This topic provides a general overview of Column-level Security and describes the features and support that are common to both Dynamic Data
Masking and External Tokenization.
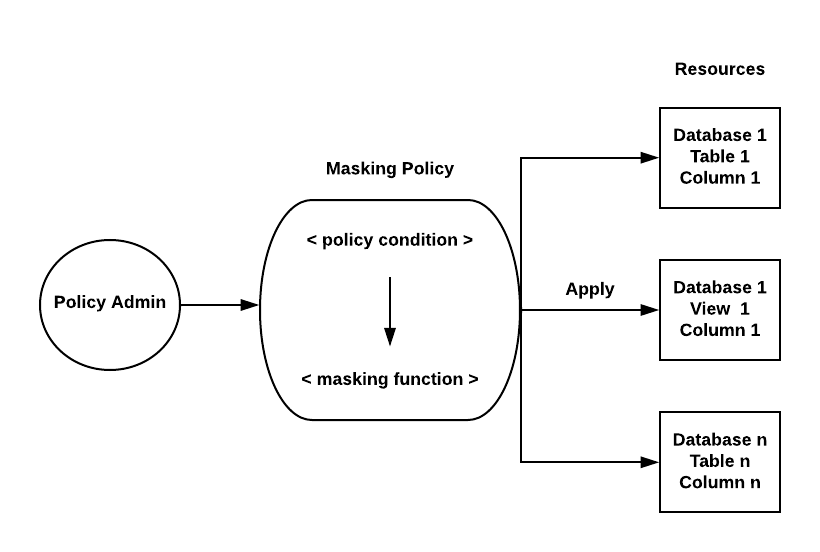
Column-level Security in Snowflake allows the application of a masking policy to a column within a table or view. Currently, Column-level Security includes two features:
Dynamic Data Masking is a Column-level Security feature that uses masking policies to selectively mask plain-text data in table and view columns at query time.
External Tokenization enables accounts to tokenize data before loading it into Snowflake and detokenize the data at query runtime. Tokenization is the process of removing sensitive data by replacing it with an undecipherable token. External Tokenization makes use of masking policies with external functions.
Snowflake supports masking policies as a schema-level object to protect sensitive data from unauthorized access while allowing authorized users to access sensitive data at query runtime. This means that sensitive data in Snowflake is not modified in an existing table (i.e. no static masking). Rather, when users execute a query in which a masking policy applies, the masking policy conditions determine whether unauthorized users see masked, partially masked, obfuscated, or tokenized data. Masking policies as a schema-level object also provide flexibility in choosing a centralized, decentralized, or hybrid management approach. For more information, see Managing Column-level Security (in this topic).
Masking policies can include conditions and functions to transform the data at query runtime when those conditions are met. The policy-driven approach supports segregation of duties to allow security teams to define policies that can limit sensitive data exposure, even to the owner of an object (i.e. the role with the OWNERSHIP privilege on the object, such as a table or view) who normally have full access to the underlying data.
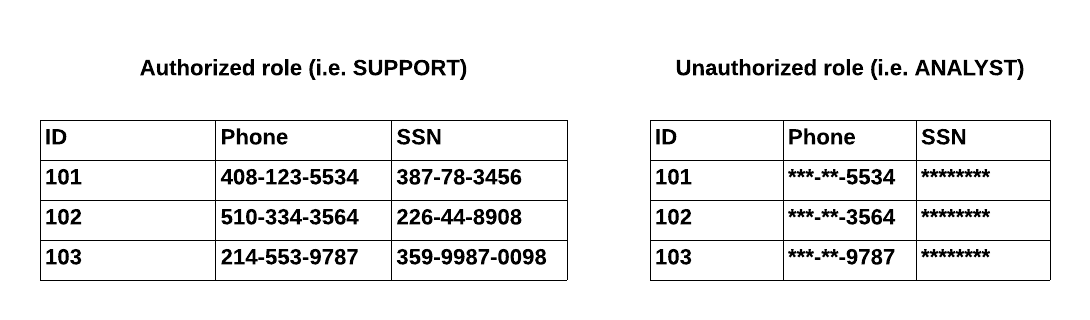
For example, masking policy administrators can implement a masking policy such that analysts (i.e. users with the custom ANALYST role) can only view the last four digits of a phone number and none of the social security number, while customer support representatives (i.e. users with the custom SUPPORT role) can view the entire phone number and social security number for customer verification use cases.
A masking policy consists of a single data type, one or more conditions, and one or more masking
functions.
You can apply the masking policy to one or more table/view columns with the matching data type. For example, you can define a policy for an email address once and apply it to 1000s of email columns across databases and schemas.
While Snowflake offers secure views to restrict access to sensitive data, secure views present management challenges due to large numbers of views and derived business intelligence (BI) dashboards from each view. Masking policies solve this management challenge by avoiding an explosion of views and dashboards to manage.
Masking policies support segregation of duties (SoD) through the role separation of policy administrators from object owners. Secure views do not have SoD, which is a profound limitation to their utility. This role separation leads to the following default settings:
Object owners (i.e. the role that has the OWNERSHIP privilege on the object) do not have the privilege to unset masking policies.
Object owners cannot view column data in which a masking policy applies.
Masking policies for Dynamic Data Masking and External Tokenization adopt the same structure and format with one notable exception: masking policies for External Tokenization require using Writing external functions in the masking policy body.
The reason for this exception is that External Tokenization requires a third-party tokenization provider to tokenize data before loading data into Snowflake. At query runtime, Snowflake uses the external function to make a REST API call to the tokenization provider, which then evaluates a tokenization policy (that is created outside of Snowflake) to return either tokenized or detokenized data based on the masking policy conditions. Note that role mapping must exist in Snowflake and the tokenization provider to ensure that the correct data can be returned from a given query.
Snowflake supports creating masking policies using CREATE MASKING POLICY. For example:
-- Dynamic Data MaskingCREATEMASKINGPOLICY employee_ssn_mask AS(val string)RETURNSstring->CASEWHENCURRENT_ROLE()IN('PAYROLL')THEN val
ELSE'******'END;-- External TokenizationCREATEMASKINGPOLICY employee_ssn_detokenize AS(val string)RETURNSstring->CASEWHENCURRENT_ROLE()IN('PAYROLL')THEN ssn_unprotect(VAL)ELSE val -- sees tokenized dataEND;
Where:
employee_ssn_mask
The name of the Dynamic Data Masking policy.
employee_ssn_detokenize
The name of the External Tokenization policy.
AS (val string) RETURNS string
Specifies the input and output data types. The data types must match.
->
Separates the policy signature from its body.
case ... end;
Specifies the masking policy body (i.e. SQL expression) conditions.
In these two examples, if the query operator is using the PAYROLL custom role in the current session, the operator sees the unmasked/detokenized value. Otherwise, a fixed masked/tokenized value is seen.
ssn_unprotect
The external function to operate on the tokenized data.
Tip
If you want to update an existing masking policy and need to see the current definition of the policy, call the GET_DDL function or run the DESCRIBE MASKING POLICY command.
The masking policy definition can then be updated with the ALTER MASKING POLICY command. This command does not
require unsetting a masking policy from a column, if the masking policy is set on a column. So, a column that is protected by a policy
remains protected while the policy definition is being updated.
Conditional masking uses a masking policy to selectively protect the column data in a table or view based on the values in one or more
different columns.
Using a different column to determine whether data in a given column should be protected offers policy administrators
(i.e. users with the POLICY_ADMIN custom role) more freedom to create policy conditions.
Note the difference between the two representative policy examples:
Masking policy:
This policy can be used for dynamic data masking.
CREATEMASKINGPOLICY email_mask AS(val string)RETURNSstring->CASEWHENCURRENT_ROLE()IN('PAYROLL')THEN val
ELSE'******'END;
This policy specifies only one argument, val, which represents any column that contains string data. This policy can be created
once and applied to any column containing string data. Only users whose CURRENT_ROLE is the PAYROLL
custom role can see the column data. Otherwise, Snowflake returns a fixed masked value in the query result.
This policy specifies two arguments, email and visibility, and these arguments are column names. The first column always
specifies the column to mask. The second column is a conditional column to evaluate whether the first column should be masked. Multiple
conditional columns can be specified. In this policy, users whose CURRENT_ROLE is the ADMIN custom role can view the email address.
If the email address also has a visibility column value of Public, then the email address is visible in the query result.
Otherwise, Snowflake returns a query result with a fixed masked value for the email column.
This policy can be used on multiple tables and views provided that column structure in the table or view matches the columns specified in
the policy. For more information, see CREATE MASKING POLICY.
Since the same object type is used for each representative example, the overall behavior of the policies should be similar, including, but not limited to:
External tables. For details, see: External tables (in this topic).
Considerations:
In addition to the existing normal masking policy considerations, evaluate the following
points prior to using conditional masking policies:
Ensure all columns specified in the CREATE MASKING POLICY statement reside in the same table or view.
Minimize the number of column arguments in the policy definition. Snowflake must evaluate each column at query runtime. Specifying
fewer columns leads to faster performance overall.
Track conditional column usage in a masking policy by calling the Information Schema table function
POLICY_REFERENCES.
At runtime, Snowflake rewrites the query to apply the masking policy expression to the columns specified in the masking policy. The masking
policy is applied to the column regardless of where in a SQL expression the column is referenced, including:
Projections.
JOIN predicates.
WHERE clause predicates.
ORDER BY and GROUP BY clauses.
Important
A masking policy is deliberately applied wherever the relevant column is referenced by a SQL construct to prevent the de-anonymization of
data through creative queries to include masked column data.
Therefore, if executing a query results in masked data in one or more columns, the query output may not provide the anticipated value
because the masked data prevents evaluating all of the query output data in the desired context.
Masking policies with nested objects:
Snowflake supports nested masking policies, such as a masking policy on a table and a masking policy on a view for the same table. At
query runtime, Snowflake evaluates all masking policies that are relevant to a given query in the following sequence:
The masking policy that is applicable to the table is always executed first.
The policy for the view is executed after evaluating the policy for the table.
If nested views exist (e.g. table_1 » view_1 » view_2 » … view_n), the policies are applied in sequential
order from left to right.
This pattern continues for however many masking policies exist with respect to the data in the query. The following diagram illustrates
the relationship between a query performer, tables, views, and policies.
User queries:
The following example shows a user-submitted query followed by the Snowflake runtime query rewrite in which the masking policy
(i.e. sql_expression) applies to the email column only.
SELECTemail, city
FROM customers
WHERE city ='San Mateo';SELECT<SQL_expression>(email), city
FROM customers
WHERE city ='San Mateo';
Query with a protected column in the WHERE clause predicate (anti-pattern):
The following examples show a user-submitted query followed by the Snowflake runtime query rewrite in which the masking policy
(i.e. sql_expression) applies to only one side of a comparison (e.g. the email column but not the string to which the email column
is compared). The results of the query are not what the user intended. Masking only one side of a comparison is a common
anti-pattern.
Query with a protected column in the JOIN predicate (anti-pattern):
SELECT b.email, d.city
FROM
sf_tuts.public.emp_basic AS b
JOIN sf_tuts.public.emp_details AS d ON b.email= d.email;SELECT<SQL_expression>(b.email),
d.city
FROM
sf_tuts.public.emp_basic AS b
JOIN sf_tuts.public.emp_details AS d ON<SQL_expression>(b.email)=<SQL_expression>(d.email);
Snowflake recommends considering the following factors when trying to predict the effect of applying a masking policy to a column and whether the query operator sees masked data:
A masking policy can reference a subquery in the policy definition, however, there are limits to subquery support in Snowflake. For more information, see Working with Subqueries.
The first three items are explained in greater detail in Advanced Column-level Security topics. Data sharing only applies to Dynamic Data Masking because external functions cannot be invoked in the context of a share.
Ultimately, the specific use case determines whether Dynamic Data Masking or External Tokenization is the best fit.
Choosing Dynamic Data Masking or External Tokenization¶
To choose the correct feature that best meets the need of your organization, evaluate the major use cases for your data along with relevant considerations and limitations. The following two sections summarize the benefits and limitations between the two features.
The following table compares the benefits of Dynamic Data Masking and External Tokenization.
Factor
Dynamic Data Masking
External Tokenization
Notes
Preserve analytical value after de-identification.
✔
Since tokenization provides a unique value for a given set of characters, it is possible to group records by a tokenized value
without revealing the sensitive information.
For example, group medical records by diagnosis code with the patient diagnosis code
tokenized. Data analysts can then query a view on the diagnosis code to obtain a count of the number of patients with a unique
diagnosis code.
Pre-load tokenized Data.
✔
Unauthorized users never see the real data value. Requires third-party tokenization provider.
Pre-load unmasked data.
✔
Only need built-in Snowflake functionality, no third-parties required.
Write a policy once and have it apply to thousands of columns across databases and schemas.
Data administration and SoD.
✔
✔
A security or privacy officer decides which columns to protect, not the object owner.
Masking policies are easy to manage and support centralized and decentralized administration models.
Data authorization and governance.
✔
✔
Contextual data access by role or custom entitlements.
✔
✔
Supports data governance as implemented by security or privacy officers and can prohibit privileged users with the ACCOUNTADMIN
or SECURITYADMIN system roles from unnecessarily viewing data.
Database replication and account object replication.
The following table describes the current limitations for Column-level Security. A checkmark (i.e. ✔) indicates a limitation or lack of current support for the feature.
Dropping a database or schema requires the masking policy and its mappings to be self-contained within the database or schema.
For example, database_1 contains policy_1 and policy_1 is only used in database_1.
External tables.
✔
✔
An external table cannot be referenced as a lookup table (i.e. in a subquery) to determine whether column values should be masked.
For more information, see External Tables (in this topic)
Different data types in the input and output of a policy definition.
✔
✔
A masking policy definition must have the same data type for the input and output. In other words, as a representative example,
you cannot define the input datatype as a timestamp and return a string.
Masking policy change management.
✔
✔
You can optionally store and track masking policy changes in a version control system of your choice.
Use caution when inserting values from a source column that has a masking policy on the source column to a target column without a masking policy on the target column. Since a masking policy is set on the source column, a role that views unmasked column data can insert unmasked data into another column, where any role with sufficient privileges on the table or view can see the value.
If a role that sees masked data in the source column inserts those values into a target column, the inserted values remain masked. If a masking policy is not set on the target column, then users with sufficient privileges on the table or view may see a combination of masked and unmasked values in the target column. Therefore, as a best practice:
Exercise caution when applying masking policies to columns.
Verify queries using columns that have masking policies before making tables and views available to users.
Determine additional tables and views (i.e. target columns) where the data in the source column may appear.
Use caution when creating the setup script for a Snowflake Native App when the masking policy exists in a versioned schema. For details, see
version schema considerations.
Snowflake supports masking policies with tables and views. The following describes how masking policies affect tables and views in
Snowflake.
Tip
Call the POLICY_CONTEXT function to simulate a query on a column that is protected by a masking
policy, a table or view protected by a row access policy, or both types of policies. You can also simulate
SYS_CONTEXT namespace values, such as activated roles and agent types.
The policy conditions can evaluate the user’s active primary and secondary roles in a session directly, look up active roles in a mapping
table, or do both depending on how the policy administrator wants to write the policy. If the policy contains a mapping table lookup,
create a centralized mapping table and store the mapping table in the same database as the protected table. This is particularly important
if the policy calls the IS_DATABASE_ROLE_IN_SESSION function. For details, see the function
usage notes.
For these use cases, Snowflake recommends writing the policy conditions to call the IS_ROLE_IN_SESSION or
the IS_DATABASE_ROLE_IN_SESSION function depending on whether you want to specify an account role or
database role. For examples, see:
Examples section in the IS_ROLE_IN_SESSION function.
When a column is not protected by a masking policy, there are two options to apply a masking policy to a column in a table or view:
With a new table or view, apply the policy to a table column with a CREATE TABLE statement or a view
column with a CREATE VIEW statement.
With an existing table or view, apply the policy to a table column with an ALTER TABLE … ALTER COLUMN
statement or a view column with an ALTER VIEW statement.
For a new table or view, execute the following statements:
-- tableCREATE OR REPLACETABLE user_info (ssn stringmaskingpolicy ssn_mask);-- viewCREATE OR REPLACEVIEW user_info_v (ssn maskingpolicy ssn_mask_v)ASSELECT*FROM user_info;
For an existing table or view, execute the following statements:
After creating a masking policy using
conditional columns, there are two options to set a conditional masking policy on a column
when the column is not already protected by a masking policy:
For a new table or view, apply the policy to a table or view column with the corresponding CREATE statement.
Once a masking policy is set on a column, there are two different pathways to replace the masking policy on the column with a different
masking policy without having to replace the entire table or view.
These examples use ALTER TABLE commands. The same approach applies to views with the
ALTER VIEW command:
Unset the policy from a table column in one statement and then set a new policy on the column in a different statement:
The FORCE keyword requires the data type of the policy in the ALTER TABLE statement
(i.e. STRING) to match the data type of the masking policy currently set on the column (i.e. STRING).
The FORCE keyword can be combined with the USING clause to set a conditional masking policy on column:
Exercise caution when replacing a masking policy on a column.
Depending on the timing of the replacement and the query on the column, choosing to replace the policy in two separate statements could
lead to a data leak because the column data is unprotected in the time interval between the UNSET and SET operations.
However, if the policy conditions are different in the replacement policy, specifying the FORCE keyword could lead to a lack of
access because (previously) users could access data and the replacement no longer allows access.
Prior to replacing a policy, consult your internal data administrators to coordinate the best approach to protect data with masking
policies and replace masking policies as needed.
A given table or view column can be specified in either a masking policy signature or a row access policy signature. In other words, the
same column cannot be specified in both a masking policy signature and a row access policy signature at the same time.
This behavior also applies to column used as conditional columns in a masking policy.
Call the POLICY_CONTEXT function to simulate a query on a column that is protected by a masking policy,
a table or view protected by a row access policy, or both types of policies. You can also simulate
SYS_CONTEXT namespace values, such as activated roles and agent types. For example:
Snowflake lets you set a masking policy on a materialized view column. At query runtime, the query plan executes any masking policy that
is present prior to creating the materialized view rewrite. Once the materialized view rewrite occurs, masking policies cannot be set on
any materialized view columns.
There are two options to set a masking policy on a materialized view column:
Additionally, the following two limitations exist regarding masking policies and materialized views:
A masking policy cannot be set on a table column if a materialized view is already created from the underlying table. Snowflake returns
the following error message when this attempt is made:
SQL execution error: One or more materialized views exist on the table. number of mvs=<number>, table name=<table_name>.
If a masking policy is set on an underlying table column and a materialized view is created from that table, the
materialized view only contains columns that are not protected by a masking policy. Snowflake also returns the following error message
if the attempting to include one or more columns protected by a masking policy:
Unsupported feature 'CREATE ON MASKING POLICY COLUMN'.
Tip
If you prefer to set a masking policy on a column in the base table, consider creating a dynamic table from the base table. For more
information, see Masking and row access policies.
You cannot assign a masking policy to the external table VALUE column when creating the external table with a
CREATE EXTERNAL TABLE statement because this column is automatically created by default.
You can assign the masking policy to the external table VALUE column by executing an ALTER TABLE … ALTER COLUMN
statement on the external table. The data type of the masking policy that protects the VALUE column must be VARIANT.
You can assign a masking policy to a virtual column in an external table as follows:
Set the EXEMPT_OTHER_POLICIES masking policy property to TRUE in the masking policy that protects VALUE column in the external
table.
If this property is not already set, execute a CREATE OR REPLACE statement on the masking policy the protects the VALUE column and
specify the EXEMPT_OTHER_POLICIES property. The virtual column inherits the policy that protects the VALUE column, and this property
allows the policy on the virtual column to override the inherited policy. For details, see
CREATE MASKING POLICY.
Assign a different masking policy to the virtual column using an ALTER TABLE command. This policy can be less strict than the policy for
the VALUE column because the virtual column is less sensitive. The virtual column contains a lesser amount of data than the VALUE
column; the VALUE column contains all of the data for each row in the external table.
The data type in the policy that protects the virtual column depends on the data type of the virtual column.
Regarding conditional columns in a masking policy, a virtual column can be listed as an conditional column argument to determine whether
the first column argument should be masked or tokenized. However, a virtual column cannot be specified as the first column to mask or
tokenize.
Snowflake does not support using an external table as a lookup table (i.e. in a subquery) in a masking policy. While cloning a database,
Snowflake clones the masking policy, but not the external table. Therefore, the policy in the cloned database refers to a table that
is not present in the cloned database.
If the data in the external table is necessary for the policy, consider moving the external table data to a dedicated schema
within the database in which the masking policy exists prior to completing a clone operation. Update the masking policy to
reference the fully qualified table name to ensure the policy refers to a table in the cloned database.
The following approach helps to safeguard data from users with the SELECT privilege on the table or view when accessing a cloned object:
Cloning an individual policy object is not supported.
Cloning a schema results in the cloning of all policies within the schema.
A cloned table maps to the same policies as the source table. In other words, if a policy is set on the base table or its columns, the
policy is attached to the cloned table or its columns.
If a table or view exists in the source schema/database and has references to policies in the same schema/database, the cloned table or
view is mapped to the corresponding cloned policy (in the target schema/database) instead of the policy in the source schema/database.
If the source table refers to a policy in a different schema (i.e. a foreign reference), then the cloned table retains the
foreign reference.
Executing a CREATE TABLE … AS SELECT (CTAS) statement applies any masking policies on columns included in the statement before the data is populated in the new table (i.e. the applicable column data is masked in the new table). This flow is adhered to because a table created using a CTAS statement may have a different set of columns than the source objects, and Snowflake cannot apply masking policies to the new table columns implicitly.
If there is a need to copy unmasked data, use a role authorized for protected data to run the CTAS statement. After creating the new table, transfer ownership of the new table to another role and ask the masking policy administrator to apply the masking policies to the columns of the new table.
A representative use case is that a data analyst wants to obtain the COUNT for a column of social security numbers without needing to see the actual data. However, if the data analyst runs a query using SELECT on a masked table column, the query returns a fixed masked value. Users with the PAYROLL custom role in the current session see the unmasked data and everyone else sees masked data.
To achieve this outcome:
The table owner creates a view on the column that contains the aggregate function.
Grant the ANALYST role full privileges on the view. Do not grant the analyst any privileges on the table.
Apply a masking policy to the table column. Note that the table policy is always applied before the view policy, if there is a policy on a view column.
CASEWHENCURRENT_ROLE()IN('PAYROLL')THEN val
ELSE'***MASKED***'END;
A UDF can be passed into the masking policy conditions.
It is important to ensure that the data type for the table or view column, the UDF, and the masking policy match. If the data
types are different, such as having a table column and UDF with data type VARIANT and the masking policy (with this UDF in the policy
conditions) returns VARCHAR data type, Snowflake returns an error when making a query on the table column when this masking policy is set
on the table column.
For a representative example of matching the data type for a table column, UDF, and masking policy, see the Using JavaScript
UDFs on JSON (Variant) example in CREATE MASKING POLICY.
If the provider assigns a policy to a shared table or view and the policy conditions call the
CURRENT_ROLE or CURRENT_USER function, or the policy conditions call a secure UDF, Snowflake returns a NULL value for the function or the UDF in the consumer account.
The reason is that the owner of the data being shared does not typically control the users or roles in the account in which the table
or view is being shared. As a workaround, use the CURRENT_ACCOUNT function in the policy conditions.
Alternatively, as a provider, write the policy conditions to call the IS_DATABASE_ROLE_IN_SESSION
function and share the database role. As a consumer, grant the shared database role to an account role. For details, see
Share data protected by a policy.
Limitations:
A data sharing provider cannot create a policy in a reader account.
Data sharing consumers cannot apply a policy to a shared table or view. As a workaround, import the shared database and create a local
view from the shared table or view.
Data sharing consumers cannot query a shared table or view that references two different providers. For example:
rap1 is a row access policy that protects the table named t1, where t1 is in the share named share1 from a provider.
The rap1 policy conditions reference a mapping table named t2, where t2 comes from share2 and a different provider.
The consumer query on t1 fails.
The provider for t1 can query t1.
External functions:
Snowflake returns an error if:
The policy assigned to a shared table or view is updated to call an external function.
The policy calls an external function and you attempt to assign the policy to a shared table or view.
Note
For External Tokenization, Secure Data Sharing is not applicable because external functions
cannot be invoked in the context of a share.
Masking policies and their assignments can be replicated using database replication and replication groups.
For database replication, the replication operation fails if either of the
following conditions is true:
The primary database is in an Enterprise (or higher) account and contains a policy but one or more of the accounts approved for
replication are on lower editions.
A table or view contained in the primary database has a dangling reference to a
masking policy in another database.
The dangling reference behavior for database replication can be avoided when replicating multiple databases in a
replication group.
Note
If using failover or failback actions, the Snowflake account must be Business Critical Edition or higher.
When used on a column with a masking policy, the EXPLAIN command output includes the masked data, not the masking policy body.
The following example generates the EXPLAIN plan for a query on a table of employee identification numbers and social security numbers. The command in this example generates the example in JSON format.
The column containing the social security numbers has a masking policy.
Using the COPY INTO <location> command on a column that has a masking policy results in the masking policy being applied to the data. Therefore, unauthorized users see masked data after executing the command.
This section provides information useful for determining your overall management approach to masking policies, describes the privileges required to manage Column-level Security, and lists supported DDL commands.
Choosing a centralized, hybrid, or decentralized approach¶
To manage Dynamic Data Masking and External Tokenization policies effectively, it is helpful to consider whether your approach to masking data in columns should follow a centralized security approach, a decentralized approach, or a hybrid of each of these two approaches.
The following table summarizes some of the considerations with each of these two approaches.
Policy Action
Centralized Management
Hybrid Management
Decentralized Management
Create policies
Security officer
Security officer
Individual teams
Apply policies to columns
Security officer
Individual teams
Individual teams
As a best practice, Snowflake recommends that your organization gathers all relevant stakeholders to determine the best management approach for implementing Column-level Security in your environment.
This section describes the Column-level Security masking policy privileges and how they apply to a centralized, decentralized, or hybrid management approach.
Snowflake provides the following privileges for Column-level Security masking policies.
Operating on an object in a schema requires at least one privilege on the parent database and at least one privilege on the parent schema.
Privilege
Usage
APPLY
Enables executing the unset and set operations for a masking policy on a column.
Note that granting the global APPLY MASKING POLICY privilege (i.e. APPLY MASKING POLICY on ACCOUNT) enables executing the DESCRIBE
operation on tables and views.
Grants full control over the masking policy. Required to alter most properties of a masking policy. Only a single role can hold this
privilege on a specific object at a time.
Note
Operating on a masking policy also requires the USAGE privilege on the parent database and schema.
The following examples show how granting privileges apply to different management approaches. After granting the APPLY privilege to a role, the masking policy can be set on a table column using an ALTER TABLE … ALTER COLUMN statement or set on a view column using an ALTER VIEW statement (by a member of the role with the APPLY privilege on the masking policy).
Centralized Management
In a centralized management approach, only the security officer custom role (e.g. security_officer) creates and applies masking policies to columns in tables or views. This approach can provide the most consistency in terms of masking policy management and masking sensitive data.
-- create a security_officer custom roleUSEROLEACCOUNTADMIN;CREATEROLE security_officer;-- grant CREATE AND APPLY masking policy privileges to the SECURITY_OFFICER custom role.GRANTCREATEMASKINGPOLICYONSCHEMA mydb.mysch TOROLE security_officer;GRANTAPPLYMASKINGPOLICYONACCOUNTTOROLE security_officer;
Where:
schema_name
Specifies the identifier for the schema; must be unique for the database in which the schema is created.
In addition, the identifier must start with an alphabetic character and cannot contain spaces or special characters unless the entire identifier string is enclosed in double quotes (e.g. “My object”). Identifiers enclosed in double quotes are also case-sensitive.
In a hybrid management approach, the security officer custom role (e.g. security_officer) creates masking policies and individual teams (e.g. finance, payroll, human resources) apply the masking policies to columns in tables or views owned by the teams. This approach can lead to consistent policy creation and maintenance but requires individual teams to have the increased responsibility to mask sensitive data.
The SECURITY_OFFICER custom role grants the APPLY privilege to the human resources team (i.e. users with the HUMAN_RESOURCES custom role) to mask social security numbers (e.g. masking policy: ssn_mask) in columns for objects owned by the HUMAN_RESOURCES custom role.
In a decentralized management approach, individual teams create and apply masking policies to columns in tables or views. This approach can lead to inconsistent policy management, with the possibility of sensitive data not being masked properly, since individual teams assume all responsibility for managing masking policies and masking sensitive data.
In this representative example, the support team (i.e. users with the custom role SUPPORT) and the finance team (i.e. users with the custom role FINANCE) can create masking policies. Note that these custom roles may not include the SECURITY_OFFICER custom role.
The support team grants the APPLY privilege to the human resources team (i.e. users with the custom role HUMAN_RESOURCES) to mask social security numbers (e.g. masking policy: ssn_mask) in columns for objects owned by the HUMAN_RESOURCES custom role.
The finance team grants the APPLY privilege to the internal audit team (i.e. users with the custom role AUDIT_INTERNAL) to mask cash flow data (e.g. masking policy: cash_flow_mask) in columns for objects owned by the AUDIT_INTERNAL custom role.
The following table summarizes the relationship between the Column-level Security masking policy DDL operations and their necessary privileges.
Operating on an object in a schema requires at least one privilege on the parent database and at least one privilege on the parent schema.
Operation
Privilege
Create masking policy
A role with the CREATE MASKING POLICY on SCHEMA privilege.
Alter masking policy
The masking policy owner (i.e. the role with the OWNERSHIP privilege on the masking policy).
Drop masking policy
The masking policy owner (i.e. the role with the OWNERSHIP privilege on the masking policy).
Show masking policies
One of the following:
A role with the global APPLY MASKING POLICY privilege, or
The masking policy owner (i.e. the role with the OWNERSHIP privilege on the masking policy) or
A role with the APPLY privilege on the masking policy.
Describe masking policy
One of the following:
A role with the global APPLY MASKING POLICY privilege or
The masking policy owner (i.e. the role with the OWNERSHIP privilege on the masking policy) or
A role with the APPLY privilege on the masking policy.
List of columns having a masking policy
One of the following:
The role with the APPLY MASKING POLICY privilege, or
The role with the APPLY on MASKING POLICY privilege on a given masking policy and has OWNERSHIP on the target object.
Using UDFs in a masking policy
If creating a new or altering an existing masking policy, the policy administrator role must have usage on the UDF, all scalar UDFs
in the policy expression should have the same data type, and the UDF must exist.
At the query runtime, Snowflake verifies if the UDF exists; if not, the SQL expression will not resolve and the query fails.
You can use the MASKING_POLICIES view in the Account Usage schema of the shared
SNOWFLAKE database. This view is a catalog for all masking policies in your Snowflake account. For example:
Snowflake supports different options to identify masking policy assignments, depending on whether the query needs to target the account
or a specific database.
Account-level query:
Use the Account Usage POLICY_REFERENCES view to determine all of the columns
that have a masking policy. For example:
Every Snowflake database includes an Snowflake Information Schema. Use the Information Schema table function
POLICY_REFERENCES to determine all of the masking policies on columns for a given table:
You can use the Snowsight Governance & security » Tags & policies area to monitor and report on the usage of
policies and tags with tables, views, and columns. There are two different interfaces: Dashboard and Tagged Objects.
When using the Dashboard and the Tagged Objects interface, note the following details.
The Dashboard and Tagged Objects interfaces require a running warehouse.
Snowsight updates the Dashboard every 12 hours.
The Tagged Objects information latency can be up to two hours and returns up to 1000 objects.
To access the Tags & policies area, your Snowflake account must be Enterprise Edition or higher.
Additionally, you must do either of the following:
Use the ACCOUNTADMIN role.
Use an account role that is directly granted the GOVERNANCE_VIEWER and OBJECT_VIEWER database roles.
You must use an account role with these database role grants. Currently, Snowsight does not evaluate role hierarchies
and user-defined database roles that have access to tables, views, data access policies, and tags.
To determine if your account role is granted these two database roles, use a SHOW GRANTS command:
If your account role is not granted either or both of these database roles, use the GRANT DATABASE ROLE command
and run the SHOW GRANTS command again to confirm the grants:
As a data administrator, you can use the Dashboard interface to monitor tag and policy usage in the following ways.
Coverage: specifies the count and percentage based on whether a table, view, or column has a policy or tag.
Prevalence: lists and counts the most frequently used policies and tags.
The coverage and prevalence provide a snapshot as to how well the data is protected and tagged.
When you select a count number, percentage, policy name, or tag name, the Tagged Objects interface opens. The Tagged Objects
interface updates the filters automatically based on your selection in the Dashboard.
The monitoring information is an alternative or complement to running complex and query-intensive operations on multiple Account
Usage views.
As a data administrator, you can use this table to associate the coverage and prevalence in the Dashboard to a list of specific
tables, view, or columns quickly. You can also filter the table results manually as follows.
Choose Tables or Columns.
For tags, you can filter with tags, without tags, or by a specific tag.
For policies, you can filter with policies, without policies, or by a specific policy.
When you select a row in the table, the Table Details or Columns tab in Catalog » Database Explorer opens. You can edit
the tag and policy assignments as needed.
Tip
You can use Snowsight to troubleshoot masking policy assignments. In the Columns tab, the MASKING POLICY column
shows Policy Error when there is a conflict with the masking policy assignment on the column. You can select the Policy
Error for more information.
Additionally, the Data Preview tab does not render a data preview when there is a error with a masking policy assignment on a
column. Instead, the Data Preview tab returns the SQL error message. This message corresponds to one of the error values in the
POLICY_STATUS column of the Account Usage POLICY_REFERENCES view and the Information Schema POLICY_REFERENCES table function.
To correct the error, use the SQL error message and the Policy Error message to modify the tag or policy assignment.