Snowpark Migration Accelerator: Relatórios selecionados¶
O Snowpark Migration Accelerator (SMA) gera relatórios de avaliação abrangentes por meio da análise de dados detalhados. A seção a seguir lista esses relatórios disponíveis.
Os resultados da avaliação, inclusive os inventários detalhados de todos os elementos, podem ser encontrados nas planilhas nas páginas seguintes.
Relatório detalhado¶
Perigo
O relatório DetailedReport.html foi descontinuado e não é mais suportado a partir do Spark Conversion Core V2.43.0
Nota
Esta página explica cada seção do relatório detalhado, conforme mostrado no arquivo do documento.
O SMA Detailed Report é o principal relatório de análise que fornece informações abrangentes em várias seções.
O relatório de avaliação contém as seguintes seções e suas descrições:
A primeira página do relatório detalhado apresenta uma visão geral concisa da ferramenta Snowpark Migration Accelerator (SMA).
.png)
Esta página contém a seguinte subseção:
A seção Resumo da execução é exibida:
O nome da sua organização e o endereço de e-mail das configurações de criação do projeto Snowpark Migration Accelerator: Configuração do projeto
Um número de identificação exclusivo para cada execução do SMA (esse ID é referenciado em toda a seção de inventários)
O carimbo de data/hora da execução
Detalhes da versão para SMA e Snowpark API
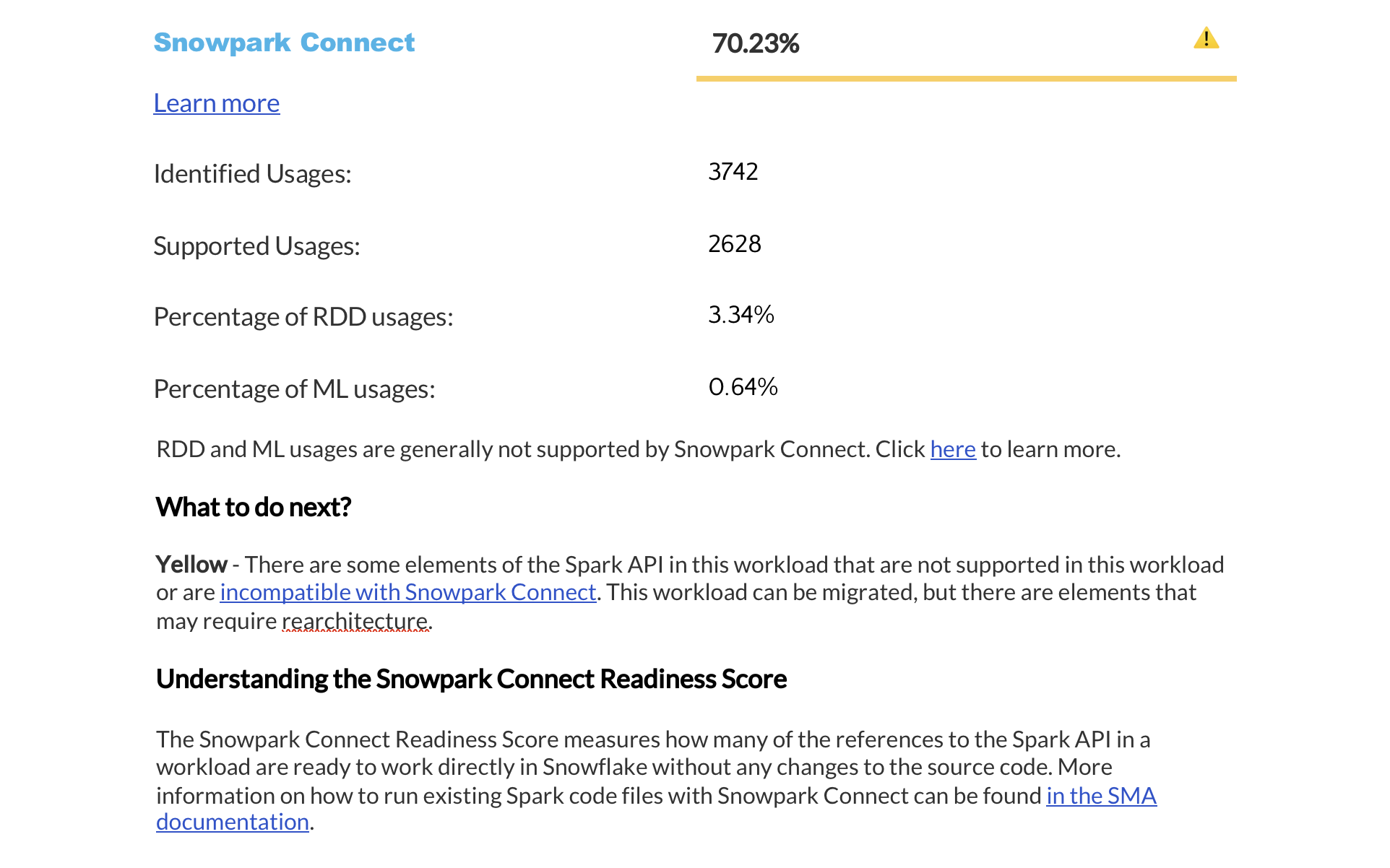
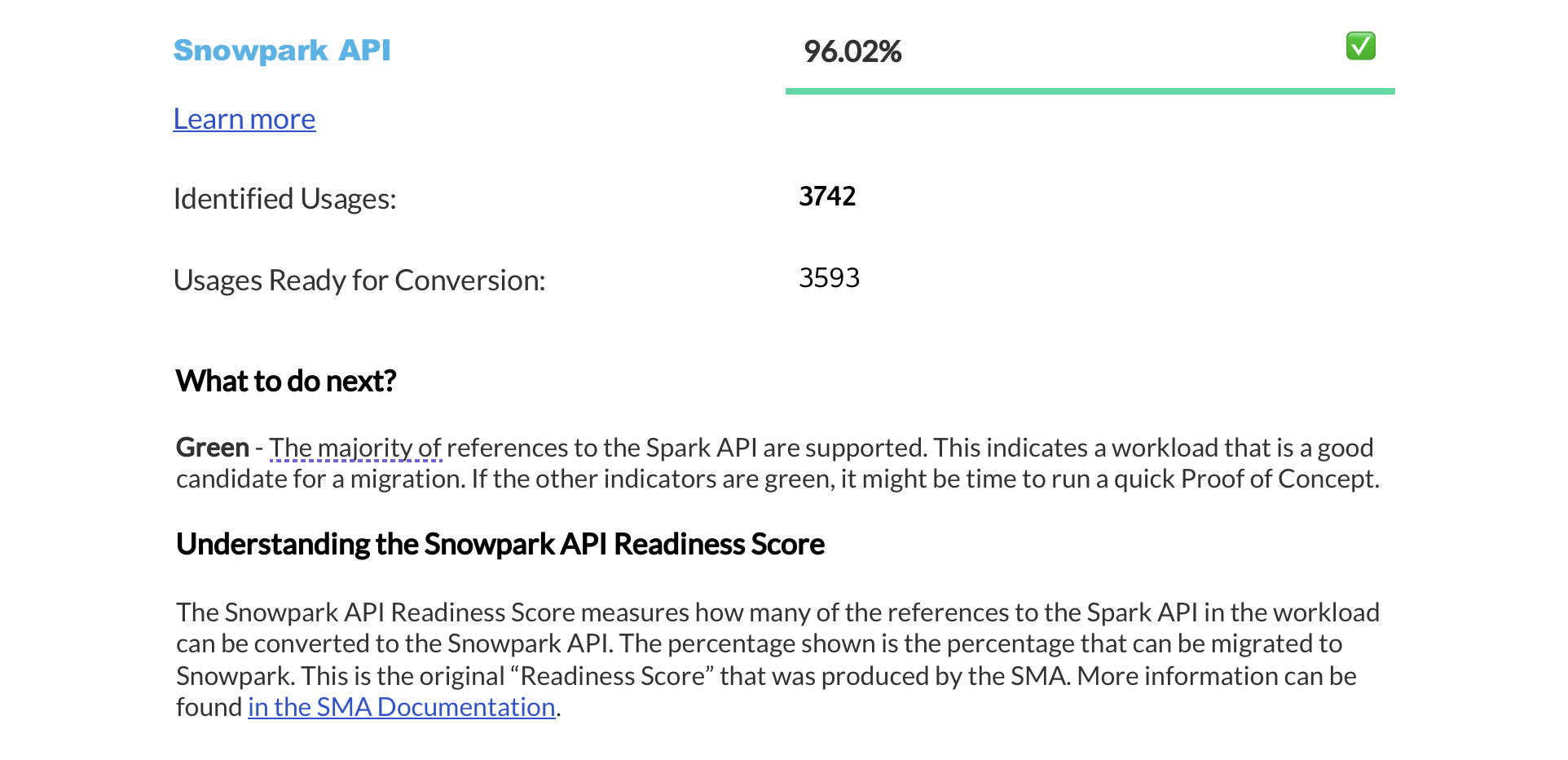
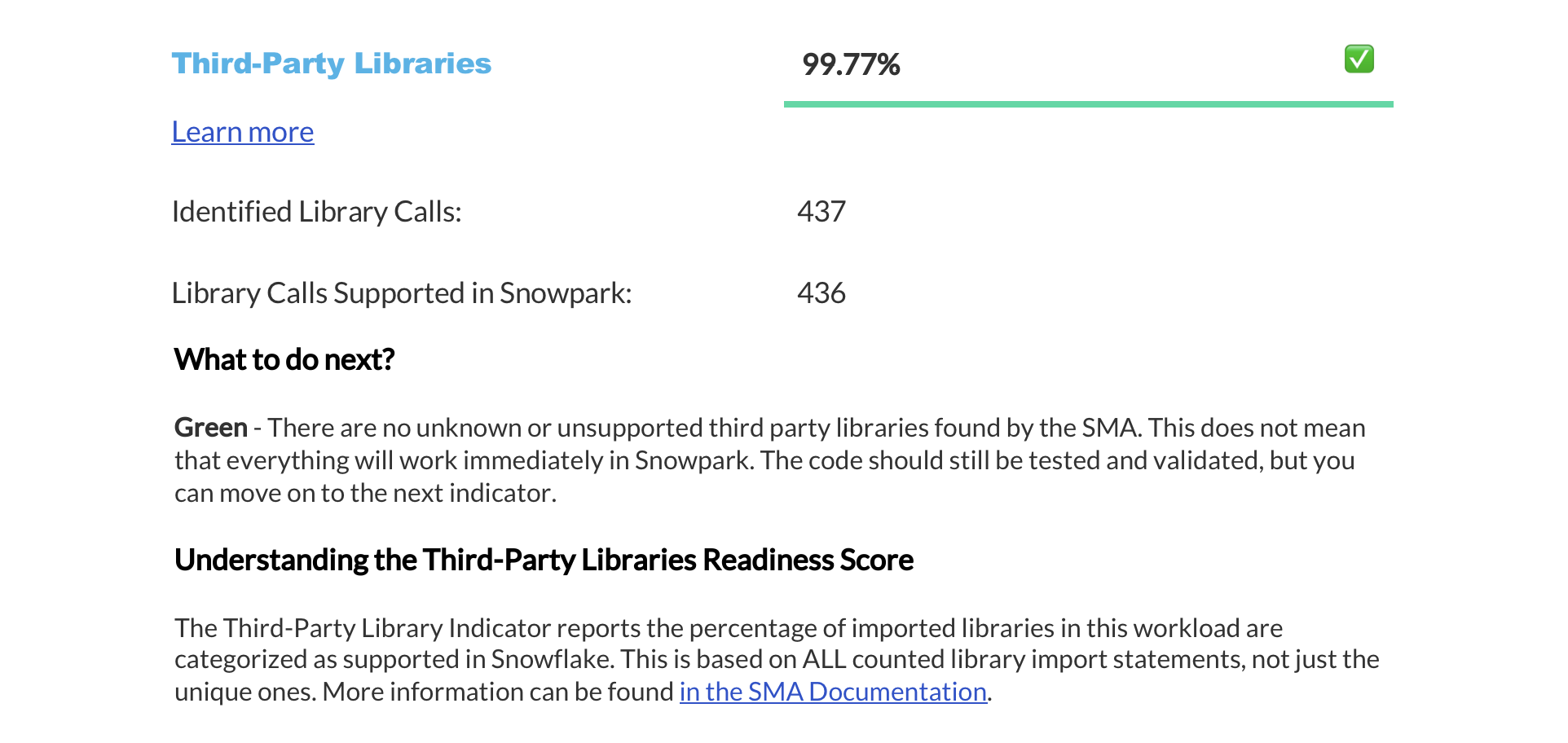
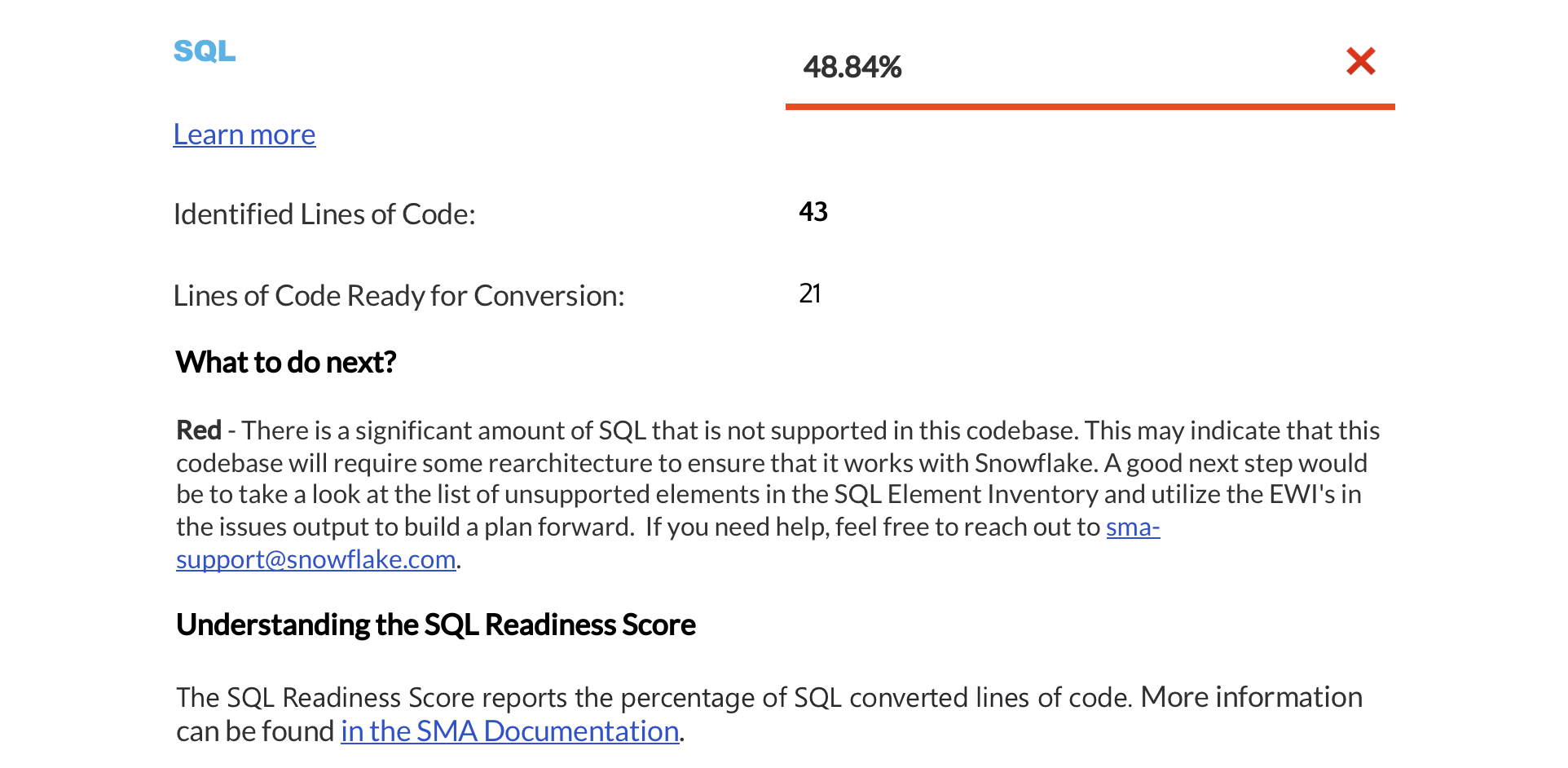
Resumo das pontuações de preparação¶
The next page displays a summary of readiness scores. It includes scores for Spark API and Third-Party libraries, along with guidance on how to interpret them. These scores help you understand how well-prepared your codebase is for migration to Snowflake.

Esta seção fornece informações detalhadas sobre cada pontuação de preparação.
Resumo do arquivo¶
A seção de resumo do arquivo começa na página seguinte. Esta seção pode abranger várias páginas, dependendo de quantos tipos de arquivos diferentes foram processados durante a execução dessa ferramenta.
Essas informações também estão disponíveis no resumo da avaliação apresentado no aplicativo.
.png)
Resumo do tipo de arquivo: Exibe um detalhamento das tecnologias reconhecidas, incluindo o número de arquivos para cada tipo de tecnologia, suas linhas totais de código e a porcentagem que representam de todos os arquivos analisados.
Resumo da extensão de arquivo: Mostra estatísticas para cada extensão de arquivo reconhecida, incluindo o número de arquivos com essa extensão, o total de linhas de código e a porcentagem que representam de todos os arquivos analisados.
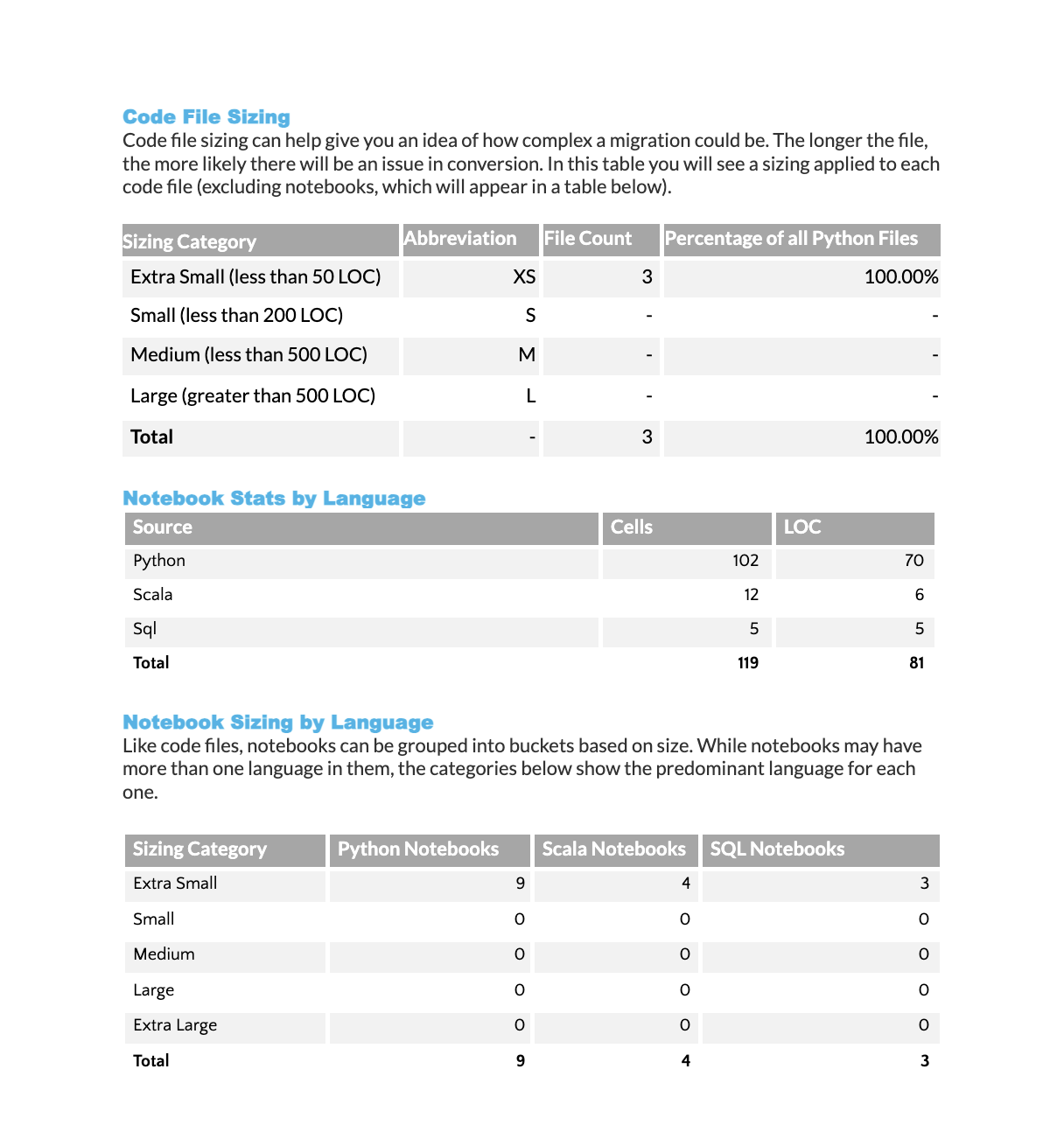
Análise do tamanho do arquivo de código: Exibe a distribuição de arquivos de código por categoria de tamanho (dimensionamento de «camiseta»). Cada categoria de tamanho mostra o número de arquivos e sua porcentagem da base de código total.
Estatísticas de linguagem de notebook: Fornece um detalhamento das linhas de código e células por linguagem de programação em todos os notebooks verificados.
Classificação do tamanho do notebook por idioma: Categoriza cada arquivo de notebook por tamanho com base no total de linhas de código. O tipo de notebook (Python, Scala ou SQL) é determinado pela linguagem predominante utilizada. As categorias de tamanho são:
XS: Menos de 50 linhas
S: 50-200 linhas
M: 200-500 linhas
L: 500-1.000 linhas
XL: Mais de 1.000 linhas
Resumo do Spark API¶
O Spark API Summary fornece uma análise detalhada da pontuação de preparação mostrada na seção Readiness Score. Esta seção contém quatro tabelas:
Uma lista de arquivos contendo referências do Spark API
Um detalhamento dos recursos suportados e não suportados
A pontuação de preparação organizada pelas categorias do Spark API
A pontuação de preparação organizada por status de mapeamento
Explicaremos quais referências do Spark API são compatíveis e quais não são. Veja a seguir o que esses termos significam:
Suportado: O Snowpark Migration Accelerator (SMA) pode converter automaticamente esse elemento API para o Snowpark API ou fornecer uma solução alternativa conhecida.
Não suportado: O Snowpark Migration Accelerator (SMA) não pode converter automaticamente este elemento API para o Snowpark API. Isso não significa que a conversão seja impossível, mas exigirá intervenção manual.
.png)
Arquivos com referências ao Spark: Esta tabela mostra um detalhamento do uso da tecnologia Spark em sua carga de trabalho, categorizada por tipo de tecnologia.
Arquivos com status de suporte do Spark: Esta tabela exibe o número de recursos Spark com e sem suporte em seu código-fonte, organizados por tipo de tecnologia.

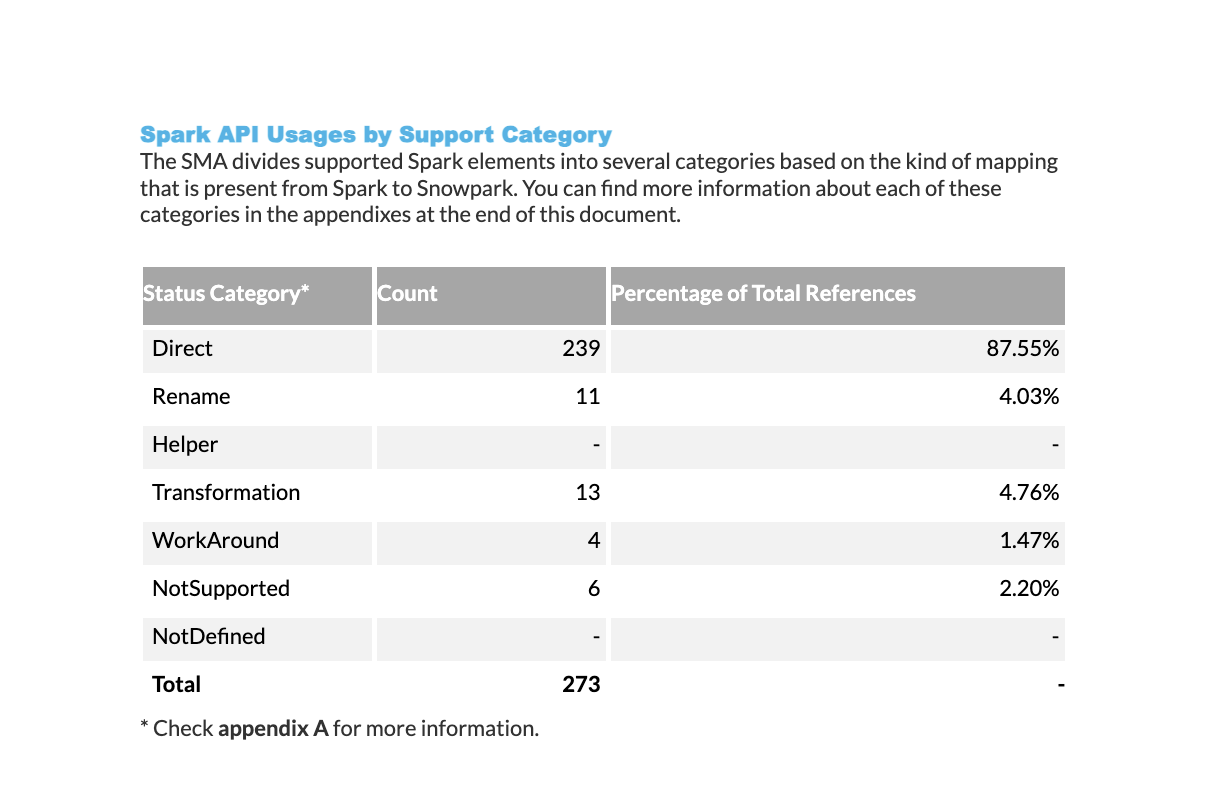
Resumo de uso do Spark API: uma tabela que mostra quantas funções do Spark API são compatíveis e não são compatíveis com Python e Scala. A tabela é organizada pela categoria de API e inclui uma pontuação de preparação do Spark API, que corresponde à pontuação mostrada na seção de pontuação de preparação.
Categorias de suporte de uso do Spark API: Um detalhamento de quantas vezes as funções do Spark API são usadas em seu código, organizadas por seu status de suporte. Para obter descrições detalhadas de cada categoria de suporte, consulte a página de Categorias de referência do Spark.
Resumo do uso do Pandas API¶
Nota
O resumo de uso do Pandas API está disponível apenas para execuções que contêm arquivos Python.
O resumo do Pandas API fornece uma lista de referências ao Pandas API, semelhante ao resumo do Spark API mostrado anteriormente.
.png)
Arquivos com uso do Pandas: Um detalhamento mostrando o número de referências ao Pandas encontradas em cada tecnologia em toda a sua carga de trabalho.
Resumo do uso do Pandas API: uma lista detalhada das funções da biblioteca Pandas usadas em seu código-fonte, classificadas por frequência de uso.
Resumo da referência de importação¶
A seção de Análise de importação exibe todas as dependências externas importadas para a sua base de código. Isso inclui bibliotecas de terceiros e outros componentes externos usados em todos os arquivos. Observe que as importações de arquivos dentro de sua própria base de código não são mostradas nessa tabela.
Chamadas de importação de código
.png){kind=link}
A tabela exibe as informações do pacote Python com os seguintes detalhes:
Nomes de pacotes que foram importados
Se cada pacote é compatível com a distribuição Anaconda do Snowpark
Número de vezes que cada pacote aparece nas importações
Porcentagem de arquivos contendo cada importação
Observe que, embora o total da coluna «Porcentagem» seja igual a 100%, as porcentagens individuais podem somar mais de 100%, pois os arquivos geralmente contêm várias importações de pacotes.
Resumo de referência SQL¶

Uso de SQL por tipo de arquivo: Essa tabela categoriza o uso do SQL com base em diferentes tecnologias, mostrando o número total de arquivos SQL e células SQL encontrados em sua carga de trabalho.
Uso do SQL por status de suporte: Esta tabela organiza os elementos do SQL com base no fato de eles terem ou não um recurso equivalente no Snowflake.
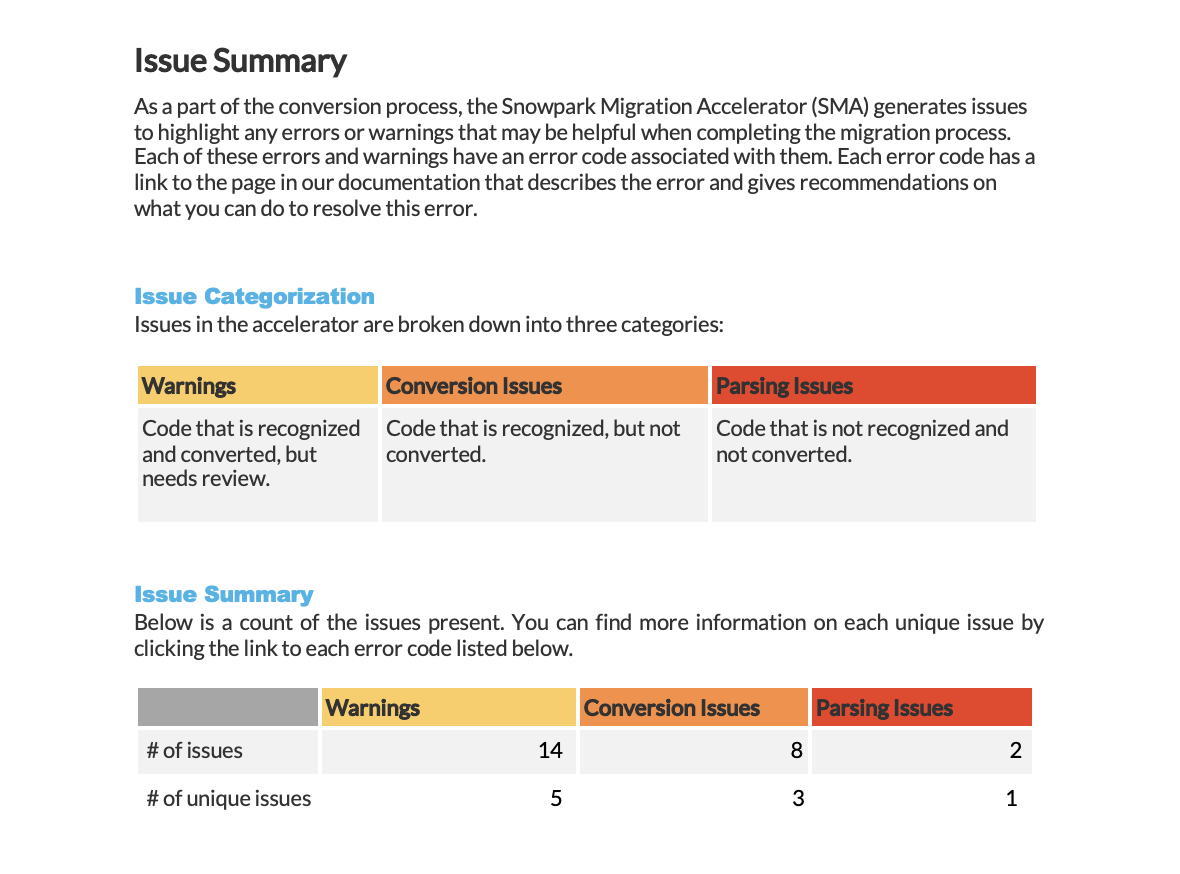
Resumo dos problemas do Snowpark Migration Accelerator (SMA)¶
O Snowpark Migration Accelerator (SMA) cria relatórios de problemas sempre que detecta avisos, erros de conversão ou erros de análise em seu código. A resolução desses problemas é essencial para concluir uma migração de código bem-sucedida usando o SMA.
Para obter um guia detalhado sobre como entender e analisar problemas, consulte a seção de análise de problemas da nossa documentação.
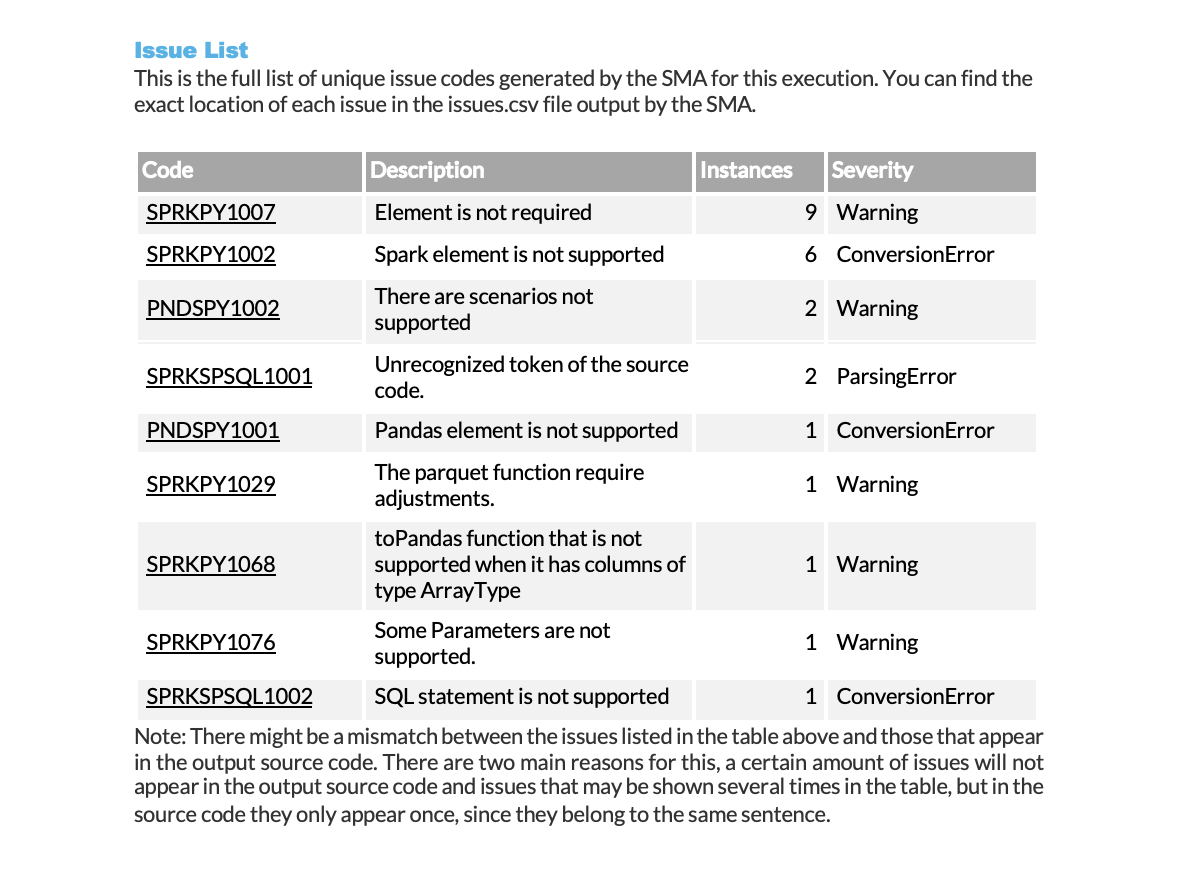
O resumo exibe cada problema com as seguintes informações:
Código de problema (com um link para a documentação detalhada)
Número de ocorrências na carga de trabalho
Nível de gravidade
O relatório exibe três níveis de gravidade (Warning, Conversion Error e Parsing Error) juntamente com um resumo organizado por cada nível.
Ao trabalhar com ferramentas de migração, siga estas prioridades para lidar com diferentes tipos de problemas:
Resolva os erros de análise primeiro, pois eles exigem atenção imediata
Resolver erros de conversão por meio de soluções programáticas
Monitore e acompanhe os avisos durante todo o processo de migração
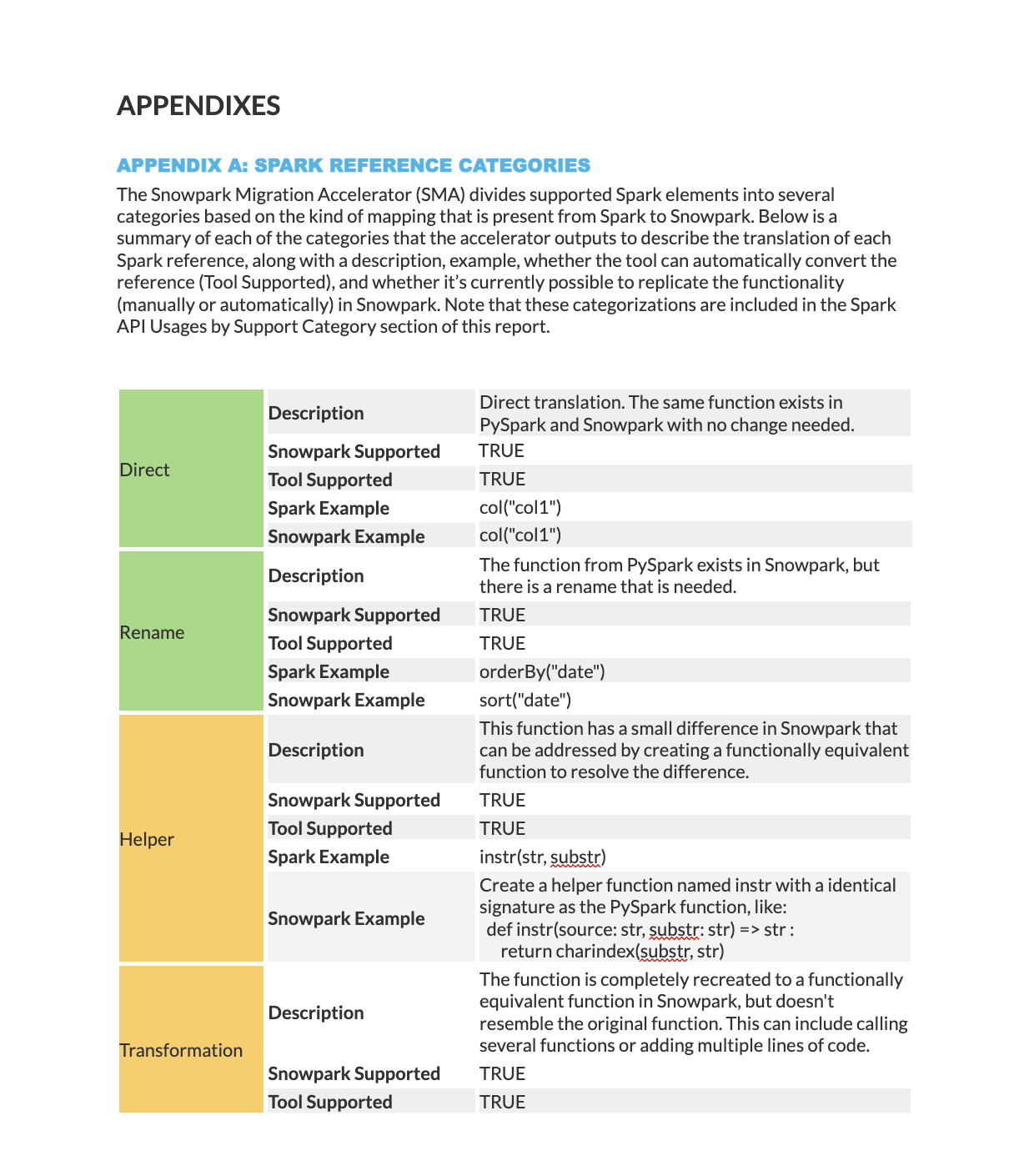
Apêndices
O Apêndice A fornece descrições detalhadas de todas as categorias de status de mapeamento.
Este relatório abrangente contém informações detalhadas coletadas dos arquivos de inventário que o Snowpark Migration Accelerator (SMA) gera.
Para obter informações detalhadas sobre o relatório, entre em contato com a equipe do Snowpark Migration Accelerator (SMA) pelo e-mail sma-support@snowflake.com.
Perigo
O recurso Summary Report foi removido e não está mais disponível a partir do Spark Conversion Core V2.43.0
O SMA gera vários relatórios de saída, que incluem planilhas detalhadas nos resultados.