Snowflake Connector for Kafka with Snowpipe Streaming classic¶
Important
- Advance notice: This page documents using Snowpipe Streaming classic with the Kafka connector (v3 and earlier). For new implementations, Snowflake recommends the Snowflake Connector for Kafka (v4), which natively uses the high-performance architecture.
- No immediate changes are required. Your current workloads continue to be fully supported.
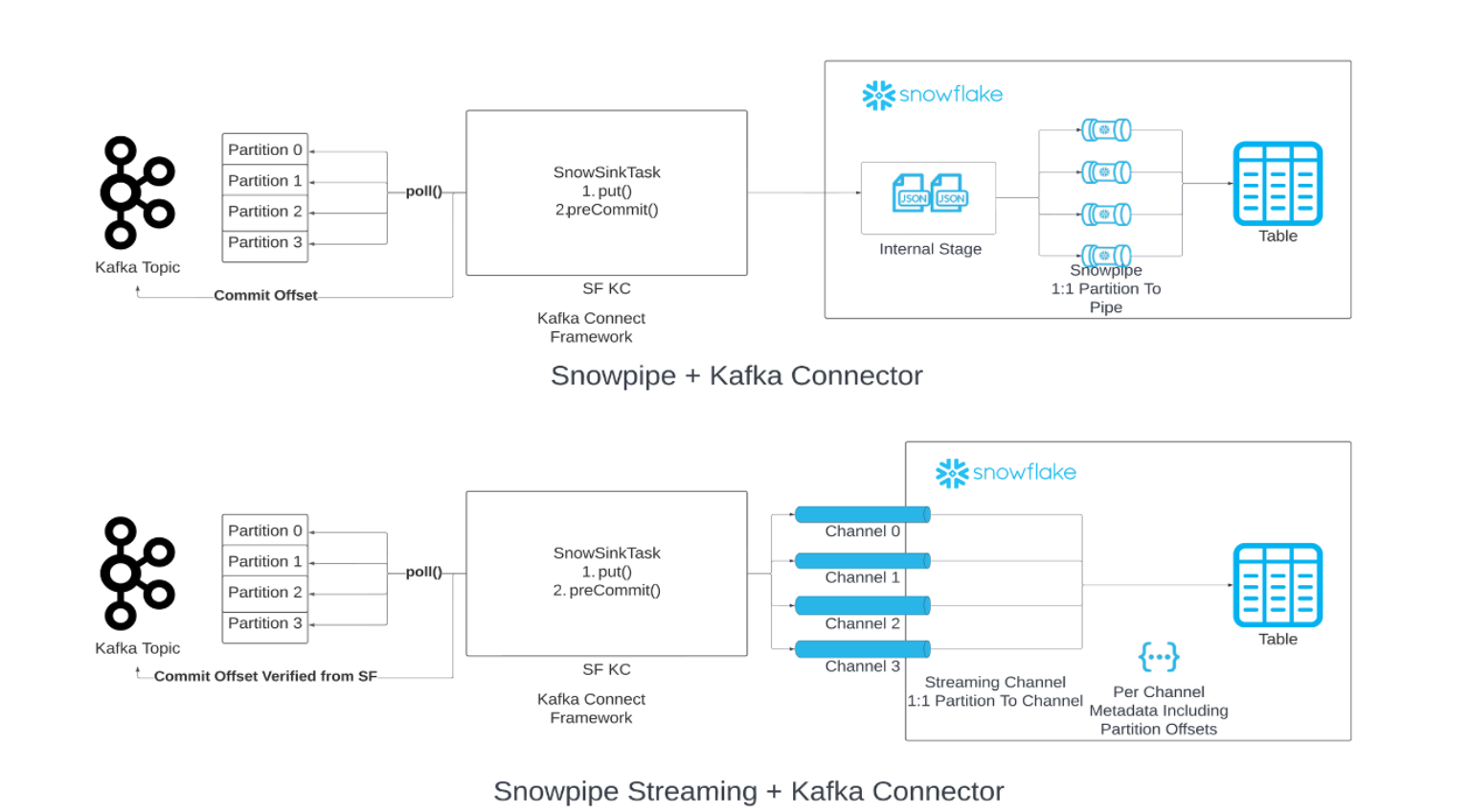
You can replace Snowpipe with Snowpipe Streaming in your data loading chain from Kafka. When the specified flush buffer threshold (time, memory, or number of messages) is reached, the connector calls the Snowpipe Streaming API (“API”) to write rows of data to Snowflake tables. This architecture results in lower load latencies with corresponding lower costs for loading similar volumes of data.
Version 2.0.0 (or later) of the Kafka connector is required for use with Snowpipe Streaming Classic. The Kafka connector with Snowpipe Streaming Classic includes the Snowflake Ingest SDK and supports streaming rows from Apache Kafka topics directly into target tables.
Minimum required version¶
The minimum required Kafka connector version that supports Snowpipe Streaming is 2.0.0.
Kafka configuration properties¶
Save your connection settings in the Kafka connector properties file. For more information, see Configuring the Kafka connector.
Required properties¶
Add or edit your connection settings in the Kafka connector properties file. For more information, see Configuring the Kafka connector.
snowflake.ingestion.methodRequired only if using the Kafka connector as the streaming ingest client. Specifies whether to use Snowpipe Streaming or standard Snowpipe to load your Kafka topic data. The supported values are as follows:
SNOWPIPE_STREAMINGSNOWPIPE(default)
No additional settings are required to choose the backend service to queue and load topic data. Configure additional properties in your Kafka connector properties file as usual.
snowflake.role.nameAccess control role to use when inserting the rows into the table.
Client optimization properties¶
enable.streaming.client.optimizationSpecifies whether to enable one-client optimization. This property is supported by Kafka connector release version 2.1.2 and later. It is enabled by default.
With one-client optimization, only one client is created for multiple topic partitions per Kafka connector. This feature can reduce client runtime and lower migration cost by creating larger files.
- Values:
truefalse
- Default:
true
Note that in a high throughput scenario (for example, 50 MB/s per connector), enabling this property can result in a higher latency or cost. We recommend that you disable this property for high-throughput scenarios.
Buffer and polling properties¶
buffer.flush.timeNumber of seconds between buffer flushes; each flush results in insert operations for the buffered records. The Kafka connector calls the Snowpipe Streaming API once after each flush.
The minimum value supported for the
buffer.flush.timeproperty is1(in seconds). For higher average data flow rates, we suggest that you decrease the default value for improved latency. If cost is a greater concern than latency, you could increase the buffer flush time. Be careful to flush the Kafka memory buffer before it becomes full to avoid out-of-memory exceptions.- Values:
- Minimum:
1 - Maximum: No upper limit
- Minimum:
- Default:
10
Note that Snowpipe Streaming automatically flushes data every one second, which is different from the buffer flush time for the Kafka connector. After the Kafka buffer flush time is reached, data will be sent with one second latency to Snowflake through Snowpipe Streaming. For more information, see Snowpipe Streaming latency.
buffer.count.recordsNumber of records buffered in memory per Kafka partition before ingesting to Snowflake.
- Values:
- Minimum:
1 - Maximum: No upper limit
- Minimum:
- Default:
10000
buffer.size.bytesCumulative size in bytes of records buffered in memory per the Kafka partition before they are ingested in Snowflake as data files.
The records are compressed when they are written to data files. As a result, the size of the records in the buffer may be larger than the size of the data files created from the records.
- Values:
- Minimum:
1 - Maximum: No upper limit
- Minimum:
- Default:
20000000(20 MB)
snowflake.streaming.max.client.lagSpecifies how often Snowflake Ingest Java flushes the data to Snowflake, in seconds.
A low value keeps the latency low, but it might result in a worse query performance especially when snowflake.streaming.enable.single.buffer is enabled. For more information, see the recommended latency configurations for Snowpipe Streaming.
- Values:
- Minimum:
1second - Maximum:
600seconds
- Minimum:
- Default:
30seconds for version 3.1.1 and later,120seconds for versions 3.0.0 and 3.1.0,1second otherwise
snowflake.streaming.enable.single.bufferSpecifies whether to enable single buffer for Snowpipe Streaming and to skip buffering data in the connector’s internal buffer.
This property is supported by the Kafka connector version 2.3.1 and later.
Streaming connector uses internal buffer alongside with the one provided by Snowflake Ingest Java. Setting this property to
truemakes Kafka connector skip the internal buffer in order to achieve lower latency.Note that setting this property to
truemakesbuffer.flush.timeandbuffer.count.recordsirrelevant.- Values:
truefalse
- Default:
truefor version 3.0.0 and later,falseotherwise
In addition to the Kafka connector properties, note the Kafka consumer max.poll.records property, which controls the maximum number of records returned by Kafka to Kafka Connect in a single poll. The default value of 500 can be increased, but be mindful of memory constraints. For more information about this property, see the documentation for your Kafka package:
Error handling and DLQ properties¶
errors.toleranceSpecifies how to handle errors encountered by the Kafka connector:
This property supports the following values:
- Values:
NONE: Stop loading data when the first error is encountered.ALL: Ignore all errors and continue to load data.
- Default:
NONE
errors.log.enableSpecifies whether to write error messages to the Kafka Connect log file.
This property supports the following values:
- Values:
TRUE: Write error messages.FALSE: Do not write error messages.
- Default:
FALSE
errors.deadletterqueue.topic.nameSpecifies the name of the DLQ (dead-letter queue) topic in Kafka for delivering messages to Kafka that could not be ingested into Snowflake tables. For more information, see Dead-letter Queues (in this topic).
- Values:
Custom text string
- Default:
None
Exactly-once semantics¶
Exactly-once semantics ensure the delivery of Kafka messages without duplication or data loss. This delivery guarantee is set by default for the Kafka connector with Snowpipe Streaming.
The Kafka connector adopts a one-to-one mapping between partition and channel and uses two distinct offsets:
- Consumer offset: This tracks the most recent offset consumed by the consumer and is managed by Kafka.
- Offset token: This tracks the most recent committed offset in Snowflake and is managed by Snowflake.
Note that the Kafka connector doesn’t always handle missing offsets. Snowflake expects that all records to have sequentially increasing offsets. The missing offsets will break the Kafka connector in specific use cases. It is recommended that you use tombstone records instead of NULL records.
The Kafka connector achieves exactly-once delivery by implementing the following best practices:
Opening/reopening a channel:
- When opening or reopening a channel for a given partition, the Kafka Connector uses the latest committed offset token retrieved from Snowflake through the
getLatestCommittedOffsetTokenAPI as the source of truth and resets the consumer offset in Kafka accordingly.- If the consumer offset is no longer within the data retention period, an exception is thrown, and you can determine the appropriate action to take.
- The only scenario in which the Kafka Connector does not reset the consumer offset in Kafka and uses it as the source of truth is when the offset token from Snowflake is NULL. In this case, the connector accepts the offset sent by Kafka, and the offset token is subsequently updated.
Processing records:
- To ensure an additional layer of safety against non-continuous offsets that could arise from potential bugs in Kafka, Snowflake maintains an in-memory variable that tracks the latest processed offset. Snowflake only accepts rows if the current row’s offset equals the latest processed offset plus one, thereby adding an extra layer of protection to ensure that the ingestion process is continuous and accurate.
Dealing with exceptions, failures, crashes recovery:
- As part of the recovery process, Snowflake consistently adheres to the channel open/reopen logic outlined earlier by reopening the channel and resetting the consumer offset with the latest committed offset token. By doing this, Snowflake signals Kafka to send the data from the offset value that is one greater than the latest committed offset token, which enables the resumption of ingestion from the point of failure with no data loss.
Implementing a retry mechanism:
- To account for potential transient issues, Snowflake incorporates a retry mechanism in the API calls. Snowflake retries these API calls multiple times to increase the chances of success and mitigate the risk of intermittent failures affecting the ingestion process.
Advancing the consumer offset:
- At regular intervals, Snowflake advances the consumer offset using the latest committed offset token to ensure that the ingestion process is continuously aligned with the latest state of data in Snowflake.
Converters¶
Snowpipe Streaming supports many community-based converters such as the following:
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
Other community-based converters may be supported but have not been validated. Snowflake converters are not supported with Snowpipe Streaming.
Dead-letter queues¶
The Kafka connector with Snowpipe Streaming supports dead-letter queues (DLQ) for broken records or records that cannot be processed successfully due to a failure.
For more information about monitoring, see the Apache Kafka documentation.
Schema detection and schema evolution¶
The Kafka connector with Snowpipe Streaming supports schema detection and evolution. The structure of tables in Snowflake can be defined and evolved automatically to support the structure of new Snowpipe Streaming data loaded by the Kafka connector. To enable schema detection and evolution for the Kafka connector with Snowpipe Streaming, configure the following Kafka properties:
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
For more information, see Schema detection and evolution for Kafka connector with Snowpipe Streaming classic.
Estimating ingestion latency¶
To estimate ingestion latency, use the SnowflakeConnectorPushTime field in RECORD_METADATA.
This timestamp represents a point in time when a record was pushed into an Ingest SDK buffer.
For more information about the RECORD_METADATA format, see Schema of tables for Kafka topics.
Note
This field does not represent when a record became visible in a Snowflake table, because it doesn’t take into account your configured Snowpipe Streaming latency.
Billing and usage¶
For Snowpipe Streaming billing information, see Costs for Snowpipe Streaming Classic.
Limitations¶
Snowpipe streaming limitations¶
See Snowpipe Streaming limitations.
Failover limitations¶
When a secondary failover group is promoted to primary, the Kafka connector with Snowpipe Streaming requires manual interaction. Exactly-once semantics are still preserved.
If enable.streaming.client.optimization property is set to false, the Kafka connector should be restarted. After you restart the connector, it will target a new primary deployment.
If enable.streaming.client.optimization property is set to true, the host JVM that the connector is running on should be shut down and restarted. After you restart the host JVM, a newly started Kafka connector will target a new primary deployment.