About the Snowflake Connector for SharePoint¶
Note
The Snowflake Connector for SharePoint is subject to the Connector Terms.
Important
Thank you for your interest in the Snowflake Connector for SharePoint. We’re now focused on a next-generation solution that will offer a significantly improved experience; therefore, moving this connector to the general availability status is currently not on our product roadmap. You may continue to use this connector as a preview feature, but please note that support for future bug fixes and improvements is not guaranteed. The new solution is available as Openflow Connector for SharePoint and includes better performance, customizability, and enhanced deployment options.
This topic describes the basic concepts of Snowflake Connector for SharePoint, its use cases and benefits, key features, how it works, and limitations.
The Snowflake Connector for SharePoint connector connects a Microsoft 365 SharePoint site and Snowflake to ingest files and user permissions and keeps them up to date. Snowflake Connector for SharePoint also supports the Cortex Search service and can make ingested files ready for conversational analysis for use in AI Assistants using SQL, Python or REST APIs.
Benefits¶
Frictionless ingestion: The connector is easy to set up and configure. You can use files from SharePoint with Cortex Search in your chat interface of choice.
Secure by default: The connector adheres to end-user access controls in SharePoint through Cortex Search filters.
Scalable by design: Built on the Snowflake Native App framework, the connector leverages Snowflake’s built-in security, scalability and reliability capabilities.
Saves costs: The connector saves you cost by eliminating the need to manually transfer files or integrate against API endpoints or manage third-party solutions.
Use cases¶
Use this connector if you’re looking to do the following:
How it works¶
This section describes how this connector works with respect to the two use cases mentioned earlier.
Create AI assistants for public documents within your organization’s SharePoint site¶
Working with Snowflake Connector for SharePoint for this use case can be broadly divided into four phases, each associated with a specific user persona. The following workflow describes these phases, the associated user journey, and how this connector works:
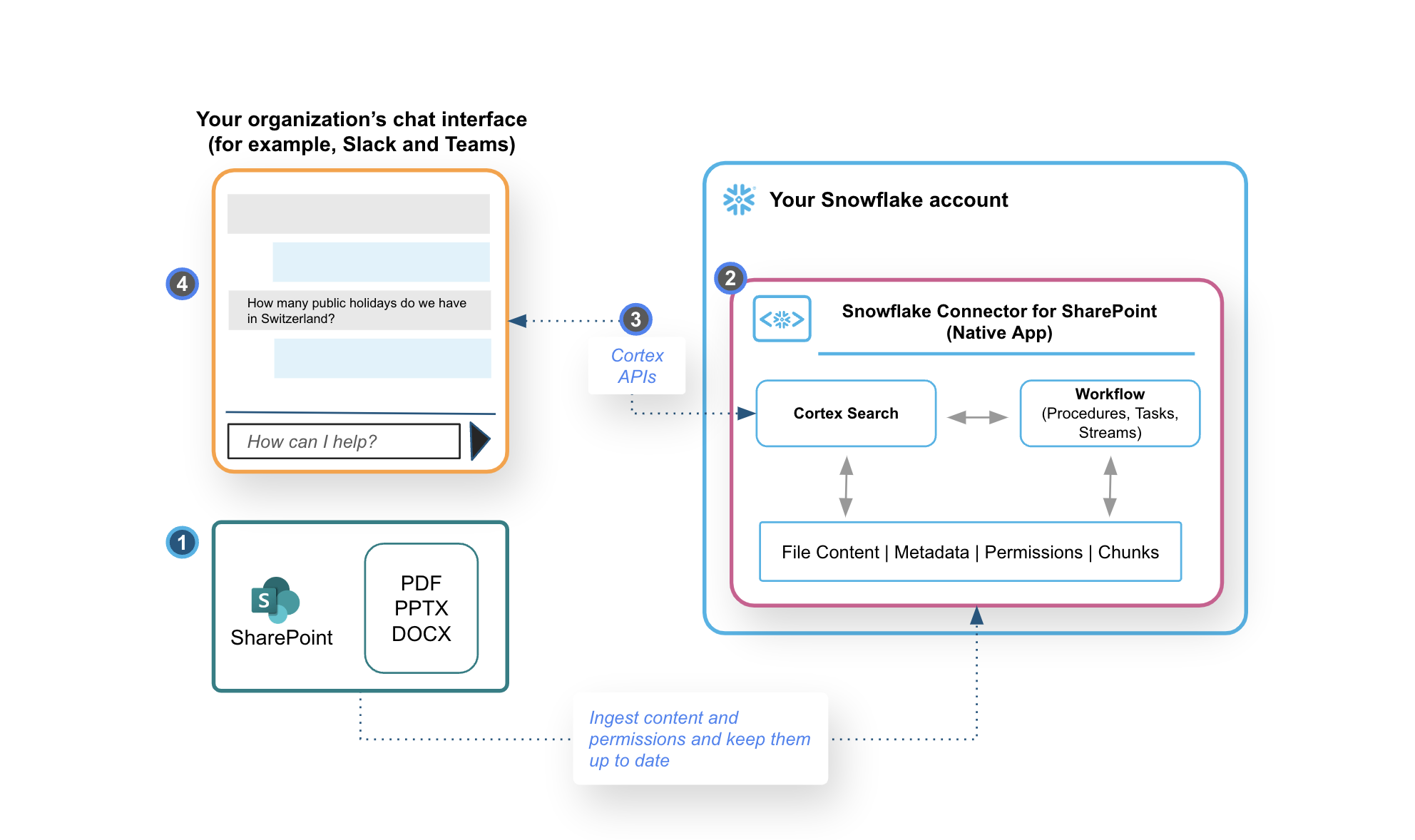
An Azure or Office 365 account administrator in your organization configures Microsoft Graph to enable OAuth authentication as described in Get access without a user. They then share the required credentials with the organization’s data engineer.
A data engineer or data scientist in your organization installs the SharePoint Connector for Snowflake from the Snowflake marketplace into their Snowflake account. They then configure the connector with the following information:
Specifying the SharePoint OAuth credentials (ClientID, Client Secret and TenantID) obtained from step 1.
Specifying the URL of their SharePoint site. Typically, this is a specific subsite within your SharePoint site.
Choosing whether to ingest files from all folders or a specific folder in the SharePoint URL. Note that the files from subfolders are always included.
After the connector validates the configuration, it does the following:
Ingests supported files and user permissions from the specified source.
Uses the PARSE_DOCUMENT function of Cortex AI to parse and chunk the ingested files.
Creates a Cortex Search service to serve as a RAG engine for your own AI assistants with your parsed and chunked data.
An IT developer in the organization creates a chatbot in their chat interface of choice, such as bot extensions in Slack, Teams or a web page, and hosts it as appropriate within their environment. The IT Developer configures roles, permissions and authentication in Snowflake to use the Cortex Search REST API endpoint available in the suite of Snowflake REST APIs.
After your AI assistant is up and running, business users in your organization can interact with it to ask questions and see responses based on the files ingested from your SharePoint site into your Snowflake account. All responses have citations that are links to the source documents from your SharePoint site.
Enable your AI assistants to adhere to access controls specified in your organization’s SharePoint site¶
Working with Snowflake Connector for SharePoint for this use case can be broadly divided into four phases, each associated with a specific user persona. The following workflow describes these phases, the associated user journey, and how this connector works:
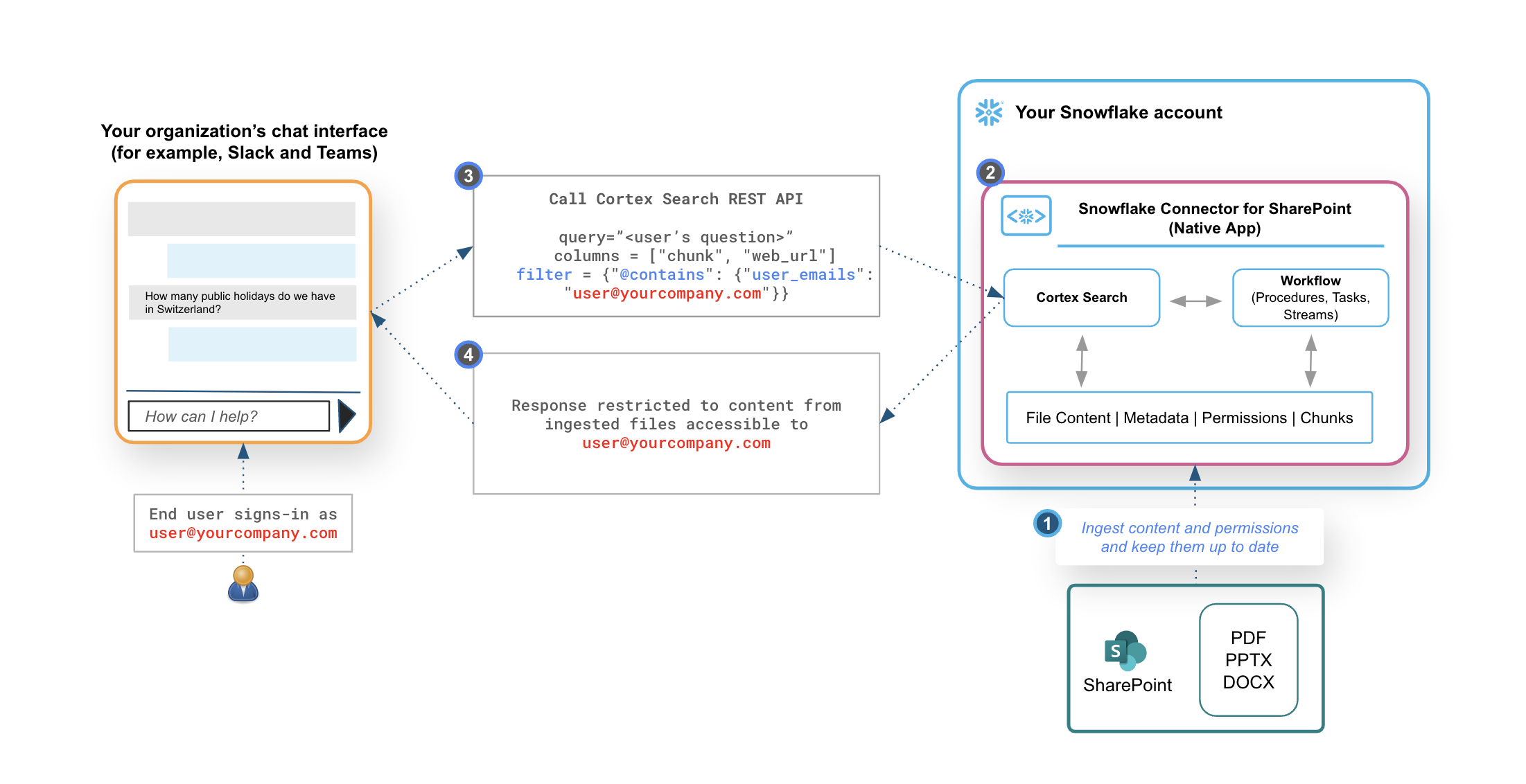
An Azure or Office 365 account administrator in your organization configures Microsoft Graph to enable OAuth authentication as described in Get access without a user. They then share the required credentials with the organization’s data engineer or data scientist.
A data engineer or data scientist in your organization installs the SharePoint Connector for Snowflake from the Snowflake marketplace into their Snowflake account. They then configure the connector by:
Specifying the SharePoint OAuth credentials (client ID, client secret and tenant ID) obtained in step 1.
Specifying the URL of their SharePoint site. Typically, this is a specific subsite within your SharePoint site.
Choosing whether to ingest files from all folders or a specific folder in the SharePoint URL. Note that the files from subfolders are always included.
After the connector validates the configuration, it does the following:
Ingests supported files and user permissions from the specified source.
Uses the PARSE_DOCUMENT function of Cortex AI to parse and chunk the ingested files.
Creates a Cortex Search service to serve as a RAG engine for your own AI assistants with your parsed and chunked data.
An IT developer in the organization creates a chatbot in their chat interface of choice, such as bot extensions in Slack, Teams or a web page, and hosts it as appropriate within their environment.
They configure roles, permissions, and authentication in Snowflake to use the Cortex Search REST API endpoint available in the suite of Snowflake REST APIs.
They specify a filter containing the email ID of the SharePoint user when the AI assistant queries the Cortex Search REST API, for example
filter.@contains.user_idsorfilter.@contains.user_emails. This restricts responses from Cortex Search to documents that the specified business user has access to in your organization’s SharePoint.
After your AI assistant is up and running, when business users in your organization interact with it to ask questions, they will only see information from files in your SharePoint thay have access to because of the filter specified in Step 3(b). All responses have citations that are links to the source documents from your SharePoint site.
Limitations¶
Changes caused by moving or renaming folders aren’t captured during incremental ingestion.
The connector supports only Microsoft 365 groups.
The connector ingests only the supported file types and ignores others.
Regional availability¶
The Snowflake Connector for SharePoint depends on Cortex Parse document and Cortex Search.
The Snowflake Connector for SharePoint is currently available in the regions listed in Cortex Parse Document regional availability.