Cortex AI Function Studio¶
Cortex AI Function Studio features a Cortex Code Skill for creating, evaluating, and optimizing production-ready Cortex AI Functions for unstructured data workflows. It provides a structured development lifecycle that automates prompt engineering, model selection, evaluation, and optimization.
Cortex AI Function Studio provides two primary interfaces for authoring, evaluating, and optimizing AI Functions:
- Cortex Code CLI: A command-line experience built for AI and Data Engineers, supporting scriptable workflows, agentic task definition, and rapid iteration within development environments.
- Snowsight AI Studio (Guided): A native Snowflake UI built for Analysts and Data Scientists that provides a guided, no-code experience for creating, benchmarking, optimizing, and deploying AI Functions.
Create¶
Getting started is as simple as prompting Cortex Code in Snowsight or the Cortex Code CLI:
This command initiates the AI Function Studio workflow. You can also enter with a direct request (for example, “summarize themes from my PDF documents” or “build a function to classify my support tickets”) and the skill will route you directly to the relevant workflow without showing the menu.
Define task: Users specify the AI function’s objective, including the task description, expected inputs, and desired output format (for example: summaries, structured JSON, classifications, or generated answers).
Note
AI Function Studio supports multimodal workflows based on model availability, including text, document, and image inputs.
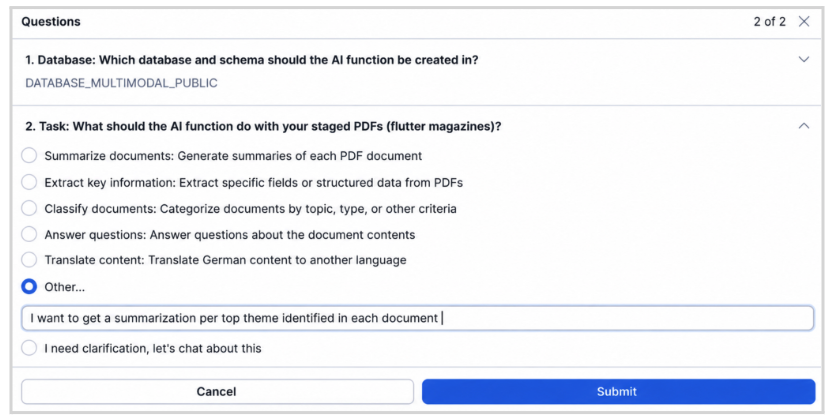
The AI Function Studio automatically selects a model for the task, though you can override the selection. In this example, because the staged files are PDFs, the system infers that a multimodal, document-capable model is required.
The system and user prompts used in your Custom AI Function are fully transparent. At this stage, the prompt has not yet been evaluated or optimized against your test data. That evaluation occurs after the function is created.
As part of the creation workflow, AI Function Studio automatically generates and runs smoke tests to validate the function behavior. For example, smoke tests can automatically validate that the function returns outputs in the expected structure.
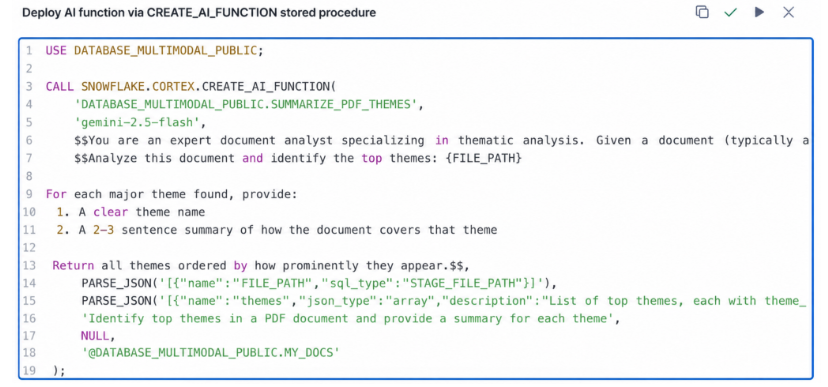
Once the function is registered, it can be used like any other Cortex AI Function!
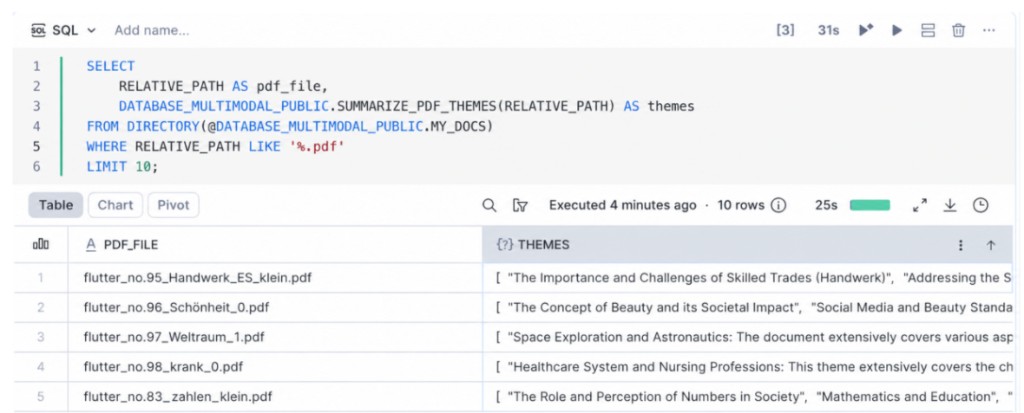
Custom AI Functions created using Cortex Code in Snowsight or via the Cortex Code CLI are visible in the Snowsight AI & ML » AI Functions page.
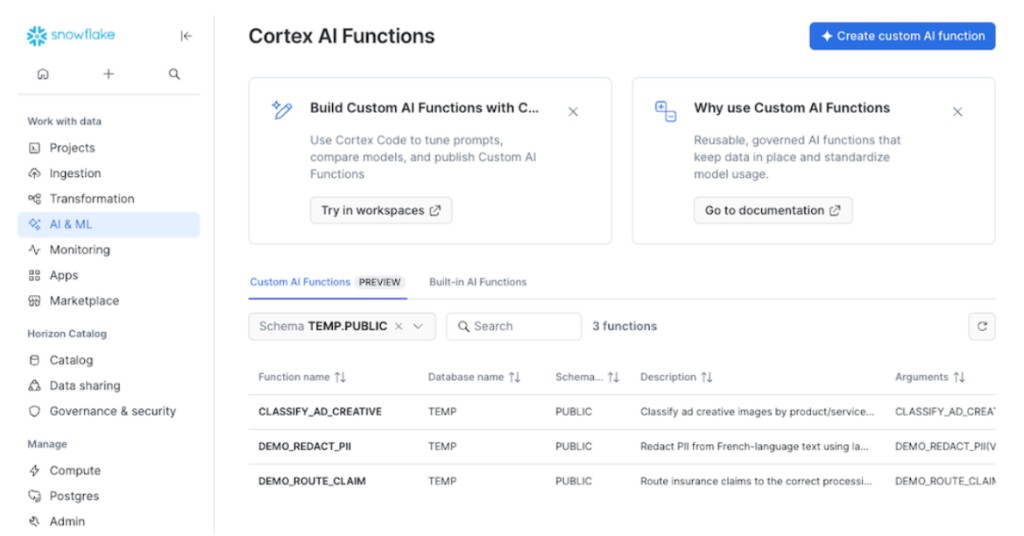
Created Custom AI Functions can also be listed via SNOWFLAKE.ACCOUNT_USAGE query with their associated built-in tag
Evaluate¶
Evaluation and optimization are optional steps in the AI Function Studio workflow. After the function is created, the Studio guides you through available next steps such as testing, evaluation, and optimization. These workflows can also be revisited later at any time.
AI Function Studio benchmarks candidate function configurations against representative datasets to measure accuracy, consistency, and overall performance. Depending on the data available, there are three evaluation paths:
- Labeled Dataset (Ground Truth): If you already have a dataset with known expected outputs, AI Function Studio uses it as the evaluation baseline to calculate accuracy and quality metrics.
- Label Generation: If you have input data but no labeled outputs, AI Function Studio can automatically generate evaluation labels using a state-of-the-art reasoning model. By default, the system selects the most capable available model for label generation and can recommend alternatives when needed.
- Synthetic Dataset Generation: If no evaluation dataset exists, AI Function Studio can generate synthetic evaluation data based on the task definition. The system creates representative examples and expected outputs to bootstrap benchmarking and optimization workflows.
Once the evaluation dataset is prepared, AI Function Studio applies configurable evaluation metrics to compare candidate prompts, models, and function configurations. You can select the evaluation strategy and metrics that best align with your use case.
For example, AI Function Studio recommends using LLM as a judge for a document summarization task:
After the evaluation completes, AI Function Studio generates a detailed results summary, including insights into low-scoring records to support human-in-the-loop review and analysis.

Optimize¶
AI Function Studio includes a managed AI optimization engine that automatically improves function quality using advanced optimization techniques such as the Genetic-Pareto Algorithm. Rather than relying on manual prompt engineering, the optimizer systematically explores and evaluates alternative prompts, models, and workflow strategies to improve accuracy and overall performance.
Prompt iterations¶
AI Function Studio supports multiple optimization budgets that control how extensively the system searches for improvements to your AI Function. Higher budgets explore a broader range of prompt, model, and workflow variations to maximize quality:
| Budget | Best for | Optimization behavior | Example use cases |
|---|---|---|---|
demo (2 iterations) | Quick validation and workflow previews | Performs a lightweight sanity check with minimal experimentation. Useful for validating the end-to-end workflow or previewing optimization behavior, but unlikely to uncover major improvements. | Demo environments, prototype validation, smoke testing, initial workflow verification |
light (6 iterations) | Simple, well-defined tasks | Evaluates a focused set of prompt and function-body variations. Best when small refinements are likely to produce meaningful gains. | Sentiment classification, spam detection, language detection, yes/no validation, simple text categorization |
medium (12 iterations) | Multi-step or nuanced tasks | Explores a broader range of optimization strategies, including alternative prompt structures and pre/post-processing approaches. Provides a balanced tradeoff between runtime, cost, and optimization quality. | Theme extraction from documents, named entity extraction, multi-label classification, structured Q&A, formatted summarization workflows |
heavy (18 iterations) | Complex, high-value production workloads | Conducts a deeper search across the optimization space, including advanced prompt restructuring and workflow modifications. Best for maximizing quality in production-critical systems. | Legal contract analysis, medical record extraction, policy-based routing, multi-stage reasoning pipelines, context-aware PII redaction |
Model selection¶
You can choose how many models available in your account AI Function Studio should evaluate and optimize against your baseline function.
Selecting more models increases evaluation time and overall compute cost, since each prompt iteration is executed independently for every selected model. In addition, operating on multimodal files (including but not limited to PDF, MP3, or MP4 files) further increases evaluation time.
For example, using the medium optimization budget (~12 iterations) with 6 selected models results in each model processing approximately 6-7 evaluation records across all 12 optimization iterations. This enables the system to benchmark multiple prompt and workflow variations across different model families and cost/performance tiers.
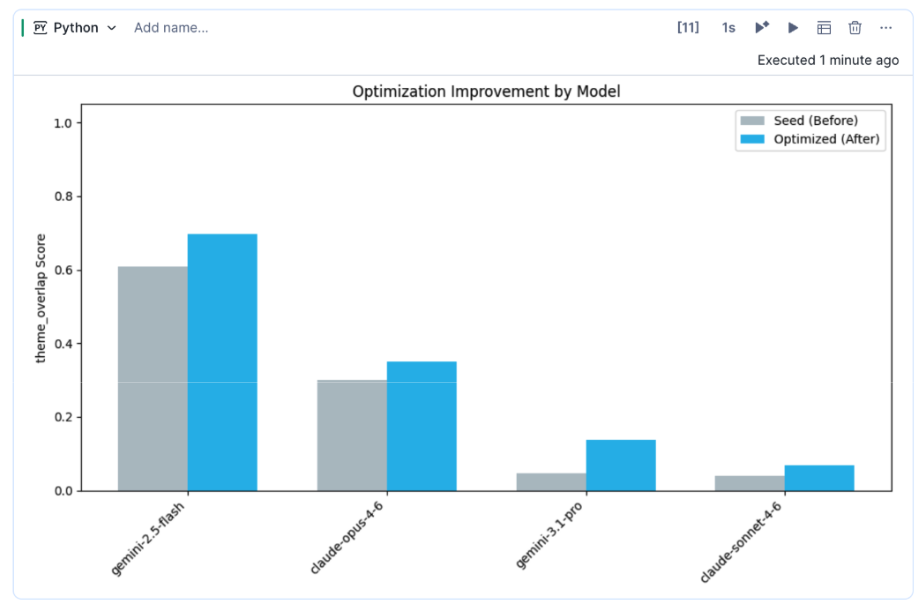
After optimization completes, AI Function Studio generates a comparative analysis showing how different models and prompt optimization strategies performed against the evaluation dataset. This allows teams to quantify quality improvements, compare model tradeoffs, and identify the best-performing configuration for their specific workload.
In the example below, iterative optimization improved overall summarization quality across multiple models, with Gemini 2.5 Flash achieving the strongest performance.
AI Function Studio can also help explain why certain models outperform others for a specific workload. By analyzing evaluation results, model characteristics, and document patterns, the system provides actionable insights into quality differences across models.
Once an optimized configuration is selected, the AI Function can be deployed with a single click. As new models become available, teams can rerun optimization workflows independently without rebuilding the entire function pipeline end-to-end.
Evaluation metrics guidelines¶
Choose the evaluation metric that best matches your task type:
| Category | Metric | Use cases |
|---|---|---|
| Rule-based | Exact Match | Uses straightforward, case-insensitive string comparison to check whether an output exactly matches the expected result. This approach works best for strict classification tasks where precision matters. |
| Rule-based | Fuzzy Match | Relies on token-level similarity to compare outputs, making it tolerant of small spelling differences or minor character variations. It’s a good fit when approximate matches are acceptable. |
| Rule-based | Contains Match | Looks for the presence of a specific substring within the output, which makes it especially useful for tasks like information extraction or keyword detection. |
| Semantic | LLM-as-a-Judge | Uses a reference language model to evaluate whether two pieces of text are meaningfully equivalent. This allows for more nuanced scoring in complex tasks such as summarization, translation, or other open-ended generation. |
| Customized | Custom Metrics | Custom metrics automatically generated by the AI Function Studio’s agentic engine to align with the unique objectives and success criteria of your task. Ideal when standard approaches such as Exact Match or LLM-as-a-Judge are insufficient, enabling sophisticated, task-specific evaluation logic. |
Built-in AI functions¶
In addition to custom AI functions, AI Function Studio can help you use Snowflake’s built-in Cortex AI functions directly. If your task maps to a built-in function, you can get immediate results with no setup — just SQL.
Supported built-in functions: AI_CLASSIFY, AI_FILTER, AI_EXTRACT, AI_COMPLETE, AI_PARSE_DOCUMENT, AI_SUMMARIZE_AGG, AI_AGG, AI_SENTIMENT, AI_TRANSLATE, AI_EMBED, AI_SIMILARITY, AI_REDACT, AI_TRANSCRIBE.
AI Function Studio looks up the latest Snowflake documentation for the correct syntax and helps you construct queries against your data. If accuracy on a built-in function isn’t sufficient or you need more control over cost/quality (model selection, prompt optimization), you can escalate to a custom AI function.
Known limitations¶
- Audio and video modalities are not yet supported. AI Function Studio currently supports text, document, and image inputs only. Support for audio and video inputs is planned for a future release.
Cost considerations¶
-
Development phase: Authoring, evaluation, and optimization are billed by two parts:
- The tokens processed by the models used during the experimentation process.
- Cortex Code usages.
-
Production phase: Once registered, a Custom AI Function is billed according to the underlying models it uses. There is no additional surcharge for the function abstraction itself.
To monitor and control costs, we recommend:
- Using the
SNOWFLAKE.ACCOUNT_USAGE.CORTEX_AI_FUNCTIONS_USAGE_HISTORYview and associated examples in Managing Cortex AI Function costs with Account Usage.
- Using the
-
Cost/quality tradeoffs: During optimization, AI Function Studio evaluates multiple models across different cost and performance tiers. This allows teams to select configurations that balance accuracy requirements against per-token costs — for example, using a smaller model that achieves acceptable accuracy at significantly lower cost.
To get the number of tokens consumed by your custom AI function, issue the following query: