Snowpark Migration Accelerator:ノートブック変換¶
コードベースのレポートノートブックに移動してみましょう:**基本レポートノートブック-SqlServer Spark.ipynb**パイプラインスクリプトと同じようなステップを踏んでいきます。
すべての問題の解決:ここでの「問題」とは、SMAによって発生した問題を意味します。出力コードを見てみましょう。解析エラーや変換エラーを解決し、警告を調査します。
セッションコールの解決:セッションコールをどのように出力コードに書くかは、ファイルを実行する場所によって異なります。コードファイルを元々実行しようとしていたのと同じ場所で実行し、その後Snowflakeで実行することで、この問題を解決します。
入出力の解決:異なるソースへの接続は、SMAで完全に解決することはできません。プラットフォームには違いがあり、SMAは通常それらを無視します。これは、ファイルを実行する場所にも影響されます。
クリーンアップとテスト:コードを実行してみます。うまくいくかどうか見てみましょう。このラボではスモークテストを行いますが、Snowpark Python Checkpointsなど、より広範なテストやデータ検証を行うツールもあります。
はじめましょう。
すべての問題の解決¶
では、ノートブックに書かれている問題を見てみましょう。
(ノートブックはVS Codeで開くことができますが、適切に表示するには、VS Code用のJupyter拡張機能をインストールすることをお勧めします。あるいは、Jupyterで開くこともできますが、Snowflakeは、Snowflake拡張機能がインストールされた VS Codeを推奨しています)
パイプラインファイルの場合と同様に、比較機能を使用してこれら2つを並べて表示できますが、その場合、jsonに似た形式になります。
このノートブックには、EWI が2つだけあるというわけではありません。検索バーに戻れば見つけることができるが、これはとても短いので、下にスクロールすることもできます。固有の問題は次のとおりです。
SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.jdbc is not supported. This is a similar issue to the one we saw in the pipeline file, but that was a write call. This is a read call to the SQL Server database. We will resolve this in a bit.
SPRKPY1068 => "pyspark.sql.dataframe.DataFrame.toPandas is not supported if there are columns of type ArrayType, but it has a workaround. See documentation for more info. This is another warning. If we pass an array to this function in Snowpark, it may not work. Let’s keep an eye on this when we test it.
ノートブックと問題についてはこれで終わりです。解析エラーを解決し、入力/出力を修正する必要があることを認識しました。また、注意する必要がある潜在的な機能上の違いがいくつかあります。次のステップに進み、セッション呼び出しを解決しましょう。
セッション呼び出しの解決¶
レポートノートブックのセッション呼び出しを更新するには、セッション呼び出しのあるセルを見つける必要があります。セルは次のようになります。

では、パイプラインファイルですでにやったことをやってみましょう。
「spark」セッション変数へのすべての参照を「session」に変更します(ノートブック全体に適用されます)
スパークドライバーの構成機能を削除します。
前後は次のようになります。
このセルには他のコードがあることに注意してください。このコード:
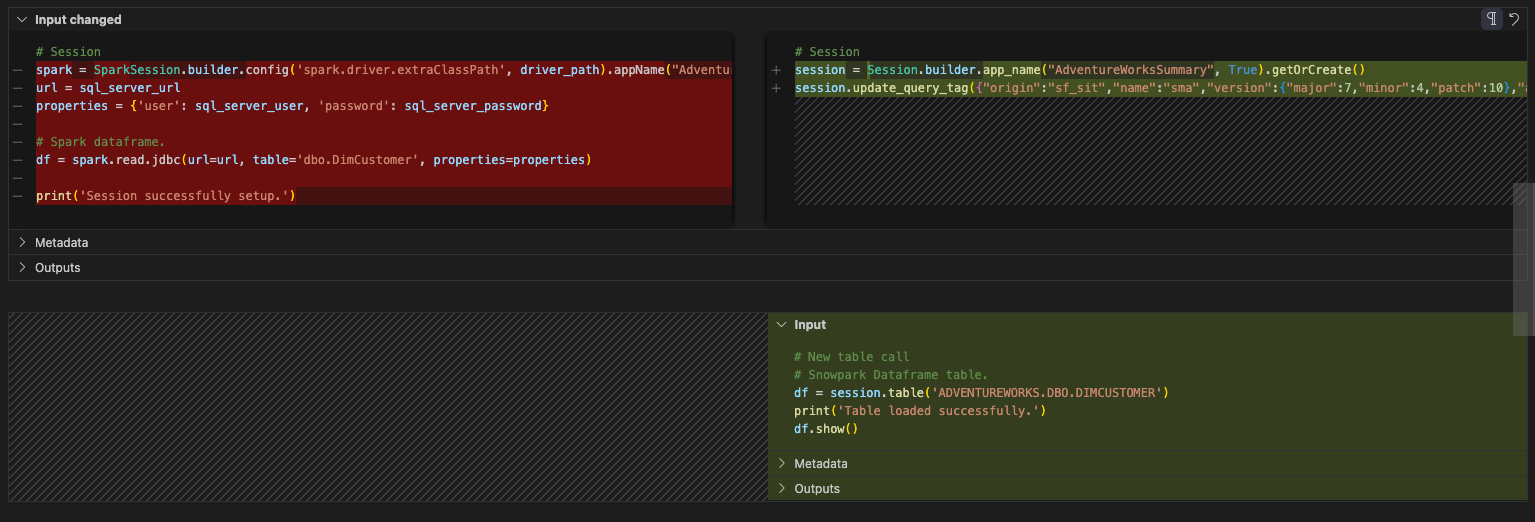
読み取りステートメントを実行する準備はほぼ整いましたが、まだそこまでには至っていません。これをすべて別のセルに移動しましょう。このセルの下に新しいセルを作成し、このコードをそのセルに移動します。このようになります。

Is this all we need for the session call? No. Recall (and possibly review) the previous page under Notes on Session Calls. You will either need to make sure that your connection.toml file has your connection information or you will need to explicitly specify the connection parameters you intend to use in the session.
入出力の解決¶
では、入出力を解決しましょう。これは、ファイルをローカルで実行するか、Snowflakeで実行するかによって異なることに注意してください。ただし、ノートブックに関しては、すべてをローカルでもSnowflakeでも実行できます。セッションを呼び出す必要もないので、コードは少しシンプルになります。アクティブなセッションを取得するだけです。パイプラインファイルと同様に、ローカルで実行/オーケストレーションする部分と、Snowflakeで実行する部分の2つに分けて行います。
レポーティングノートブックでの入出力の作業は、パイプラインのときよりもかなり簡単になります。ここでは、ローカルファイルからの読み込みやファイル間のデータ移動は行われません。単純に、SQL サーバーのテーブルからの読み取りが、Snowflakeのテーブルから読み取られるようになりました。SQL サーバーにはアクセスしないので、SQL サーバープロパティへの参照をすべて削除できます。また、読み取りステートメントはSnowflakeのテーブルステートメントに置き換えることができます。このセルの前後は次のようになります。
以上です。ノートブックファイルのクリーンアップとテストに移りましょう。
クリーンアップとテスト¶
Let’s do some clean up (like we did previously for the pipeline file). We never looked at our import calls and we have config files that are not necessary at all. Let’s start by removing the references to the config files. This will be each of the cells between the import statements and the session call.
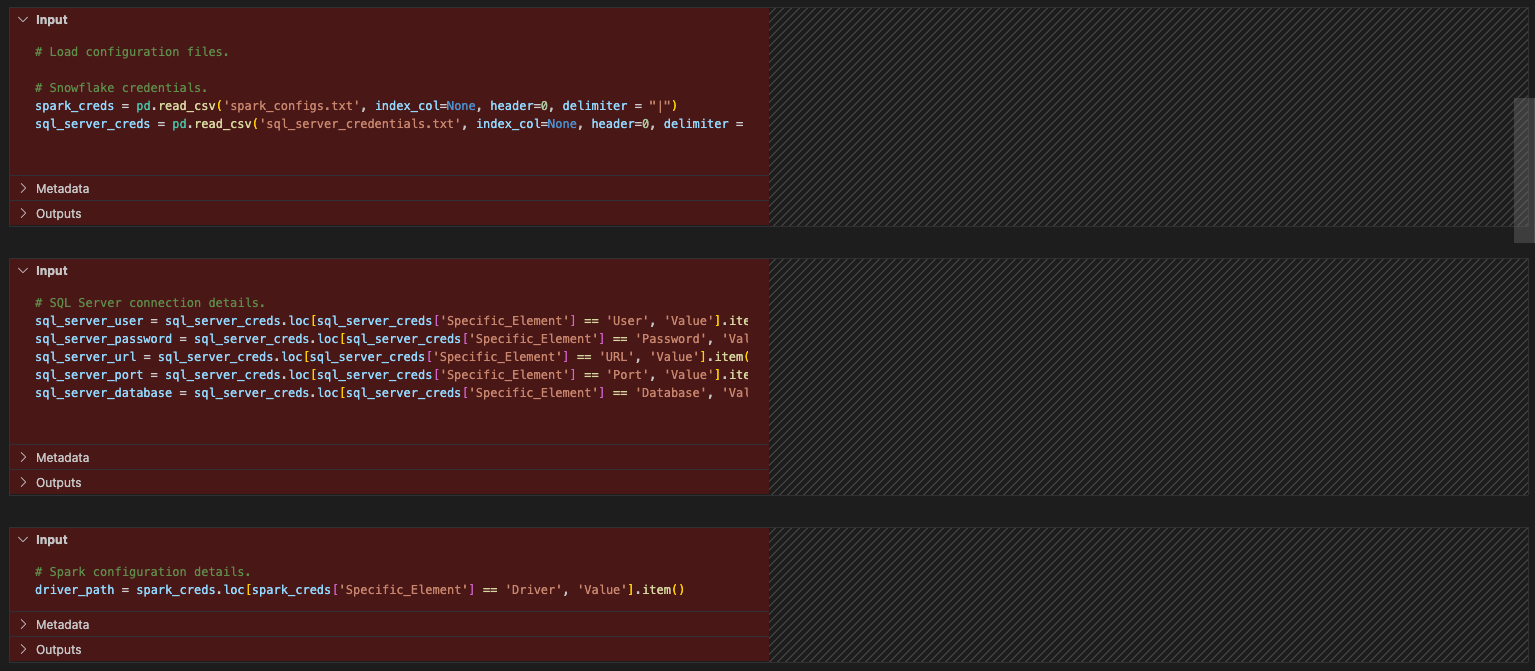
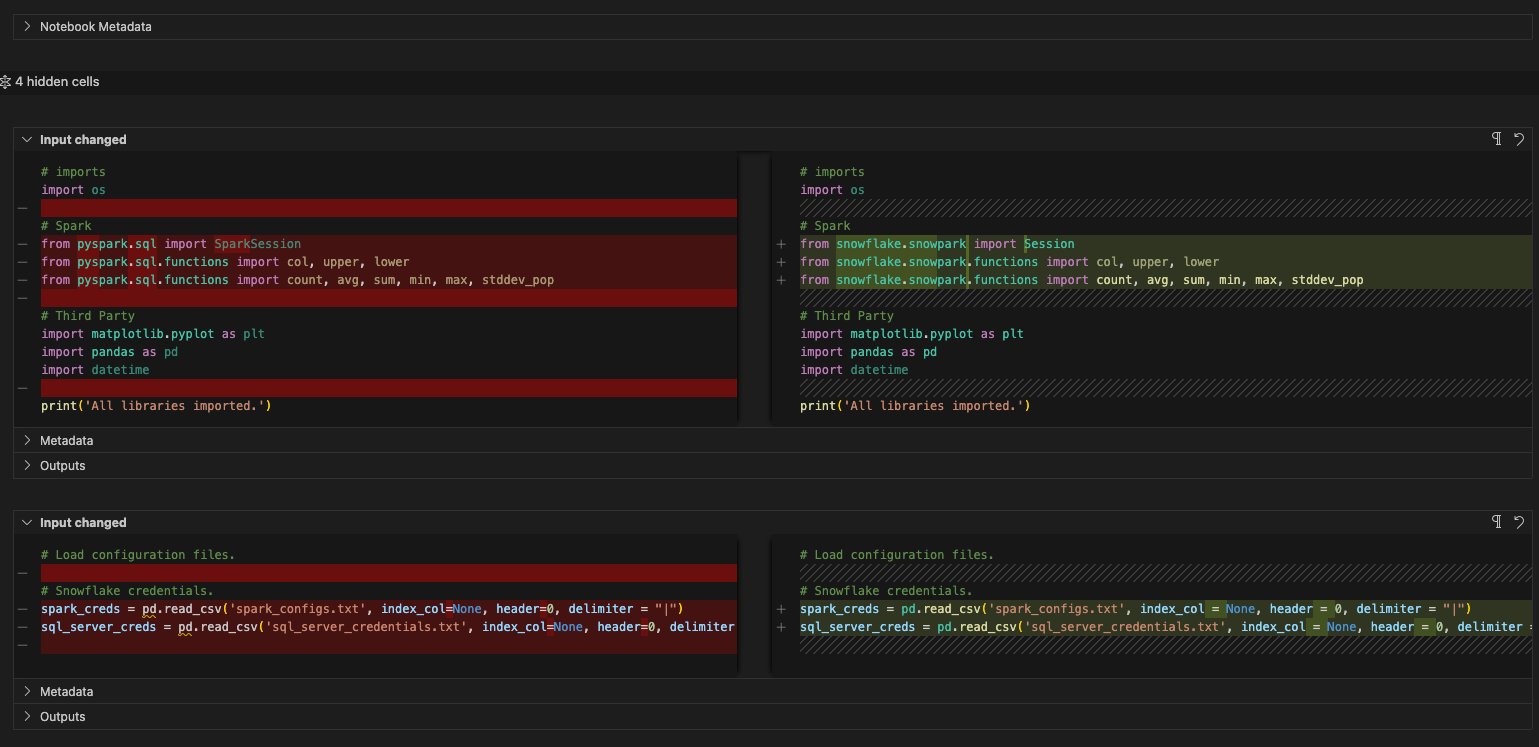
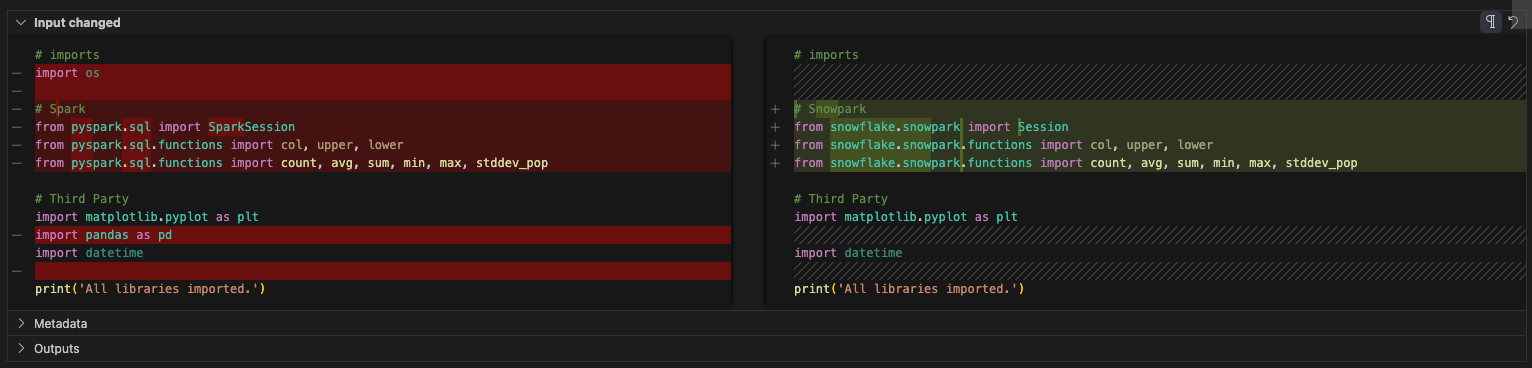
では、インポートを見てみましょう。osへの参照は削除できます。(元のファイルでも使用されていないようですが...)pandasへの参照があります。構成ファイルが参照されるようになったため、このノートブックではpandasが使用されていないようです。レポートセクションのSnowpark dataframe API の一部としてtoPandas参照がありますが、これはpandasライブラリの一部ではありません。
オプションで、pandasへのインポート呼び出しをすべてmodinのpandasライブラリに置き換えることができます。このライブラリは、Snowflakeの強力なコンピューティングを活用するためにpandasのデータフレームを最適化します。この変更は次のようになります。
そうは言っても、これも削除できます。SMA によって、Spark特有のインポートステートメントがすべてSnowparkに関連するものに置き換えられていることに注意してください。最終的なインポートセルは次のようになります。
And that’s it for our cleanup. We still have a couple of EWIs in the reporting and visualization cells, but it looks like we should make it. Let’s run this one and see if we get an output.
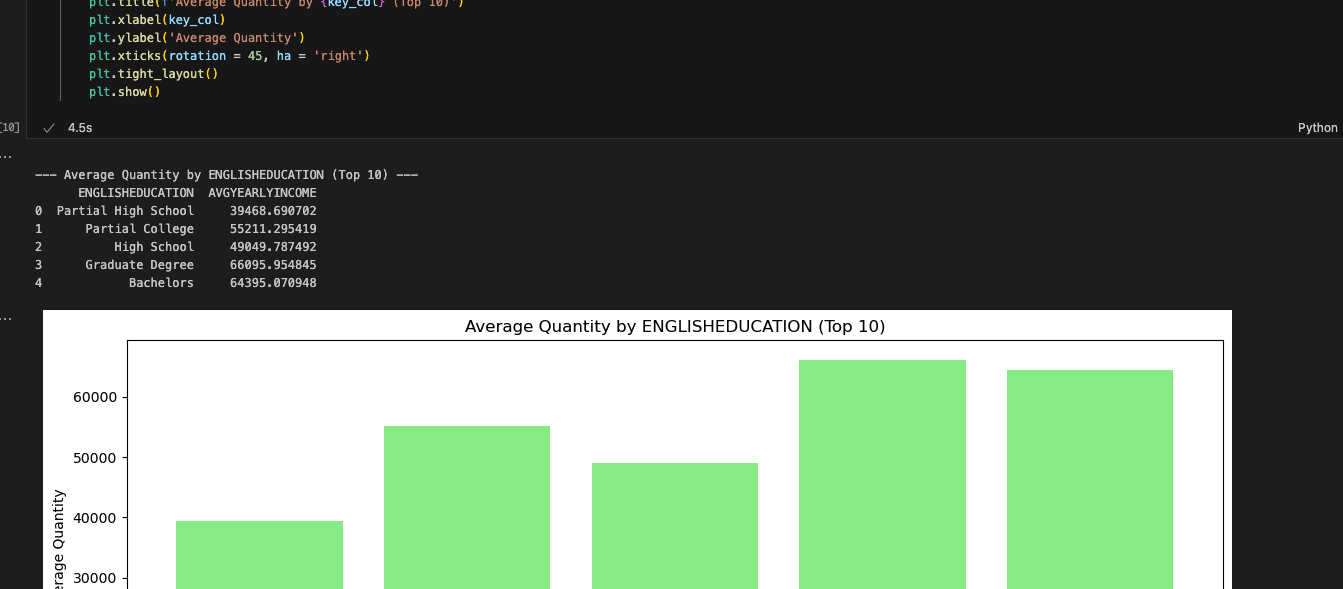
やりました。レポートは、Sparkノートブックが出力したものと一致しているようです。レポートセルが複雑に見えても、Snowparkはそれに対応できます。SMA から問題があるかもしれないと知らされましたが、問題はないようです。より多くのテストが必要ですが、最初のスモークテストは合格しました。
では、このノートブックをSnowsightで見てみよう。パイプラインファイルとは異なり、これはすべてSnowsightで行うことができます。
Snowsightでノートブックを実行する¶
今あるノートブックのバージョン(問題、セッション呼び出し、入出力を処理したもの)をSnowflakeに読み込んでみましょう。これを行うには、SnowSight のノートブックセクションにアクセスします。
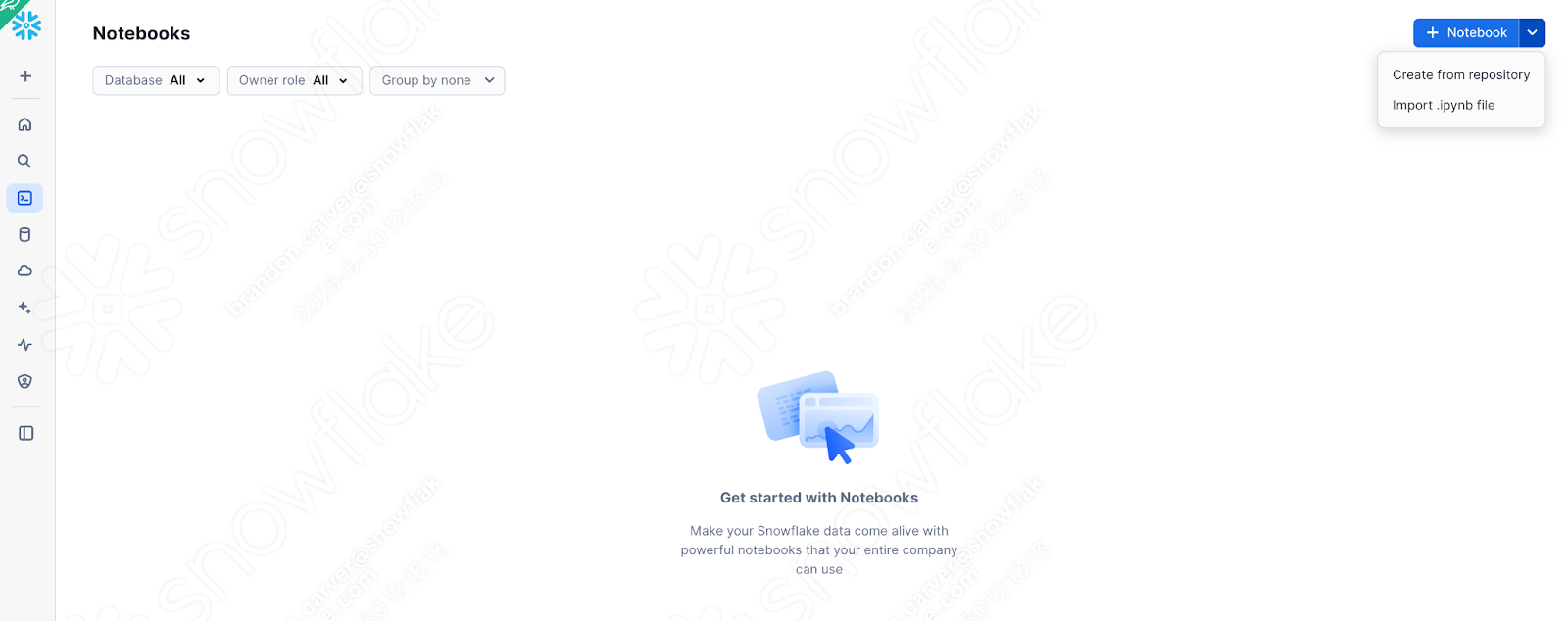
And select down arrow next to the +Notebook button in the top right, and select “Import .ipynb file” (shown above).
これがインポートされたら、プロジェクトフォルダー内の SMA で作成された出力ディレクトリで作業していたノートブックファイルを選択します。
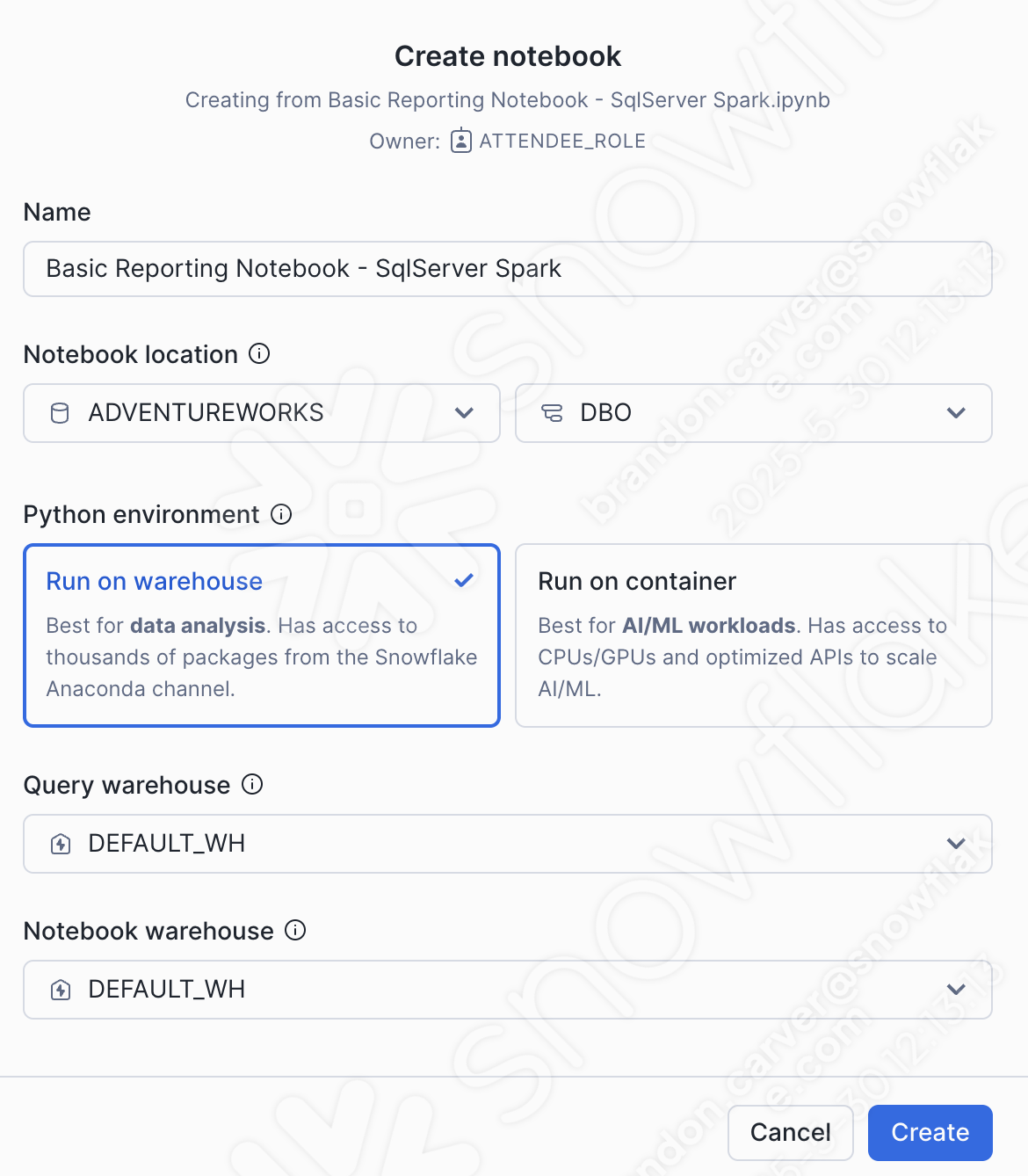
ノートブックの作成ダイアログウィンドウが開きます。今回のアップロードでは、以下のオプションを選択します。
Notebook location:
データベース: ADVENTUREWORKS
スキーマ: DBO
Python環境: ウェアハウスで実行
This is not a large notebook with a bunch of ml. This is a basic reporting notebook. We can run this on a warehouse.
Query warehouse: DEFAULT_WH
Notebook warehouse: DEFAULT_WH (you can leave it as the system chosen warehouse (will be a streamlit warehouse)... for this notebook, it will not matter)
これらのセレクションは下記で見ることができます。
これでノートブックがSnowflakeに読み込まれ、次のように表示されます。
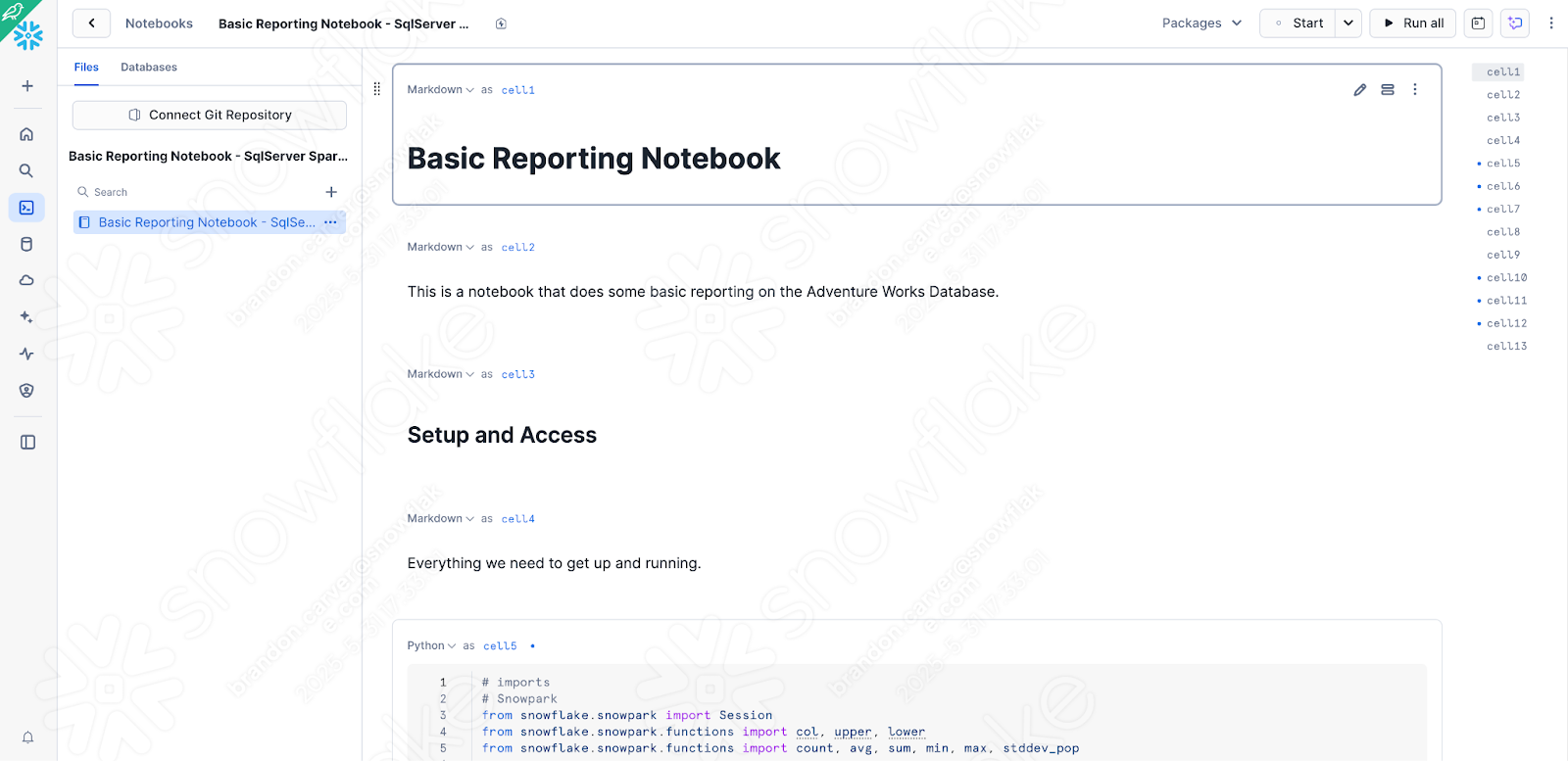
ノートブックがSnowsightで実行されることを確認するために、ローカルでテストしたバージョンからいくつかの簡単なチェックや変更を行う必要があります。
アクティブなセッションを取得するためにセッション呼び出しを変更します
インストールが必要な依存ライブラリが利用可能であることを確認します
Let’s start with the first one. It may seem odd to alter the session call again after we spent so much time on it in the first place, but we’re running inside of Snowflake now. You can remove anything associated with reading the session call and replacing it with the “get_active_session” call that is standard at the top of most Snowflake notebooks:
すでに接続されているので、接続パラメーターを指定したり、.tomlファイルを更新したりする必要はありません。今Snowflake内にいます。
セル内の古いコードを新しいコードに置き換えてみましょう。次のようになります。
ここで、今回の実行で利用可能なパッケージについて説明しましょう。何を追加する必要があるかを考える必要はありません。Snowflakeに任せましょう。ノートブックを使う良い点のひとつは、個々のセルを動かして結果を確認できることです。インポートライブラリのセルを動かしてみましょう。
まだの方は、画面右上の 「開始」と書いてあるところをクリックしてセッションを開始してください。
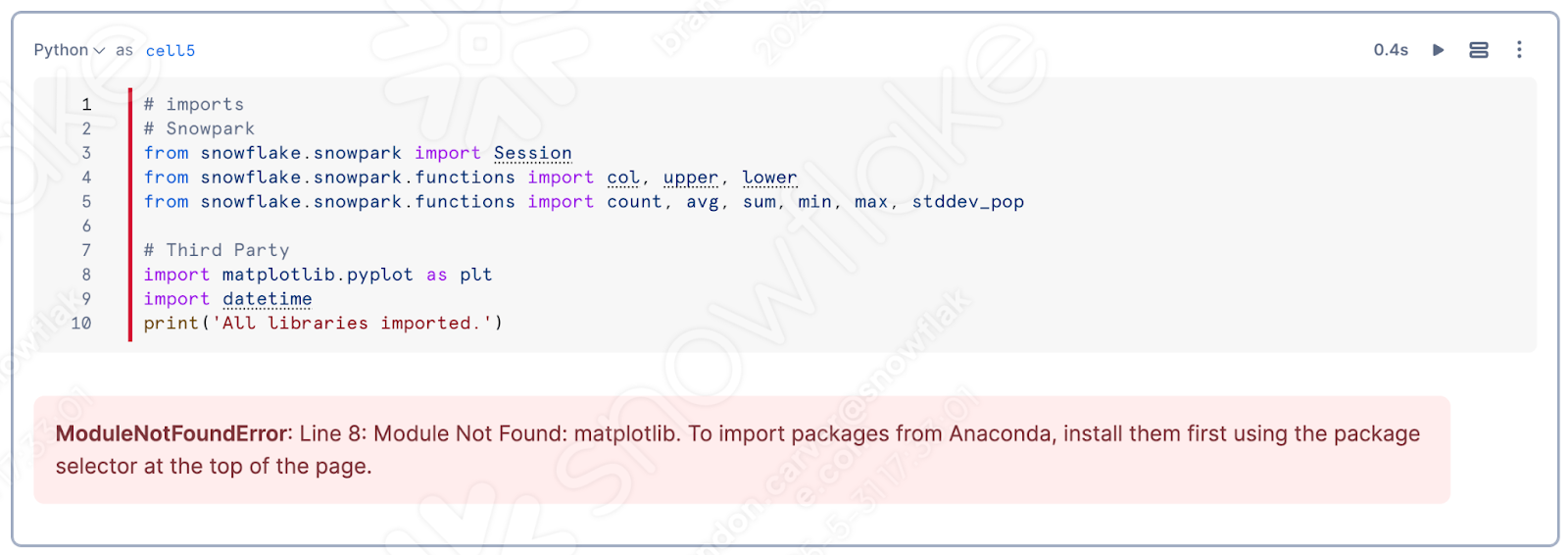
ノートブックの一番上のセルを実行すると、matplotlibがセッションにロードされていないことに気づくはずです。
これはこのノートブックにとってかなり重要なことです。ノートブックの右上にある「パッケージ」オプションを使って、そのライブラリをノートブック/セッションに追加することができます。
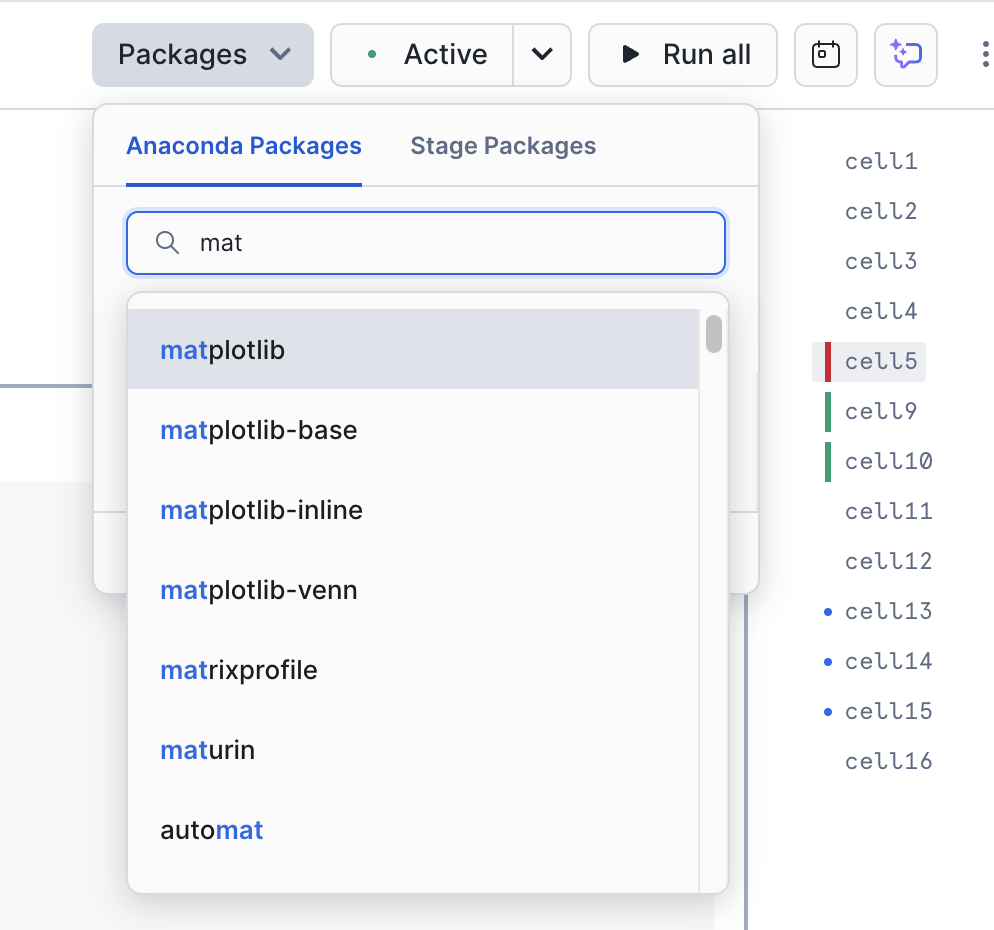
matplotlib を検索して選択します。これで、このパッケージはセッションで使用可能になります。
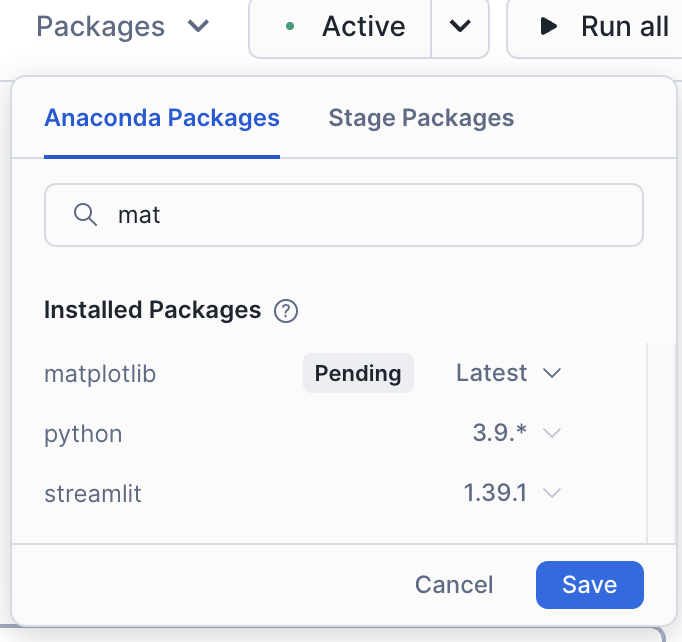
このライブラリをロードしたら、セッションを再開する必要があります。セッションを再開したら、最初のセルをもう一度実行してください。今回は成功したと言われるでしょう。

パッケージがロードされ、セッションが修正され、コード内の残りの問題がすでに解決されているので、ノートブックの残りの部分をチェックするにはどうすればよいでしょうか。では実行してみましょう。画面右上の「Run all」を選択して、ノートブックのすべてのセルを実行し、エラーが出るか確認してみましょう。
どうやら成功したようです。
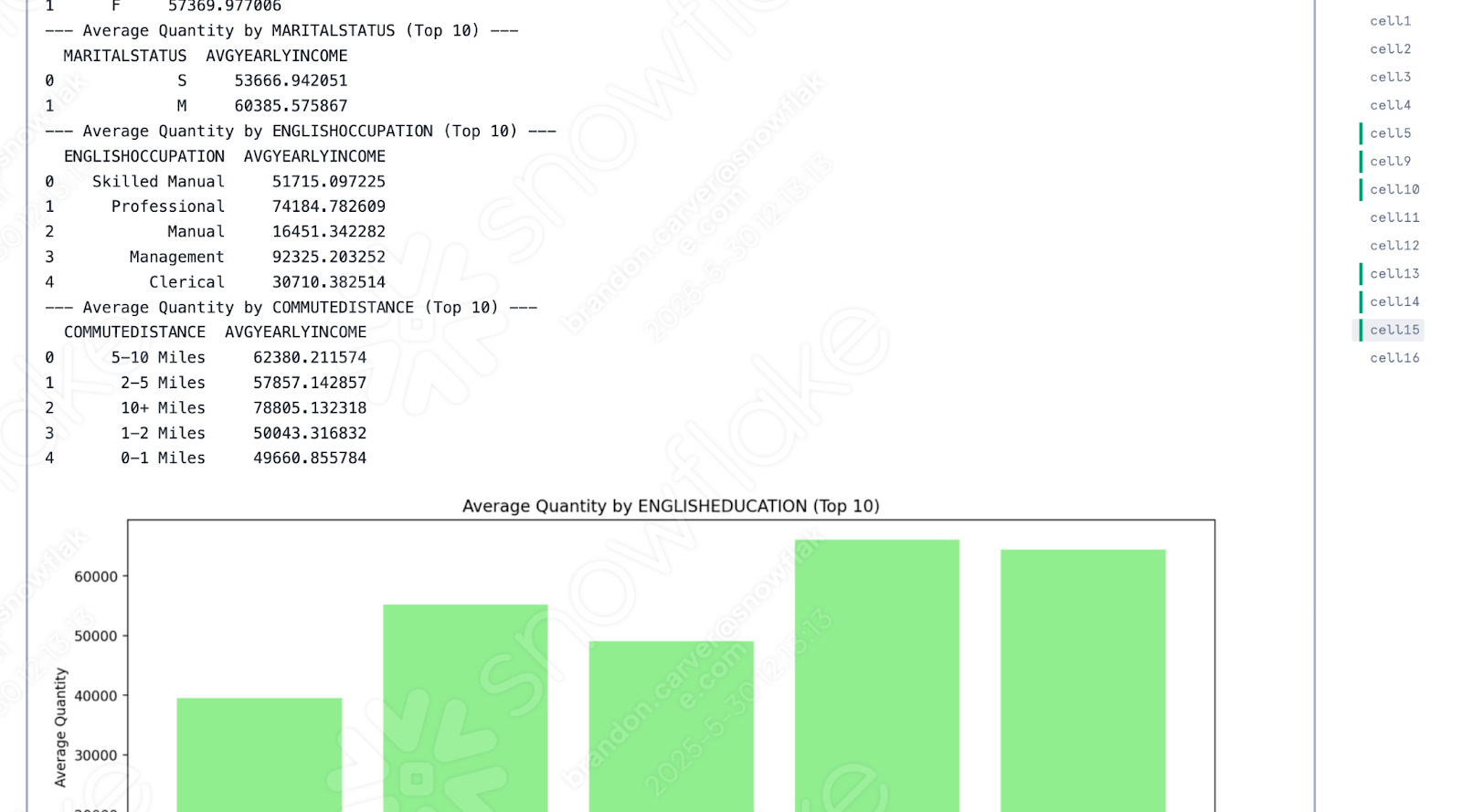
2つのノートブックの実行を比較すると、Snowflakeバージョンではすべての出力データセットが最初に置かれ、その後に画像が続くのに対し、Spark Jupyter Notebookではそれらが混在しているという点だけが異なるように見えます。
この違いは、API の違いではなく、Snowflakeのノートブックがこれをどのようにオーケストレーションするかの違いであることに注意してください。これはおそらく、AdventureWorks が受け入れる違いでしょう。
結論¶
SMA を活用することで、データパイプラインとレポーティングノートブックの両方の移行を加速させることができました。それぞれが多ければ多いほど、SMA のようなツールが提供できる価値は高くなります。
これまで一貫して行ってきた評価 -> 変換 -> 検証のフローに戻りましょう。この移行では、次を行いました。
SMA でプロジェクトをセットアップした
SMA の評価および変換エンジンをコードファイルに対して実行した
SMA からの出力レポートを精査し、何を得たかをよりよく理解した
SMA で変換できなかったものを VS Codeで精査する
問題やエラーを解決する
セッション参照を解決する
入出力参照を解決する
ローカルでコードを実行する
Snowflakeでコードを実行する
新しく移行したスクリプトを実行し、その成功を検証した
Snowflakeは、 SnowConvert 、 SnowConvert 移行アシスタント、Snowpark Migration Acceleratorのような移行ツールの改善に時間を費やしてきたのと同様に、インジェストとデータエンジニアリング機能の改善に多大な時間を費やしてきました。これらはそれぞれ今後も改善され続けるでしょう。移行ツールについてご提案がありましたら、お気軽にご連絡ください。これらのチームは、ツールを改善するための追加のフィードバックを常に求めています。