Snowpark Migration Accelerator: DBC-Dateien explodieren¶
Bevor Sie Databricks-Workloads migrieren, müssen Sie zwei Schritte durchführen:
Extrahieren Sie den Quellcode aus Ihren .dbc-Dateien mit Hilfe des Explode-Prozesses
Verwenden Sie SnowConvert AI, um den extrahierten Quellcode zu migrieren
To run the explode process, you need Python installed on your computer. We recommend using Python 3.7.
Explode-Skript ausführen¶
Run dbcexplode.py and provide the path to your .dbc file as a command-line argument.

Das Skript erstellt einen Ordner in demselben Verzeichnis wie das dbcexplode.py-Skript. Der Name des neuen Ordners ist der Name Ihrer DBC-Datei, gefolgt von .dbc-exploded.
Dieser Ordner enthält einen separaten Ordner für jedes in der .dbc-Datei gefundene Notebook. In diesem Beispiel enthält die .dbc-Datei ein einzelnes Notebook namens SanFranciscoFireCallsAnalysis (1).python.
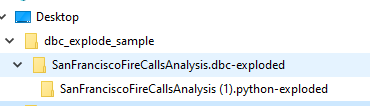
In diesem Ordner finden Sie separate Dateien für jeden Befehl aus dem verarbeiteten Notebook. Jede Datei folgt dem Benennungsmuster <notebook_name>-<sequence_number>. Die <sequence_number> gibt die Reihenfolge an, in der die Befehle im Notebook angezeigt werden. Zum Beispiel steht SanFranciscoFireCallsAnalysis (1)-001.md für den ersten im Notebook gefundenen Befehl.
Hinweis: Wenn eine Zelle des Notebook-Codes eine magic-Zeichenfolge enthält, erstellt das Skript eine Datei mit der Erweiterung .magic.


