Database replication considerations¶
Important
This section describes a limited database replication feature that is different from the account replication feature. Snowflake strongly recommends using the account replication feature to replicate and failover databases.
This topic describes the behavior of certain Snowflake features in secondary databases when using database replication. For additional guidance for working with replicated objects and data, refer to Replication considerations.
Database replication and security objects¶
This section describes the database replication behavior of security policies and secrets.
- Masking & Row Access Policies:
The replication operation fails if either of the following conditions is true:
- The primary database is in an Enterprise (or higher) account and contains a policy/tag but one or more of the accounts approved for replication are on lower editions.
- An object contained in the primary database has a dangling reference to a tag in a different database.
The dangling reference behavior for database replication can be avoided when replicating multiple databases in a replication or failover group.
- Tag-based masking policies:
The replication operation fails if either of the following conditions is true:
- The primary database is in an Enterprise (or higher) account and contains a policy/tag but one or more of the accounts approved for replication are on lower editions.
- An object contained in the primary database has a dangling reference to a tag in a different database.
For more information about tag-based masking policies, refer to Tag-based masking policies.
- Password, Session, & Authentication Policies:
The replication operation fails if either of the following conditions is true:
- The primary database is in an Enterprise (or higher) account and contains a policy but one or more of the accounts approved for replication are on lower editions.
- Either of these objects contained in the primary database is attached to a user in the same account. In this case, Snowflake fails the replication operation.
To avoid the failed database replication operation due to a reference to a user, use a replication or failover group instead.
For details, refer to Replication and security policies.
- Secrets:
You cannot replicate a secret using database replication. Use a replication or failover group to replicate a secret. For details, see Replication and secrets.
Dangling references¶
References to objects in another database¶
Carefully analyze whether views or table constraints in a primary database reference objects in another database. For database objects, you can view object dependencies in the Account Usage OBJECT_DEPENDENCIES view.
The following table describes the database replication behavior when an object (the referencing object) in a database references an object (the referenced object) in another database:
| Referencing Object | Referenced Object | Replication Behavior |
|---|---|---|
| Non-materialized view | Object | Succeeds |
| Materialized view | Object | Fails |
| Materialized view | Dropped object | Fails |
| Foreign key constraint | Primary key | Fails |
| Table | Sequence | Fails |
| Masking policy, row access policy, or tag | Object policy/tag is assigned to | Fails |
| Stream | Object | Fails |
Non-materialized views¶
Non-materialized views that reference any object in another database (e.g. table columns, other views, UDFs, or stages) can be replicated, because this type of reference is name based. Name-based references do not cause replication to fail; however, queries on the view in secondary databases will fail if the other database(s) are not replicated in the same region.
For example, suppose view v1 in database d1 references tables t1 and t2 in databases d1 and d2,
respectively. To successfully query view v1 in the secondary database d1, secondary database d2 must also exist in the
account (e.g. as another secondary database). In addition, for consistent query results with the primary databases, secondary
databases d1 and d2 must be refreshed at the same time.
Materialized views¶
Dangling references in materialized views can cause replication to fail with the following error message:
These dangling references can occur if:
-
A materialized view references any object in another database.
Materialized views reference objects by ID rather than name. A database snapshot cannot resolve ID-based references to objects outside the database.
To work around this limitation, replicate both databases together in the same replication or failover group. Alternatively, you can store materialized views and the objects they reference in the same database.
-
A materialized view is invalid (i.e. references a dropped object).
To avoid a dangling reference error for invalid materialized views, identify and fix the problem with the materialized view. Refer to the Troubleshooting section in the materialized views topic.
Constraints¶
Currently, dangling foreign keys cause the replication to fail with the following error message:
This situation occurs when a foreign key in the primary database references a primary key in another database, or vice-versa. That is because constraint references are ID-based. A database snapshot cannot resolve ID-based references to objects outside its own database.
To view the foreign key references in your account, query the Information Schema TABLE_CONSTRAINTS view or the Account Usage TABLE_CONSTRAINTS view.
To work around this limitation, replicate both databases together in the same replication or failover group. Alternatively, you can store linked tables in the same database.
Sequences¶
Currently, dangling sequences cause the replication to fail with the following error message:
This situation occurs when a table in a primary database references a sequence in another database. That is because sequence references are ID-based. A database snapshot cannot resolve ID-based references to objects outside its own database.
To work around this limitation, replicate both databases together in the same replication or failover group. Alternatively, you can reference sequences in the same database.
Masking & row access policies and tags¶
A dangling reference for a masking policy, row access policy, or tag causes the replication to fail with the following error message:
This situation occurs when the policy/tag and the object that has the policy/tag assigned to it exist in different databases. For
example, a table named db1.s1.t1, a row access policy named db2.s1.rap1, and the row access policy is assigned to the table.
To work around this limitation, replicate both databases together in the same replication or failover group.
References to dropped objects¶
Dropping an object that is referenced by another object in the same, or another, database results in a dangling reference. When an object in the primary database references a dropped object, a replication operation fails with the following error message:
To work around this limitation, we recommend that you complete any one of the following steps:
- Undrop any referenced objects.
- Modify the referring objects (for example, modify a materialized view using ALTER MATERIALIZED VIEW). Either reference a different object or remove the reference to the dropped object.
- Drop any objects in the primary database that reference dropped objects.
Replication of multiple databases¶
When multiple databases are replicated, point in time consistency across databases is not available. A snapshot of each primary database is created independently and changes to the secondary database are committed independently. This can be problematic if you have views that join across tables in different databases or depend on cross-database transactions. For example, a transaction that updates two primary databases atomically might not be reflected in the secondary databases at the same time.
To replicate multiple databases with point in time consistency, use a replication or failover group.
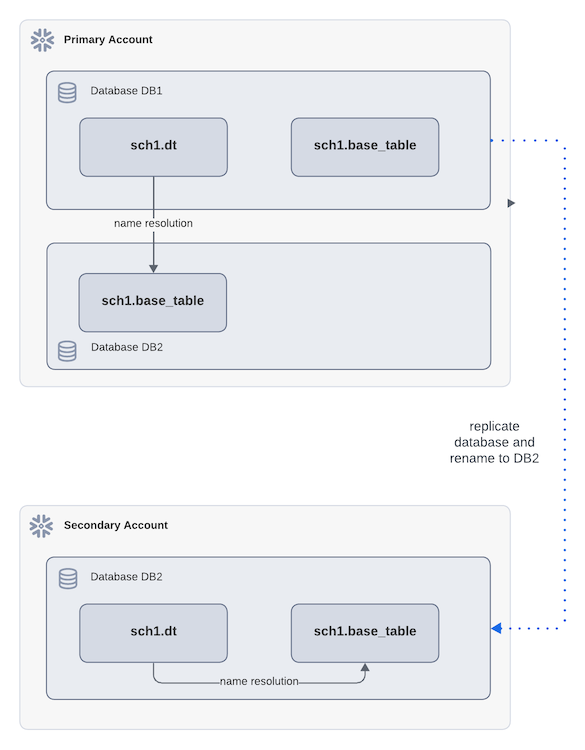
Dynamic tables and data replication¶
If a dynamic table references source objects outside database replication, it can still be replicated. However, name resolution can become complex if the secondary database has a different name than the primary. After failover, this can lead to unexpected refresh results depending on how the source object is referenced. To prevent this, avoid renaming the database during replication setup or use failover group replication instead.
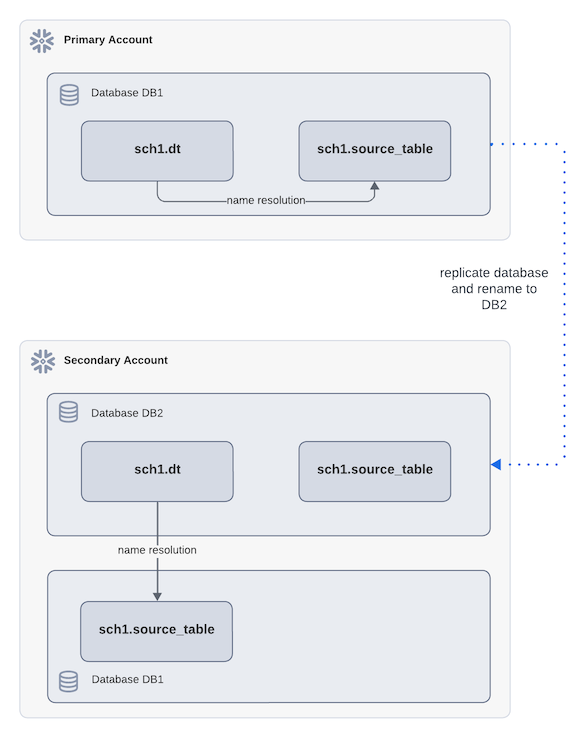
In the following diagram, the dynamic table dt references a source object source_table using a fully qualified
name. For example:
During replication, DB1 is renamed to DB2 in the secondary account. After failover, refreshing the
dynamic table dt in DB2 in the secondary account resolves the source table within the same database, not the
original primary database. While this aligns with name resolution rules, it might lead to unexpected results.
In the following diagram, dt references source_table using a fully qualified name, and the replication renames
DB1 to DB2 in the secondary account. dt in the secondary account now references a source table that is
outside of the containing database.