Snowpark Migration Accelerator : Considérations relatives au prétraitement¶
Lors de la préparation du code source pour l’analyse avec l’outil Snowpark Migration Accelerator (SMA), veuillez noter que l’outil ne peut traiter que le code situé dans le répertoire d’entrée. Avant d’exécuter SMA, assurez-vous que tous les fichiers source pertinents sont placés dans ce répertoire.
Taille¶
L’outil SMA analyse le code source et les fichiers texte, pas les fichiers de données. Lors de l’analyse de larges bases de code ou de nombreux fichiers, l’outil peut rencontrer des limites de mémoire sur votre machine locale. Par exemple, si vous incluez le code exporté de toutes les bibliothèques dépendantes comme fichiers d’entrée, l’analyse prendra beaucoup plus de temps. Gardez à l’esprit que SMA n’identifiera que les références de code spécifiques à Spark, quelle que soit la quantité de code que vous incluez dans l’analyse.
Nous vous recommandons de rassembler tous les fichiers de code qui :
Sont exécutés régulièrement dans le cadre d’un processus automatisé
Ont été utilisés pour créer le processus (s’ils sont distincts de l’exécution normale)
Sont des bibliothèques personnalisées développées par votre organisation qui sont référencées par le processus ou ses scripts de création
Vous n’avez pas besoin d’inclure le code qui crée des bibliothèques tierces établies (telles que Pandas, Scikit-Learn ou autres). L’outil répertorie automatiquement ces références sans avoir besoin de leur code de définition.
Cela devrait fonctionner.¶
L’outil Snowpark Migration Accelerator (SMA) exige un code source complet et valide pour fonctionner correctement. Il ne peut pas traiter des fragments de code incomplets ou des extraits qui ne s’exécutent pas indépendamment en Scala ou en Python. Si vous rencontrez de nombreuses erreurs d’analyse lors de l’exécution de SMA, cela signifie probablement que le code source est incomplet ou contient des erreurs de syntaxe. Pour garantir la réussite de l’analyse, assurez-vous que votre répertoire d’entrée ne contient que du code fonctionnel et syntaxiquement correct provenant de votre plateforme source.
Cas d’utilisation¶
La compréhension de la sortie de l’outil SMA va au-delà de l’outil lui-même. Alors que SMA analyse votre base de code, il est important de comprendre votre cas d’utilisation spécifique afin d’identifier les défis potentiels de la migration. Par exemple, si vous avez un notebook qui utilise SQL et un connecteur de base de données sans aucune référence à Spark, SMA ne signalera que les bibliothèques tierces utilisées dans ce notebook. Ces informations sont utiles, mais l’outil ne fournit pas de score de préparation pour ces fichiers. Le fait de connaître le contexte de votre application vous permet d’interpréter ces résultats de manière plus efficace.
Code issu des notebooks Databricks¶
Les notebooks Databricks vous permettent d’écrire du code dans plusieurs langages de programmation (SQL, Scala, et PySpark) dans le même notebook. Lorsque vous exportez un notebook, l’extension du fichier correspond à la catégorie de langage principal (.ipynb ou .py pour les notebooks Python, .sql pour les notebooks SQL). Tout code écrit dans un langage différent du langage principal du notebook sera automatiquement commenté lors de l’exportation. Par exemple, si vous écrivez du code SQL dans un notebook Python, ce code SQL sera commenté lorsque vous exporterez le notebook.
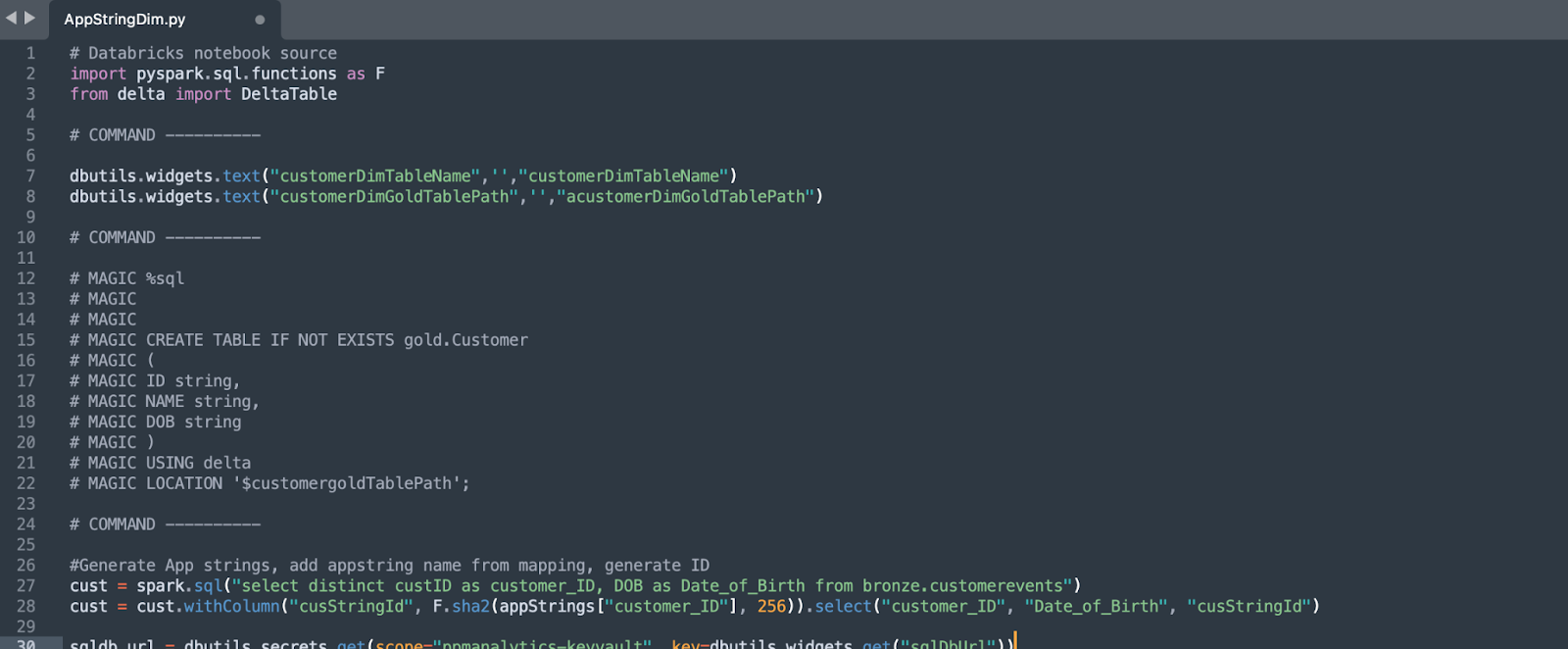
Les commentaires contenant du code ne sont pas analysés par l’outil SMA. Si vous souhaitez que le code contenu dans les commentaires soit analysé, vous devez d’abord le prétraiter afin de l’exposer dans un format de fichier que l’outil peut reconnaître.
Lorsque vous travaillez avec des notebooks, SMA peut analyser et reconnaître le code écrit dans des langages différents de l’extension de fichier du notebook. Par exemple, si vous avez du code SQL dans un notebook Jupyter (fichier .ipynb), SMA le détectera et le traitera même si le code n’est pas commenté.
Pour les fichiers autres que des fichiers notebooks, assurez-vous que votre code est enregistré avec l’extension de fichier correcte correspondant au langage source (par exemple, enregistrez le code Python avec une extension .py). Cela permet de s’assurer que le code peut être correctement analysé.