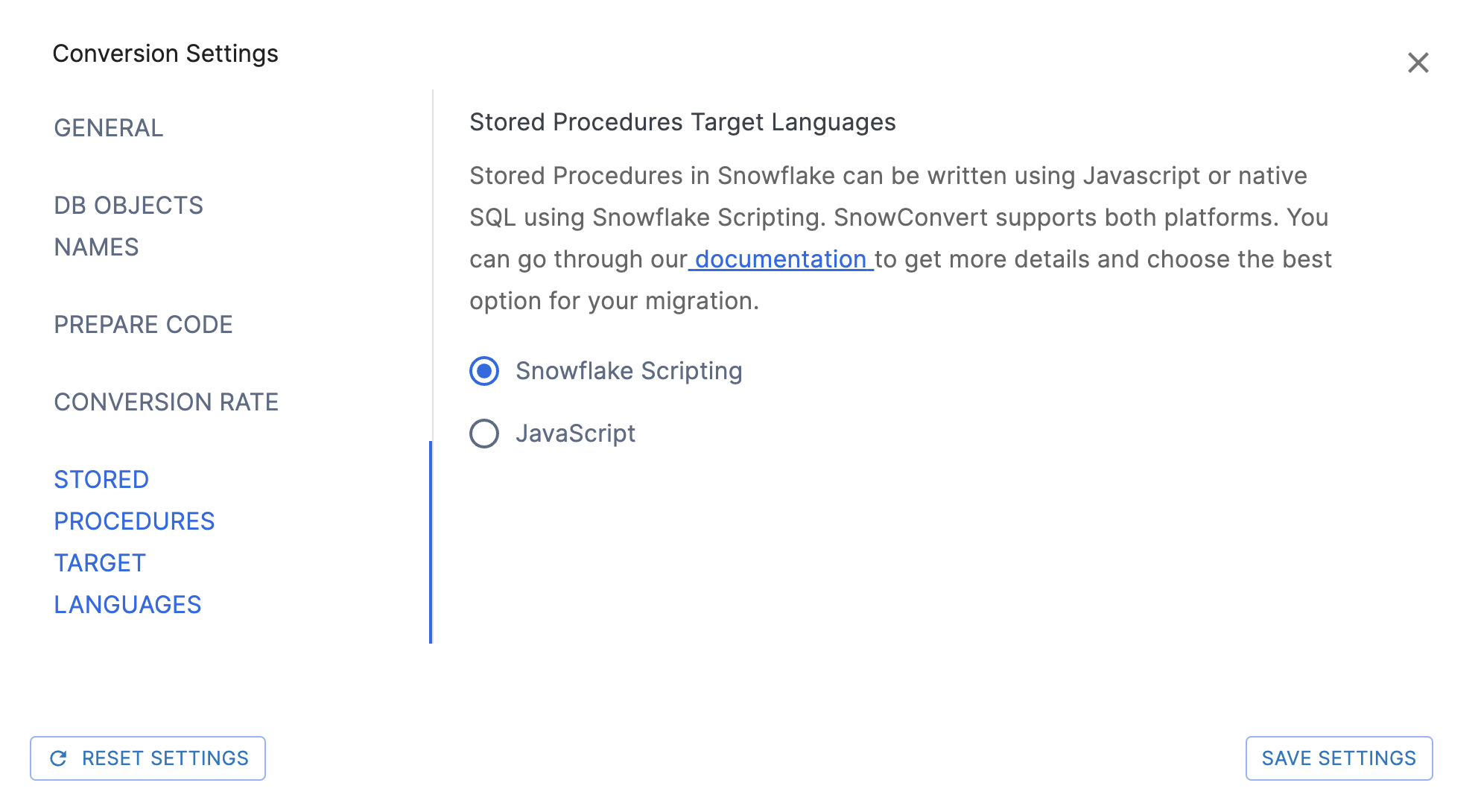
Auf dieser Seite können Sie wählen, ob gespeicherte Prozeduren nach in Snowflake SQL eingebettetes JavaScript oder nach Snowflake Scripting migriert werden sollen. Die Standardoption ist Snowflake Scripting.
Reset Settings: Diese Option zum Zurücksetzen der Einstellungen wird auf jeder Seite angezeigt. Wenn Sie Änderungen vorgenommen haben, können Sie SnowConvert AI auf die ursprünglichen Standardeinstellungen zurücksetzen.