Snowpark Migration Accelerator: Explosão de arquivos DBC¶
Antes de migrar as cargas de trabalho do Databricks, você precisa concluir duas etapas:
Extraia o código-fonte de seus arquivos .dbc usando o processo explode
Use o SnowConvert AI para migrar o código-fonte extraído.
To run the explode process, you need Python installed on your computer. We recommend using Python 3.7.
Execute o script explode¶
Run dbcexplode.py and provide the path to your .dbc file as a command-line argument.

O script cria uma pasta no mesmo diretório que o script dbcexplode.py. O nome da nova pasta será o nome do arquivo DBC seguido de .dbc-exploded.
Essa pasta conterá uma pasta separada para cada notebook encontrado no arquivo .dbc. Neste exemplo, o arquivo .dbc contém um único notebook chamado SanFranciscoFireCallsAnalysis (1).python.
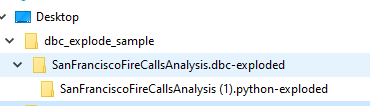
Dentro dessa pasta, você encontrará arquivos separados para cada comando do notebook processado. Cada arquivo segue o padrão de nomenclatura <nome_notebook>-<sequence_number>. O <sequence_number> representa a ordem em que os comandos aparecem no notebook. Por exemplo, SanFranciscoFireCallsAnalysis (1)-001.md representa o primeiro comando encontrado no notebook.
Observação: Se uma célula de código do notebook contiver uma cadeia de cadeia de caracteres mágica, o script gerará um arquivo com extensão .magic.


