Clustering Keys & Clustered Tables¶
In general, Snowflake produces well-clustered data in tables; however, over time, particularly as DML occurs on very large tables (as defined by the amount of data in the table, not the number of rows), the data in some table rows might no longer cluster optimally on desired dimensions.
To improve the clustering of the underlying table micro-partitions, you can always manually sort rows on key table columns and re-insert them into the table; however, performing these tasks could be cumbersome and expensive.
Instead, Snowflake supports automating these tasks by designating one or more table columns/expressions as a clustering key for the table. A table with a clustering key defined is considered to be clustered.
You can cluster materialized views, as well as tables. The rules for clustering tables and materialized views are generally the same. For a few additional tips specific to materialized views, see Materialized Views and Clustering and Best Practices for Materialized Views.
Attention
Clustering keys are not intended for all tables due to the costs of initially clustering the data and maintaining the clustering. Clustering is optimal when either:
- You require the fastest possible response times, regardless of cost.
- Your improved query performance offsets the credits required to cluster and maintain the table.
For more information about choosing which tables to cluster, see: Considerations for Choosing Clustering for a Table.
What is a Clustering Key?¶
A clustering key is a subset of columns in a table (or expressions on a table) that are explicitly designated to co-locate the data in the table in the same micro-partitions. This is useful for very large tables where the ordering was not ideal (at the time the data was inserted/loaded) or extensive DML has caused the table’s natural clustering to degrade.
Some general indicators that can help determine whether to define a clustering key for a table include:
- Queries on the table are running slower than expected or have noticeably degraded over time.
- The clustering depth for the table is large.
A clustering key can be defined at table creation (using the CREATE TABLE command) or afterward (using the ALTER TABLE command). The clustering key for a table can also be altered or dropped at any time.
Attention
Clustering keys cannot be defined for hybrid tables. In hybrid tables, data is always ordered by primary key.
Benefits of Defining Clustering Keys (for Very Large Tables)¶
Using a clustering key to co-locate similar rows in the same micro-partitions enables several benefits for very large tables, including:
- Improved scan efficiency in queries by skipping data that does not match filtering predicates.
- Better column compression than in tables with no clustering. This is especially true when other columns are strongly correlated with the columns that comprise the clustering key.
- After a key has been defined on a table, no additional administration is required, unless you chose to drop or modify the key. All future maintenance on the rows in the table (to ensure optimal clustering) is performed automatically by Snowflake.
Although clustering can substantially improve the performance and reduce the cost of some queries, the compute resources used to perform clustering consume credits. As such, you should cluster only when queries will benefit substantially from the clustering.
Typically, queries benefit from clustering when the queries filter or sort on the clustering key for the table. Sorting is commonly done for ORDER BY operations,
for GROUP BY operations, and for some joins. For example, the following join would likely cause Snowflake to perform a sort operation:
In this pseudo-example, Snowflake is likely to sort the values in either my_materialized_view.col1 or my_table.col1. For example, if the values in my_table.col1 are
sorted, then as the materialized view is being scanned, Snowflake can quickly find the corresponding row in my_table.
The more frequently a table is queried, the more benefit clustering provides. However, the more frequently a table changes, the more expensive it will be to keep it clustered. Therefore, clustering is generally most cost-effective for tables that are queried frequently and do not change frequently.
Note
After you define a clustering key for a table, the rows are not necessarily updated immediately. Snowflake only performs automated maintenance if the table will benefit from the operation. For more details, see Reclustering (in this topic) and Automatic Clustering.
Considerations for Choosing Clustering for a Table¶
Whether you want faster response times or lower overall costs, clustering is best for a table that meets all of the following criteria:
-
The table contains a large number of micro-partitions. Typically, this means that the table contains multiple terabytes (TB) of data.
-
The queries can take advantage of clustering. Typically, this means that one or both of the following are true:
- The queries are selective. In other words, the queries need to read only a small percentage of rows (and thus usually a small percentage of micro-partitions) in the table.
- The queries sort the data. (For example, the query contains an ORDER BY clause on the table.)
-
A high percentage of the queries can benefit from the same clustering key(s). In other words, many/most queries select on, or sort on, the same few column(s).
If your goal is primarily to reduce overall costs, then each clustered table should have a high ratio of queries to DML operations (INSERT/UPDATE/DELETE). This typically means that the table is queried frequently and updated infrequently. If you want to cluster a table that experiences a lot of DML, then consider grouping DML statements in large, infrequent batches.
Also, before choosing to cluster a table, Snowflake strongly recommends that you test a representative set of queries on the table to establish some performance baselines.
Strategies for Selecting Clustering Keys¶
A single clustering key can contain one or more columns or expressions. For most tables, Snowflake recommends a maximum of 3 or 4 columns (or expressions) per key. Adding more than 3-4 columns tends to increase costs more than benefits.
Selecting the right columns/expressions for a clustering key can dramatically impact query performance. Analysis of your workload will usually yield good clustering key candidates.
Snowflake recommends prioritizing keys in the order below:
- Cluster columns that are most actively used in selective filters. For many fact tables involved in date-based queries (for example “WHERE invoice_date > x AND invoice date <= y”), choosing the date column is a good idea. For event tables, event type might be a good choice, if there are a large number of different event types. (If your table has only a small number of different event types, then see the comments on cardinality below before choosing an event column as a clustering key.)
- If there is room for additional cluster keys, then consider columns frequently used in join predicates, for example “FROM table1 JOIN table2 ON table2.column_A = table1.column_B”.
If you typically filter queries by two dimensions (e.g. application_id and user_status columns), then
clustering on both columns can improve performance.
The number of distinct values (i.e. cardinality) in a column/expression is a critical aspect of selecting it as a clustering key. It is important to choose a clustering key that has:
- A large enough number of distinct values to enable effective pruning on the table.
- A small enough number of distinct values to allow Snowflake to effectively group rows in the same micro-partitions.
A column with very low cardinality might yield only minimal pruning, such as a column named IS_NEW_CUSTOMER
that contains only Boolean values.
At the other extreme, a column with very high cardinality is also typically not a good candidate to use as a clustering key directly.
For example, a column that contains nanosecond timestamp values would not make a good clustering key.
Tip
In general, if a column (or expression) has higher cardinality, then maintaining clustering on that column is more expensive.
The cost of clustering on a unique key might be more than the benefit of clustering on that key, especially if point lookups are not the primary use case for that table.
If you want to use a column with very high cardinality as a clustering key, Snowflake recommends defining the key as an expression on the column, rather than on the column directly, to reduce the number of distinct values. The expression should preserve the original ordering of the column so that the minimum and maximum values in each partition still enable pruning.
For example, if a fact table has a TIMESTAMP column c_timestamp containing many discrete values (many more than
the number of micro-partitions in the table), then a clustering key could be defined on the column by casting the
values to dates instead of timestamps (e.g. to_date(c_timestamp)). This would reduce the cardinality to the
total number of days, which typically produces much better pruning results.
As another example, you can truncate a number to fewer significant digits by using the TRUNC functions and a
negative value for the scale (e.g. TRUNC(123456789, -5)).
Tip
If you are defining a multi-column clustering key for a table, the order in which the columns are specified in
the CLUSTER BY clause is important. As a general rule, Snowflake recommends ordering the columns from
lowest cardinality to highest cardinality. Putting a higher cardinality column before a lower
cardinality column will generally reduce the effectiveness of clustering on the latter column.
Tip
When clustering on a text field, the cluster key metadata tracks only the first several bytes (typically 5 or 6 bytes). Note that for multi-byte character sets, this can be fewer than 5 characters.
In some cases, clustering on columns used in GROUP BY or ORDER BY clauses can be helpful. However, clustering
on these columns is usually less helpful than clustering on columns that are heavily used in filter or JOIN
operations. If you have some columns that are heavily used in filter/join operations and different columns that are
used in ORDER BY or GROUP BY operations, then favor the columns used in the filter and join operations.
Reclustering¶
As DML operations (INSERT, UPDATE, DELETE, MERGE, COPY) are performed on a clustered table, the data in the table might become less clustered. Periodic/regular reclustering of the table is required to maintain optimal clustering.
During reclustering, Snowflake uses the clustering key for a clustered table to reorganize the column data, so that related records are relocated to the same micro-partition. This DML operation deletes the affected records and re-inserts them, grouped according to the clustering key.
Note
Reclustering in Snowflake is automatic; no maintenance is needed. For more details, see Automatic Clustering.
However, for certain accounts, manual reclustering has been deprecated, but is still allowed. For more details see Manual Reclustering.
Credit and Storage Impact of Reclustering¶
Similar to all DML operations in Snowflake, reclustering consumes credits. The number of credits consumed depends on the size of the table and the amount of data that needs to be reclustered.
Reclustering also results in storage costs. Each time data is reclustered, the rows are physically grouped based on the clustering key for the table, which results in Snowflake generating new micro-partitions for the table. Adding even a small number of rows to a table can cause all micro-partitions that contain those values to be recreated.
This process can create significant data turnover because the original micro-partitions are marked as deleted, but retained in the system to enable Time Travel and Fail-safe. The original micro-partitions are purged only after both the Time Travel retention period and the subsequent Fail-safe period have passed (i.e. minimum of 8 days and up to 97 days for extended Time Travel, if you are using Snowflake Enterprise Edition (or higher)). This typically results in increased storage costs. For more information, see Snowflake Time Travel & Fail-safe.
Important
Before defining a clustering key for a table, you should consider the associated credit and storage costs.
Reclustering Example¶
Building on the clustering diagram from the previous topic, this diagram illustrates how reclustering a table can help reduce scanning of micro-partitions to improve query performance:
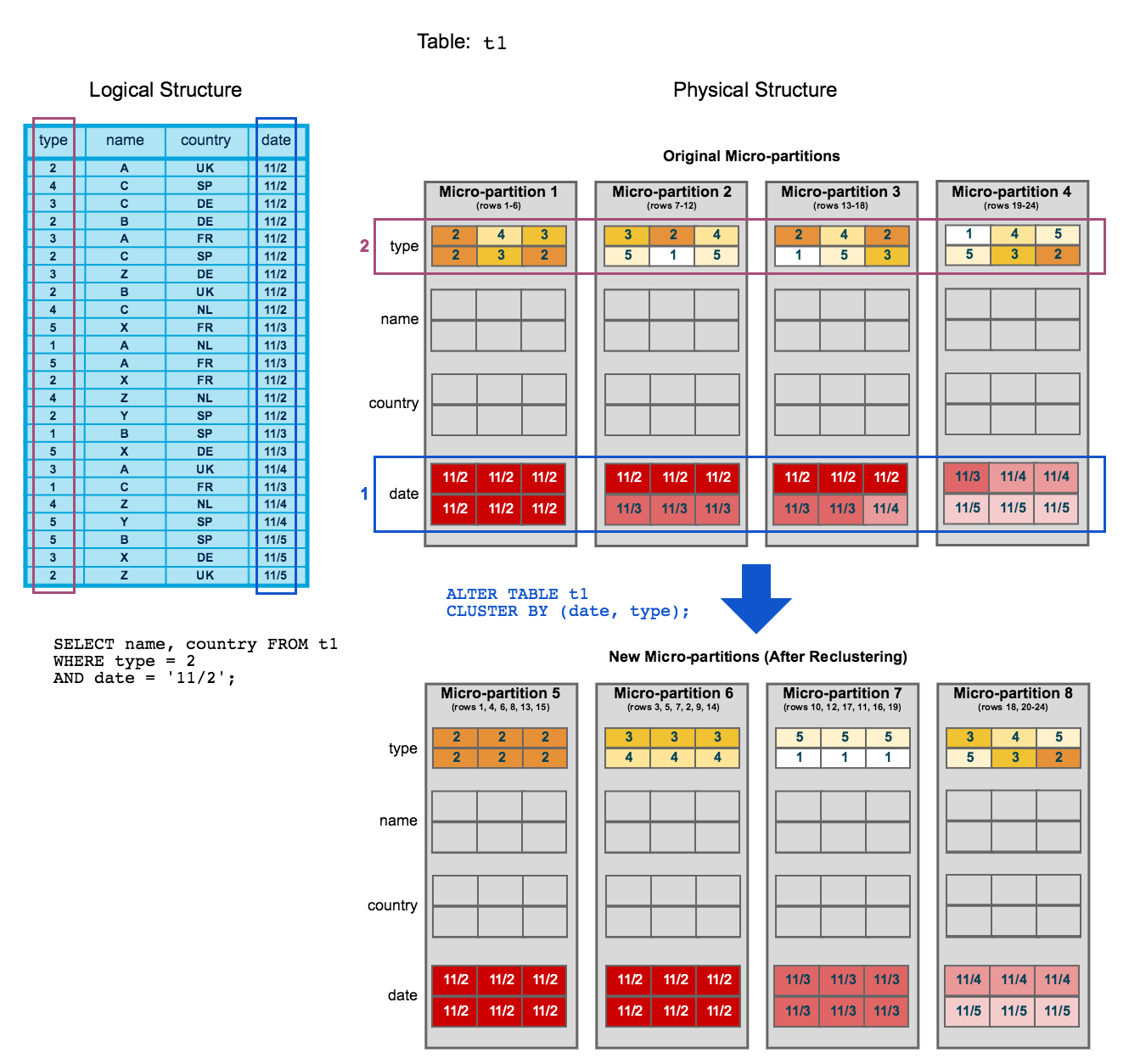
- To start, table
t1is naturally clustered bydateacross micro-partitions 1-4. - The query (in the diagram) requires scanning micro-partitions 1, 2, and 3.
dateandtypeare defined as the clustering key. When the table is reclustered, new micro-partitions (5-8) are created.- After reclustering, the same query only scans micro-partition 5.
In addition, after reclustering:
- Micro-partition 5 has reached a constant state (i.e. it cannot be improved by reclustering) and is therefore excluded when computing depth and overlap for future maintenance. In a well-clustered large table, most micro-partitions will fall into this category.
- The original micro-partitions (1-4) are marked as deleted, but are not purged from the system; they are retained for Time Travel and Fail-safe.
Note
This example illustrates the impact of reclustering on an extremely small scale. Extrapolated to a very large table (i.e. consisting of millions of micro-partitions or more), reclustering can have a significant impact on scanning and, therefore, query performance.
Defining Clustered Tables¶
Calculating the Clustering Information for a Table¶
Use the system function, SYSTEM$CLUSTERING_INFORMATION, to calculate clustering details, including clustering depth, for a given table. This function can be run on any columns on any table, regardless of whether the table has an explicit clustering key:
- If a table has an explicit clustering key, the function doesn’t require any input arguments other than the name of the table.
- If a table doesn’t have an explicit clustering key (or a table has a clustering key, but you want to calculate the ratio on other columns in the table), the function takes the desired column(s) as an additional input argument.
Defining a Clustering Key for a Table¶
A clustering key can be defined when a table is created by appending a CLUSTER BY clause to CREATE TABLE:
Where each clustering key consists of one or more table columns/expressions, which can be of any data type, except GEOGRAPHY, VARIANT, OBJECT, or ARRAY. A clustering key can contain any of the following:
- Base columns.
- Expressions on base columns.
- Expressions on paths in VARIANT columns.
For example:
Important Usage Notes¶
-
Standard tables: For each VARCHAR column in the clustering key, the current implementation of clustering uses only the first 5 bytes.
If the first N characters are the same for every row, or do not provide sufficient cardinality, then consider clustering on a substring that starts after the characters that are identical, and that has optimal cardinality. (For more information about optimal cardinality, see Strategies for Selecting Clustering Keys.) For example:
-
Interactive tables: For interactive tables, the clustering key can use up to 1 KB total across all clustering key columns. The per-column 5-byte limit for VARCHAR columns doesn’t apply to interactive tables.
-
If you define two or more columns/expressions as the clustering key for a table, the order has an impact on how the data is clustered in micro-partitions.
For more details, see Strategies for Selecting Clustering Keys (in this topic).
-
An existing clustering key is copied when a table is created using CREATE TABLE … CLONE. However, Automatic Clustering is suspended for the cloned table and must be resumed.
-
An existing clustering key is not supported when a table is created using CREATE TABLE … AS SELECT; however, you can define a clustering key after the table is created.
-
Defining a clustering key directly on top of VARIANT columns is not supported; however, you can specify a VARIANT column in a clustering key if you provide an expression consisting of the path and the target type.
Changing the Clustering Key for a Table¶
At any time, you can add a clustering key to an existing table or change the existing clustering key for a table using ALTER TABLE:
For example:
Important Usage Notes¶
-
When adding a clustering key to a table already populated with data, not all expressions are allowed to be specified in the key. You can check whether a specific function is supported using SHOW FUNCTIONS:
show functions like 'function_name';The output includes a column,
valid_for_clustering, at the end of the output. This column displays whether the function can be used in a clustering key for a populated table. -
Changing the clustering key for a table does not affect existing records in the table until the table has been reclustered by Snowflake.
Dropping the Clustering Keys for a Table¶
At any time, you can drop the clustering key for a table using ALTER TABLE:
For example: