The Snowflake JDBC driver supports additional methods beyond the standard JDBC specification. This section documents
how to use unwrapping to access the Snowflake-specific methods, then describes three of the situations in which you might
need to unwrap:
The Snowflake JDBC driver supports Snowflake-specific methods. These methods are defined in Snowflake-specific
Java-language interfaces, such as SnowflakeConnection, SnowflakeStatement, and SnowflakeResultSet. For example,
the SnowflakeStatement interface contains a getQueryID() method that is not in the JDBC Statement interface.
When the Snowflake JDBC driver is asked to create a JDBC object (e.g. create a JDBC Statement object by
calling a Connection object’s createStatement() method), the Snowflake JDBC driver actually creates
Snowflake-specific objects that implement not only the methods of the JDBC standard, but also the additional methods
from the Snowflake interfaces.
To access these Snowflake methods, you “unwrap” an object (such as a Statement object) to expose the Snowflake
object and its methods. You can then call the additional methods.
The following code shows how to unwrap a JDBC Statement object to expose the methods of the
SnowflakeStatement interface, and then call one of those methods, in this case setParameter:
Statement statement1;
...// Unwrap the statement1 object to expose the SnowflakeStatement object, and call the// SnowflakeStatement object's setParameter() method.
statement1.unwrap(SnowflakeStatement.class).setParameter(...);
The Snowflake JDBC Driver supports asynchronous queries, such as queries that return control to the user before they finish. You can start a query and then use polling to determine when the query has finished. When it does, the user can read the result set.
This feature allows a client program to run multiple queries in parallel without the client program itself using
multi-threading.
Asynchronous queries use methods added to the SnowflakeConnection, SnowflakeStatement, SnowflakePreparedStatement, and
SnowflakeResultSet classes.
Note
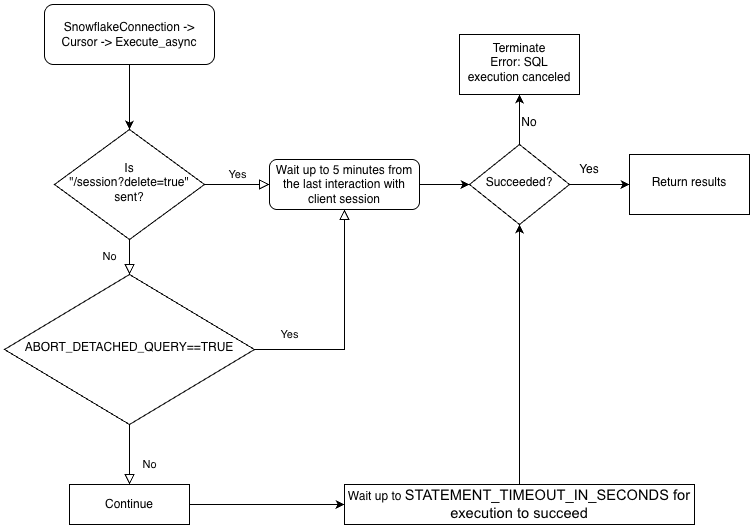
To perform asynchronous queries, you must ensure the ABORT_DETACHED_QUERY configuration parameter is FALSE (default value).
If the connection to client is lost:
For synchronous queries, all in-progress synchronous queries are aborted immediately regardless of the parameter value.
For asynchronous queries:
If ABORT_DETACHED_QUERY is set to FALSE, in-progress asynchronous queries continue to run until they end normally.
If ABORT_DETACHED_QUERY is set to TRUE, Snowflake automatically aborts all in-progress asynchronous queries when a client connection is not re-established after five minutes.
You can prevent the asynchronous query from being aborted at the five minute mark by calling cursor.query_result(queryId). While this call does not retrieve the actual query result as the query is still running, it does prevent the query from being canceled. Invoking query_result is a synchronous operation, which might or might not be appropriate for your particular use case.
You can run a mix of synchronous and asynchronous queries in the same session.
Note
Asynchronous queries don’t support PUT/GET statements.
When executeAsyncQuery(query) is used, the Snowflake JDBC driver automatically keeps track of the queries submitted asynchronously. When the connection is explicitly closed with connection.close(), the list of async queries is examined and, if any of them are still running, the Snowflake-side session is not deleted.
If no async queries are running within the same connection, the Snowflake session belonging to the connection is logged out when connection.close() is called, which implicitly cancels all other queries running in the same session.
This behavior also depends on the SQL ABORT_DETACHED_QUERY parameter. For more information, see the ABORT_DETACHED_QUERY parameter documentation.
As a best practice, isolate all long-running async tasks (especially those intended to continue after the connection is closed) into a separate connection.
To better understand the hierarchy of the drivers’ business logic and the ABORT_DETACHED_QUERY parameter’s interaction, see the following flowchart:
Ensure that you know which queries are dependent on other queries before you run any queries in parallel. Queries that are interdependent and order-sensitive are not suitable for parallelizing. For example, an INSERT statement should not start until after the corresponding CREATE TABLE statement has finished.
Ensure that you do not run too many queries for the memory that you have available.
Running multiple queries in parallel typically consumes more memory, especially if more than one ResultSet is stored in memory at the same time.
When polling, handle the rare cases where a query does not succeed. For example, avoid the following potential infinite loop:
QueryStatus queryStatus = resultSet.unwrap(SnowflakeAsyncResultSet.class).getStatus();
while (!queryStatus.isSuccess()) { // NOT RECOMMENDEDThread.sleep(2000); // 2000 milliseconds.
queryStatus = resultSet.unwrap(SnowflakeAsyncResultSet.class).getStatus();
}
Instead, use code similar to the following:
// Assume that the query is not done yet.QueryStatus queryStatus = resultSet.unwrap(SnowflakeAsyncResultSet.class).getStatus();
while (queryStatus.isStillRunning()) {
Thread.sleep(2000); // 2000 milliseconds.
queryStatus = resultSet.unwrap(SnowflakeAsyncResultSet.class).getStatus();
}
if (queryStatus.isSuccess()) {
...
}
QueryStatus queryStatus =QueryStatus.RUNNING;
while (queryStatus !=QueryStatus.SUCCESS) { // NOT RECOMMENDEDThread.sleep(2000); // 2000 milliseconds.
queryStatus = resultSet.unwrap(SnowflakeResultSet.class).getStatus();
}
Instead, use code similar to the following:
// Assume that the query is not done yet.QueryStatus queryStatus =QueryStatus.RUNNING;
while (queryStatus ==QueryStatus.RUNNING|| queryStatus ==QueryStatus.RESUMING_WAREHOUSE) {
Thread.sleep(2000); // 2000 milliseconds.
queryStatus = resultSet.unwrap(SnowflakeResultSet.class).getStatus();
}
if (queryStatus ==QueryStatus.SUCCESS) {
...
}
Ensure that transaction control statements (BEGIN, COMMIT, and ROLLBACK) are not executed in parallel with other statements.
Upload data files directly from a stream to an internal stage¶
You can upload data files using the PUT command. However, sometimes it makes sense to transfer data directly from a
stream to an internal (i.e. Snowflake) stage as a file. (The stage
can be any internal stage type: table stage, user stage, or named stage. The JDBC driver does not support uploading to an external
stage.) Here is the method exposed in the SnowflakeConnection class:
/** * Method to compress data from a stream and upload it at a stage location. * The data will be uploaded as one file. No splitting is done in this method. * * Caller is responsible for releasing the inputStream after the method is * called. * * @param stageName stage name: e.g. ~ or table name or stage name * @param destPrefix path / prefix under which the data should be uploaded on the stage * @param inputStream input stream from which the data will be uploaded * @param destFileName destination file name to use * @param compressData compress data or not before uploading stream * @throws java.sql.SQLException failed to compress and put data from a stream at stage */void uploadStream(String stageName, String destFileName, InputStream inputStream)
throws SQLException;
void uploadStream(String stageName, String destFileName, InputStream inputStream,
UploadStreamConfig config)
throws SQLException;
/** * Method to compress data from a stream and upload it at a stage location. * The data will be uploaded as one file. No splitting is done in this method. * * Caller is responsible for releasing the inputStream after the method is * called. * * @param stageName stage name: e.g. ~ or table name or stage name * @param destPrefix path / prefix under which the data should be uploaded on the stage * @param inputStream input stream from which the data will be uploaded * @param destFileName destination file name to use * @param compressData compress data or not before uploading stream * @throws java.sql.SQLException failed to compress and put data from a stream at stage */publicvoid uploadStream(String stageName,
String destPrefix,
InputStream inputStream,
String destFileName,
boolean compressData)
throws SQLException
Code written for JDBC Driver versions prior to 3.9.2 might cast SnowflakeConnectionV1 rather than
unwrap SnowflakeConnection.class. For example:
...// For versions prior to 3.9.2:// upload file stream to user stage
((SnowflakeConnectionV1) connection.uploadStream("MYSTAGE", "testUploadStream",
fileInputStream, "destFile.csv", true));
Note
Customers using newer versions of the driver should update their code to use unwrap.
Download data files directly from an internal stage to a stream¶
You can download data files using the GET command. However, sometimes it makes sense to transfer data directly from a
file in an internal (i.e. Snowflake) stage to a stream. (The stage
can be any internal stage type: table stage, user stage, or named stage. The JDBC driver does not support downloading to an
external stage.) Here is the method exposed in the SnowflakeConnection class:
/** * Download a file from a Snowflake stage as a stream with required parameters only. * * <p>This is a convenience method that uses default options (no decompression). For advanced * configuration, use {@link #downloadStream(String, String, DownloadStreamConfig)}. * * <p>The caller is responsible for closing the returned input stream. * * @param stageName the name of the stage (e.g., "@my_stage") * @param sourceFileName the path to the file within the stage * @return an input stream containing the file data * @throws SQLException if download fails */InputStream downloadStream(String stageName, String sourceFileName) throws SQLException;
/** * Download a file from a Snowflake stage as a stream with optional configuration. * * <p>This method allows customization of download behavior via {@link DownloadStreamConfig}, such * as automatic decompression. * * <p>The caller is responsible for closing the returned input stream. * * @param stageName the name of the stage (e.g., "@my_stage") * @param sourceFileName the path to the file within the stage * @param config optional configuration for download behavior * @return an input stream containing the file data * @throws SQLException if download fails */InputStream downloadStream(String stageName, String sourceFileName, DownloadStreamConfig config)
throws SQLException;
/** * Download file from the given stage and return an input stream * * @param stageName stage name * @param sourceFileName file path in stage * @param decompress true if file compressed * @return an input stream * @throws SnowflakeSQLException if any SQL error occurs. */InputStream downloadStream(String stageName,
String sourceFileName,
boolean decompress) throws SQLException;
This section describes how to execute multiple statements in a single request using the JDBC Driver.
Note
Executing multiple statements in a single query requires that a valid warehouse is available in a session.
By default, Snowflake returns an error for queries issued with multiple statements to protect against SQL injection .
Executing multiple statements in a single query increases the risk of SQL injection. Snowflake recommends using it sparingly.
To reduce the SQL injection risk, use the SnowflakeStatement class’s setParameter() method to specify the number of
statements to be executed, which makes it more difficult to inject a statement by appending it. For more information about SnowflakeStatement, see
Interface: `SnowflakeStatement`.
Queries containing multiple statements can be executed the same way as queries with a single statement, except that the
query string contains multiple statements separated by semicolons.
There are two ways to allow multiple statements:
Call Statement.setParameter(“MULTI_STATEMENT_COUNT”, n) to specify how many statements at a time this Statement
should be allowed to execute. See below for more details.
Set the MULTI_STATEMENT_COUNT parameter at the session level or
the account level by executing one of the following commands:
altersessionsetMULTI_STATEMENT_COUNT=0;
Or:
alteraccountsetMULTI_STATEMENT_COUNT=0;
Setting the parameter to 0 allows an unlimited number of statements. Setting the parameter to 1 allows only one
statement at a time.
In order to make SQL Injection attacks more difficult, users can call the setParameter method to
specify the number of statements to be executed in a single call, as shown below.
In this example, the number of statements to execute in a single call is 3:
// Specify the number of statements that we expect to execute.
statement.unwrap(SnowflakeStatement.class).setParameter(
"MULTI_STATEMENT_COUNT", 3);
The default number of statements is 1; in other words, multi-statement mode is off.
To execute multiple statements without specifying the exact number, pass a value of 0.
The MULTI_STATEMENT_COUNT parameter is not part of the JDBC standard; it is a Snowflake extension. This parameter
affects more than one Snowflake driver/connector.
When multiple statements are executed in a single execute() call, the result of the first statement is
available through the standard getResultSet() and getUpdateCount() methods.
To access the results of the statements that follow, use the getMoreResults() method.
This method returns true when more statements are available for iteration, and false otherwise.
The example below sets the MULTI_STATEMENT_COUNT parameter, executes 3 statements, and retrieves update counts
and result sets:
// Create a string that contains multiple SQL statements.String command_string ="create table test(n int); "+"insert into test values (1), (2); "+"select * from test order by n";
Statement stmt = connection.createStatement();
// Specify the number of statements (3) that we expect to execute.
stmt.unwrap(SnowflakeStatement.class).setParameter(
"MULTI_STATEMENT_COUNT", 3);
// Execute all of the statements.
stmt.execute(command_string); // false// --- Get results. ---// First statement (create table)
stmt.getUpdateCount(); // 0 (DDL)// Second statement (insert)
stmt.getMoreResults(); // true
stmt.getUpdateCount(); // 2// Third statement (select)
stmt.getMoreResults(); // trueResultSet rs = stmt.getResultSet();
rs.next(); // true
rs.getInt(1); // 1
rs.next(); // true
rs.getInt(1); // 2
rs.next(); // false// Past the last statement executed.
stmt.getMoreResults(); // false
stmt.getUpdateCount(); // 0 (no more results)
Snowflake recommends using execute() for multi-statement queries.
The methods executeQuery() and executeUpdate() also support multiple statements, but will throw an exception if the first result is not the expected result type (result set and update count, respectively).
If any of the SQL statements fails to compile or execute, execution is aborted. Any previous statements that ran before are unaffected.
For example, if the statements below are run as a single multi-statement query, the query will fail on the third statement, and an exception will be thrown.
CREATE OR REPLACETABLEtest(n int);INSERTINTOTESTVALUES(1),(2);INSERTINTOTESTVALUES('not_an_int');-- execution fails hereINSERTINTOTESTVALUES(3);
If you were to then query the contents of table test, values 1 and 2 would be present.
Without binding, a SQL statement specifies values by specifying literals inside the statement. For example, the following
statement uses the literal value 42 in an UPDATE statement:
stmt.execute("UPDATE table1 SET integer_column = 42 WHERE ID = 1000");
With binding, you can execute a SQL statement that uses a value that is inside a variable. For example:
int my_integer_variable =42;
PreparedStatement pstmt = connection.prepareStatement("UPDATE table1 SET integer_column = ? WHERE ID = 1000");
pstmt.setInt(1, my_integer_variable);
pstmt.executeUpdate();
The ? inside the VALUES clause specifies that the SQL statement uses the value from a variable. The setInt() method
specifies that the first question mark in the SQL statement should be replaced with the value in the variable named
my_integer_variable. Note that setInt() uses 1-based, rather than 0-based values (i.e. the first question mark is
referenced by 1, not 0).
Snowflake supports three different variations for timestamps: TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ. When you call
PreparedStatement.setTimestamp to bind a variable to a timestamp column, the JDBC Driver interprets the timestamp value in
terms of the local time zone (TIMESTAMP_LTZ) or the time zone of the Calendar object passed in as an argument:
// The following call interprets the timestamp in terms of the local time zone.
insertStmt.setTimestamp(1, myTimestamp);
// The following call interprets the timestamp in terms of the time zone of the Calendar object.
insertStmt.setTimestamp(1, myTimestamp, Calendar.getInstance(TimeZone.getTimeZone("America/New_York")));
If you want the driver to interpret the timestamp using a different variation (e.g. TIMESTAMP_NTZ), use one of the
following approaches:
Note that the parameter affects all binding operations for the current session. If you need to change the variation (e.g. back
to TIMESTAMP_LTZ), you must set this session parameter again.
(In the JDBC Driver 3.13.3 and later versions) Call the PreparedStatement.setObject method, and use the
targetSqlType parameter to specify one of the following Snowflake timestamp variations:
In your Java application code, you can insert multiple rows in a single batch by binding parameters in an INSERT statement and
calling addBatch() and executeBatch().
As an example, the following code inserts two rows into a table that contains an INTEGER column and a VARCHAR column. The example
binds values to the parameters in the INSERT statement and calls addBatch() and executeBatch() to perform a batch
insert.
When you use this technique to insert a large number of values, the driver can improve performance by streaming the data (without
creating files on the local machine) to a temporary stage for ingestion. The driver automatically does this when the number of
values exceeds a threshold.
In addition, the current database and schema for the session must be set. If these are not set, the CREATE TEMPORARY STAGE command
executed by the driver can fail with the following error:
CREATE TEMPORARY STAGE SYSTEM$BIND file_format=(type=csv field_optionally_enclosed_by='"')
Cannot perform CREATE STAGE. This session does not have a current schema. Call 'USE SCHEMA', or use a qualified name.
Note
For alternative ways to load data into the Snowflake database (including bulk loading using the COPY command), see
Load data into Snowflake.
In some cases, the JDBC Driver might fail with the following error message after a period of inactivity:
I/O error: Connection reset
You can work around the problem by setting a specific “time to live” for the connections. If a connection is idle for longer than
the “time to live”, the JDBC Driver removes the connection from the connection pool and creates a new connection.
To set the time to live, set the Java system property named net.snowflake.jdbc.ttl to the number of seconds that the
connection should live:
To set this property programmatically, call System.setProperty:
// Set the "time to live" to 60 seconds.System.setProperty("net.snowflake.jdbc.ttl", "60")
To set this property when running the java command, use the -D flag:
# Set the "time to live" to 60 seconds.
java -cp .:snowflake-jdbc-<version>.jar -Dnet.snowflake.jdbc.ttl=60 <ClassName>
The default value of the net.snowflake.jdbc.ttl property is -1, which means that idle connections are not removed from
the connection pool.
When handling errors and exceptions for a JDBC application, you can use the
ErrorCode.java
file that Snowflake provides to determine the cause of the problems.
Error codes specific to the JDBC driver start with 2, in the form: 2_NNNNN_.
Note
The link to the ErrorCode.java in the public snowflake-jdbc git repository points to the latest version of the file, which might differ from
the version of the JDBC driver you currently use.