Snowpark Migration Accelerator: Curated Reports¶
The Snowpark Migration Accelerator (SMA) generates comprehensive assessment reports by analyzing detailed data. The following section lists these available reports.
The assessment results, including detailed inventories of all elements, can be found in the spreadsheets on the following pages.
Detailed Report¶
Danger
The DetailedReport.html report has been deprecated and is no longer supported as of Spark Conversion Core V2.43.0
Note
This page explains each section of the detailed report as shown in the document file.
The SMA Detailed Report is the main analysis report that provides comprehensive information across multiple sections.
The assessment report contains the following sections and their descriptions:
The first page of the detailed report provides a concise overview of the Snowpark Migration Accelerator (SMA) tool.

This page contains the following subsection:
The Execution Summary section displays:
Your organization name and email address from your project creation settings
A unique identification number for each SMA execution (this ID is referenced throughout the inventories section)
The timestamp of execution
Version details for both SMA and Snowpark API
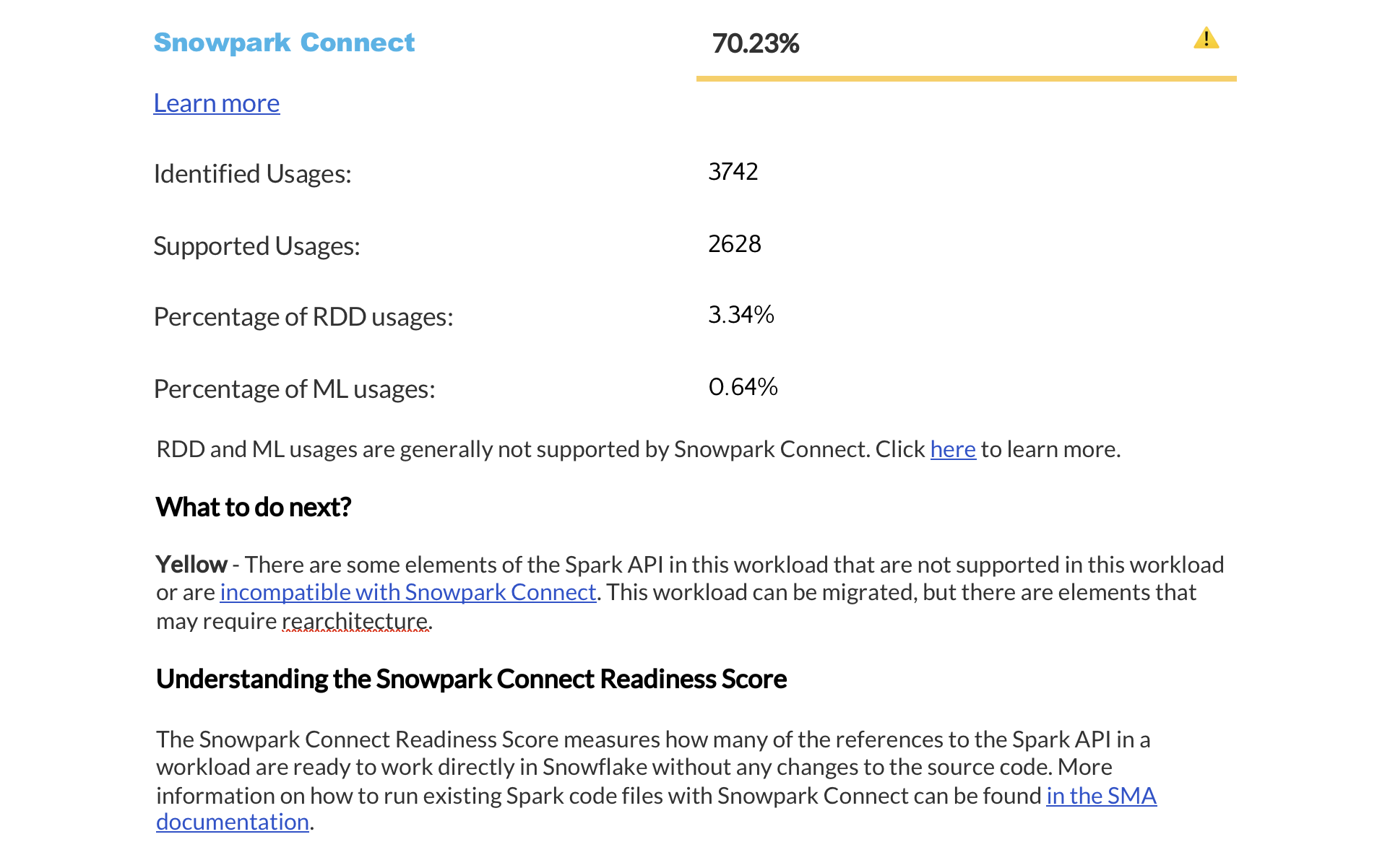
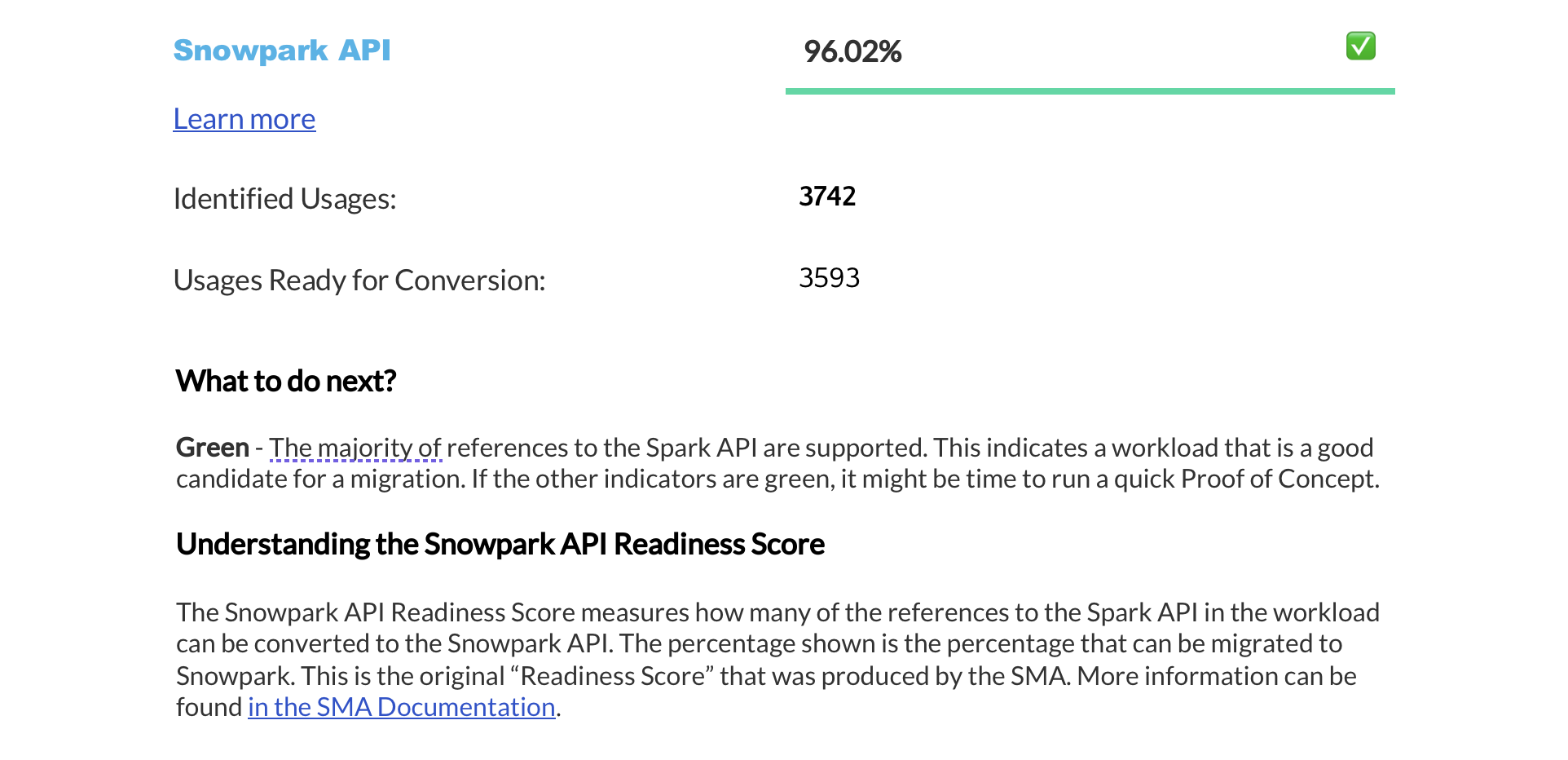
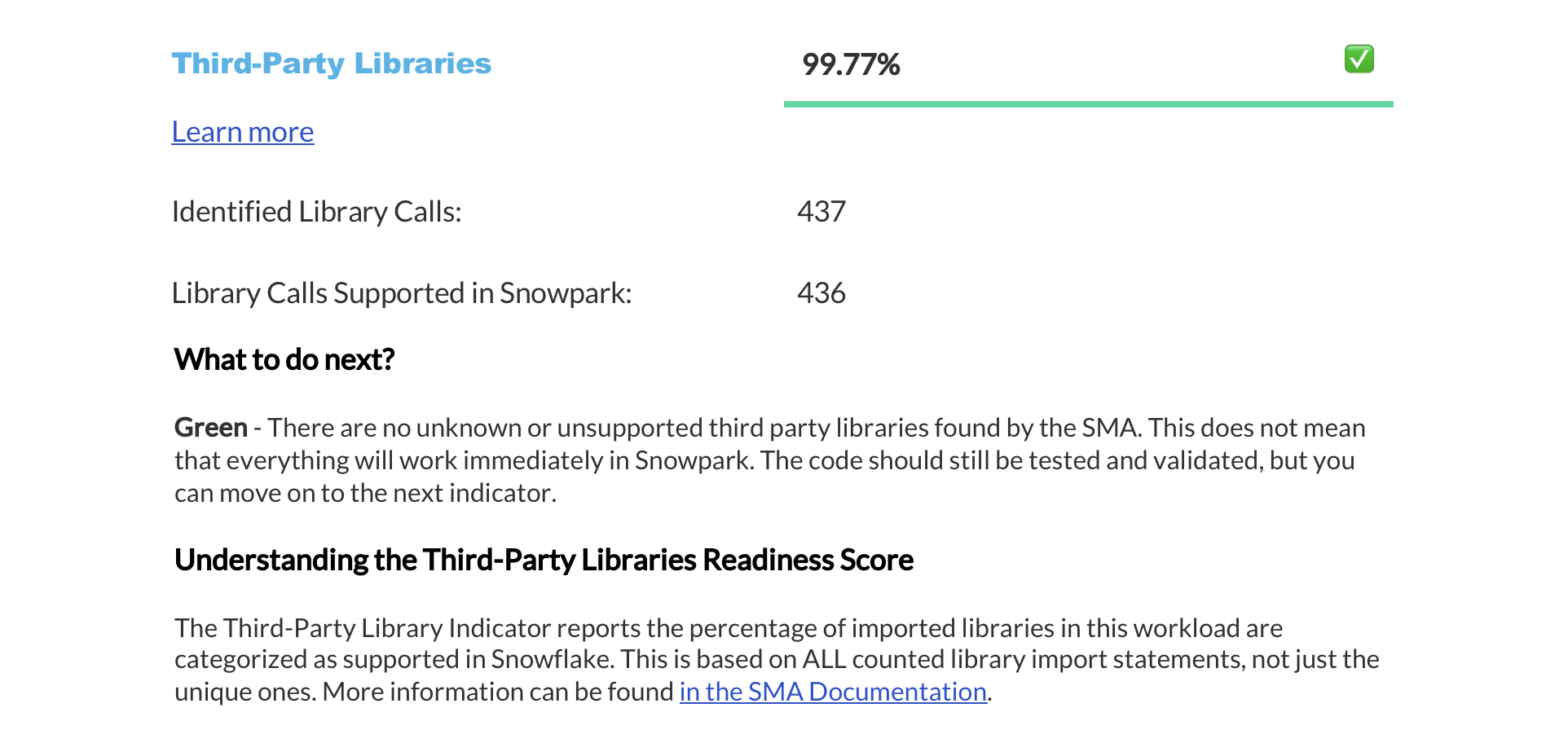
Readiness Scores Summary¶
The next page displays a summary of readiness scores. It includes scores for Spark API and Third-Party libraries, along with guidance on how to interpret them. These scores help you understand how well-prepared your codebase is for migration to Snowflake.

This section provides detailed information about each readiness score.
File Summary¶
The file summary section begins on the following page. This section may span multiple pages depending on how many different file types were processed during this tool execution.
This information is also available in the assessment summary presented in the application.
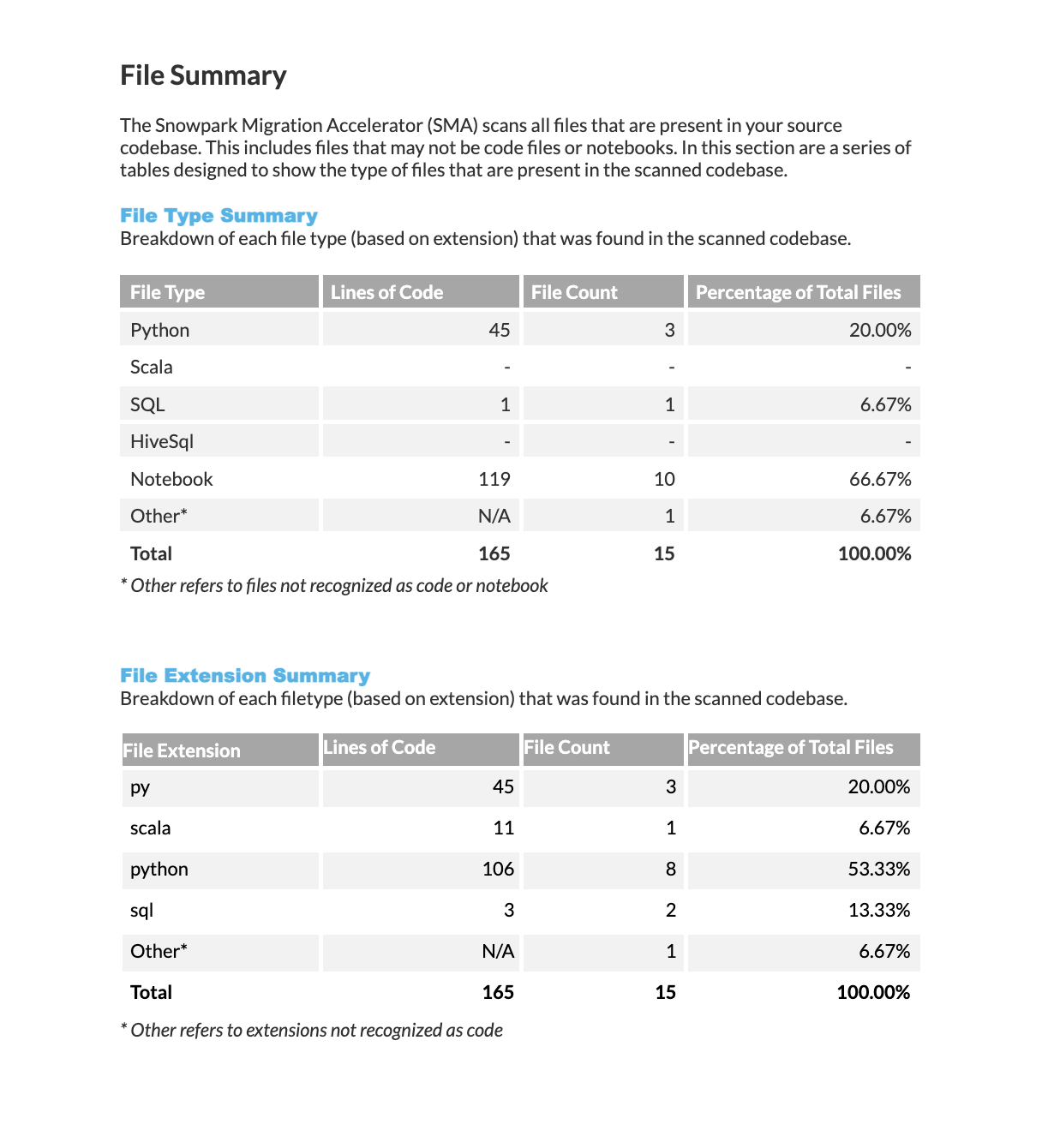
File Type Summary: Displays a breakdown of recognized technologies, including the number of files for each technology type, their total lines of code, and what percentage they represent of all analyzed files.
File Extension Summary: Shows statistics for each recognized file extension, including the number of files with that extension, their total lines of code, and what percentage they represent of all analyzed files.
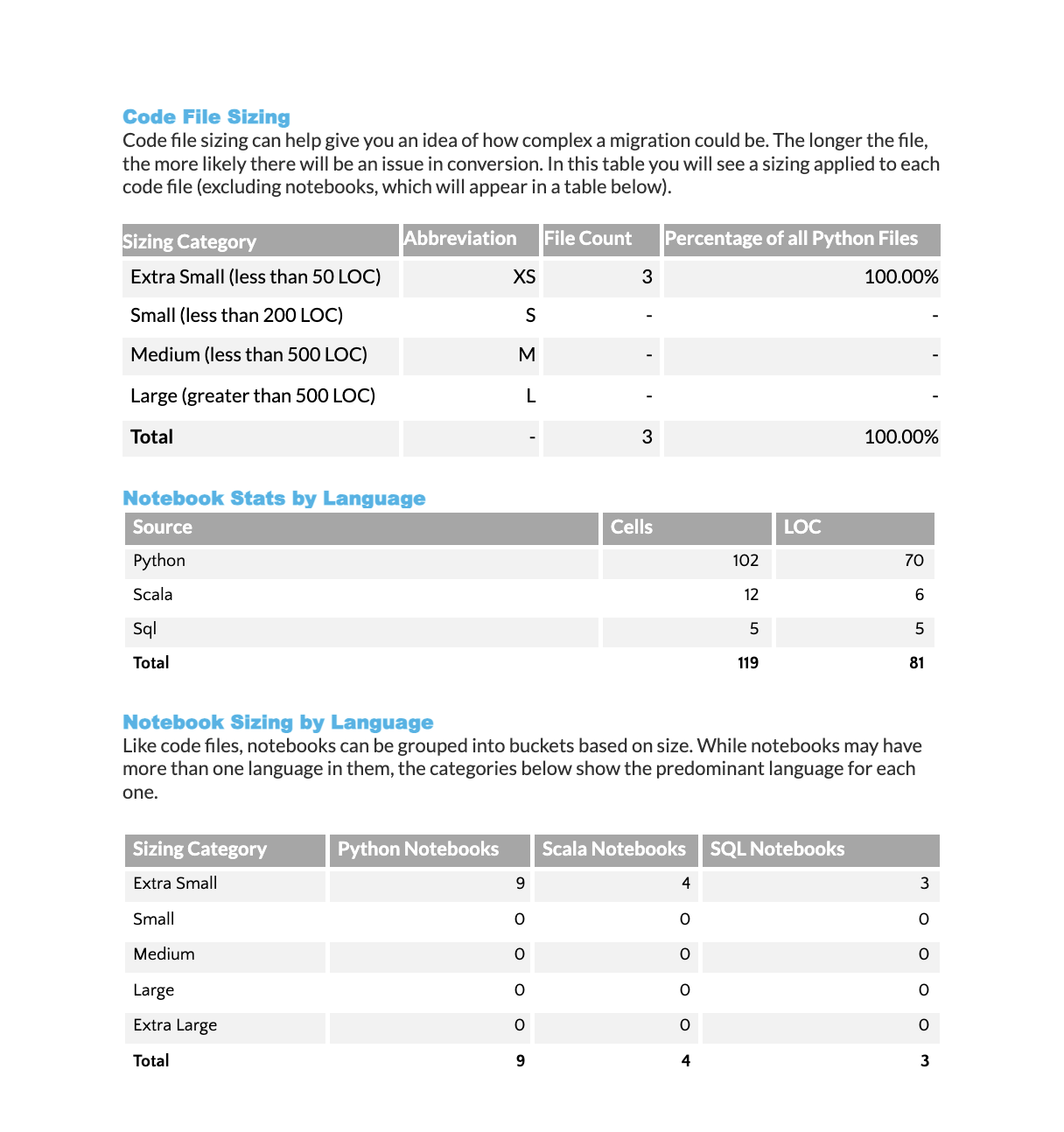
Code File Size Analysis: Displays the distribution of code files by size category (“t-shirt” sizing). Each size category shows the number of files and their percentage of the total codebase.
Notebook Language Statistics: Provides a breakdown of code lines and cells by programming language across all scanned notebooks.
Notebook Size Classification by Language: Categorizes each notebook file by size based on its total lines of code. The notebook type (Python, Scala, or SQL) is determined by the predominant language used. Size categories are:
XS: Under 50 lines
S: 50-200 lines
M: 200-500 lines
L: 500-1,000 lines
XL: Over 1,000 lines
Spark API Summary¶
The Spark API Summary provides a detailed analysis of the readiness score shown in the Readiness Score section. This section contains four tables:
A list of files containing Spark API references
A breakdown of supported and unsupported features
The readiness score organized by Spark API categories
The readiness score organized by Mapping Status
We will explain which Spark API references are supported and unsupported. Here’s what these terms mean:
Supported: The Snowpark Migration Accelerator (SMA) can automatically convert this API element to the Snowpark API or provide a known workaround.
Unsupported: The Snowpark Migration Accelerator (SMA) cannot automatically convert this API element to the Snowpark API. This does not mean conversion is impossible, but it will require manual intervention.
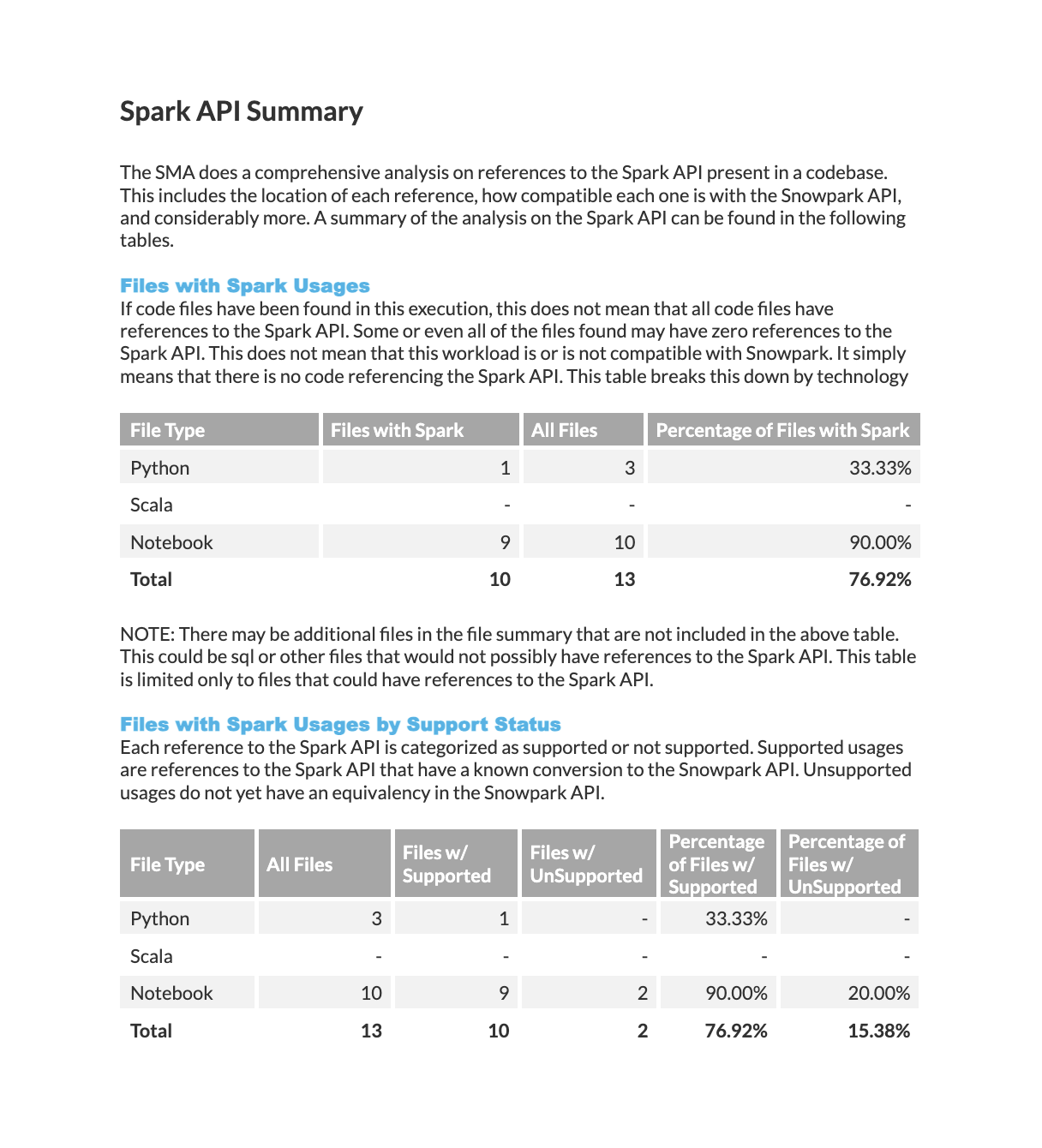
Files with Spark References: This table shows a breakdown of Spark technology usage across your workload, categorized by technology type.
Files with Spark Support Status: This table displays the number of supported and unsupported Spark features in your source code, organized by technology type.

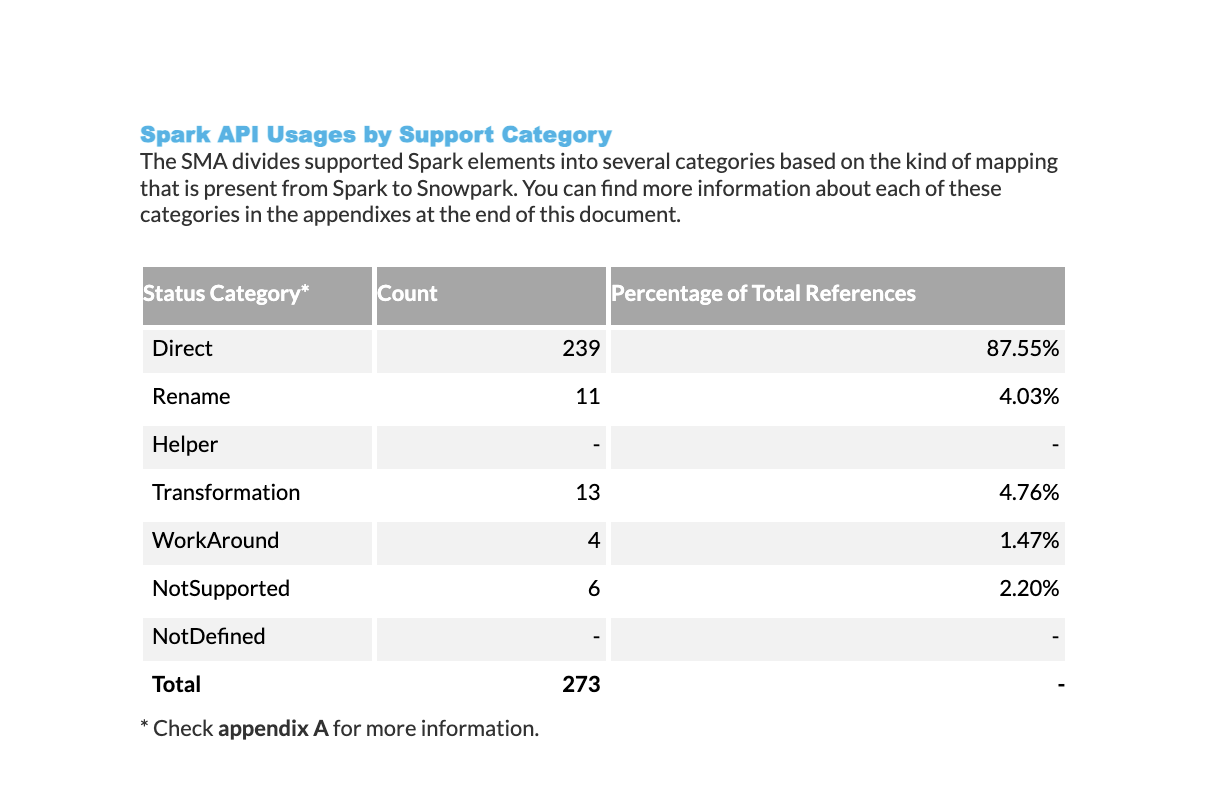
Spark API Usage Summary: A table showing how many Spark API functions are supported and not supported in Python and Scala. The table is organized by API category and includes a Spark API Readiness Score, which matches the score shown in the Readiness Score section.
Spark API Usage Support Categories: A breakdown of how many times Spark API functions are used in your code, organized by their support status. For detailed descriptions of each support category, see the Spark Reference Categories page.
Pandas API Usage Summarycv¶
Note
The Pandas API Usage Summary is only available for executions that contain Python files.
The Pandas API Summary provides a list of references to the Pandas API, similar to the Spark API Summary shown previously.
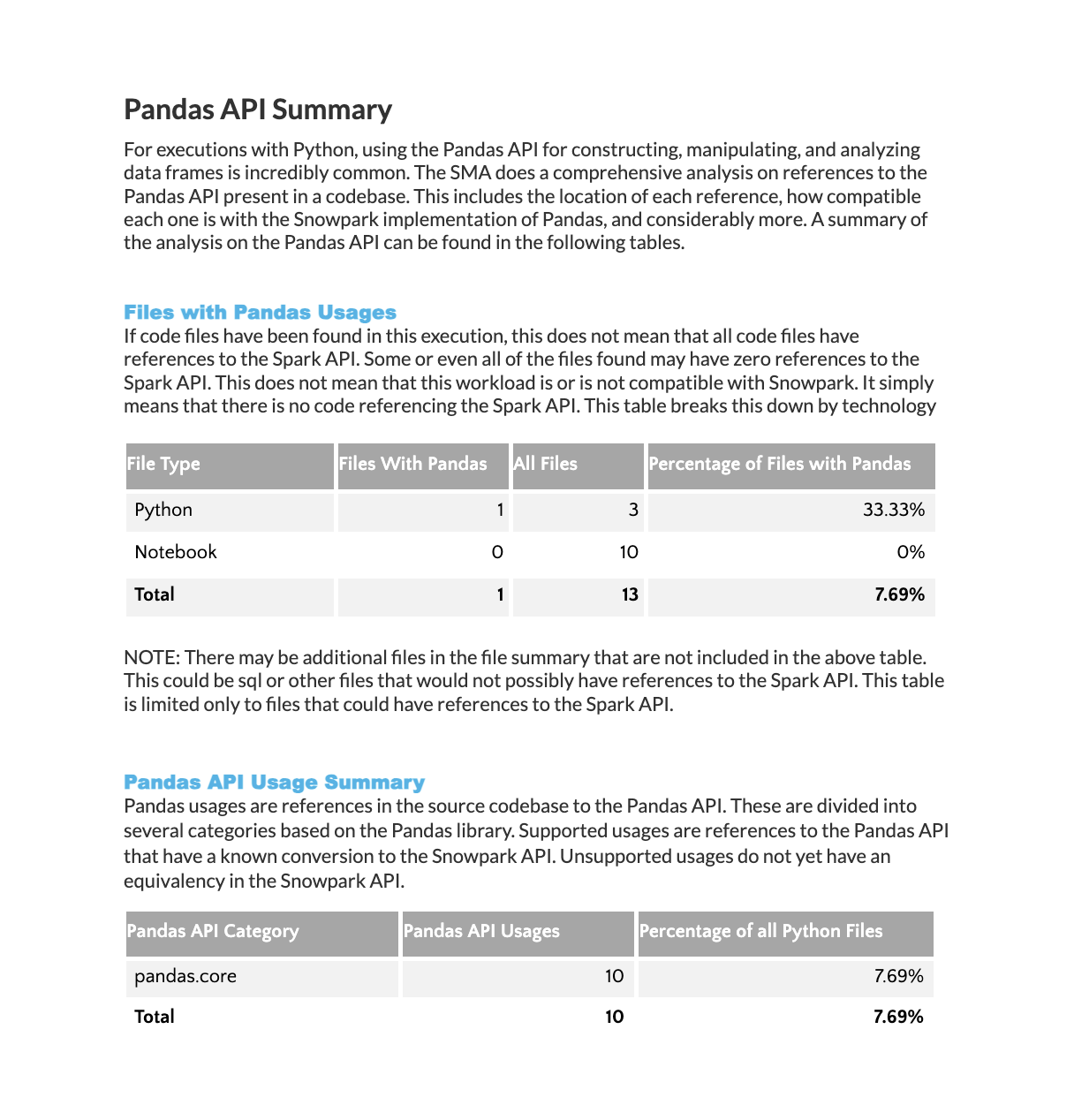
Files with Pandas Usage: A breakdown showing the number of Pandas references found in each technology across your entire workload.
Pandas API Usage Summary: A detailed list of Pandas library functions used in your source code, sorted by frequency of use.
Import Reference Summary¶
The Import Analysis section displays all external dependencies imported into your codebase. This includes third-party libraries and other external components used across all files. Note that imports from files within your own codebase are not shown in this table.
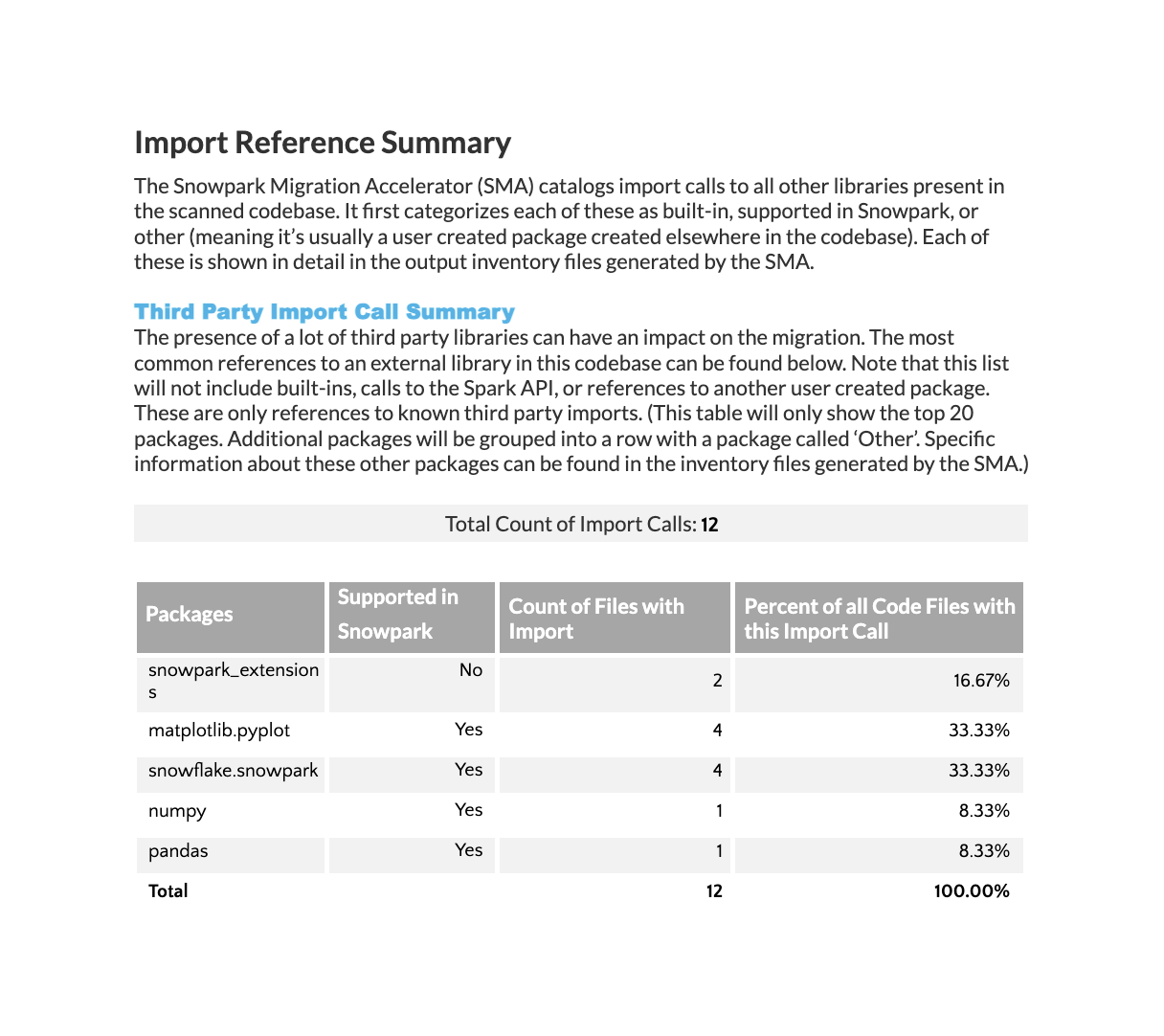
The table displays Python package information with the following details:
Package names that were imported
Whether each package is supported in Snowpark’s Anaconda distribution
Number of times each package appears in imports
Percentage of files containing each import
Note that while the “Percent” column total equals 100%, individual percentages may sum to more than 100% since files often contain multiple package imports.
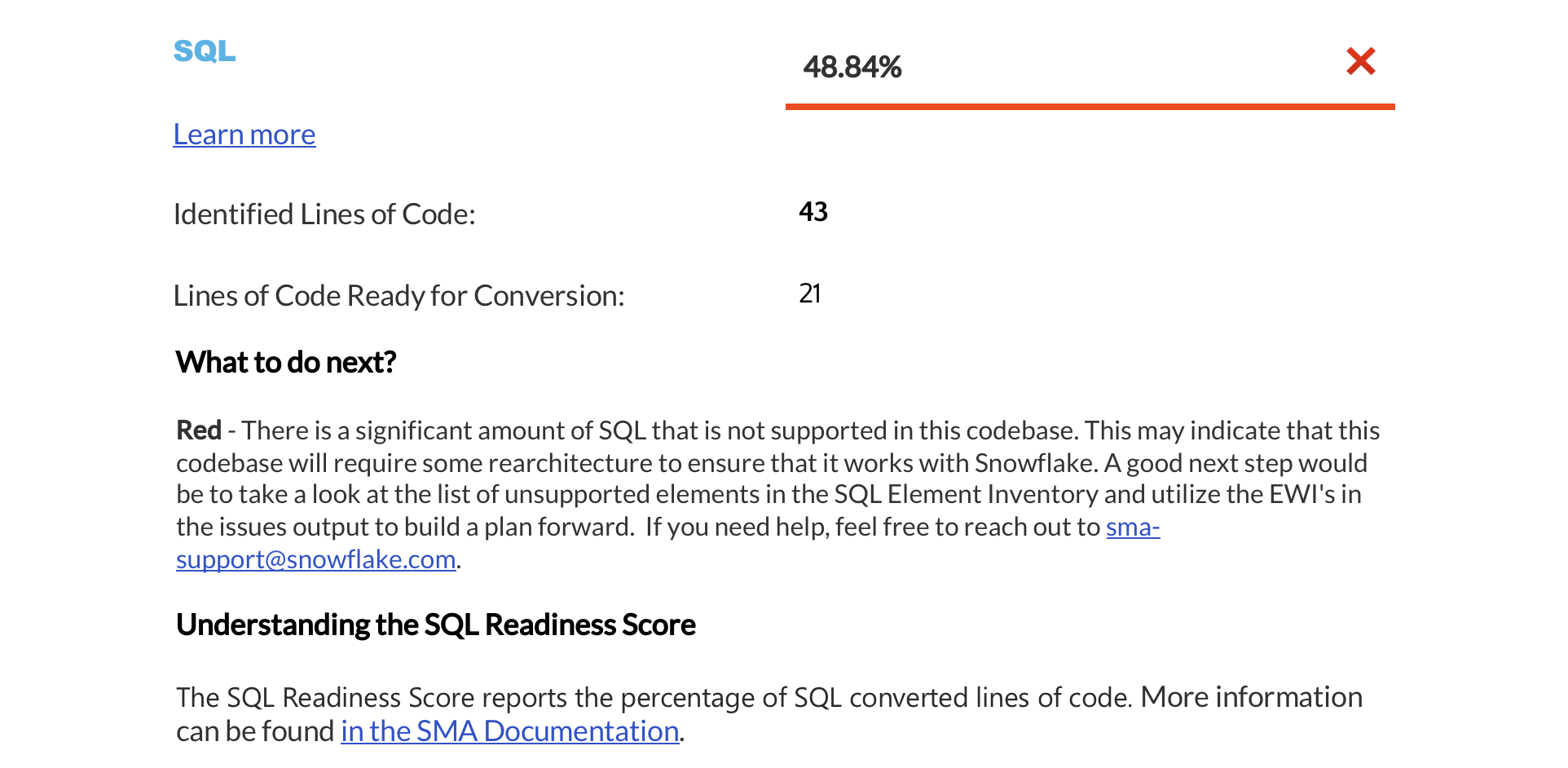
SQL Reference Summary¶

SQL Usage by File Type: This table categorizes SQL usage based on different technologies, showing the total number of SQL files and SQL cells found in your workload.
SQL Usage by Support Status: This table organizes SQL elements based on whether they have an equivalent feature in Snowflake or not.
Snowpark Migration Accelerator (SMA) Issue Summary¶
The Snowpark Migration Accelerator (SMA) creates issue reports whenever it detects warnings, conversion errors, or parsing errors in your code. Resolving these issues is essential for completing a successful code migration using SMA.
For a detailed guide on understanding and analyzing issues, please refer to the issue analysis section of our documentation.
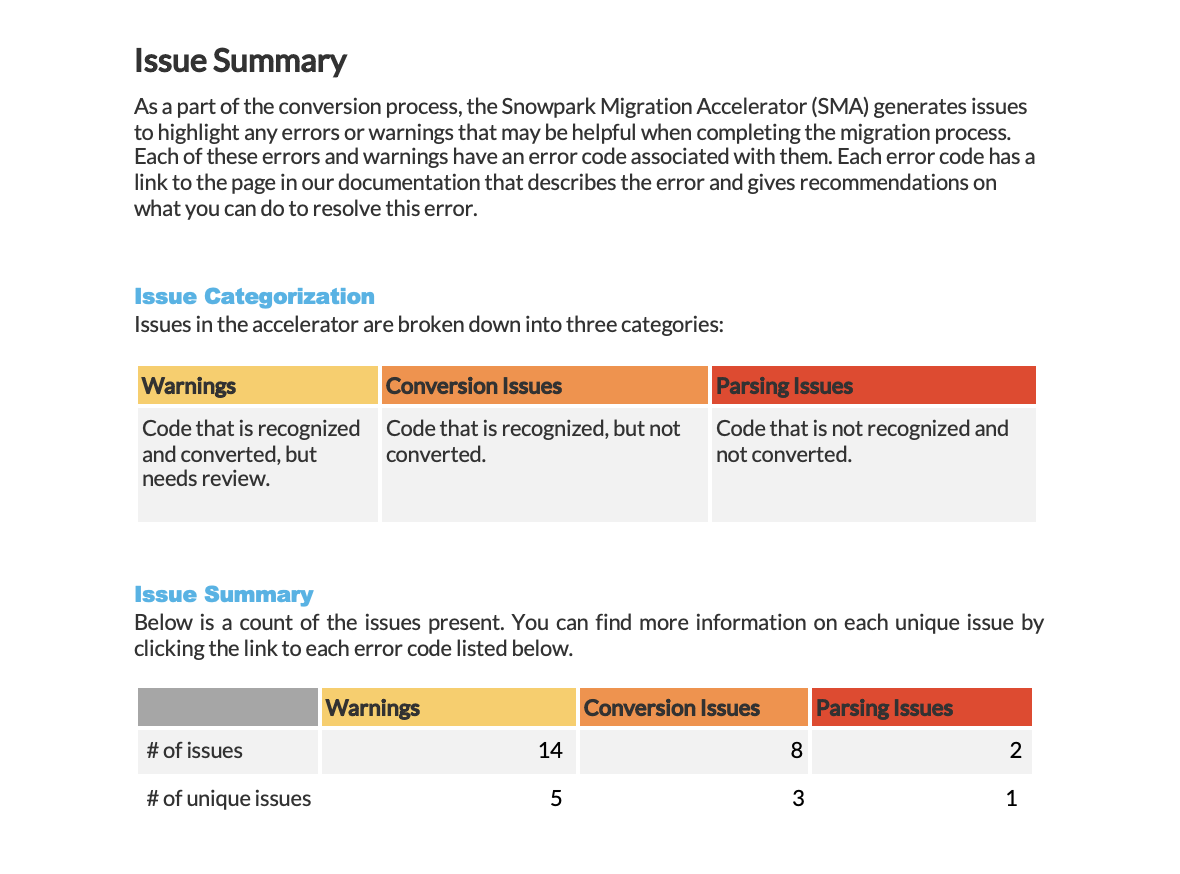
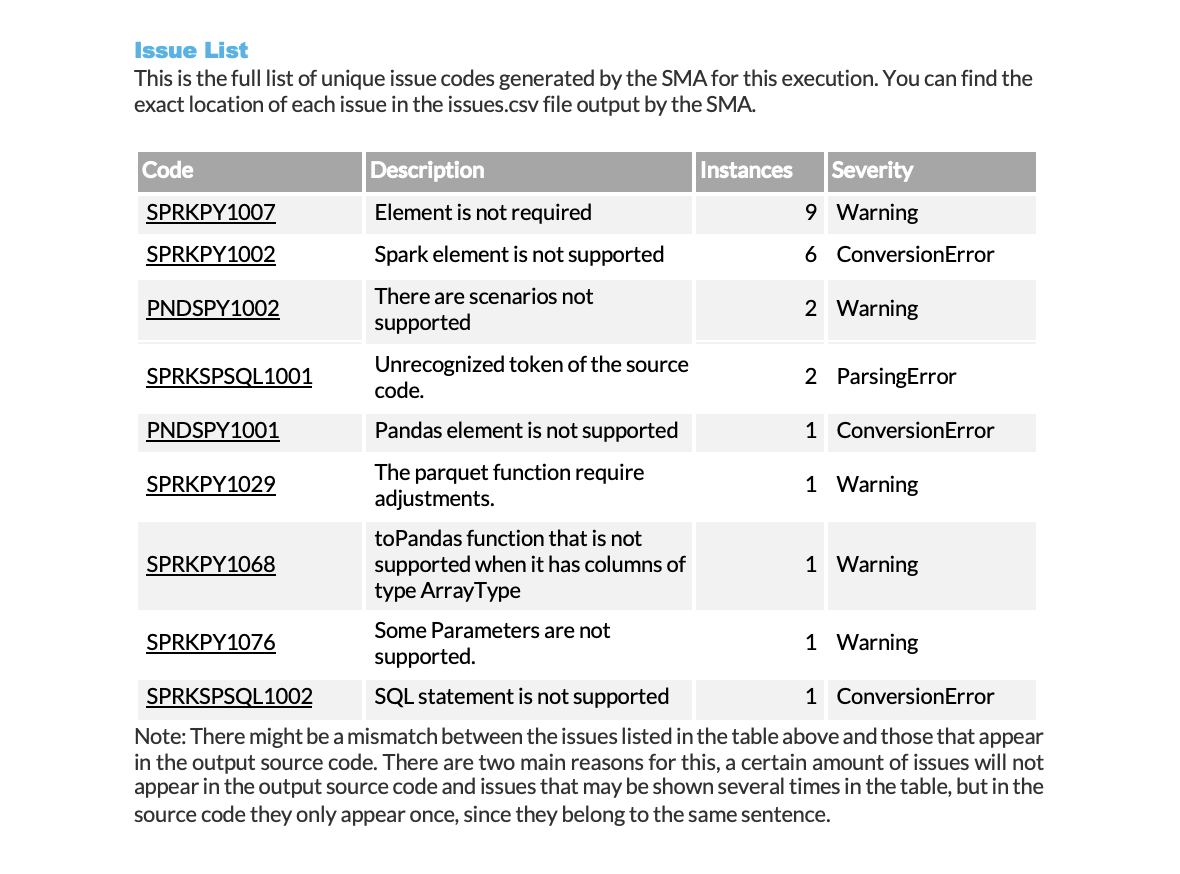
The summary displays each issue with the following information:
Issue code (with a link to detailed documentation)
Number of occurrences in the workload
Severity level
The report displays three severity levels (Warning, Conversion Error, and Parsing Error) along with a summary organized by each level.
When working with migration tools, follow these priorities for handling different types of issues:
Address parsing errors first, as they require immediate attention
Resolve conversion errors through programmatic solutions
Monitor and track warnings throughout the migration process
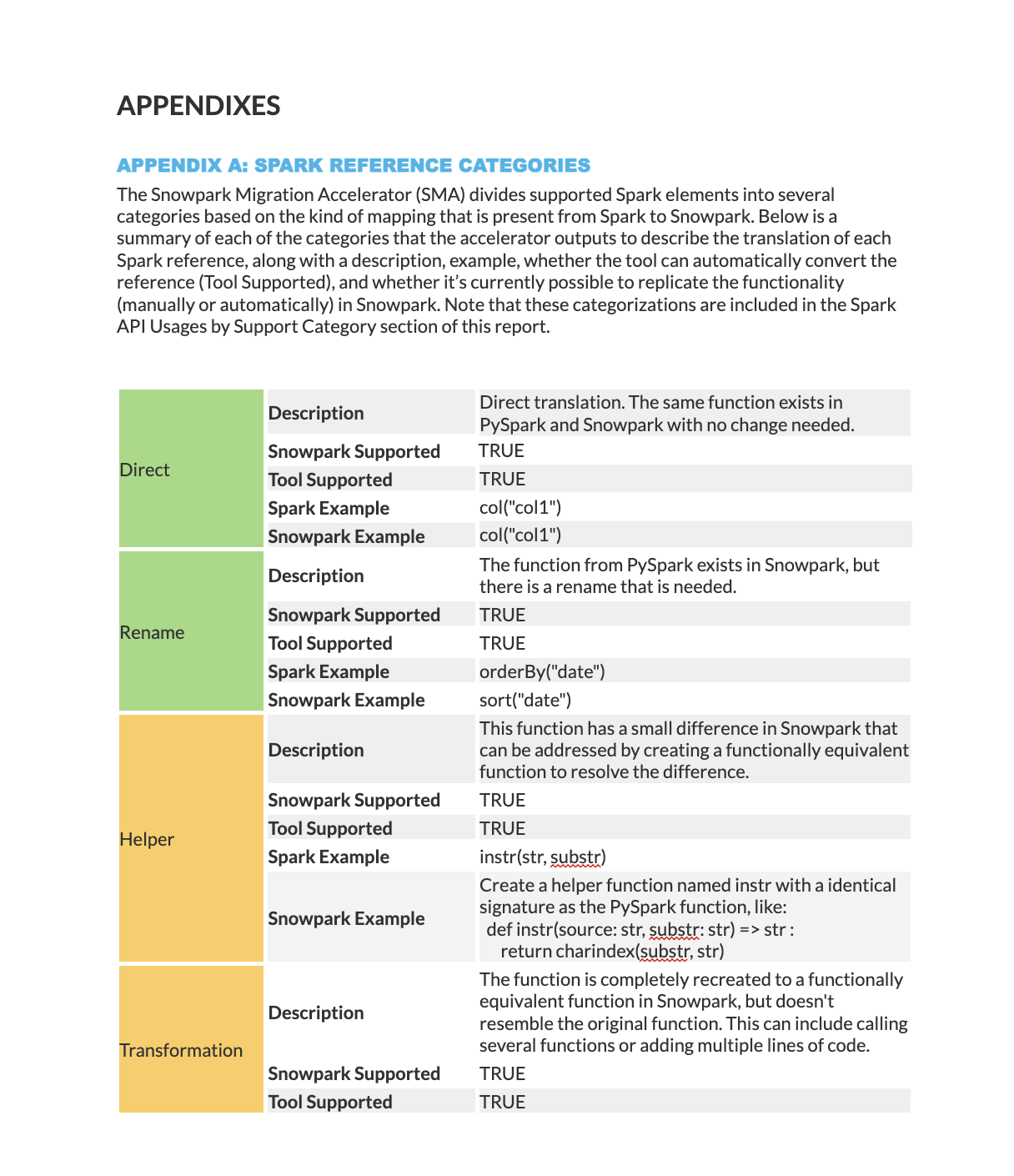
Appendices
Appendix A provides detailed descriptions of all mapping status categories.
This comprehensive report contains detailed information gathered from the inventory files that the Snowpark Migration Accelerator (SMA) generates.
For detailed information about the report, please contact the Snowpark Migration Accelerator (SMA) team at sma-support@snowflake.com.
Danger
The Summary Report feature has been removed and is no longer available starting from Spark Conversion Core V2.43.0
The SMA generates several output reports, which include detailed spreadsheets in the results.