Editando e executando notebooks no Workspaces¶
Definir o contexto de execução¶
Os notebooks no Workspaces não definem automaticamente um banco de dados ou esquema. Para consultar dados, você deve definir o contexto de execução em uma célula usando os seguintes comandos SQL:
Para garantir que os notebooks sejam executados de maneira consistente em ambientes e clientes, use nomes totalmente qualificados para tabelas e outros objetos. Por exemplo:
Uso do seletor de função e warehouse¶
Você pode definir a função ativa e o warehouse para seu notebook.
Use o seletor no canto superior esquerdo do editor do Notebooks:
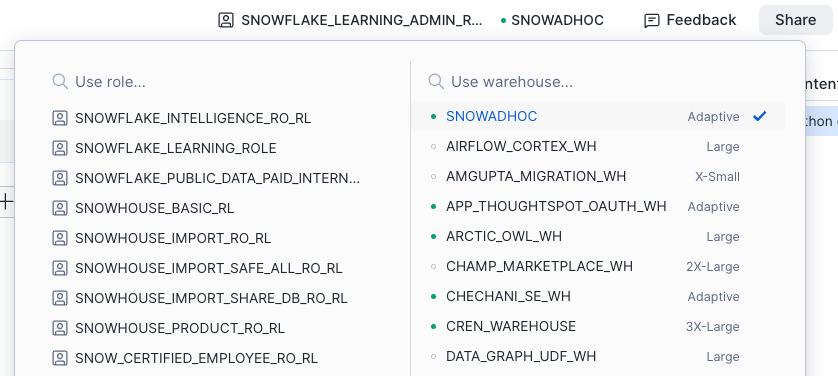
Execute os seguintes comandos SQL:
O warehouse de consulta é usado para executar as consultas SQL e a computação de pushdown do Snowpark que o notebook invoca. Ele também é usado para renderizar a grade de dados interativa, mas não há cobrança de crédito por essa operação.
Para saber mais sobre o uso de crédito, consulte Configurando a computação.
Criar uma sessão do Snowpark¶
O Snowpark é uma estrutura de desenvolvedor do Snowflake que permite criar pipelines de dados, transformações e lógica de machine learning diretamente no Snowflake sem mover os dados para fora da plataforma. Ele fornece APIs que operam com base nos dados do Snowflake como DataFrames, enviando a computação para o mecanismo do Snowflake para escalabilidade, desempenho e segurança.
Para usar as APIs Snowpark Python no Notebooks, primeiro crie uma sessão do Snowpark em uma célula Python:
Executar células¶
Há quatro opções de execução compatíveis:
Executar todas as células
Executar uma única célula
Executar a célula atual e todas as células acima (pelo menu de reticências da célula)
Executar a célula atual e todas as células abaixo (pelo menu de reticências da célula)
Cancelar a execução da célula¶
Use Stop na parte superior do notebook ou Cancel execution em uma célula.
Ambas as ações param a célula que está em execução e todas as células em fila acionadas por Run all.
Nota
O botão Run all pode mudar temporariamente para Stop quando o notebook está se conectando ou reconectando ao serviço.
Nomes de células¶
Você pode atribuir nomes às células para facilitar a navegação e fornecer rótulos contextuais.
Se um arquivo .ipynb importado já contém metadados de nome ou título, esses valores são usados automaticamente.
Referência de células¶
A referência de células bidirecional de SQL para Python permite reutilizar resultados e variáveis em células em qualquer linguagem, permitindo transições ininterruptas entre fluxos de trabalho SQL e Python.
Você pode passar o cursor do mouse sobre a dica de ferramenta do resultado para ver o nome do DataFrame que você pode usar para referenciar o resultado em Python e SQL.
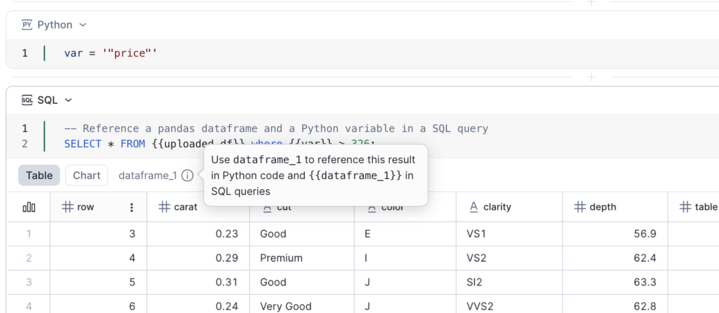
Fazendo referência a resultados de células SQL¶
Cada célula SQL expõe os resultados como um ponteiro DataFrame do Pandas chamado dataframe_x.
Em SQL, faça referência a ele usando chaves duplas:
{{dataframe_1}}.Em Python, faça referência a ele diretamente como DataFrame do Pandas:
dataframe_1.
Fazendo referência a variáveis Python¶
Para fazer referência a variáveis Python em consultas SQL, coloque-as entre chaves duplas. Por exemplo:
As variáveis DataFrame também são permitidas ao fazer referência a variáveis Python em SQL.
Exemplo de fluxo de trabalho¶
Célula Python
Célula SQL que faz referência à variável Python
Célula SQL que faz referência a resultados de células SQL
O resultado de uma célula SQL fornece um ponteiro DataFrame chamado dataframe_1. Você pode referenciá-lo em outra consulta SQL:
Grade de dados interativa¶
A grade de dados oferece suporte a:
Rolagem
Pesquisar
Filtragem
Classificação
Criação de gráficos sem código
Construtor de gráficos integrado¶
Fornece uma experiência de usuário consistente para manipulação e visualização de dados em superfícies de edição no Workspaces.
Minimapa e status da célula¶
O minimapa gera um índice de cabeçalhos Markdown e exibe um status abrangente na sessão para cada célula (em execução, com sucesso, com falha e modificado).
Pesquisa e substituição global¶
É possível pesquisar palavras-chave em todas as células no notebook atual. Se você estiver editando uma célula específica, pressione esc para sair primeiro do modo de edição daquela célula.
Para pesquisar palavras-chave em todas as células no notebook atual, faça o seguinte:
Para pesquisar palavras-chave, selecione Search no minimapa ou use o atalho de teclado CTRL + F.
As palavras-chave correspondentes em todas as células são mostradas. Você pode substituir o termo de pesquisa pelo valor desejado usando Replace next ou Replace all.
Kernel do notebook¶
O kernel do notebook permanecerá ativo enquanto o serviço do notebook estiver no estado RUNNING, permitindo a execução ininterrupta de processos críticos e de longa duração, como trabalhos de treinamento de ML e engenharia de dados.
Ações que não afetam a execução do kernel:
Navegar em outras páginas
Trabalhar em outra área do Snowsight
Fechar o navegador
Desligar o computador
Você pode desligar ou reiniciar o kernel usando o menu suspenso Connected.
Nota
O uso de Shut down kernel ou Restart kernel apagará as variáveis da memória, mas manterá os pacotes instalados pelo usuário. Se quiser um ambiente completamente limpo apenas com os pacotes pré-instalados, você deverá reiniciar o serviço ou criar um novo serviço e conectar-se a ele.
Se o serviço do notebook for suspenso, o kernel do notebook também será desligado. Para obter mais informações, consulte Configurando a computação.
Saída da célula¶
As saídas das células em um notebook no Workspaces (espaços de trabalho tanto privados quanto compartilhados) são acessíveis ao usuário que executou o notebook.
As saídas das células não são salvas no arquivo
.ipynb. Para exportar e compartilhar saídas, escolha Export as HTML. Para sessões interativas no Workspaces, Export as HTML pode ser acessado no menu de reticências no canto superior direito de cada arquivo de notebook. Para notebooks agendados, ele pode ser acessado na página de resultados de cada execução anterior.O arquivo HTML exportado tem os seguintes comportamentos:
O estado recolhido do código e da saída de cada célula é salvo.
Tabelas e DataFrames são limitados a 1.000 linhas e usam como padrão a exibição Table. Você pode alternar para Chart e configurá-lo no arquivo HTML.
Magics do Jupyter¶
Os notebooks no Workspaces executam o kernel IPython (Interactive Python) e fornecem magics de célula e de linha padrão do Jupyter. Execute %lsmagic para ver os magics disponíveis.
Por exemplo, você pode usar o comando magic %run para invocar outro notebook:
Em uma célula Python de
notebook_a, chame%run path/to/notebook_b.ipynb. Esse comando executanotebook_bno mesmo processo Python quenotebook_a.Para que DataFrames de variáveis e pandas em
notebook_bsejam renderizados nos resultados de células denotebook_a, certifique-se de imprimi-los explicitamente. Por exemplo:print(var)oudisplay(df).
Ferramentas para desenvolvedores¶
As ferramentas para desenvolvedores incluem Terminal, Scratchpad e Variables Explorer. Essas ferramentas permitem que você explore e interaja com seus dados e com o ambiente do notebook.
Para acessar as ferramentas para desenvolvedores, na barra de controle na parte superior do notebook, selecione <icon>:ui:Tools.
Você precisa estar conectado a um serviço de notebook para usar as ferramentas para desenvolvedores. Alternar para um serviço diferente reiniciará as ferramentas.
Usando o terminal¶
O terminal permite que você execute qualquer comando shell no ambiente de contêiner do notebook:
Instalar dependências:
pip install,pip listou verificar os pacotes instalados.Gerenciar arquivos:
ls,pwd, navegar por diretórios e visualizar arquivos.Executar trabalhos paralelos
Monitorar o uso de recursos de computação
Exemplo de instalação e execução de htop para monitorar o uso de recursos de computação em tempo real:
Usando o Scratchpad¶
O Scratchpad é um espaço exploratório para você fazer experimentos rápidos, por exemplo, com códigos, ideias, cálculos ou notas, sem se preocupar com estrutura ou refinamento. Os comandos executados no Scratchpad não alteram o arquivo do notebook.
Você pode fazer o seguinte no Scratchpad:
Consultas ad hoc rápidas: testar SQL sem adicionar células ao seu notebook.
Exploração de dados: verificar conteúdos de tabelas, esquemas ou executar consultas exploratórias.
Depuração: verificar dados ou testar fragmentos de consulta antes de adicioná-los às células de um notebook.
Operações pontuais: executar comandos que não precisam ser salvos (como SHOW GRANTS ou DESCRIBE TABLE).
Os resultados permanecem visíveis enquanto você trabalha, mas não são salvos com o notebook.
Usando o navegador de variáveis¶
O navegador de variáveis é uma ferramenta visual que permite inspecionar as variáveis que são carregadas em sua sessão enquanto você está trabalhando interativamente. Ele mostra Name, Type, Shape e Preview para cada variável. As variáveis são atualizadas quando uma célula termina de ser executada.