Installing and Configuring the Spark Connector¶
Multiple versions of the connector are supported; however, Snowflake strongly recommends using the most recent version of the connector. To view release information about the latest version, see the Spark Connector Release Notes (link in the sidebar).
The instructions in this topic can be used to install and configure all supported versions of the connector.
Supported Versions¶
Snowflake supports multiple versions of the connector:
| Snowflake Spark Connector versions: | 3.x, 2.x |
| Supported Spark versions: | Connector version 3.x: Spark 3.5, 3.4, 3.3, 3.2 Connector version 2.x: Spark 3.4, 3.3, 3.2 |
| Supported Scala versions: | Scala 2.13 Scala 2.12 |
| Data source name: | Connector version 3.x and 2.x: net.snowflake.spark.snowflake — v2.10.0 (or higher) of the connector allows snowflake as the data source name |
| Package name (for imported classes): | net.snowflake.spark.snowflake |
| Package distribution: | Scala 2.13 in the Maven Central Repository Scala 2.12 in the Maven Central Repository |
| Source code: | spark-snowflake (GitHub) master (for the latest version), previous_spark_version (for earlier versions) |
The developer notes for the different versions are hosted with the source code.
Note
- 3.x: A single version of the Snowflake Spark Connector version 3.0.0 and higher supports multiple versions of Spark.
- 2.x: The Snowflake Spark Connector for 2.x generally supports the three most recent versions of Spark. Download a version of the connector that is specific to your Spark version. For example, to use version 2.16.0 of the connector with Spark version 3.4, download the
2.16.0-spark_3.4version of the connector. - To enforce data protection policies when querying Apache Iceberg™ tables from Apache Spark™, you must install 3.1.6 or a later version.
Requirements¶
To install and use Snowflake with Spark, you need the following:
-
A supported operating system. For a list of supported operating systems, see Operating system support.
-
Snowflake Connector for Spark.
-
Snowflake JDBC Driver (the version compatible with the version of the connector).
-
Apache Spark environment, either self-hosted or hosted in any of the following:
-
In addition, you can use a dedicated Amazon S3 bucket or Azure Blob storage container as a staging zone between the two systems; however, this is not required with version 2.2.0 (and higher) of the connector, which uses a temporary Snowflake internal stage (by default) for all data exchange.
-
The role used in the connection needs USAGE and CREATE STAGE privileges on the schema that contains the table that you will read from or write to.
Note
If you are using Databricks or Qubole to host Spark, you do not need to download or install the Snowflake Connector for Spark (or any of the other requirements). Both Databricks and Qubole have integrated the connector to provide native connectivity.
For more details, see:
Verifying the OCSP Connector or Driver Version¶
Snowflake uses OCSP to evaluate the certificate chain when making a connection to Snowflake. The driver or connector version and its configuration both determine the OCSP behavior. For more information about the driver or connector version, their configuration, and OCSP behavior, see OCSP Configuration.
Downloading and Installing the Connector¶
The instructions in this section pertain to version 2.x and higher of the Snowflake Connector for Spark.
Important
Snowflake periodically releases new versions of the connector. The following installation tasks must be performed each time you install a new version. This also applies to the Snowflake JDBC driver, which is a prerequisite for the Spark connector.
Step 1: Download the latest version of the Snowflake Connector for Spark¶
Snowflake provides multiple versions of the connector. Download the appropriate version, based on the following:
- The version of the Snowflake Connector for Spark that you want to use.
- The version of Spark that you are using.
- The version of Scala that you are using.
You can download the Snowflake Spark Connector from Maven. If you want to build the driver, you can access the source code from GitHub.
Maven Central Repository¶
Snowflake provides separate package artifacts for each supported Scala version (2.12 and 2.13). For each of these Scala versions, Snowflake provides different versions of the Spark connector as well as separate artifacts that support different versions of Spark.
To download the Spark connector:
-
Search the Maven repository for your desired version of the Snowflake Spark Connector:
The following screenshot provides an example of the search results page:

-
The Latest version label shows the most current version of the driver. If you want to download a prior version, click the View all link beside the latest version to see all available packages. The following screenshot shows an example of all available packages for spark-snowflake_2.12.
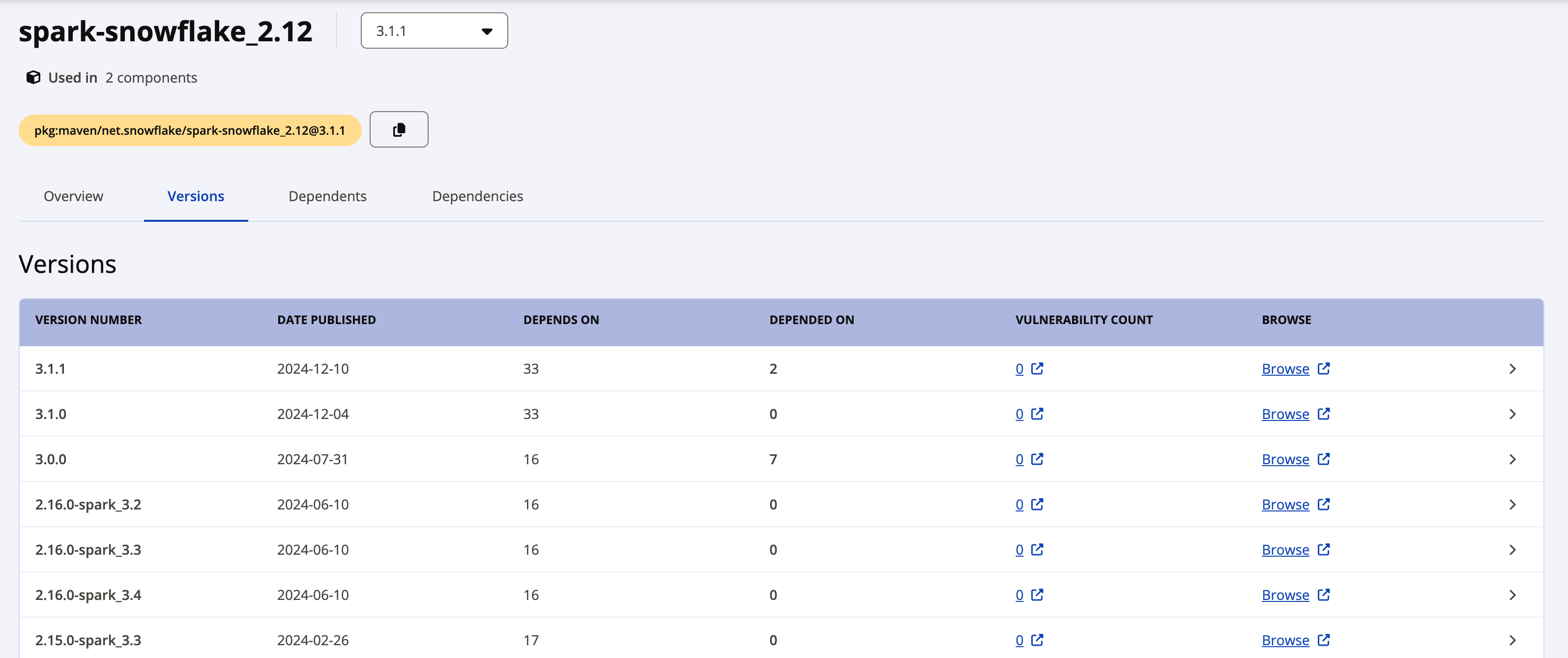
The individual packages for Snowflake Spark Connector version 2.x use the following naming convention:
where:
C.Cis the Scala version (e.g. 2.12).N.N.Nis the Snowflake version (e.g. 2.16.0).P.Pis the Spark version (e.g. 3.4).
For example:
The individual packages for Snowflake Spark Connector version 3.x use the following naming convention:
where:
C.Cis the Scala version (e.g. 2.13).N.N.Nis the Snowflake version (e.g. 3.1.1).
For example:
-
Click the Browse link beside the version you want to download, then select and download the JAR file.

-
If you plan to verify the package signature, you need to download the signature file as well. Click the filename with the .jar.asc filename extension (for example, net.snowflake:spark-snowflake_2.13:3.1.1.jar.asc or net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4.jar.asc).
GitHub¶
The source code for the Spark Snowflake Connector is available on GitHub. However, the compiled packages are not available on GitHub. You can download the compiled packages from Maven.
Step 2: Download the Compatible Version of the Snowflake JDBC Driver¶
Next, you need to download the version of the Snowflake JDBC driver that is compatible with the version of the Snowflake Spark Connector that you are using.
The Snowflake JDBC driver is provided as a standard Java package through the JDBC Driver page in the Maven Central Repository. You
can either download the package as a .jar file or you can directly reference the package. These instructions assume you are referencing the package.
To find the supported version of the Snowflake JDBC Driver for the version of the Snowflake Spark Connector that you are using, see the release notes.
For more details on downloading and installing the Snowflake JDBC Driver, see Downloading / integrating the JDBC Driver.
Step 3 (Optional): Verify the Snowflake Connector for Spark Package Signature¶
To verify the Snowflake Connector for Spark package signature:
-
From the public keyserver, download and import the Snowflake GPG public key for the version of the Snowflake Connector for Spark that you are using:
- For version 3.1.2 and higher:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 2A3149C82551A34A - For version 3.1.0 through 3.1.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 5A125630709DD64B - For version 2.11.1 through 3.0.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 630D9F3CAB551AF3 - For version 2.8.2 through 2.11.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 37C7086698CB005C - For version 2.4.13 through 2.8.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys EC218558EABB25A1 - For version 2.4.12 and lower:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 93DB296A69BE019ANote
If this command fails with the following error:
then specify that you want to use port 80 for the keyserver:
- For version 3.1.2 and higher:
-
Run the
gpg --verifycommand to verify the signature of the package.For the
--verifycommand-line flag, specify the.ascfile that you downloaded earlier as the signature file and the JAR file as the file containing the signed data.where:
x.xxis the Scala version (e.g. 2.12).N.N.Nis the version of the Snowflake Connector for Spark (e.g. 2.16.0).P.Pis the Spark version (e.g. 3.4).
Note
Verifying the signature produces a warning similar to the following:
To avoid the warning, you can grant the Snowflake GPG public key implicit trust.
-
Your local environment can contain multiple GPG keys; however, for security reasons, Snowflake periodically rotates the public GPG key. As a best practice, we recommend deleting the existing public key after confirming that the latest key works with the latest signed package. For example:
Step 4: Configure the Local Spark Cluster or Amazon EMR-hosted Spark Environment¶
If you have a local Spark installation, or a Spark installation in Amazon EMR, you
need to configure the spark-shell program to include both the Snowflake JDBC driver and the Spark Connector:
- To include the Snowflake JDBC driver, use the
--packageoption to reference the JDBC package from the JDBC Driver page in the Maven Central Repository, providing the exact version of the driver you wish to use (e.g.net.snowflake:snowflake-jdbc:3.13.30). - To include the Spark Connector, use the
--packageoption to reference the appropriate package (Scala 2.12 or Scala 2.13) hosted in the Maven Central Repository, providing the exact version of the driver you want to use (e.g.net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4).
For example:
Installing Additional Packages (If Needed)¶
Depending on your Spark installation, some packages required by the connector may be missing. You can add missing packages to your installation by using the appropriate
flag for spark-shell:
--packages--jars(if the packages were downloaded as.jarfiles)
The required packages are listed below, with the syntax (including version number) for using the --packages flag to reference the packages:
org.apache.hadoop:hadoop-aws:2.7.1org.apache.httpcomponents:httpclient:4.3.6org.apache.httpcomponents:httpcore:4.3.3com.amazonaws:aws-java-sdk-core:1.10.27com.amazonaws:aws-java-sdk-s3:1.10.27com.amazonaws:aws-java-sdk-sts:1.10.27
For example, if the Apache packages are missing, to add the packages by reference:
Preparing an External Location For Files¶
You might need to prepare an external location for files that you want to transfer between Snowflake and Spark.
This task is required if either of the following situations is true:
-
You will run jobs that take longer than 36 hours, which is the maximum duration for the token used by the connector to access the internal stage for data exchange.
-
The Snowflake Connector for Spark version is 2.1.x or lower (even if your jobs require less than 36 hours).
Note
If you are not currently using v2.2.0 (or higher) of the connector, Snowflake strongly recommends upgrading to the latest version.
Preparing an AWS External S3 Bucket¶
Prepare an external S3 bucket that the connector can use to exchange data between Snowflake and Spark. You then provide the location information, together with the necessary AWS credentials for the location, to the connector. For more details, see Authenticating S3 for Data Exchange in the next topic.
Important
If you use an external S3 bucket, the connector does not automatically remove any intermediate/temporary data from this location. As a result, it is best to use a specific bucket or path (prefix) and set a lifecycle policy on the bucket/path to clean up older files automatically. For more details on configuring a lifecycle policy, see the Amazon S3 documentation.
Preparing an Azure Blob Storage Container¶
Prepare an external Azure Blob storage container that the connector can use to exchange data between Snowflake and Spark. You then provide the location information, together with the necessary Azure credentials for the location, to the connector. For more details, see Authenticating Azure for Data Exchange in the next topic.