Introduction to streams¶
A stream object records data manipulation language (DML) changes made to tables, including inserts (including COPY INTO), updates, and deletes, as well as metadata about each change, so that actions can be taken using the changed data. This process is referred to as change data capture (CDC). This topic introduces key concepts for change data capture using streams.
An individual table stream tracks the changes made to rows in a source table. A table stream (also referred to as simply a “stream”) makes a “change table” available of what changed, at the row level, between two transactional points of time in a table. This allows querying and consuming a sequence of change records in a transactional fashion.
Streams can be created to query change data on the following objects:
- Standard tables, including shared tables.
- Views, including secure views
- Directory tables
- Dynamic tables
- Apache Iceberg™ tables with Limitations.
- Event tables
- External tables
Offset storage¶
When created, a stream logically takes an initial snapshot of every row in the source object (e.g. table, external table, or the underlying tables for a view) by initializing a point in time (called an offset) as the current transactional version of the object. The change tracking system utilized by the stream then records information about the DML changes after this snapshot was taken. Change records provide the state of a row before and after the change. Change information mirrors the column structure of the tracked source object and includes additional metadata columns that describe each change event.
Streams use the current table schema. However, since streams may read deleted data to track changes over time, any incompatible schema changes between the offset and the advance can cause query failures.
Note that a stream itself does not contain any table data. A stream only stores an offset for the source object and returns CDC records by leveraging the versioning history for the source object. When the first stream for a table is created, several hidden columns are added to the source table and begin storing change tracking metadata. These columns consume a small amount of storage. The CDC records returned when querying a stream rely on a combination of the offset stored in the stream and the change tracking metadata stored in the table. Note that for streams on views, change tracking must be enabled explicitly for the view and underlying tables to add the hidden columns to these tables.
It might be useful to think of a stream as a bookmark, which indicates a point in time in the pages of a book (i.e. the source object). A bookmark can be thrown away and other bookmarks inserted in different places in a book. So too, a stream can be dropped and other streams created at the same or different points of time (either by creating the streams consecutively at different times or by using Time Travel) to consume the change records for an object at the same or different offsets.
One example of a consumer of CDC records is a data pipeline, in which only the data in staging tables that has changed since the last extraction is transformed and copied into other tables.
Table versioning¶
A new table version is created whenever a transaction that includes one or more DML statements is committed to the table. This applies to the following table types:
- Standard tables
- Directory tables
- Dynamic tables
- External tables
- Apache Iceberg™ tables
- Underlying tables for a view
In the transaction history for a table, a stream offset is located between two table versions. Querying a stream returns the changes caused by transactions committed after the offset and at or before the current time.
The following example shows a source table with 10 committed versions in the timeline. The offset for stream s1 is currently between
table versions v3 and v4. When the stream is queried (or consumed), the records returned include all transactions between table
version v4, the version immediately after the stream offset in the table timeline, and v10, the most recent committed table version
in the timeline, inclusive.
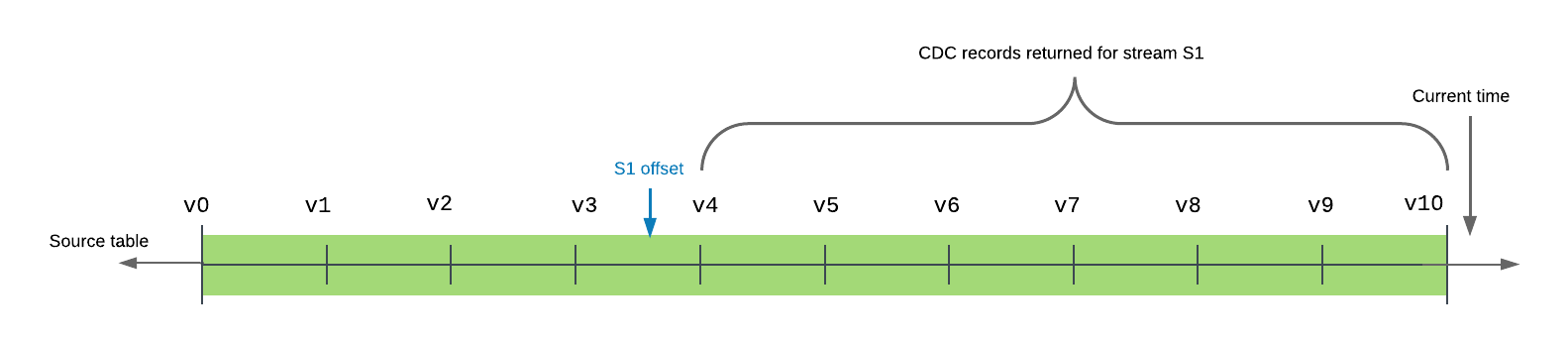
A stream provides the minimal set of changes from its current offset to the current version of the table.
Multiple queries can independently consume the same change data from a stream without changing the offset. A stream advances the offset only when it is used in a DML transaction. This includes a Create Table As Select (CTAS) transaction or a COPY INTO location transaction and this behavior applies to both explicit and autocommit transactions. (By default, when a DML statement is executed, an autocommit transaction is implicitly started and the transaction is committed at the completion of the statement. This behavior is controlled with the AUTOCOMMIT parameter.) Querying a stream alone does not advance its offset, even within an explicit transaction; the stream contents must be consumed in a DML statement.
Note
To advance the offset of a stream to the current table version without consuming the change data in a DML operation, complete either of the following actions:
- Recreate the stream (using the CREATE OR REPLACE STREAM syntax).
- Insert the current change data into a temporary table. In the INSERT statement, query the stream but include a WHERE clause that
filters out all of the change data (e.g.
WHERE 0 = 1).
When a SQL statement queries a stream within an explicit transaction, the stream is queried at the stream advance point (i.e. the timestamp) when the transaction began rather than when the statement was run. This behavior pertains both to DML statements and CREATE TABLE … AS SELECT (CTAS) statements that populate a new table with rows from an existing stream.
A DML statement that selects from a stream consumes all of the change data in the stream as long as the transaction commits successfully. To ensure multiple statements access the same change records in the stream, surround them with an explicit transaction statement (BEGIN .. COMMIT). This locks the stream. DML updates to the source object in parallel transactions are tracked by the change tracking system but do not update the stream until the explicit transaction statement is committed and the existing change data is consumed.
Repeatable read isolation¶
Streams support repeatable read isolation. In repeatable read mode, multiple SQL statements within a transaction see the same set of records in a stream. This differs from the read committed mode supported for tables, in which statements see any changes made by previous statements executed within the same transaction, even though those changes are not yet committed.
The delta records returned by streams in a transaction is the range from the current position of the stream until the transaction start time. The stream position advances to the transaction start time if the transaction commits; otherwise it stays at the same position.
Consider the following example:
| Time | Transaction 1 | Transaction 2 |
|---|---|---|
| 1 | Begin transaction. | |
| 2 | Query stream s1 on table t1. The stream returns the change data capture records between the current position to the Transaction 1 start time. If the stream is used in a DML statement the stream is then locked to avoid changes by concurrent transactions. | |
| 3 | Update rows in table t1. | |
| 4 | Query stream s1. Returns the same state of stream when it was used at Time 2. | |
| 5 | Commit transaction. If the stream was consumed in DML statements within the transaction, the stream position advances to the transaction start time. | |
| 6 | Begin transaction. | |
| 7 | Query stream s1. Results include table changes committed by Transaction 1. |
Within Transaction 1, all queries to stream s1 see the same set of records. DML changes to table t1 are recorded to the stream only
when the transaction is committed.
In Transaction 2, queries to the stream see the changes recorded to the table in Transaction 1. Note that if Transaction 2 had begun before Transaction 1 was committed, queries to the stream would have returned a snapshot of the stream from the position of the stream to the beginning time of Transaction 2 and would not see any changes committed by Transaction 1.
Stream columns¶
A stream stores an offset for the source object and not any actual table columns or data. When queried, a stream accesses and returns the historic data in the same shape as the source object (i.e. the same column names and ordering) with the following additional columns:
- METADATA$ACTION:
Indicates the DML operation (INSERT, DELETE) recorded.
- METADATA$ISUPDATE:
Indicates whether the operation was part of an UPDATE statement. Updates to rows in the source object are represented as a pair of DELETE and INSERT records in the stream with a metadata column METADATA$ISUPDATE values set to TRUE.
Note that streams record the differences between two offsets. If a row is added and then updated in the current offset, the delta change is a new row. The METADATA$ISUPDATE row records a FALSE value.
- METADATA$ROW_ID:
Specifies a unique, immutable row ID for tracking changes over time. If CHANGE_TRACKING is disabled and later re-enabled on the stream’s source object, the row ID could change.
Snowflake provides the following guarantees with respect to METADATA$ROW_ID:
-
The METADATA$ROW_ID depends on the stream’s source object.
For instance, a stream
stream1on tabletable1and streamstream2on tabletable1produce the same METADATA$ROW_IDs for the same rows, but a streamstream_viewon viewview1is not guaranteed to produce the same METADATA$ROW_IDs asstream1, even ifviewis defined using the statementCREATE VIEW view AS SELECT * FROM table1. -
A stream on a source object and a stream on the source object’s clone produce the same METADATA$ROW_IDs for the rows that exist at the time of the cloning.
-
A stream on a source object and a stream on the source object’s replica produce the same METADATA$ROW_IDs for the rows that were replicated.
Types of streams¶
The following stream types are available based on the metadata recorded by each:
- Standard:
Supported for streams on standard tables, dynamic tables, Snowflake-managed Apache Iceberg™ tables, directory tables, or views. A standard (i.e. delta) stream tracks all DML changes to the source object, including inserts, updates, and deletes (including table truncates). This stream type performs a join on inserted and deleted rows in the change set to provide the row level delta. As a net effect, for example, a row that is inserted and then deleted between two transactional points of time in a table is removed in the delta (i.e. is not returned when the stream is queried).
Note
Standard streams cannot retrieve change data for geospatial data. We recommend creating append-only streams on objects that contain geospatial data.
- Append-only:
Supported for streams on standard tables, dynamic tables, Snowflake-managed Apache Iceberg™ tables, or views. An append-only stream exclusively tracks row inserts. Update, delete, and truncate operations are not captured by append-only streams. For instance, if 10 rows are initially inserted into a table, and then 5 of those rows are deleted before advancing the offset for an append-only stream, the stream would only record the 10 inserted rows.
An append-only stream specifically returns the appended rows, making it notably more performant than a standard stream for extract, load, and transform (ELT), and similar scenarios reliant solely on row inserts. For example, a source table can be truncated immediately after the rows in an append-only stream are consumed, and the record deletions do not contribute to the overhead the next time the stream is queried or consumed.
Creating an append-only streams in a target account using a secondary object as the source is not supported.
- Insert-only:
Supported for streams on externally managed Apache Iceberg™ or external tables. An insert-only stream tracks row inserts only; they do not record delete operations that remove rows from an inserted set (i.e. no-ops). For example, in-between any two offsets, if
File1is removed from the cloud storage location referenced by the external table, andFile2is added, the stream returns records for the rows inFile2only, regardless of whetherFile1was added before or within the requested change interval. Unlike when tracking CDC data for standard tables, access to the historical records for files in cloud storage is not governed by or guaranteed to Snowflake.Overwritten or appended files are essentially handled as new files: The old version of the file is removed from cloud storage, but the insert-only stream does not record the delete operation. The new version of the file is added to cloud storage, and the insert-only stream records the rows as inserts. The stream does not record the diff of the old and new file versions. Note that appends may not trigger an automatic refresh of the external table metadata, such as when using Azure AppendBlobs.
Data flow¶
The following diagram shows how the contents of a standard stream change as rows in the source table are updated. Whenever a DML statement consumes the stream contents, the stream position advances to track the next set of DML changes to the table (i.e. the changes in a table version):
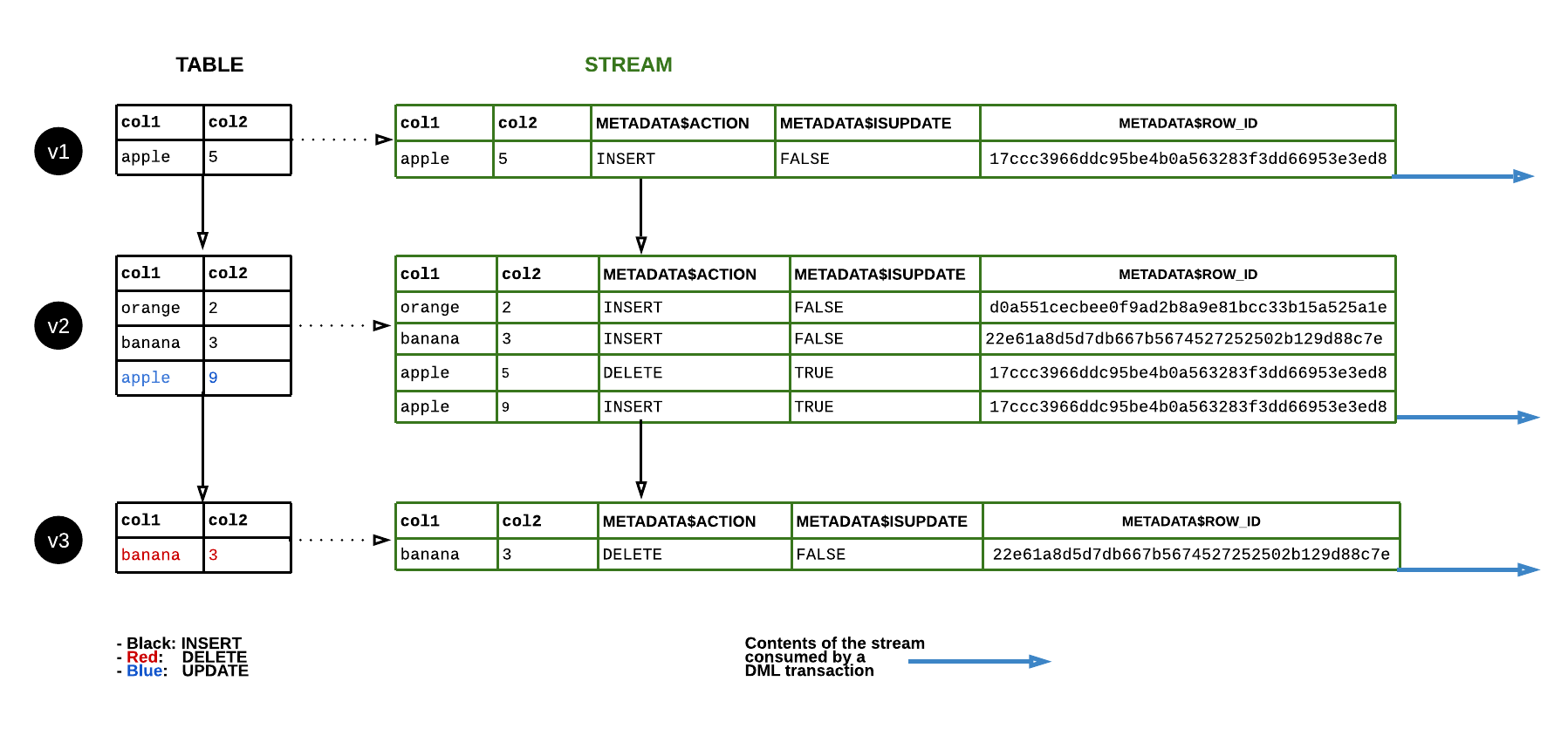
Data retention period and staleness¶
A stream becomes stale when its offset falls outside of the data retention period for its source table (or underlying tables for a source view). In a stale state, historical data and any unconsumed change records for the source table are no longer accessible. To continue tracking new change records, you must recreate the stream using the CREATE STREAM command.
To prevent a stream from becoming stale, consume the stream records within a DML
statement during the table’s retention period and regularly consume its change data
before its STALE_AFTER timestamp (that is, within the extended data retention period
for the source object). Additionally, calling
SYSTEM$STREAM_HAS_DATA on the stream prevents it from
becoming stale, provided the stream is empty and the SYSTEM$STREAM_HAS_DATA function
returns FALSE.
For more information on data retention periods, see Understanding & using Time Travel.
Note
Streams on shared tables or views don’t extend the data retention period for the table or underlying tables, respectively. For more information, see Streams on shared objects.
If the data retention period for a table is less than 14 days and a stream hasn’t been consumed, Snowflake temporarily extends this period to prevent the stream from going stale. The retention period is extended to the stream’s offset, up to a maximum of 14 days by default, regardless of your Snowflake edition. The maximum number of days for which Snowflake can extend the data retention period is determined by the MAX_DATA_EXTENSION_TIME_IN_DAYS parameter value. Once the stream is consumed, the extended data retention period reverts to the table’s default.
The following table shows examples of DATA_RETENTION_TIME_IN_DAYS and MAX_DATA_EXTENSION_TIME_IN_DAYS values, indicating how often the stream contents should be consumed to avoid staleness:
| DATA_RETENTION_TIME_IN_DAYS | MAX_DATA_EXTENSION_TIME_IN_DAYS | Consume Streams in X Days |
|---|---|---|
| 14 | 0 | 14 |
| 1 | 14 | 14 |
| 0 | 90 | 90 |
To check the staleness status of a stream, use the DESCRIBE STREAM or SHOW STREAMS command. The STALE_AFTER column timestamp is the extended data retention period for the source object. It shows when the stream is predicted to become stale or when it became stale if the timestamp is in the past. This timestamp is calculated by adding the greater value of the DATA_RETENTION_TIME_IN_DAYS or MAX_DATA_EXTENSION_TIME_IN_DAYS parameters setting for the source object to the last consumption time of the stream.
Note
If the data retention period for the source table is set at the schema or database level, the current role must have access to the schema or database to calculate the STALE_AFTER value.
Consuming change data for a stream updates the STALE_AFTER timestamp. Although reading from the stream might succeed for some time after the STALE_AFTER timestamp, the stream can become stale at any moment. The STALE column indicates if the stream is expected to be stale, though it might not be stale yet.
To prevent a stream from becoming stale, regularly consume its change data before its STALE_AFTER timestamp (that is, within the extended data retention period for the source object). Don’t rely on the results from a stream after the STALE_AFTER period has elapsed because the STREAM_HAS_DATA function might return unexpected results.
After the STALE_AFTER timestamp has passed, the stream can become stale at any time, even if it has no unconsumed records. Querying a stream might return 0 records even if there is change data for the source object. For example, an append-only stream tracks row inserts only, but updates and deletes also write change records to the source object. Additionally, some table writes, like reclustering, don’t produce change data. Consuming change data for a stream advances its offset to the present, regardless of whether there is intervening change data.
Important
- Recreating an object (using the CREATE OR REPLACE TABLE syntax) drops its history, which also makes any stream on the table or view stale. In addition, recreating or dropping any of the underlying tables for a view makes any stream on the view stale.
- Currently, when a database or schema that contains a stream and its source table (or the underlying tables for a source view) is cloned, any unconsumed records in the stream clone are inaccessible. This behavior is consistent with Time Travel for tables. If a table is cloned, historical data for the table clone begins at the time/point when the clone was created.
- Renaming a source object does not break a stream or cause it to go stale. In addition, if a source object is dropped and a new object is created with the same name, any streams linked to the original object are not linked to the new object.
Multiple consumers of streams¶
We recommend that users create a separate stream for each consumer of change records for an object. “Consumer” refers to a task, script, or other mechanism that consumes the change records for an object using a DML transaction. As stated earlier in this topic, a stream advances its offset only when it is used in a DML transaction. This includes a Create Table As Select (CTAS) transaction or a COPY INTO location transaction.
Different consumers of change data in a single stream retrieve different deltas unless Time Travel is used. When the change data captured from the latest offset in a stream is consumed using a DML transaction, the stream advances the offset. The change data is no longer available for the next consumer. To consume the same change data for an object, create multiple streams for the object. A stream only stores an offset for the source object and not any actual table column data; therefore, you can create any number of streams for an object without incurring significant cost.
Streams on views¶
Streams on views support both local views and views shared using Snowflake Secure Data Sharing, including secure views. Currently, streams cannot track changes in materialized views.
Streams are limited to views that satisfy the following requirements:
- Underlying Tables:
- All of the underlying tables must be native tables.
- The view can apply only the following operations:
- Projections
- Filters
- Inner or cross joins
- UNION ALL
Nested views and subqueries in the FROM clause are supported as long as the fully expanded query satisfies the other requirements in this requirements table.
- View Query:
General requirements:
- The query can select any number of columns.
- The query can contain any number of WHERE predicates.
- Views with the following operations are not yet supported:
- GROUP BY clauses
- QUALIFY clauses
- Subqueries not in the FROM clause
- Correlated subqueries
- LIMIT clauses
- DISTINCT clauses
Functions:
- Functions in the select list must be system-defined, scalar functions.
- Change Tracking:
Change tracking must be enabled in the underlying tables.
Before creating a stream on a view, you must enable change tracking on the underlying tables for the view. For instructions, see Enabling change tracking on views and underlying tables.
Join results behavior¶
When examining the results of a stream that tracks changes to a view containing a join, it’s important to understand what data is being joined. Changes that have occurred on the left table since the stream offset are being joined with the right table, changes on the right table since the stream offset are being joined with the left table, and changes on both tables since the stream offset are being joined with each other.
Consider the following example:
Two tables are created:
A view is created to join the two tables on id. Each table has a single row that joins with the other:
A stream is created that tracks changes to the view:
The view has one entry and the stream has none since there have been no changes to the tables since the stream’s current offset:
Once updates are made to the underlying tables, selecting ordersByCustomerStream will produce records of orders x Δ customers + Δ orders x
customers + Δ orders x Δ customers where:
- Δ
ordersand Δcustomersare the changes that have occurred to each table since the stream offset.- orders and customers are the total contents of the tables at the current stream offset.
Note that due to optimizations in Snowflake the cost of computing this expression is not always linearly proportional to the size of the inputs.
If another joining row is inserted in orders then ordersByCustomer will have a new row:
Selecting from ordersByCustomersStream produces one row because Δ orders x customers contains the new insert and orders x Δ customers +
Δ orders x Δ customers is empty:
If another joining row is then inserted into customers then ordersByCustomer will have a total of three new rows:
Selecting from ordersByCustomersStream produces three rows because
Δ orders x customers, orders x Δ customers, and Δ orders x Δ customers will each produce one row:
Note that for append-only streams, Δ orders and Δ customers will contain row inserts only,
while orders and customers will contain the complete contents of the tables including any updates that happened before the stream offset.
CHANGES clause: Read-only alternative to streams¶
As an alternative to streams, Snowflake supports querying change tracking metadata for tables or views using the CHANGES clause for SELECT statements. The CHANGES clause enables querying change tracking metadata between two points in time without having to create a stream with an explicit transactional offset. Using the CHANGES clause does not advance the offset (i.e. consume the records). Multiple queries can retrieve the change tracking metadata between different transactional start and endpoints. This option requires specifying a transactional start point for the metadata using an AT | BEFORE clause; the end point for the change tracking interval can be set using the optional END clause.
A stream stores the current transactional table version and is the appropriate source of CDC records in most scenarios. For infrequent scenarios that require managing the offset for arbitrary periods of time, the CHANGES clause is available for your use.
Currently, the following must be true before change tracking metadata is recorded:
- Tables:
Either enable change tracking on the table (using ALTER TABLE … CHANGE_TRACKING = TRUE), or create a stream on the table (using CREATE STREAM).
- Views:
Enable change tracking on the view and its underlying tables. For instructions, see Enabling change tracking on views and underlying tables.
Enabling change tracking adds several hidden columns to the table and begins storing change tracking metadata. The values in these hidden CDC data columns provide the input for the stream metadata columns. The columns consume a small amount of storage.
No change tracking metadata for the object is available for the period before one of these conditions is satisfied.
Required access privileges¶
Querying a stream requires a role with a minimum of the following role permissions:
| Object | Privilege | Notes |
|---|---|---|
| Database | USAGE | |
| Schema | USAGE | |
| Stream | SELECT | |
| Table | SELECT | Streams on tables only. |
| View | SELECT | Streams on views only. |
| External stage | USAGE | Streams on directory tables (on external stages) only |
| Internal stage | READ | Streams on directory tables (on internal stages) only |
Billing for streams¶
As described in Data Retention Period and Staleness (in this topic), when a stream is not consumed regularly, Snowflake temporarily extends the data retention period for the source table or the underlying tables in the source view. If the data retention period for the table is less than 14 days, then behind the scenes, the period is extended to the smaller of the stream transactional offset or 14 days (if the data retention period for the table is less than 14 days) regardless of the Snowflake edition for your account.
Extending the data retention period requires additional storage which will be reflected in your monthly storage charges.
The main cost associated with a stream is the processing time used by a virtual warehouse to query the stream. These charges appear on your bill as familiar Snowflake credits.
Limitations¶
The following limitations apply for streams:
- You can’t use standard or append-only streams on Apache Iceberg™ tables that use an external catalog. (Insert-only streams are supported.)
- You can’t track changes on a view with GROUP BY clauses.
- After adding or modifying a column to be NOT NULL, queries on streams might fail if the stream outputs rows with impermissible NULL values. This happens because the stream’s schema enforces the current NOT NULL constraint, which doesn’t match the historical data returned by the stream.
- When a task is triggered by Streams on Views, then any changes to tables referenced by the Streams on Views query will also trigger the task, regardless of any joins, aggregations, or filters in the query.
- Streams are not supported on partitioned external tables.