Snowpipe Streaming¶
Snowpipe Streaming ist der Dienst von Snowflake zum kontinuierlichen Laden von Streaming-Daten mit niedriger Latenz direkt in Snowflake. Er ermöglicht die Erfassung und Analyse von Daten nahezu in Echtzeit, was für zeitnahe Einblicke und unmittelbare operative Reaktionen entscheidend ist. Große Datenmengen aus verschiedenen Streaming-Quellen werden innerhalb von Sekunden für Abfragen und Analysen zur Verfügung gestellt.
Wert von Snowpipe Streaming¶
Datenverfügbarkeit in Echtzeit: Im Gegensatz zu herkömmlichen Batch-Lademethoden werden die Daten bei ihrem Eintreffen aufgenommen. Dies unterstützt Anwendungsfälle wie Live-Dashboards, Echtzeitanalysen und Betrugserkennung.
Effiziente Streaming-Workloads: Nutzt Snowflake Ingest-SDKs, um Zeilen direkt in Tabellen zu schreiben und so den Cloud-Zwischenspeicher zu umgehen. Dieser direkte Ansatz reduziert die Latenzzeit und vereinfacht die Datenaufnahmearchitektur.
Vereinfachte Datenpipelines: Bietet einen optimierten Ansatz für kontinuierliche Datenpipelines aus Quellen wie Anwendungsereignissen, IoTSensoren, Change Data Capture (CDC) Streams und Message Queues (z. B. Apache Kafka).
Serverlos und skalierbar: Da es sich um ein serverloses Angebot handelt, skaliert es die Rechenressourcen automatisch auf der Grundlage der Aufnahmelast und eliminiert die manuelle Warehouse-Verwaltung für Datenaufnahmeaufgaben.
Kostengünstig für Streaming: Die Abrechnung ist für Streaming-Aufnahme optimiert und bietet möglicherweise kosteneffektivere Lösungen für hochvolumige Dateneinspeisungen mit niedriger Latenz im Vergleich zu häufigen COPY-Operationen mit kleinen Batches.
Mit Snowpipe Streaming können Sie Echtzeitdatenanwendungen in der Snowflake Data Cloud erstellen, sodass Sie Entscheidungen auf der Grundlage der aktuellsten verfügbaren Daten treffen können.
Snowpipe Streaming-Implementierungen¶
Snowpipe Streaming bietet zwei verschiedene Implementierungen, um den unterschiedlichen Anforderungen an die Datenverarbeitung und die Leistung gerecht zu werden: Snowpipe Streaming mit Hiegh-Performance-Architektur (Vorschau) und Snowpipe Streaming mit klassischer Architektur:
Snowpipe Streaming mit High-Performance-Architektur (Vorschau)
Snowflake hat diese Implementierung der nächsten Generation entwickelt, um den Durchsatz erheblich zu steigern, die Streaming-Leistung zu optimieren und ein vorhersehbares Kostenmodell zu bieten, das den Stagingbereich für fortschrittliche Daten-Streaming-Funktionen schafft.
Wichtige Merkmale:
SDK: Verwendet das neue
snowpipe-streaming-SDK.Preisgestaltung: Transparente, durchsatzbasierte Preisgestaltung (Credits pro unkomprimiertem GB)
Datenflussmanagement: Nutzt das PIPE-Objekt zur Verwaltung des Datenflusses und zur Ermöglichung einfacher Transformationen zum Aufnahmezeitpunkt. Für dieses PIPE-Objekt werden Kanäle geöffnet.
Datenaufnahme: Bietet eine REST-API für die direkte, einfache Datenaufnahme über die PIPE.
Schemavalidierung: Wird auf der Serverseite während der Datenaufnahme anhand des in der PIPE definierten Schemas durchgeführt.
Leistung: Entwickelt für einen deutlich höheren Durchsatz und eine verbesserte Abfrageeffizienz bei aufgenommenen Daten.
Wir empfehlen Ihnen, diese fortschrittliche Architektur zu erkunden – insbesondere für neue Streaming-Projekte.
Snowpipe Streaming mit klassischer Architektur
Dies ist die ursprüngliche, allgemein verfügbare Implementierung, die eine zuverlässige Lösung für etablierte Datenpipelines darstellt.
Wichtige Merkmale:
SDK: Verwendet das snowflake-ingest-java-SDK (alle Versionen bis 4.x).
Datenflussmanagement: Verwendet nicht das PIPE-Objektkonzept für die Streaming-Aufnahme. Kanäle werden direkt für Zieltabellen konfiguriert und geöffnet.
Preisgestaltung: Basierend auf einer Kombination von serverlosen Computeressourcen, die für die Datenaufnahme genutzt werden, und der Anzahl aktiver Clientverbindungen.
Auswahl Ihrer Implementierung¶
Berücksichtigen Sie bei der Auswahl einer Implementierung Ihren unmittelbaren Bedarf und Ihre langfristige Datenstrategie:
Neue Streaming-Projekte: Wir empfehlen Ihnen, die Snowpipe Streaming-High-Performance-Architektur (Vorschau) wegen ihres zukunftsweisenden Designs, ihrer besseren Leistung, Skalierbarkeit und Kostenvorhersagbarkeit zu evaluieren.
Leistungsanforderungen: Die High-Performance-Architektur ist auf maximalen Durchsatz und Optimierung der Echtzeitleistung ausgelegt.
Bevorzugte Preisgestaltung: Die High-Performance-Architektur bietet eine klare, durchsatzbasierte Preisgestaltung, während die klassische Architektur auf der Grundlage des serverlosen Computing und der Clientverbindungen abgerechnet wird.
Bestehende Konfigurationen: Bestehende Anwendungen, die die klassische Architektur verwenden, können weiterhin genutzt werden. Ziehen Sie bei zukünftigen Erweiterungen oder Umgestaltungen eine Migration auf die High-Performance-Architektur in Betracht.
Feature-Set und Verwaltung: Das PIPE-Objekt in der High-Performance- Architektur bietet erweiterte Management- und Transformationsfunktionen, die in der klassischen Architektur nicht vorhanden sind.
Snowpipe Streaming versus Snowpipe¶
Snowpipe Streaming ist als Ergänzung zu Snowpipe gedacht, nicht als Ersatz. Verwenden Sie die Snowpipe Streaming-API in Streaming-Szenarien, in denen Daten mit Zeilen gestreamt werden (z. B. Apache Kafka-Themen), anstatt in Dateien geschrieben zu werden. Die API eignet sich für einen Erfassungs-Workflow, bei dem eine bestehende kundenspezifische Java-Anwendung eingesetzt wird, die Datensätze produziert oder empfängt. Mit der API müssen Sie keine Dateien erstellen, um Daten in Snowflake-Tabellen zu laden, und die API ermöglicht das automatische, kontinuierliche Laden von Datenstreams in Snowflake, sobald die Daten verfügbar sind.
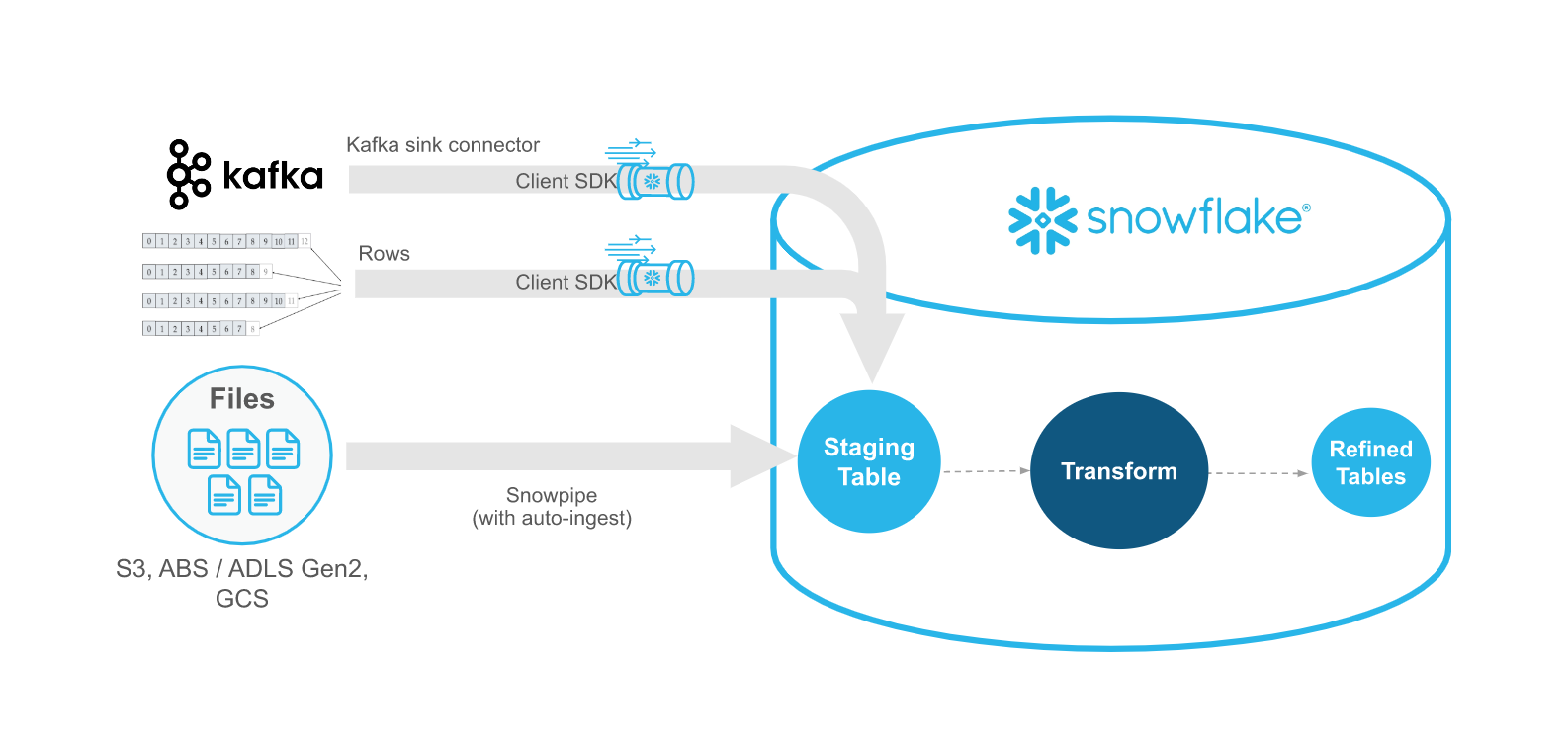
In der folgenden Tabelle werden die Unterschiede zwischen Snowpipe Streaming und Snowpipe beschrieben:
Kategorie |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Form der zu ladenden Daten |
Zeilen |
Dateien. Wenn Ihre bestehende Datenpipeline Dateien im Blobspeicher generiert, empfehlen wir die Verwendung von Snowpipe anstelle der API. |
Anforderungen an Software von Drittanbietern |
Kundenspezifischer Java-Anwendungscode-Wrapper für das Snowflake Ingest SDK |
Keine |
Reihenfolge der Daten |
Geordnete Einfügungen innerhalb jedes Kanals |
Nicht unterstützt. Snowpipe kann Daten aus Dateien in einer Reihenfolge laden, die von den Zeitstempeln der Dateierstellung im Cloudspeicher abweicht. |
Ladeverlauf |
Ladeverlauf wird in Ansicht SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage) erfasst |
Aufgezeichneter Ladehverlauf in COPY_HISTORY (Account Usage) und COPY_HISTORY-Funktion (Information Schema) |
Pipeobjekt |
Bei der klassischen Architektur ist kein Pipe-Objekt erforderlich: Die API schreibt Datensätze direkt in die Zieltabellen. Die High-Performance-Architektur erfordert ein Pipe-Objekt. |
Erfordert ein Pipeobjekt, das Stagingdatei-Daten in eine Warteschlange stellt und in Zieltabellen lädt. |
Software-Anforderungen¶
Java SDK¶
Spezielle Java-SDKs erleichtern die Interaktion mit dem Snowpipe Streaming-Dienst. Sie können die SDKs aus dem Maven Central Repository herunterladen. Die folgenden Listen zeigen die Anforderungen, die je nach der von Ihnen verwendeten Snowpipe Streaming-Architektur variieren:
Für Snowpipe Streaming mit High-Performance-Architektur:
SDK: Verwendet das neue snowpipe-streaming-SDK.
Java-Version: Benötigt Java 11 oder höher.
Für Snowpipe Streaming Classic:
SDK: Verwendet das snowflake-ingest-sdk Version 4.X oder höher.
Java-Version: Benötigt Java 8 oder höher.
Zusätzliche Voraussetzung: Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files müssen für Ihre Java 8-Umgebung installiert sein.
Wichtig
Das SDK führt REST-API-Anrufe in Snowflake aus. Möglicherweise müssen Sie die Regeln Ihrer Netzwerk-Firewall anpassen, um Konnektivität zu ermöglichen.
Kundenspezifische Clientanwendung¶
Die API erfordert eine benutzerdefinierte Java-Anwendungsschnittstelle, die Datenzeilen transferieren und auftretende Fehler handhaben kann. Es liegt in Ihrer Verantwortung, dass die Anwendung ohne Unterbrechung ausgeführt wird und nach einem Ausfall wiederhergestellt werden kann. Für einen bestimmten Batch von Zeilen unterstützt API das Äquivalent von ON_ERROR = CONTINUE | SKIP_BATCH | ABORT.
CONTINUE: Fahren Sie fort, die zulässigen Datenzeilen zu laden, und geben Sie alle Fehler zurück.SKIP_BATCH: Überspringen Sie das Laden, und geben Sie alle Fehler zurück, wenn ein Fehler im gesamten Batch von Zeilen auftritt.ABORT(Standardeinstellung): Der gesamte Batch von Zeilen wird abgebrochen, und beim ersten Fehler wird eine Ausnahme ausgelöst.
Bei Snowpipe Streaming Classic führt die Anwendung Schemavalidierungen anhand der Antwort der Methoden insertRow (einzelne Zeile) oder insertRows (Satz von Zeilen) durch. Informationen zur Fehlerbehandlung für die High-Performance-Architektur finden Sie unter Behandlung von Fehlern.
Kanäle¶
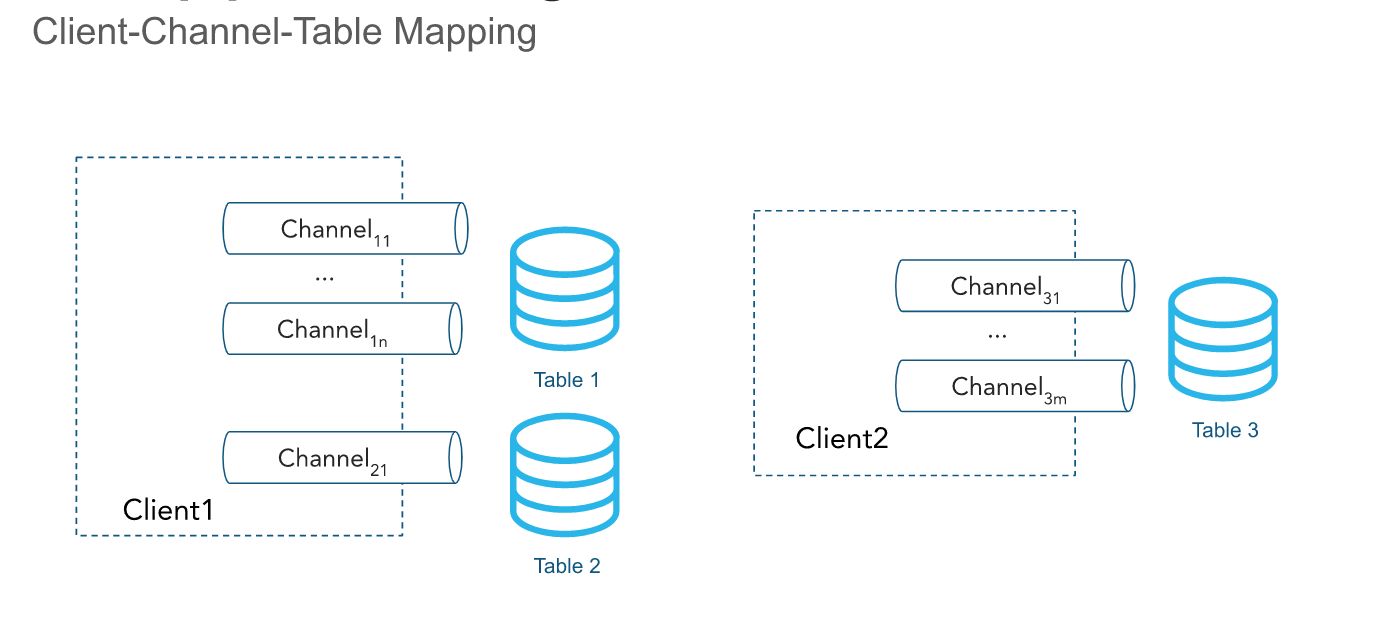
Die API nimmt Zeilen über einen oder mehrere Kanäle auf. Ein Kanal stellt eine benannte logische Streaming-Verbindung zu Snowflake dar, über die Daten in eine Tabelle geladen werden. Ein einzelner Kanal ist genau einer Tabelle in Snowflake zugeordnet. Es können jedoch mehrere Kanäle auf dieselbe Tabelle verweisen. Das Client-SDK kann mehrere Kanäle zu mehreren Tabellen öffnen. Das SDK kann jedoch keine Kanäle über Konten hinweg öffnen. Die Reihenfolge der Zeilen und die entsprechenden Offset-Token werden innerhalb eines Kanals aufbewahrt, aber nicht zwischen Kanälen, die auf dieselbe Tabelle verweisen.
Kanäle sind für eine lange Verwendungsdauer gedacht, wenn ein Client aktiv Daten einfügt, und sollten wiederverwendet werden, da die Informationen zu Offset-Token erhalten bleiben. Die Daten innerhalb des Kanals werden standardmäßig alle 1 Sekunde automatisch geleert und der Kanal muss nicht geschlossen werden. Weitere Informationen dazu finden Sie unter Latenz.
Wenn Sie einen Kanal und die zugehörigen Offset-Metadaten nicht mehr benötigen, können Sie ihn mithilfe der DropChannelRequest-API dauerhaft löschen. Es gibt zwei Möglichkeiten, einen Kanal zu löschen:
Löschen eines Kanals beim Schließen Die Daten im Kanal werden automatisch gelöscht, bevor der Kanal gelöscht wird.
Blindes Löschen eines Kanals Wir raten jedoch davon ab, da beim Löschen eines Kanals alle ausstehenden Daten verworfen werden und bereits geöffnete Kanäle ungültig werden könnten.
Sie können den Befehl SHOW CHANNELS ausführen, um die Kanäle aufzulisten, für die Sie Zugriffsrechte haben. Weitere Informationen dazu finden Sie unter SHOW CHANNELS.
Bemerkung
Inaktive Kanäle werden zusammen mit ihren Offset-Token automatisch nach 30 Tagen gelöscht.
Offset-Token¶
Ein Offset-Token ist eine Zeichenfolge, die ein Client in seine Anfragen zur Zeilenübermittlung (z. B. für einzelne oder mehrere Zeilen) einfügen kann, um den Fortschritt der Datenaufnahme pro Kanal zu verfolgen. Die verwendeten Methoden sind insertRow oder insertRows für die klassische Architektur und appendRow oder appendRows für die High-Performance-Architektur. Das Token wird bei der Erstellung des Kanals mit NULL initialisiert, und es wird aktualisiert, wenn die Zeilen mit einem bereitgestellten Offset-Token durch einen asynchronen Prozess an Snowflake übergeben werden. Clients können in regelmäßigen Abständen Anfragen an die Methode getLatestCommittedOffsetToken stellen, um das neueste Offset-Token für einen bestimmten Kanal zu erhalten und dieses zu verwenden, um den Fortschritt der Datenaufnahmezu ermitteln. Dieses Token wird von Snowflake nicht zum Deduplizieren verwendet; jedoch können Clients dieses Token verwenden, um mithilfe eigener Logik eine Duplikatsvermeidung umzusetzen.
Wenn ein Client einen Kanal wieder öffnet, wird das letzte gespeicherte Offset-Token zurückgegeben. Der Client kann seine Position in der Datenquelle mithilfe des Tokens zurücksetzen, um zu vermeiden, dass dieselben Daten zweimal gesendet werden. Beachten Sie, dass bei einem Wiederöffnungsereignis eines Kanals alle in Snowflake gepufferten Daten verworfen werden, damit sie nicht übertragen werden.
Sie können das letzte bestätigte Offset-Token verwenden, um die folgenden allgemeinen Anwendungsfälle durchzuführen:
Verfolgen des Erfassungsfortschritts
Überprüfen, ob ein bestimmter Offset übertragen wurde, indem dieser mit dem letzten übertragenen Offset-Token verglichen wird
Aktualisieren des Quellen-Offsets und Bereinigen der bereits bestätigten Daten
Aktivieren der Deduplizierung und Sicherstellen der genau einmaligen Bereitstellung von Daten
Beispielsweise könnte der Kafka-Konnektor ein Offset-Token aus einem Topic lesen, wie <partition>:<offset> oder einfach <offset>, wenn die Partition im Kanalnamen kodiert ist. Betrachten Sie das folgende Szenario:
Der Kafka-Konnektor geht online und öffnet einen Kanal, der
Partition 1im Kafka-TopicTmit dem KanalnamenT:P1entspricht.Der Konnektor beginnt mit dem Lesen von Datensätzen aus der Kafka-Partition.
Der Konnektor ruft die API auf und führt eine
insertRows-Methodenanforderung mit dem Offset aus, der dem Datensatz als Offset-Token zugeordnet ist.Das Offset-Token könnte zum Beispiel
10lauten und damit auf den zehnten Datensatz in der Kafka-Partition verweisen.Der Konnektor führt in regelmäßigen Abständen
getLatestCommittedOffsetToken-Methodenanforderungen aus, um den Erfassungsfortschritt zu ermitteln.
Wenn der Kafka-Konnektor abstürzt, kann mit dem folgende Ablauf das Lesen von Datensätzen aus dem korrekten Offset für die Kafka-Partition wieder aufgenommen werden:
Der Kafka-Konnektor ist wieder online und öffnet den Kanal erneut unter demselben Namen wie zuvor.
Der Konnektor ruft die API auf und führt eine
getLatestCommittedOffsetToken-Methodenanforderung aus, um den letzten bestätigten Offset für die Partition zu erhalten.Angenommen, das letzte persistent gespeicherte Offset-Token ist
20.Der Konnektor verwendet die Kafka-Lese-APIs, um einen Cursor zurückzusetzen, der dem Offset plus 1 zugeordnet ist (in diesem Beispiel
21).Der Konnektor setzt das Lesen der Datensätze fort. Nachdem der Lesecursor erfolgreich neu positioniert wurde, werden keine doppelten Daten abgerufen.
In einem weiteren Beispiel liest eine Anwendung Protokolle aus einem Verzeichnis und verwendet das Snowpipe Streaming Client SDK, um diese Protokolle nach Snowflake zu exportieren. Sie könnten eine Anwendung für den Protokollexport entwickeln, die Folgendes umsetzt:
Auflisten der Dateien im Log-Verzeichnis.
Angenommen, das Protokollierungs-Framework generiert Protokolldateien, die lexikografisch sortiert werden können, wobei neue Protokolldateien an das Ende dieser Sortierung positioniert werden.
Liest eine Protokolldatei zeilenweise und ruft die API auf, die
insertRows-Methodenanforderungen mit einem Offset-Token ausführt, das dem Namen der Protokolldatei und der Zeilenzahl oder Byteposition entspricht.Ein Offset-Token könnte zum Beispiel
messages_1.log:20sein, wobeimessages_1.logder Name der Protokolldatei und20die Zeilennummer ist.
Wenn die Anwendung abstürzt oder neu gestartet werden muss, kann die API aufgerufen und eine getLatestCommittedOffsetToken-Methodenanforderung ausgeführt werden, um das Offset-Token abzurufen, das der letzten exportierten Protokolldatei und -zeile entspricht. Im Beispiel wäre dies messages_1.log:20. Die Anwendung würde dann messages_1.log öffnen und nach Zeile 21 suchen, um zu verhindern, dass dieselbe Protokollzeile zweimal erfasst wird.
Bemerkung
Die Informationen zum Offset-Token können verloren gehen. Das Offset-Token ist mit einem Kanalobjekt verknüpft, und ein Kanal wird automatisch gelöscht, wenn für einen Zeitraum von 30 Tagen keine neue Erfassung unter Verwendung des Kanals ausgeführt wird. Um den Verlust des Offset-Tokens zu verhindern, sollten Sie einen separaten Offset pflegen und das Offset-Token des Kanals bei Bedarf zurückzusetzen.
Rollen von offsetToken und continuationToken¶
offsetToken und continuationToken werden beide verwendet, um eine genau einmalige Datenbereitstellung sicherzustellen, aber sie dienen unterschiedlichen Zwecken und werden von unterschiedlichen Systemen verwaltet. Der primäre Unterschied besteht darin, wer den Wert des Tokens und den Umfang seiner Verwendung kontrolliert.
continuationToken(gilt nur für die High-Performance-Architektur):Dieses Token wird von Snowflake verwaltet und ist unerlässlich, um den Status einer einzelnen, kontinuierlichen Streaming-Sitzung aufrecht zu erhalten. Wenn ein Client Daten über die
Append RowsAPI sendet, gibt Snowflake eincontinuationTokenzurück. Der Client muss dieses Token in seiner nächsten Anforderung verwenden, um sicherzustellen, dass die Daten in der richtigen Reihenfolge und ohne Lücken empfangen werden. Snowflake verwendet das Token, um doppelte Daten im Falle eines erneuten SDK-Versuchs zu erkennen und zu verhindern.offsetToken(gilt sowohl für klassische als auch für High-Performance-Architekturen):Dieses Token ist ein benutzerdefinierter Bezeichner, der die genau einmalige Bereitstellung von einer externen Quelle ermöglicht. Snowflake verwendet dieses Token nicht für seine eigenen internen Operationen oder um die erneute Erfassung zu verhindern. Stattdessen speichert Snowflake diesen Wert einfach. Es liegt in der Verantwortung des externen Systems (wie eines Kafka-Konnektors), das offsetToken von Snowflake zu lesen und es zu verwenden, um den eigenen Aufnahmefortschritt zu verfolgen und das Senden doppelter Daten zu vermeiden, wenn der externe Stream wiederholt werden muss.
Best Practices für genau einmalige Bereitstellung¶
Die genau einmalige Bereitstellung kann eine Herausforderung sein. Entscheidend ist die Einhaltung der folgenden Grundsätze in Ihrem kundenspezifischen Code:
Um eine angemessene Wiederherstellung nach Ausnahmen, Fehlern oder Abstürzen sicherzustellen, müssen Sie den Kanal wieder neu öffnen und die Erfassung mit dem letzten bestätigten Offset-Token neu starten.
Auch wenn Ihre Anwendung ihren eigenen Offset pflegt, ist es wichtig, den letzten von Snowflake bereitgestellten Offset-Token als Quelle der Wahrheit zu verwenden und den eigenen Offset entsprechend zurückzusetzen.
Der einzige Fall, in dem Ihr eigener Offset als die Quelle der Wahrheit behandelt werden sollte, ist, wenn das Offset-Token von Snowflake auf NULL gesetzt oder zurückgesetzt wird. Ein NULL-Offset-Token hat in der Regel einen der folgenden Gründe:
Es handelt sich um einen neuen Kanal, weshalb noch kein Offset-Token festgelegt wurde.
Die Zieltabelle wurde gelöscht und neu erstellt, sodass der Kanal als neu angesehen wird.
In den letzten 30 Tagen gab es keine Datenerfassungsaktivitäten über den Kanal, sodass der Kanal automatisch bereinigt wurde und die Offset-Token-Informationen verloren gingen.
Falls erforderlich, können Sie die Quelldaten, die bereits auf der Grundlage des letzten übertragenen Offset-Tokens übertragen wurden, regelmäßig bereinigen und Ihren eigenen Offset aktualisieren.
Wenn das Tabellenschema geändert wird, während Snowpipe Streaming-Kanäle aktiv sind, muss der Kanal erneut geöffnet werden. Der Snowflake Kafka Connector handhabt dieses Szenario automatisch, aber wenn Sie Snowflake Ingest SDK direkt verwenden, müssen Sie den Kanal selbst wieder öffnen.
Weitere Informationen darüber, wie der Kafka-Konnektor mit Snowpipe Streaming eine genau einmalige Bereitstellung erreicht, finden Sie unter „Exactly-once“-Semantik.
Laden von Daten in Apache Iceberg™-Tabellen¶
Mit Snowflake Ingest SDK ab Version 3.0.0 kann Snowpipe Streaming Daten in von Snowflake verwaltete Apache Iceberg-Tabellen einlesen. Das Snowpipe Streaming Ingest Java SDK unterstützt das Laden in Standard-Snowflake-Tabellen (nicht Iceberg) und in Iceberg-Tabellen.
Weitere Informationen dazu finden Sie unter Verwendung von Snowpipe Streaming Classic mit Apache Iceberg™-Tabellen.
Latenz¶
Snowpipe Streaming löscht die Daten innerhalb von Kanälen automatisch jede Sekunde. Sie müssen den Kanal also nicht schließen, damit die Daten gelöscht werden.
Mit Snowflake Ingest SDK ab Version 2.0.4 können Sie die Latenz mit der Option MAX_CLIENT_LAG konfigurieren.
Für Standard-Snowflake-Tabellen (nicht Iceberg) ist die Standardeinstellung
MAX_CLIENT_LAG1 Sekunde.Für Iceberg-Tabellen (unterstützt von Snowflake Ingest SDK ab Version 3.0.0) beträgt die Standardeinstellung
MAX_CLIENT_LAG30 Sekunden.
Die maximale Latenz kann auf bis zu 10 Minuten eingestellt werden. Weitere Informationen dazu finden Sie unter MAX_CLIENT_LAG und Empfohlene Latenzkonfigurationen für Snowpipe Streaming.
Beachten Sie, dass der Kafka-Konnektor für Snowpipe Streaming über einen eigenen Puffer verfügt. Nach Erreichen der Kafka-Pufferleerungszeit werden die Daten mit einer Sekunde Latenz über Snowpipe Streaming an Snowflake gesendet. Weitere Informationen dazu finden Sie unter buffer.flush.time.
Migration zu optimierten Dateien in der klassischen Architektur¶
Die API schreibt die Zeilen aus den Kanälen in Blobs des Cloudspeichers, die dann in die Zieltabelle übertragen werden. Zunächst werden die in eine Zieltabelle geschriebenen Streaming-Daten in einem temporären Zwischendateiformat gespeichert. In dieser Phase wird die Tabelle als „gemischte Tabelle“ betrachtet, da die partitionierten Daten in einer Mischung aus nativen Dateien und Zwischendateien gespeichert sind. Ein automatischer Hintergrundprozess migriert die Daten aus den aktiven Zwischendateien in native Dateien, die Abfrage- und DML-Operationen optimiert sind, je nach Bedarf.
Replikation in der klassischen Architektur¶
Snowpipe Streaming unterstützt Replikation und Failover von Snowflake-Tabellen, die von Snowpipe Streaming und den zugehörigen Kanal-Offsets befüllt werden, von einem Quellkonto zu einem Zielkonto über verschiedene Regionen und verschiedene Cloudplattformen hinweg.
Replikation wird für die High-Performance-Architektur nicht unterstützt.
Weitere Informationen dazu finden Sie unter Replikation und Snowpipe Streaming.
Nur-Einfüge-Operationen¶
Die API ist derzeit auf das Einfügen von Zeilen beschränkt. Um Daten ändern, löschen oder kombinieren zu können, müssen Sie die „rohen“ Datensätze in eine oder mehrere Stagingtabellen schreiben. Das Zusammenführen, Verknüpfen oder Transformieren der Daten kann mithilfe von kontinuierlichen Datenpipelines erfolgen, mit denen geänderte Daten in Zielberichtstabellen eingefügt werden können.
Klassen und Schnittstellen¶
Die Dokumentation zu den Klassen und Schnittstellen für die klassische Architektur finden Sie unter Snowflake Ingest SDK API.
Die Unterschiede zwischen der klassischen und der High-Performance-Architektur finden Sie unter API-Unterschiede.
Unterstützte Java-Datentypen¶
Die folgende Tabelle fasst zusammen, welche Java-Datentypen für das Einfügen in Snowflake-Spalten unterstützt werden:
Snowflake-Spaltentyp |
Zulässiger Java-Datentyp |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Erforderliche Zugriffsrechte¶
Zum Aufrufen der Snowpipe Streaming-API ist eine Rolle mit den folgenden Berechtigungen erforderlich:
Objekt |
Berechtigung |
|---|---|
Tabelle |
OWNERSHIP oder mindestens INSERT und EVOLVE SCHEMA (nur erforderlich bei Verwendung der Schemaentwicklung für den Kafka-Konnektor mit Snowpipe Streaming) |
Datenbank |
USAGE |
Schema |
USAGE |
Pipe |
OPERATE (nur für die High-Performance-Architektur erforderlich) |
Einschränkungen¶
Beachten Sie bei Snowpipe Streaming Classic die folgenden Beschränkungen:
Snowpipe Streaming Classic unterstützt nicht die erhöhten Größenbeschränkungen für Datenbankobjekte von 128 MB für VARCHAR, VARIANT, ARRAY und OBJECT, und 64 MB für BINARY, GEOGRAPHY und GEOMETRY, die Teil des Verhaltensänderungs-Bundle 2025_03 sind.
Fail-safe unterstützt keine Tabellen, die Daten enthalten, die von Snowpipe Streaming Classic aufgenommen wurden. Für solche Tabellen können Sie Fail-safe nicht zur Wiederherstellung verwenden, da Fail-safe-Operationen für diese Tabelle vollständig fehlschlagen.
Snowpipe Streaming unterstützt nur die Verwendung von 256-Bit-AES-Schlüsseln für die Datenverschlüsselung.
Wenn Automatic Clustering auch für dieselbe Tabelle aktiviert ist, in die Snowpipe Streaming eingefügt wird, können die Rechenkosten für die Dateimigration reduziert werden. Weitere Informationen dazu finden Sie unter Best Practices für Snowpipe Streaming Classic.
Die folgenden Objekte oder Typen werden nicht unterstützt:
Datentypen GEOGRAPHY und GEOMETRY
Spalten mit Sortierung
TEMPORARY-Tabellen
Die Gesamtzahl der Kanäle pro Tabelle darf 10.000 nicht überschreiten. Wir empfehlen, Kanäle bei Bedarf wiederzuverwenden. Wenden Sie sich an den Snowflake Support, wenn Sie mehr als 10.000 Kanäle pro Tabelle öffnen müssen.
Die High-Performance-Architektur weist im Vergleich zur klassischen Architektur weitere Besonderheiten und Beschränkungen auf. Weitere Informationen finden Sie unter Beschränkungen der High-Performance-Architektur.