Réplication des bases de données et des objets de compte sur plusieurs comptes¶
Cette rubrique décrit les étapes nécessaires pour répliquer les objets et les données de compte entre les comptes Snowflake de la même organisation, et maintenir la synchronisation des objets et des données. La réplication de comptes peut se produire entre des comptes Snowflake dans différentes régions et entre des plateformes Cloud.
Note
Lorsque vous mettez à niveau un compte vers Business Critical Edition (ou une version supérieure), il peut s’écouler jusqu’à 12 heures avant que les fonctionnalités de basculement ne soient disponibles.
Prise en charge de la région pour la réplication et le basculement/la récupération¶
Les clients peuvent répliquer dans toutes les régions d’un groupe de régions. Pour effectuer une réplication entre des régions de Groupes de régions différentes (par exemple, d’une région commerciale Snowflake à une région gouvernementale Snowflake), veuillez contacter l’assistance de Snowflake afin d’autoriser l’accès.
Transition de la réplication de base de données à la réplication par groupe¶
Les bases de données pour lesquelles la réplication a été activée à l’aide de ALTER DATABASE doivent avoir la réplication désactivée avant qu’elles puissent être ajoutées à un groupe de réplication ou de basculement.
Note
Exécutez les instructions SQL de cette section en utilisant le rôle ACCOUNTADMIN.
Étape 1. Désactiver la réplication pour une base de données pour laquelle la réplication a été autorisée¶
Exécutez la fonction SYSTEM$DISABLE_DATABASE_REPLICATION pour désactiver la réplication d’une base de données principale, ainsi que de toutes les bases de données secondaires qui lui sont liées, afin de l’ajouter à un groupe de réplication ou de basculement.
Exécutez l’instruction SQL suivante depuis le compte source avec la base de données principale :
SELECT SYSTEM$DISABLE_DATABASE_REPLICATION('mydb');
Étape 2. Ajouter la base de données à un groupe de basculement principal et créer un groupe de basculement secondaire¶
Une fois que vous avez réussi à désactiver la réplication pour une base de données, vous pouvez ajouter la base de données principale à un groupe de basculement dans le compte source.
Ensuite, créez un groupe de basculement secondaire dans le compte cible. Lorsque le groupe de basculement secondaire est actualisé dans le compte cible, la base de données précédemment secondaire sera automatiquement ajoutée en tant que membre du groupe de basculement secondaire et actualisée avec les modifications de la base de données principale.
Pour plus de détails sur la création de groupes de basculement principaux et secondaires, voir Workflow.
Note
Lorsque vous ajoutez une base de données précédemment répliquée à un groupe de réplication ou de basculement, Snowflake ne réplique pas à nouveau les données qui ont déjà été répliquées pour cette base de données. Seules les modifications depuis la dernière actualisation sont répliquées lorsque le groupe est actualisé.
Workflow¶
Les instructions SQL suivantes démontrent le flux de travail pour activer la réplication des objets de compte et de base de données et pour actualiser les objets. Chaque étape est examinée en détail ci-dessous.
Note
Les exemples suivants exigent que la réplication soit activée pour les comptes source et cible. Pour plus de détails, voir Condition préalable : activer la réplication des comptes dans l’organisation.
Exemples¶
Exécutez les instructions SQL suivantes dans votre client Snowflake préféré pour activer la réplication et le basculement des objets de compte et de base de données, et actualiser les objets.
Exécuter à partir du compte source¶
Créez un rôle et accordez-lui le privilège CREATE FAILOVER GROUP. Cette étape est facultative :
USE ROLE ACCOUNTADMIN; CREATE ROLE myrole; GRANT CREATE FAILOVER GROUP ON ACCOUNT TO ROLE myrole;
Créez un groupe de basculement dans le compte source et activez la réplication vers des comptes cibles spécifiques.
Note
Si vous avez des bases de données à ajouter à un groupe de réplication ou de basculement qui ont été précédemment activées pour la réplication de base de données et le basculement à l’aide de ALTER DATABASE, suivez les instructions Transition de la réplication de base de données à la réplication par groupe (dans cette rubrique) avant de les ajouter à un groupe.
Pour ajouter une base de données à un groupe de basculement, le rôle actif doit avoir le privilège MONITOR sur la base de données. Pour plus de détails sur les privilèges de la base de données, voir Privilèges de base de données (dans une rubrique distincte).
USE ROLE myrole; CREATE FAILOVER GROUP myfg OBJECT_TYPES = USERS, ROLES, WAREHOUSES, RESOURCE MONITORS, DATABASES ALLOWED_DATABASES = db1, db2 ALLOWED_ACCOUNTS = myorg.myaccount2, myorg.myaccount3 REPLICATION_SCHEDULE = '10 MINUTE';
Exécuté sur le compte cible¶
Créez un rôle dans le compte cible et accordez-lui le privilège CREATE FAILOVER GROUP. Cette étape est facultative :
USE ROLE ACCOUNTADMIN; CREATE ROLE myrole; GRANT CREATE FAILOVER GROUP ON ACCOUNT TO ROLE myrole;
Créez un groupe de basculement dans le compte cible comme un réplica du groupe de basculement dans le compte source.
Note
S’il existe dans le compte cible des objets de compte (par exemple, des utilisateurs ou des rôles) qui n’existent pas dans le compte source, reportez-vous à Réplication initiale des utilisateurs et des rôles avant de créer un groupe secondaire.
USE ROLE myrole; CREATE FAILOVER GROUP myfg AS REPLICA OF myorg.myaccount1.myfg;
Actualisez manuellement le groupe de basculement secondaire. Il s’agit d’une étape facultative. Si le groupe de basculement primaire est créé avec un plan de réplication, le rafraîchissement initial du groupe de basculement secondaire est automatiquement exécuté lors de la création du groupe de basculement secondaire.
Créez un rôle avec le privilège REPLICATE sur le groupe de basculement. Cette étape est facultative.
Exécution dans le compte cible à l’aide d’un rôle doté du privilège OWNERSHIP sur le groupe de basculement :
GRANT REPLICATE ON FAILOVER GROUP myfg TO ROLE my_replication_role;
Exécutez l’instruction d’actualisation à l’aide d’un rôle doté du privilège REPLICATE :
USE ROLE my_replication_role; ALTER FAILOVER GROUP myfg REFRESH;
Créez un rôle avec le privilège FAILOVER sur le groupe de basculement. Cette étape est facultative.
Exécution dans le compte cible à l’aide d’un rôle doté du privilège OWNERSHIP sur le groupe de basculement :
GRANT FAILOVER ON FAILOVER GROUP myfg TO ROLE my_failover_role;;
Réplication d’objets de compte et de bases de données¶
Les instructions de cette section expliquent comment préparer vos comptes pour la réplication, activer la réplication d’objets spécifiques du compte source vers le compte cible, et synchroniser les objets dans le compte cible.
Important
Les comptes cibles n’ont pas Tri-Secret Secure ou une connectivité privée au service Snowflake, par exemple AWS PrivateLink, activé par défaut. Si vous avez besoin de Tri-Secret Secure ou d’une connectivité privée au service Snowflake à des fins de conformité, de sécurité ou à d’autres fins, il est de votre responsabilité de configurer et d’activer ces fonctionnalités dans le compte cible.
Condition préalable : activer la réplication des comptes dans l’organisation¶
L’administrateur de l’organisation doit activer la réplication pour les comptes source et cible.
Pour activer la réplication des comptes, un administrateur de l’organisation utilise la fonction SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER pour définir le paramètre ENABLE_ACCOUNT_DATABASE_REPLICATION sur true.
En tant qu’administrateur de l’organisation, activez la réplication pour chaque compte source et cible de votre organisation.
-- View the list of the accounts in your organization
-- Note the organization name and account name for each account for which you are enabling replication
SHOW ACCOUNTS;
-- Enable replication by executing this statement for each source and target account in your organization
SELECT SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER('<organization_name>.<account_name>', 'ENABLE_ACCOUNT_DATABASE_REPLICATION', 'true');
Bien que la fonction SYSTEM$GLOBAL_ACCOUNT_SET_PARAMETER prenne en charge l’ancien identificateur de localisateur de compte , elle donne des résultats inattendus lorsqu’une organisation possède plusieurs comptes qui partagent le même localisateur (dans différentes régions).
Étape 1 : Créer un rôle avec le privilège CREATE FAILOVER GROUP dans le compte source — Facultatif¶
Créez un rôle et accordez-lui le privilège CREATE FAILOVER GROUP. Cette étape est facultative. Si vous avez déjà créé ce rôle, passez à Étape 3 : Création d’un groupe de basculement principal dans un compte source.
USE ROLE ACCOUNTADMIN;
CREATE ROLE myrole;
GRANT CREATE FAILOVER GROUP ON ACCOUNT
TO ROLE myrole;
Étape 2 : Identification des comptes autorisés pour la réplication et l’appartenance à un groupe¶
Avant de créer un groupe de basculement primaire, identifiez les comptes activés pour la réplication et les groupes de basculement et de réplication existants.
Voir tous les comptes pour lesquels la réplication est activée¶
Pour récupérer la liste des comptes de votre organisation pour lesquels la réplication est activée, utilisez SHOW REPLICATION ACCOUNTS.
Exécutez l’instruction SQL suivante en utilisant le rôle ACCOUNTADMIN :
SHOW REPLICATION ACCOUNTS;
Renvoie :
+------------------+-------------------------------+--------------+-----------------+-----------------+-------------------+--------------+
| snowflake_region | created_on | account_name | account_locator | comment | organization_name | is_org_admin |
+------------------+-------------------------------+--------------+-----------------+-----------------+-------------------+--------------+
| AWS_US_WEST_2 | 2020-07-15 21:59:25.455 -0800 | myaccount1 | myacctlocator1 | | myorg | true |
+------------------+-------------------------------+--------------+-----------------+-----------------+-------------------+--------------+
| AWS_US_EAST_1 | 2020-07-23 14:12:23.573 -0800 | myaccount2 | myacctlocator2 | | myorg | false |
+------------------+-------------------------------+--------------+-----------------+-----------------+-------------------+--------------+
| AWS_US_EAST_2 | 2020-07-25 19:25:04.412 -0800 | myaccount3 | myacctlocator3 | | myorg | false |
+------------------+-------------------------------+--------------+-----------------+-----------------+-------------------+--------------+
Voir la liste complète des IDs de région.
Afficher l’appartenance à un groupe de basculement et de réplication¶
Les objets de compte, de base de données et de partage ont des contraintes sur l’appartenance à un groupe. Avant de créer de nouveaux groupes ou d’ajouter des objets aux groupes existants, vous pouvez consulter la liste des groupes de basculement existants et les objets de chaque groupe.
Note
Seuls un administrateur de compte (utilisateur avec le rôle ACCOUNTADMIN) ou le propriétaire du groupe (rôle avec le privilège OWNERSHIP sur le groupe) peuvent exécuter les instructions SQL de cette section.
Voir tous les groupes de basculement liés au compte actuel et les types d’objets dans chaque groupe :
SHOW FAILOVER GROUPS;
Voir toutes les bases de données du groupe de basculement myfg :
SHOW DATABASES IN FAILOVER GROUP myfg;
Voir tous les partages du groupe de basculement myfg :
SHOW SHARES IN FAILOVER GROUP myfg;
Étape 3 : Création d’un groupe de basculement principal dans un compte source¶
Créez un groupe de basculement principal et activez la réplication et le basculement d’objets spécifiques du compte actuel (source) vers un ou plusieurs comptes cibles dans la même organisation.
Vous pouvez créer un groupe de réplication ou de basculement en utilisant Snowsight ou SQL.
Note
Si vous avez des bases de données à ajouter à un groupe de réplication ou de basculement pour lesquelles la réplication de base de données est activée à l’aide de ALTER DATABASE, suivez les instructions Transition de la réplication de base de données à la réplication par groupe (dans cette rubrique) avant de les ajouter à un groupe.
Créer un groupe de réplication ou de basculement à l’aide de Snowsight¶
Note
Seuls les administrateurs de comptes peuvent créer un groupe de réplication ou de basculement à l’aide de Snowsight (reportez-vous à Limites de l’utilisation de Snowsight pour la configuration de la réplication).
Vous devez être connecté au compte cible en tant qu’utilisateur ayant le rôle ACCOUNTADMIN. Si ce n’est pas le cas, vous serez invité à vous connecter.
Le compte source et le compte cible doivent tous les deux utiliser le même type de connexion (Internet public). Sinon, la connexion au compte cible échoue.
Effectuez les étapes suivantes pour créer un nouveau groupe de réplication ou de basculement :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Admin » Accounts.
Sélectionnez Replication, puis effectuez l’une des actions suivantes dans l’onglet Groups :
Pour les comptes Business Critical Edition (ou version supérieure), effectuez l’une des actions suivantes :
S’il n’existe aucun groupe de réplication ni aucune connexion, sélectionnez Get started pour configurer un groupe de réplication et une connexion. L’assistant Setup business continuity s’affiche.
Sélectionnez + Group pour configurer un groupe de réplication sans configurer de connexion. L’assistant Create a group s’affiche.
Pour les comptes Standard Edition et Enterprise Edition, effectuez l’une des actions suivantes :
S’il n’y a pas de groupes de réplication ou de connexions, sélectionnez Get started pour configurer un groupe de réplication. L’assistant Setup replication s’affiche.
Si un ou plusieurs groupes de réplication existent, sélectionnez + Group pour configurer un groupe de réplication. L’assistant Create a group s’affiche.
Sur la page Select a target account, sélectionnez un compte cible et connectez-vous, puis sélectionnez Next.
Sur la page Create a group, dans la case Group name, saisissez un nom pour le groupe qui réponde aux exigences suivantes :
Il doit commencer par un caractère alphabétique et ne peut contenir d’espaces ou de caractères spéciaux, sauf si la chaîne de l’identificateur est placée entre guillemets doubles (par exemple, « Mon objet »). Les identificateurs entre guillemets doubles sont également sensibles à la casse.
Pour plus d’informations, voir Exigences relatives à l’identificateur.
Doit être unique pour tous les groupes de basculement et de réplication d’un compte.
Choisissez Edit objects pour ajouter des objets de partage et de compte à votre groupe.
Note
Des objets de compte ne peuvent être ajoutés qu’à un seul groupe de réplication ou de basculement. Si un groupe de réplication ou de basculement comportant des objets de compte existe déjà dans votre compte, vous ne pouvez pas sélectionner ces objets.
Choisissez Select databases pour ajouter des objets de base de données à votre groupe.
Sélectionnez Replication frequency.
Si le compte est de type Business Critical Edition ou supérieur, un groupe de basculement est créé par défaut. Vous pouvez choisir de créer un groupe de réplication à la place. Pour créer un groupe de réplication, sélectionnez Advanced options, puis désélectionnez Enable failover.
Effectuez l’une des actions suivantes :
Pour les comptes Business Critical Edition (ou supérieurs), sélectionnez Next.
Pour les comptes Standard Edition et Enterprise Edition, sélectionnez Start replication pour créer le groupe de réplication.
Pour les comptes Business Critical Edition (ou supérieurs), sur la page Create connection, saisissez un nom de connexion dans la case Connection name, puis sélectionnez Start replication.
Si la création du groupe de réplication échoue, reportez-vous à Résoudre les problèmes liés à la création et à la modification des groupes de réplication à l’aide de Snowsight pour connaître les erreurs les plus courantes et savoir comment les résoudre.
Créez un groupe de basculement à l’aide de SQL¶
Créez un groupe de basculement d’objets de compte et de base de données spécifiés dans le compte source et activez la réplication et le basculement vers une liste de comptes cibles. Pour plus d’informations sur la syntaxe, voir CREATE FAILOVER GROUP.
Par exemple, activez la réplication d’utilisateurs, de rôles, d’entrepôts, de moniteurs de ressources et de bases de données db1 et db2 du compte source vers le compte myaccount2 dans la même organisation. Définissez la planification de réplication pour actualiser automatiquement myaccount2 toutes les 10 minutes.
Exécutez l’instruction suivante sur le compte source :
USE ROLE myrole;
CREATE FAILOVER GROUP myfg
OBJECT_TYPES = USERS, ROLES, WAREHOUSES, RESOURCE MONITORS, DATABASES, INTEGRATIONS, NETWORK POLICIES
ALLOWED_DATABASES = db1, db2
ALLOWED_INTEGRATION_TYPES = API INTEGRATIONS
ALLOWED_ACCOUNTS = myorg.myaccount2
REPLICATION_SCHEDULE = '10 MINUTE';
Étape 4 : Création d’un rôle avec le privilège CREATE FAILOVER GROUP dans le compte cible — Facultatif¶
Créez un rôle dans le compte cible et accordez-lui le privilège CREATE FAILOVER GROUP. Cette étape est facultative. Si vous avez déjà créé ce rôle, passez à Étape 5 : Création d’un groupe de basculement secondaire dans le compte cible.
USE ROLE ACCOUNTADMIN;
CREATE ROLE myrole;
GRANT CREATE FAILOVER GROUP ON ACCOUNT
TO ROLE myrole;
Étape 5 : Création d’un groupe de basculement secondaire dans le compte cible¶
Note
S’il existe dans le compte cible des objets de compte (par exemple, des utilisateurs ou des rôles) qui n’existent pas dans le compte source, reportez-vous à Réplication initiale des utilisateurs et des rôles avant de créer un groupe secondaire.
Créez un groupe de basculement secondaire dans le compte cible en tant que réplica du groupe de basculement principal dans le compte source.
Exécutez une instruction CREATE FAILOVER GROUP … AS REPLICA OF dans chaque compte cible pour lequel vous avez activé la réplication dans Étape 3 : Création d’un groupe de basculement principal dans un compte source (dans cette rubrique).
Exécution à partir de chaque compte cible :
USE ROLE myrole;
CREATE FAILOVER GROUP myfg
AS REPLICA OF myorg.myaccount1.myfg;
Étape 6. Rafraîchissez manuellement un groupe de basculement secondaire dans le compte cible — Facultatif¶
Pour actualiser manuellement les objets d’un compte cible, exécutez la commande ALTER FAILOVER GROUP … REFRESH.
Nous vous recommandons de planifier vos actualisations secondaires en définissant le paramètre REPLICATION_SCHEDULE à l’aide de CREATE FAILOVER GROUP ou ALTER FAILOVER GROUP.
Note
Si l’utilisateur qui appelle la fonction dans le compte cible a été détruit dans le compte source, l’opération d’actualisation échoue.
Accorder le privilège REPLICATE sur le groupe de basculement au rôle — Facultatif¶
Pour exécuter la commande d’actualisation d’un groupe de réplication ou de basculement secondaire dans le compte cible, vous devez utiliser un rôle doté du privilège REPLICATE sur le groupe de basculement. Le privilège REPLICATE est actuellement non répliqué et doit être accordé à un groupe de basculement (ou de réplication) dans les comptes source et cible.
Exécution de cette instruction à partir du compte source en utilisant un rôle doté du privilège OWNERSHIP sur le groupe :
GRANT REPLICATE ON FAILOVER GROUP myfg TO ROLE my_replication_role;Exécution de cette instruction à partir du compte cible en utilisant un rôle doté du privilège OWNERSHIP sur le groupe :
GRANT REPLICATE ON FAILOVER GROUP myfg TO ROLE my_replication_role;
Actualiser manuellement un groupe de basculement secondaire¶
Par exemple, pour actualiser les objets du groupe de basculement myfg, exécutez l’instruction suivante à partir du compte cible :
USE ROLE my_replication_role; ALTER FAILOVER GROUP myfg REFRESH;
Étape 7. Grant le privilège FAILOVER sur le groupe de basculement au rôle — Facultatif¶
Pour exécuter la commande de basculement d’un groupe de basculement secondaire dans un compte cible, vous devez utiliser un rôle doté du privilège FAILOVER sur le groupe de basculement. Le privilège FAILOVER est n’est actuellement pas répliqué et doit être accordé dans chaque compte source et cible.
Pour plus d’informations, voir Réplication de rôles et d’accords de privilèges.
Par exemple, pour accorder le privilège FAILOVER au rôle my_failover_role sur le groupe de basculement my_fg, exécutez l’instruction suivante dans le compte cible à l’aide d’un rôle doté du privilège OWNERSHIP sur le groupe :
GRANT FAILOVER ON FAILOVER GROUP myfg TO ROLE my_failover_role;
Pour obtenir des instructions sur la création d’un rôle personnalisé avec un ensemble spécifique de privilèges, voir Création de rôles personnalisés.
Pour des informations générales sur les rôles et les privilèges accordés pour effectuer des actions SQL sur des objets sécurisables, voir Aperçu du contrôle d’accès.
Réplication au niveau du schéma pour les groupes de basculement¶
Pour les bases de données des groupes de basculement, vous pouvez éventuellement configurer le paramètre REPLICABLE_WITH_FAILOVER_GROUPS sur la base de données et/ou les schémas individuels de la base de données afin de spécifier un sous-ensemble de schémas pour la réplication.
Cette fonction vous permet de contrôler les schémas d’un groupe de basculement qui sont répliqués, ce qui est utile si seul un sous-ensemble de données d’une base de données a besoin de la protection supplémentaire contre les sinistres offerte par le basculement.
Ce paramètre étant activé par défaut pour toutes les bases de données et les schémas qu’elles contiennent, vous pouvez ajuster la granularité de la réplication en choisissant les bases de données et/ou les schémas à exclure de la réplication. Vous pouvez affiner les paramètres de réplication en autorisant la réplication de certains schémas, même si la base de données qui les contient n’est pas répliquée.
Spécifiez les schémas à répliquer ou à ignorer¶
Vous pouvez spécifier explicitement les schémas à répliquer ou à ignorer dans une base de données d’un groupe de basculement à l’aide du paramètre facultatif REPLICABLE_WITH_FAILOVER_GROUPS.
paramètre REPLICABLE_WITH_FAILOVER_GROUPS¶
Le paramètre REPLICABLE_WITH_FAILOVER_GROUPS indique si un schéma appartenant à une base de données d’un groupe de basculement est répliqué. Ce paramètre peut être ensemble pour une base de données et tous les schémas de la base de données. Si le paramètre est défini pour une base de données, tous les schémas de la base de données héritent de la valeur, à moins qu’une valeur différente ne soit explicitement définie pour un schéma donné.
Le paramètre accepte deux valeurs, 'YES' ou 'NO' (sans tenir compte de la casse), et est facultatif :
Si le paramètre REPLICABLE_WITH_FAILOVER_GROUPS n’est pas explicitement défini pour une base de données (ou s’il est explicitement désactivé), la base de données suit le comportement de réplication standard, ce qui équivaut à définir le paramètre sur
'YES'.Si REPLICABLE_WITH_FAILOVER_GROUPS n’est pas explicitement défini pour un schéma (ou explicitement désactivé), le comportement de réplication est hérité de la base de données parentale.
ALTER DATABASE <name> SET REPLICABLE_WITH_FAILOVER_GROUPS = { 'YES' | 'NO' }
ALTER DATABASE <name> UNSET REPLICABLE_WITH_FAILOVER_GROUPS
ALTER SCHEMA <name> SET REPLICABLE_WITH_FAILOVER_GROUPS = { 'YES' | 'NO' }
ALTER SCHEMA <name> UNSET REPLICABLE_WITH_FAILOVER_GROUPS
Exigences en matière de sécurité¶
Pour définir ou désactiver ce paramètre sur une base de données ou un schéma, les privilèges suivants sont requis :
REPLICATE (privilèges au niveau du compte). Avant la fonction de réplication au niveau du schéma, ce privilège était uniquement un privilège de niveau objet sur les groupes de réplication et les groupes de basculement. Les utilisateurs ayant le rôle ACCOUNTADMIN peuvent accorder ce privilège à d’autres rôles.
USAGE (privilège de la base de données et du schema) ou tout autre privilège similaire permettant d’effectuer des actions sur la base de données et le schéma.
Exemples¶
Grant des privilèges nécessaires sur un rôle préexistant, replicationadmin :
USE ROLE ACCOUNTADMIN;
GRANT REPLICATE ON ACCOUNT TO ROLE replicationadmin;
GRANT USAGE ON DATABASE db1 TO ROLE replicationadmin;
GRANT USAGE ON SCHEMA db1.sch1 TO ROLE replicationadmin;
Ne répliquez qu’un seul schéma, sch1, dans la base de données db1 :
USE ROLE replicationadmin;
ALTER DATABASE db1 SET REPLICABLE_WITH_FAILOVER_GROUPS = 'NO';
ALTER SCHEMA sch1 SET REPLICABLE_WITH_FAILOVER_GROUPS = 'YES';
Répliquez tous les schémas à l’exception d’un schéma, sch2, dans la base de données db2 :
USE ROLE replicationadmin;
ALTER DATABASE db2 SET REPLICABLE_WITH_FAILOVER_GROUPS = 'YES';
ALTER SCHEMA sch2 SET REPLICABLE_WITH_FAILOVER_GROUPS = 'NO';
Actualisation des schémas avec l’ensemble REPLICABLE_WITH_FAILOVER_GROUPS dans les comptes cibles¶
Lors d’une actualisation de la base de données :
Les schémas avec REPLICABLE_WITH_FAILOVER_GROUPS défini sur
'YES'sont répliqués du compte source vers le compte cible.Les schémas avec REPLICABLE_WITH_FAILOVER_GROUPS défini sur
'NO'ne sont pas répliqués, sauf dans les deux paramètres suivants :Le schéma cible est une réplique du schéma de compte source. Dans ce casse-tête, le schéma cible est toujours synchronisé avec son schéma source.
Le schéma cible présente un conflit de nom avec le schéma de compte source. Dans ce cas, la tâche de réplication échoue en raison du conflit de noms.
Liste des bases de données et des schémas dont l’ensemble est REPLICABLE_WITH_FAILOVER_GROUPS dans votre compte¶
Vous pouvez dresser la liste des valeurs définies pour le paramètre REPLICABLE_WITH_FAILOVER_GROUPS dans le compte courant en interrogeant les vues ACCOUNT_USAGE et INFORMATION_SCHEMA.
Astuce
Si vous ne savez pas pourquoi vous pouvez utiliser les vues ACCOUNT_USAGE ou INFORMATION_SCHEMA, consultez Différences entre Account Usage et Information Schema.
Exemples¶
Pour ces exemples, nous utiliserons les vues INFORMATION_SCHEMA. De cette façon, vous pouvez voir les paramètres immédiatement après avoir effectué des modifications.
À l’aide du rôle préexistant replicationadmin, renvoyez toutes les valeurs des paramètres du compte, qui possède deux bases de données :
Base de données
db1explicitement paramétrée surNOet schémasch1dans la base de données explicitement paramétré surYES. Seul ce schéma de la base de données peut faire l’objet d’une réplication.Base de données
db2explicitement paramétrée surYESet schémasch2dans la base de données explicitement paramétré surNO. Tous les schémas de la base de données peuvent faire l’objet d’une réplication, à l’exception de ce seul schéma.
USE ROLE replicationadmin;
SELECT database_name, replicable_with_failover_groups
FROM db1.INFORMATION_SCHEMA.DATABASES;
+---------------+---------------------------------+
| DATABASE_NAME | REPLICABLE_WITH_FAILOVER_GROUPS |
+---------------+---------------------------------+
| DB1 | NO |
| DB2 | YES |
| DB3 | UNSET |
+---------------+---------------------------------+
SELECT schema_name, catalog_name, replicable_with_failover_groups
FROM db1.INFORMATION_SCHEMA.SCHEMATA ORDER BY catalog_name;
+--------------------+--------------+---------------------------------+
| SCHEMA_NAME | CATALOG_NAME | REPLICABLE_WITH_FAILOVER_GROUPS |
+--------------------+--------------+---------------------------------+
| PUBLIC | DB1 | NO |
| SCH1 | DB1 | YES |
| SCH2 | DB1 | NO |
| SCH3 | DB1 | NO |
| INFORMATION_SCHEMA | DB1 | UNSET |
+--------------------+--------------+---------------------------------+
USE ROLE replicationadmin;
SELECT schema_name, catalog_name, replicable_with_failover_groups
FROM db2.INFORMATION_SCHEMA.SCHEMATA
ORDER BY catalog_name;
+--------------------+--------------+---------------------------------+
| SCHEMA_NAME | CATALOG_NAME | REPLICABLE_WITH_FAILOVER_GROUPS |
+--------------------+--------------+---------------------------------+
| PUBLIC | DB2 | YES |
| SCH1 | DB2 | YES |
| SCH2 | DB2 | NO |
| SCH3 | DB2 | YES |
| INFORMATION_SCHEMA | DB2 | UNSET |
+--------------------+--------------+---------------------------------+
Appliquer des IDs globaux à des objets créés par des scripts dans des comptes cibles¶
Si vous avez créé des objets de compte, par exemple des utilisateurs et des rôles, dans votre compte cible par un moyen autre que via la réplication (par exemple, à l’aide de scripts), ces utilisateurs et ces rôles n’ont pas d’identificateur global par défaut. L’opération d’actualisation utilise des identificateurs globaux pour synchroniser ces objets avec les mêmes objets dans le compte source.
Dans la plupart des cas, lorsqu’un compte cible est actualisé à partir du compte source, l’opération d’actualisation détruit tous les objets de compte des types de la liste OBJECT_TYPES du compte cible qui n’ont pas d’identificateur global. La réplication initiale des utilisateurs et des rôles vers un compte cible peut toutefois entraîner l’échec de la première opération d’actualisation. Pour plus de détails sur ce comportement, reportez-vous à Réplication initiale des utilisateurs et des rôles.
Utiliser SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME() pour appliquer des IDs globaux¶
Vous pouvez éviter la perte de certains types d’objets en liant les objets correspondants portant le même nom dans les comptes source et cible. La fonction SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME ajoute un identificateur global aux objets du compte cible.
Note
Les identificateurs globaux ne sont ajoutés qu’aux objets de compte qui sont inclus dans un groupe de réplication ou de basculement pour les types d’objets suivants :
RESOURCE_MONITORROLEUSERWAREHOUSE
Appliquer des identificateurs globaux aux objets du compte cible des types inclus dans la liste object_types pour le groupe de basculement myfg :
Exécutez l’instruction SQL suivante en utilisant le rôle ACCOUNTADMIN :
SELECT SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME('myfg');
Réplication initiale des utilisateurs et des rôles¶
Le comportement de l’opération d’actualisation initiale pour les types d’objets USERS et ROLES peut varier selon qu’il existe ou non des objets correspondants portant le même nom dans le compte cible.
Note
Le comportement décrit dans cette section ne s’applique que la première fois que ces types d’objets sont répliqués sur le compte cible.
Les scénarios ci-dessous décrivent la réplication de USERS. Il en va de même pour la réplication de ROLES.
S’il existe dans le compte cible des utilisateurs portant le même nom que des utilisateurs du compte source, l’opération d’actualisation initiale échoue et décrit les deux options à votre disposition pour continuer :
Forcer l’opération d’actualisation et permettre la suppression de tout utilisateur existant dans le compte cible. Les utilisateurs du compte source seront répliqués dans le compte cible.
Pour forcer l’actualisation d’un groupe, utilisez le paramètre FORCE de la commande refresh. Par exemple, pour forcer l’actualisation d’un groupe de basculement, exécutez la commande suivante :
ALTER FAILOVER GROUP <fg_name> REFRESH FORCE;
Lier les objets du compte par leur nom. La fonction SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME relie les utilisateurs portant le même nom dans le compte cible et le compte source. Les utilisateurs du compte cible qui sont liés ne sont pas supprimés.
Pour lier les comptes par leur nom, exécutez la commande suivante :
SELECT SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME('<rg_name>');
Note
Tout utilisateur dans le compte cible qui n’a pas d’utilisateur correspondant dans le compte source avec le même nom est supprimé.
S’il n’y a aucun utilisateur dans le compte cible dont les noms correspondent à ceux des utilisateurs du compte source, l’opération d’actualisation initiale dans le compte cible supprime tous les utilisateurs. Cela peut entraîner les pertes de données et de métadonnées suivantes :
Si des USERS sont inclus dans la liste OBJECT_TYPES pour un groupe de réplication ou de basculement :
Les feuilles de calcul sont perdues.
L’historique des requêtes est perdu.
Si des USERS sont inclus dans la liste OBJECT_TYPES, mais pas de ROLES :
Les privilèges accordés aux utilisateurs sont perdus.
Si des ROLES sont inclus dans la liste OBJECT_TYPES :
Les privilèges accordés pour partager des objets sont perdus.
Pour éviter de supprimer des utilisateurs ou des rôles dans le compte cible :
Dans le compte source, recréez manuellement les utilisateurs ou les rôles qui n’existent que dans le compte cible avant la réplication initiale.
Dans le compte cible, reliez les objets correspondants portant le même nom dans les deux comptes à l’aide de la fonction SYSTEM$LINK_ACCOUNT_OBJECTS_BY_NAME.
Configurer l’accès au stockage Cloud pour les intégrations de stockage secondaire¶
Si vous activez la réplication de l’intégration de stockage, vous devez prendre des mesures supplémentaires après la réplication de l’intégration de stockage sur les comptes cibles. L’intégration répliquée possède sa propre entité de gestion des identités et des accès (IAM) qui est différente de l’identité et de l’entité IAM de l’intégration principale. Par conséquent, vous devez mettre à jour les autorisations de votre fournisseur Cloud afin d’accorder à l’intégration répliquée l’accès à votre stockage sur le Cloud.
Vous ne devez configurer cette relation de confiance sur les comptes cibles qu’une seule fois.
Le processus est similaire à l’attribution d’un accès au compte source. Pour plus d’informations, consultez les pages suivantes :
Configuration de l’actualisation automatique des tables de répertoire dans les zones de préparation secondaires¶
Si vous répliquez une zone de préparation externe avec une table de répertoire et que vous avez configuré l’actualisation automatique pour la table de répertoire source, vous devez prendre des mesures pour configurer l’actualisation automatique de la table de répertoire secondaire.
La procédure est similaire à la mise en place de l’actualisation automatique dans votre compte source. Pour plus d’informations, voir ce qui suit :
Amazon S3 : le processus de configuration dépend de la manière dont vous avez configuré les notifications d’événements.
Si vous utilisez les notifications d’événement Amazon S3 avec Amazon Simple Queue Service (SQS), suivez les instructions dans Étape 2 : Configuration de notifications d’événement. Vous pouvez également migrer de SQS vers SNS. Pour plus d’informations, voir Migration vers Amazon Simple Notification Service (SNS).
Si vous utilisez Amazon Simple Notification Service (SNS), consultez Abonnement à la file d’attente Snowflake SQS à votre sujet SNS.
Google Cloud Storage : créez un nouvel abonnement à votre sujet Pub/Sub et une nouvelle intégration de notification dans votre compte cible. Ensuite, accordez un accès à Snowflake à l’abonnement Pub/Sub Pour obtenir des instructions, voir Configure automation using GCS Pub/Sub.
Azure Blob Storage : créez un nouvel abonnement Event Grid et une nouvelle file d’attente de stockage. Ensuite, créez une nouvelle intégration de notification dans le compte cible et accordez à Snowflake l’accès à votre file d’attente de stockage. Pour obtenir des instructions, voir Configuration de l’automatisation avec Azure Event Grid.
Important
Après avoir effectué ces étapes de configuration dans votre compte cible, vous devez procéder à une actualisation complète de votre table de répertoire afin de vous assurer qu’aucune notification n’a été omise.
Pour Google Cloud Storage et Azure Blob Storage, le nom de l’intégration de notification dans chaque compte cible doit correspondre au nom de l’intégration de notification dans le compte source.
Configurer les notifications pour les canaux secondaires d’intégration automatique¶
Vous devez prendre des mesures supplémentaires pour configurer les notifications Cloud pour les canaux d’intégration automatique secondaires avant le basculement. Cette section explique pourquoi cette configuration supplémentaire est nécessaire et comment la compléter pour chaque fournisseur Cloud pris en charge.
Amazon S3¶
Le processus de configuration dépend de la manière dont vous avez configuré les notifications d’événements. Par exemple, supposons que vous ayez un canal d’intégration automatique qui s’appuie sur un sujet Amazon Simple Notification Service (SNS) pour publier des messages sur l’emplacement de la zone de préparation Snowflake.
Lorsque vous répliquez le canal vers un compte cible, Snowflake crée automatiquement une nouvelle file d’attente Amazon Simple Queue Service (SQS). Vous devez abonner cette file d’attente SQS pour votre compte cible au sujet SNS pour recevoir des notifications sur l’emplacement de la zone de préparation.
Si vous utilisez les notifications d’événement Amazon S3 avec Amazon Simple Queue Service (SQS), suivez les instructions dans Étape 4 : Configuration des notifications d’événement.
Important
Pour s’assurer que le canal n’a manqué aucune notification, il convient d’actualiser le canal après avoir effectué un basculement vers la nouvelle file d’attente SQS.
Vous pouvez également migrer de SQS vers SNS. Pour plus d’informations, voir Migration vers Amazon Simple Notification Service (SNS).
Si vous utilisez Amazon Simple Notification Service (SNS), consultez Abonnement à la file d’attente Snowflake SQS à votre sujet SNS.
Si vous utilisez Amazon EventBridge, consultez Option 3 : Configuration d’Amazon EventBridge pour automatiser Snowpipe.
Stockage d’objets blob Microsoft Azure¶
Un canal qui charge automatiquement des données à partir de fichiers situés sur une zone de préparation dans le stockage blob de Microsoft Azure nécessite un abonnement Event Grid, une file d’attente de stockage et une intégration de notification liée à la file d’attente de stockage. Un canal secondaire dans un compte cible nécessite un Event Grid distinct, une file d’attente de stockage et une intégration de notification liée à la file d’attente de stockage. Event Grid des comptes source et cible doit être configuré en tant que points de terminaison pour la même source Azure Storage.
Voir le diagramme ci-dessous pour les détails de la configuration :
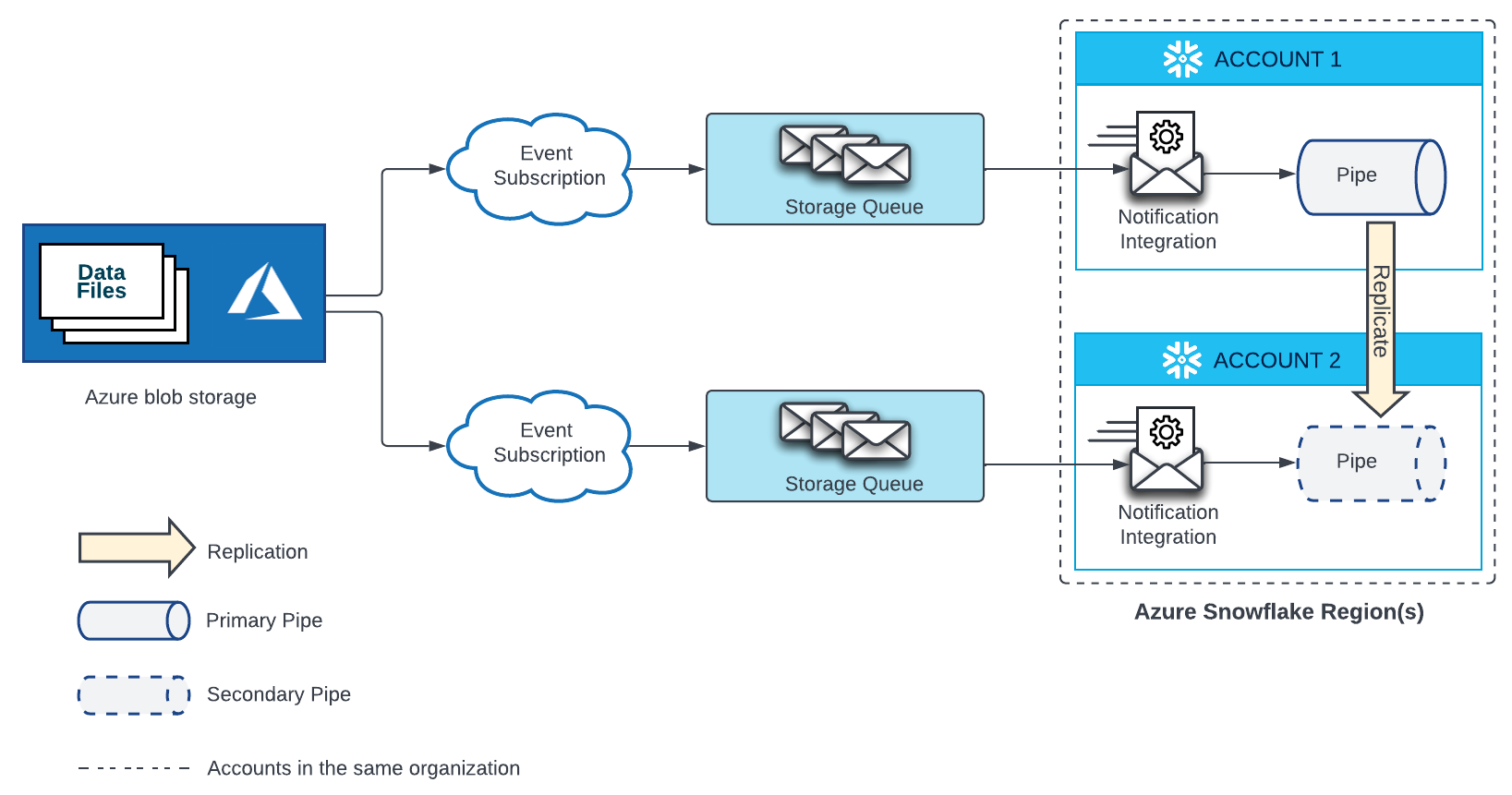
Créez un nouvel abonnement Event Grid et une nouvelle file d’attente de stockage. Ensuite, créez une nouvelle intégration de notification dans le compte cible et accordez à Snowflake l’accès à votre file d’attente de stockage. Pour obtenir des instructions, voir Configuration de l’automatisation avec Azure Event Grid.
Important
Le nom de l’intégration de notification dans chaque compte cible doit correspondre au nom de l’intégration de notification dans le compte source.
Zone de préparation externe pour Google Cloud Storage¶
Un canal qui charge automatiquement des données à partir de fichiers situés dans Google Cloud Storage nécessite un abonnement Google Pub/Sub et une intégration de notification qui fait référence à cet abonnement. Chaque canal répliqué dans un compte cible nécessite également un abonnement Google Pub/Sub et une intégration de notification qui fait référence à cet abonnement. L’abonnement Pub/Sub de chaque compte source et cible doit être souscrit au même sujet Pub/Sub qui reçoit les notifications de la source Google Cloud Storage.
Voir le diagramme ci-dessous pour les détails de la configuration :
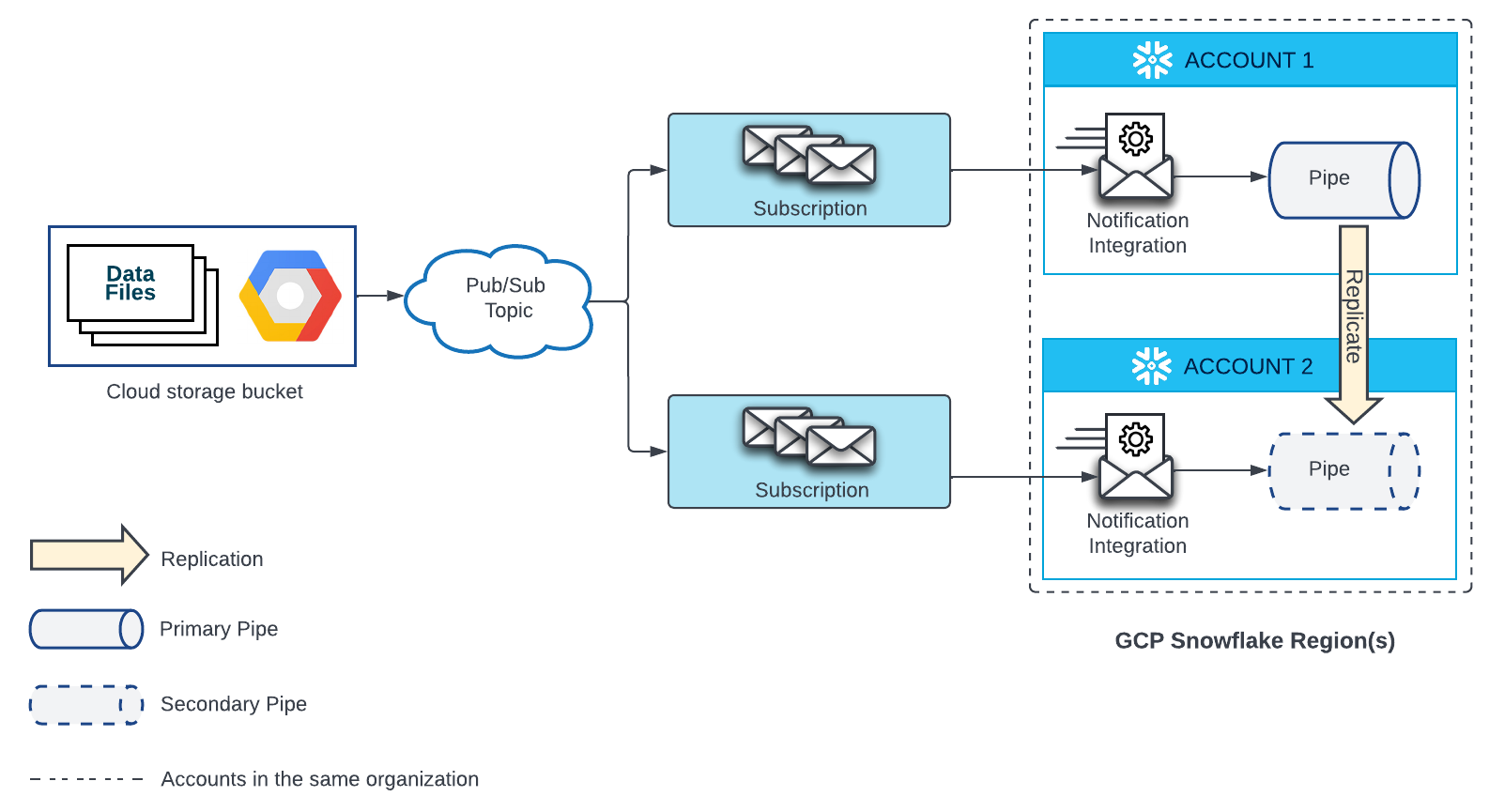
- Créez un nouvel abonnement à votre rubrique Pub/Sub et une nouvelle intégration de notification dans votre compte cible.
Ensuite, accordez un accès à Snowflake à l’abonnement Pub/Sub Pour obtenir des instructions, voir Configuration de l’automatisation à l’aide de Pub/Sub GCS.
Important
Le nom de l’intégration de notification dans chaque compte cible doit correspondre au nom de l’intégration de notification dans le compte source.
Mise à jour du service distant pour les intégrations API¶
Si vous avez activé la réplication de l’intégration API, des étapes supplémentaires sont nécessaires après la réplication de l’intégration API sur le compte cible. L’intégration répliquée possède sa propre entité de gestion des identités et des accès (IAM) qui sont différents de l’identité et de l’entité IAM de l’intégration principale. Par conséquent, vous devez mettre à jour les autorisations sur le service distant pour accorder l’accès à des fonctions répliquées. Le processus est similaire à l’octroi d’accès à des fonctions sur le compte principal. Voir les liens ci-dessous pour plus de détails :
Amazon Web Services Configurer la ou les relation(s) de confiance entre Snowflake et le nouveau rôle IAM.
Google Cloud Platform : créez une politique de sécurité GCP pour le service proxy.
Microsoft Azure :
Comparaison des ensembles de données dans les bases de données principales et secondaires¶
Snowflake effectue des contrôles de vérification automatiques dans le cadre de chaque opération d’actualisation de la réplication. En cas d’échec de la vérification, l’actualisation échoue. Par conséquent, vous n’avez pas besoin de vérifier manuellement les données répliquées. Si vous avez besoin d’une vérification supplémentaire pour des raisons de conformité, vous pouvez effectuer des étapes de vérification manuelle après la fin de l’opération d’actualisation.
Vérification automatique par Snowflake¶
Snowflake effectue actuellement les contrôles suivants entre le compte principal et le compte secondaire après chaque opération d’actualisation :
Snowflake compare les valeurs de hachage entre le compte principal et le compte secondaire pour tous les fichiers qui ont été répliqués.
Pour chaque table, Snowflake compare les valeurs suivantes entre le compte principal et le compte secondaire :
Nombre de fichiers.
Nombre de lignes.
Nombre d’octets.
Vérification manuelle¶
Si les objets de la base de données sont répliqués dans un groupe de réplication ou de basculement, vous pouvez utiliser la fonction HASH_AGG pour comparer les lignes de certaines tables ou de toutes les tables dans une base de données primaire et secondaire afin de vérifier la cohérence des données. La fonction HASH_AGG renvoie une valeur de hachage globale signée de 64 bits sur l’ensemble des lignes d’entrée. La valeur de hachage est la même quel que soit l’ordre des lignes d’entrée.
Interrogez cette fonction sur toutes les tables, ou sur un sous-ensemble aléatoire de tables, dans le compte secondaire comme dans le compte principal. Sur le compte principal, utilisez une clause AT | BEFORE pour spécifier le moment de la dernière actualisation de la base de données associée. Comparez la sortie entre les requêtes sur les deux comptes.
Exemple de vérification manuelle des données après une actualisation¶
Dans les exemples suivants, la base de données mydb est incluse dans le groupe de basculement myfg. La base de données mydb contient la table myschema.mytable.
Commandes à exécuter sur le compte cible¶
Interrogez la fonction de table REPLICATION_GROUP_REFRESH_PROGRESS (dans Schéma d’information de Snowflake). Notez le
primarySnapshotTimestampdans la colonneDETAILSpour la phasePRIMARY_UPLOADING_METADATA. Il s’agit de l’horodatage de la dernière actualisation de cette base de données sur le compte principal.SELECT PARSE_JSON(details)['primarySnapshotTimestamp'] FROM TABLE(information_schema.replication_group_refresh_progress('myfg')) WHERE PHASE_NAME = 'PRIMARY_UPLOADING_METADATA';
Interrogez la fonction HASH_AGG pour une table spécifiée dans le compte secondaire. La requête suivante renvoie une valeur de hachage pour toutes les lignes de la table
myschema.mytable:SELECT HASH_AGG( * ) FROM mydb.myschema.mytable;
Commandes à exécuter sur le compte source¶
Interrogez la fonction HASH_AGG pour la même table dans le compte principal. À l’aide de Time Travel, spécifiez l’horodatage de la dernière actualisation effectuée pour la base de données secondaire :
SELECT HASH_AGG( * ) FROM mydb.myschema.mytable AT(TIMESTAMP => '<primarySnapshotTimestamp>'::TIMESTAMP);
Comparez les résultats des deux requêtes. La sortie doit être identique.
Modification d’un groupe de basculement ou de réplication dans un compte source¶
Vous pouvez modifier le nom, les objets inclus et la planification de la réplication d’un groupe de basculement ou de réplication dans un compte source en utilisant l”Snowsight ou SQL.
Note
Les groupes de réplication ne peuvent pas être transformés en groupes de basculement et vice versa. Pour activer ou désactiver le basculement, supprimez le groupe et recréez-le avec le paramètre de basculement correct.
Modifier un groupe de basculement ou de réplication dans un compte source à l’aide de Snowsight¶
Note
Seuls les administrateurs de comptes peuvent modifier un groupe de réplication ou de basculement à l’aide de Snowsight (reportez-vous à Limites de l’utilisation de Snowsight pour la configuration de la réplication).
Pour effectuer ces actions, vous devez être connecté au compte source. Si vous n’êtes pas connecté, la colonne Status affiche un message de connexion au lieu du statut d’actualisation.
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Admin » Accounts.
Sélectionnez Replication, puis sélectionnez Groups.
Localisez le groupe de basculement ou de réplication que vous souhaitez modifier et sélectionnez le menu More (…) dans la dernière colonne de la ligne.
Sélectionnez Edit.
Pour modifier le nom du groupe, entrez un nouveau nom dans la boîte Group name qui répond aux exigences suivantes :
Il doit commencer par un caractère alphabétique et ne peut contenir d’espaces ou de caractères spéciaux, sauf si la chaîne de l’identificateur est placée entre guillemets doubles (par exemple, « Mon objet »). Les identificateurs entre guillemets doubles sont également sensibles à la casse.
Pour plus d’informations, voir Exigences relatives à l’identificateur.
Les identificateurs des groupes de basculement et des groupes de réplication d’un compte doivent être uniques.
Choisissez Edit objects pour ajouter ou supprimer des objets de partage et de compte.
Note
Des objets de compte ne peuvent être ajoutés qu’à un seul groupe de réplication ou de basculement. Si un groupe de réplication ou un groupe de basculement contenant des objets de compte existe déjà dans votre compte, vous ne pouvez pas sélectionner ces objets.
Choisissez Select databases pour ajouter ou supprimer des objets de base de données.
Sélectionnez l’adresse Replication frequency pour modifier le calendrier de réplication d’un groupe.
Sélectionnez Save pour mettre à jour le groupe.
Si l’enregistrement des modifications apportées au groupe échoue, reportez-vous à la page Résoudre les problèmes liés à la création et à la modification des groupes de réplication à l’aide de Snowsight pour connaître les erreurs les plus courantes et savoir comment les résoudre.
Modifier un groupe de basculement ou de réplication dans un compte source à l’aide de la fonction SQL¶
Vous pouvez modifier les propriétés d’un groupe de réplication ou de basculement à l’aide de la commande ALTER REPLICATION GROUP ou ALTER FAILOVER GROUP.
Mettre en pause ou reprendre une planification de réplication dans un compte cible¶
Vous pouvez mettre en pause (suspendre) ou reprendre une planification de réplication dans un compte cible à l’aide de l”Snowsight ou SQL.
Interrompre ou reprendre une planification de réplication dans un compte cible à l’aide de Snowsight¶
Note
Seuls les administrateurs de comptes peuvent modifier un groupe de réplication ou de basculement à l’aide de Snowsight (reportez-vous à Limites de l’utilisation de Snowsight pour la configuration de la réplication).
Pour interrompre ou reprendre une planification de réplication, vous devez être connecté au compte cible.
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Admin » Accounts.
Sélectionnez Replication, puis sélectionnez Groups.
Localisez le groupe de basculement ou de réplication que vous souhaitez modifier et sélectionnez le menu More (…) dans la dernière colonne de la ligne.
Sélectionnez Pause ou Resume.
Interrompre ou reprendre une planification de réplication dans un compte cible à l’aide de la fonction SQL¶
Vous pouvez interrompre ou reprendre une planification de réplication dans un compte cible à l’aide de la commande ALTER REPLICATION GROUP ou ALTER FAILOVER GROUP. Pour faire une pause, spécifiez le paramètre SUSPEND. Pour reprendre, spécifiez le paramètre RESUME.
Suppression d’un groupe de réplication ou de basculement secondaire¶
Vous pouvez détruire une réplication secondaire ou un basculement en utilisant la commande DROP REPLICATION GROUP ou DROP FAILOVER GROUP. Seul le propriétaire du groupe de basculement ou de réplication (c’est-à-dire le rôle disposant du privilège OWNERSHIP sur le groupe) peut supprimer le groupe.
Pour supprimer un groupe de réplication ou de basculement secondaire à l’aide de Snowsight, vous devez supprimer le groupe dans le compte source. Voir Supprimer un groupe de réplication ou de basculement à l’aide de Snowsight.
Suppression d’un groupe de réplication ou de basculement principal¶
Vous pouvez abandonner un groupe de réplication ou de basculement primaire en utilisant Snowsight ou SQL. Si vous supprimez un groupe primaire à l’aide de SQL, vous devez d’abord supprimer tous les groupes secondaires. Voir Suppression d’un groupe de réplication ou de basculement secondaire.
Supprimer un groupe de réplication ou de basculement principal à l’aide de SQL¶
Un groupe de basculement ou de réplication primaire ne peut être abandonné que lorsque toutes les répliques du groupe (c’est-à-dire les groupes de basculement ou de réplication secondaires) ont été abandonnées. Vous pouvez également promouvoir un groupe de basculement secondaire pour qu’il serve de groupe de basculement principal, puis supprimer l’ancien groupe de basculement principal.
Notez que seul le propriétaire du groupe peut détruire le groupe.
Supprimer un groupe de réplication ou de basculement à l’aide de Snowsight¶
Note
Seuls les administrateurs de comptes peuvent supprimer un groupe de réplication ou de basculement à l’aide de Snowsight (reportez-vous à Limites de l’utilisation de Snowsight pour la configuration de la réplication).
Vous pouvez supprimer un groupe de réplication ou de basculement primaire et tous les groupes secondaires liés.
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Admin » Accounts.
Sélectionnez Replication, puis Groups.
Localisez le groupe de réplication ou de basculement que vous souhaitez supprimer. Sélectionnez le menu More (…) dans la dernière colonne de la ligne.
Sélectionnez Drop, puis sélectionnez Drop group.
Résoudre les problèmes liés à la création et à la modification des groupes de réplication à l’aide de Snowsight¶
Les scénarios suivants peuvent vous aider à résoudre les problèmes qui peuvent survenir lors de la création ou de la modification d’un groupe de réplication ou de basculement à l’aide de Snowsight.
Vous ne pouvez pas ajouter une base de données à un groupe¶
Erreur |
Database '<database_name>' is already configured to replicate to
account '<account_name>' by replication group '<group_name>'.
|
|---|---|
Cause |
Une base de données ne peut être ajoutée qu’à un seul groupe de réplication ou de basculement. L’une des bases de données que vous avez sélectionnées pour le groupe est déjà incluse dans un autre groupe de réplication ou de basculement. |
Solution |
Choisissez Select Databases et désélectionnez toute(s) base(s) de données déjà incluse(s) dans un autre groupe. |
Erreur |
Cannot directly add previously replicated object '<database_name>' to a
replication group. Please use the provided system functions to convert
this object first.
|
|---|---|
Cause |
La base de données que vous souhaitez ajouter à un groupe de réplication ou de basculement a été précédemment configurée pour la réplication de bases de données. |
Solution |
Désactivez la réplication de la base de données. Voir Transition de la réplication de base de données à la réplication par groupe. |
Limites de l’utilisation de Snowsight pour la configuration de la réplication¶
Seul un utilisateur ayant le rôle ACCOUNTADMIN peut créer un groupe de réplication ou de basculement à l’aide de Snowsight. Un utilisateur ayant un rôle avec le privilège CREATE REPLICATION GROUP ou CREATE FAILOVER GROUP peut créer un groupe à l’aide des commandes SQL respectives.
Seul un utilisateur ayant le rôle ACCOUNTADMIN peut modifier ou supprimer un groupe de réplication ou de basculement à l’aide de Snowsight. Un utilisateur ayant un rôle avec le privilège OWNERSHIP sur un groupe de réplication ou de basculement peut modifier et supprimer des groupes à l’aide des commandes SQL correspondantes.
Si votre compte utilise la connectivité privée, vous ne pouvez pas utiliser Snowsight pour créer, modifier ou supprimer des groupes. Vous pouvez utiliser SQL pour réaliser ces actions.