- description:
What do you need to know to get the most out of the tool?
Snowpark Migration Accelerator: Pre-Processing Considerations¶
When preparing source code for analysis with the Snowpark Migration Accelerator (SMA), please note that the tool can only process code located in the input directory. Before running SMA, ensure all relevant source files are placed in this directory.
Size¶
The SMA tool analyzes source code and text files, not data files. When scanning large codebases or numerous files, the tool may experience memory limitations on your local machine. For example, if you include exported code from all dependent libraries as input files, the analysis will take significantly longer. Keep in mind that SMA will only identify Spark-specific code references, regardless of how much code you include in the scan.
We recommend collecting all code files that:
- Are executed regularly as part of an automated process
- Were used to create the process (if separate from regular execution)
- Are custom libraries developed by your organization that are referenced by either the process or its creation scripts
You do not need to include code that creates established third-party libraries (such as Pandas, Scikit-Learn, or others). The tool automatically catalogs these references without requiring their defining code.
It should work¶
The Snowpark Migration Accelerator (SMA) requires complete and valid source code to function properly. It cannot process incomplete code fragments or snippets that don’t execute independently in Scala or Python. If you encounter numerous parsing errors while running SMA, it likely means the source code is incomplete or contains syntax errors. To ensure successful analysis, make sure your input directory contains only working, syntactically correct code from your source platform.
Use Case¶
Understanding the SMA output goes beyond the tool itself. While SMA analyzes your codebase, it’s important to understand your specific use case to identify potential migration challenges. For example, if you have a notebook that uses SQL and a database connector without any Spark references, SMA will only report the third-party libraries used in that notebook. This information is useful, but the tool won’t provide a readiness score for such files. Having context about your application helps you interpret these findings more effectively.
Code from Databricks Notebooks¶
Databricks notebooks allow you to write code in multiple programming languages (SQL, Scala, and PySpark) within the same notebook. When you export a notebook, the file extension will match the primary language category (.ipynb or .py for Python notebooks, .sql for SQL notebooks). Any code written in a different language than the notebook’s primary language will be automatically commented out during export. For example, if you write SQL code in a Python notebook, that SQL code will be commented out when you export the notebook.
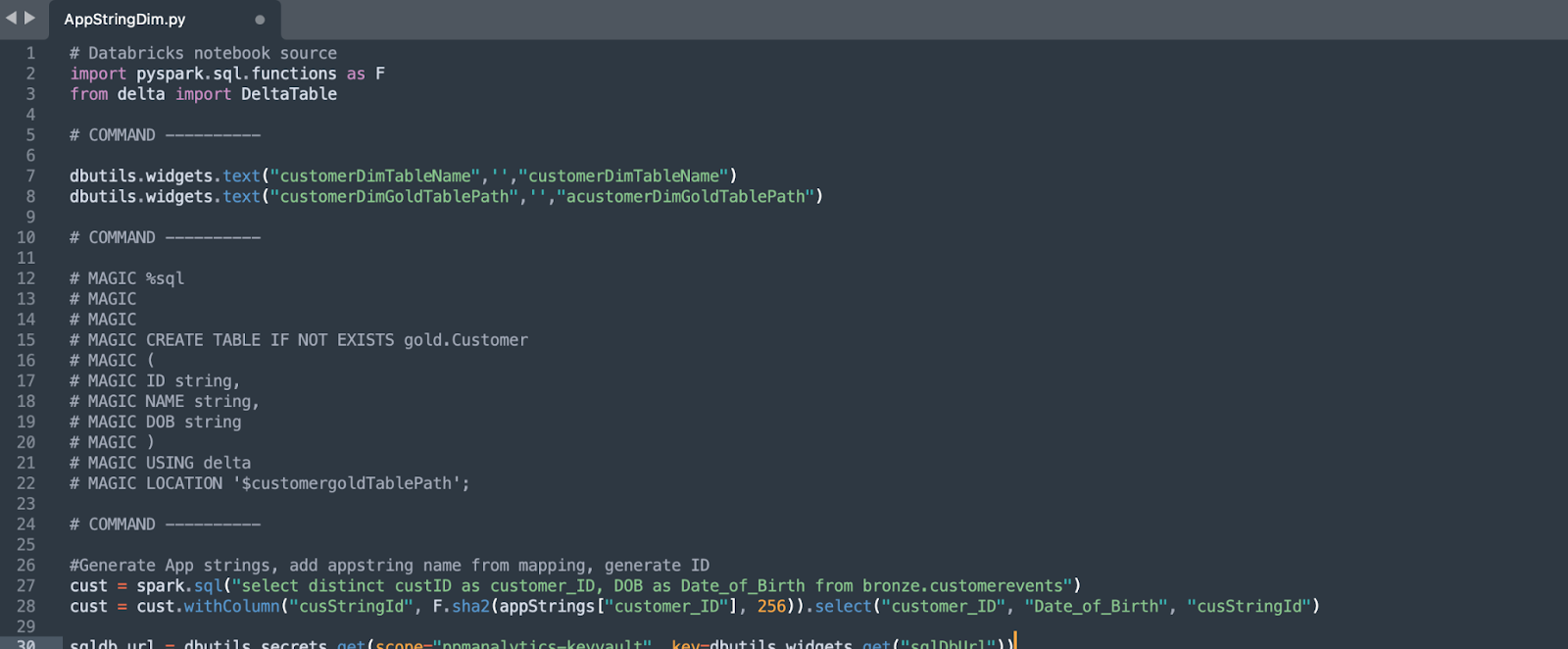
Comments containing code are not analyzed by the SMA tool. If you want the code within comments to be analyzed, you must first preprocess it to expose the code in a file format that the tool can recognize.
When working with notebooks, SMA can analyze and recognize code written in languages different from the notebook’s file extension. For example, if you have SQL code in a Jupyter notebook (.ipynb file), SMA will detect and process it even if the code is not commented.
For non-notebook files, make sure your code is saved with the correct file extension that matches the source language (for example, save Python code with a .py extension). This ensures the code can be properly analyzed.