Snowpark Migration Accelerator : Conversion des notebooks¶
Passons au Notebook de rapports dans notre base de code : Notebook de rapports de base - SqlServer Spark.ipynb. Nous allons suivre un ensemble d’étapes similaire à celui que nous avons suivi pour le script du pipeline.
Résoudre tous les problèmes : « Problèmes » signifie ici les problèmes générés par SMA. Jetez un coup d’œil au code de sortie. Résolvez les erreurs d’analyse et les erreurs de conversion, et enquêtez sur les avertissements.
Résoudre les appels de session : La façon dont l’appel de session est écrit dans le code de sortie dépend de l’endroit où nous allons exécuter le fichier. Nous allons résoudre ce problème pour exécuter le(s) fichier(s) de code au même emplacement que celui qui devait être exécuté à l’origine, puis pour les exécuter dans Snowflake.
Résoudre l’entrée/les sorties : Les connexions à différentes sources ne peuvent pas être résolues entièrement par SMA. Il existe des différences entre les plateformes, ce que SMA ignorera généralement. Cela dépend également de l’endroit où le fichier sera exécuté.
Nettoyer et tester ! Exécutons le code. Vérifions qu’il fonctionne. Nous procéderons à des smoke tests dans cet atelier, mais il existe des outils pour effectuer des tests et une validation des données plus étendus, dont des points de contrôle Snowpark Python.
C’est parti !
Résoudre tous les problèmes¶
Commençons à examiner les problèmes présents dans le notebook.
(Notez que vous pouvez ouvrir le notebook dans VS Code, mais pour le visualiser correctement, nous vous conseillons d’installer l’extension Jupyter pour VS Code. Vous pouvez également ouvrir le notebook dans Jupyter, mais Snowflake recommande quand même VS Code avec l’extension Snowflake installée).
Vous pouvez utiliser la fonctionnalité de comparaison pour visualiser les deux à la fois comme nous l’avons fait avec le fichier du pipeline. Dans ce cas, il ressemblera plutôt à un json :
Remarquez qu’il n’y a que deux EWI uniques dans ce notebook. Vous pouvez revenir à la barre de recherche pour les trouver, mais comme cela est très court, vous pouvez aussi simplement… faire défiler l’écran vers le bas. Voici les problèmes uniques :
SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.jdbc is not supported. This is a similar issue to the one we saw in the pipeline file, but that was a write call. This is a read call to the SQL Server database. We will resolve this in a bit.
SPRKPY1068 => « pyspark.sql.dataframe.DataFrame.toPandas is not supported if there are columns of type ArrayType, but it has a workaround. See documentation for more info. This is another warning. If we pass an array to this function in Snowpark, it may not work. Let’s keep an eye on this when we test it.
Et c’est tout pour le notebook… et nos problèmes. Nous avons résolu une erreur d’analyse, reconnu que nous devions corriger l’entrée/les sorties, et noté qu’il existe quelques différences fonctionnelles potentielles sur lesquelles nous devons garder un œil. Passons à l’étape suivante : résoudre les appels de session.
Résoudre les appels de session¶
Pour mettre à jour les appels de session dans le notebook de rapports, nous devons localiser la cellule contenant l’appel de session. Cela ressemble à ceci :

Essayons maintenant de faire ce que nous avons déjà fait pour notre fichier de pipeline :
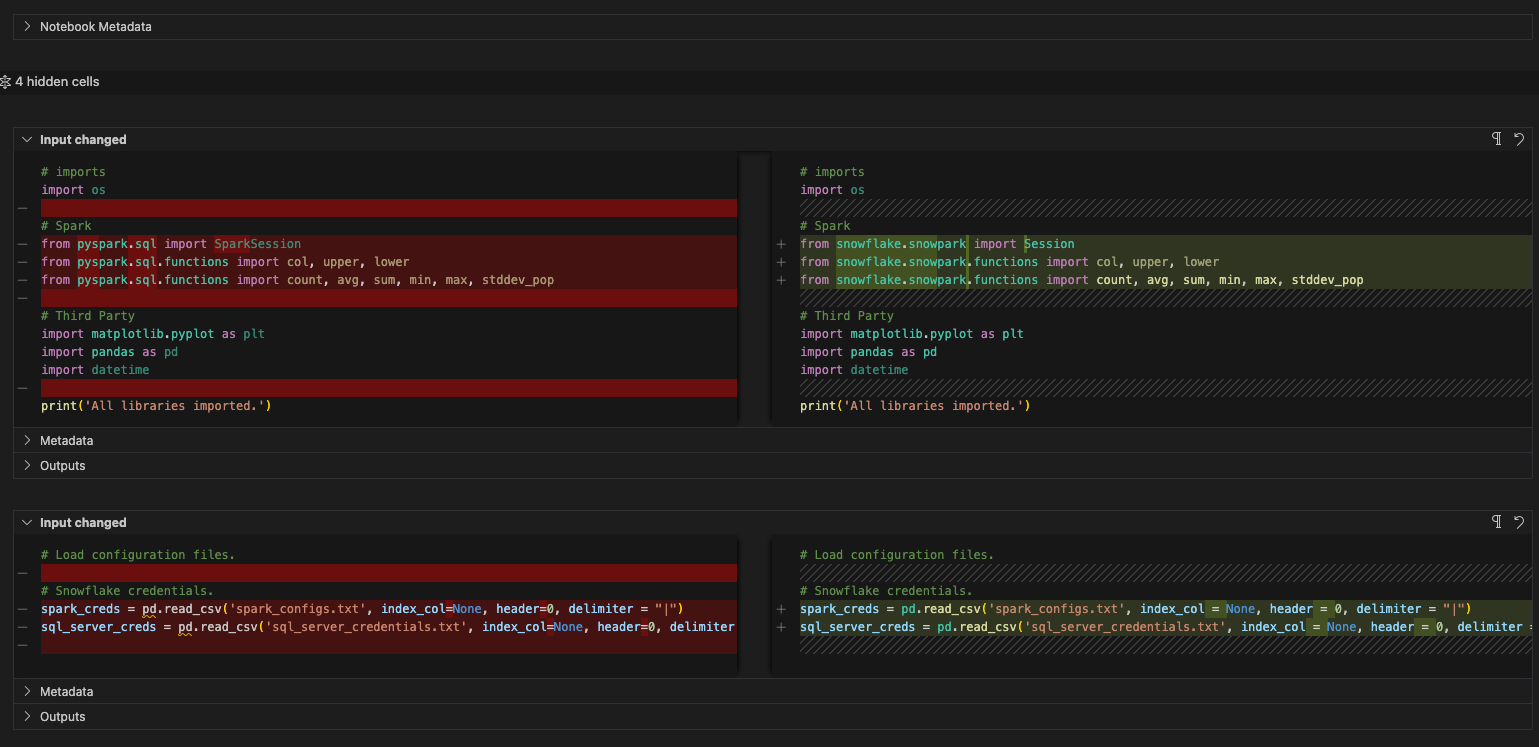
Remplacer toutes les références à la variable de session « spark » par « session » (notez que cette opération est à effectuer dans l’ensemble du notebook).
Supprimez la fonction de configuration avec le pilote spark.
L’avant et l’après de cette opération ressembleront à ceci :
Notez qu’il y a un autre code dans cette cellule. Ce code :
Nous sommes presque prêts à nous attaquer à l’instruction de lecture, mais nous n’y sommes pas encore. Déplaçons simplement tout cela vers une autre cellule. Créons une nouvelle cellule sous celle-ci, et déplaçons ce code vers cette cellule. Comme ceci :

Is this all we need for the session call? No. Recall (and possibly review) the previous page under Notes on Session Calls. You will either need to make sure that your connection.toml file has your connection information or you will need to explicitly specify the connection parameters you intend to use in the session.
Résolution des entrées/sorties¶
Résolvons maintenant nos entrées et sorties. Notez que cela peut varier selon que vous exécutez les fichiers localement ou dans Snowflake, mais pour le notebook, tout peut être exécuté localement ou dans Snowflake. Le code sera un peu plus simple, car nous n’aurons même pas besoin d’appeler une session. Nous allons simplement… activer la session. Comme pour le fichier pipeline, nous effectuerons cette opération en deux parties : avec une exécution/orchestration en local, et une exécution dans Snowflake.
La gestion des entrées et des sorties dans le notebook de rapports sera considérablement plus simple que pour le pipeline. Il n’y a pas de lecture à partir d’un fichier local ni de déplacement de données entre des fichiers. Il y a simplement une lecture depuis une table dans le serveur SQL qui est maintenant une lecture depuis une table dans Snowflake. Comme nous n’accéderons pas au serveur SQL, nous pouvons abandonner toute référence aux propriétés du serveur SQL. Et l’instruction de lecture peut être remplacée par une instruction de table dans Snowflake. L’avant et l’après pour cette cellule devraient ressembler à ceci :
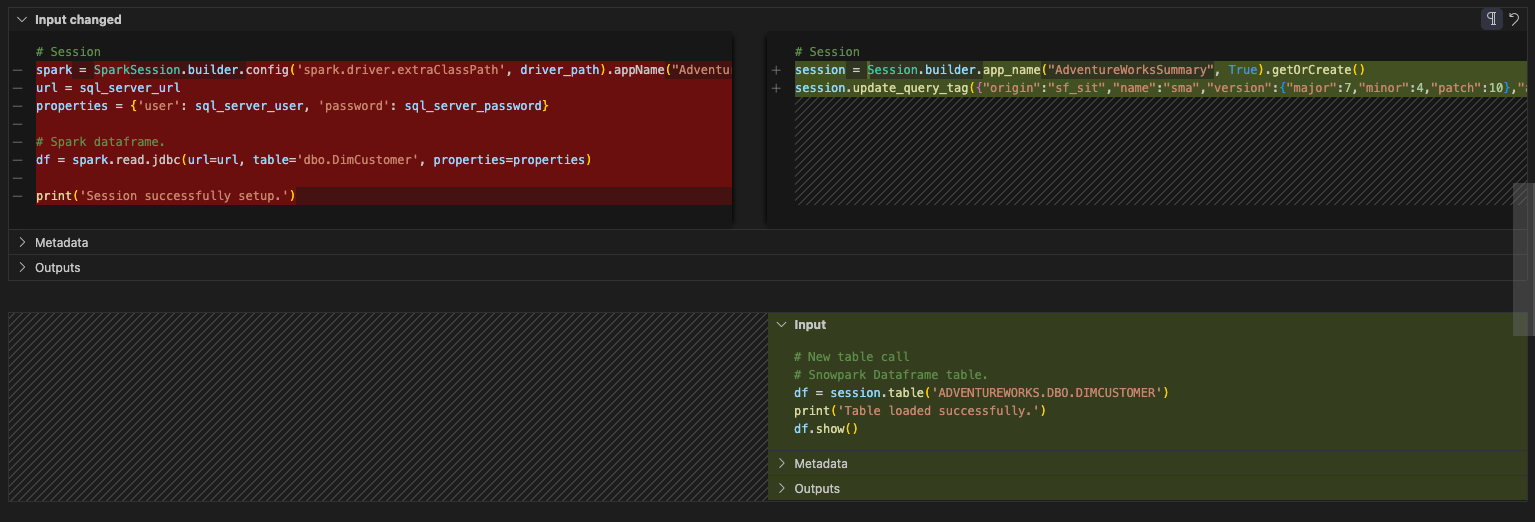
Et en fait… c’est tout. Passons à la partie Nettoyer et tester le fichier notebook.
Nettoyer et tester¶
Let’s do some clean up (like we did previously for the pipeline file). We never looked at our import calls and we have config files that are not necessary at all. Let’s start by removing the references to the config files. This will be each of the cells between the import statements and the session call.
Examinons maintenant nos importations. La référence à l’Os peut être supprimée. (Il semble que cela n’ait pas non plus été utilisé dans le fichier d’origine). Il existe une référence aux pandas. Les Pandas ne semblent plus être utilisés dans ce notebook maintenant que les fichiers de configuration sont référencés. Il existe une référence à toPandas dans le cadre de l’API du dataframe Snowpark dans la section des rapports, mais cela ne fait pas partie de la bibliothèque des pandas.
Vous pouvez éventuellement remplacer tous les appels d’importation aux pandas par la bibliothèque de pandas modin. Cette bibliothèque optimisera les dataframes pandas pour tirer parti de la puissance de calcul de Snowflake. Ce changement ressemblerait à ceci :
Ceci étant dit, nous pouvons aussi le supprimer. Notez que SMA a remplacé toutes les instructions d’importation spécifiques à Spark par celles liées à Snowpark. La cellule d’importation finale ressemblerait à ceci :
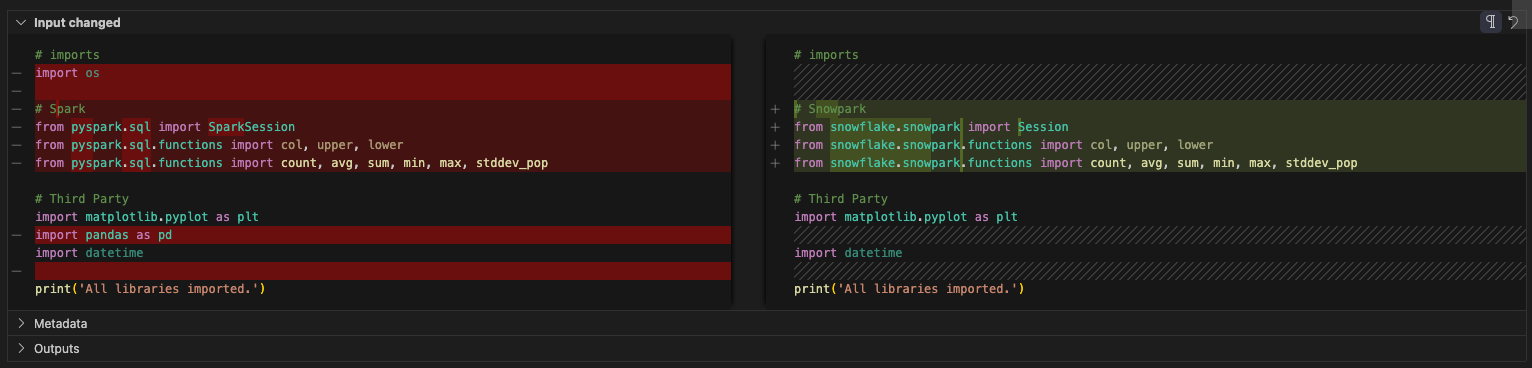
And that’s it for our cleanup. We still have a couple of EWIs in the reporting and visualization cells, but it looks like we should make it. Let’s run this one and see if we get an output.
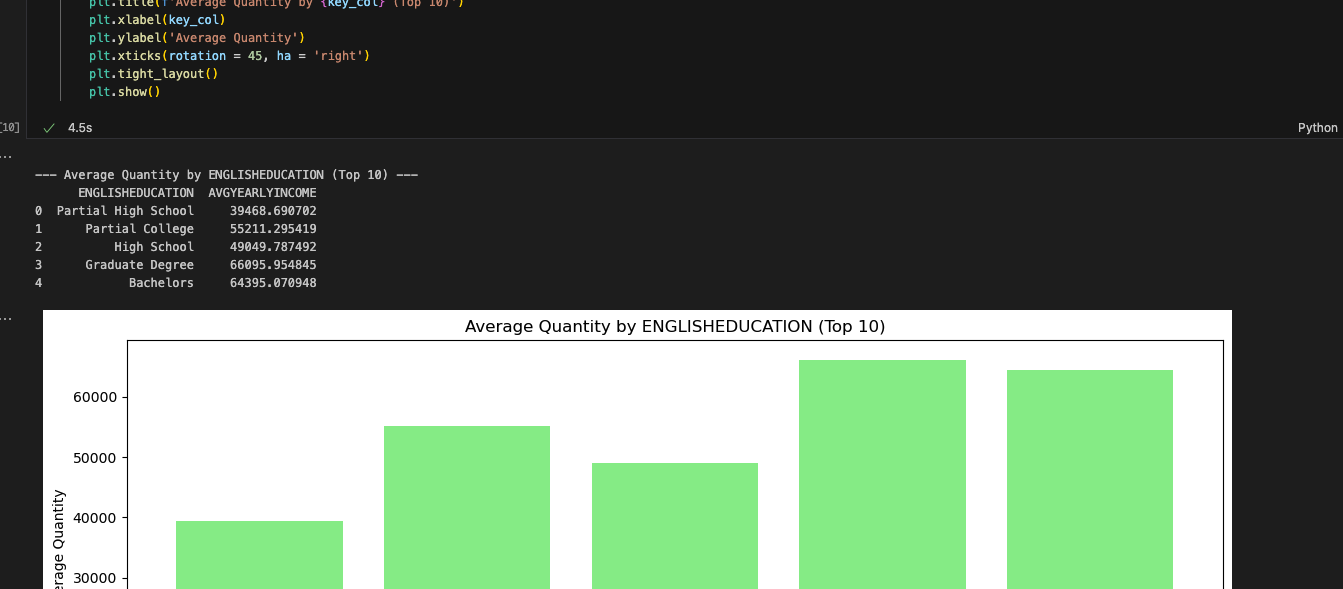
Et c’est fait. Les rapports semblent correspondre à la sortie du notebook Spark. Même si les cellules de rapports semblaient complexes, Snowpark est en mesure de les utiliser. SMA nous fait savoir qu’il pourrait y avoir un problème, mais qu’il semble n’y en avoir aucun. Davantage de tests seraient utiles, mais notre première série de smoke tests a réussi.
Regardons maintenant ce notebook dans Snowsight. Contrairement au fichier du pipeline, nous pouvons le faire entièrement dans Snowsight.
Exécution du notebook dans Snowsight¶
Prenons la version du notebook que nous avons actuellement (après avoir traité les problèmes, les appels de session et les entrées et sorties) et chargeons-la dans Snowflake. Pour ce faire, accédons à la section Notebooks dans SnowSight :
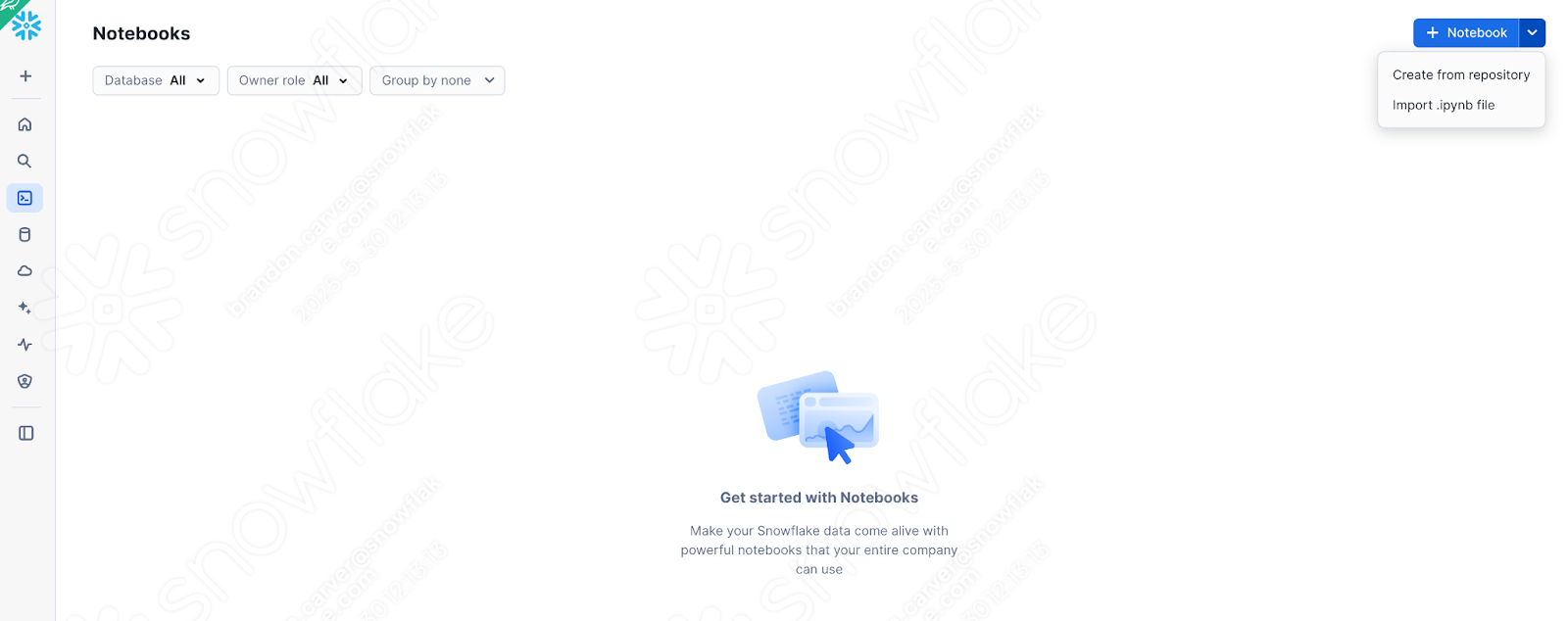
And select down arrow next to the +Notebook button in the top right, and select “Import .ipynb file” (shown above).
Une fois ce fichier importé, choisissez le fichier de notebook avec lequel nous travaillons dans le répertoire de sortie créé par SMA dans le dossier de votre projet.
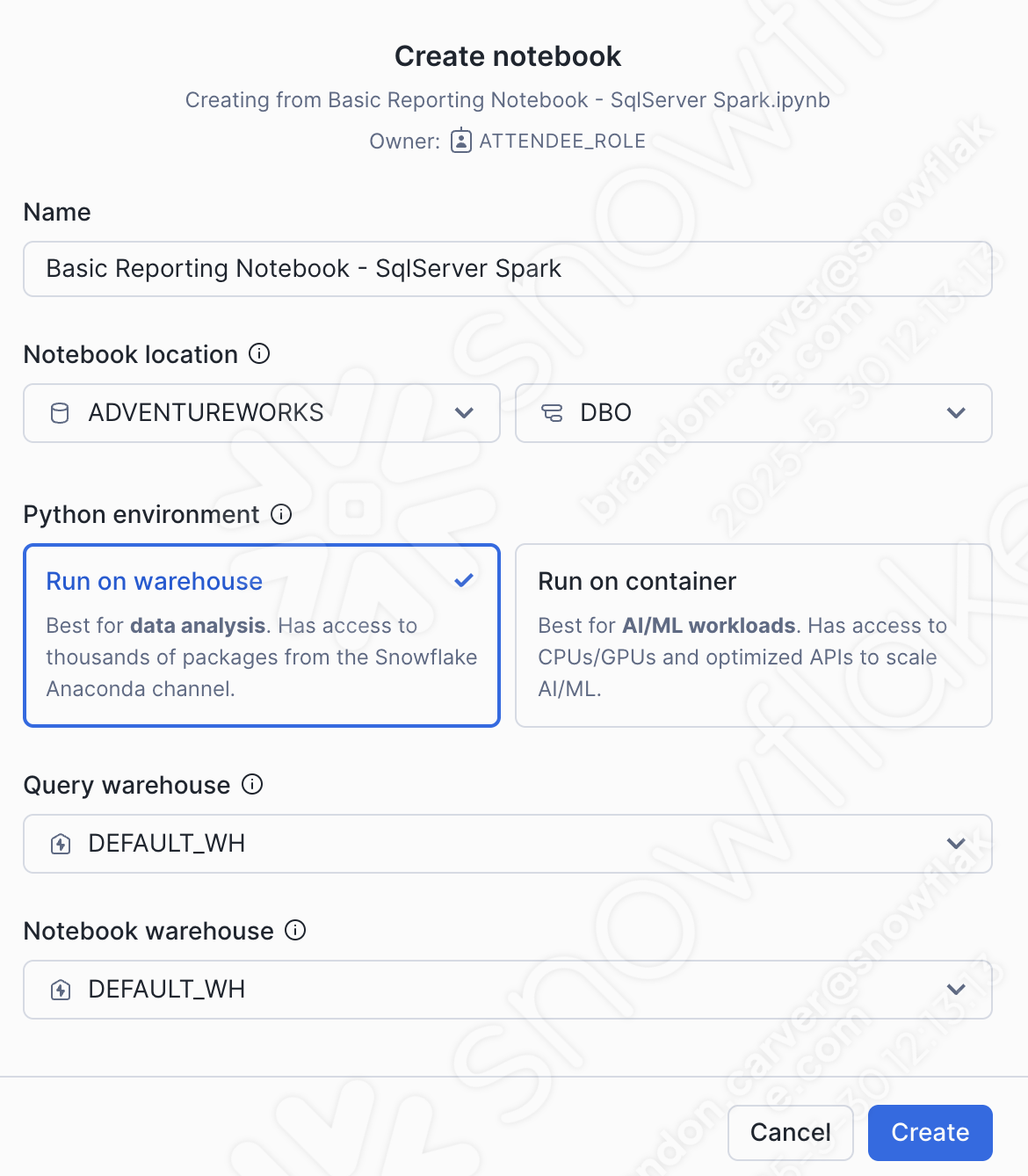
Une boîte de dialogue de création de notebook s’ouvre. Pour ce chargement, nous choisirons les options suivantes :
Notebook location:
Base de données : ADVENTUREWORKS
Schéma : DBO
Environnement Python : Exécuter sur un entrepôt
This is not a large notebook with a bunch of ml. This is a basic reporting notebook. We can run this on a warehouse.
Query warehouse: DEFAULT_WH
Notebook warehouse: DEFAULT_WH (you can leave it as the system chosen warehouse (will be a streamlit warehouse)… for this notebook, it will not matter)
Vous pouvez voir ces sélections ci-dessous :
Cela devrait charger votre notebook dans Snowflake et cela ressemblera à ceci :
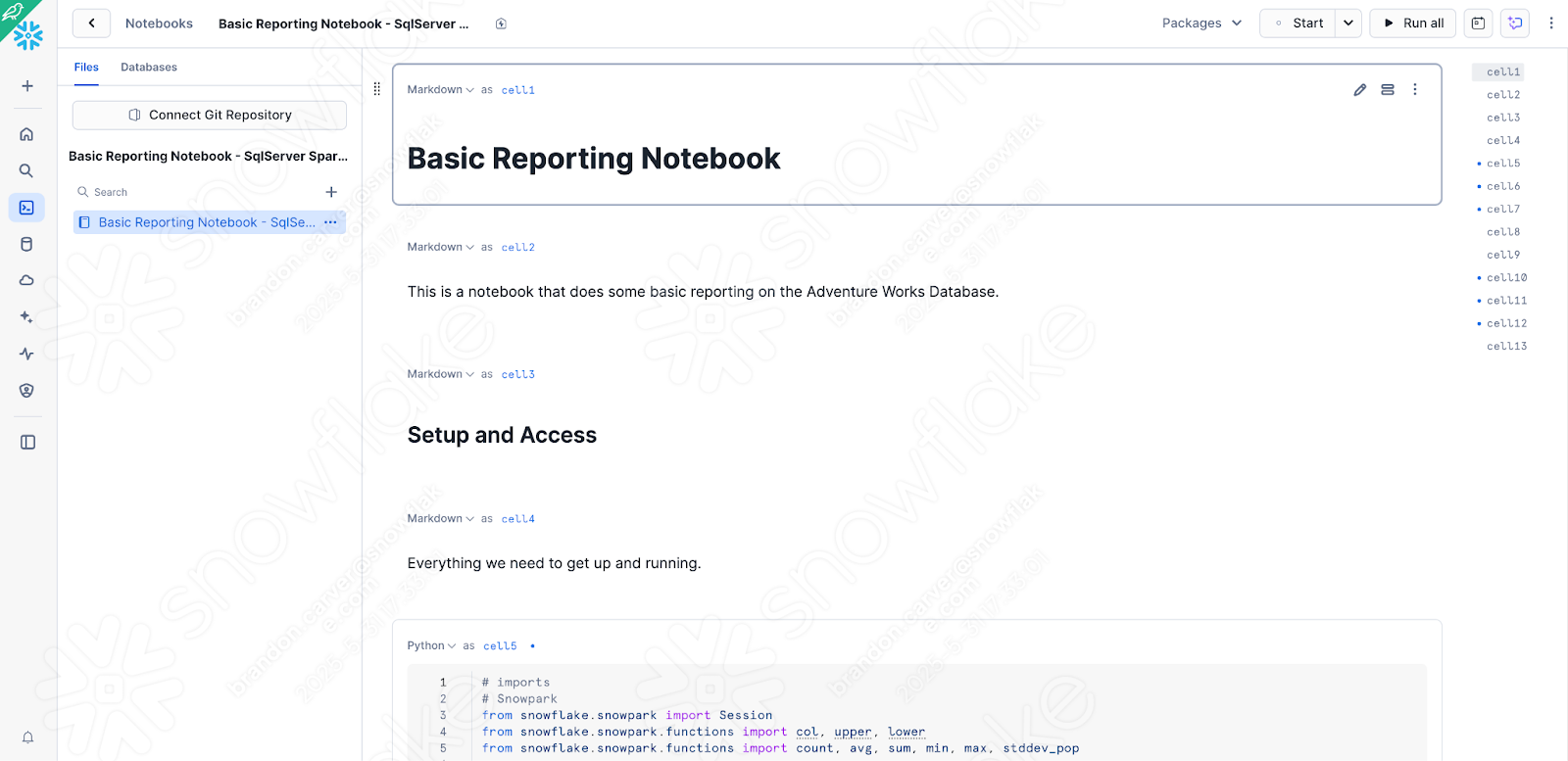
Il y a quelques contrôles/modifications rapides que nous devons apporter à partir de la version que nous venez de tester localement afin de nous assurer que le notebook fonctionne dans Snowsight :
Modifier les appels de session pour récupérer la session active
Assurez-vous que les bibliothèques dépendantes que nous devons installer sont disponibles
Let’s start with the first one. It may seem odd to alter the session call again after we spent so much time on it in the first place, but we’re running inside of Snowflake now. You can remove anything associated with reading the session call and replacing it with the “get_active_session” call that is standard at the top of most Snowflake notebooks:
Nous n’avons pas besoin de spécifier des paramètres de connexion ou de mettre à jour un fichier .toml car nous sommes déjà connectés et nous sommes dans Snowflake.
Remplaçons l’ancien code de la cellule par le nouveau code. Cela ressemblera à ceci :
Occupons-nous maintenant des paquets disponibles pour cette exécution, mais au lieu de déterminer ce que nous devons ajouter, laissons Snowflake le faire. L’une des meilleures parties de l’utilisation d’un notebook est que nous pouvons exécuter des cellules individuelles et voir ce que sont les résultats. Exécutons notre cellule de bibliothèque d’importation.
Si vous ne l’avez pas encore fait, démarrez la session en cliquant dans le coin supérieur droit de l’écran sur « Démarrer » :
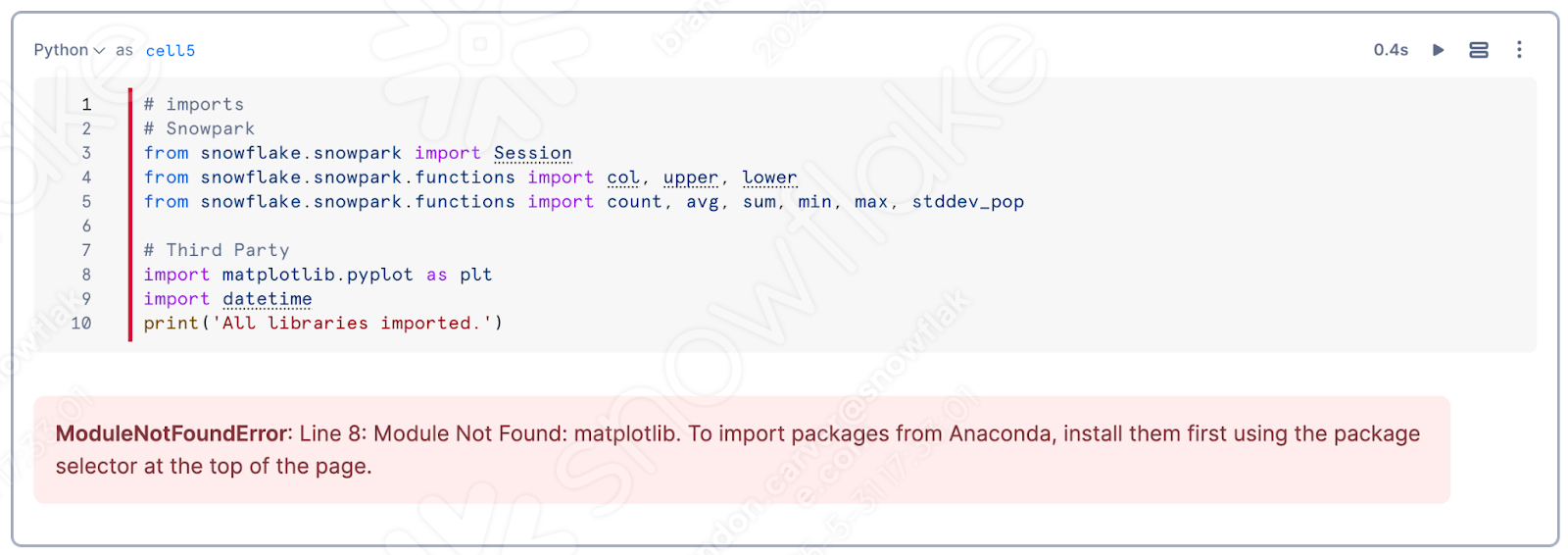
Si vous exécutez la cellule la plus élevée du notebook, vous découvrirez probablement que matplotlib n’est pas chargé dans la session :
C’est un point assez important pour ce notebook. Vous pouvez ajouter cette bibliothèque à votre notebook/session en utilisant l’option « Paquets » en haut à droite du notebook :
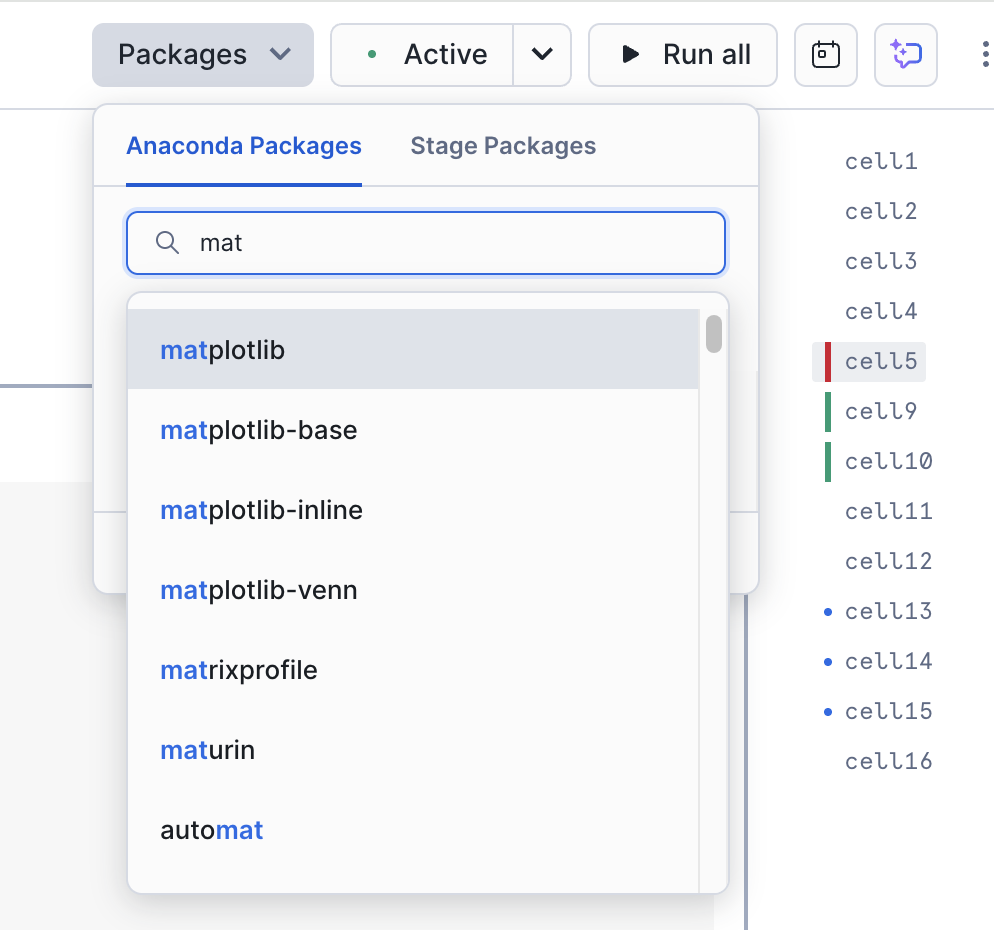
Recherchez matplotlib et sélectionnez-le. Ce paquet sera alors disponible dans la session.
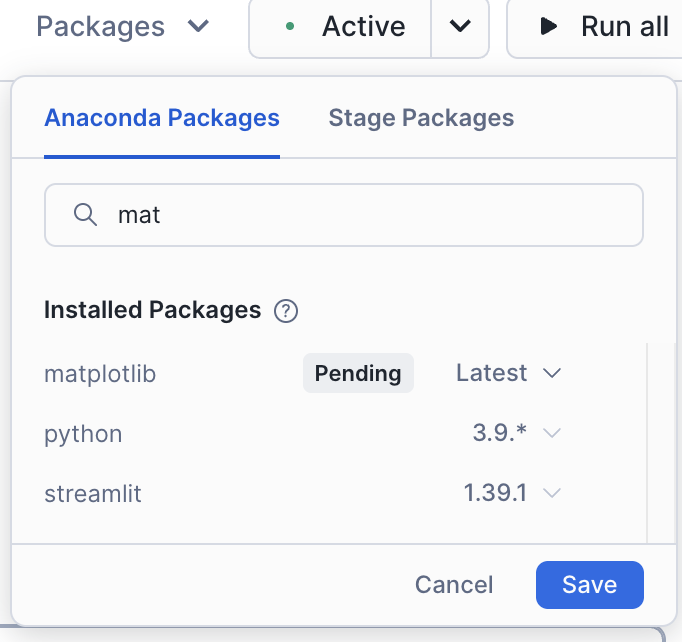
Une fois que vous avez chargé cette bibliothèque, vous devrez redémarrer la session. Une fois que vous avez redémarré la session, exécutez à nouveau cette première cellule. Vous recevrez certainement un message disant que l’opération a réussi cette fois-ci.

Une fois les paquets chargés, la session réparée et le reste des problèmes dans le code déjà résolus, que pouvons-nous faire pour vérifier le reste du notebook ? L’exécuter ! Vous pouvez exécuter toutes les cellules du notebook en sélectionnant « Exécuter tout » dans le coin supérieur droit de l’écran, et voir si nous obtenons des erreurs.
Il semble que l’exécution a réussi :
Si vous comparez l’exécution des deux notebooks, la seule différence est que la version de Snowflake place tous les ensembles de données de sortie en premier suivis des images, alors qu’ils sont mélangés dans le notebook Spark Jupyter :
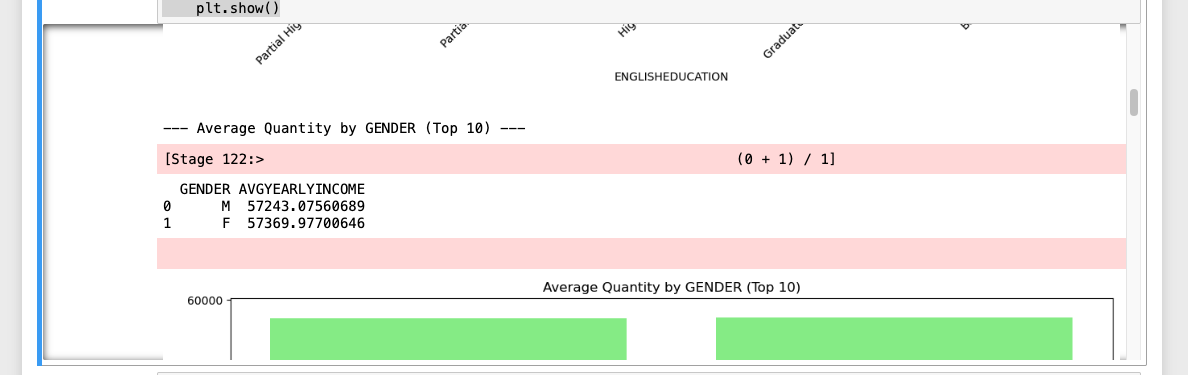
Notez que cette différence n’est pas une différence d’API, mais plutôt une différence dans la façon dont les notebooks dans Snowflake orchestrent tout ceci. Il s’agit probablement d’une différence qu’AdventureWorks est prêt à accepter !
Conclusions¶
En utilisant SMA, nous avons pu accélérer la migration à la fois d’un pipeline de données et d’un notebook de rapports. Plus vous en avez, plus un outil comme SMA peut fournir de la valeur.
Et revenons au flux d’évaluation -> conversion -> validation auquel nous revenons toujours. Dans cette migration, nous avons :
Configuré le projet dans SMA
Exécuté le moteur d’évaluation et de conversion de SMA sur les fichiers de code
Examiné les rapports de sortie de SMA pour mieux comprendre ce que nous avons
Vérifié ce qui n’a pas pu être converti par SMA dans VS Code
Résolu les problèmes et les erreurs
Résolu les références de session
Résolu les références aux entrées/sorties
Exécuté le code localement
Et exécuté le code dans Snowflake
Exécuté les scripts qui venaient d’être migrés et validé leur réussite
Snowflake a consacré beaucoup de temps à améliorer ses capacités d’ingestion et d’ingénierie des données, tout comme il a consacré du temps à améliorer les outils de migration tels que SnowConvert, l’Assistant de migration SnowConvert et Snowpark Migration Accelerator. Chacun de ces éléments continuera à s’améliorer. N’hésitez pas à contacter Snowflake si vous avez des suggestions concernant les outils de migration. Les équipes Snowflake sont toujours à la recherche de commentaires supplémentaires pour améliorer les outils.