Snowpark Migration Accelerator : Remarques sur la préparation du code¶
Avant d’exécuter l’outil Snowpark Migration Accelerator (SMA), assurez-vous que tous vos fichiers de code source se trouvent sur l’ordinateur où vous avez installé SMA. Vous n’avez pas besoin de vous connecter à une base de données source ou à un environnement Spark puisque SMA effectue uniquement l’analyse du code.
Le code source doit être dans un format lisible pour que SMA puisse le traiter correctement, car l’outil repose entièrement sur le code source que vous fournissez.
Extraction¶
Avant d’exécuter l’outil Snowpark Migration Accelerator (SMA), organisez tous vos fichiers de code source dans un seul dossier principal. Vous pouvez conserver votre structure de sous-dossiers existante dans ce dossier principal, mais tous les fichiers de code doivent être situés dans ce répertoire unique. Cette exigence s’applique aux éléments suivants :
Les types de fichiers suivants sont pris en charge :
Référentiels GitHub (téléchargés sous forme de fichiers ZIP et extraits sur votre machine locale)
Fichiers de script Python
Fichiers de projet Scala
Fichiers notebook Databricks
Les notebooks Jupyter s’exécutent sur votre ordinateur local
Avant de commencer votre migration, rassemblez tous les fichiers du code source dans un seul dossier principal. Bien que votre code source puisse provenir de différents emplacements, le fait de l’organiser en un seul endroit rendra le processus de migration plus efficace. Si vous disposez déjà d’une structure d’organisation des fichiers, conservez-la intacte dans le dossier principal.
Export GitHub repositories to ZIP files
To generate accurate and complete reports using the Snowpark Migration Accelerator (SMA), scan only the code that is relevant to your migration project. Rather than scanning all available code, identify and include only the essential code files that you plan to migrate. For more information, refer to Size in the Considerations section.
Considérations¶
Passons en revue les types de fichiers compatibles avec Snowpark Migration Accelerator (SMA) et comprenons les considérations clés lors de la préparation de votre code source pour l’analyse avec SMA.
Types de fichiers¶
L’outil Snowpark Migration Accelerator (SMA) examine tous les fichiers de votre répertoire source, mais ne traite que les fichiers avec des extensions spécifiques qui peuvent contenir du code Spark API. Cela comprend à la fois les fichiers de code ordinaires et les notebooks de Jupyter.
You can find a list of file types that SMA supports in the Supported Filetypes section of this documentation.
Fichiers exportés¶
Si votre code est stocké dans une plateforme de contrôle source au lieu de fichiers locaux, vous devez l’exporter dans un format que SMA peut traiter. Voici comment vous pouvez exporter votre code :
For Databricks users: To use the Snowpark Migration Accelerator (SMA), you need to export your notebooks to .dbc format. You can find detailed instructions on how to export notebooks in the Databricks documentation on exporting notebooks.
Need help exporting files? Visit the export scripts in the Snowflake Labs Github repo, where Snowflake Professional Services maintains scripts for Databricks, Hive, and other platforms.
If you are using a different platform, please refer to the Code Extraction page for specific instructions for your platform. If you need assistance converting your code into a format that works with SMA, please contact sma-support@snowflake.com.
Taille¶
L’outil Snowpark Migration Accelerator (SMA) est conçu pour analyser le code source et non les données. Pour garantir des performances optimales et éviter l’épuisement des ressources du système, nous vous recommandons ce qui suit :
N’incluez que les fichiers de code spécifiques que vous souhaitez migrer
Évitez d’inclure des dépendances de bibliothèque inutiles
Bien que vous puissiez inclure les fichiers de code des bibliothèques dépendantes, cela augmentera considérablement le temps de traitement sans ajouter de valeur, car SMA se concentre spécifiquement sur l’identification du code Spark qui nécessite une migration.
Nous vous recommandons de rassembler tous les fichiers de code qui…
S’exécutent automatiquement dans le cadre d’un processus planifié
Ont été utilisés pour créer ou configurer ce processus (s’ils sont distincts)
Sont des bibliothèques personnalisées créées par votre organisation qui sont utilisées dans l’un ou l’autre des scénarios ci-dessus
Vous n’avez pas besoin d’inclure le code des bibliothèques tierces courantes telles que Pandas ou Sci-Kit Learn. L’outil détectera et classera automatiquement les références de ces bibliothèques sans avoir besoin de leur code source.
Fonctionne t’il ?¶
The Snowpark Migration Accelerator (SMA) can only process complete and syntactically correct source code. Your code must be able to run successfully in a supported source platform. If the SMA reports multiple parsing errors, this usually indicates that your source code contains syntax errors. To achieve the best results, ensure that your input directory contains only valid code that can be executed on the source platform.
Cas d’utilisation¶
Il est essentiel de comprendre l’objectif de votre base de code lorsque vous examinez les résultats de l’analyse. Cela vous aidera :
À déterminer les applications ou les processus susceptibles de ne pas fonctionner correctement avec Snowpark
À comprendre et analyser plus efficacement les résultats de l’évaluation de la préparation
À vérifier si votre code et vos systèmes existants sont compatibles avec Snowflake
Lors de l’analyse d’un notebook qui utilise un dialecte SQL non pris en charge et un connecteur de base de données sans Spark, l’outil SMA n’affichera que les bibliothèques tierces importées. Bien que ces informations soient utiles, le notebook ne recevra pas de score de préparation Spark API. Comprendre comment vous prévoyez d’utiliser votre code vous aidera à mieux appréhender ces limites et à prendre de meilleures décisions lors de la migration.
Exportations à partir de notebooks Databricks¶
Les notebooks Databricks prennent en charge plusieurs langages de programmation telles que SQL, Scala, et PySpark dans un seul notebook. Lorsque vous exportez un notebook, l’extension du fichier reflète son langage principal :
Notebooks Python : .ipynb ou .py
Notebooks SQL : .sql
Tout code écrit dans un langage différent du langage principal du notebook sera automatiquement converti en commentaires lors de l’exportation. Par exemple, si vous incluez du code SQL dans un notebook Python, le code SQL apparaîtra sous forme de commentaires dans le fichier exporté.
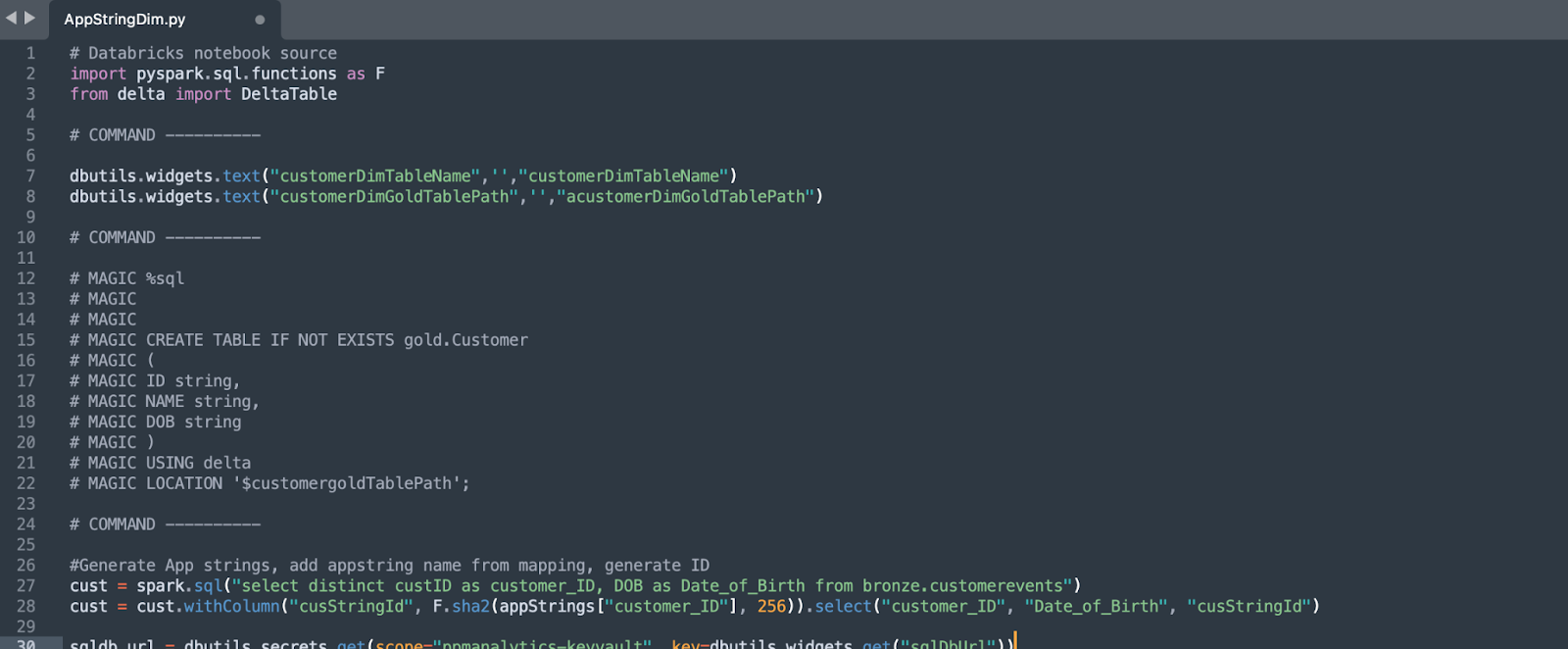
Les commentaires de code sont exclus de l’analyse SMA. Pour que votre code soit correctement analysé, placez-le dans un fichier dont l’extension correspond au langage source. Par exemple :
Le code Python doit se trouver dans des fichiers .py
Le code SQL doit se trouver dans des fichiers .sql
Notez que même le code non commenté ne sera pas analysé s’il se trouve dans un fichier dont l’extension n’est pas la bonne (comme du code Python dans un fichier .sql).
Before using the tool, please read the Pre-Processing Considerations section in our documentation. This section contains essential information that you need to know before proceeding.
Guide de la base de code¶
Sélectionnez l’un des répertoires d’exemple de base de code extraits comme entrée pour l’outil Snowpark Migration Accelerator (SMA).
Lors de la migration du code, conservez la structure de votre dossier d’origine. Cela permet de préserver l’organisation des fichiers et d’aider les développeurs à comprendre l’architecture du code. Le processus de conversion du code et l’analyse de l’évaluation sont effectués fichier par fichier.
Pour ce tutoriel, nous travaillerons avec de petits échantillons de code Spark fonctionnels (chacun inférieur à 1MB). Ces échantillons présentent différents scénarios et fonctions qui peuvent être convertis. Bien que ces exemples soient des versions simplifiées et non du code de production, ils illustrent efficacement les différentes possibilités de conversion.
Le répertoire source peut contenir des notebooks Jupyter (.ipynb), des scripts Python (.py) et des fichiers texte. Alors que SMA examine tous les fichiers de votre base de code, il ne recherche que les références Spark API dans les fichiers Python (.py) et les fichiers Jupyter notebook (.ipynb).