Snowpark Migration Accelerator : Script explode des fichiers DBC¶
Avant de migrer les charges de travail Databricks, vous devez effectuer deux étapes :
Extraire le code source de vos fichiers .dbc à l’aide du processus explode
Utiliser l’AI SnowConvert pour migrer le code source extrait
To run the explode process, you need Python installed on your computer. We recommend using Python 3.7.
Exécuter le script explode¶
Run dbcexplode.py and provide the path to your .dbc file as a command-line argument.

Le script crée un dossier dans le même répertoire que le script dbcexplode.py. Le nom du nouveau dossier sera le nom de votre fichier DBC, suivi de . dbc-exploded.
Ce dossier contiendra un dossier distinct pour chaque notebook trouvé dans le fichier .dbc. Dans cet exemple, le fichier .dbc contient un seul notebook nommé SanFranciscoFireCallsAnalysis (1).python.
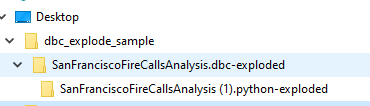
Dans ce dossier, vous trouverez des fichiers distincts pour chaque commande du notebook traité. Chaque fichier suit le modèle de dénomination <notebook_name>-<sequence_number>. Le <sequence_number> représente l’ordre dans lequel les commandes apparaissent dans le notebook. Par exemple, SanFranciscoFireCallsAnalysis (1)-001.md représente la première commande trouvée dans le notebook.
Remarque : Si une cellule de code du notebook contient une chaîne magique, le script génère un fichier avec une extension .magic.


