Snowpark Migration Accelerator: Considerações sobre o pré-processamento¶
Ao preparar o código-fonte para análise com o Snowpark Migration Accelerator (SMA), observe que a ferramenta só pode processar o código localizado no diretório de entrada. Antes de executar o SMA, certifique-se de que todos os arquivos de origem relevantes estejam colocados nesse diretório.
Tamanho¶
A ferramenta SMA analisa o código-fonte e os arquivos de texto, não os arquivos de dados. Ao fazer a varredura de grandes bases de código ou de vários arquivos, a ferramenta pode apresentar limitações de memória em seu computador local. Por exemplo, se você incluir o código exportado de todas as bibliotecas dependentes como arquivos de entrada, a análise levará muito mais tempo. Lembre-se de que o SMA só identificará referências de código específicas do Spark, independentemente da quantidade de código que você incluir na varredura.
Recomendamos coletar todos os arquivos de código que:
São executados regularmente como parte de um processo automatizado
Foram usados para criar o processo (se separado da execução regular)
São bibliotecas personalizadas desenvolvidas por sua organização que são referenciadas pelo processo ou por seus scripts de criação
Não é necessário incluir o código que cria bibliotecas de terceiros estabelecidas (como Pandas, Scikit-Learn ou outras). A ferramenta cataloga automaticamente essas referências sem exigir seu código de definição.
Deve funcionar¶
O Snowpark Migration Accelerator (SMA) requer um código-fonte completo e válido para funcionar corretamente. Ele não pode processar fragmentos de código incompletos ou trechos que não são executados independentemente em Scala ou Python. Se encontrar vários erros de análise ao executar o SMA, isso provavelmente significa que o código-fonte está incompleto ou contém erros de sintaxe. Para garantir uma análise bem-sucedida, certifique-se de que o diretório de entrada contenha apenas código funcional e sintaticamente correto da plataforma de origem.
Caso de uso¶
A compreensão do resultado do SMA vai além da própria ferramenta. Embora o SMA analise sua base de código, é importante entender seu caso de uso específico para identificar possíveis desafios de migração. Por exemplo, se você tiver um notebook que use SQL e um conector de banco de dados sem nenhuma referência ao Spark, o SMA informará apenas as bibliotecas de terceiros usadas nesse notebook. Essas informações são úteis, mas a ferramenta não fornecerá uma pontuação de preparação para esses arquivos. Ter o contexto do seu aplicativo ajuda a interpretar essas descobertas com mais eficiência.
Código de notebooks Databricks¶
Os Databricks Notebooks permitem que você escreva código em várias linguagens de programação (SQL, Scala e PySpark) no mesmo notebook. Quando você exporta um notebook, a extensão do arquivo corresponde à categoria da linguagem principal (.ipynb ou .py para notebooks Python, .sql para notebooks SQL). Qualquer código escrito em linguagem diferente da principal do notebook será automaticamente comentado durante a exportação. Por exemplo, se você escrever código SQL em um notebook Python, esse código SQL será comentado quando exportar o notebook.
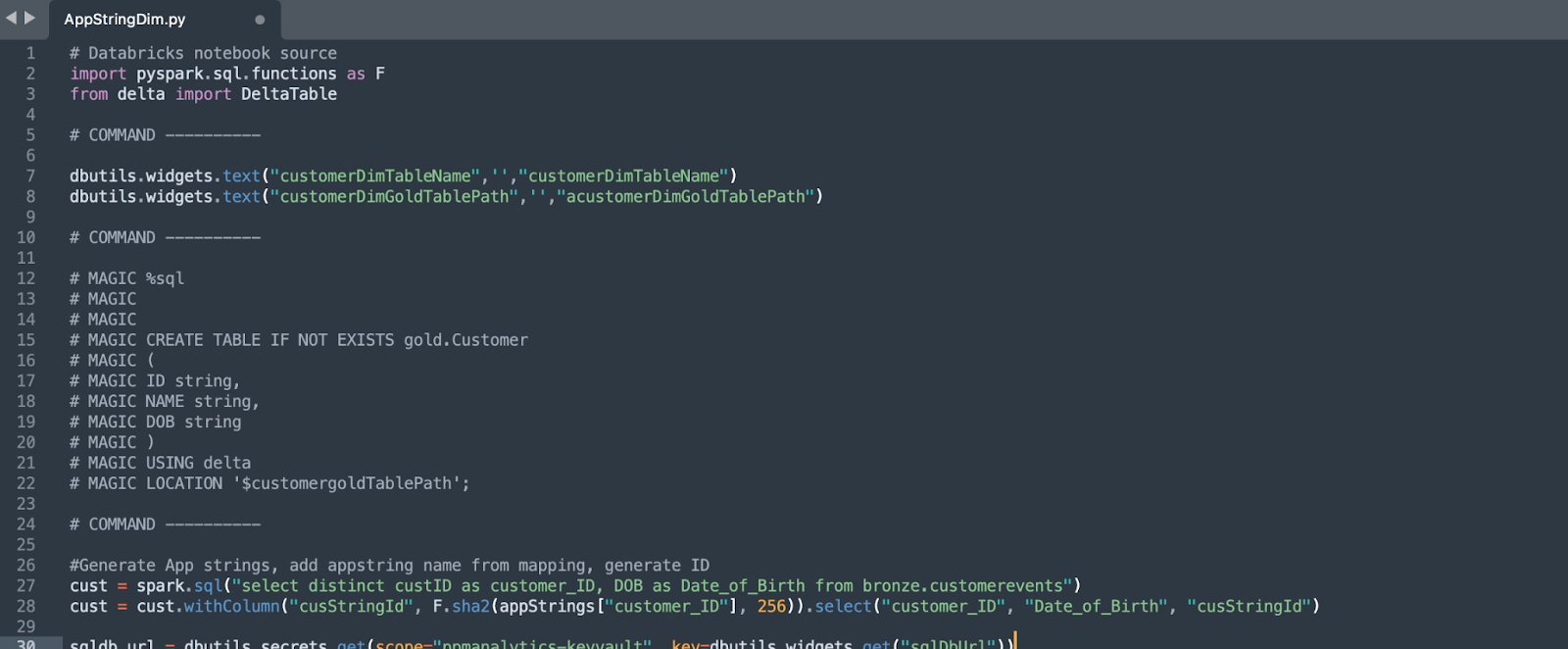
Os comentários que contêm código não são analisados pela ferramenta SMA. Se quiser que o código dentro dos comentários seja analisado, deve primeiro pré-processá-lo para expor o código em um formato de arquivo que a ferramenta possa reconhecer.
Ao trabalhar com notebooks, o SMA pode analisar e reconhecer códigos escritos em linguagens diferentes da extensão de arquivo do notebook. Por exemplo, se você tiver um código SQL em um notebook Jupyter (arquivo .ipynb), o SMA o detectará e processará mesmo que o código não esteja comentado.
Para arquivos que não sejam de notebook, certifique-se de que o código seja salvo com a extensão de arquivo correta que corresponda à linguagem de origem (por exemplo, salve o código Python com uma extensão .py). Isso garante que o código possa ser analisado adequadamente.