Configuration des Snowflake Notebooks¶
Les Snowflake Notebooks sont des objets de première classe stockés dans un schéma sous une base de données. Ils peuvent fonctionner sur deux architectures de calcul : les entrepôts et les conteneurs. Cette rubrique présente les paramètres permettant de configurer votre compte en tant qu’administrateur et de commencer à utiliser Snowflake Notebooks.
Configurer l’administrateur¶
Pour configurer votre organisation à l’aide de Snowflake Notebooks, procédez comme suit :
Examinez les exigences en matière de compte et de déploiement.
Acceptez les conditions d’utilisation d’Anaconda pour importer des bibliothèques.
Créez des ressources et accordez des privilèges pour créer des notebooks.
Examiner les exigences en matière de compte et de déploiement¶
Assurez-vous que *.snowflake.app et *.snowflake.com figurent sur la liste d’autorisations de votre réseau, y compris des systèmes de filtrage de contenu, et qu’ils peuvent se connecter à Snowflake. Pour les applications Streamlit utilisant des environnements d’exécution de conteneur, ajoutez également *.snowflakecomputing.app à la liste d’autorisations. Lorsque ces domaines figurent sur la liste d’autorisations, vos applications peuvent communiquer avec les serveurs Snowflake sans aucune restriction. Cependant, dans certains cas, l’ajout de ces domaines peut ne pas être suffisant à cause des politiques réseau qui bloquent les sous-chemins sous ceux-ci. Si cela se produit, contactez votre administrateur réseau.
De plus, pour éviter tout problème de connexion au backend Snowflake, assurez-vous que les WebSockets ne sont pas bloqués dans votre configuration réseau.
Utilisation de paquets tiers à partir d’Anaconda¶
Snowflake donne accès à un ensemble choisi de paquets Python construits par Anaconda. Ces paquets s’intègrent directement aux fonctionnalités Python de Snowflake, sans frais supplémentaires.
Conditions de la licence¶
Dans Snowflake : régies par votre accord client Snowflake existant, y compris les restrictions d’utilisation d’Anaconda décrites dans cette documentation. Aucun condition Anaconda distincte ne s’applique à l’utilisation dans Snowflake.
Développement local : à partir du référentiel Anaconda dédié de Snowflake : Sous réserve des Conditions applicables au client final intégrées d’Anaconda et des conditions de service d’Anaconda publiées dans le référentiel. L’utilisation locale est limitée au développement/test de charges de travail destinées à être déployées dans Snowflake.
Créer des ressources et accorder des privilèges¶
Pour créer un notebook, un rôle a besoin de privilèges sur les ressources suivantes :
Privilège CREATE NOTEBOOK sur un emplacement
Privilège USAGE sur les ressources de calcul
(Facultatif) Privilège USAGE d’accès aux intégrations externes (EAIs)
Voir Modèle pour la configuration de Notebooks pour des exemples de scripts de création et d’octroi d’autorisations sur ces ressources.
Emplacement¶
L’emplacement est l’endroit où l’objet notebook est stocké. L’utilisateur final peut effectuer des requêtes dans toutes les bases de données et tous les schémas auxquels son rôle lui donne accès.
Pour passer à une autre base de données ou à un autre schéma, utilisez les commandes USE DATABASE ou USE SCHEMA dans une cellule SQL.
Dans Container Runtime, le rôle qui crée le notebook doit également disposer du privilège CREATE SERVICE sur le schéma.
Privilège |
Objet |
|---|---|
USAGE |
Base de données |
USAGE |
Schéma |
CREATE NOTEBOOK |
Schéma |
CREATE SERVICE |
Schéma |
Les rôles qui possèdent un schéma ont automatiquement le privilège de créer des notebooks dans ce schéma, car les propriétaires peuvent créer n’importe quel type d’objet, y compris des notebooks.
Privilège |
Objet |
|---|---|
USAGE |
Base de données |
OWNERSHIP |
Schéma |
Ressources de calcul¶
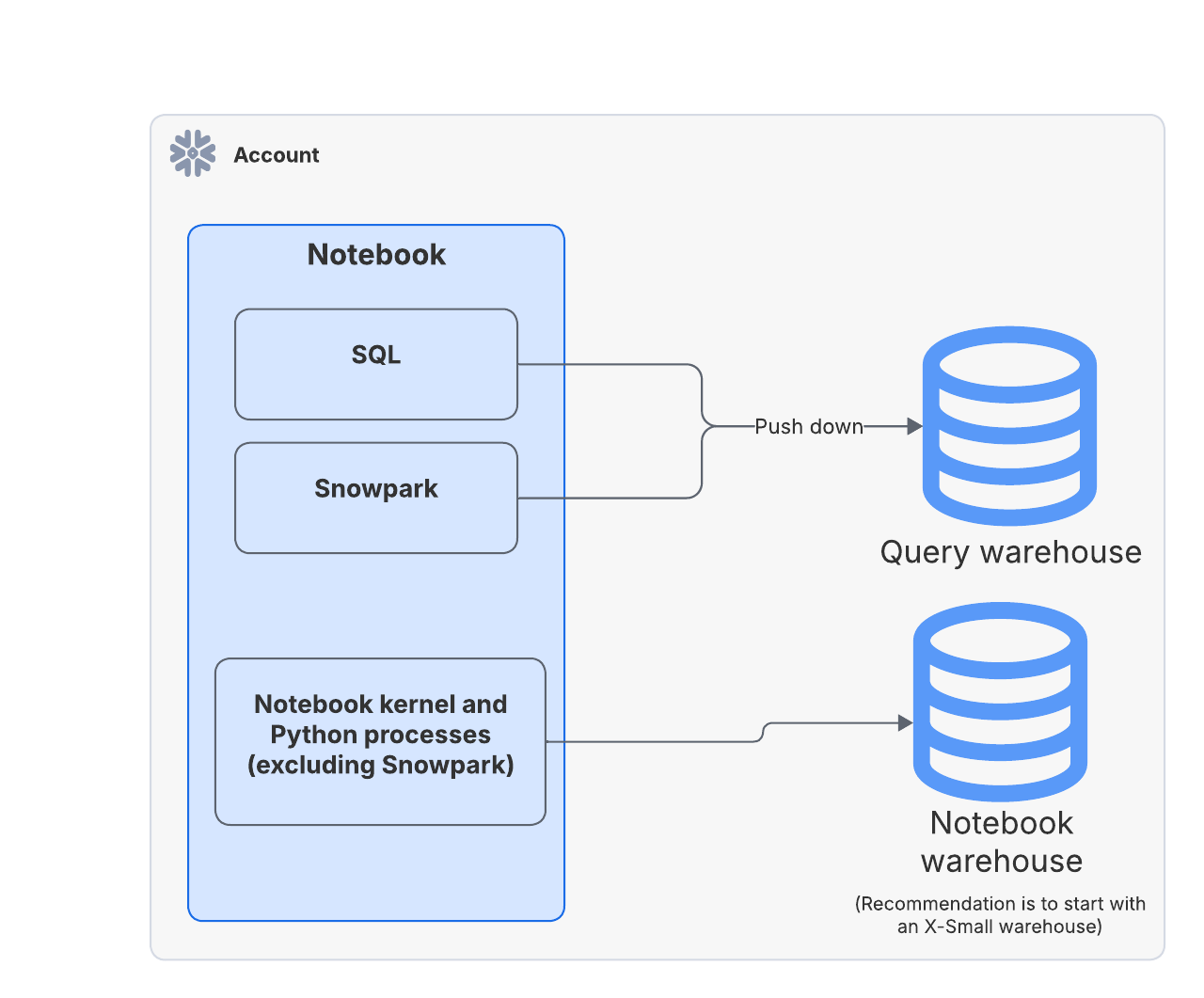
Dans Warehouse Runtime, le moteur d’un notebook et les processus Python issus du code rédigé dans le notebook s’exécutent dans l’entrepôt du notebook, mais les requêtes SQL et les requêtes push down de Snowpark s’exécutent dans l’entrepôt Query. Le rôle de propriétaire du notebook requiert le privilège USAGE sur les deux entrepôts.
Si un notebook s’exécute dans Container Runtime, le rôle doit disposer du privilège USAGE sur un pool de calcul plutôt que sur l’entrepôt de ce notebook. Les pools de calcul sont des machines virtuelles basées sur CPU ou GPUgérées par Snowflake. Lors de la création d’un pool de calcul, définissez le paramètre MAX_NODES sur une valeur supérieure à un, car chaque notebook nécessitera un nœud complet pour fonctionner. Pour plus d’informations, voir Snowpark Container Services : utilisation des pools de calcul.
Privilège |
Objet |
|---|---|
USAGE |
Entrepôt du notebook ou pool de calcul |
USAGE |
Entrepôt de requêtes |
Intégrations d’accès externes (en option)¶
Si vous autorisez certains rôles à accéder à un réseau externe, utilisez le rôle ACCOUNTADMIN pour définir et accorder le privilège USAGE sur les intégrations d’accès externes (EAIs). Les EAIs permettent l’accès à des points de terminaison externes spécifiques afin que vos équipes puissent télécharger des données et des modèles, envoyer des requêtes et des réponses à l’API, se connecter à d’autres services, etc. Pour les notebooks fonctionnant dans Container Runtime, les EAI permettent également à vos équipes d’installer des paquets provenant de dépôts tels que PyPi et Hugging Face.
Pour plus de détails sur la configuration d’une EAI pour votre notebook, voir Configurer l’accès externe pour Snowflake Notebooks.
Privilège |
Objet |
|---|---|
USAGE |
Intégration de l’accès externe |
Modèle pour la configuration de Notebooks¶
Les notebooks étant des objets dont les privilèges de création et de propriété sont basés sur des rôles, vous pouvez configurer l’accès à la fonction Notebooks en fonction des besoins de votre organisation et de votre équipe. Voici quelques exemples :
Permettre à chacun de créer des notebooks dans un emplacement spécifique¶
Les étapes suivantes expliquent comment configurer l’accès pour la création de notebooks dans un emplacement spécifique en accordant l’utilisation d’une base de données et d’un schéma.
Remplacez <database> et <database.schema> par la base de données et le schéma spécifiques dans lesquels vous souhaitez créer vos notebooks :
Créer un rôle dédié¶
Si vous souhaitez que seuls des utilisateurs spécifiques puissent créer des notebooks (en supposant qu’ils ne OWN pas déjà des schémas), vous pouvez créer un rôle dédié pour contrôler l’accès. Par exemple :
Accorder ROLE notebook_rl à des utilisateurs spécifiques. Ensuite, utilisez le script ci-dessus pour créer des ressources et accorder des autorisations à ce rôle (remplacez ROLE PUBLIC par ROLE notebook_rl).
Moteur du notebook¶
Le moteur du notebook (« noyau ») et les processus Python s’exécutent sur l’entrepôt du notebook. Snowflake vous recommande de commencer par un entrepôt X-Small afin de minimiser la consommation de crédit.
Pendant que vous utilisez le notebook (par exemple, pour modifier du code, exécuter, réorganiser ou supprimer des cellules), ou si le notebook reste actif pendant son délai d’expiration, une requête EXECUTE NOTEBOOK est exécutée en permanence pour indiquer que le moteur du notebook est actif et qu’une session de notebook est en cours d’utilisation. Vous pouvez vérifier le statut de cette requête sur Query history. Lorsque le site EXECUTE NOTEBOOK est en cours d’exécution, l’entrepôt du notebook est également en cours d’exécution. À la fin de EXECUTE NOTEBOOK, s’il n’y a pas d’autres requêtes ou jobs en cours dans l’entrepôt, celui-ci s’arrêtera conformément à sa politique de suspension automatique.
Pour mettre fin à la requête EXECUTE NOTEBOOK (terminer la session du notebook), procédez comme suit :
Sélectionnez Active ou sélectionnez End session dans le menu déroulant Active.
Dans Query history, trouvez la requête EXECUTE NOTEBOOK correspondante et sélectionnez Cancel query.
Laissez le notebook s’éteindre pour cause d’inactivité en fonction de son paramètre de temps d’inactivité. Si les paramètres STATEMENT_TIMEOUT_IN_SECONDS et STATEMENT_QUEUED_TIMEOUT_IN_SECONDS de l’entrepôt de du notebook sont définis sur une petite valeur, le notebook risque de s’éteindre rapidement ou de ne pas démarrer, quelle que soit l’activité de l’utilisateur.
Requêtes¶
Les requêtes SQL et Snowpark (par exemple, session.sql) sont poussées vers l’entrepôt de requêtes, qui est utilisé à la demande. Lorsque les requêtes SQL et Snowpark ont fini de s’exécuter, l’entrepôt de requêtes est suspendu si aucun autre job n’est en cours d’exécution en dehors du notebook. Sélectionnez la taille de l’entrepôt qui correspond le mieux à vos besoins en matière de performance des requêtes. Par exemple, vous pourriez vouloir exécuter des requêtes SQL volumineuses ou effectuer des opérations de calcul intensif à l’aide de Snowpark Python qui nécessitent un entrepôt plus important. Pour les opérations qui nécessitent une utilisation importante de la mémoire, envisagez d’utiliser un entrepôt optimisé par Snowpark.
Vous pouvez modifier l’entrepôt de requêtes dans Notebook Settings. Vous pouvez également exécuter la commande suivante dans n’importe quelle cellule SQL du notebook pour modifier l’entrepôt de requêtes pour toutes les requêtes ultérieures dans la session actuelle du notebook :
Temps d’inactivité et reconnexion¶
Le temps d’inactivité s’accumule lorsque l’utilisateur n’effectue aucune action, telle que l’édition de code, l’exécution de cellules, la réorganisation de cellules ou la suppression de cellules. Chaque fois que vous reprenez une activité, le temps d’inactivité se réinitialise. Lorsque le temps d’inactivité atteint le paramètre de délai d’expiration, la session du notebook s’arrête automatiquement.
Par défaut, les notebooks sont suspendus après une période d’inactivité. Le délai d’inactivité par défaut dépend de l’environnement d’exécution :
** Notebooks Runtime d’entrepôt :** 30 minutes (1 800 secondes) d’inactivité
** Notebooks Runtime de conteneur :** 60 minutes (3 600 secondes) d’inactivité
Vous pouvez définir le délai d’inactivité à un maximum de 72 heures (259 200 secondes). Pour mettre à jour le paramètre de délai d’expiration d’inactivité, utilisez soit la commande CREATE NOTEBOOK ou ALTER NOTEBOOK pour définir la valeur de la propriété IDLE_AUTO_SHUTDOWN_TIME_SECONDS.
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Projects » Notebooks.
Ouvrez le notebook que vous souhaitez mettre à jour.
Sélectionnez le menu vertical indiqué par une ellipse (
 ) en haut à droite de votre notebook.
) en haut à droite de votre notebook.Sélectionnez Notebook settings.
Sélectionnez Owner.
Sélectionnez le paramètre de délai d’inactivité dans la liste déroulante.
Redémarrez manuellement la session pour que le nouveau délai d’inactivité prenne effet.
Avant le délai d’expiration, votre session notebook restera active jusqu’à ce que la période de délai d’expiration soit atteinte, même si vous actualisez la page, visitez d’autres parties de l”Snowsight ou éteignez ou mettez en veille votre ordinateur. Lorsque vous rouvrez le même notebook, vous vous reconnectez à la même session, tous les états et variables de la session étant préservés, ce qui vous permet de continuer à travailler en toute transparence. Notez toutefois que l’état de vos widgets Streamlit ne sera pas conservé.
Chaque utilisateur utilisant le même notebook a sa propre session indépendante. Ils n’interfèrent pas les uns avec les autres.
Recommandations pour l’optimisation des coûts¶
En tant qu’administrateur de compte, tenez compte des recommandations suivantes pour contrôler le coût de fonctionnement des notebooks :
Demandez à vos équipes d’utiliser le même entrepôt (X-Small est recommandé) comme « entrepôt du notebook » dédié à l’exécution des sessions du notebook afin d’augmenter la simultanéité. Notez que cela peut conduire à des démarrages de session plus lents (file d’attente sur l’entrepôt) ou à des erreurs de mémoire si un trop grand nombre de notebooks doivent être exécutés simultanément.
Permettez à vos équipes d’utiliser un entrepôt dont la valeur STATEMENT_TIMEOUT_IN_SECONDS est plus faible pour exécuter des notebooks. Ce paramètre de l’entrepôt contrôle la durée des requêtes, y compris les sessions des notebooks. Par exemple, si le paramètre est défini sur 10 minutes, la session du notebook peut durer au maximum 10 minutes, que l’utilisateur soit ou non actif dans la session du notebook pendant cette période.
Demandez à vos équipes de mettre fin à leurs sessions de notebook lorsqu’elles n’ont pas l’intention de travailler activement au cours de la session.
Demandez à vos équipes de réduire le paramètre de délai d’expiration (par exemple, à 15 minutes) si elles n’ont pas besoin que la session se poursuive pendant une période prolongée.
Vous pouvez également envoyer un ticket d’assistance pour définir une valeur par défaut pour le temps d’inactivité qui s’applique à l’ensemble de votre compte. Cette valeur peut encore être remplacée au niveau du notebook par le propriétaire du notebook.
Commencer à utiliser les notebooks en ajoutant des données¶
Avant de commencer à utiliser les Snowflake Notebooks, ajoutez des données à Snowflake.
Vous pouvez ajouter des données à Snowflake de plusieurs façons :
Ajoutez des données d’un fichier CSV à une table à l’aide de l’interface Web. Voir Charger des données avec l”Snowsight.
Ajoutez des données à partir d’un stockage externe dans le cloud :
Pour charger des données à partir d’Amazon S3, consultez Chargement en masse à partir d’Amazon S3.
Pour charger des données à partir de Google Cloud Storage, consultez Chargement en masse à partir de Google Cloud Storage.
Pour charger des données à partir de Microsoft Azure, consultez Chargement en masse à partir de Microsoft Azure.
Ajoutez des données en masse de manière programmatique. Voir Chargement en masse à partir d’un système de fichiers local.
Vous pouvez également ajouter des données par d’autres moyens. Voir Vue d’ensemble du chargement de données pour plus de détails.