Modifier et exécuter des notebooks dans Workspaces¶
Définir le contexte d’exécution¶
Les notebooks dans Workspaces ne définissent pas automatiquement une base de données ou un schéma. Pour interroger des données, vous devez définir le contexte d’exécution dans une cellule à l’aide des commandes SQLsuivantes :
Pour que les notebooks fonctionnent de manière cohérente dans les environnements et les applications clientes, utilisez des noms entièrement qualifiés pour les tables et les autres objets. Par exemple :
Utiliser le rôle et le sélecteur d’entrepôt¶
Vous pouvez définir le rôle actif et l’entrepôt pour votre notebook.
Utilisez le sélecteur en haut à gauche de l’éditeur de notebooks :
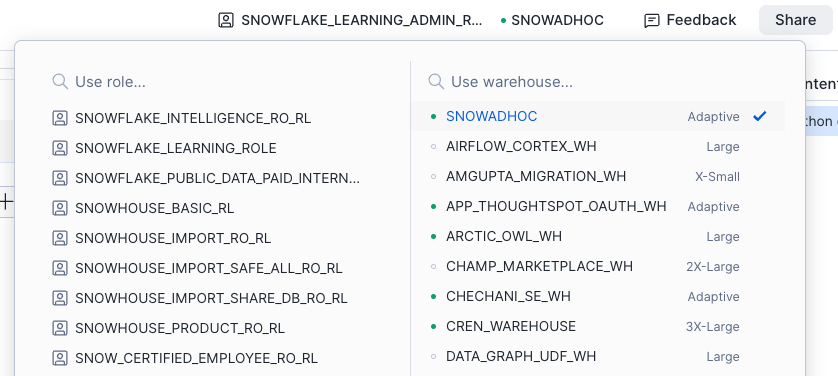
Exécutez les commandes SQL suivantes :
L’entrepôt de requêtes est utilisé pour exécuter les requêtes SQL et le calcul pushdown Snowpark invoqués par le notebook. Il permet également de rendre la grille de données interactive, mais cette opération n’implique aucun frais de crédit.
Pour en savoir plus sur l’utilisation du crédit, voir Configuration du calcul.
Créer une session Snowpark¶
Snowpark est un framework de développement Snowflake qui vous permet de créer des pipelines de données, des transformations et des logiques de machine learning directement dans Snowflake sans déplacer les données hors de la plateforme. Il fournit des APIs qui opèrent sur des données Snowflake comme DataFrames, poussant le calcul vers le moteur de Snowflake pour l’évolutivité, la performance et la sécurité.
Pour utiliser les APIs Snowpark Python dans Notebooks, créez d’abord une session Snowpark dans une cellule Python :
Exécuter des cellules¶
Il existe quatre options d’exécution prises en charge :
Exécuter toutes les cellules
Exécuter une seule cellule
Exécuter la cellule actuelle et toutes les cellules ci-dessus (via le menu à points de suspension de la cellule)
Exécuter la cellule actuelle et toutes les cellules ci-dessous (via le menu à points de suspension de la cellule)
Annuler l’exécution de la cellule¶
Utilisez Stop en haut du notebook ou Cancel execution dans une cellule.
Les deux actions arrêtent la cellule en cours d’exécution et toutes les cellules en file d’attente déclenchées par Run all.
Note
Le bouton Run all peut se transformer temporairement en Stop lorsque le notebook se connecte ou se reconnecte au service.
Noms de cellule¶
Vous pouvez attribuer des noms aux cellules pour faciliter la navigation et fournir des étiquettes contextuelles.
Si un fichier .ipynb importé contient déjà des métadonnées de nom ou de titre, ces valeurs sont utilisées automatiquement.
Référencement de cellule¶
Le référencement bidirectionnel de cellules SQL vers Python vous permet de réutiliser les résultats et les variables dans les cellules dans n’importe quel langage, permettant des transitions transparentes entre les workflows SQL et Python.
Vous pouvez survoler l’info-bulle du résultat pour voir le nom du DataFrame que vous pouvez utiliser pour référencer le résultat en Python et SQL.
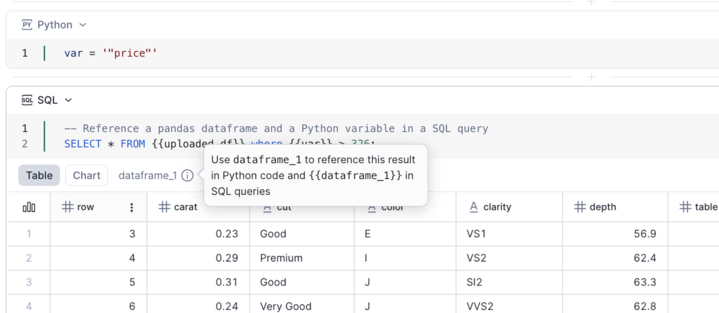
Référencement des résultats de cellule SQL¶
Chaque cellule SQL expose son résultat sous forme de pointeur vers un DataFrame pandas nommé dataframe_x.
Dans SQL, référencez-le en utilisant des accolades doubles :
{{dataframe_1}}.En Python, référencez-le directement en tant que DataFrame pandas :
dataframe_1.
Référencement de variables Python¶
Pour référencer des variables Python dans les requêtes SQL, entourez-les d’accolades. Par exemple :
Les variables DataFrame sont également prises en charge lors du référencement à des variables Python dans SQL.
Exemple de flux de travail¶
Calcul Python
Cellule SQL référençant une variable Python
Cellule SQL référençant les résultats de cellules SQL
Le résultat d’une cellule SQL fournit un pointeur DataFrame appelé dataframe_1. Vous pouvez y faire référence dans une autre requête SQL :
Grille de données interactive¶
La grille de données prend en charge :
Défilement
Rechercher
Filtrage
Tri
Création de graphiques sans code
Créateur de graphiques intégré¶
Fournit une expérience utilisateur cohérente pour la manipulation et la visualisation des données sur les zones d’édition dans Workspaces.
Minimap et statut de cellule¶
La minimap génère une table des matières à partir d’en-têtes Markdown et affiche un statut complet en session pour chaque cellule (en cours d’exécution, réussite, échec et modifiée).
Recherche et remplacement globaux¶
Vous pouvez rechercher des mots-clés dans toutes les cellules du notebook actuel. Si vous modifiez une cellule particulière, appuyez sur esc pour quitter d’abord le mode d’édition pour cette cellule.
Pour rechercher des mots-clés dans toutes les cellules du notebook actuel, procédez comme suit :
Pour rechercher des mots-clés, sélectionnez Search dans la mini-carte, ou utilisez le raccourci clavier CTRL + F.
Les mots-clés correspondants dans toutes les cellules sont affichés. Si vous le souhaitez, vous pouvez remplacer le terme de recherche par la valeur souhaitée en utilisant Replace next ou Replace all.
Noyau de notebook¶
Le noyau du notebook reste actif tant que le service du notebook se trouve dans l’état RUNNING, ce qui permet d’exécuter sans interruption des processus critiques de longue durée tels que des tâches de formation et d’ingénierie des données ML.
Actions qui n’affectent pas l’exécution du noyau :
Navigation vers d’autres pages
Travailler ailleurs dans Snowsight
Fermeture de votre navigateur
Arrêt de votre ordinateur
Vous pouvez arrêter ou redémarrer le noyau en utilisant le menu déroulant Connected.
Note
Utiliser Shut down kernel ou Restart kernel effacera les variables en mémoire, mais conservera tous les paquets installés par l’utilisateur. Si vous souhaitez un environnement parfaitement propre avec uniquement les paquets préinstallés, vous devez redémarrer le service ou créer un nouveau service et vous y connecter.
Si le service du notebook est suspendu, le noyau du notebook est également arrêté. Pour plus d’informations, voir Paramétrage du calcul.
Sortie de cellule¶
Les sorties des cellules d’un notebook dans des espaces de travail (espaces de travail privés et partagés) sont accessibles à l’utilisateur qui a exécuté le notebook.
Les sorties de cellules ne sont pas enregistrées sur le fichier
.ipynb. Pour exporter et partager des sorties, choisissez Export as HTML. Pour les sessions interactives dans les espaces de travail, Export as HTML est accessible à partir du menu à points de suspension situé en haut à droite de chaque fichier de notebook. Pour les notebooks planifiés, il est accessible dans la page de résultats de chaque exécution passée.Le fichier HTML exporté a les comportements suivants :
L’état réduit du code et de la sortie de chaque cellule est enregistré.
Les tables et les DataFrames sont limitées à 1 000 lignes et correspondent par défaut à la vue Table. Vous pouvez basculer vers,:ui:
Chartet le configurer dans le fichier HTML.
Magics Jupyter¶
Les notebooks dans Workspaces exécutent le noyau IPython (Python interactif) et fournissent des cellules Jupyter standard et des lignes de magics. Exécutez %lsmagic pour afficher les magics disponibles.
Par exemple, vous pouvez utiliser la commande générique %run pour appeler un autre notebook :
Dans une cellule Python de
notebook_a, appelez%run path/to/notebook_b.ipynb. Cette action exécutenotebook_bdans le même processus Python quenotebook_a.Pour les variables et les DataFrames pandas dans
notebook_bà afficher dans les résultats de cellulenotebook_a, veillez à les imprimer explicitement. Par exemple,print(var)oudisplay(df).
Outils de développement¶
Les outils de développement comprennent Terminal, le Scratchpad et le Variables Explorer. Ces outils vous permettent d’explorer vos données et l’environnement du notebook et d’interagir avec eux.
Pour accéder aux outils de développement, dans la barre de contrôle en haut du notebook, sélectionnez <icon>:ui:Tools.
Vous devez être connecté à un service de notebook pour utiliser les outils de développement. L’utilisation d’un autre service entraîne le redémarrage des outils.
Utilisation du terminal¶
Le terminal vous permet d’exécuter n’importe quelle commande shell dans l’environnement de conteneur du notebook :
Installer les dépendances -
pip install,pip list, ou vérifier les paquets installés.Gérer les fichiers -
ls,pwd, naviguer dans les répertoires et afficher les fichiers.Exécuter des tâches parallèles
Surveiller l’utilisation des ressources de calcul
Exemple d’installation et d’exécution de htop pour surveiller l’utilisation des ressources de calcul en temps réel :
Utilisation du Scratchpad (bloc-notes)¶
Le Scratchpad est un espace d’exploration pour vous permettre d’expérimenter rapidement, par exemple, avec du code, des idées, des calculs ou des notes, sans vous soucier de la structure ou du fini. Les commandes que vous exécutez dans le Scratchpad ne modifient pas le fichier du notebook.
Vous pouvez effectuer les opérations suivantes dans le Scratchpad :
Requêtes ad hoc rapides - Testez le SQL sans ajouter de cellules à votre notebook.
Exploration des données - Vérifiez le contenu des tables, les schémas ou exécutez des requêtes exploratoires.
Débogage - Vérifiez les données ou testez les fragments de requête avant de les ajouter aux cellules d’un notebook.
Opérations uniques - Exécutez des commandes qui n’ont pas besoin d’être enregistrées (comme SHOW GRANTS ou DESCRIBE TABLE).
Les résultats restent visibles pendant que vous travaillez, mais ne sont pas enregistrés dans le notebook.
Utilisation de l’explorateur de variables¶
L’explorateur de variables est un outil visuel qui vous permet d’inspecter les variables actuellement chargées dans votre session tout en travaillant de manière interactive. Il montre les éléments suivants pour chaque variable : Name, Type, Shape et Preview. Les variables sont mises à jour lorsqu’une cellule termine son exécution.