Snowpark Migration Accelerator: Kuratierte Berichte¶
Der Snowpark Migration Accelerator (SMA) erstellt durch die Analyse von detaillierten Daten umfassende Bewertungsberichte. Im folgenden Abschnitt finden Sie eine Liste dieser verfügbaren Berichte.
Die Ergebnisse der Bewertung, einschließlich detaillierter Bestandsaufnahmen aller Elemente, finden Sie in den Tabellen auf den folgenden Seiten.
Detaillierter Bericht¶
Gefahr
Der Bericht DetailedReport.html ist veraltet und wird ab Spark Conversion Core V2.43.0 nicht mehr unterstützt
Bemerkung
Auf dieser Seite werden die einzelnen Abschnitte des detaillierten Berichts erläutert, wie sie in der Dokumentendatei dargestellt sind.
Der detaillierte SMA-Bericht ist der wichtigste Analysebericht, der umfassende Informationen in mehreren Abschnitten enthält.
Der Bewertungsbericht enthält die folgenden Abschnitte und ihre Beschreibungen:
Die erste Seite des detaillierten Berichts gibt einen kurzen Überblick über das Tool Snowpark Migration Accelerator (SMA).

Diese Seite enthält den folgenden Unterabschnitt:
Der Abschnitt „Ausführungszusammenfassung“ wird angezeigt:
Ihr Organisationsname und Ihre E-Mail-Adresse aus den Einstellungen Ihrer Projekterstellung
Eine eindeutige Identifikationsnummer für jede SMA-Ausführung (auf diese ID wird im gesamten Inventarabschnitt Bezug genommen)
Der Zeitstempel der Ausführung
Versionsdetails für SMA und Snowpark API
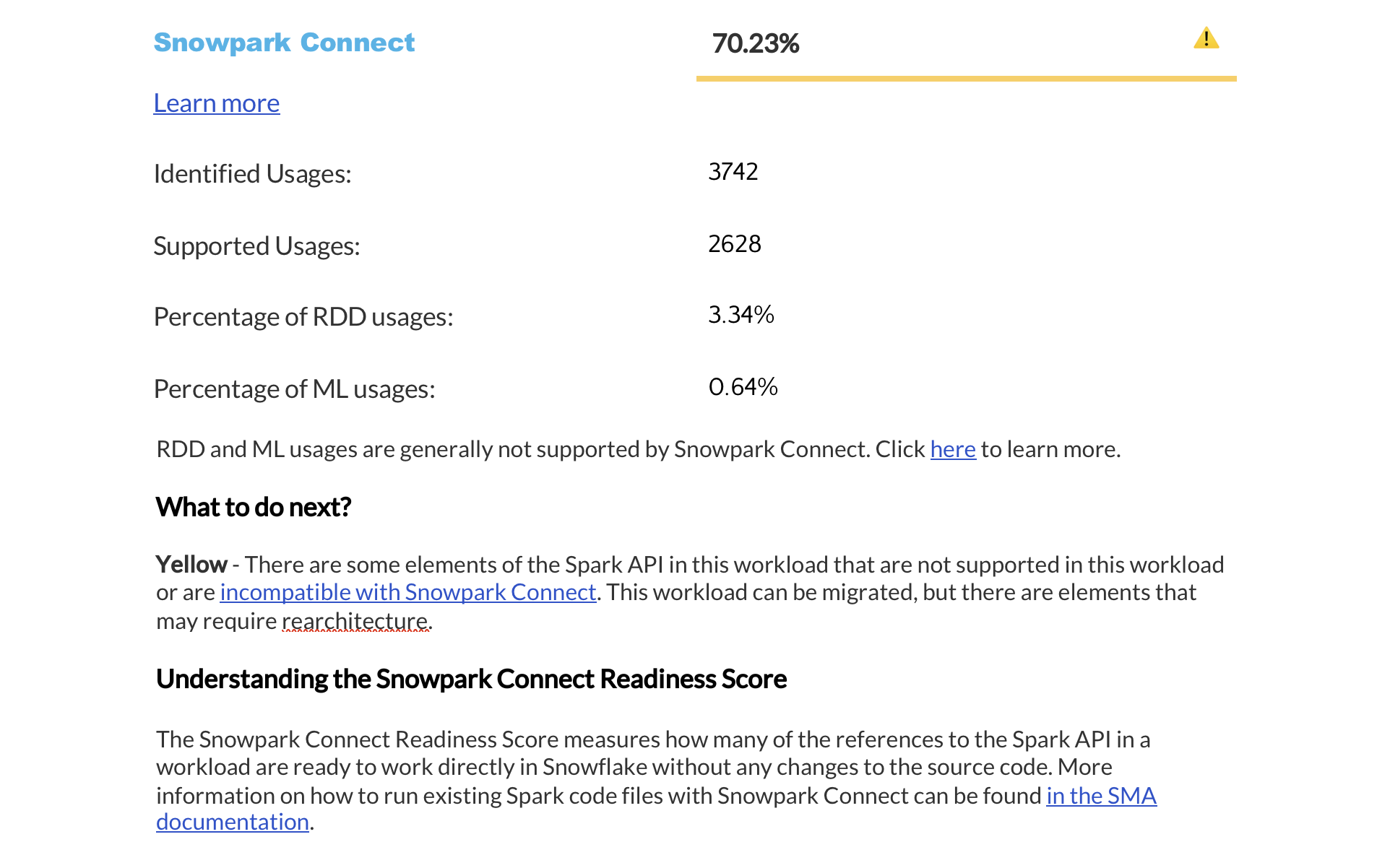
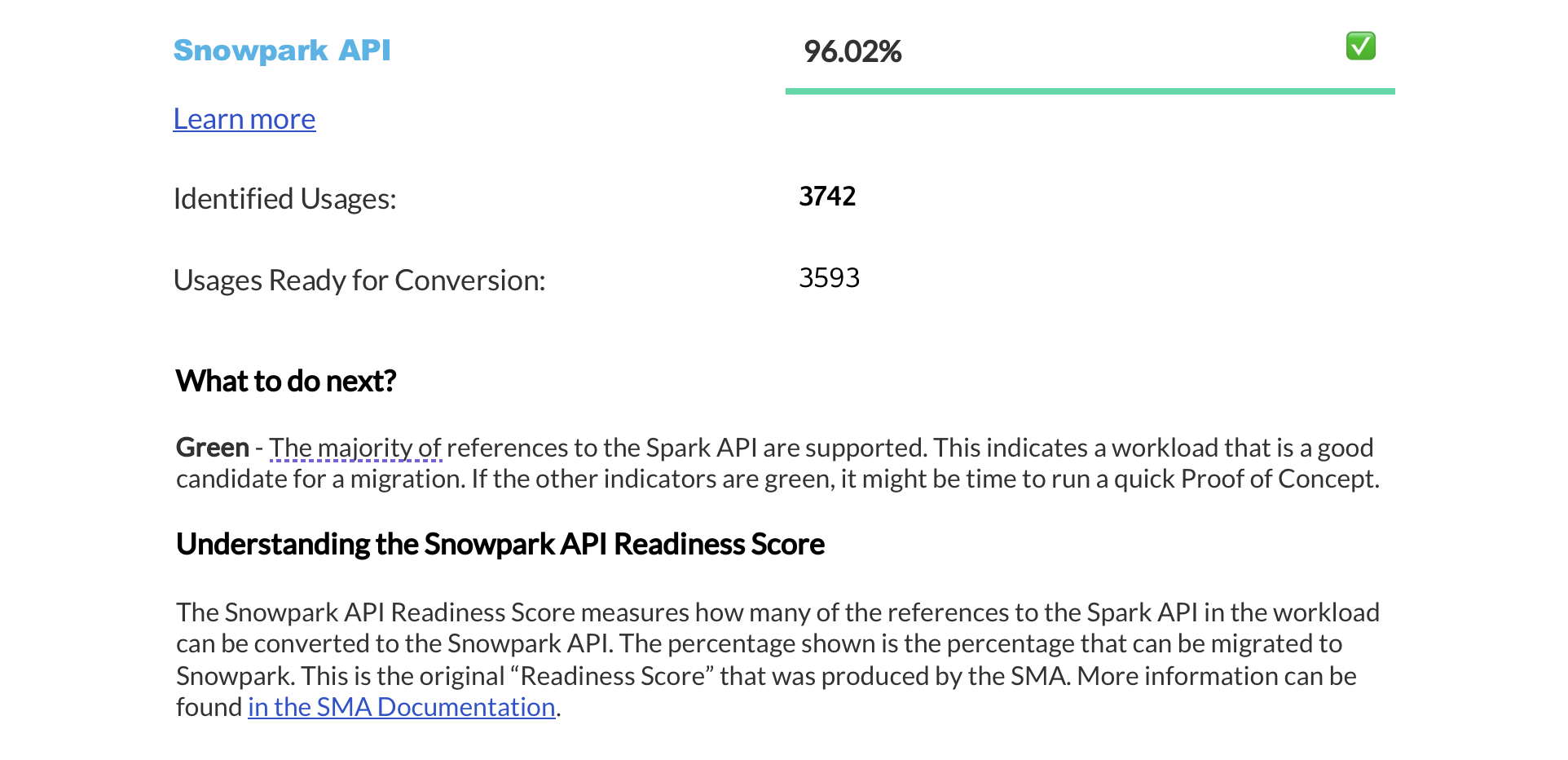
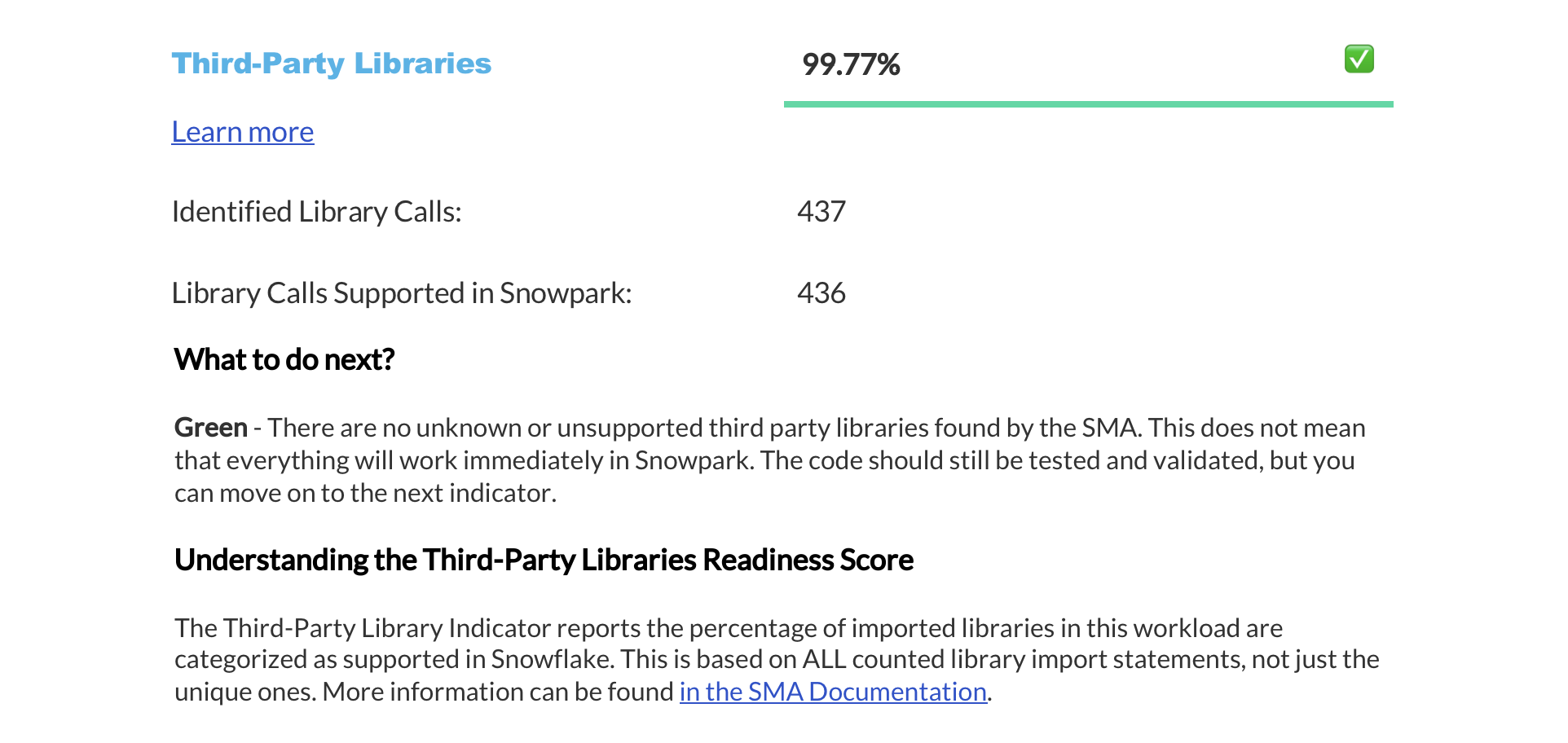
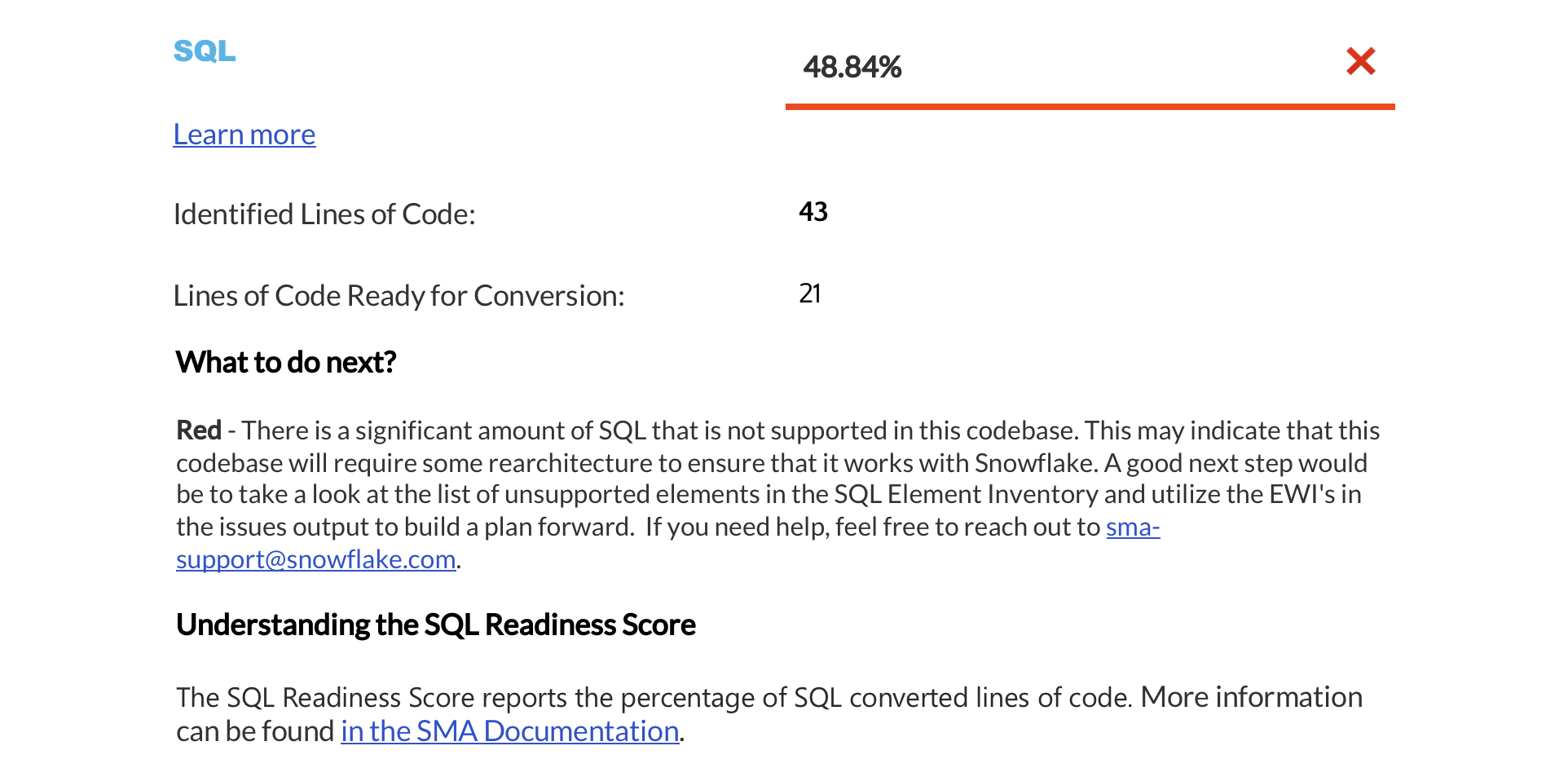
Zusammenfassung der Bereitschaftsbewertungen¶
The next page displays a summary of readiness scores. It includes scores for Spark API and Third-Party libraries, along with guidance on how to interpret them. These scores help you understand how well-prepared your codebase is for migration to Snowflake.

In diesem Abschnitt finden Sie detaillierte Informationen zu den einzelnen Bereitschaftsbewertungen.
Dateizusammenfassung¶
Der Abschnitt mit der Dateizusammenfassung beginnt auf der folgenden Seite. Dieser Abschnitt kann sich über mehrere Seiten erstrecken, je nachdem, wie viele verschiedene Dateitypen bei der Ausführung dieses Tools verarbeitet wurden.
Diese Informationen finden Sie auch in der Anwendung enthaltenen Bewertungszusammenfassung.
.png> „Bild“)
Zusammenfassung der Dateitypen: Zeigt eine Aufschlüsselung der erkannten Technologien an, einschließlich der Anzahl der Dateien für jeden Technologietyp, der gesamten Codezeilen und des prozentualen Anteils der Dateien an allen analysierten Dateien.
Zusammenfassung der Dateierweiterung: Zeigt Statistiken für jede erkannte Dateierweiterung an, einschließlich der Anzahl der Dateien mit dieser Erweiterung, ihrer Gesamtanzahl an Codezeilen und ihres Anteils an allen analysierten Dateien.
.png> „Bild“)
Analyse der Größe von Codedateien: Zeigt die Verteilung der Codedateien nach Größenkategorie an („T-Shirt“-Größe). Jede Größenkategorie zeigt die Anzahl der Dateien und ihren prozentualen Anteil an der gesamten Codebasis.
Notebook-Sprachstatistik: Liefert eine Aufschlüsselung der Codezeilen und Zellen nach Programmiersprache für alle gescannten Notebooks.
Klassifizierung der Notebook-Größe nach Sprache: Kategorisiert jede Notebook-Datei nach ihrer Größe auf der Grundlage der Gesamtanzahl der Codezeilen. Der Notebook-Typ (Python, Scala oder SQL) wird durch die vorherrschende Sprache bestimmt. Die Größenkategorien sind:
XS: Unter 50 Zeilen
S: 50-200 Zeilen
M: 200-500 Zeilen
L: 500-1.000 Zeilen
XL: Über 1.000 Zeilen
Spark API-Zusammenfassung¶
Die Spark API-Zusammenfassung bietet eine detaillierte Analyse der Bereitschaftsbewertung, die im Abschnitt Bereitschaftsbewertung angezeigt wird. Dieser Abschnitt enthält vier Tabellen:
Eine Liste von Dateien mit Spark API-Referenzen
Eine Aufschlüsselung der unterstützten und nicht unterstützten Features
Das Ergebnis der Bereitschaft, geordnet nach Spark API-Kategorien
Die Bereitschaftsbewertung, geordnet nach Zuordnungsstatus
Wir erklären Ihnen, welche Spark API-Referenzen unterstützt und welche nicht unterstützt werden. Hier erfahren Sie, was diese Begriffe bedeuten:
Unterstützt: Der Snowpark Migration Accelerator (SMA) kann dieses API-Element automatisch in das Snowpark API konvertieren oder eine bekannte Problemumgehung anbieten.
Wird nicht unterstützt: Der Snowpark Migration Accelerator (SMA) kann dieses API-Element nicht automatisch in das Snowpark API konvertieren. Das bedeutet nicht, dass die Konvertierung unmöglich ist, aber sie erfordert einen manuellen Eingriff.
.png> „Bild“)
Dateien mit Spark-Referenzen: Diese Tabelle zeigt eine Aufschlüsselung der Nutzung der Spark-Technologie in Ihrem Workload, kategorisiert nach Technologietyp.
Dateien mit Spark-Unterstützungsstatus: Diese Tabelle zeigt die Anzahl der unterstützten und nicht unterstützten Spark-Features in Ihrem Quellcode, geordnet nach Technologietyp.
.png> „Bild“)
.png> „Bild“)
Spark API-Verwendungszusammenfassung: Eine Tabelle, die zeigt, wie viele Funktionen von Spark API in Python und Scala unterstützt werden und welche nicht. Die Tabelle ist nach der API-Kategorie geordnet und enthält einen Spark API-Bereitschaftsbewertung, die mit der im Abschnitt „Bereitschaftsbewertung“ angezeigten Bewertung übereinstimmt.
Spark API-Verwendungsunterstützungskategorien: Eine Aufschlüsselung, wie oft die Funktionen von Spark API in Ihrem Code verwendet werden, geordnet nach ihrem Unterstützungsstatus. Ausführliche Beschreibungen der einzelnen Support-Kategorien finden Sie unter der Spark-Referenz-Kategorien-Seite.
Pandas API-Verwendungszusammenfassung¶
Bemerkung
Die Pandas API-Verwendungszusammenfassungist nur für Ausführungen verfügbar, die Python-Dateien enthalten.
Die Pandas API-Zusammenfassung bietet eine Liste von Referenzen auf die Pandas API, ähnlich wie die zuvor gezeigte Spark API-Zusammenfassung.
.png> „Bild“)
Dateien mit Pandas-Verwendung: Eine Aufschlüsselung, die die Anzahl der Pandas-Referenzen zeigt, die in jeder Technologie in Ihrem gesamten Workload gefunden wurden.
Pandas API-Verwendungszusammenfassung: Eine detaillierte Liste der in Ihrem Quellcode verwendeten Funktionen der Pandas-Bibliothek, sortiert nach Häufigkeit der Verwendung.
Zusammenfassung der Importreferenz¶
Im Abschnitt „Importanalyse“ werden alle externen Abhängigkeiten angezeigt, die in Ihre Codebasis importiert wurden. Dazu gehören Bibliotheken von Drittanbietern und andere externe Komponenten, die in allen Dateien verwendet werden. Beachten Sie, dass Importe aus Dateien innerhalb Ihrer eigenen Codebasis in dieser Tabelle nicht angezeigt werden.
.png> „Bild“)
Die Tabelle zeigt Informationen zum Python-Paket mit den folgenden Details an:
Paketnamen, die importiert wurden
Ob die einzelnen Pakete in Snowpark’s Anaconda-Verteilung unterstützt werden
Anzahl, wie oft jedes Paket in Importen angezeigt wird
Prozentsatz der Dateien, die jeden Import enthalten
Beachten Sie, dass die Gesamtsumme der Spalte „Prozent“ zwar 100 % beträgt, die Summe der einzelnen Prozentsätze jedoch mehr als 100 % betragen kann, da Dateien oft mehrere Paketimporte enthalten.
SQL Referenz-Zusammenfassung¶
.png> „Bild“)
SQL Nutzung nach Dateityp: Diese Tabelle kategorisiert die Nutzung von SQL auf der Grundlage verschiedener Technologien und zeigt die Gesamtzahl der SQL-Dateien und SQL-Zellen, die in Ihrem Workload gefunden wurden.
SQL Verwendung nach Unterstützungsstatus: In dieser Tabelle sind die Elemente von SQL danach geordnet, ob sie ein entsprechendes Feature in Snowflake haben oder nicht.
Snowpark Migration Accelerator (SMA) Problemzusammenfassung¶
Der Snowpark Migration Accelerator (SMA) erstellt Problemberichte, wenn er Warnungen, Konvertierungs- oder Parsing-Fehler in Ihrem Code entdeckt. Die Lösung dieser Probleme ist eine wesentliche Voraussetzung für eine erfolgreiche Code-Migration mit SMA.
Eine ausführliche Anleitung zum Verständnis und zur Analyse von Problemen finden Sie unter dem Problemanalyseabschnitt in unserer Dokumentation.


Die Zusammenfassung zeigt jedes Problem mit den folgenden Informationen an:
Problemcode (mit einem Link zur ausführlichen Dokumentation)
Anzahl der Vorkommnisse im Workload
Schweregrad
Der Bericht zeigt drei Schweregrade an (Warnung, Konvertierungsfehler und Parsing-Fehler) und enthält eine Zusammenfassung für jeden Schweregrad.
Beachten Sie bei der Arbeit mit Migrationstools die folgenden Prioritäten für die Behandlung verschiedener Arten von Problemen:
Kümmern Sie sich zuerst um Parsing-Fehler, da diese sofortige Aufmerksamkeit erfordern
Beheben Sie Konvertierungsfehler durch programmatische Lösungen
Überwachen und verfolgen Sie Warnungen während des gesamten Migrationsprozesses
Anhänge
Anhang A enthält detaillierte Beschreibungen aller Kategorien des Zuordnungsstatus.
.png> „Bild“)
Dieser umfassende Bericht enthält detaillierte Informationen aus den Inventardateien, die der Snowpark Migration Accelerator (SMA) erzeugt.
Für detaillierte Informationen über den Bericht wenden Sie sich bitte an das Team von Snowpark Migration Accelerator (SMA) unter sma-support@snowflake.com.
Gefahr
Das Feature Zusammenfassungsbericht wurde entfernt und ist ab Spark Conversion Core V2.43.0 nicht mehr verfügbar
SMA generiert mehrere Ausgabeberichte, die detaillierte Tabellen mit den Ergebnissen enthalten.