Snowpark Migration Accelerator: DBC ファイルの展開¶
Databricksワークロードを移行する前に、2つのステップを完了する必要があります。
展開プロセスを使って.dbcファイルからソースコードを抽出します。
SnowConvert AI を使用して、抽出したソースコードを移行する
To run the explode process, you need Python installed on your computer. We recommend using Python 3.7.
展開スクリプトを実行する¶
Run dbcexplode.py and provide the path to your .dbc file as a command-line argument.

このスクリプトは dbcexplode.py スクリプトと同じディレクトリにフォルダーを作成します。新しいフォルダーの名前は、 DBC ファイルの名前の後に、 .dbc-exploded を付けたものになります。
このフォルダーには、.dbcファイルで見つかったノートブックごとに別々のフォルダーが含まれます。この例では、.dbcファイルには SanFranciscoFireCallsAnalysis (1).python という1つのノートブックが含まれています。
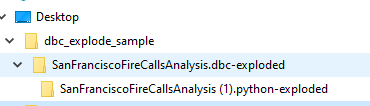
このフォルダーの中には、処理されたノートブックのコマンドごとに別々のファイルがあります。各ファイルは、 <notebook_name>-<sequence_number> という命名パターンに従っています。<sequence_number> は、コマンドがノートブックに出現する順番を表します。たとえば、 SanFranciscoFireCallsAnalysis (1)-001.md はノートブックで最初に見つかったコマンドを表します。
メモ: ノートブックコードのセルにmagic文字列が含まれている場合、スクリプトは拡張子.magicのファイルを生成します。


