Cortex Search¶
Get started with Cortex Search
Überblick¶
Cortex Search ermöglicht eine qualitativ hochwertige „unscharfe“ Suche mit geringer Latenz in Ihren Snowflake-Daten. Cortex Search ermöglicht Snowflake-Benutzern ein breites Spektrum an Suchmöglichkeiten, darunter Retrieval Augmented Generation (RAG)-Anwendungen, die Large Language Models (LLMs) nutzen.
Mit Cortex Search können Sie eine hybride (Vektor- und Schlüsselwort-) Suchmaschine für Ihre Textdaten in wenigen Minuten in Betrieb nehmen, ohne sich um die Einbettung, die Wartung der Infrastruktur, die Abstimmung der Parameter für die Suchqualität oder die laufende Indexaktualisierung kümmern zu müssen. Das bedeutet, dass Sie weniger Zeit für die Optimierung der Infrastruktur und der Suchqualität aufwenden müssen und mehr Zeit für die Entwicklung hochwertiger Chat- und Sucherlebnisse unter Verwendung Ihrer Daten haben. In den Cortex Search Tutorials finden Sie Schritt-für-Schritt-Anweisungen zur Verwendung von Cortex Search für AI-Chat- und Suchanwendungen.
Wann Sie Cortex Search verwenden sollten¶
Die beiden Hauptanwendungsfälle für Cortex Search sind das Abrufen von Augmented Generation (RAG) und die Unternehmenssuche.
RAG Engine für LLM Chatbots: Verwenden Sie Cortex Search als RAG-Engine für Chat-Anwendungen mit Ihren Textdaten, indem Sie die semantische Suche für individuelle, kontextbezogene Antworten nutzen.
Enterprise-Suche: Verwenden Sie Cortex Search als Backend für eine hochwertige, in Ihre Anwendung eingebettete Suchleiste.
Cortex Search für RAG¶
Retrieval Augmented Generation (RAG) ist eine Technik zum Abrufen von Daten aus einer Wissensdatenbank, um die generierte Antwort eines großen Sprachmodells zu verbessern. Das folgende Architekturdiagramm zeigt, wie Sie Cortex Search mit Cortex LLM-Funktionen kombinieren können, um Unternehmens-Chatbots mit RAG zu erstellen, die Ihre Snowflake-Daten als Wissensdatenbank nutzen.
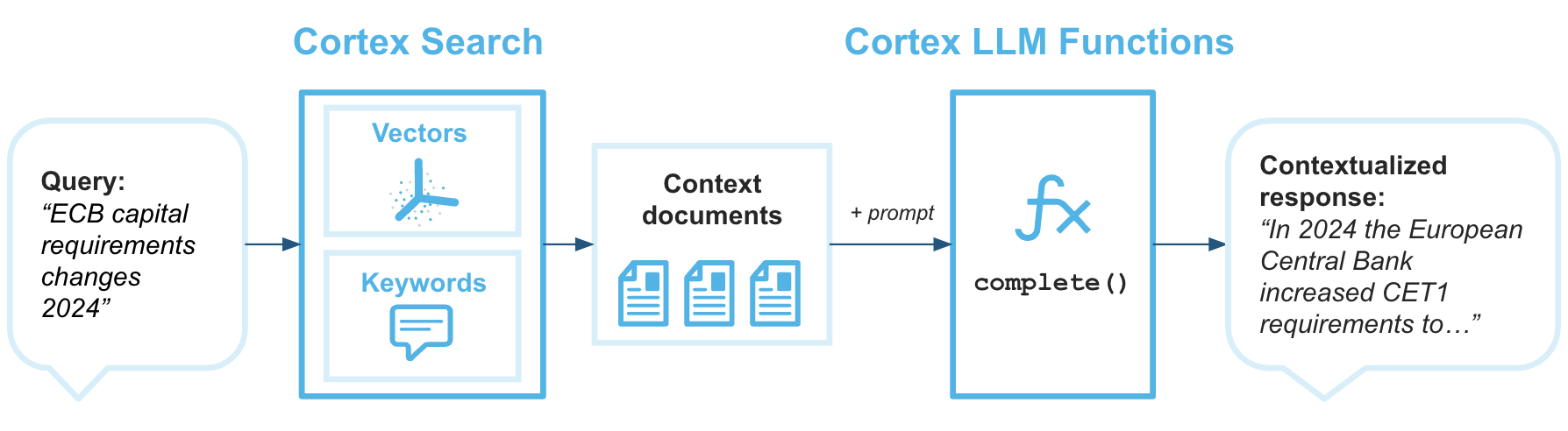
Cortex Search ist die Suchmaschine, die das Large Language Model mit dem nötigen Kontext versorgt, um Antworten zu liefern, die auf Ihren aktuellsten proprietären Daten beruhen.
Beispiel: Einen Cortex Search Service erstellen und abfragen¶
Dieses Beispiel führt Sie durch die Schritte zur Erstellung eines Cortex Search Service und dessen Abfrage mithilfe der REST API. Weitere Einzelheiten zur Abfrage des Services finden Sie unter Abfrage eines Cortex Search Service.
Dieses Beispiel verwendet ein Beispieldatenset für ein Kundensupport-Transkript.
Führen Sie die folgenden Befehle aus, um die Beispieldatenbank und das Schema einzurichten.
Führen Sie die folgenden SQL-Befehle aus, um das Datenset zu erstellen.
Dienst erstellen¶
Sie können einen Cortex Search Service mit einer einzelnen SQL-Abfrage oder über das Snowflake AI & ML-Studio erstellen. Wenn Sie einen Cortex Search Service erstellen, führt Snowflake Transformationen an Ihren Quelldaten durch, um sie für die Bereitstellung mit niedriger Latenz bereit zu machen. In den folgenden Abschnitten wird gezeigt, wie Sie einen Service sowohl mit SQL als auch im Snowflake AI & ML-Studio über die Snowsight erstellen.
Bemerkung
Wenn Sie einen Service erstellen, wird der Suchindex als Teil des Erstellungsprozesses erstellt. Das bedeutet, dass die Anweisung CREATE CORTEX SEARCH SERVICE bei größeren Datensets länger dauern kann.
Verwenden von SQL¶
Das folgende Beispiel veranschaulicht, wie ein Cortex Search Service mit CREATE CORTEX SEARCH SERVICE anhand des im vorherigen Abschnitt erstellten Beispiel-Datensets für Kundensupport-Transkripte erstellt wird.
Dieser Befehl löst den Aufbau des Search Services für Ihre Daten aus. In diesem Beispiel:
Bei Abfragen an den Dienst wird nach Übereinstimmungen in der Spalte
transcript_textgesucht.Der Parameter
TARGET_LAGlegt fest, dass der Cortex Search Service etwa einmal pro Tag nach Aktualisierungen der Basistabellesupport_transcriptssucht.Die Spalten
regionundagent_idwerden indiziert, sodass sie zusammen mit den Ergebnissen von Abfragen in der Spaltetranscript_textzurückgegeben werden können.Die Spalte
regionsteht bei der Abfrage der Spaltetranscript_textals Filterspalte zur Verfügung.Das Warehouse
cortex_search_whwird verwendet, um die Ergebnisse der angegebenen Abfrage anfänglich und bei jeder Änderung der Basistabelle zu materialisieren.
Bemerkung
Abhängig von der Größe des in der Abfrage angegebenen Warehouse und der Anzahl der Zeilen in Ihrer Tabelle kann dieser CREATE-Befehl bis zu mehreren Stunden in Anspruch nehmen.
Snowflake empfiehlt, für jeden Service ein eigenes Warehouse zu verwenden, das nicht größer als MEDIUM ist.
Die Spalten im Feld ATTRIBUTES müssen in der Abfrage enthalten sein, entweder über eine explizite Aufzählung oder einen Platzhalter (
*).
Verwenden von Snowsight¶
Folgen Sie diesen Schritten, um einen Cortex Search Service in Snowsight zu erstellen:
Melden Sie sich bei Snowsight an.
Wählen Sie eine Rolle, die die Datenbankrolle SNOWFLAKE.CORTEX_USER hat.
Wählen Sie im Navigationsmenü die Option AI & ML » Cortex Search aus.
Wählen Sie Create aus.
Wählen Sie eine Rolle und ein Warehouse.
Der Rolle muss die Datenbankrolle SNOWFLAKE.CORTEX_USER zugewiesen sein. Das Warehouse wird für die Materialisierung der Ergebnisse der Quellabfrage verwendet, wenn der Service erstellt und aktualisiert wird.
Wählen Sie eine Datenbank und ein Schema, in dem der Dienst definiert ist.
Geben Sie einen Namen für Ihren Dienst ein und wählen Sie dann Next aus.
Wählen Sie die Daten aus, die indiziert werden sollen.
Um eine Tabelle oder Ansicht auszuwählen, wählen Sie Table or view aus.
Wählen Sie die Tabelle oder Ansicht, die die Textdaten enthält, die für die Suche indiziert werden sollen, und wählen Sie dann Next aus. Wählen Sie zum Beispiel die Tabelle
support_transcriptsaus.Um Dateien aus einem Stagingbereich auszuwählen, wählen Sie Stage aus. (Vorschau)
Wählen Sie den Stagingbereich aus, der die Dateien enthält, die für die Suche indiziert werden sollen, und wählen Sie dann Next aus.
Bemerkung
Wenn Sie bei der Definition Ihres Dienstes mehrere Datenquellen angeben oder Transformationen durchführen möchten, verwenden Sie SQL.
Wenn Sie Table or view ausgewählt haben:
Markieren Sie die Spalten, die in den Suchergebnissen enthalten sein sollen, zum Beispiel
transcript_text,regionundagent_id, und wählen Sie dann Next aus.Markieren Sie die Spalte, die durchsucht werden soll, zum Beispiel
transcript_text, und wählen Sie dann Next aus.Wenn Sie Ihre Suchergebnisse nach mehreren bestimmten Spalten filtern möchten, markieren Sie diese Spalten und wählen dann Next aus. Wenn Sie keine Filter benötigen, wählen Sie Skip this option.
Wenn Sie Stage (Vorschau) ausgewählt haben:
Wählen Sie das Ziel für Ihre verarbeiteten Daten aus, und wählen Sie dann Next aus.
Wählen Sie die Konfigurationsparameter für den Dienst aus.
Legen Sie Ihr Ziel fest, d. h. die Zeitspanne, die Ihr Inhalt Ihres Dienstes hinter den Aktualisierungen der Basisdaten zurückbleiben soll, und wählen Sie dann Create aus.
Der letzte Schritt bestätigt, dass Ihr Service erstellt wurde und zeigt den Namen des Service und seine Datenquelle an.
Bemerkung
Wenn Sie den Dienst von der Snowsight aus erstellen, wird der Name des Dienstes in doppelten Anführungszeichen angegeben. Was das bedeutet, wenn Sie den Dienst in SQL referenzieren, erfahren Sie unter Bezeichner mit doppelten Anführungszeichen.
Berechtigungen für die Nutzung erteilen¶
Nachdem der Service und der Index erstellt wurden, können Sie anderen Rollen wie customer_support die Nutzung des Services, seiner Datenbank und seines Schemas gestatten.
Vorschau auf den Dienst¶
Um zu bestätigen, dass der Service ordnungsgemäß mit Daten gefüllt ist, können Sie eine Vorschau des Services über die Funktion SEARCH_PREVIEW aus einer SQL Umgebung heraus anzeigen:
Beispiel für eine erfolgreiche Antwort auf eine Abfrage:
Diese Antwort bestätigt, dass der Service mit Daten gefüllt ist und angemessene Ergebnisse für die gegebene Abfrage liefert.
Sie können auch die Tabellenfunktion CORTEX_SEARCH_DATA_SCAN verwenden, um den Inhalt des Dienstes zu überprüfen.
Abfrage des Dienstes von Ihrer Anwendung aus¶
Nachdem Sie den Search Service erstellt, Ihrer Rolle die Nutzung gewährt und eine Vorschau angezeigt haben, können Sie ihn nun von Ihrer Anwendung aus mit Python API abfragen.
Der folgende Code zeigt die Verwendung von Python API zum Abrufen des Support-Tickets, das für eine Abfrage über internet issues am relevantesten ist, gefiltert, um Ergebnisse in der Region North America zurückzugeben:
Beispiel für eine erfolgreiche Antwort auf eine Abfrage:
Cortex Search Services geben alle Spalten zurück, die im Feld columns in Ihrer Abfrage angegeben sind.
Erforderliche Berechtigungen¶
Um einen Cortex Search Service zu erstellen, muss Ihre Rolle über die erforderlichen Berechtigungen zur Nutzung der Cortex-Einbettungsfunktionen verfügen, was die Gewährung der Datenbankrolle SNOWFLAKE.CORTEX_USER oder SNOWFLAKE.CORTEX_EMBED_USER für die Rolle des Diensterstellenden erfordert. Sie müssen außerdem über die folgenden Berechtigungen verfügen:
CREATE CORTEX SEARCH SERVICE oder OWNERSHIP für das Schema, in dem Sie den Dienst erstellen.
SELECT für die zugrunde liegenden Tabellen oder Ansichten, die der Dienst abfragt.
USAGE für das Warehouse, das den Dienst aktualisiert.
Die Änderungsverfolgung muss für alle zugrunde liegenden Objekte, die von einem Cortex Search Service verwendet werden, aktiviert sein. Weitere Informationen zu den Anforderungen der Änderungsverfolgung finden Sie unter Anforderungen an die Änderungsverfolgung.
Um einen Cortex Search Service abzufragen, muss die Rolle des abfragenden Benutzers über die Berechtigung USAGE für den Dienst selbst sowie für die Datenbank und das Schema, in dem sich der Dienst befindet, verfügen. Siehe Anforderungen an die Cortex Search-Zugriffssteuerung Anforderungen.
Um einen Cortex Search Service mit dem Befehl ALTER auszusetzen oder wieder fortzusetzen, muss die Rolle des abfragenden Benutzers die Berechtigung OPERATE für den Service haben. Siehe ALTER CORTEX SEARCH SERVICE.
Wichtig
Cortex Search Services führen Suchvorgänge mit den Rechten des Eigentümers durch und folgen demselben Sicherheitsmodell wie andere Snowflake-Objekte, die mit den Rechten des Eigentümers laufen. Weitere Informationen finden Sie unter Anforderung der Zugriffssteuerung für Cortex Search
Die Qualität von Cortex Search verstehen¶
Cortex Search nutzt eine Reihe von Abruf- und Ranking-Modellen, um Ihnen ein hohes Maß an Suchqualität zu bieten, wobei nur wenig bis gar keine Anpassung erforderlich ist. Im Hintergrund verfolgt Cortex Search einen „hybriden“ Ansatz zum Abrufen und Rankint von Dokumenten. Jede Suchabfrage verwendet:
Vektorsuche zum Abrufen von semantisch ähnlichen Dokumenten.
Schlüsselwortsuche zum Abrufen von lexikalisch ähnlichen Dokumenten.
Semantische Neusortierung zur Neusortierung der relevantesten Dokumente in der Ergebnismenge
Dieser hybride Abrufansatz, gekoppelt mit einem semantischen Reranking-Schritt, erreicht eine hohe Suchqualität über eine breite Palette von Datasets und Abfragen.
Sie können die Bewertung der Suchergebnisse anpassen, indem Sie numerische Erhöhungen, Zeitveränderungen anwenden, Komponentengewichtungen anpassen oder die Neusortierung deaktivieren. Weitere Informationen dazu finden Sie unter Anpassen der Cortex Search-Bewertungen.
Cortex Search-Einbettungsmodelle¶
Cortex Search ermöglicht es Benutzern, ein gehostetes Einbettungsmodell auszuwählen, das im Stagingbereich der Vektorsuche verwendet werden soll. Die folgenden Einbettungsmodelle sind in Cortex Search verfügbar.
Wichtig
Die Preise für die Modelle variieren. Die Preise für kanonische Modelle finden Sie in der Snowflake Service Consumption Table. Wenn ein unten genannter Preis von dem Preis abweicht, der für das Modell in der Snowflake Service Consumption Table angezeigt wird, gilt die Snowflake Service Consumption Table.
Modellbezeichnung |
Umfang der Ausgabe |
Größe des Kontextfensters (Token) |
Unterstützung von Sprachen |
Beschreibung |
|---|---|---|---|---|
|
768 |
512 |
Nur auf Englisch |
Snowflakes praktischstes, rein englischsprachiges Einbettungsmodell. Dieses Open-Source-Modell mit 110 Mio. Parametern bietet die schnellsten Indizierungszeiten aller in Cortex Search verfügbaren Modelle. Weitere Informationen finden Sie im Blogbeitrag Arctic Embed 1.5 und Arctic Embed 1.5 Modellkarte. |
|
1024 |
512 |
Mehrsprachig |
Das preisgünstige mehrsprachige Einbettungsmodell von Snowflake mit einem Kontextfenster von 512 Token. Dieses Open-Source-Modell mit 568 Mio. Parametern liefert eine hohe Qualität sowohl bei englischen als auch bei nicht englischen Datensets. Weitere Informationen dazu finden Sie im Blogeintrag zu Arctic Embed 2 und in der `Arctic Embed 2-Modellkarte<https://huggingface.co/Snowflake/snowflake-arctic-embed-l-v2.0>`_. |
|
1024 |
8192 |
Mehrsprachig |
Das preisgünstige mehrsprachige Einbettungsmodell von Snowflake mit einem erweiterten Kontextfenster von 8.000 Token. Dieses Open-Source-Modell mit 568 Mio. Parametern liefert eine hohe Qualität sowohl bei englischen als auch bei nicht englischen Datensets. |
|
1024 |
32,000 |
Mehrsprachig |
Das mehrsprachige Einbettungsmodell von Voyage. Dieses Modell liefert sowohl bei englischen als auch bei nicht-englischen Datensätzen eine hohe Qualität. Weitere Informationen finden Sie im Blogbeitrag Voyage Multilingual 2 |
Einige Einbettungsmodelle sind für Cortex Search nur in bestimmten Regionen der Cloud verfügbar. Eine Liste der Verfügbarkeit nach Modell und Region finden Sie unter Regionale Verfügbarkeit von Cortex Search.
Jedes Modell hat unterschiedliche Leistungs-, Kosten- und Qualitätsmerkmale sowie eine jeweils andere Kontextfenstergröße. Prüfen Sie die Modellspezifikationen sorgfältig, um das beste Modell für Ihre spezielle Arbeitslast zu finden. In der Snowflake Service Consumption Table finden Sie eine möglichst genaue Ansicht der Kosten jedes Modells in Credits pro Million Token.
Token, Modellkontextfenster und Textaufteilung¶
Ein Token ist eine Sequenz von Zeichen und ist die kleinste Texteinheit, die von einem großen Sprachmodell (Large Language Model) verarbeitet werden kann. Ein Token entspricht ungefähr 3/4 eines englischen Wortes, also etwa 4 Zeichen. Um die Anzahl der Token in einer Zeichenfolge zu berechnen, verwenden Sie die COUNT_TOKENS Cortex-Funktion. Zum Beispiel die Berechnung der Token für eine Zeichenfolge, die mit dem Modell snowflake-arctic-embed-m-v1.5 eingebettet werden soll:
Jedes Vektoreinbettungsmodell unterstützt ein Kontextfenster mit fester Größe für Texteingaben, das in der vorhergehenden Tabelle des Einbettungsmodells angegeben ist. Wenn die Anzahl der Token in einem Wert in der Suchspalte sowohl bei der Indizierung als auch bei der Bereitstellung die Größe des Kontextfensters überschreitet, kürzt Cortex Search die Zeichenfolge auf die Größe des Kontextfensters, bevor sie für die semantische Suche in den Vektorraum eingebettet wird. Cortex Search verwendet jedoch den gesamten Text für die schlüsselwortbasierte Suche.
Snowflake bietet integrierte Funktionen, die das Aufteilen von Text in kleinere Blöcke unterstützen. Weitere Informationen dazu finden Sie unter SPLIT_TEXT_RECURSIVE_CHARACTER.
Für optimale Suchergebnisse mit der Cortex Search empfiehlt Snowflake, den Text in Ihrer Suchspalte in Blöcke von nicht mehr als 512 Token (etwa 385 englische Wörter) aufzuteilen. Obwohl es heute Modelle zur Einbettung in einen längeren Kontext gibt, wie z. B. snowflake-arctic-embed-l-v2.0-8k, zeigen Untersuchungen, dass eine geringere Blockgröße in der Regel zu einer höheren Abruf- und nachgelagerten LLM-Antwortqualität führt. Mit kleineren Blöcken kann der Abruf für eine bestimmte Abfrage genauer sein; in einem RAG-Szenario (Retrieval-Augmented Generation) empfängt das nachgelagerte LLM Textblöcke, die für die Abfrage relevanter sind.
Aktualisierungen¶
Der Inhalt, der in einem Cortex Search Service angeboten wird, basiert auf den Ergebnissen einer bestimmten Abfrage. Wenn sich die einem Cortex Search Service zugrunde liegenden Daten ändern, wird der Service aktualisiert, um diese Änderungen widerzuspiegeln. Diese Aktualisierungen werden als Auffrischung (engl. refresh) bezeichnet. Dieser Prozess ist automatisiert und umfasst die Analyse der Abfrage, die der Tabelle zugrunde liegt.
Die Cortex Search Services haben die gleichen Eigenschaften wie die dynamische Tabellen. Unter Initialisierung und Aktualisierung dynamischer Tabellen verstehen finden Sie Informationen zu den Aktualisierungsmerkmalen eines Cortex Search Service.
Die Quellabfrage für einen Cortex Search Service muss ein Kandidat für die dynamische inkrementelle Tabellenaktualisierung sein. Einzelheiten zu diesen Anforderungen finden Sie unter Unterstützung von inkrementellen Aktualisierungen. Diese Einschränkung soll verhindern, dass die Kosten für die Berechnung der Vektoreinbettung unkontrolliert steigen. Weitere Informationen über die Konstrukte, die für die dynamische inkrementelle Aktualisierung von Tabellen nicht unterstützt werden, finden Sie unter Unterstützte Abfragen für dynamische Tabellen.
Primärschlüssel¶
Ein Primärschlüssel eines Cortex Search Service ist ein optionaler Satz von Spalten, der jede Zeile in der Quellabfrage eindeutig identifiziert (d. h. nur eine Zeile enthält diese exakte Kombination von Werten in den dafür vorgesehenen Spalten). Um mit Cortex Search Services verwendet werden zu können, müssen die Spalten des Primärschlüssels vom Datentyp TEXT sein.
Ein Primärschlüssel kann bei der Erstellung des Service wie folgt angegeben werden:
Die Primärschlüsselspalten vorhandener Services können mit ALTER CORTEX SEARCH SERVICE ... SET PRIMARY KEY (...) geändert werden. Für eine detaillierte Syntax siehe ALTER CORTEX SEARCH SERVICE.
Services mit Primärschlüsseln können einen optimierten Aktualisierungspfad verwenden, wenn sich die dem Service zugrunde liegenden Daten ändern. Dieser optimierte Pfad kann zu erheblichen Reduzierungen der Kosten und der Latenz einer Aktualisierung führen. Wenn diese Optimierung aktiviert ist, komprimiert der Suchservice regelmäßig die Indexinformationen, die während einer Aktualisierung generiert wurden. Sie können eine Zielhäufigkeit für die Indexaktualisierung angeben, indem Sie die Eigenschaft FULL_INDEX_BUILD_INTERVAL_DAYS für den Dienst festlegen. Weitere Informationen zur Syntax finden Sie unter CREATE CORTEX SEARCH SERVICE und ALTER CORTEX SEARCH SERVICE.
Bemerkung
FULL_INDEX_BUILD_INTERVAL_DAYS ist ein vorläufiges Ziel. Vollständige Aktualisierungen können häufiger erfolgen als zu dem angegebenen Intervall, um die Bereitstellungsleistung auf der Grundlage von Faktoren wie der Verzögerung des Dienstziels, der Änderungsrate in den Quelldaten des Dienstes und der Gesamtgröße des Dienstes zu optimieren.
Abfragen an Services mit Primärschlüsseln können auch den @primarykey-Filteroperator verwenden.
Wichtig
Die Werte der Primärschlüsselspalten müssen für jede Zeile in der Quellabfrage eindeutig sein. Duplikate werden im resultierenden Suchindex ignoriert.
Multi-Index Cortex Search¶
Cortex Search kann mehrere Spalten indizieren oder kundenspezifische Vektoreinbettungen für Abfragen verwenden, was Ihnen zusätzliche Flexibilität bei der Interpretation von Daten durch Ihren Cortex Search Service und die Reaktion auf Benutzeranfragen ermöglicht. Sie sollten die Multi-Index Cortex Search verwenden, wenn Sie einen Anwendungsfall haben, der einen oder mehrere der folgenden Punkte aufweist:
Mehrere Suchfelder: Benutzende müssen über verschiedene Felder eines Datensatzes suchen.
Von Benutzenden bereitgestellte Vektoreinbettungen: Sie haben vorberechnete Vektoreinbettungen für eine oder mehrere Spalten, bevor Sie diese in den Cortex Search Service aufnehmen.
Gemischte Suchtypen: Sie möchten die Suche in verschiedenen Feldern unterstützen und bevorzugen einen Suchtyp.
Verwenden Sie Textindizes für Felder, in denen genaue oder ungenaue Übereinstimmungen der Schlüsselwörter wichtig sind. Einige Beispiele sind Produktcodes, Namen und Kategorien.
Verwenden Sie Vektorindizes für Felder mit einem längeren Textinhalt, bei denen ein semantisches Verständnis wertvoll ist. Beispiele sind Produktbeschreibungen, Benutzerbewertungen und Supportfälle.
Feldspezifische Relevanz: Verschiedene Felder Ihrer Daten sollten unterschiedlich zur Relevanz eines Suchergebnisses beitragen.
Für einen Anwendungsfall bei der Suche in einem Produktkatalog können Sie beispielsweise einen Multi-Index-Service erstellen, bei dem Folgendes gilt:
Produktnamen und SKUs sind Textindizes für eine präzise lexikalische Übereinstimmung.
Produktbeschreibungen sind Vektorindizes für den semantischen Abgleich.
Kategorie- und Markennamen sind Text- und Vektor-Indizes, sodass sowohl lexikalische als auch semantische Übereinstimmungen unterstützt werden.
Beispiele für die Erstellung eines Multi-Index Cortex Search Service finden Sie unter CREATE CORTEX SEARCH SERVICE … TEXT INDEXES .. VECTOR INDEXES. Beispiele für die Abfrage eines Multi-Index-Service finden Sie unter Abfrage eines Cortex Search Service – Multi-Index-Abfragen.
Von Benutzenden bereitgestellte Vektoreinbettungen¶
Cortex Search mit mehreren Indizes ermöglicht es Ihnen, vorberechnete Vektoreinbettungen aus jedem Einbettungsmodell (einschließlich Open-Source-Modelle, kommerzielle und kundenspezifisch trainierte Modelle) zu verwenden. Verwenden Sie von Benutzenden bereitgestellte Vektoreinbettungen in folgenden Fällen:
Sie möchten ein Einbettungsmodell verwenden, das in Cortex Search nicht nativ verfügbar ist, oder Sie möchten Einbettungen, die Sie bereits erstellt haben, wiederverwenden, um die Kosten zu senken und die Leistung zu verbessern.
Sie möchten Ihre Vektoreinbettungen mit den Textindizes von Cortex Search für hybrides Abrufen kombinieren.
Wenn Sie in einen einfachen Spaltennamen in der VECTORINDEXES-Klausel, aber kein Modell angeben, behandelt Cortex Search den Inhalt der Spalte als vom Benutzenden bereitgestellte Vektoreinbettungen. Vom Benutzenden bereitgestellte Vektoren werden unverändert indiziert und verursachen keine Einbettungskosten.
Bemerkung
Sie können Vektoren nicht direkt in eine Snowflake-Tabelle laden. Wandeln Sie stattdessen beim Einfügen oder Aktualisieren von Daten in der Quelltabelle für Ihren Cortex Search Service ein Array von Zahlen in den VECTOR-Datentyp um. Details und Beispiele hierzu finden Sie unter Vektor-Konvertierung.
Cortex Search wählt zum Zeitpunkt der Suche einen der folgenden Modi, je nachdem, ob Sie einen Abfragevektor oder einen Abfragetext in Ihrer Anfrage angeben:
Modus |
Indexzeit |
Abfragezeit |
|---|---|---|
Vollständig benutzerverwaltet |
Bereitstellen von Vektoren in einerVECTOR-Spalte |
Bereitstellen eines Abfragevektors über multi_index_query |
Benutzerverwaltet mit verwalteten Abfrageeinbettungen |
Bereitstellen von Vektoren in einerVECTOR-Spalte |
Cortex Search bettet Abfragetext unter Verwendung des angegebenen Modells ein |
Anhalten der Indizierung und Bereitstellung¶
Ähnlich wie bei Dynamic Tables setzt Cortex Search Services den Indizierungsstatus automatisch aus, wenn fünf aufeinanderfolgende Aktualisierungsfehler in Bezug auf die Ausgangsabfrage festgestellt werden. Wenn dieser Fehler bei Ihrem Service auftritt, können Sie den spezifischen SQL-Fehler entweder unter DESCRIBE CORTEX SEARCH SERVICE oder unter Ansicht CORTEX_SEARCH_SERVICES anzeigen. Die Ausgabe von beiden umfasst die folgenden Spalten:
Die Spalte INDEXING_STATE, die SUSPENDED für einen angehaltenen Dienst ist.
Die Spalte INDEXING_ERROR, die den spezifischen SQL-Fehler enthält, der in der Quellabfrage aufgetreten ist.
Sobald die Ursache behoben ist, können Sie den Dienst unter ALTER CORTEX SEARCH SERVICE <name> RESUME INDEXING fortsetzen. Für eine detaillierte Syntax siehe ALTER CORTEX SEARCH SERVICE.
Hinweise zu Kosten¶
Ein Cortex Search Service verursacht Kosten auf folgende Weise:
Kategorie |
Beschreibung |
|---|---|
Computing von virtuellen Warehouses |
Ein Cortex Search Service benötigt ein virtuelles Warehouse, um den Service zu aktualisieren: um Abfragen gegen Basisobjekte durchzuführen, wenn diese initialisiert und aktualisiert werden, einschließlich der Orchestrierung von Texteinbettungsaufträgen und dem Aufbau des Suchindexes. Diese Operationen nutzen Computeressourcen, die Credits verbrauchen. Wenn bei einer Aktualisierung keine Änderungen festgestellt werden, werden keine Credits für das virtuelle Warehouse verbraucht, da es keine neuen Daten zu aktualisieren gibt. |
EMBED_TEXT-Token berechnen |
Ein Cortex Search Service bettet automatisch jede Textzeile in der im Parameter |
Multi-Index Cortex Search |
Die Kosten für Multi-Index Cortex Search Services hängen davon ab, wie Sie die Token einbetten, und von der Anzahl der Spalten, die Sie indizieren. Größere Einbettungsvektoren oder eine größere Anzahl von Indexspalten verursachen höhere Kosten. Die Einbettungen werden jedes Mal berechnet, wenn eine Zeile eingefügt oder aktualisiert wird. Die Einbettungen werden bei der Auswertung der Abfrage inkrementell verarbeitet, sodass die Einbettungskosten nur für hinzugefügte oder geänderte Dokumente anfallen. |
Rechenleistung |
Ein Cortex Search Service nutzt mandantenfähige Rechenleistung, die von einem vom Benutzer bereitgestellten Warehouse getrennt ist, um einen Dienst mit niedriger Latenz und hohem Durchsatz einzurichten. Die Rechenkosten für diese Komponente fallen pro GB pro Monat (GB/mo) unkomprimierter indizierter Daten an, wobei indizierte Daten die vom Benutzer in der Cortex Search-Quellabfrage bereitgestellten Daten plus die im Namen des Benutzers berechneten Vektoreinbettungen sind. Diese Kosten fallen an, solange der Dienst zur Beantwortung von Abfragen zur Verfügung steht, auch wenn in einem bestimmten Zeitraum keine Abfragen gestellt werden. Die Credit-Rate für Cortex Search-Bereitstellung pro GB/mo indizierter Daten finden Sie in der Snowflake Service Consumption Table. |
Speicher |
Cortex Search Services materialisiert die Abfrage in einer Tabelle, die in Ihrem Konto gespeichert ist. Diese Tabelle wird in Datenstrukturen umgewandelt, die für eine niedrige Latenzzeit optimiert sind und ebenfalls in Ihrem Konto gespeichert werden. Der Speicher für die Tabelle und die dazwischen liegenden Strukturen basiert auf einer Pauschale pro Terabyte (TB). |
Cloud Services Compute |
Cortex Search Services verwenden Cloud Services-Berechnung um Änderungen in den zugrunde liegenden Basisobjekten zu erkennen und um festzustellen, ob das Warehouse aufgerufen werden muss. Die Computekosten für Clouddienste-Computing unterliegen der Einschränkung, dass Snowflake diese nur abrechnet, wenn die täglichen Kosten der Clouddienste mehr als 10 % der täglichen Warehouse-Kosten für das Konto betragen. |
Bewährte Verfahren zur Verwaltung der Kosten eines Cortex Search Service finden Sie unter Die Kosten für Cortex Search Services verstehen.
Um die AI Services-bezogenen Verbrauchskosten für jeden Cortex Search Service in Ihrem Konto, täglich aggregiert, anzuzeigen, besuchen Sie die Ansicht CORTEX_SEARCH_DAILY_USAGE_HISTORY
Bekannte Einschränkungen¶
Die Verwendung von Cortex Search unterliegt den folgenden Beschränkungen:
Größe der Basistabelle: Das Ergebnis der materialisierten Abfrage im Suchdienst muss weniger als 100 Millionen Zeilen groß sein, um eine optimale Leistung zu gewährleisten. Wenn das materialisierte Ergebnis Ihrer Abfrage mehr als 100M Zeilen enthält, schlägt die Erstellungsabfrage mit einem Fehler fehl.
Bemerkung
Um die Beschränkungen der Zeilenskalierung bei einem Cortex Search Service über 100 Mio. zu erhöhen, wenden Sie sich bitte an das Team Ihres Snowflake-Kontos.
Durchsatz- und Ratenbegrenzung: Cortex Search liefert einen HTTP-Statuscode 429, wenn ein Client Anforderungen zu schnell sendet oder wenn der Service überlastet ist. Die Clientlogik, die den Search Service aufruft, sollte eine Backoff- und eine Wiederholungslogik implementieren, um diese 429-Antworten ordnungsgemäß verarbeiten zu können.
Bemerkung
Zur Erhöhung des Durchsatzes über 20 QPS für einen einzelnen Search Service oder 140 QPS für alle Dienste in Ihrem Konto wenden Sie sich an Ihren Snowflake-Kundenbetreuer.
Abfragekonstrukte: Die Abfragen des Cortex Search Service müssen denselben Abfragebeschränkungen unterliegen wie die dynamischen Tabellen. Weitere Informationen finden Sie unter Beschränkungen für dynamische Tabellen.
Datenaufbewahrung: Cortex Search Services haben die gleichen Anforderungen wie dynamische Tabellen an die Datenaufbewahrung. Insbesondere können Sie nicht den Objektparameter:ref:
label-data_retention_time_in_daysin Ihren Basistabellen auf null setzen oder diesen Parameter für das Schema oder die Datenbank festlegen, das/die den Search Service enthält. Außerdem können Search Services veralten, wenn sie nicht innerhalb von MAX_DATA_EXTENSION_TIME_IN_DAYS aktualisiert werden. Sobald sie veraltet sind, müssen sie neu erstellt werden, um die Aktualisierungen fortzusetzen. Weitere Informationen finden Sie unter Beschränkungen für dynamische Tabellen.Klonen: Cortex Search Services unterstützen derzeit nicht das cloning. Snowflake beabsichtigt, diese Funktion in einem zukünftigen Release bereitzustellen, kann dies aber nicht garantieren.
Unveränderlichkeit der Tabelle: Während der Ausführung erfordern Ihre Cortex Search Services, dass Tabellen, auf die sie zugreifen, nicht geändert oder gelöscht werden. Um die von einem Cortex Search Service verwendeten Tabellen auf sichere Weise zu aktualisieren, müssen Sie den Service anhalten, bevor Sie Ihre Änderungen vornehmen.
Regionale Verfügbarkeit¶
Dieses Feature ist für Konten in den folgenden Snowflake-Regionen verfügbar: Die Verfügbarkeit für bestimmte Einbettungsmodelle innerhalb einer Region ist durch ein Häkchen gekennzeichnet.
Cloudanbieter
|
Region
|
snowflake-arctic-embed-m-v1.5 |
snowflake-arctic-embed-l-v2.0 |
snowflake-arctic-embed-l-v2.0-8k |
voyage-multilingual-2 |
|---|---|---|---|---|---|
AWS
|
US West 2 (Oregon)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US East 2 (Ohio)
|
✔ |
✔ |
✔ |
|
AWS
|
US East 1 (N. Virginia)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US East (Commercial Gov - N. Virginia)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Canada (Central)
|
✔ |
✔ |
✔ |
|
AWS
|
South America (São Paulo)
|
✔ |
✔ |
✔ |
|
AWS
|
Europa (Irland)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe (London)
|
✔ |
✔ |
✔ |
|
AWS
|
Europe Central 1 (Frankfurt)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Europe (Stockholm)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Tokio)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
Asia Pacific (Mumbai)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Sydney)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Jakarta)
|
✔ |
✔ |
✔ |
|
AWS
|
Asia Pacific (Seoul)
|
✔ |
✔ |
✔ |
|
Azure
|
East US 2 (Virginia)
|
✔ |
✔ |
✔ |
|
Azure
|
West US 2 (Washington)
|
✔ |
✔ |
✔ |
|
Azure
|
South Central US (Texas)
|
✔ |
✔ |
✔ |
|
Azure
|
UK South (London)
|
✔ |
✔ |
✔ |
|
Azure
|
North Europe (Irland)
|
✔ |
✔ |
✔ |
|
Azure
|
West Europe (Niederlande)
|
✔ |
✔ |
✔ |
✔ |
Azure
|
Switzerland North (Zürich)
|
✔ |
✔ |
✔ |
|
Azure
|
Central India (Pune)
|
✔ |
✔ |
✔ |
|
Azure
|
Japan East (Tokyo, Saitama)
|
✔ |
✔ |
✔ |
|
Azure
|
Southeast Asia (Singapur)
|
✔ |
✔ |
✔ |
|
Azure
|
Australia East (New South Wales)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 2 (London)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 3 (Frankfurt)
|
✔ |
✔ |
✔ |
|
GCP
|
Europe West 4 (Niederlande)
|
✔ |
✔ |
✔ |
|
GCP
|
Naher Osten Zentral 2 (Dammam)
|
✔ |
✔ |
✔ |
|
GCP
|
US Central 1 (Iowa)
|
✔ |
✔ |
✔ |
|
GCP
|
US East 4 (N. Virginia)
|
✔ |
✔ |
✔ |
Bemerkung
Sie können den regionsübergreifenden Inferenzparameter in jeder der oben genannten Regionen angeben, um auf Modelle zuzugreifen, die nicht direkt von Ihrer Standardregion unterstützt werden.
Cortex Search ist in den folgenden Regionen nur mit regionenübergreifender Inferenz verfügbar. Um die Cortex Search mit regionenübergreifender Inferenz zu nutzen, verwenden Sie den Parameter regionenübergreifende Inferenz.
AWS Europa (Paris)
AWS Europa (Zürich)
AWS Asia Pacific (Singapur)
AWS Asia Pacific (Osaka)
Azure Canada Central (Toronto)
Azure Central US (Iowa)
Azure UAE North (Dubai)
Bemerkung
Bei der regionenübergreifenden Inferenz hängt die Latenz bei Abfragen zwischen Regionen von der Infrastruktur des Cloudanbieters und dem Netzwerkstatus ab. Snowflake empfiehlt, dass Sie Ihren speziellen Anwendungsfall mit aktivierter regionsübergreifender Inferenz testen.
Rechtliche Hinweise¶
Die Datenklassifizierung der Eingaben und Ausgaben ist in der folgenden Tabelle aufgeführt.
Klassifizierung von Eingabedaten |
Klassifizierung von Ausgabedaten |
Benennung |
|---|---|---|
Usage Data |
Customer Data |
Die allgemein verfügbaren Funktionen sind abgedeckte AI-Features. Die Vorschaufunktionen sind Vorschau-AI-Features. [1] |
Weitere Informationen dazu finden Sie unter KI und ML in Snowflake.