Bearbeiten und Ausführen von Notebooks in Workspaces¶
Ausführungskontext festlegen¶
Notebooks in Workspaces legen nicht automatisch eine Datenbank oder ein Schema fest. Um Daten abzufragen, müssen Sie den Ausführungskontext in einer Zelle mit den folgenden SQL-Befehlen definieren:
Um sicherzustellen, dass Notebooks über Umgebungen und Clients hinweg konsistent ausgeführt werden, verwenden Sie vollqualifizierte Namen für Tabellen und andere Objekte. Beispiel:
Rollen- und Warehouse-Auswahl verwenden¶
Sie können die aktive Rolle und das aktive Warehouse für Ihr Notebook festlegen.
Verwenden Sie die Auswahl oben links im Notebooks-Editor:
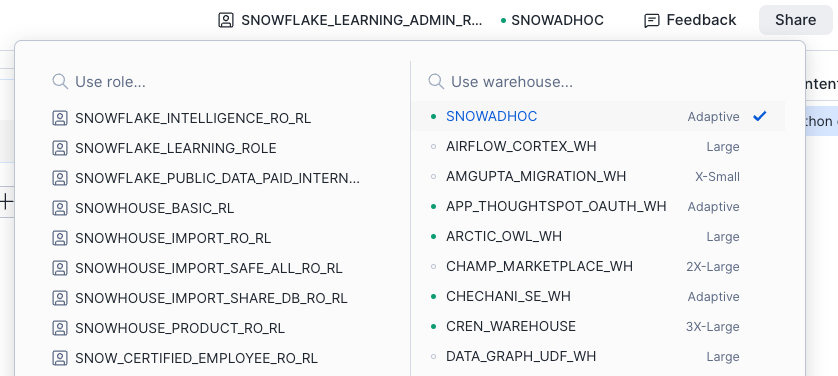
Führen Sie die folgenden SQL-Befehle aus:
Das Abfrage-Warehouse wird zur Ausführung von SQL-Abfragen und Snowpark-Pushdown-Compute, das vom Notebook aufgerufen wird, verwendet. Es wird auch verwendet, um das interaktive Datenraster zu rendern, aber für diesen Vorgang fallen keine Credit-Gebühren an.
Mehr über die Credit-Nutzung erfahren Sie unter Einrichten von Computeressourcen.
Snowpark-Sitzung erstellen¶
Snowpark ist ein Snowflake-Entwickler-Framework, mit dem Sie Datenpipelines, Transformationen und Logik für maschinelles Lernen direkt innerhalb von Snowflake erstellen können, ohne Daten aus der Plattform verschieben zu müssen. Es bietet APIs, die Snowflake-Daten als DataFrames verarbeiten und Berechnungen zur Sicherstellung von Skalierbarkeit, Leistung und Sicherheit an die Snowflake-Engine delegieren.
Um Snowpark Python APIs in Notebooks zu verwenden, erstellen Sie zunächst eine Snowpark-Sitzung in einer Python-Zelle:
Zellen ausführen¶
Es gibt vier unterstützte Ausführungsoptionen:
Alle Zellen ausführen
Eine einzelne Zelle ausführen
Aktuelle Zelle und alle darüber befindlichen Zellen ausführen (über das Ellipsenmenü der Zelle)
Aktuelle Zelle und alle darunter liegenden Zellen ausführen (über das Dreipunktmenü der Zelle)
Ausführung von Zellen abbrechen¶
Verwenden Sie Stop oben im Notebook oder Cancel execution in einer Zelle.
Beide Aktionen stoppen die aktuell ausgeführte Zelle und alle in der Warteschlange befindlichen Zellen, die durch Run all ausgelöst wurden.
Bemerkung
Die Schaltfläche Run all kann sich vorübergehend in Stop ändern, wenn das Notebook eine Verbindung zum Service herstellt oder erneut eine Verbindung herstellt.
Zellennamen¶
Sie können den Zellen Namen zuweisen, um die Navigation zu erleichtern und kontextbezogene Beschriftungen bereitzustellen.
Wenn eine importierte .ipynb-Datei bereits Metadaten zum Namen oder Titel enthält, werden diese Werte automatisch verwendet.
Zellenreferenzierung¶
Bidirektionales Referenzieren von SQL in Python-Zellen ermöglicht Ihnen, Ergebnisse und Variablen über Zellen hinweg in beiden Sprachen wiederzuverwenden, was nahtlose Übergänge zwischen SQL- und Python-Workflows ermöglicht.
Sie können den Mauszeiger über die Ergebnis-QuickInfo bewegen, um den DataFrame-Namen anzuzeigen, mit dem Sie das Ergebnis in Python und SQL referenzieren können.
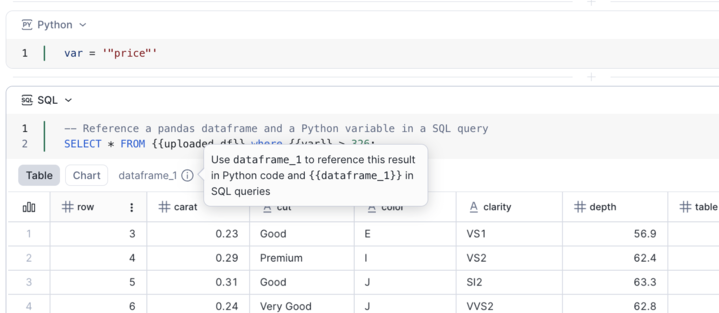
Referenzieren von SQL-Zellenergebnissen¶
Jede SQL-Zelle stellt ihr Ergebnis als einen Pandas-DataFrame-Pointer mit dem Namen dataframe_x bereit.
Referenzieren Sie dies in SQL anhand von doppelten geschweiften Klammern:
{{dataframe_1}}.Referenzieren Sie dies in Python direkt als einen Pandas-DataFrame:
dataframe_1.
Referenzieren von Python-Variablen¶
Um Python-Variablen in SQL-Abfragen zu referenzieren, schließen Sie diese in doppelte geschweifte Klammern ein. Beispiel:
DataFrame-Variablen werden auch unterstützt, wenn Python-Variablen in SQL referenziert werden.
Beispiel-Workflow¶
Python-Zelle
SQL-Zelle, die auf Python-Variable verweist
SQL-Zelle, die auf SQL-Zellenergebnisse verweist
Das Ergebnis einer SQL-Zelle liefert einen DataFrame-Pointer namens dataframe_1. Sie können ihn in einer anderen SQL-Abfrage referenzieren:
Interaktives Datenraster¶
Das Datenraster unterstützt Folgendes:
Scrollen
Suche
Filtern
Sortierung
Diagrammerstellung ohne Code
Integrierter Diagrammgenerator¶
Bietet eine konsistente Benutzererfahrung für die Datenbearbeitung und -visualisierung auf allen Bearbeitungsoberflächen in Workspaces.
Minimap und Zellenstatus¶
Die Minimap generiert ein Inhaltsverzeichnis aus den Markdown-Headern und zeigt einen umfassenden Sitzungsstatus für jede Zelle an (ausgeführt, erfolgreich, fehlgeschlagen und geändert).
Globales Suchen und Ersetzen¶
Sie können in allen Zellen des aktuellen Notebooks nach Schlüsselwörtern suchen. Wenn Sie eine bestimmte Zelle bearbeiten, drücken Sie esc, um zuerst den Bearbeitungsmodus für diese Zelle zu verlassen.
Um nach Schlüsselwörtern in allen Zellen des aktuellen Notebooks zu suchen, gehen Sie wie folgt vor:
Um nach Schlüsselwörtern zu suchen, wählen Sie Search in der Minimap aus, oder verwenden Sie das Tastaturkürzel CTRL + F.
Übereinstimmende Schlüsselwörter in allen Zellen werden angezeigt. Optional können Sie den Suchbegriff mithilfe von Replace next oder Replace all durch den gewünschten Wert ersetzen.
Notebook-Kernel¶
Der Notebook-Kernel bleibt aktiv, solange der Notebook-Service sich im Status RUNNING befindet, der eine ununterbrochene Ausführung von kritischen, langlaufenden Prozessen wie ML-Training und Data-Engineering-Jobs ermöglicht.
Aktionen, die sich nicht auf die Kernel-Ausführung auswirken:
Navigation zu anderen Seiten
Arbeiten an anderen Stellen in Snowsight
Schließen des Browsers
Herunterfahren des Computers
Sie können den Kernel über die Dropdown-Liste Connected herunterfahren oder neu starten.
Bemerkung
Die Verwendung von Shut down kernel oder Restart kernel löscht Variablen im Speicher, behält jedoch alle vom Benutzer installierten Pakete bei. Wenn Sie eine völlig saubere Umgebung mit nur den vorinstallierten Paketen wünschen, müssen Sie den Dienst neu starten oder einen neuen Dienst erstellen und sich mit diesem verbinden.
Wenn der Notebook-Service ausgesetzt wird, wird auch der Notebook-Kernel heruntergefahren. Weitere Informationen dazu finden Sie unter Einrichten von Computeressourcen.
Zellenausgabe¶
Die Zellenausgaben in einem Notebook in Arbeitsbereichen (sowohl private als auch freigegebene Arbeitsbereiche) sind für den Benutzenden zugänglich, der das Notebook ausgeführt hat.
Die Zellenausgaben werden nicht in der
.ipynb-Datei gespeichert. Um Ausgaben zu exportieren und freizugeben, wählen Sie Export as HTML aus. Für interaktive Sitzungen in Arbeitsbereichen kann Export as HTML über das Ellipsenmenü in der oberen rechten Ecke in jeder Notebook-Datei aufgerufen werden. Für geplante Notebooks kann über die Ergebnisseite jeder vergangenen Ausführung zugegriffen werden.Die exportierte HTML-Datei hat die folgenden Verhaltensweisen:
Der zusammengeklappte Zustand des Codes und der Ausgabe jeder Zelle wird gespeichert.
Tabellen und DataFrames sind auf 1.000 Zeilen begrenzt und haben standardmäßig die Table-Ansicht. Sie können zu Chart wechseln und die Konfiguration in der HTML-Datei vornehmen.
Jupyter Magics¶
Notebooks in Workspaces führen den IPython-Kernel (Interaktiver Python-Kernel) aus und stellen Standard-Jupyter-Zellen- und -Zeilen-Magics bereit. Führen Sie %lsmagic aus, um die verfügbaren Magics anzuzeigen.
Sie können zum Beispiel den Magic-Befehl %run verwenden, um ein anderes Notebook aufzurufen:
Rufen Sie in einer Python-Zelle von
notebook_a%run path/to/notebook_b.ipynbauf. Dadurch wirdnotebook_bim selben Python-Prozess wienotebook_aausgeführt.Damit Variablen und pandas-DataFrames aus
notebook_bin den Zellen vonnotebook_aangezeigt werden, müssen sie explizit ausgegeben werden. Beispiel:print(var)oderdisplay(df)
Entwicklertools¶
Zu den Entwicklertools gehören Terminal, Scratchpad und Variables Explorer. Mit diesen Tools können Sie Ihre Daten und die Notebook-Umgebung erkunden und mit ihnen interagieren.
Um auf die Entwicklertools zuzugreifen, wählen Sie in der Kontrollleiste am oberen Rand des Notebooks <icon>:ui:Tools aus.
Sie müssen mit einem Notebook-Service verbunden sein, um die Entwicklertools verwenden zu können. Wenn Sie zu einem anderen Service wechseln, werden die Tools neu gestartet.
Terminal verwenden¶
Über das Terminal können Sie jeden Shell-Befehl in der Container-Umgebung des Notebooks ausführen:
Abhängigkeiten installieren:
pip install,pip listaufrufen oder installierte Pakete überprüfen.Dateien verwalten:
vs,pwd, in Verzeichnissen navigieren und Dateien anzeigen.Parallele Jobs ausführen
Nutzung von Computeressourcen überwachen
Beispiel für die Installation und Ausführung von htop zur Überwachung der Computeressourcennutzung in Echtzeit:
Scratchpad verwenden¶
Das Scratchpad ist ein Bereich zum Erkunden, in dem Sie schnell experimentieren können, z. B. mit Code, Ideen, Berechnungen oder Notizen, ohne sich um Struktur oder Ausarbeitung kümmern zu müssen. Befehle, die Sie im Scratchpad ausführen, ändern nicht die Notebook-Datei.
Sie können im Scratchpad Folgendes tun:
Schnelle Ad-hoc-Abfragen: Testen Sie SQL, ohne Zellen zu Ihrem Notebook hinzuzufügen.
Datenexploration: Überprüfen Sie Tabelleninhalte oder Schemas, oder führen Sie explorative Abfragen durch.
Debugging: Überprüfen Sie Daten oder testen Sie Abfragefragmente, bevor Sie sie zu Notebook-Zellen hinzufügen.
Eindeutige Operationen: Führen Sie Befehle aus, die nicht gespeichert werden müssen (z. B. SHOW GRANTS oder DESCRIBE TABLE).
Die Ergebnisse bleiben während der Arbeit sichtbar, werden aber nicht mit dem Notebook gespeichert.
Verwenden des Variables Explorer¶
Der Variables Explorer ist ein visuelles Tool, mit dem Sie die aktuell in Ihrer Sitzung geladenen Variablen überprüfen können, während Sie interaktiv arbeiten. Er zeigt Name, Type, Shape und Preview für jede Variable an. Variablen werden aktualisiert, wenn die Ausführung einer Zelle beendet ist.