Snowpark Migration Accelerator: DBC 파일 분해¶
Databricks 워크로드를 마이그레이션하기 전에 두 단계를 완료해야 합니다.
분해 프로세스를 사용하여 .dbc 파일에서 소스 코드를 분해합니다.
SnowConvert AI를 사용하여 추출된 소스 코드 마이그레이션
To run the explode process, you need Python installed on your computer. We recommend using Python 3.7.
분해 스크립트 실행¶
Run dbcexplode.py and provide the path to your .dbc file as a command-line argument.

이 스크립트는 dbcexplode.py 스크립트와 동일한 디렉터리에 폴더를 생성합니다. 새 폴더의 이름은 DBC 파일 이름 뒤에 .dbc-exploded 가 옵니다.
이 폴더에는 .dbc 파일에 있는 각 노트북에 대한 별도의 폴더가 들어 있습니다. 이 예제에서 .dbc 파일에는 SanFranciscoFireCallsAnalysis (1).python 이라는 이름의 단일 노트북이 포함되어 있습니다.
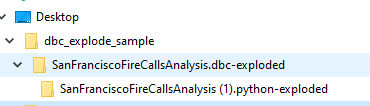
이 폴더 안에는 처리된 노트북의 각 명령어에 대한 별도의 파일이 있습니다. 각 파일은 명명 패턴 <notebook_name>-<sequence_number> 를 따릅니다. <sequence_number> 는 노트북에 명령이 표시되는 순서를 나타냅니다. 예를 들어, SanFranciscoFireCallsAnalysis (1)-001.md 는 노트북에 있는 첫 번째 명령을 나타냅니다.
참고: 노트북 코드 셀에 매직 문자열이 포함되어 있으면 스크립트에서 확장자가 .magic인 파일을 생성합니다.


