SnowConvert AI - Oracle変換設定¶
一般的な変換設定¶
オブジェクトの変換¶
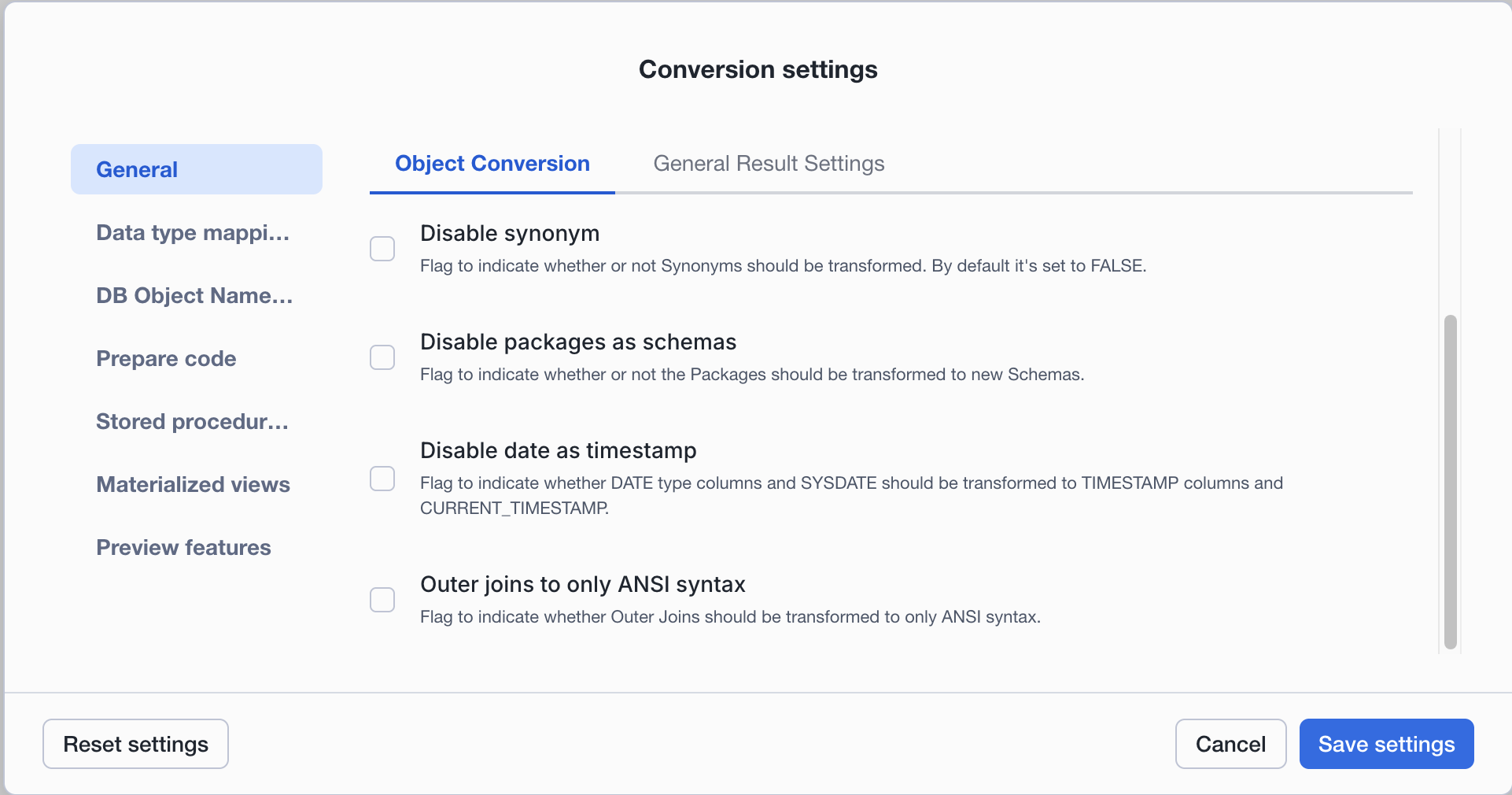
同義語を変換する: 同義語を変換するかどうかを示すフラグ。デフォルトではtrueに設定されています。
パッケージを新しいスキーマに変換する: パッケージを新しいスキーマに変換するかどうかを示すフラグ。
フラグを有効や無効にするプロシージャの名前を確認してください。
入力
出力デフォルト
disablePackagesAsSchemas パラメーター付きの出力
タイムスタンプとして日付を変換する:
SYSDATE を CURRENT_DATE または CURRENT_TIMESTAMP に変換すべきかどうかを示すフラグ。これは、 TIMESTAMP に変換されるすべての DATE 列にも影響します。
入力
出力デフォルト
disableDateAsTimestamp パラメーター付きの出力
OUTER JOINS を ANSI 構文に変換する: 外側結合を ANSI 構文のみに変換するかどうかを示すフラグ。
Data type mappings¶
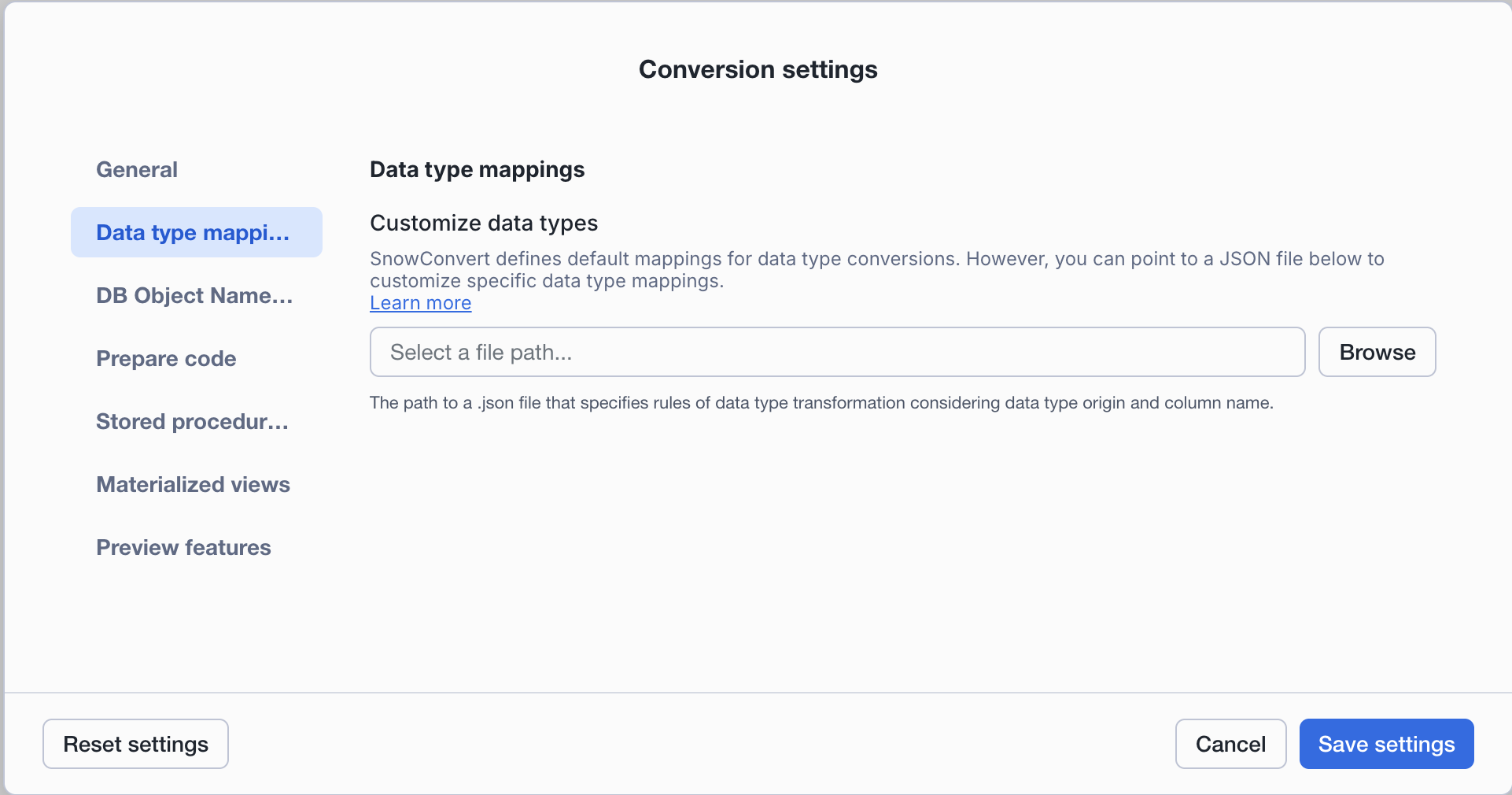
SnowConvert defines default mappings for data type conversions. However, you can point to a JSON file to customize specific data type mappings.
Customize data types: You can upload a JSON file to define specific data type transformation rules. This feature allows you to customize how data types are converted during migration.
Supported transformations include:
NUMBERto customNUMBERwith specific precision and scaleNUMBERtoDECFLOATfor preserving exact decimal precision
When you upload a data type customization file:
SnowConvert AI applies your transformation rules during conversion
Numeric literals in
INSERTstatements targeting customized columns are automatically cast to the appropriate typeA TypeMappings Report is generated showing all data type transformations applied
JSON Structure:
The JSON file supports three ways to specify data type changes:
Method |
Scope |
Use Case |
|---|---|---|
|
Global |
Transform all occurrences of a specific data type |
|
Global |
Transform columns matching a name pattern (case-insensitive substring match) |
|
Table-specific |
Transform specific columns in specific tables |
警告
Use column name patterns carefully. The projectTypeChanges.columns rules only apply to columns with NUMBER data types, but they match by name pattern without considering the precision or scale of the original NUMBER type. This means a pattern like "MONTH" will transform all matching NUMBER columns to the target type, regardless of their original precision (e.g., NUMBER(10,0), NUMBER(38,18), or NUMBER without precision). Always review the TypeMappings Report after conversion to verify that the transformations were applied correctly.
Priority order: When multiple rules apply to the same column, SnowConvert AI uses this priority (highest to lowest):
specificTableTypeChanges(most specific)projectTypeChanges.columns(name pattern)projectTypeChanges.types(global type mapping)
Example JSON configuration:
Download template: Copy and save the JSON structure above as your starting point.
Example transformation:
Given the following Oracle input code:
Oracle¶
And a JSON customization file with:
"NUMBER": "NUMBER(11, 2)"inprojectTypeChanges.types"NUMBER(10, 0)": "NUMBER(18, 0)"inprojectTypeChanges.types"MONTH"pattern targetingNUMBER(2,0)inprojectTypeChanges.columnsSALARYcolumn targetingNUMBER(15, 2)inspecificTableTypeChangesfor EMPLOYEES table
The output will be:
Snowflake¶
Column |
Original Type |
Transformed To |
Rule Applied |
|---|---|---|---|
employee_ID |
NUMBER |
NUMBER(11, 2) |
|
manager_YEAR |
NUMBER(10, 0) |
NUMBER(18, 0) |
|
manager_MONTH |
NUMBER(10, 0) |
NUMBER(2, 0) |
|
salary |
NUMBER(12, 2) |
NUMBER(15, 2) |
|
一般結果タブ¶
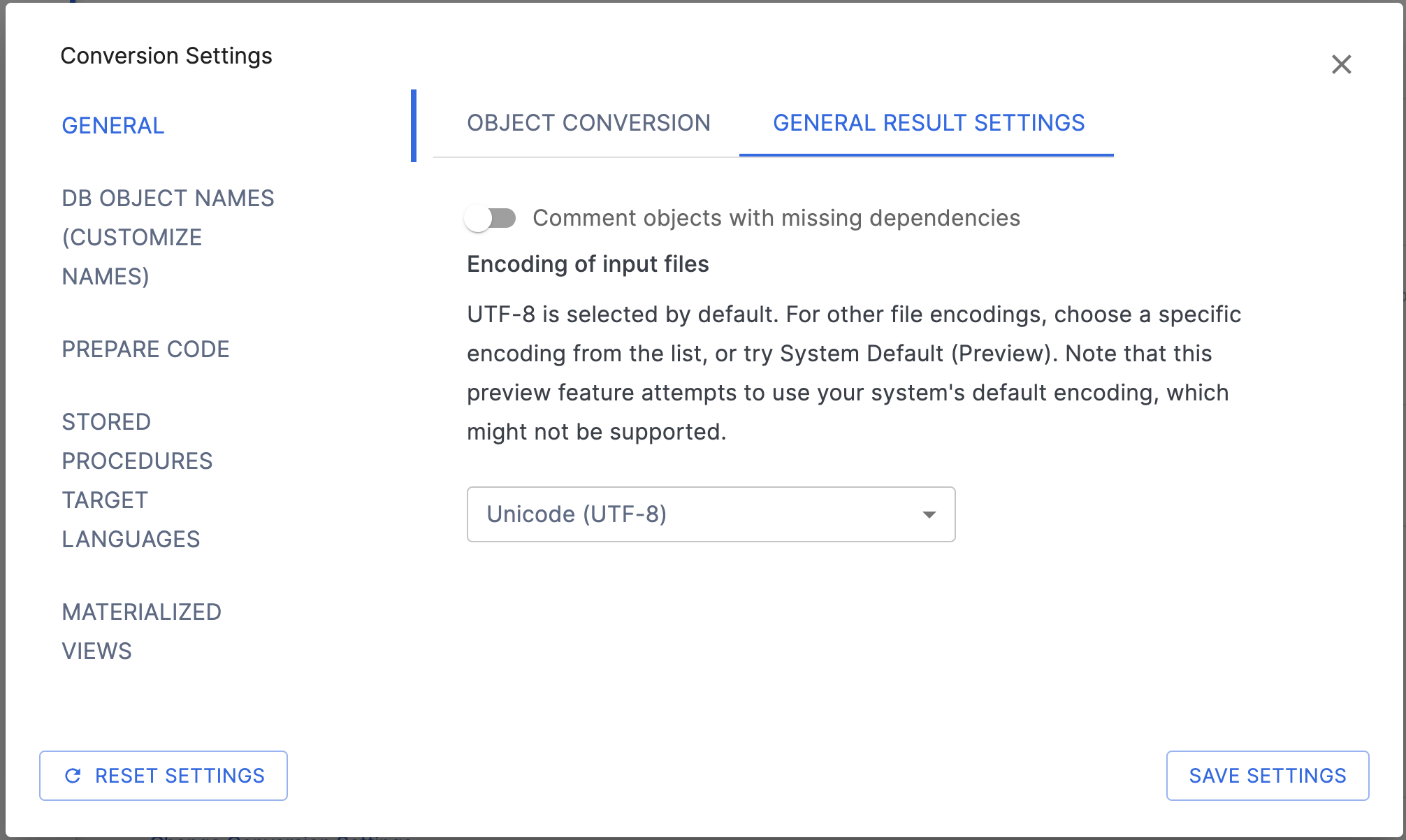
Comment objects with missing dependencies: このフラグは、ユーザーが依存関係が欠落しているノードにコメントしたいかどうかを示します。
入力ファイルのエンコードを設定する: 詳しくは 一般変換設定 を確認してください。
注釈
すべてのサポート言語に適用される設定を確認するには、次の 記事 をご覧ください。
DB オブジェクト名の設定¶
.png)
スキーマ: 文字列値は、適用するカスタムスキーマ名を指定します。指定しない場合は、元のデータベース名が使用されます。例: DB1.myCustomSchema.Table1。
データベース: 文字列値は、適用するカスタムデータベース名を指定します。例: MyCustomDB.PUBLIC.Table1。
デフォルト: 上記のいずれの設定もオブジェクト名には使用されません。
コード準備設定¶
.png)
説明¶
Prepare my code: 解析と変換の前に入力コードを処理すべきかどうかを示すフラグです。これは、構文解析プロセスを改善するのに役立ちます。デフォルトでは、 FALSE に設定されています。
入力コードのトップレベルオブジェクトを複数のファイルに分割します。フォルダーは以下のように構成されます。
コピー
例¶
入力¶
出力¶
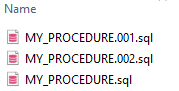
ファイル名は、入力ファイルのトップレベルのオブジェクトの名前であると仮定します。
「schema name」フォルダーの中には、入力コードのトップレベルオブジェクトと同じ数のファイルがあるはずです。また、複数の同じタイプのトップレベルオブジェクトが同じ名前を持つ場合、いくつかのファイルのコピーを持つことが可能です。この場合、ファイル名は昇順に列挙されます。
要件 ¶
トップレベルオブジェクトを識別するには、その宣言の前にタグをコメントに含める必要があります。抽出 スクリプトは、これらのタグを生成します。
タグは次の形式に従ってください。
次の例に従うことができます。
変換率設定¶
.png)
このページでは、変換に成功したコードのパーセントを、コードの行数で計算するか、文字数の合計で計算するかを選択できます。文字変換率 がデフォルトのオプションです。ドキュメントページ ですべての率に関するドキュメントを参照できます。
ストアドプロシージャターゲット言語設定¶
.png)
このページでは、ストアドプロシージャをSnow SQL に埋め込まれた JavaScript に移行するか、Snowflake Scriptingに移行するかを選択できます。デフォルトのオプションはSnowflake Scriptingです。
Reset Settings: 設定のリセットオプションは、すべてのページに表示されます。変更を加えた場合は、 SnowConvert AI を元のデフォルト設定にリセットすることができます。