Abfrageaktivität mit Abfrageverlauf überwachen¶
Um die Abfrageaktivitäten in Ihrem Konto zu überwachen, können Sie Folgendes verwenden:
Die Seiten Query History und Grouped Query History in Snowsight.
Die Ansicht QUERY_HISTORY und Ansicht AGGREGATE_QUERY_HISTORY im Schema ACCOUNT_USAGE der Datenbank SNOWFLAKE.
Die QUERY_HISTORY-Familie von Tabellenfunktionen in INFORMATION_SCHEMA.
Auf der Seite Query History in Snowsight können Sie Folgendes tun:
Überwachen Sie einzelne oder gruppierte Abfragen, die von Benutzern in Ihrem Konto ausgeführt werden.
Anzeigen von Details zu Abfragen, einschließlich Performancedaten. In einigen Fällen sind Abfragedetails nicht verfügbar.
Untersuchen jedes Schritts einer ausgeführten Abfrage im Query Profile.
Auf der Seite „Query History“ (Abfrageverlauf) können Sie die in Ihrem Snowflake-Konto ausgeführten Abfragen der letzten 14 Tage anzeigen.
Innerhalb eines Arbeitsblatts können Sie den Abfrageverlauf für Abfragen einsehen, die in diesem Arbeitsblatt ausgeführt wurden. Siehe Abfrageverlauf anzeigen.
Abfrageverlauf in Snowsight überprüfen¶
Um die Seite Query History in Snowsight aufzurufen, gehen Sie wie folgt vor:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Monitoring » Query History aus.
Rufen Sie Individual Queries oder Grouped Queries auf. Weitere Informationen über gruppierte Abfragen finden Sie unter Verwenden Sie die Ansicht „Gruppierter Abfrageverlauf“ in Snowsight.
Für Individual Queries, filtern Sie Ihre Ansicht, um die relevantesten und genauesten Ergebnisse zu sehen.
Wenn am Anfang der Liste eine Schaltfläche Load More erscheint, bedeutet dies, dass noch weitere Ergebnisse zum Laden vorhanden sind. Sie können die nächste Gruppe von Ergebnissen abrufen, indem Sie entweder Load More wählen oder zum Ende der Liste blättern.
Erforderliche Berechtigungen zum Anzeigen des Abfrageverlaufs¶
Sie können jederzeit den Verlauf der von Ihnen ausgeführten Abfragen einsehen.
Es hängt aber von Ihrer aktiven Rolle ab, für welche weitere Abfragen Ihnen auf der Seite Query History Verläufe angezeigt werden:
Wenn Ihre aktive Rolle die Rolle ACCOUNTADMIN ist, können Sie Verläufe aller Abfragen des Kontos einsehen.
Wenn Ihre aktive Rolle die Berechtigung MONITOR oder OPERATE für ein Warehouse hat, können Sie Abfragen anzeigen, die von anderen Benutzern ausgeführt wurden, die dieses Warehouse verwenden.
Wenn Ihrer aktiven Rolle die Datenbankrolle GOVERNANCE_VIEWER für die Datenbank SNOWFLAKE zugewiesen ist, reicht es aus, die ACCOUNT_USAGE-Ansichten direkt mit SQL abzufragen. Sie ermöglicht es Ihnen auch, Grouped Queries im Abfrageverlauf anzuzeigen. Diese Rolle allein bietet Ihnen jedoch nicht die Fähigkeit, Individual Queries von anderen Benutzern in Snowsight anzuzeigen. Um alle Benutzerabfragen (sowohl gruppiert als auch individuell) anzuzeigen, muss Ihre Rolle ACCOUNTADMIN sein oder Sie müssen IMPORTED PRIVILEGES für die SNOWFLAKE-Datenbank gewährt bekommen. Alternativ können die folgenden beiden Berechtigungen die IMPORTED PRIVILEGES ersetzen:
Wenn Ihrer aktiven Rolle die Datenbankrolle READER_USAGE_VIEWER für die Datenbank SNOWFLAKE zugewiesen ist, können Sie den Abfrageverlauf für alle Benutzer von Leserkonten anzeigen, die mit Ihrem Konto verbunden sind. Siehe SNOWFLAKE-Datenbankrollen.
Hinweise zur Verwendung des Abfrageverlaufs¶
Wenn Sie den Abfrageverlauf in Query History für Ihr Konto überprüfen, beachten Sie Folgendes:
Details für Abfragen, die vor mehr als sieben Tagen ausgeführt wurden, enthalten keine User-Informationen aufgrund der Datenaufbewahrungsrichtlinie für Sitzungen. Sie können den Benutzerfilter verwenden, um die von einzelnen Benutzern ausgeführten Abfragen abzurufen. Siehe Abfrageverlaufsfilter.
Bei Abfragen, die aufgrund von Syntax- oder Parsing-Fehlern fehlgeschlagen sind, wird Ihnen anstelle der ausgeführten SQL-Anweisung
<redacted>(Abfragetext ist unkenntlich gemacht) angezeigt. Wenn Sie über eine Rolle mit entsprechenden Berechtigungen verfügen, können Sie den Parameter ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR setzen, um den vollständigen Abfragetext anzuzeigen.Für Filter und die Spalten Started und End Time wird Ihre aktuelle Zeitzone verwendet. Sie können diese Einstellung nicht ändern. Die Einstellung des Parameters TIMEZONE für die Sitzung ändert nicht die verwendete Zeitzone.
Abfrageverlaufsfilter¶
Sie können die Abfrageverlaufsliste nach folgenden Kriterien filtern:
Status der Abfrage, um z. B. Abfragen mit langer Ausführungszeit, fehlgeschlagene Abfragen und Abfragen in der Warteschlange zu identifizieren.
Benutzer, der die Abfrage ausgeführt hat, einschließlich:
All, um alle Benutzer anzuzeigen, für die Sie Zugriff auf den Abfrageverlauf haben.
Benutzer, mit dem Sie sich angemeldet haben (Standard)
Einzelne Snowflake-Benutzer in Ihrem Konto, wenn Sie mit Ihrer Rolle den Abfrageverlauf von anderen Benutzer einsehen dürfen.
Zeitraum, in dem die Abfrage ausgeführt wurde, begrenzt auf 14 Tage.
Weitere Filter, darunter die folgenden:
SQL Text, um beispielsweise Abfragen anzuzeigen, die bestimmte Anweisungen verwenden, wie GROUP BY.
Query ID, um Details zu einer bestimmten Abfrage anzuzeigen.
Warehouse, um Abfragen anzuzeigen, die unter Verwendung eines bestimmten Warehouses ausgeführt wurden.
Statement Type, um Abfragen anzuzeigen, die einen bestimmten Anweisungstyp verwenden, z. B. DELETE, UPDATE, INSERT oder SELECT.
Duration, um z. B. Abfragen mit besonders langer Ausführungsdauer zu identifizieren.
Session ID, um Abfragen anzuzeigen, die während einer bestimmten Snowflake-Sitzung ausgeführt wurden.
Query Tag, um Abfragen mit einem bestimmten Abfrage-Tag anzuzeigen, das über den Sitzungsparameter QUERY_TAG festgelegt wurde.
Parameterized Query Hash, um Abfragen gruppiert nach der im Filter angegebenen ID des parametrisierten Abfrage-Hashwert anzuzeigen. Weitere Informationen dazu finden Sie unter Verwenden des Hash-Wertes der parametrisierten Abfrage (query_parameterized_hash).
Client generated statements, um interne Abfragen anzuzeigen, die von einem Client, Treiber oder einer Bibliothek ausgeführt werden, einschließlich der Weboberfläche. Wenn ein Benutzer beispielsweise in Snowsight zur Seite Warehouses navigiert, führt Snowflake im Hintergrund eine SHOW WAREHOUSES-Anweisung aus. Diese Anweisung wird sichtbar, wenn dieser Filter aktiviert ist. Ihrem Konto werden keine Anweisungen in Rechnung gestellt, die vom Client generiert werden.
Queries executed by user tasks, um ausgeführte SQL-Anweisungen oder gespeicherte Prozeduren anzuzeigen, die von Benutzeraufgaben aufgerufen wurden.
Show replication refresh history, um Abfragen anzuzeigen, die zum Ausführen von Aktualisierungsaufgaben für die Replikation in Remoteregionen und Remotekonten verwendet werden.
Wenn Sie Ergebnisse nahezu in Echtzeit anzeigen möchten, aktivieren Sie Auto Refresh. Wenn Auto Refresh aktiviert ist, wird die Tabelle alle zehn Sekunden aktualisiert.
In der Tabelle Queries werden standardmäßig die folgenden Spalten angezeigt:
SQL Text mit dem Text der ausgeführten Anweisung (immer angezeigt).
Query ID mit der ID der Abfrage (immer angezeigt).
Status mit dem Status der ausgeführten Anweisung (immer angezeigt).
User mit dem Benutzernamen, der eine Anweisung ausgeführt hat.
Warehouse mit dem Warehouse, das zum Ausführen einer Anweisung verwendet wurde.
Duration mit der Zeitdauer, die zum Ausführen einer Anweisung benötigt wurde.
Started mit dem Zeitpunkt, zu dem die Ausführung der Anweisung gestartet wurde.
Wenn Sie mehr Ergebnisse haben, können Sie die Tabelle nicht sortieren. Wenn Sie nach dem Sortieren der Tabelle Load More am Anfang der Liste auswählen, werden die neuen Ergebnisse an das Ende der Daten angehängt und die Sortierreihenfolge gilt nicht mehr.
Um spezifischere Informationen anzuzeigen, können Sie durch Auswahl von Columns Spalten zur Tabelle hinzuzufügen oder entfernen, z. B.:
All, um alle Spalten anzuzeigen.
User, um den Benutzer anzuzeigen, der die Anweisung ausgeführt hat.
Warehouse, um den Namen des Warehouse anzuzeigen, das für die Ausführung der Anweisung verwendet wird.
Warehouse Size, um die Größe des Warehouses anzuzeigen, das zur Ausführung der Anweisung verwendet wurde.
Duration, um die Zeit anzuzeigen, die für die Ausführung der Anweisung benötigt wurde.
Started, um die Startzeit der Anweisung anzuzeigen.
End Time, um den Zeitpunkt anzuzeigen, an dem die Ausführung der Anweisung beendet war.
Session ID, um den ID der Sitzung anzuzeigen, die die Anweisung ausgeführt hat.
Client Driver, um den Namen und die Version von Client, Treiber oder Bibliothek anzuzeigen, die zur Ausführung der Anweisung verwendet werden. Bei Anweisungen, die in Snowsight ausgeführt werden, wird
Go 1.1.5angezeigt.Bytes Scanned, um die Anzahl der Bytes anzuzeigen, die während der Verarbeitung der Abfrage gescannt wurden.
Rows, um die Anzahl der von einer Anweisung zurückgegebenen Zeilen anzuzeigen.
Query Tag, um das auf eine Abfrage gesetzte Tag anzuzeigen.
Parameterized Query Hash, um Abfragen anzuzeigen, die nach der ID des im Filter angegebenen parametrisierten Abfrage-Hashwerts gruppiert sind. Weitere Informationen dazu finden Sie unter Verwenden des Hash-Wertes der parametrisierten Abfrage (query_parameterized_hash).
Incident, um Details zu Anweisungen mit Ausführungsstatus „Incident“ (Vorfall) anzuzeigen, die für Problembehandlung oder Debugging verwendet werden können.
Um zusätzliche Details zu einer Abfrage anzuzeigen, wählen Sie die Abfrage in der Tabelle aus, wodurch Query Details geöffnet wird.
Verwenden Sie die Ansicht „Gruppierter Abfrageverlauf“ in Snowsight¶
Sie können die Ansicht Grouped Query History in Snowsight verwenden, um die Nutzung und Leistung von kritischen und häufig ausgeführten Abfragen zu überwachen. Diese grafische Ansicht basiert auf Informationen, die im Ansicht AGGREGATE_QUERY_HISTORY gespeichert sind. Ausgeführte Abfragen werden anhand der ID des parametrisierten Abfrage-Hashwerts gruppiert. Sie können die wichtigsten Statistiken im Laufe der Zeit überwachen und die einzelnen Abfragen, die zu jeder Gruppe gehören, aufschlüsseln.
Obwohl diese Ansicht alle Abfragen auf Snowflake umfasst, ist sie besonders nützlich für die Überwachung und Analyse von Unistore Workloads, die wiederholt eine kleine Anzahl von unterschiedlichen Anweisungen mit hohem Durchsatz ausführen. Bei Workloads, die Hybridtabellen beinhalten, ist es schwierig, die Leistung anhand einzelner Abfragen zu überwachen.
Ihre Arbeitslast könnte beispielsweise aus Tausenden von sehr ähnlichen Point-Lookup-Abfragen und Einfügungen bestehen, die sich nur durch die Benutzer-ID unterscheiden, extrem schnell ablaufen und sich so oft wiederholen, dass sie nicht einzeln analysiert werden können. Eine aggregierte Ansicht dieser Operationen ist unerlässlich, wenn Sie Fragen wie diese beantworten möchten:
Welche gruppierten Abfragen (oder parametrisierte Abfragen) verbrauchen die meiste Gesamtzeit oder die meisten Ressourcen in meinem Konto oder meiner Arbeitslast?
Hat sich die Leistung einer parametrisierten Abfrage im Laufe der Zeit wesentlich verändert?
Welche Arten von Problemen treten bei einer parametrisierten Abfrage auf? Sperre? Warteschlange? Lange Kompilierungszeiten?
Wie oft ist eine parametrisierte Abfrage erfolgreich oder fehlgeschlagen? Weniger als ein Prozent der Zeit oder häufiger als das?
So verwenden Sie den gruppierten Abfrageverlauf¶
Gehen Sie wie folgt vor, um die Seite Grouped Query History unter Snowsight aufzurufen:
Melden Sie sich bei Snowsight an.
Wählen Sie im Navigationsmenü die Option Monitoring » Query History » Grouped Queries aus. Die Seite zeigt Ihnen Abfragen gruppiert nach der gemeinsamen ID ihres parametrisierten Abfrage-Hashwerts.
Bemerkung
Die einzelnen Abfragen werden nicht sofort in der Liste Grouped Queries angezeigt. Die Latenzzeit für die Aktualisierung der Liste anhand der Datensätze in der Ansicht AGGREGATE_QUERY_HISTORY kann bis zu 180 Minuten (3 Stunden) betragen, aber die Liste wird oft viel schneller aufgefüllt.
Wählen Sie eine beliebige gruppierte Abfrage aus, um Leistungsstatistiken für diesen parametrisierten Abfrage-Hashwert anzuzeigen. Snowsight zeigt die Gesamtzahl der ausgeführten Abfragen, die Anzahl der fehlgeschlagenen Abfragen, die Latenz (p50, p90, p99) und die Ausführungen pro Minute an. Im unteren Abschnitt der Seite finden Sie einige Beispiele für einzelne Abfragen, die im Rahmen dieses Hashwerts ausgeführt wurden. Sie können jede Abfrage auswählen, um ihre spezifischen Details anzuzeigen.
Während des letzten Tages wurden in dieser Gruppe beispielsweise etwa 540 Abfragen mit einer Gesamtdauer von etwa 3 Stunden durchgeführt:
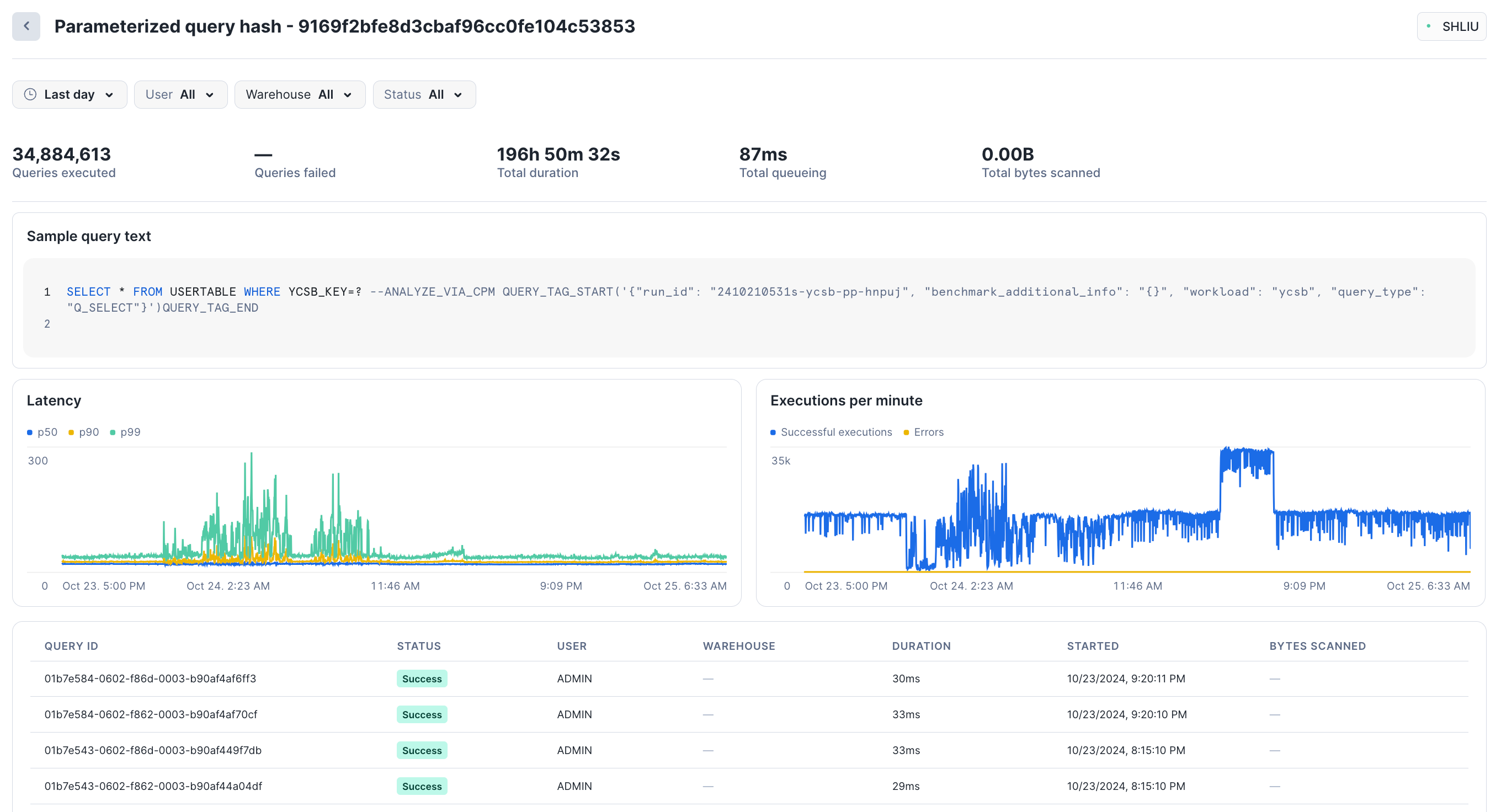
In der Ansicht Parameterized query hash können Sie Abfragen nach Status filtern, wie z. B. Failed oder Successful. Sie können sowohl in der Ansicht Grouped Queries als auch in der Ansicht Parameterized query hash nach Datumsbereich, Benutzendem und Warehouse filtern. Der Datumsbereich ist auf ein Maximum der letzten 14 Tage des gruppierten Abfrageverlaufs beschränkt. Sie können keine Informationen zu Abfragen abrufen, die vor mehr als 14 Tagen ausgeführt wurden.
Beachten Sie, dass es sich bei einigen Warehouses um interne Warehouses handelt, die von Snowflake verwaltet werden, und dass diese Warehouses nicht vom Filter Warehouse angezeigt werden. Ähnlich verhält es sich mit SYSTEM-Benutzer, der auch nicht vom Filter User angezeigt wird.
Alternativ zur Verwendung von Filtern können Sie aggregierte Abfragen ausführen, die gefilterte Ergebnisse liefern. Siehe auch Ansicht AGGREGATE_QUERY_HISTORY.
Liste der einzelnen Abfragen¶
Alternativ können Sie sich auch Individual Queries ansehen. Diese Ansicht spiegelt nicht alle Abfragen wider, die von Unistore Workloads ausgeführt werden, angesichts der schieren Menge an Abfragen, die für Hybridtabellen erstellt werden können. Weitere Informationen zu diesem Verhalten finden Sie im Abschnitt zu Hybridtabellen unter Nutzungshinweise. Snowflake empfiehlt, dass alle Benutzenden mit Unistore Workloads zunächst die Ansicht Grouped Queries überwachen.
Erforderliche Berechtigungen zum Anzeigen des gruppierten Abfrageverlaufs¶
Benutzer können jederzeit den Verlauf der von ihnen durchgeführten Abfragen anzeigen. Die aktive Rolle eines Benutzers beeinflusst, welche anderen Abfragen angezeigt werden. Sie können sowohl Grouped Queries als auch Individual Queries anzeigen, wenn einer der folgenden Punkte zutrifft:
Ihre aktive Rolle ist ACCOUNTADMIN.
Ihre aktive Rolle wurde IMPORTED PRIVILEGES in der Datenbank SNOWFLAKE zugewiesen (siehe Ermöglicht anderen Rollen die Verwendung von Schemas in der SNOWFLAKE-Datenbank.).
Sie haben die GOVERNANCE_VIEWER Datenbankrolle.
Wenn Sie keine dieser Rollen oder Berechtigungen haben, können Sie nur Individual Queries anzeigen. Weitere Informationen über Zugriffsrechte finden Sie unter Abfrageaktivität mit Abfrageverlauf überwachen.
Details und Profil einer bestimmten Anfrage überprüfen¶
Wenn Sie in Query History eine Abfrage auswählen, können Sie zugehörige Details und das Profil der Abfrage überprüfen.
Von einer Snowflake Native App ausgeblendete Query Profile-Daten¶
Das Snowflake Native App Framework maskiert in den folgenden Kontexten die Informationen aus dem Query Profile:
Abfragen, die ausgeführt werden, wenn die App installiert oder aktualisiert wird.
Abfragen, die von einer gespeicherten Prozedur stammen, deren Eigentümer die App ist.
Abfragen, die eine nicht sichere Ansicht oder Funktion enthalten, deren Eigentümer die App ist.
Für jeden dieser Abfragetypen fasst Snowsight die Query Profile-Daten zu einem einzigen leeren Knoten zusammen, anstatt den vollständigen Query Profile-Strukturbaum anzuzeigen.
Abfragedetails überprüfen¶
Um die Details einer bestimmten Abfrage zu überprüfen und die Ergebnisse einer erfolgreichen Abfrage anzuzeigen, öffnen Sie Query Details für eine Abfrage.
Unter Details können Sie Informationen zur Abfrageausführung überprüfen, einschließlich:
Status der Abfrage
Zeitpunkt des Beginns der Abfrage, in der lokalen Zeitzone des Benutzers
Zeitpunkt des Endes der Abfrage, in der lokalen Zeitzone des Benutzers
Größe des für die Abfrage verwendeten Warehouses
Dauer der Abfrage
Abfrage-ID
Abfrage-Tag für die Abfrage, falls vorhanden
Treiberstatus. Weitere Details dazu finden Sie unter View the Snowflake client version.
Namen und Version von Client, Treiber oder Bibliothek, die zur Übermittlung der Abfrage verwendet wurden. Beispiel:
Go 1.1.5für Abfragen, die über Snowsight ausgeführt wurden.Sitzung-ID
Über der Registerkarte Query Details wird das Warehouse angezeigt, das zur Ausführung der Abfrage verwendet wurde, sowie der Benutzer, der die Abfrage ausgeführt hat.
Der Bereich SQL Text enthält den eigentlichen Text der Abfrage. Bewegen Sie den Mauszeiger über den SQL-Text, um die Anweisung in einem Arbeitsblatt zu öffnen oder die Anweisung zu kopieren. Wenn die Abfrage fehlgeschlagen ist, können Sie die Fehlerdetails überprüfen.
Der Bereich Results enthält die Ergebnisse der Abfrage. Es werden nur die ersten 10.000 Zeilen eines Ergebnisses angezeigt, und die Ergebnisse können nur von dem Benutzer eingesehen werden, der die Abfrage ausgeführt hat. Wählen Sie Export Results aus, um den vollständigen Satz von Ergebnissen als CSV-formatierte Datei zu exportieren.
Query Profile überprüfen¶
Auf der Registerkarte Query Profile können Sie den Ausführungsplan der Abfrage untersuchen und detaillierte Informationen zu den einzelnen Ausführungsschritten abrufen.
Query Profile ist ein leistungsfähiges Tool zum Verständnis der Mechanismen von Abfragen. Es kann verwendet werden, wenn Sie mehr über die Leistung oder das Verhalten einer bestimmten Abfrage erfahren müssen. Das Tool soll Ihnen helfen, typische Fehler in SQL-Abfrageausdrücken zu erkennen, um potenzielle Leistungsengpässe und Verbesserungsmöglichkeiten zu identifizieren.
Dieser Abschnitt gibt einen kurzen Überblick über die Navigation und Verwendung von Query Profile.
Schnittstelle |
Beschreibung |
|---|---|
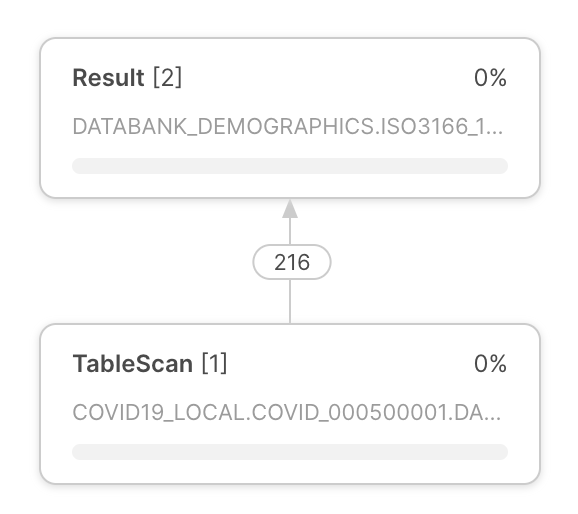
Ausführungsplan von Abfragen |
Der Ausführungsplan von Abfragen wird in der Mitte von Query Profile angezeigt. Der Ausführungsplan von Abfragen besteht aus Operatorknoten, die Rowset-Operatoren repräsentieren. Pfeile zwischen den Operatoren zeigen die Rowsets an, die von einem Operator zu einem anderen weitergegeben werden. |
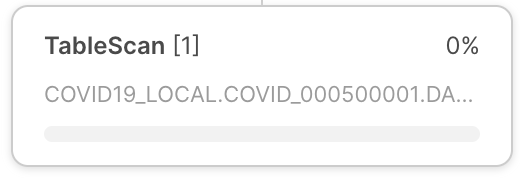
Operatorknoten |
Jeder Operatorknoten enthält folgende Informationen:
|

Query Profile-Navigation |
Verwenden Sie die Schaltflächen in der linken oberen Ecke von Query Profile für folgende Aktionen:
Bemerkung Schritte werden nur angezeigt, wenn die Abfrage in Schritten ausgeführt wurde. |

Informationsbereiche |
Query Profile bietet verschiedene Informationsbereiche. Die Bereiche werden im Abfrageausführungsplan angezeigt. Welche Bereiche angezeigt werden, hängt vom Fokus des Abfrageausführungsplans ab. Query Profile enthält die folgenden Informationsbereiche:
Weitere Informationen zu den Informationen, die in den Bereichen bereitgestellt werden, finden Sie unter Referenz zum Query Profile. |
Von einer Snowflake Native App ausgeblendete Abfrageverlaufsdaten¶
Bei Abfragen, die sich auf eine Snowflake Native App beziehen, werden die Felder query_text und error_message in der Abfragehistorie (Query History) in den folgenden Kontexten ausgeblendet:
Abfragen, die ausgeführt werden, wenn die App installiert oder aktualisiert wird.
Abfragen, die von einem untergeordneten Job einer gespeicherten Prozedur stammen, deren Eigentümer die App ist.
In jeder dieser Situationen ist die Zelle des Abfrageverlaufs in Snowsight leer.
Referenz zum Query Profile¶
In diesem Abschnitt werden alle Elemente beschrieben, die in den einzelnen Informationsbereichen angezeigt werden können. Der genaue Inhalt der Informationsfenster hängt vom Kontext des Abfrageausführungsplans ab.
Profilübersicht¶
Der Bereich enthält Informationen dazu, welche Verarbeitungsaufgaben Abfragezeit verbraucht haben. Die Ausführungszeit enthält Informationen darüber, wofür die Zeit während der Verarbeitung einer Abfrage verbraucht wurde. Die aufgewendete Zeit kann in folgende Kategorien unterteilt werden:
Processing – Zeit, die von der CPU für die Datenverarbeitung verbraucht wurde.
Local Disk IO – Zeit, in der die Verarbeitung durch den Zugriff auf die lokale Festplatte blockiert wurde.
Remote Disk IO – Zeit, in der die Verarbeitung durch Remote-Festplattenzugriff blockiert wurde.
Network Communication – Zeit, in der die Verarbeitung auf die Netzwerkdatenübertragung wartete.
Synchronization – Verschiedene Synchronisationsaktivitäten zwischen den beteiligten Prozessen.
Initialization – Zeit, die für das Einrichten der Abfrageverarbeitung verbraucht wurde.
Hybrid Table Requests Throttling – Zeitaufwand Drosselung von Anfragen zum Lesen und Schreiben von Daten, die in Hybridtabellen gespeichert sind.
Abfragen von Insights¶
Wenn es Bedingungen gibt, die sich auf die Abfrageleistung auswirken, bietet dieses Fenster Einblicke in diese Bedingungen. Jeder Insight enthält eine Meldung, die erläutert, wie die Abfrage-Performance möglicherweise beeinträchtigt wird, und gibt eine allgemeine Empfehlung für die nächsten Schritte.
Weitere Informationen dazu finden Sie unter Verwenden von Abfrageanalysen zur Verbesserung der Abfrageleistung.
Bemerkung
Sie können auf diese Einblicke zugreifen, indem Sie Ansicht QUERY_INSIGHTS abfragen.
Statistiken¶
Eine wichtige Informationsquelle im Detailbereich sind die verschiedenen Statistiken, die in folgende Abschnitte unterteilt sind:
IO – Informationen zu den während der Abfrage ausgeführten Eingabe/Ausgabe-Operationen:
Scan progress – Prozentsatz der Daten, die bislang für eine bestimmte Tabelle gescannt wurden.
Bytes scanned – Anzahl der bislang gescannten Bytes.
Percentage scanned from cache – Prozentsatz der Daten, die vom lokalen Festplattencache gescannt wurden.
Bytes written – Geschriebene Bytes (z. B. beim Laden in eine Tabelle).
Bytes written to result – Bytes, die in das Ergebnisobjekt geschrieben wurden. So würde beispielsweise
select * from . . .eine Menge von Ergebnissen im tabellarischen Format für jedes Feld in der Auswahl liefern. Im Allgemeinen repräsentiert das Ergebnisobjekt das, was als Ergebnis der Abfrage erzeugt wird, und Bytes written to result steht für die Größe des zurückgegebenen Ergebnisses.Bytes read to result – Bytes, die aus dem Ergebnisobjekt gelesen wurden.
External Bytes scanned – Bytes, die von einem externen Objekt, z. B. einem Stagingbereich, gelesen wurden.
DML – Statistiken zu DML–Abfragen (Datenbearbeitungssprache):
Number of rows inserted – Anzahl der in eine Tabelle (oder Tabellen) eingefügten Zeilen.
Number of rows updated – Anzahl der in einer Tabelle aktualisierten Zeilen.
Number of rows deleted – Anzahl der aus einer Tabelle gelöschten Zeilen.
Number of rows unloaded – Anzahl der während des Datenexports entladenen Zeilen.
Pruning – Informationen zu den Auswirkungen der Tabellenverkürzung:
Partitions scanned – Anzahl der bisher gescannten Partitionen.
Partitions total – Gesamtanzahl der Partitionen einer Tabelle.
Spilling – Informationen zur Festplattennutzung für Operationen, bei denen Zwischenergebnisse nicht in den Arbeitsspeicher passen:
Bytes spilled to local storage – Datenmenge, die auf die lokale Festplatte übertragen wurde.
Bytes spilled to remote storage – Datenmenge, die auf die externe Festplatte übertragen wurde.
Network – Netzwerk-Kommunikation:
Bytes sent over the network – Über das Netzwerk gesendete Datenmenge.
External Functions – Informationen zu Aufrufen externer Funktionen:
Die folgenden Statistiken werden für jede externe Funktion angezeigt, die von der SQL-Anweisung aufgerufen wird. Wenn dieselbe Funktion mehrmals von derselben SQL-Anweisung aufgerufen wurde, werden die Statistiken aggregiert.
Total invocations – Häufigkeit, mit der eine externe Funktion aufgerufen wurde. Der Wert kann sich von der Anzahl der externen Funktionsaufrufe im Text der SQL-Anweisung unterscheiden und zwar aufgrund der Anzahl der Batches, in die Zeilen unterteilt sind, der Anzahl der Wiederholungsversuche (bei vorübergehenden Netzwerkproblemen) usw.
Rows sent – Anzahl der an externe Funktionen gesendeten Zeilen.
Rows received – Anzahl der von externen Funktionen empfangenen Zeilen.
Bytes sent (x-region) – Anzahl der an externe Funktionen gesendeten Bytes. Wenn das Etikett „(x-region)“ enthält, wurden die Daten über Regionen hinweg gesendet (was sich auf die Abrechnung auswirken kann).
Bytes received (x-region) – Anzahl der von externen Funktionen empfangenen Bytes. Wenn das Etikett „(x-region)“ enthält, wurden die Daten über Regionen hinweg gesendet (was sich auf die Abrechnung auswirken kann).
Retries due to transient errors – Anzahl der Wiederholungen aufgrund vorübergehender Fehler.
Average latency per call – Durchschnittliche Zeit pro Aufruf zwischen dem Zeitpunkt, zu dem Snowflake die Daten gesendet hat, und dem Zeitpunkt, zu dem Snowflake die zurückgegebenen Daten empfangen hat.
HTTP 4xx errors – Gesamtzahl der HTTP-Anforderungen, die einen 4xx-Statuscode zurückgegeben haben.
HTTP 5xx errors – Gesamtzahl der HTTP-Anforderungen, die einen 5xx-Statuscode zurückgegeben haben.
Latency per successful call (avg) – Durchschnittliche Latenz von erfolgreichen HTTP-Anforderungen.
Avg throttle latency overhead – Durchschnittlicher Overhead pro erfolgreicher Anforderung aufgrund einer durch Drosselung verursachten Verlangsamung (HTTP 429).
Batches retried due to throttling – Anzahl der Batches, deren Ausführung aufgrund von HTTP-Fehler 429 erneut versucht wurden.
Latency per successful call (P50) – 50. Perzentil-Latenz von erfolgreichen HTTP-Anforderungen. 50 Prozent aller erfolgreichen Anforderungen wurden in weniger als dieser Zeit abgeschlossen.
Latency per successful call (P90) – 90. Perzentil-Latenz von erfolgreichen HTTP-Anforderungen. 90 Prozent aller erfolgreichen Anforderungen wurden in weniger als dieser Zeit abgeschlossen.
Latency per successful call (P95) – 95. Perzentil-Latenz von erfolgreichen HTTP-Anforderungen. 95 Prozent aller erfolgreichen Anforderungen wurden in weniger als dieser Zeit abgeschlossen.
Latency per successful call (P99) – 99. Perzentil-Latenz von erfolgreichen HTTP-Anforderungen. 99 Prozent aller erfolgreichen Anforderungen wurden in weniger als dieser Zeit abgeschlossen.
Extension Functions – Informationen zu Aufrufen von Erweiterungsfunktionen:
Java UDF handler load time – Zeit, die der Java-UDF-Handler zum Laden benötigt.
Total Java UDF handler invocations – Anzahl der Aufrufe des Java-UDF-Handlers.
Max Java UDF handler execution time – Maximaler Zeitaufwand für die Ausführung des Java-UDF-Handlers.
Avg Java UDF handler execution time – Durchschnittlicher Zeitaufwand für die Ausführung des Java-UDF-Handlers.
Java UDTF process() invocations – Anzahl der Aufrufe der Java-UDTF-Methode process.
Java UDTF process() execution time – Zeitaufwand für die Ausführung des Java-UDTF-Prozesses.
Avg Java UDTF process() execution time – Durchschnittlicher Zeitaufwand für die Ausführung des Java-UDTF-Prozesses.
Java UDTF’s constructor invocations – Anzahl der Aufrufe des Java-UDTF-Konstruktors.
Java UDTF’s constructor execution time – Zeitaufwand für die Ausführung des Java-UDTF-Konstruktors.
Avg Java UDTF’s constructor execution time – Durchschnittlicher Zeitaufwand für die Ausführung des Java-UDTF-Konstruktors.
Java UDTF endPartition() invocations – Anzahl der Aufrufe der Java-UDTF-Methode endPartition.
Java UDTF endPartition() execution time – Zeitaufwand für die Ausführung der Java-UDTF-Methode endPartition.
Avg Java UDTF endPartition() execution time – Durchschnittlicher Zeitaufwand für die Ausführung der Java-UDTF-Methode endPartition.
Max Java UDF dependency download time – Maximaler Zeitaufwand für das Herunterladen der Java-UDF-Abhängigkeiten.
Max JVM memory usage – Spitzenauslastung des Arbeitsspeichers, wie von JVM gemeldet.
Java UDF inline code compile time in ms – Kompilierungszeit für den Java-UDF-Inline-Code.
Total Python UDF handler invocations – Anzahl der Aufrufe des Python-UDF-Handlers.
Total Python UDF handler execution time – Gesamtausführungszeit für den Python-UDF-Handler.
Avg Python UDF handler execution time – Durchschnittlicher Zeitaufwand für die Ausführung des Python-UDF-Handlers.
Python sandbox max memory usage – Spitzenauslastung des Arbeitsspeichers durch die Python-Sandbox-Umgebung.
Avg Python env creation time: Download and install packages – Durchschnittlicher Zeitaufwand für das Erstellen der Python-Umgebung, einschließlich des Herunterladens und Installierens von Paketen.
Conda solver time – Zeitaufwand für die Ausführung des Conda-Solvers zur Auflösung von Python-Paketen.
Conda env creation time – Zeitaufwand für das Erstellen der Python-Umgebung.
Python UDF initialization time – Zeitaufwand für das Initialisieren der Python-UDF.
Number of external file bytes read for UDFs – Anzahl der für UDFs gelesenen Bytes für externe Dateien.
Number of external files accessed for UDFs – Anzahl der Zugriffe auf externe Dateien für UDFs.
Wenn der Wert eines Feldes, z. B. „Retries due to transient errors“, null ist, wird das Feld nicht angezeigt.
Die teuersten Knoten¶
Im Bereich werden alle Knoten aufgelistet, die 1 % oder mehr der gesamten Ausführungszeit der Abfrage (oder die Ausführungszeit für den angezeigten Abfrageschritt, wenn die Abfrage in mehreren Verarbeitungsschritten ausgeführt wurde) in Anspruch genommen haben. Der Bereich listet die Knoten nach Ausführungszeit in absteigender Reihenfolge auf, sodass Benutzer die teuersten Operatorknoten in Bezug auf die Ausführungszeit schnell finden können.
Attribute¶
In den folgenden Abschnitten finden Sie eine Liste der häufigsten Operatortypen und ihrer Attribute.
Datenzugriffs- und Datengenerierungsoperatoren¶
- TableScan:
Stellt den Zugriff auf eine einzelne Tabelle dar. Attribute:
Vollständiger Tabellenname – der vollständig qualifizierte Name der durchsuchten Tabelle
Table alias – Verwendeter Tabellenalias, falls vorhanden
Columns – Liste der gescannten Spalten
Extracted Variant path – Liste der aus VARIANT-Spalten extrahierten Pfade
Scanmodus – ROW_BASED oder COLUMN_BASED (wird nur für Scans von Hybridtabellen angezeigt)
Zugriffsprädikate – Bedingungen aus der Abfrage, die beim Tabellenscan angewendet werden
- IndexScan:
Stellt den Zugriff auf sekundäre Indizes in Hybridtabellen dar. Attribute:
Vollständiger Tabellenname – der vollständig qualifizierte Name der gescannten Tabelle, die den Index enthält
Columns — Liste der gescannten Index-Spalten
Scanmodus – ROW_BASED oder COLUMN_BASED
Zugriffsprädikate – Bedingungen aus der Abfrage, die während der Indexsuche angewendet werden
Vollständiger Indexname — der vollständig qualifizierte Name des gescannten Index
- ValuesClause:
Liste der Werte, die mit der VALUES-Klausel bereitgestellt werden. Attribute:
Number of values – Anzahl der produzierten Werte.
Values – Liste der produzierten Werte.
- Generator:
Generiert Datensätze mit dem
TABLE(GENERATOR(...))-Konstrukt. Attribute:rowCount – bereitgestellter rowCount-Parameter
timeLimit – bereitgestellter timeLimit-Parameter
- ExternalScan:
Stellt den Zugriff auf Daten dar, die in Stagingobjekten gespeichert sind. Kann Teil von Abfragen sein, die Daten direkt in Stagingbereichen scannen, aber auch Datenladeoperationen (d. h. COPY-Anweisungen).
Attribute:
Stage name – Name des Stagingbereichs, von dem die Daten gelesen werden.
Stage type – Typ des Stagingbereichs (z. B. TABLE STAGE).
- InternalObject:
Stellt den Zugriff auf ein internes Datenobjekt dar (z. B. eine Information Schema-Tabelle oder das Ergebnis einer vorherigen Abfrage). Attribute:
Object Name – Name oder Typ des Objekts, auf das zugegriffen wird.
Datenverarbeitungsoperatoren¶
- Filter:
Stellt eine Operation dar, mit der Datensätze gefiltert werden. Attribute:
Filter condition – Bedingung, die zum Filtern verwendet wird.
- Join:
Kombiniert zwei Eingaben unter einer bestimmten Bedingung. Attribute:
Join Type – Typ der Join-Verknüpfung (z. B. INNER, LEFT OUTER usw.)
Equality Join Condition – Listet bei Joins, die auf Gleichheit basierende Bedingungen verwenden, die zum Verbinden der Elemente verwendeten Ausdrücke auf.
Additional Join Condition – Einige Verbindungen verwenden Bedingungen mit Prädikaten, die nicht auf Gleichheit basieren. Diese werden hier aufgelistet.
Bemerkung
Join-Prädikate, die auf Ungleichheit basieren, können zu deutlich niedrigeren Verarbeitungsgeschwindigkeiten führen und sollten nach Möglichkeit vermieden werden.
- Aggregat:
Gruppiert die Eingabe und berechnet Aggregatfunktionen. Kann SQL-Konstrukte wie GROUP BY oder SELECT DISTINCT darstellen. Attribute:
Grouping Keys – Wenn GROUP BY verwendet wird, werden die Ausdrücke aufgelistet, nach denen gruppiert wird.
Aggregate Functions – Liste der Funktionen, die für jede Aggregatgruppe berechnet wurden, z. B. SUM.
- GroupingSets:
Repräsentiert Konstrukte wie GROUPING SETS, ROLLUP und CUBE. Attribute:
Grouping Key Sets – Liste der Gruppierungssätze
Aggregate Functions – Liste der Funktionen, die für jede Gruppe berechnet wurden, z. B. SUM.
- WindowFunction:
Berechnet Fensterfunktionen. Attribute:
Window Functions – Liste der berechneten Fensterfunktionen.
- Sort:
Sortiert die Eingabe anhand eines gegebenen Ausdrucks. Attribute:
Sort Keys – Ausdruck, der die Sortierreihenfolge definiert.
- SortWithLimit:
Erstellt nach der Sortierung einen Teil der Eingabesequenz, normalerweise das Ergebnis eines
ORDER BY ... LIMIT ... OFFSET ...-Konstrukts in SQL.Attribute:
Sort Keys – Ausdruck, der die Sortierreihenfolge definiert.
Number of rows – Anzahl der erzeugten Zeilen.
Offset – Position in der sortierten Sequenz, ab der die produzierten Tupel ausgegeben werden.
- Flatten:
Verarbeitet VARIANT-Datensätze und vereinfacht sie ggf. in einem angegebenen Pfad. Attribute:
Input – Eingabeausdruck, der zum Vereinfachen der Daten verwendet wird.
- JoinFilter:
Spezielle Filteroperation, bei der Tupel entfernt werden, die als möglicherweise nicht mit der Bedingung eines Joins im Abfrageplan übereinstimmend identifiziert werden können. Attribute:
Original join ID – Join, mit dem Tupel identifiziert werden, die herausgefiltert werden können.
- UnionAll:
Verkettet zwei Eingänge. Attribute: keine.
- ExternalFunction:
Repräsentiert die Verarbeitung durch eine externe Funktion.
DML-Operatoren¶
- Insert:
Fügt Datensätze entweder durch eine INSERT- oder COPY-Operation zu einer Tabelle hinzu. Attribute:
Input expression – Ausdrücke, die eingefügt werden.
Table names – Namen der Tabellen, denen Datensätze hinzugefügt werden.
- Delete:
Entfernt Datensätze aus einer Tabelle. Attribute:
Table name – Name der Tabelle, aus der Datensätze gelöscht werden.
- Update:
Aktualisiert Datensätze in einer Tabelle. Attribute:
Table name – Name der aktualisierten Tabelle.
- Merge:
Führt eine MERGE-Operation für eine Tabelle aus. Attribute:
Full table name – Name der aktualisierten Tabelle.
- Unload:
Stellt eine COPY-Operation dar, bei der Daten aus einer Tabelle in einer Datei im Stagingbereich exportiert werden. Attribute:
Location – Name des Stagingbereichs, in den die Daten gespeichert werden.
Metadatenoperatoren¶
Einige Abfragen enthalten Schritte, bei denen es sich nicht um Datenverarbeitungsoperationen, sondern um reine Metadaten- bzw. Katalogoperationen handelt. Diese Schritte bestehen aus einem einzigen Operator. Einige Beispiele sind:
- DDL- und Transaktionsbefehle:
Werden zum Erstellen oder Ändern von Objekten, Sitzungen, Transaktionen usw. verwendet. Normalerweise werden diese Abfragen nicht von einem virtuellen Warehouse verarbeitet und führen zu einem Einzelschrittprofil, das der zugehörigen SQL-Anweisung entspricht. Beispiel:
CREATE DATABASE | SCHEMA | …
ALTER DATABASE | SCHEMA | TABLE | SESSION | …
DROP DATABASE | SCHEMA | TABLE | …
COMMIT
- Befehl zur Tabellenerstellung:
DDL-Befehl zum Erstellen einer Tabelle. Beispiel:
CREATE TABLE
Ähnlich wie andere DDL-Befehle führen diese Abfragen zu einem Einzelschrittprofil. Sie können jedoch auch Teil eines mehrstufigen Profils sein, z. B. in einer CTAS-Anweisung. Beispiel:
CREATE TABLE … AS SELECT …
- Wiederverwendung des Abfrageergebnisses:
Eine Abfrage, die das Ergebnis einer vorherigen Abfrage wiederverwendet.
- Metadatenbasiertes Ergebnis:
Eine Abfrage, deren Ergebnis nur auf Verarbeitung von Metadaten basiert, ohne auf Daten zuzugreifen. Diese Abfragen werden nicht von einem virtuellen Warehouse verarbeitet. Beispiel:
SELECT COUNT(*) FROM …
SELECT CURRENT_DATABASE()
Verschiedene Operatoren¶
- Result:
Gibt das Abfrageergebnis zurück. Attribute:
List of expressions – Ausdrücke, die generiert wurden.
Typische, von Query Profile identifizierte Abfrageprobleme¶
In diesem Abschnitt werden einige Probleme beschrieben, die Sie mithilfe von Query Profile identifizieren und beheben können.
„Explodierende“ Joins¶
Einer der häufigsten Fehler von SQL-Benutzern besteht darin, Tabellen zu verknüpfen, ohne eine Join-Bedingung anzugeben (was zu einem „Kartesischen Produkt“ führt), oder eine Bedingung bereitzustellen, bei der Datensätze einer Tabelle mit mehreren Datensätzen einer anderen Tabelle übereinstimmen. Für solche Abfragen produziert der Operator Join signifikant (oft um Größenordnungen) mehr Tupel, als er verbraucht.
Dies kann beobachtet werden, indem die Anzahl der Datensätze betrachtet wird, die von einem Join-Operator erzeugt wurden. Dies spiegelt sich normalerweise auch in Join-Operatoren wider, die viel Zeit in Anspruch nehmen.
UNION ohne ALL¶
In SQL können zwei Datasets mit UNION- oder UNION ALL-Konstrukten kombiniert werden. Der Unterschied zwischen beiden besteht darin, dass mit UNION ALL die Eingaben einfach verkettet werden, während UNION dasselbe tut, aber auch eine doppelte Löschung durchführt.
Ein häufiger Fehler ist die Verwendung von UNION, wenn die UNION ALL-Semantik ausreicht. Diese Abfragen werden in Query Profile als UnionAll-Operator mit einem zusätzlichen Aggregate-Operator darüber angezeigt (der eine doppelte Löschung vornimmt).
Abfragen, die zu groß für den Arbeitsspeicher sind¶
Bei einigen Operationen (z. B. doppelte Löschung bei einem großen Dataset) reicht die für die Server zur Ausführung der Operation zur Verfügung stehende Speicherkapazität möglicherweise nicht aus, um Zwischenergebnisse zu speichern. Als Ergebnis beginnt das Abfrageverarbeitungsmodul, die Daten auf die lokale Festplatte zu übertragen. Wenn der lokale Speicherplatz nicht ausreicht, werden die Überlaufdaten auf Remote-Festplatten gespeichert.
Dieser Überlauf kann sich erheblich auf die Abfrageleistung auswirken (insbesondere, wenn für den Überlauf ein Remote-Datenträger verwendet wird). Um die Auswirkungen zu reduzieren, empfehlen wir Folgendes:
Verwenden eines größeren Warehouse (effektives Erhöhen des verfügbaren Arbeitsspeichers bzw. des lokalen Festplattenspeichers für die Operation) und/oder
Verarbeiten der Daten in kleineren Batches.
Ineffizientes Verkürzen (Pruning)¶
Snowflake sammelt umfangreiche Statistiken zu Daten, sodass basierend auf den Abfragefiltern keine unnötigen Teile einer Tabelle gelesen werden. Um diesen Effekt zu erzielen, muss die Reihenfolge der Datenspeicherung mit den Abfragefilterattributen korreliert werden.
Die Effizienz des Verkürzungsprozesses kann durch Vergleichen der Statistiken Partitions scanned und Partitions total in den TableScan-Operatoren überwacht werden. Wenn ersterer Wert ein kleiner Bruchteil des letzteren Werts ist, dann ist das Verkürzen effizient. Wenn nicht, hatte das Verkürzen keine Wirkung.
Das Verkürzen kann natürlich nur für Abfragen hilfreich sein, bei denen tatsächlich eine erhebliche Datenmenge herausgefiltert wird. Wenn in den Verkürzungsstatistiken keine Datenreduktion angezeigt wird, über TableScan jedoch ein Filter-Operator steht, der eine Anzahl von Datensätzen herausfiltert, könnte dies darauf hindeuten, dass für diese Abfrage eine andere Organisation der Daten von Vorteil ist.
Weitere Informationen zum Verkürzen finden Sie unter Grundlegendes zu Tabellenstrukturen in Snowflake.