Amazon S3からの一括ロード¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths for bulk loading into Snowflake. This set of topics describes how to use the COPY command to bulk load from an S3 bucket into tables.
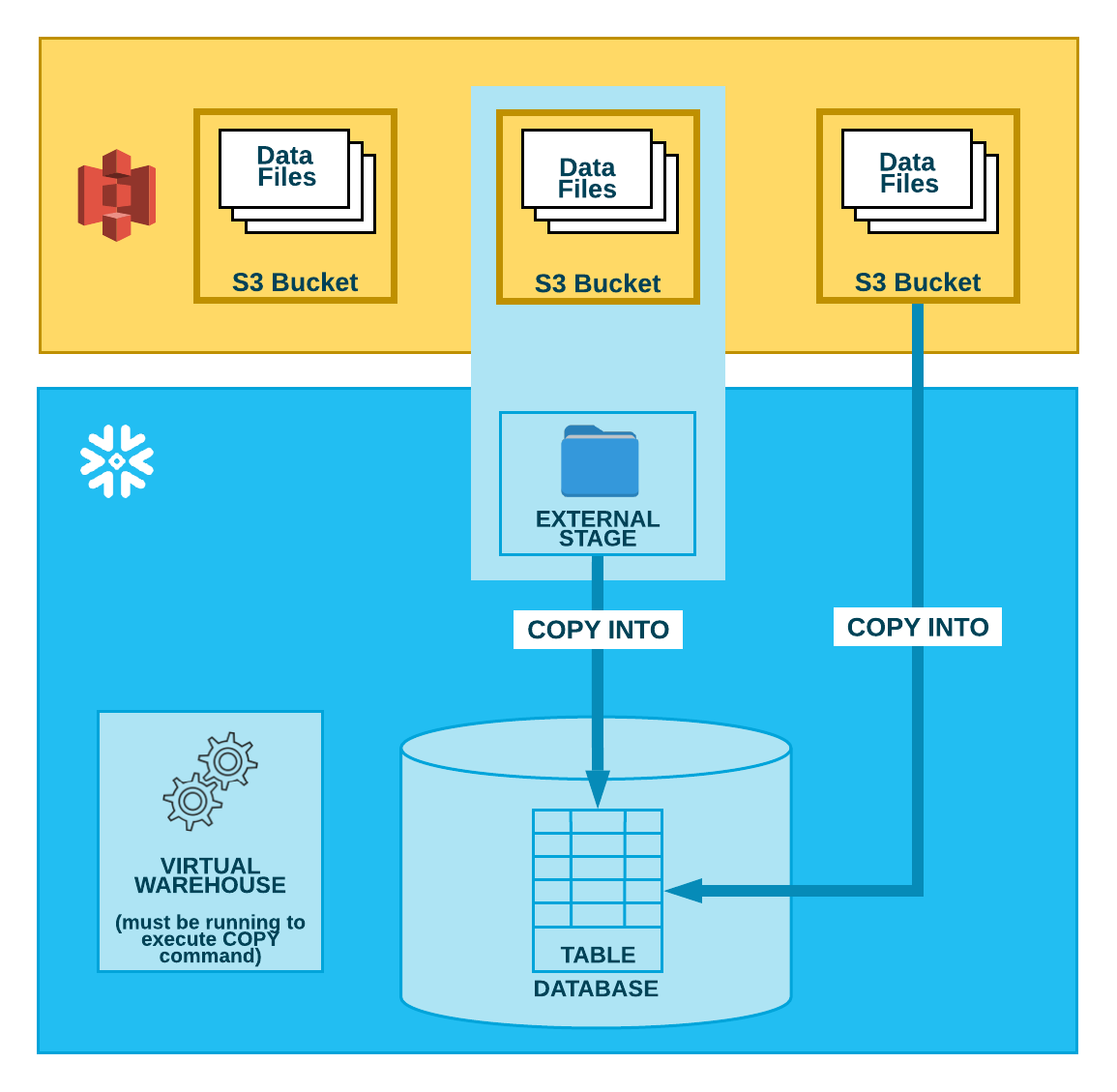
次の図に示すように、S3バケットからのデータのロードは2つのステップで実行されます。
- ステップ1:
Snowflakeは、データファイルが既にS3バケットにステージングされていることを前提としています。まだステージングされていない場合は、 AWS が提供するアップロードインターフェイス/ユーティリティを使用してファイルをステージングします。
- ステップ2:
COPY INTO <テーブル> コマンドを使用して、ステージングされたファイルの内容をSnowflakeデータベーステーブルにロードします。バケットからは直接ロードできますが、Snowflakeでは、バケットを参照する外部ステージを作成し、代わりに外部ステージを使用することをお勧めします。
コマンドを手動またはスクリプト内で実行する場合は、使用する方法に関係なく、このステップでは、稼働中の現行の仮想ウェアハウスがセッションのために必要です。ウェアハウスは、テーブルに行を実際に挿入するコンピューティングリソースを提供します。
注釈
Snowflakeは、各Amazon Virtual Private Cloudで、Amazon S3のゲートウェイエンドポイントを使用します。
Snowflakeアカウントが AWS でホストされている限り、ネットワークトラフィックが公共のインターネットを通過することはありません。これはS3バケットのリージョンに関係なく同じです。
Tip
この一連のトピックの手順では、 データのロードの準備 を読み終えて、必要がある場合は、名前付きファイル形式が作成済みであることを前提としています。
始める前に、ベストプラクティス、ヒント、およびその他のガイダンスについて データロードに関する考慮事項 を読むこともできます。
次のトピック:
構成タスク(必要に応じて完了):
データのロードタスク(ロードするファイルの各セットについて完了):