Snowpark Migration Accelerator : Rapports organisés¶
L’outil Snowpark Migration Accelerator (SMA) génère des rapports d’évaluation complets en analysant des données détaillées. La section suivante répertorie les rapports disponibles.
Les résultats de l’évaluation, y compris les inventaires détaillés de tous les éléments, se trouvent dans les feuilles de calcul des pages suivantes.
Rapport détaillé¶
Danger
Le rapport DetailedReport. html est obsolète et n’est plus pris en charge depuis Spark Conversion Core V2.43.0
Note
Cette page explique chaque section du rapport détaillé tel qu’il apparaît dans le fichier de document.
Le rapport détaillé SMA est le principal rapport d’analyse qui fournit des informations complètes dans plusieurs sections.
Le rapport d’évaluation contient les sections suivantes et leur description :
La première page du rapport détaillé donne un aperçu concis de l’outil Snowpark Migration Accelerator (SMA).

Cette page contient la sous-section suivante :
La section Résumé de l’exécution s’affiche :
Le nom de votre organisation et votre adresse e-mail figurant dans vos paramètres de création de projet
Un numéro d’identification unique pour chaque exécution de SMA (cet ID est référencé dans toute la section des inventaires)
L’horodatage de l’exécution
Détails de la version pour SMA et l’API Snowpark
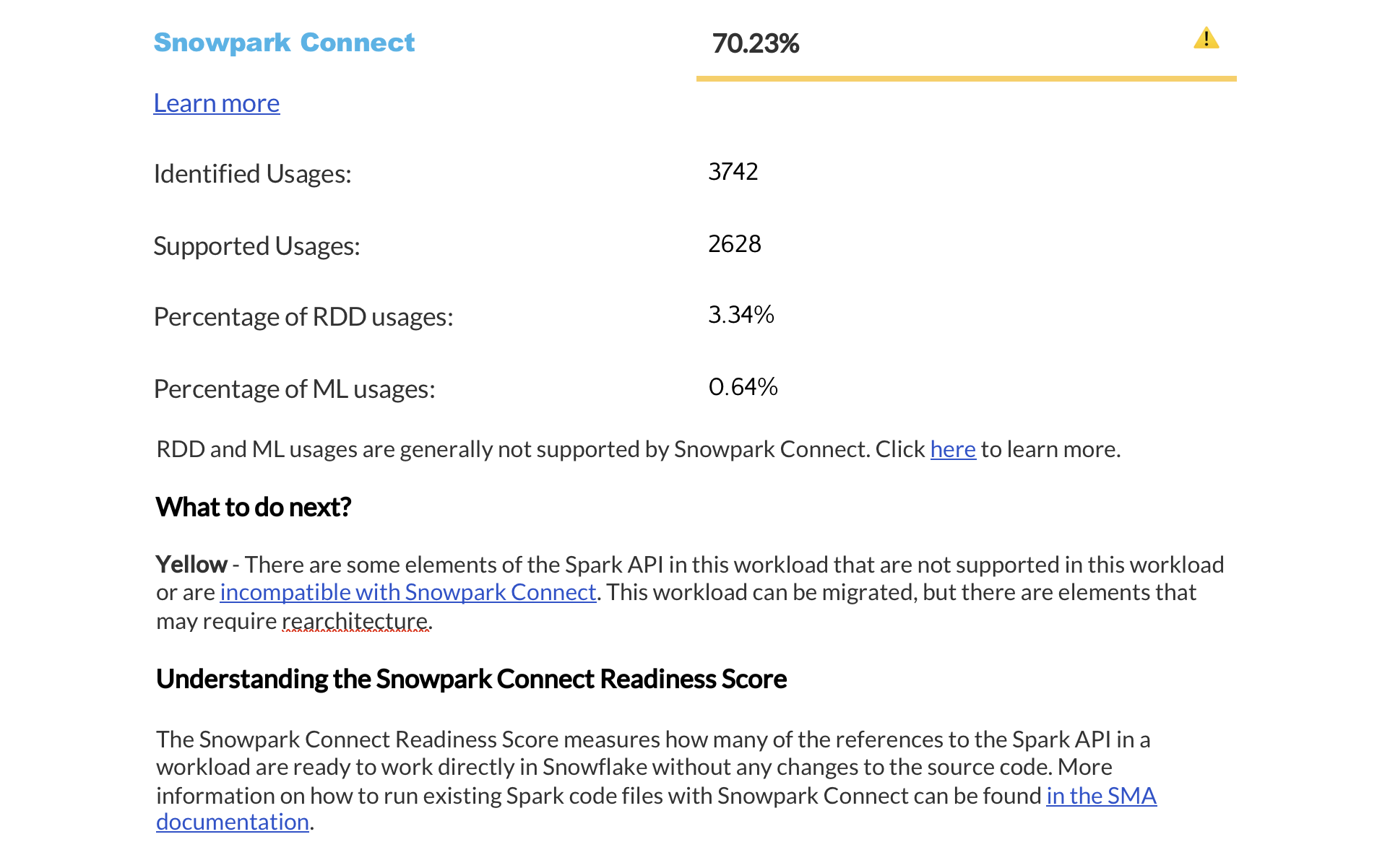
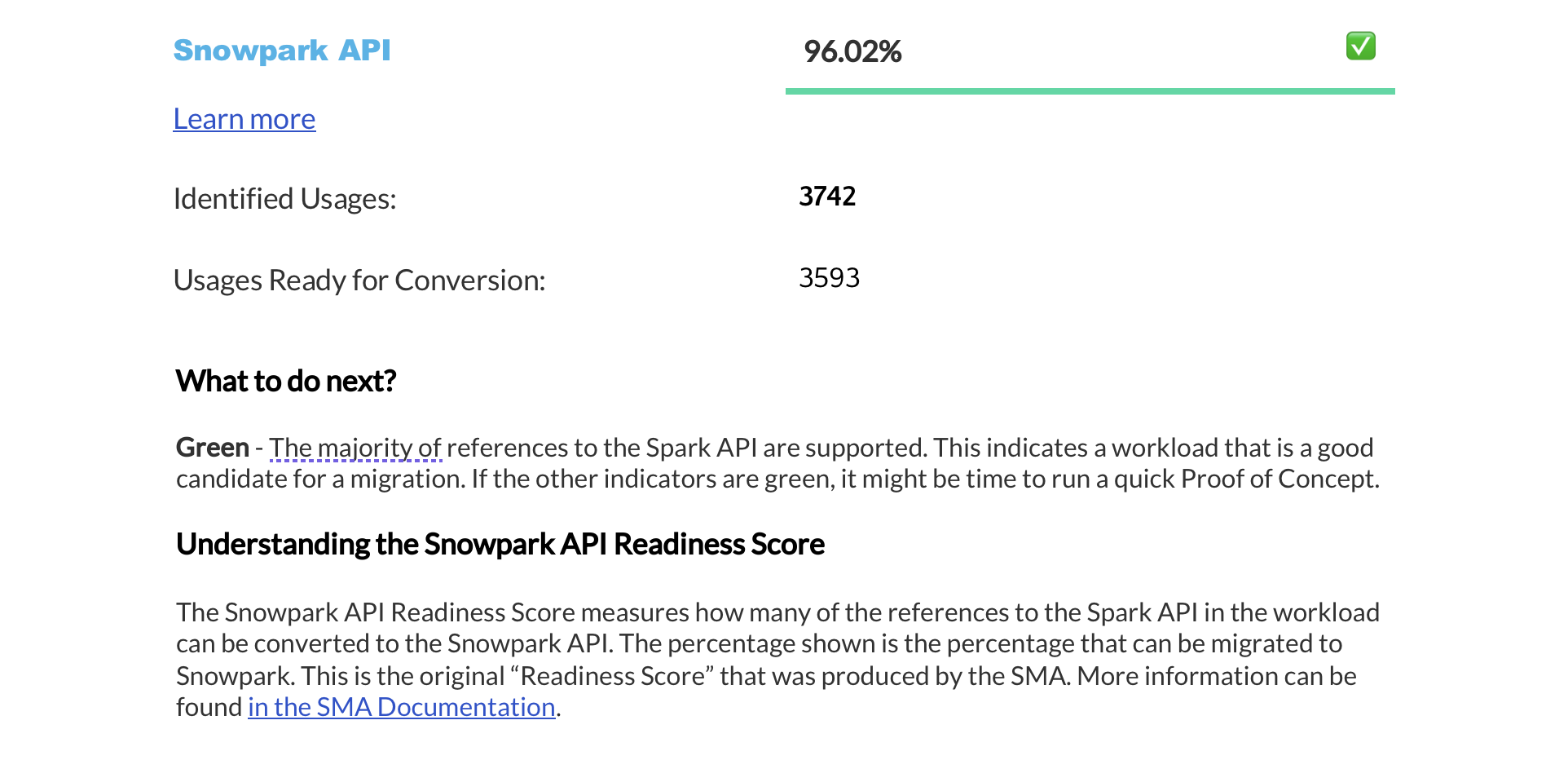
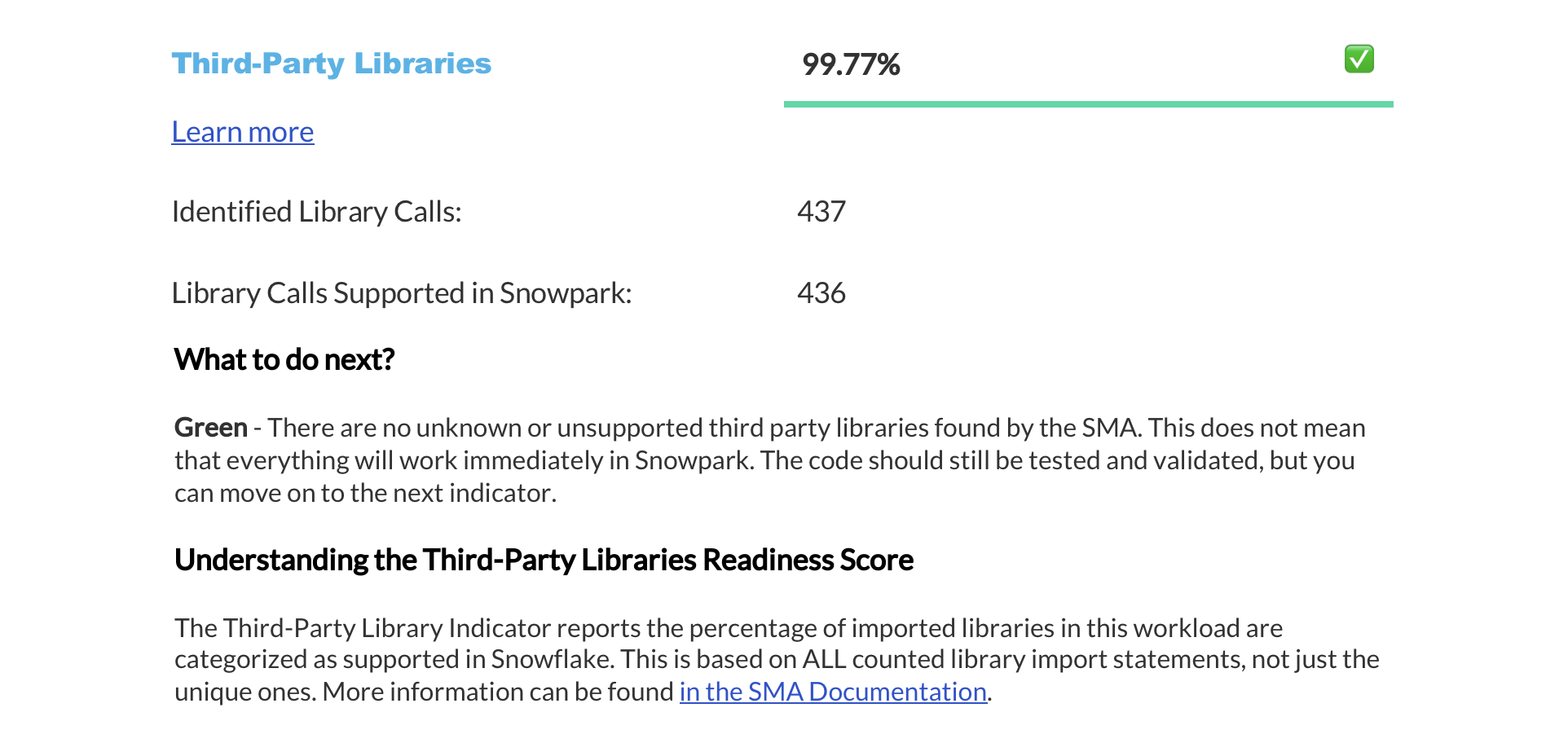
Résumé des scores de préparation¶
The next page displays a summary of readiness scores. It includes scores for Spark API and Third-Party libraries, along with guidance on how to interpret them. These scores help you understand how well-prepared your codebase is for migration to Snowflake.

Cette section fournit des informations détaillées sur chaque score de préparation.
Résumé du fichier¶
La section relative au résumé du fichier commence à la page suivante. Cette section peut s’étendre sur plusieurs pages en fonction du nombre de types de fichiers différents traités au cours de l’exécution de cet outil.
Ces informations sont également disponibles dans le résumé de l’évaluation présenté dans l’application.
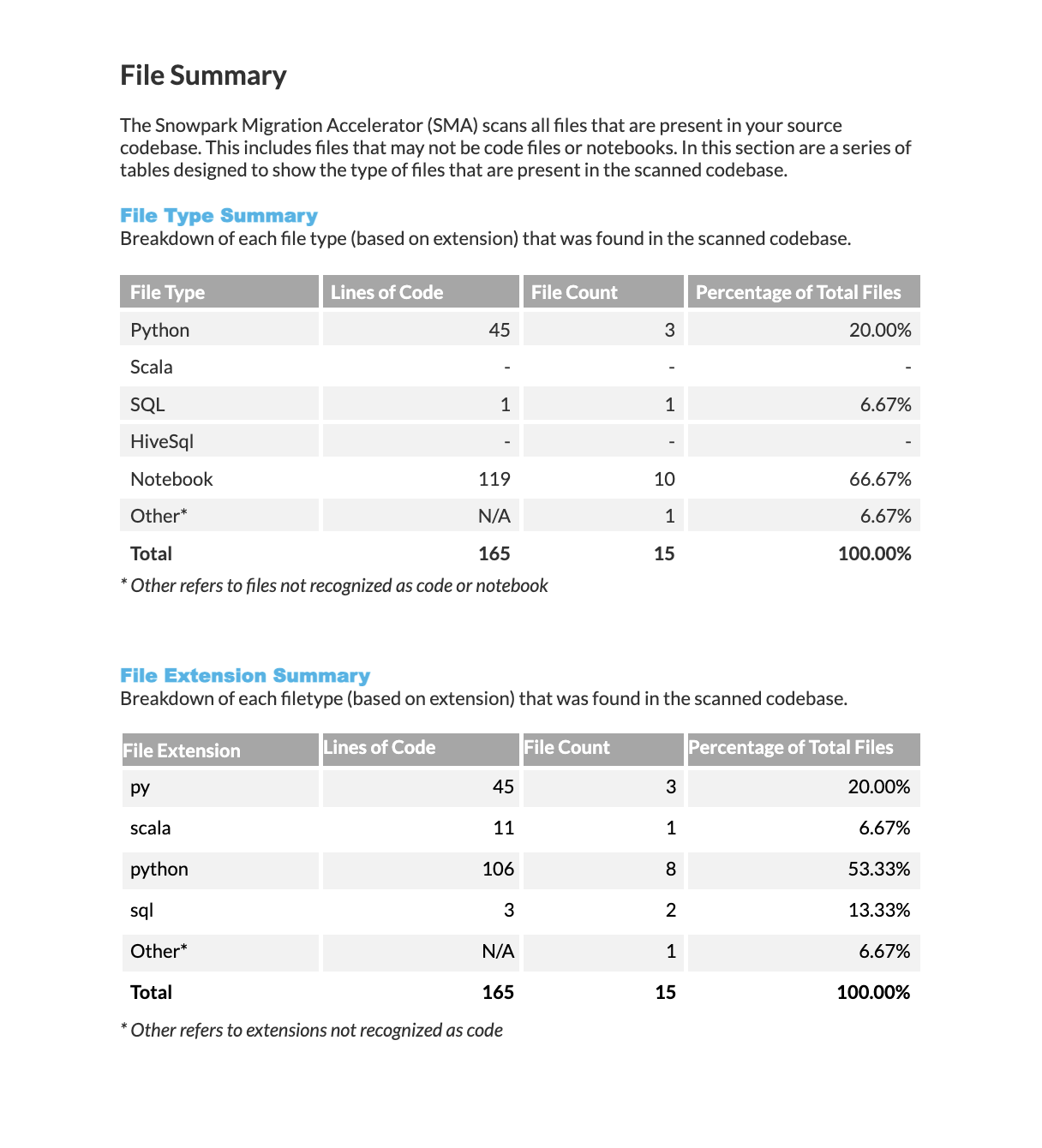
Résumé des types de fichiers : Affiche une ventilation des technologies reconnues, y compris le nombre de fichiers pour chaque type de technologie, le nombre total de lignes de code et le pourcentage qu’ils représentent par rapport à l’ensemble des fichiers analysés.
Résumé des extensions de fichiers : Affiche des statistiques pour chaque extension de fichier reconnue, notamment le nombre de fichiers portant cette extension, le nombre total de lignes de code qu’ils contiennent et le pourcentage qu’ils représentent par rapport à l’ensemble des fichiers analysés.
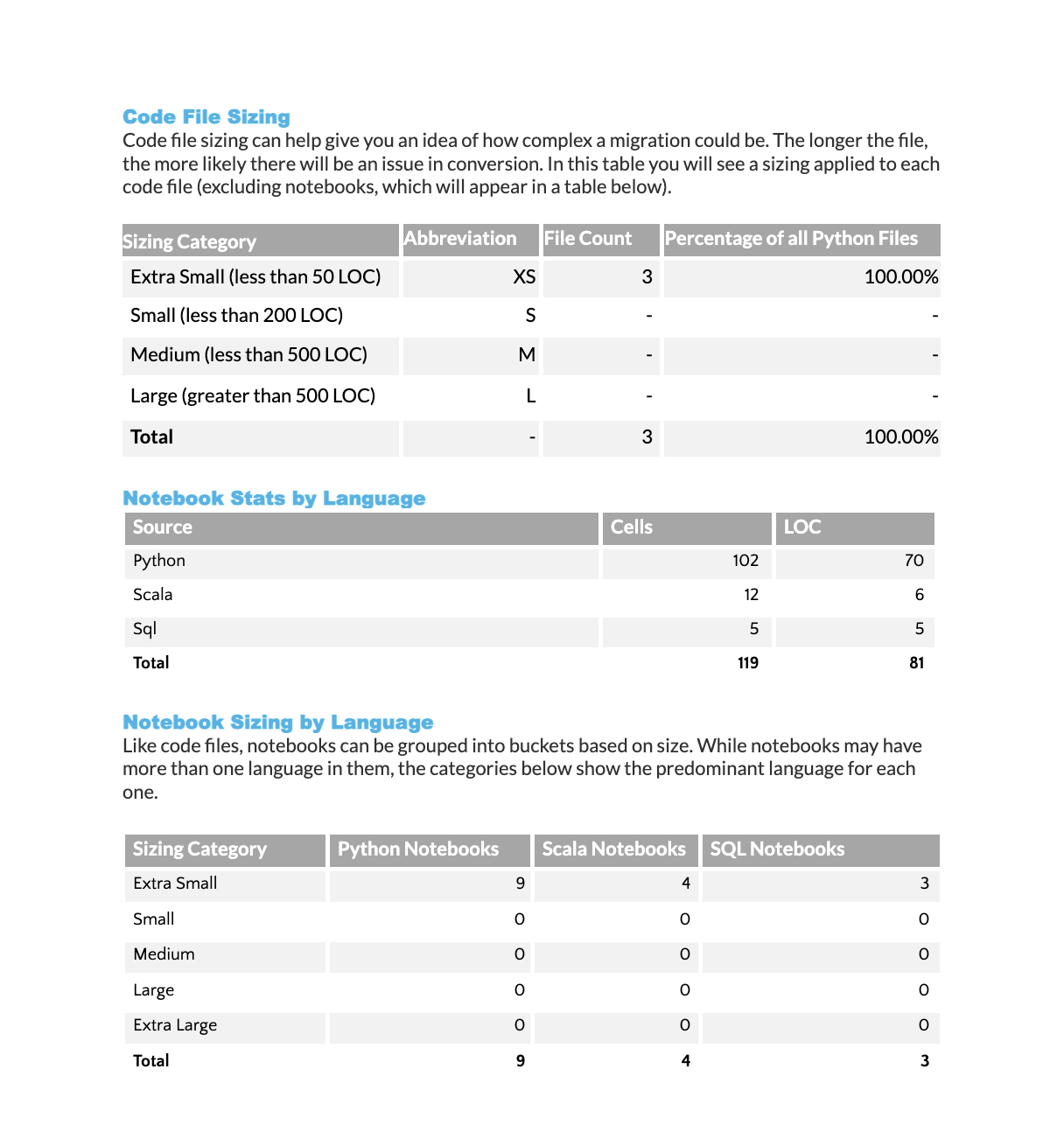
Analyse de la taille des fichiers de code : Affiche la répartition des fichiers de code par catégories de taille (méthode Taille de t-shirt). Chaque catégorie de taille indique le nombre de fichiers et leur pourcentage de l’ensemble de la base de code.
Statistiques sur les langues des notebooks : Fournit une ventilation des lignes de code et des cellules par langue de programmation pour tous les notebooks analysés.
Classification de la taille des notebooks par langue : Classe chaque fichier notebook par taille en fonction du nombre total de lignes de code qu’il contient. Le type de notebook (Python, Scala ou SQL) est déterminé par la langue prédominante utilisée. Les catégories de taille sont les suivantes :
XS : Moins de 50 lignes
S : 50 à 200 lignes
M : 200 à 500 lignes
L : 500 à 1 000 lignes
XL : Plus de 1 000 lignes
Résumé de l’API Spark¶
Le résumé de l’API Spark fournit une analyse détaillée du score de préparation indiqué dans la section Score de préparation. Cette section contient quatre tables :
Une liste de fichiers contenant les références d’API Spark
Une ventilation des fonctions prises en charge et non prises en charge
Le score de préparation organisé selon les catégories d’API Spark
Le score de préparation organisé par statut de mappage
Nous vous expliquerons les références d’API Spark qui sont prises en charge et celles qui ne le sont pas. Voici ce que signifient ces termes :
Pris en charge : L’outil Snowpark Migration Accelerator (SMA) peut automatiquement convertir cet élément d’API en API Snowpark ou fournir une solution de contournement connue.
Non pris en charge : L’outil Snowpark Migration Accelerator (SMA) ne peut pas convertir automatiquement cet élément d’API en API Snowpark. Cela ne signifie pas que la conversion est impossible, mais elle nécessitera une intervention manuelle.
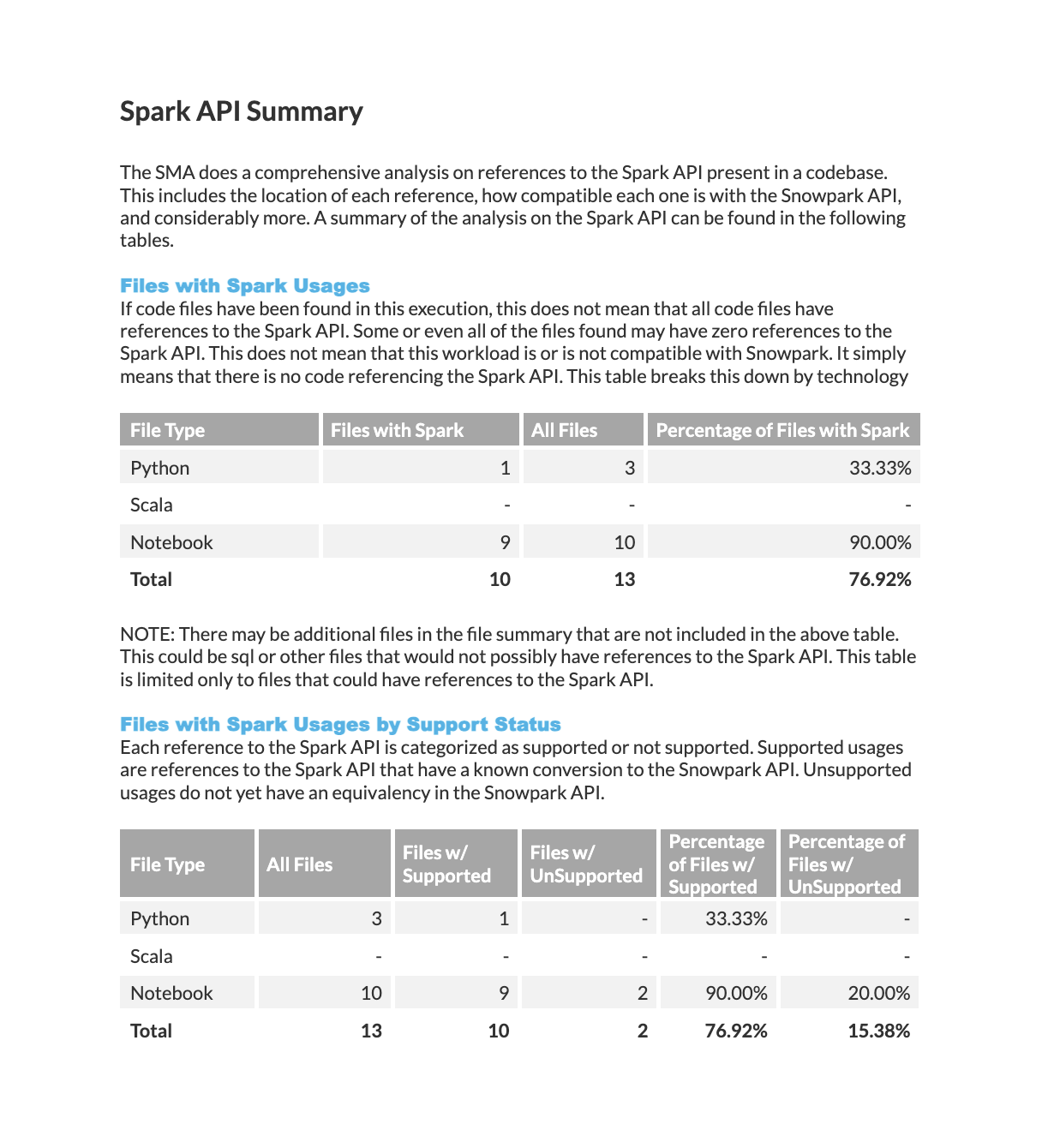
Fichiers avec références Spark : Cette table présente une répartition de l’utilisation de la technologie Spark dans votre charge de travail, classée par type de technologie.
Fichiers avec statut de prise en charge Spark : Cette table affiche le nombre de fonctions Spark prises en charge et non prises en charge dans votre code source, organisées par type de technologie.

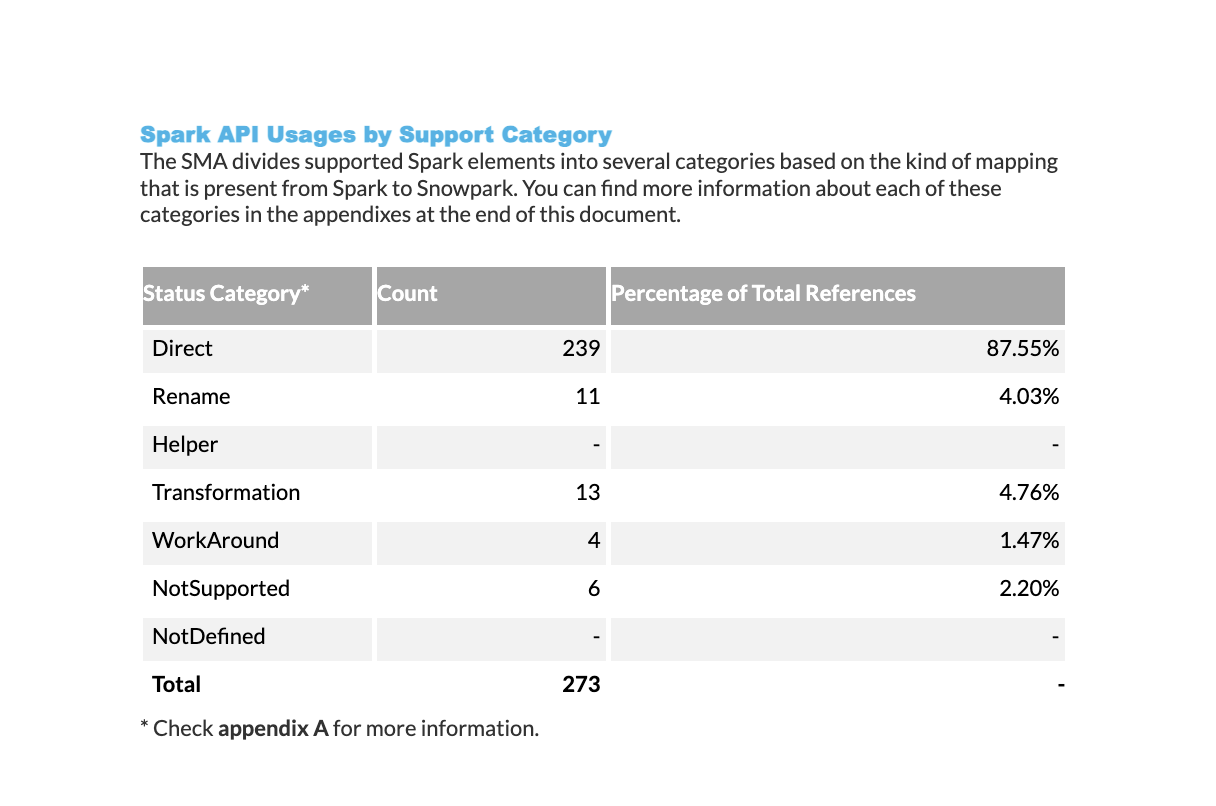
Résumé de l’utilisation de l’API Spark : Table montrant combien de fonctions d’API Spark sont prises en charge et non prises en charge dans Python et Scala. La table est organisée par catégorie d’API et comprend un score de préparation Spark API qui correspond au score indiqué dans la section Score de préparation.
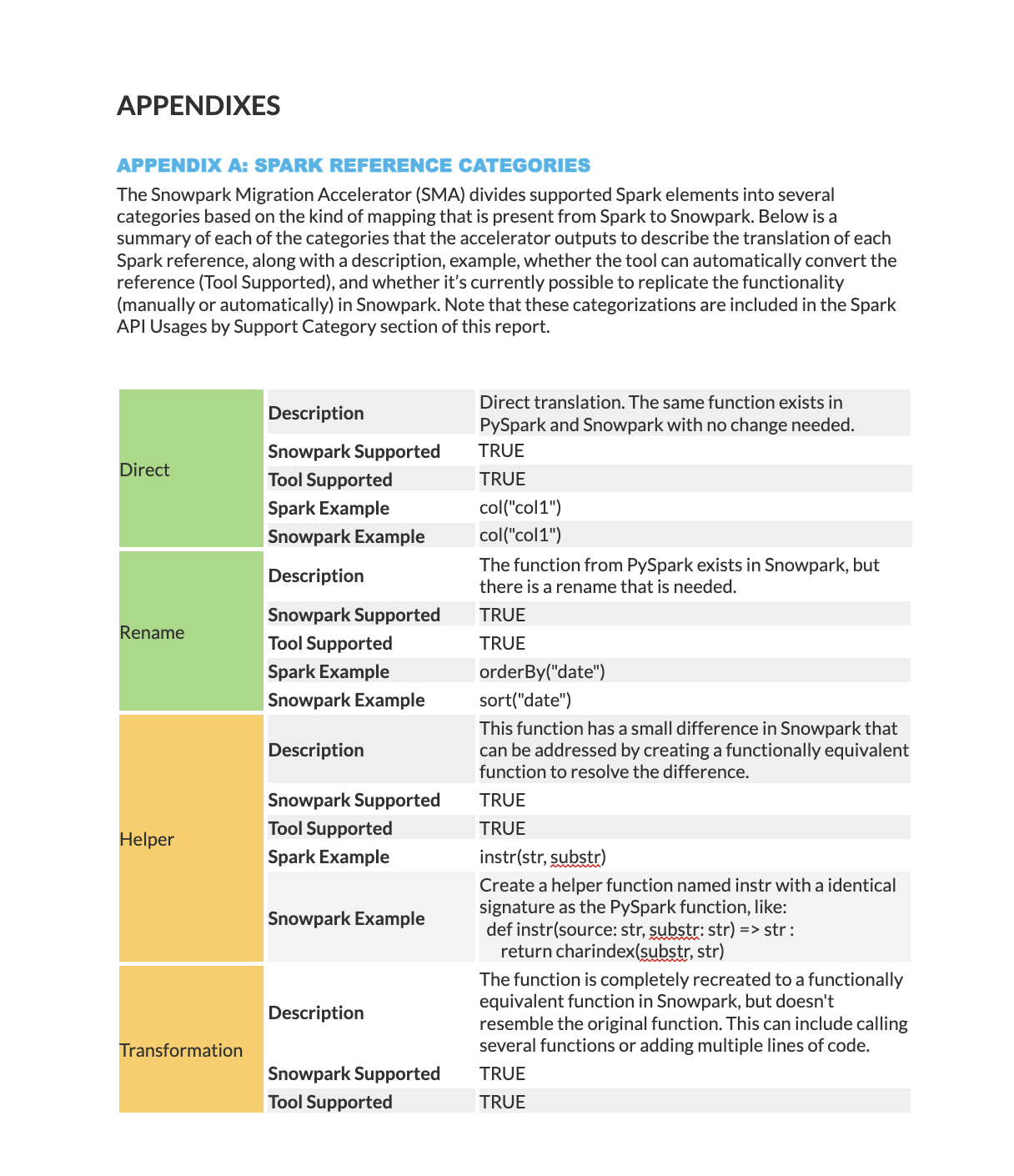
Catégories de prise en charge de l’utilisation d’API Spark : Répartition du nombre de fois où les fonctions d’API Spark sont utilisées dans votre code, organisée en fonction de leur statut de prise en charge. Pour une description détaillée de chaque catégorie de prise en charge, consultez la page Catégories de référence Spark.
Résumé de l’utilisation d’API Pandas¶
Note
Le résumé de l’utilisation d’API Pandas n’est disponible que pour les exécutions qui contiennent des fichiers Python.
Le résumé de l’utilisation d’API Pandas fournit une liste de références à l’API Pandas, similaire au résumé de l’API Spark présenté précédemment.
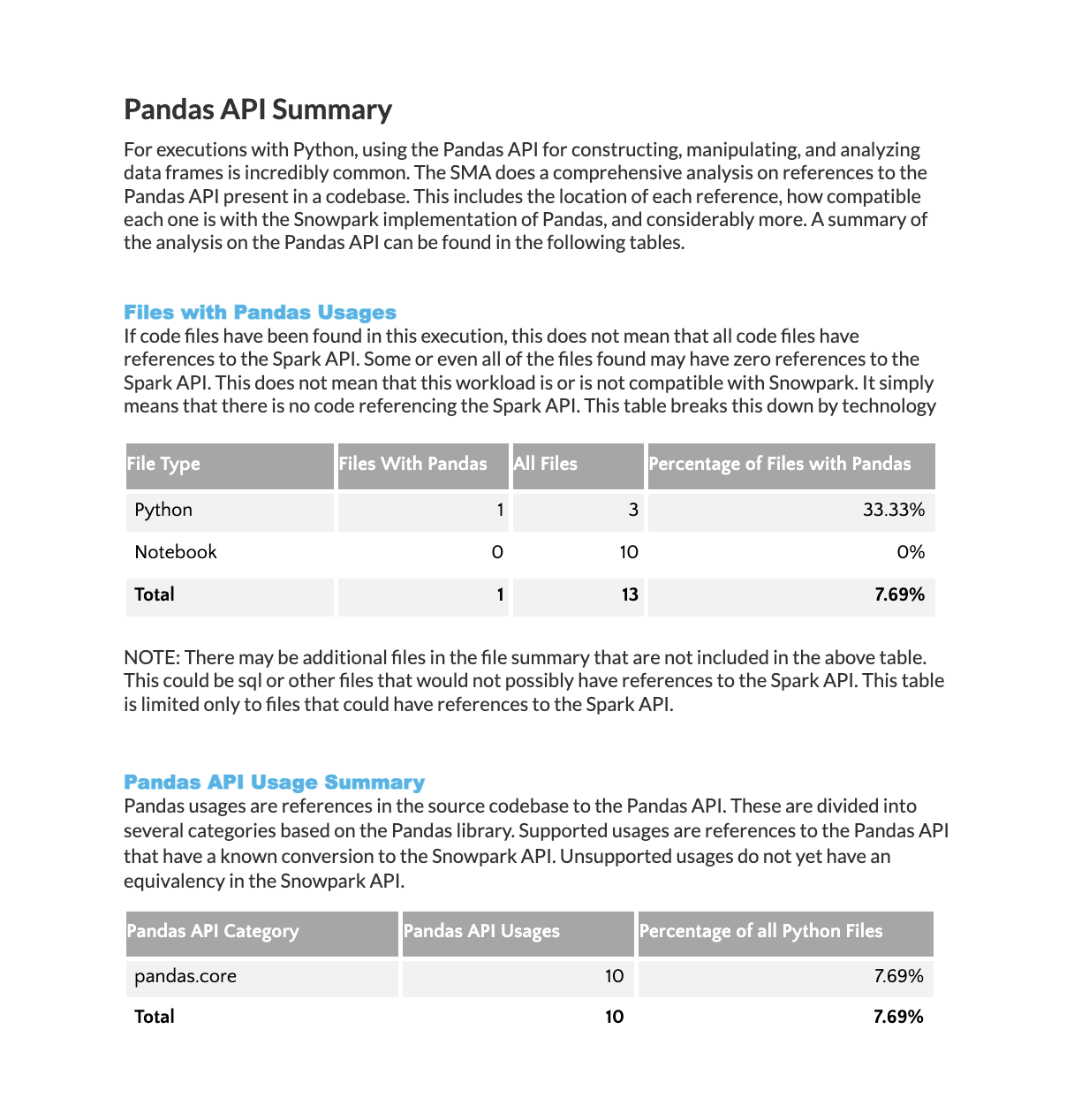
Fichiers avec utilisation de Pandas : Répartition montrant le nombre de références Pandas trouvées dans chaque technologie sur l’ensemble de votre charge de travail.
Résumé de l’utilisation d’API Pandas : Liste détaillée des fonctions de la bibliothèque Pandas utilisées dans votre code source, classées par fréquence d’utilisation.
Résumé de la référence d’importation¶
La section Analyse des importations affiche toutes les dépendances externes importées dans votre base de code. Cela inclut les bibliothèques tierces et autres composants externes utilisés dans tous les fichiers. Notez que les importations provenant de fichiers de votre propre base de code ne figurent pas dans cette table.
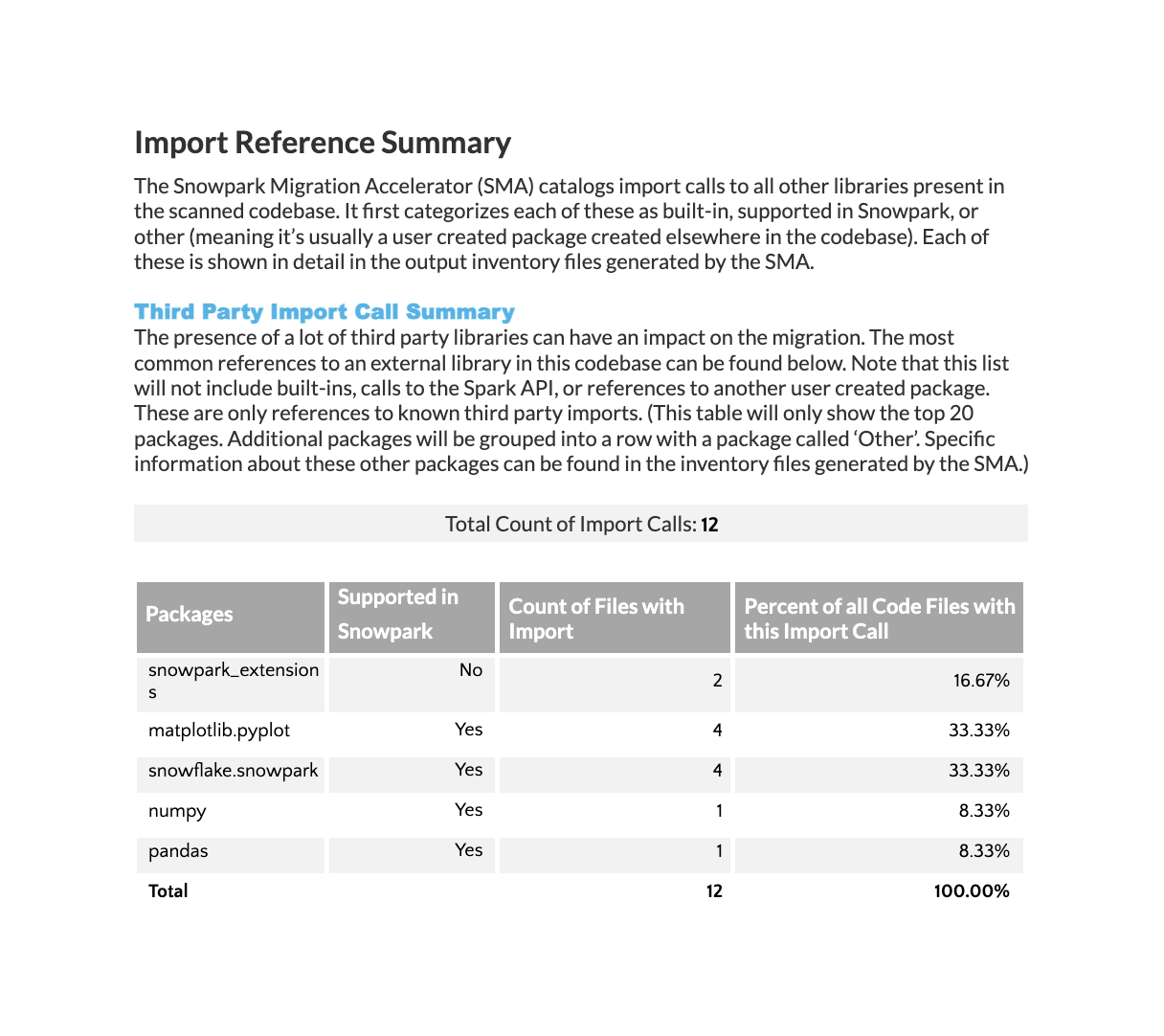
La table affiche les informations sur le paquet Python avec les détails suivants :
Noms des paquets importés
Si chaque paquet est pris en charge dans la répartition Anaconda de Snowpark
Nombre de fois où chaque paquet apparaît dans les importations
Pourcentage de fichiers contenant chaque importation
Notez que si le total de la colonne « Pourcentage » est égal à 100 %, la somme des pourcentages individuels peut être supérieure à 100 % car les fichiers contiennent souvent plusieurs importations de paquets.
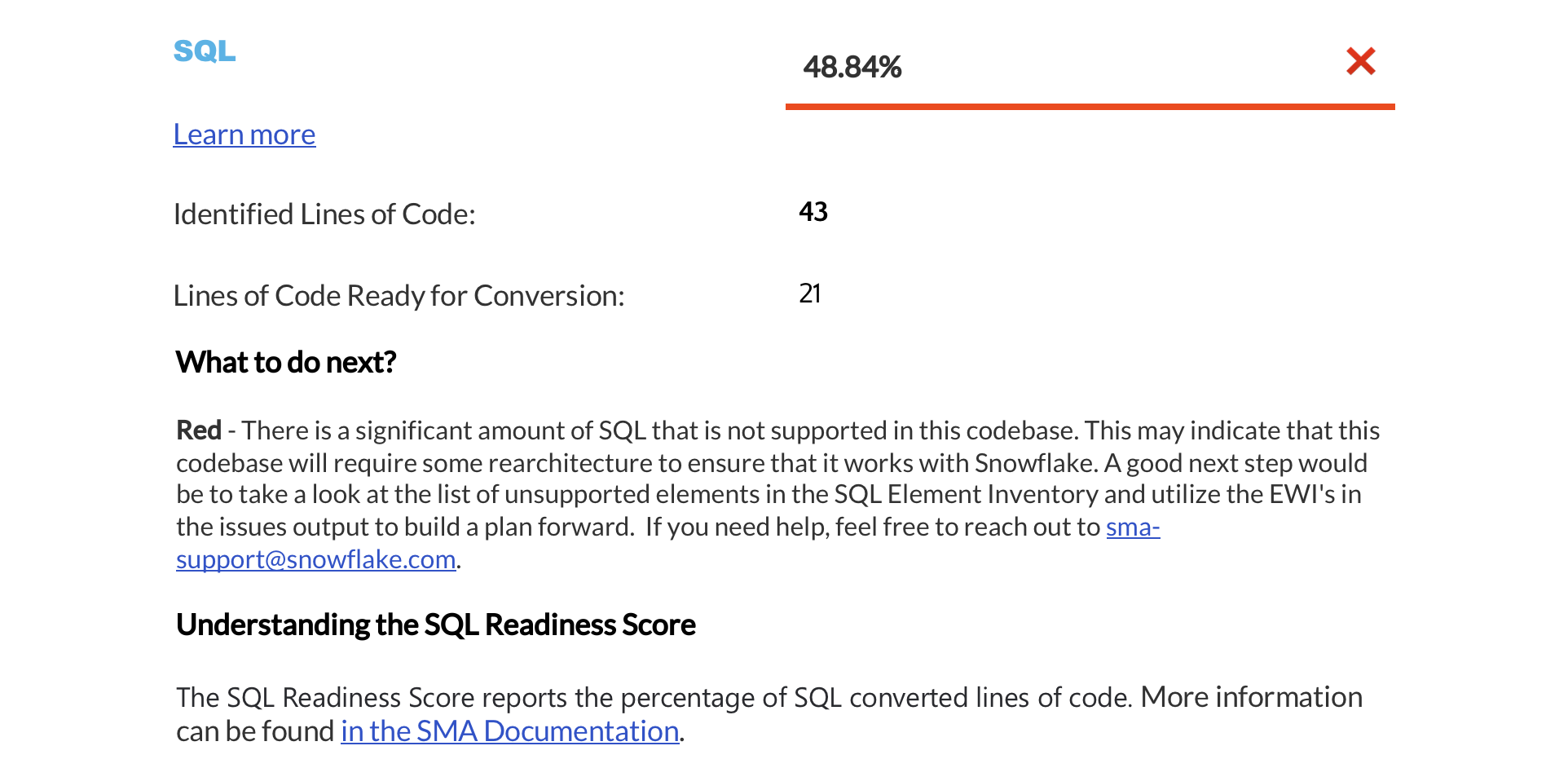
Résumé de la référence SQL¶

Utilisation SQL par type de fichier : Cette table classe l’utilisation SQL en fonction des différentes technologies, en indiquant le nombre total de fichiers SQL et de cellules SQL trouvés dans votre charge de travail.
Utilisation SQL par statut de prise en charge : Cette table organise les éléments SQL en fonction de l’existence ou non d’une fonction équivalente dans Snowflake.
Snowpark Migration Accelerator (SMA) : Résumé des problèmes¶
L’outil Snowpark Migration Accelerator (SMA) crée des rapports de problèmes chaque fois qu’il détecte des avertissements, des erreurs de conversion ou des erreurs d’analyse dans votre code. La résolution de ces problèmes est essentielle pour mener à bien une migration de code à l’aide de SMA.
Pour un guide détaillé sur la compréhension et l’analyse des problèmes, veuillez vous référer à la section sur l’analyse des problèmes de notre documentation.
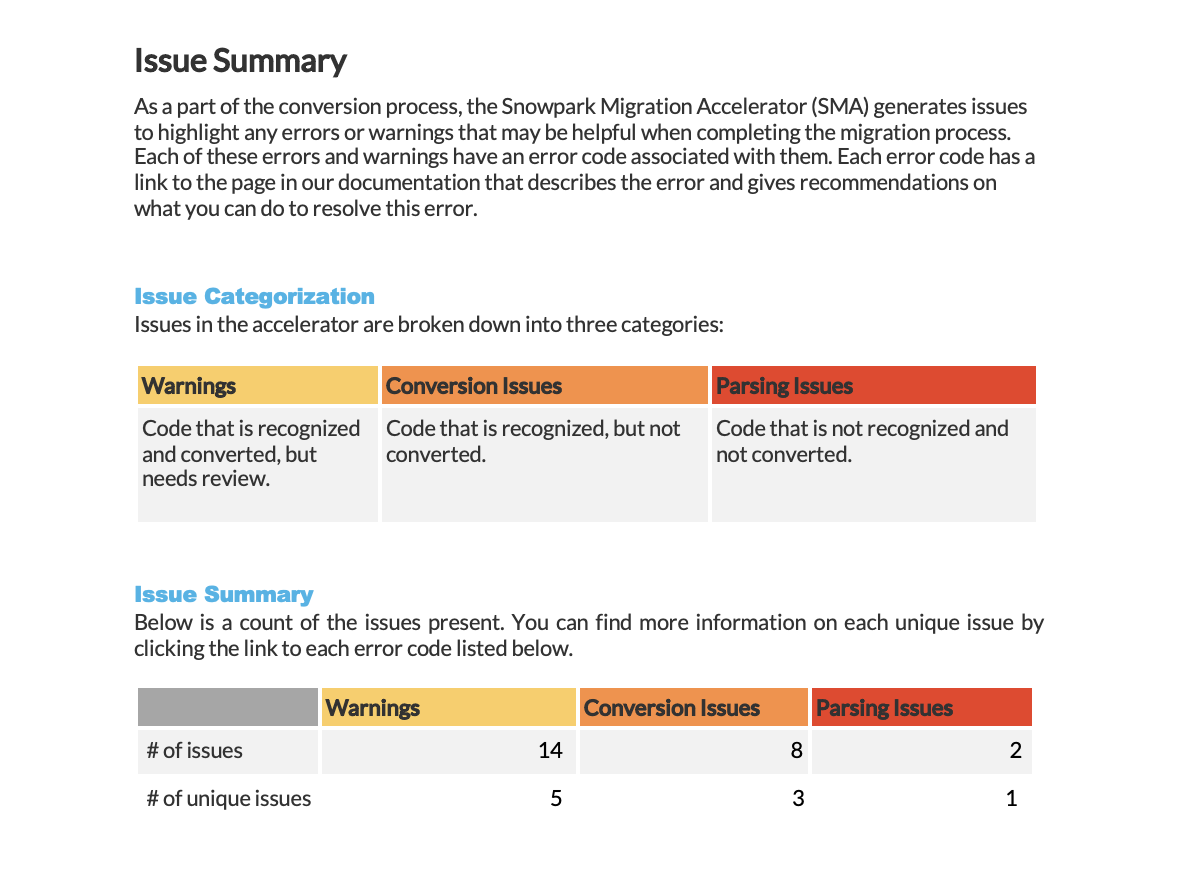
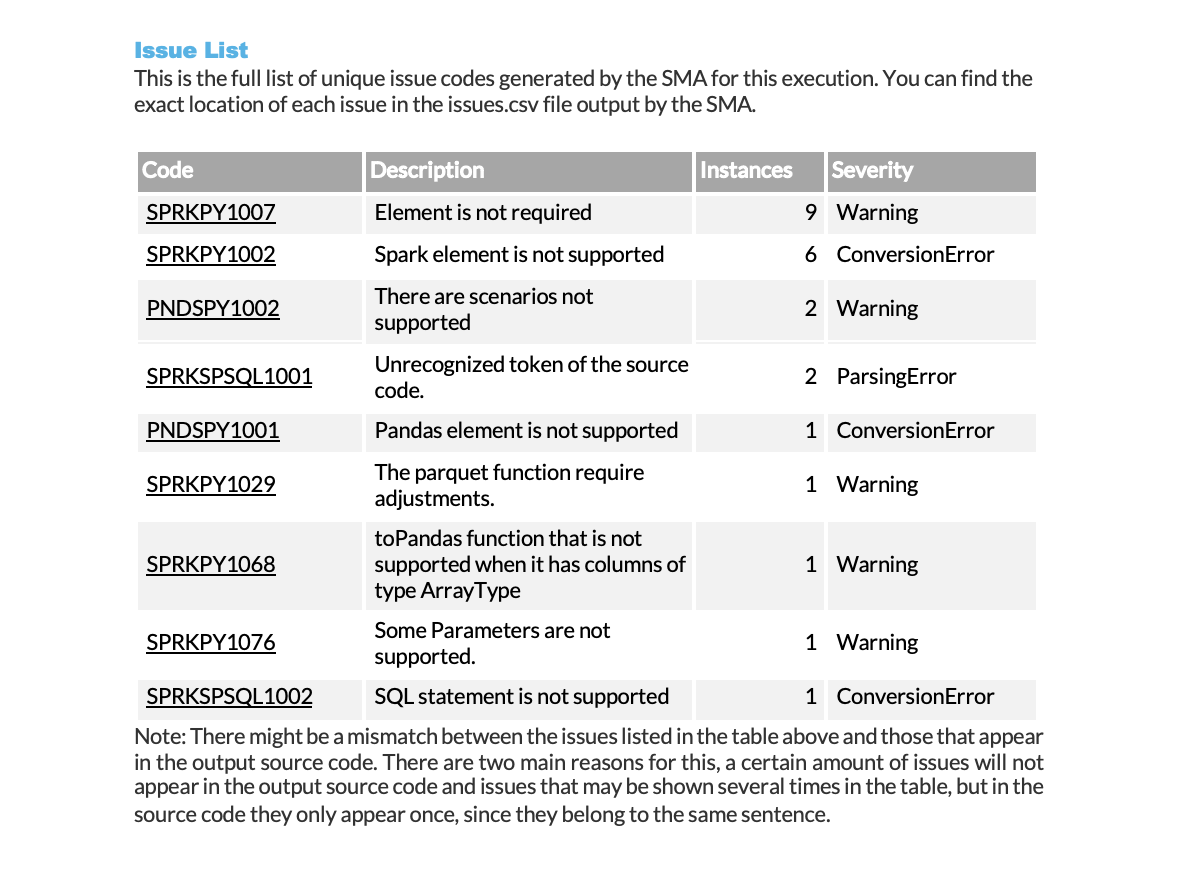
Le résumé affiche chaque problème avec les informations suivantes :
Code de problème (avec un lien vers une documentation détaillée)
Nombre d’occurrences dans la charge de travail
Niveau de gravité
Le rapport affiche trois niveaux de gravité (Avertissement, Erreur de conversion et Erreur d’analyse) ainsi qu’un résumé organisé par niveau.
Lorsque vous travaillez avec des outils de migration, suivez ces priorités pour traiter les différents types de problèmes :
Traiter d’abord les erreurs d’analyse, car elles requièrent une attention immédiate
Résoudre les erreurs de conversion grâce à des solutions programmatiques
Contrôler et suivre les avertissements tout au long du processus de migration
Annexes
L’annexe A fournit des descriptions détaillées de toutes les catégories de statut de mappage.
Ce rapport complet contient des informations détaillées recueillies à partir des fichiers d’inventaire que l’outil Snowpark Migration Accelerator (SMA) génère.
Pour obtenir des informations détaillées sur le rapport, veuillez contacter l’équipe Snowpark Migration Accelerator (SMA) à l’adresse suivante : sma-support@snowflake.com.
Danger
La fonction Rapport du résumé a été supprimée et n’est plus disponible à partir de Spark Conversion Core V2.43.0
L’outil SMA génère plusieurs rapports de sortie, dont les résultats comprennent des feuilles de calcul détaillées.