Snowpark Migration Accelerator: 노트북 변환¶
이제 코드베이스의 보고 노트북으로 넘어가 보겠습니다(기본 보고 노트북 - SqlServer Spark.ipynb). 파이프라인 스크립트에서 수행했던 단계와 유사한 단계를 살펴보겠습니다.
모든 문제 해결: 여기서 “문제”는 SMA에 의해 생성된 문제를 의미합니다. 출력 코드를 살펴봅니다. 구문 분석 오류 및 변환 오류를 해결하고 경고를 조사합니다.
세션 호출 해결: 세션 호출이 출력 코드에 작성되는 방식은 파일을 실행할 위치에 따라 다릅니다. 원래 실행하려고 했던 위치와 동일한 위치에서 코드 파일을 실행한 다음 Snowflake에서 실행하여 해결합니다.
입력 및 출력 해결: 다른 소스에 대한 연결은 SMA가 완전히 해결할 수 없습니다. 플랫폼마다 차이가 있으며, SMA는 일반적으로 이를 무시합니다. 또한 파일이 실행될 위치에 따라 영향을 받습니다.
정리 및 테스트: 코드를 실행해 보고, 작동하는지 확인합니다. 이 랩에서는 스모크 테스트를 진행하지만, Snowpark Python Checkpoints를 비롯해 더 광범위한 테스트 및 데이터 유효성 검사를 수행할 수 있는 도구가 있습니다.
시작해 보겠습니다.
모든 문제 해결¶
노트북에 있는 문제를 살펴보겠습니다.
(노트북은 VS Code에서 열 수 있지만, 제대로 보려면 VS Code용 Jupyter 확장 프로그램을 설치해야 할 수도 있습니다. 또는 Jupyter에서 열 수 있지만 Snowflake는 그래도 Snowflake 확장 프로그램이 설치된 VS Code를 권장합니다).
파이프라인 파일에서와 같이 비교 기능을 사용하여 두 파일을 나란히 볼 수 있지만, 그렇게 하면 json처럼 보일 것입니다.
이 노트북에는 단 2개의 고유한 EWI만 있는 것은 아닙니다. 검색창으로 돌아가서 찾을 수 있지만, 너무 짧기 때문에 아래로 스크롤하면 됩니다. 고유한 문제는 다음과 같습니다.
SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.jdbc is not supported. This is a similar issue to the one we saw in the pipeline file, but that was a write call. This is a read call to the SQL Server database. We will resolve this in a bit.
SPRKPY1068 => “pyspark.sql.dataframe.DataFrame.toPandas is not supported if there are columns of type ArrayType, but it has a workaround. See documentation for more info. This is another warning. If we pass an array to this function in Snowpark, it may not work. Let’s keep an eye on this when we test it.
노트북과 해당 문제에 대한 설명은 여기까지입니다. 구문 분석 오류를 해결했고, 입력 및 출력 문제를 수정해야 한다는 점을 알게 되었습니다. 그리고 몇 가지 잠재적인 기능적 차이점을 주시해야 합니다. 다음 단계인 세션 호출 해결로 넘어가 보겠습니다.
세션 호출 해결¶
보고 노트북에서 세션 호출을 업데이트하려면 세션 호출이 있는 셀을 찾아야 합니다. 이는 다음과 같습니다.

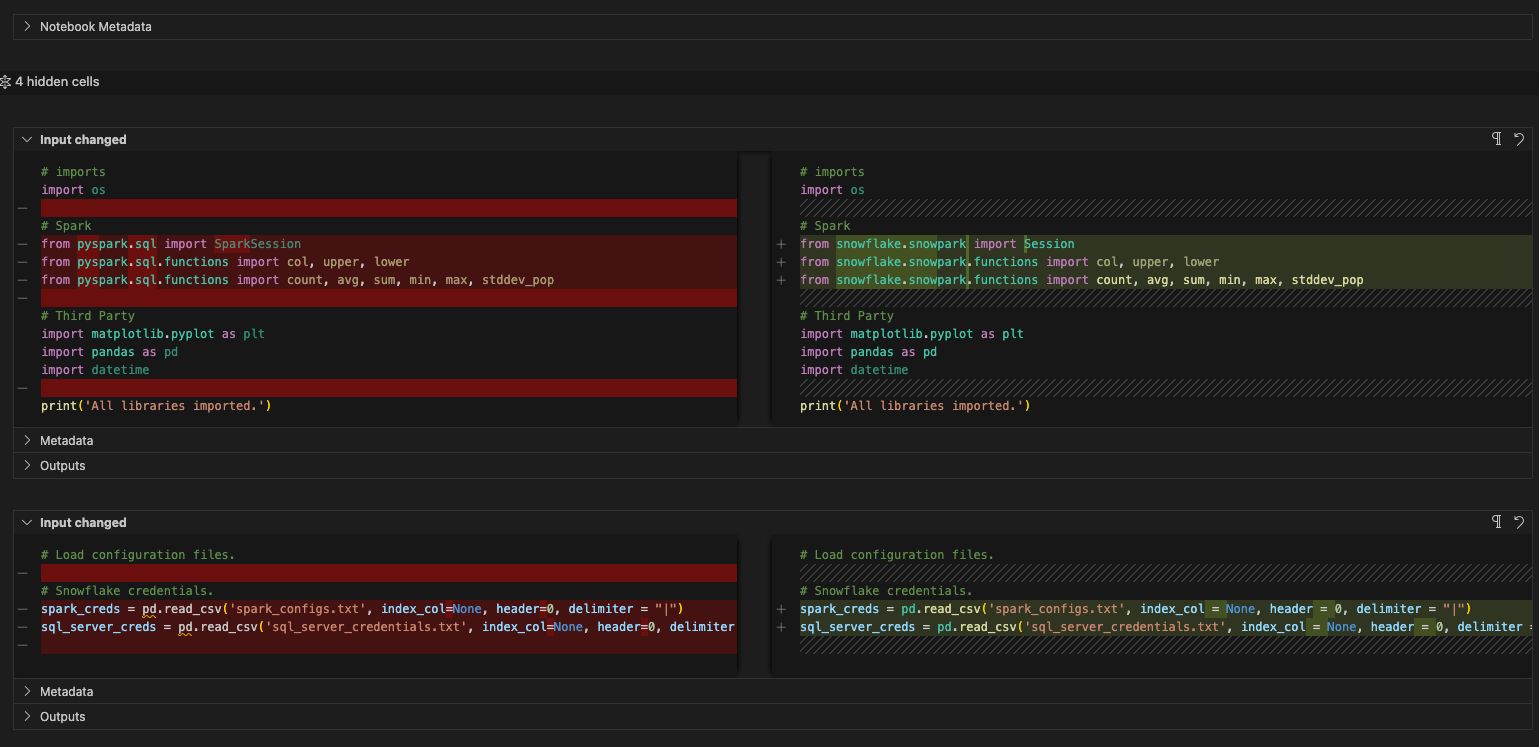
이제 파이프라인 파일에서 이미 수행한 작업을 수행해 보겠습니다.
“spark” 세션 변수에 대한 모든 참조를 “session”으로 변경합니다(이는 노트북 전체에 적용됨).
spark driver가 있는 config 함수를 제거합니다.
이 작업 전후 모습은 다음과 같습니다.
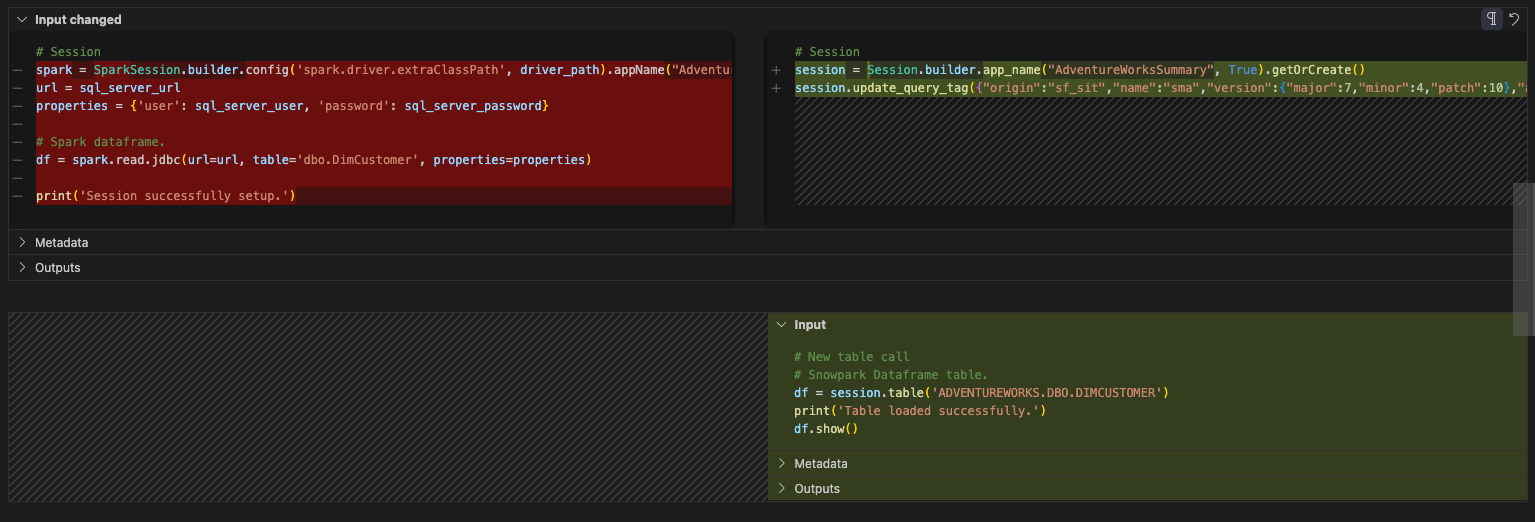
이 셀에는 다른 코드가 있습니다. 이 코드는 다음과 같습니다.
read 문을 처리할 준비가 거의 되었지만, 아직은 아닙니다. 이 모든 코드를 다른 셀로 이동해 보겠습니다. 이 셀 아래에 새 셀을 만들고 이 코드를 해당 셀로 이동합니다. 다음과 같이 표시됩니다.

Is this all we need for the session call? No. Recall (and possibly review) the previous page under Notes on Session Calls. You will either need to make sure that your connection.toml file has your connection information or you will need to explicitly specify the connection parameters you intend to use in the session.
입력 및 출력 해결¶
이제 입력과 출력을 해결하겠습니다. 파일을 로컬에서 실행하는지, 아니면 Snowflake에서 실행하는지에 따라 방법은 달라지지만, 노트북의 경우 모든 작업을 로컬에서 실행하거나 Snowflake에서 실행할 수 있습니다. 세션을 호출할 필요가 없으므로 코드가 조금 더 간단해집니다. 활성 세션만 가져오면 됩니다. 파이프라인 파일과 마찬가지로 작업은 두 부분으로 나뉩니다. 로컬에서 실행 및 오케스트레이션하고 Snowflake에서 실행합니다.
보고 노트북에서 입력 및 출력을 처리하는 작업은 파이프라인 노트북에서 했던 작업보다 상당히 간단합니다. 로컬 파일에서 데이터를 읽거나 파일 간에 데이터를 이동할 필요가 없습니다. SQL Server 테이블에서의 읽기 작업을 이제 Snowflake 테이블의 읽기 작업으로 변경합니다. SQL Server에 액세스하지 않으므로 SQL Server 속성에 대한 참조를 삭제할 수 있습니다. Snowflake에서는 read 문을 table 문으로 바꿀 수 있습니다. 이 셀의 전후 모습은 다음과 같아야 합니다.
사실 이게 전부입니다. 이제 노트북 파일의 정리 및 테스트 부분으로 넘어가 보겠습니다.
정리 및 테스트¶
Let’s do some clean up (like we did previously for the pipeline file). We never looked at our import calls and we have config files that are not necessary at all. Let’s start by removing the references to the config files. This will be each of the cells between the import statements and the session call.
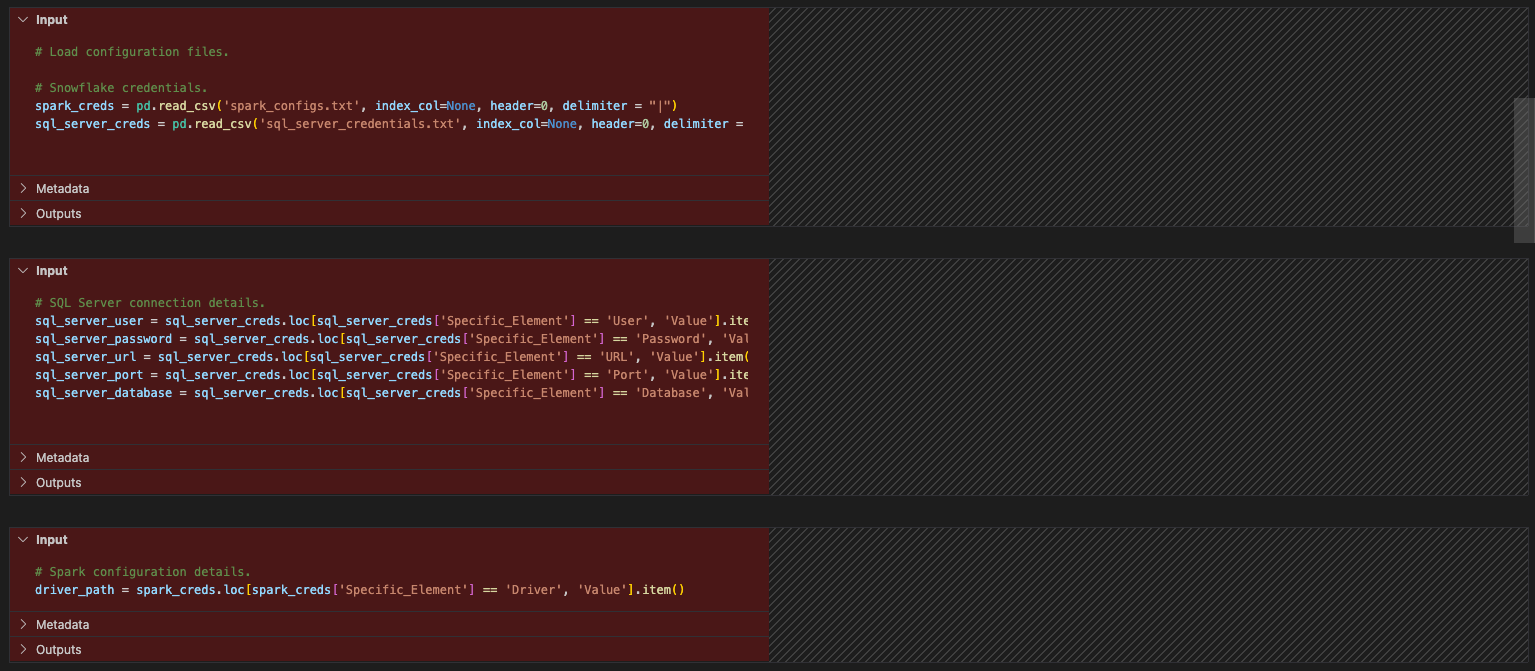
이제 가져오기를 살펴보겠습니다. os에 대한 참조는 삭제할 수 있습니다. (원본 파일에서도 사용되지 않은 것 같습니다.) 그리고 pandas 참조가 있습니다. 구성 파일이 참조되므로 이 노트북에서는 더 이상 pandas를 사용하지 않는 것 같습니다. 보고 섹션에 Snowpark DataFrame API에 포함된 toPandas 참조가 있지만, 이는 pandas 라이브러리의 일부가 아닙니다.
선택적으로 pandas에 대한 모든 import 호출을 modin pandas 라이브러리로 바꿀 수 있습니다. 이 라이브러리는 pandas DataFrame을 최적화하여 Snowflake의 강력한 컴퓨팅을 활용합니다. 다음과 같이 변경할 수 있습니다.
하지만 이것도 삭제할 수 있습니다. 참고로 SMA는 모든 Spark 관련 import 문을 Snowpark와 관련된 문으로 대체했습니다. 최종 import 셀은 다음과 같습니다.
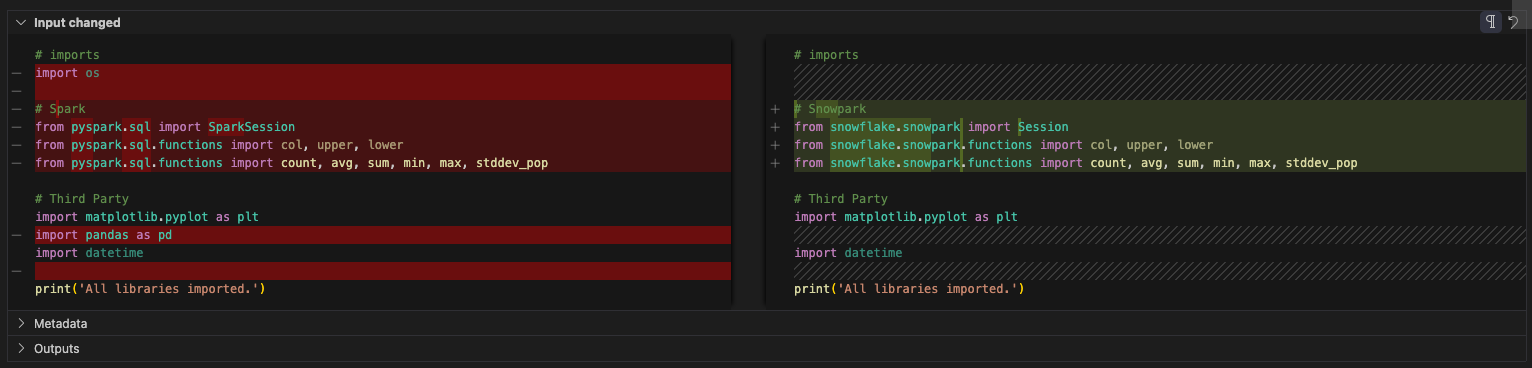
And that’s it for our cleanup. We still have a couple of EWIs in the reporting and visualization cells, but it looks like we should make it. Let’s run this one and see if we get an output.
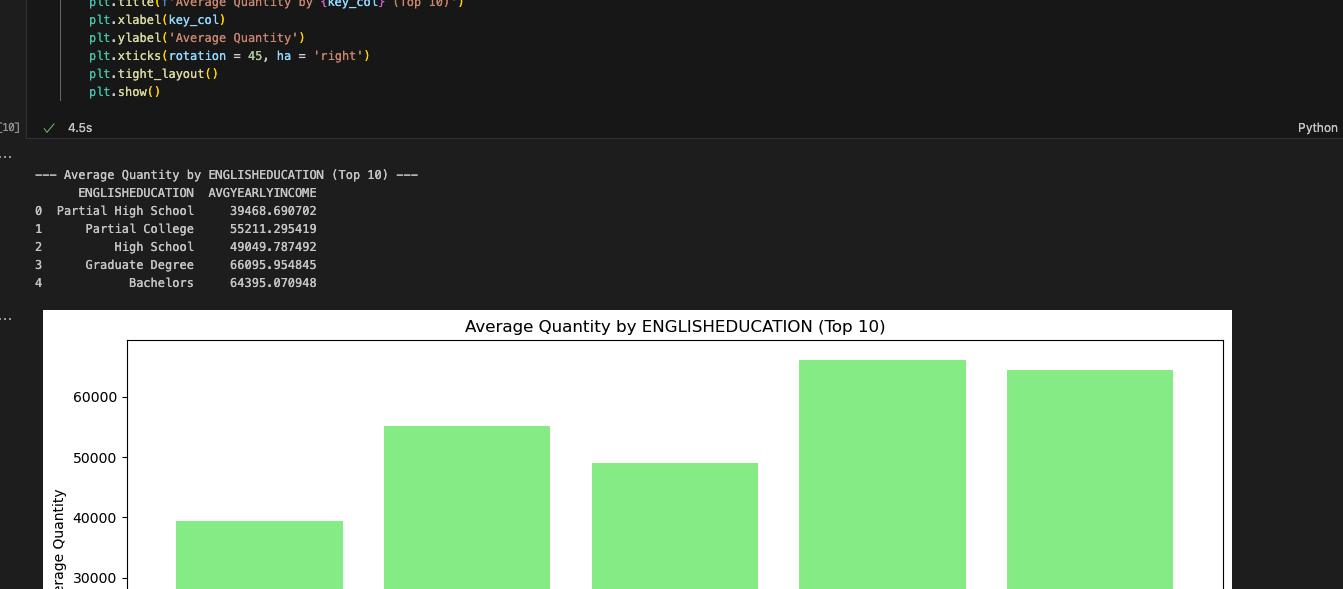
성공했습니다. 이 보고서는 Spark Notebook의 출력과 일치하는 것 같습니다. 보고 셀이 복잡해 보였지만, Snowpark는 해당 셀을 성공적으로 실행했습니다. SMA에서는 문제가 있을 수 있다고 알려주었지만 문제가 없는 것 같습니다. 더 많은 테스트가 도움이 되겠지만 첫 번째 스모크 테스트는 통과했습니다.
이제 Snowsight에서 이 노트북을 살펴보겠습니다. 파이프라인 파일과 달리, 이 작업은 Snowsight에서 완전히 수행할 수 있습니다.
Snowsight에서 노트북 실행¶
지금 사용 중인 노트북의 버전(문제, 세션 호출, 입력 및 출력을 모두 처리한 상태)을 Snowflake에 로드해 보겠습니다. 이를 위해 SnowSight의 노트북 섹션으로 이동합니다.
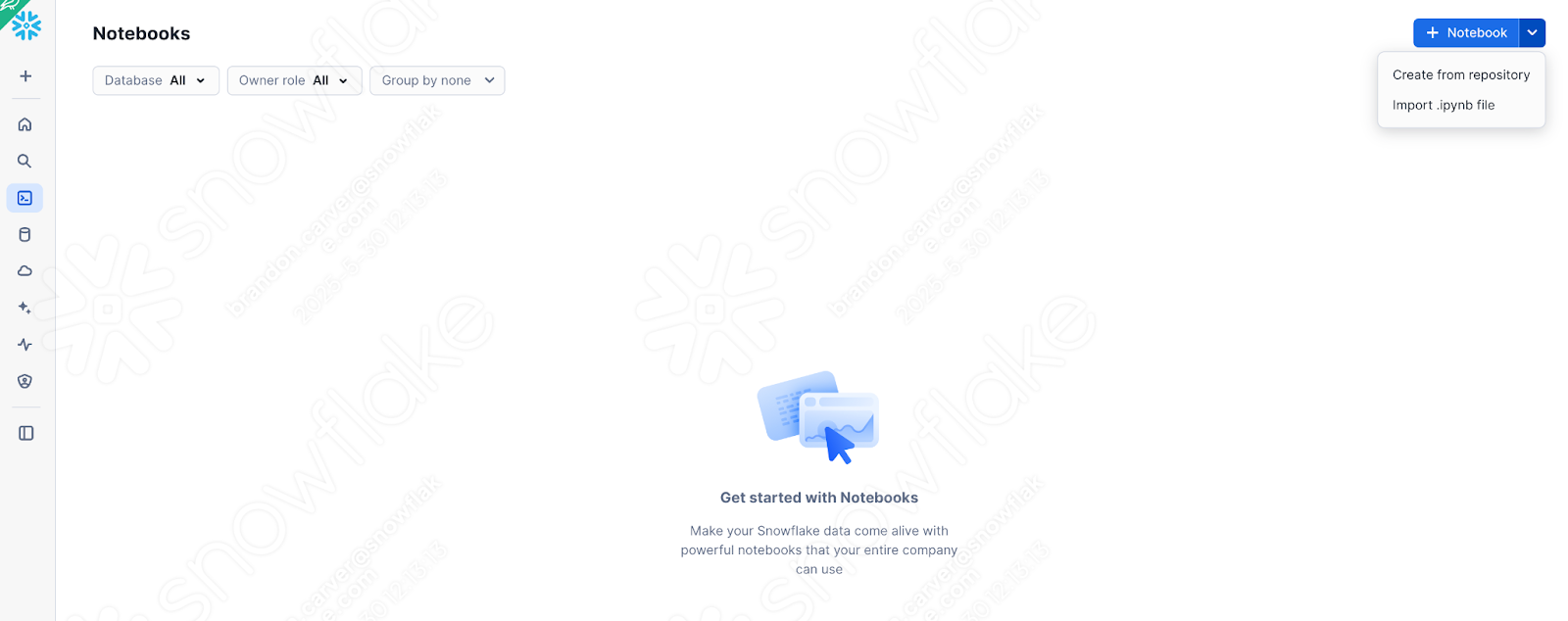
And select down arrow next to the +Notebook button in the top right, and select “Import .ipynb file” (shown above).
파일을 가져온 후에는 SMA가 프로젝트 폴더에 만든 출력 디렉터리에서 작업한 노트북 파일을 선택합니다.
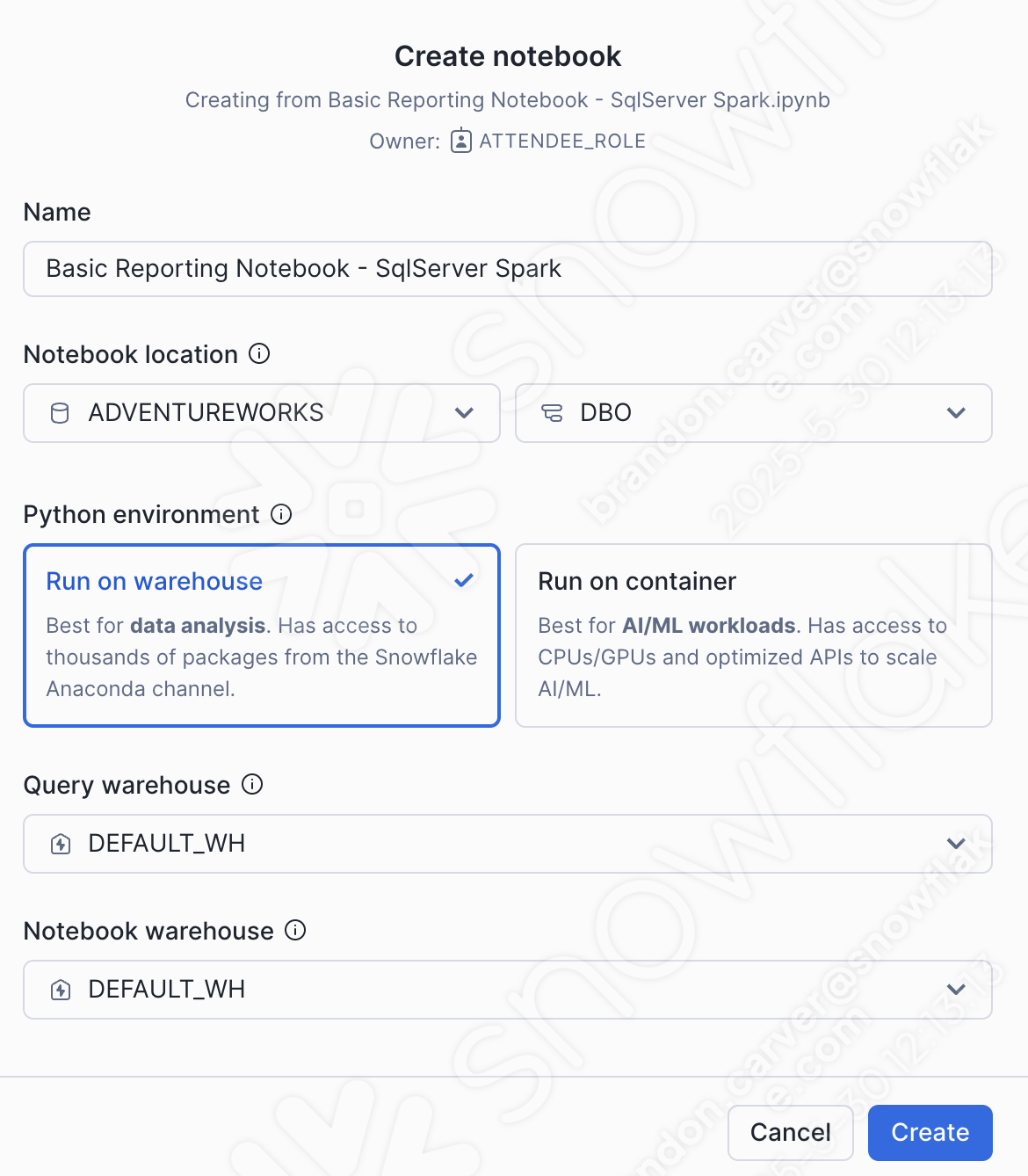
노트북 만들기 대화 상자 창이 열립니다. 업로드를 할 때 다음 옵션을 선택합니다.
Notebook location:
데이터베이스: ADVENTUREWORKS
스키마: DBO
Python 환경: 웨어하우스에서 실행
This is not a large notebook with a bunch of ml. This is a basic reporting notebook. We can run this on a warehouse.
Query warehouse: DEFAULT_WH
Notebook warehouse: DEFAULT_WH (you can leave it as the system chosen warehouse (will be a streamlit warehouse)… for this notebook, it will not matter)
이 옵션은 아래에서 확인할 수 있습니다.
노트북이 Snowflake에 로드되며 다음과 같이 표시됩니다.
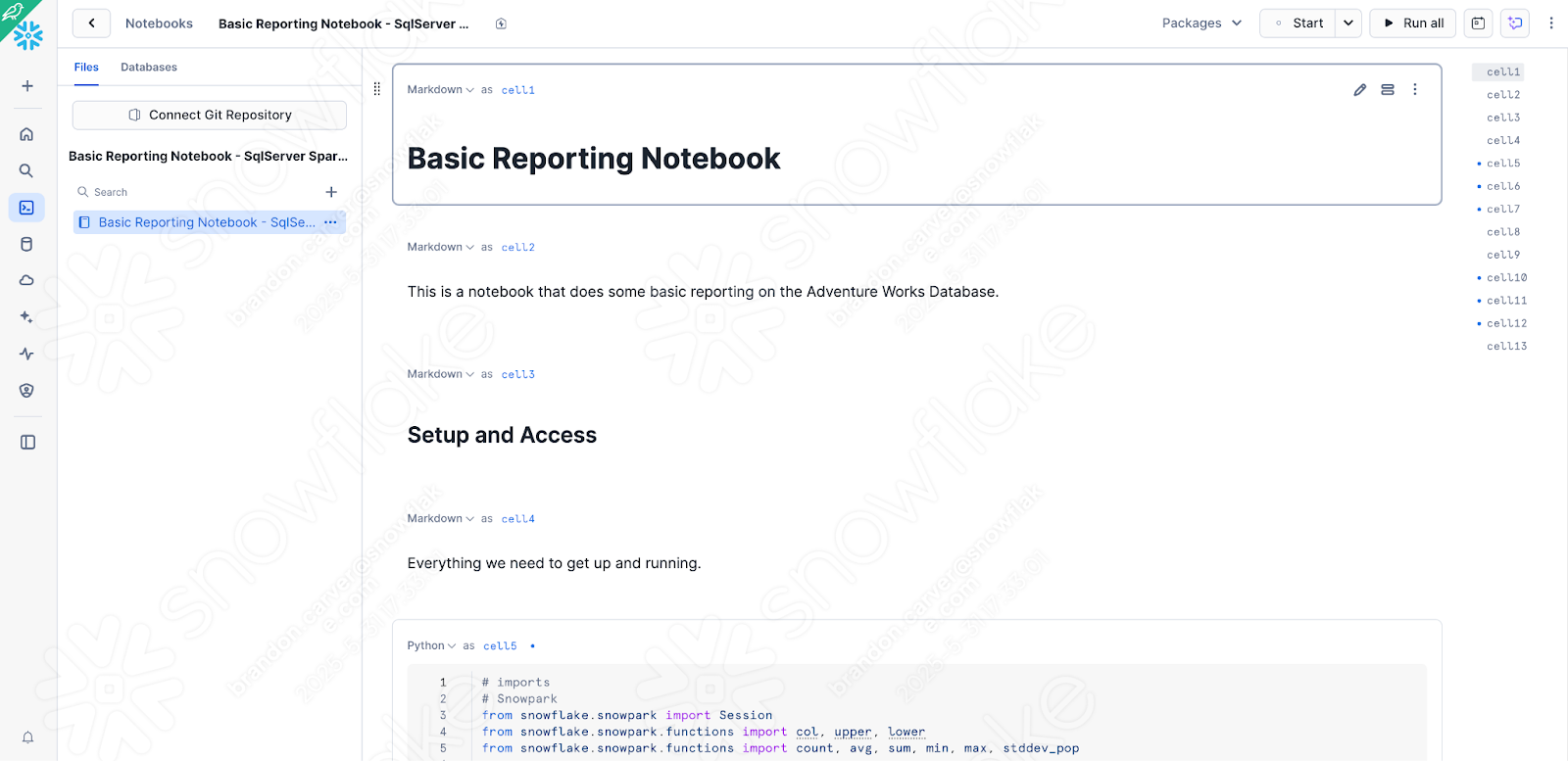
노트북을 Snowsight에서 실행하려면 방금 로컬에서 테스트한 버전에서 몇 가지 간단한 확인 및 변경을 수행해야 합니다.
세션 호출을 변경하여 활성 세션 검색
설치해야 하는 종속 라이브러리를 사용할 수 있는지 확인
Let’s start with the first one. It may seem odd to alter the session call again after we spent so much time on it in the first place, but we’re running inside of Snowflake now. You can remove anything associated with reading the session call and replacing it with the “get_active_session” call that is standard at the top of most Snowflake notebooks:
이미 연결되어 있으므로 연결 매개 변수를 지정하거나 .toml 파일을 업데이트할 필요가 없습니다. 현재 Snowflake에 있기 때문입니다.
셀의 이전 코드를 새 코드로 바꿔 보겠습니다. 다음과 같이 표시됩니다.
이제 무엇을 추가해야 할지 파악하는 대신 이 실행에 사용 가능한 패키지를 살펴보겠습니다. Snowflake를 실행해 보겠습니다. 노트북을 사용할 때의 장점 중 하나는 개별 셀을 실행하고 결과를 확인할 수 있다는 점입니다. import 라이브러리 셀을 실행해 보겠습니다.
아직 세션을 시작하지 않았다면 화면의 오른쪽 상단에서 “Start”를 클릭하여 세션을 시작합니다.
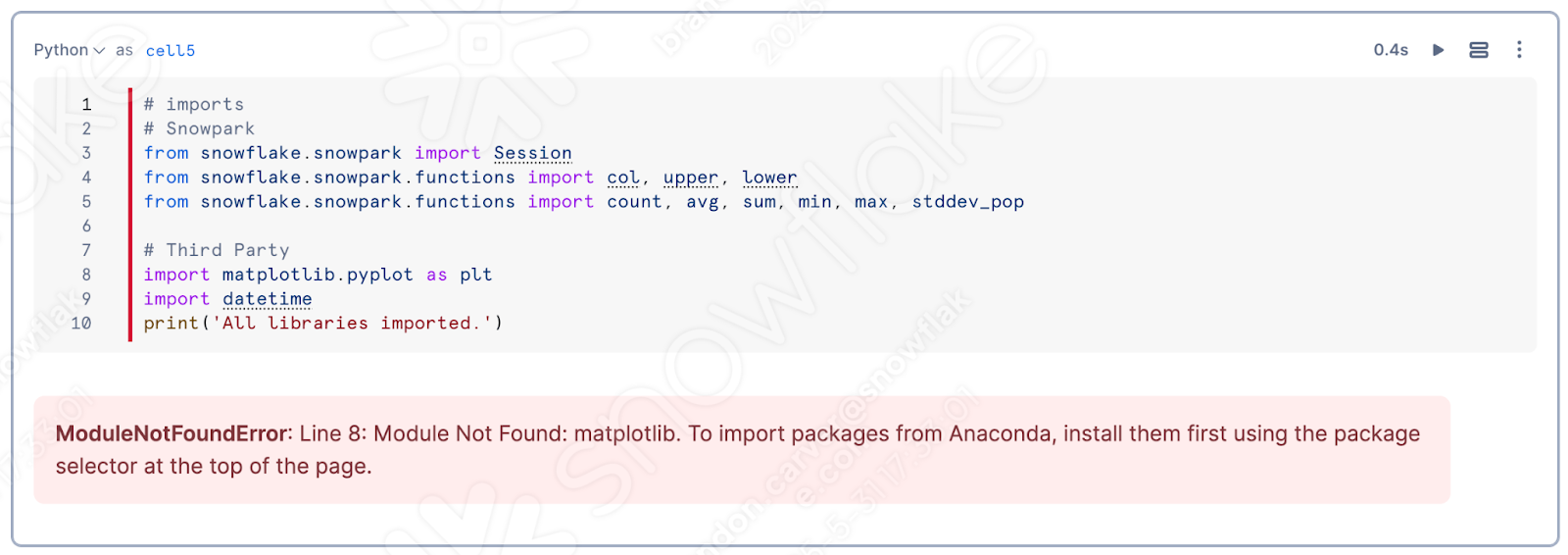
노트북에서 최상위 셀을 실행하면 matplotlib가 세션에 로드되지 않았음을 발견하게 될 것입니다.
이는 이 노트북에서 매우 중요한 라이브러리입니다. 노트북의 오른쪽 상단에 있는 “Packages” 옵션을 사용하여 노트북 및 세션에 해당 라이브러리를 추가할 수 있습니다.
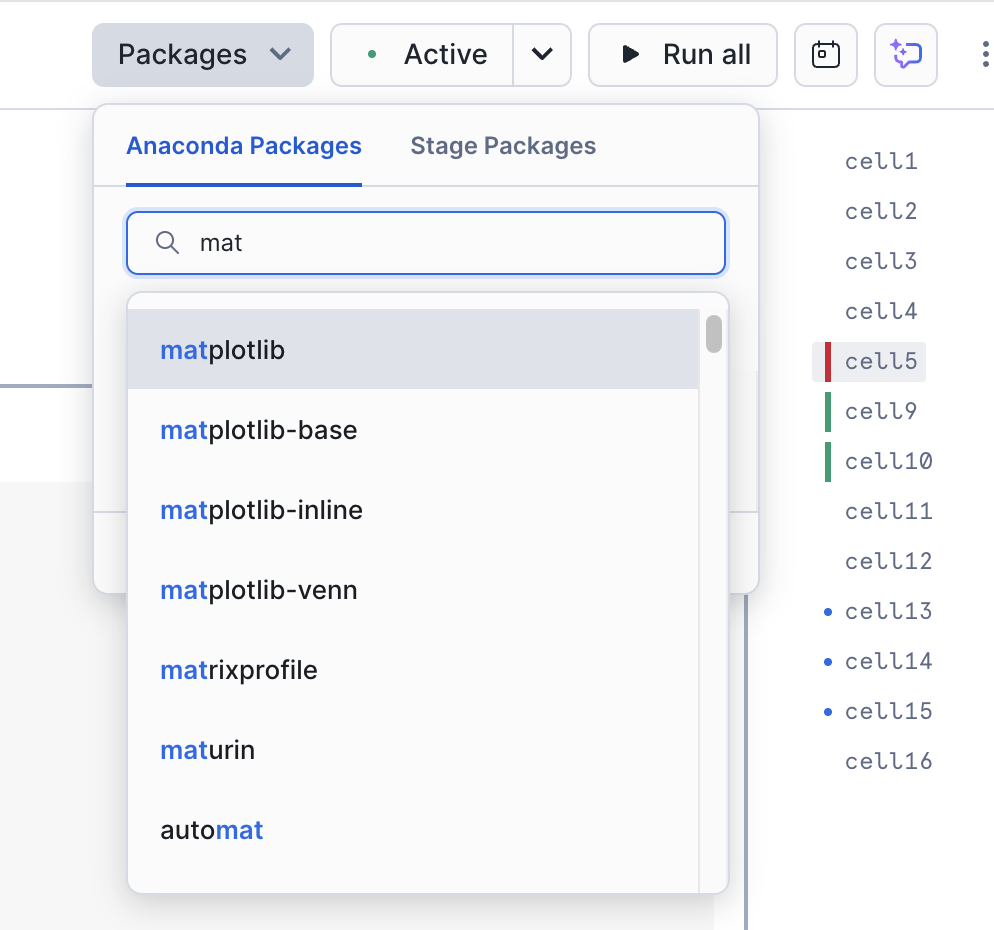
**matplotlib**를 검색하여 선택합니다. 그러면 세션에서 이 패키지를 사용할 수 있습니다.
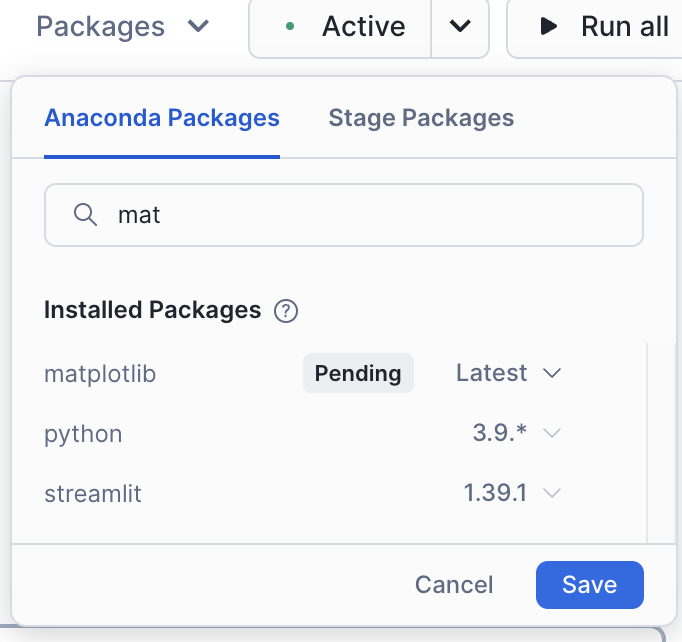
이 라이브러리를 로드한 후에는 세션을 다시 시작해야 합니다. 세션을 다시 시작한 후에는 첫 번째 셀을 다시 실행합니다. 이번에는 성공했다는 메시지가 표시될 것입니다.

패키지를 로드하고 세션을 수정하고 코드의 나머지 문제가 이미 해결된 상태에서, 노트북의 나머지 부분을 확인하려면 어떻게 해야 할까요? 실행하면 됩니다. 화면 오른쪽 상단의 “Run all”을 선택하여 노트북의 모든 셀을 실행하고 오류가 발생하는지 확인하면 됩니다.
성공적으로 실행된 것 같습니다.
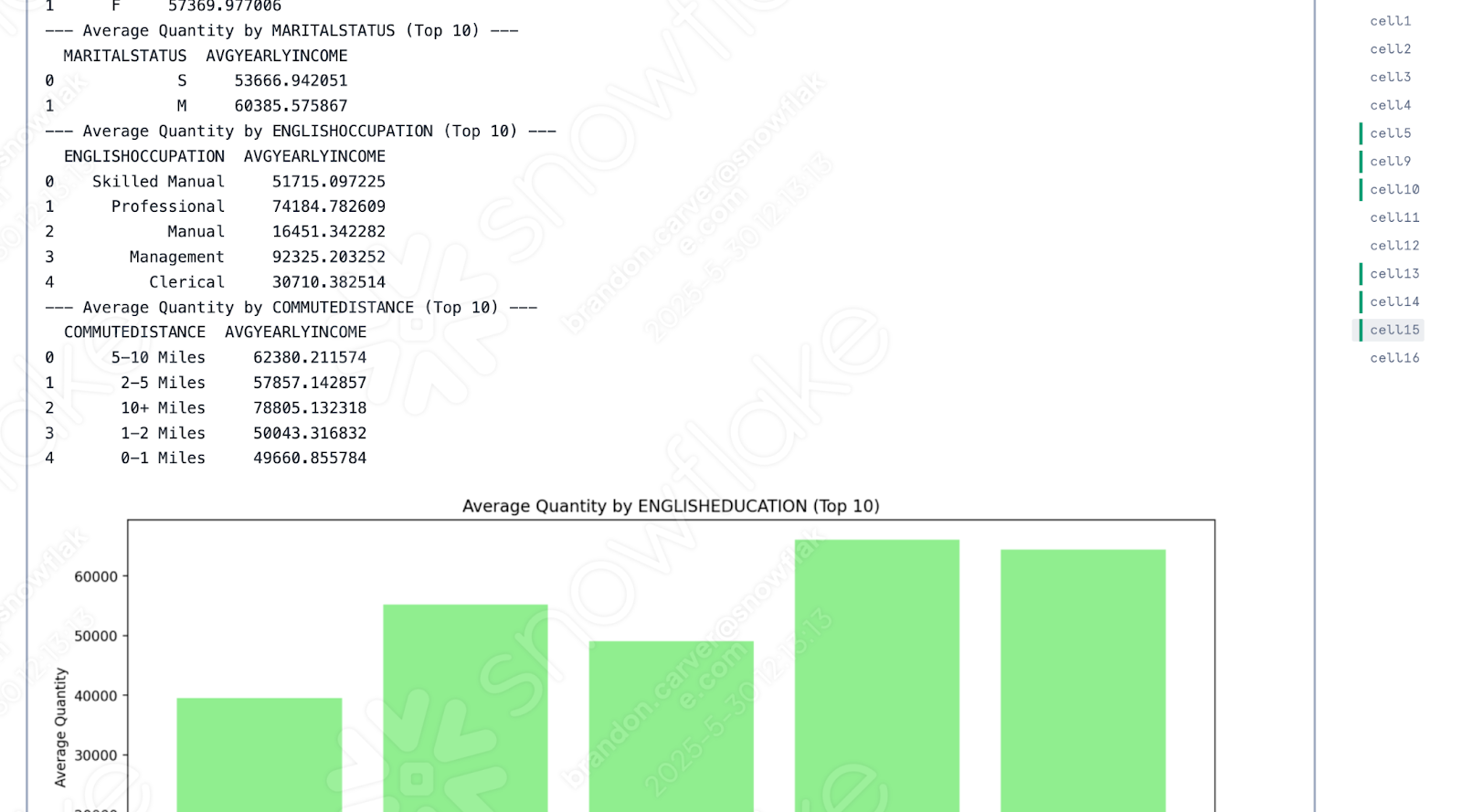
두 노트북 실행을 비교해 보면 유일한 차이점은 Snowflake 버전에서는 모든 출력 데이터 세트를 먼저 배치한 다음 이미지를 배치하는 반면, Spark Jupyter Notebook에서는 두 데이터 세트가 혼합되어 있다는 점입니다.
이러한 차이는 API의 차이가 아니라 Snowflake의 노트북이 이를 오케스트레이션하는 방식의 차이입니다. 따라서 AdventureWorks가 받아들일 만한 차이일 것입니다.
결론¶
SMA를 활용하여 데이터 파이프라인 및 보고 노트북의 마이그레이션 속도를 높일 수 있었습니다. 각각을 더 많이 보유할수록 SMA와 같은 도구가 제공할 수 있는 가치가 높아집니다.
이제 계속해서 반복해 온 평가 -> 변환 -> 유효성 검사 흐름으로 돌아가 보겠습니다. 이 마이그레이션에서는 다음을 수행했습니다.
SMA에서 프로젝트 설정
코드 파일에 대한 SMA의 평가 및 변환 엔진 실행
SMA의 출력 보고서를 검토하여 현재 상태에 대한 이해 향상
VS Code에서 SMA가 변환할 수 없는 항목 검토
문제 및 오류 해결
세션 참조 해결
입력 및 출력 참조 해결
코드를 로컬에서 실행
Snowflake에서 코드 실행
새로 마이그레이션한 스크립트 실행 및 성공 검증
Snowflake는 SnowConvert, SnowConvert Migration Assistant, Snowpark Migration Accelerator와 같은 마이그레이션 도구를 개선하는 데 시간을 투자한 것처럼 수집 및 데이터 엔지니어링 기능을 개선하는 데에도 많은 시간을 투자해 왔습니다. 이 모든 도구는 계속해서 개선될 것입니다. 마이그레이션 도구에 대한 제안 사항이 있는 경우 언제든지 문의해 주세요. 이 팀들은 항상 도구 개선에 도움이 되는 피드백을 환영합니다.