Snowpark Migration Accelerator: Notebook-Konvertierung¶
Wechseln wir zum Berichts-Notebook in unserer Codebasis: Einfaches Berichts-Notebook – SqlServer Spark.ipynb. Wir werden einen ähnlichen Satz von Schritten durchlaufen wie beim Pipeline-Skript.
Alle Probleme lösen: „Probleme“ bezeichnet hier die Probleme, die durch den SMA erzeugt werden. Werfen Sie einen Blick auf den Ausgabecode. Beheben Sie Parsing-Fehler und Konvertierungsfehler, und untersuchen Sie die Warnungen.
Sitzungsaufrufe auflösen: Wie der Sitzungsaufruf im Ausgabecode geschrieben wird, hängt davon ab, wo die Datei ausgeführt werden soll. Wir werden das Problem lösen, um die Codedateien an dem gleichen Speicherort auszuführen, an dem sie ursprünglich ausgeführt werden sollten, und um sie anschließend in Snowflake auszuführen.
Ein-/Ausgaben auflösen: Verbindungen zu verschiedenen Quellen können nicht vollständig durch den SMA aufgelöst werden. Es gibt Unterschiede zwischen den Plattformen, und der SMA wird dies in der Regel ignorieren. Dies wird auch davon beeinflusst, wo die Datei ausgeführt werden soll.
** Bereinigen und Testen **! Lassen Sie uns den Code ausführen. Überprüfen Sie, ob es funktioniert. Wir werden in diesen praktischen Übungen einfache Tests durchführen, aber es gibt Tools, mit denen Sie umfangreichere Tests und Datenvalidierungen durchführen können, einschließlich Snowpark Python Checkpoints.
Fangen wir an!
Alle Probleme lösen¶
Im Weiteren werden wir uns die Probleme mit dem Notebook ansehen.
(Beachten Sie, dass Sie das Notebook in VS Code öffnen können, aber um es angemessen anzuzeigen, sollten Sie die Jupyter-Erweiterung für VS Code installieren. Alternativ können Sie dieses auch in Jupyter öffnen, aber Snowflake empfiehlt weiterhin VS Code mit installierter Snowflake-Erweiterung).
Sie können das Vergleichs-Feature verwenden, um beide Seite an Seite anzuzeigen, wie wir es mit der Pipeline-Datei getan haben, obwohl sie dann eher wie eine JSON-Datei aussieht:
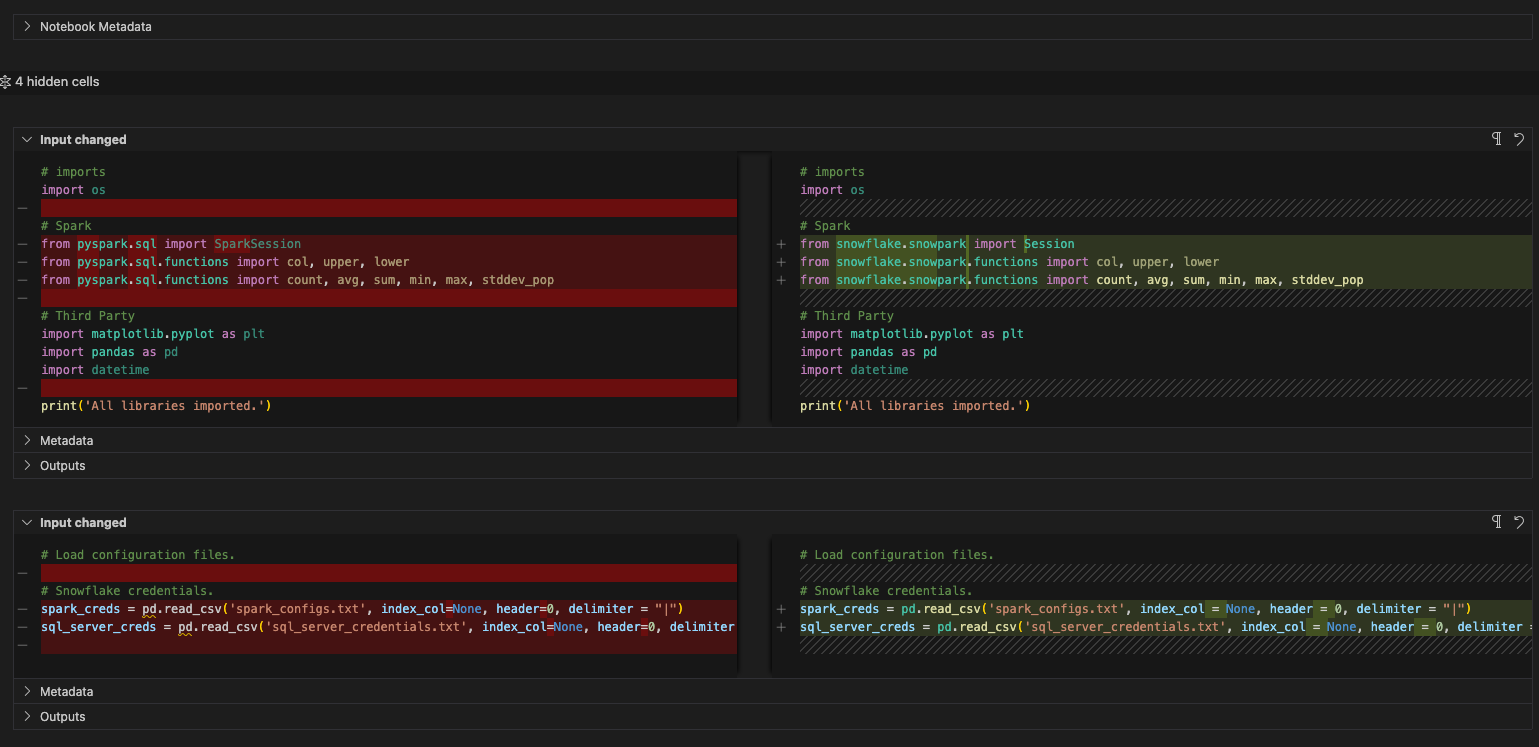
Beachten Sie, dass es nur zwei eindeutige EWIs in diesem Notebook gibt. Sie können zur Suchleiste zurückkehren, um sie zu finden, aber da dies so kurz ist, können Sie auch einfach nach unten scrollen. Dies sind die spezifischen Probleme:
SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.jdbc is not supported. This is a similar issue to the one we saw in the pipeline file, but that was a write call. This is a read call to the SQL Server database. We will resolve this in a bit.
SPRKPY1068 => „pyspark.sql.dataframe.DataFrame.toPandas is not supported if there are columns of type ArrayType, but it has a workaround. See documentation for more info. This is another warning. If we pass an array to this function in Snowpark, it may not work. Let’s keep an eye on this when we test it.
Und das war’s für das Notebook und unsere Probleme. Wir haben einen Parsing-Fehler behoben und erkannt, dass wir die Ein-/Ausgaben korrigieren müssen. Weiterhin gibt es ein paar potenzielle Funktionsunterschiede, die wir im Blick behalten sollten. Lassen Sie uns zum nächsten Schritt übergehen: dem Auflösen aller Sitzungsaufrufe.
Sitzungsaufrufe auflösen¶
Um die Sitzungsaufrufe im Berichts-Notebook zu aktualisieren, müssen wir die Zelle suchen, die den Sitzungsaufruf enthält. Das sieht wie folgt aus:

Lassen Sie uns nun das tun, was wir bereits für unsere Pipeline-Datei getan haben:
Ändern Sie alle Verweise auf die Sitzungsvariable „spark“ in „session“ (beachten Sie, dass dies im gesamten Notebook der Fall ist).
Entfernen Sie die Konfigurationsfunktion mit dem Spark-Treiber.
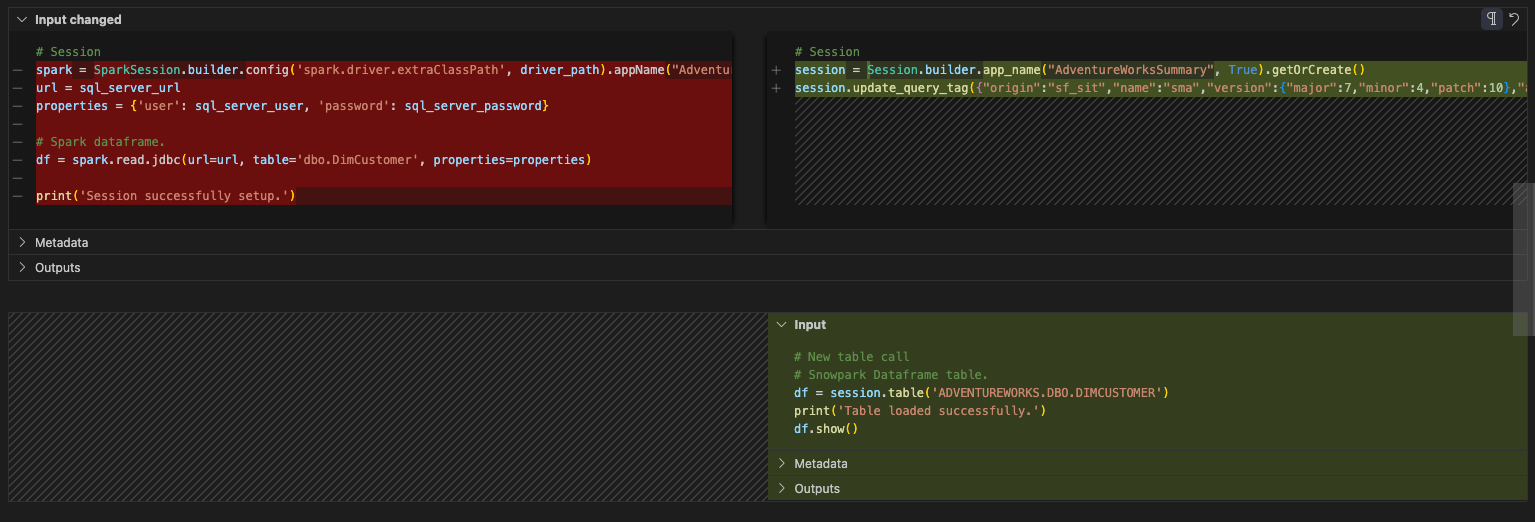
Das Vorher und Nachher sieht wie folgt aus:
Beachten Sie, dass sich in dieser Zelle anderer Code befindet. Dieser Code:
Wir sind fast bereit, die Anweisung zum Lesen zu übernehmen, aber wir sind noch nicht dort. Lassen Sie uns das alles in eine andere Zelle verschieben. Erstellen Sie eine neue Zelle unterhalb dieser Zelle, und verschieben Sie diesen Code in diese Zelle. Diese wird wie folgt aussehen:

Is this all we need for the session call? No. Recall (and possibly review) the previous page under Notes on Session Calls. You will either need to make sure that your connection.toml file has your connection information or you will need to explicitly specify the connection parameters you intend to use in the session.
Auflösen der Eingaben/Ausgaben¶
Lassen Sie uns nun unsere Ein- und Ausgaben auflösen. Beachten Sie, dass dies je nachdem, ob Sie die Dateien lokal oder in Snowflake ausführen, unterschiedlich ist. Beim Notebook kann jedoch alles lokal oder in Snowflake ausgeführt werden. Der Code wird etwas einfacher sein, da wir nicht einmal eine Sitzung aufrufen müssen. Wir erhalten nur die aktive Sitzung. Wie bei der Pipeline-Datei werden wir dies in zwei Teilen tun: für die lokale Ausführung/Orchestrierung und für die Ausführung in Snowflake.
Die Bearbeitung der Ein- und Ausgaben im Berichts-Notebook wird wesentlich einfacher sein als dies bei der Pipeline war. Es erfolgt kein Lesen aus einer lokalen Datei oder Verschieben von Daten zwischen Dateien. Es wird einfach aus einer Tabelle in SQL Server gelesen, was nun ein Lesevorgang aus einer Tabelle in Snowflake ist. Da wir nicht auf SQL Server zugreifen werden, können wir alle Verweise auf die Eigenschaften von SQL Server weglassen. Die Leseanweisung kann in Snowflake durch eine Tabellenanweisung ersetzt werden. Das Vorher und Nachher für diese Zelle sollte wie folgt aussehen:
Das ist es tatsächlich. Im Weiteren werden wir mit dem Teil „ Bereinigen und Testen“ der Notebook-Datei fortfahren.
Bereinigen und Testen¶
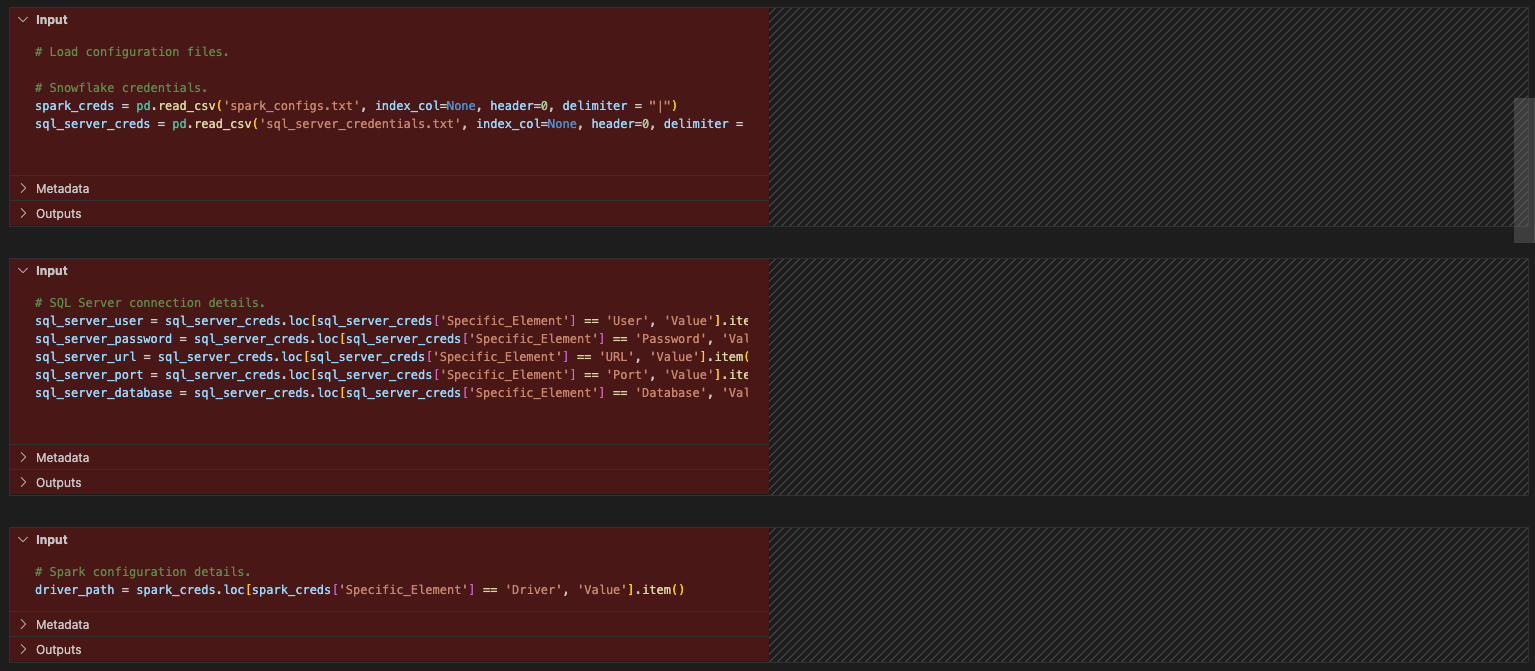
Let’s do some clean up (like we did previously for the pipeline file). We never looked at our import calls and we have config files that are not necessary at all. Let’s start by removing the references to the config files. This will be each of the cells between the import statements and the session call.
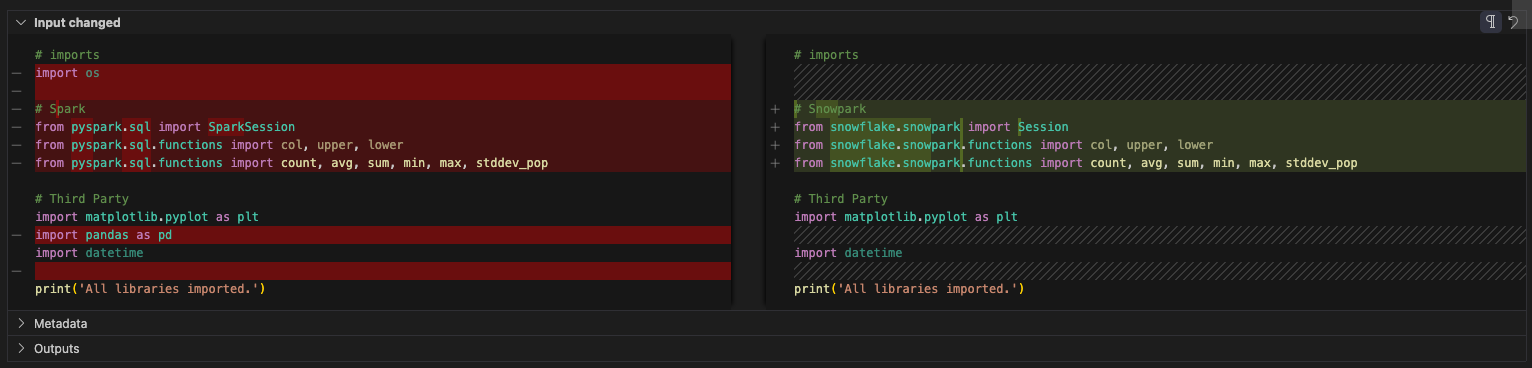
Schauen wir uns nun unsere Importe an. Der Verweis auf das BS kann gelöscht werden. (Scheint so, als wurde dies auch nicht in der Originaldatei verwendet …) Es gibt eine pandas-Referenz. Es scheint, dass es in diesem Notebook keine Verwendung von pandas mehr gibt, da auf die Konfigurationsdateien verwiesen wird. Es gibt eine toPandas-Referenz als Teil der Snowpark-Datenframe-API im Berichtsbereich, aber das ist nicht Bestandteil der pandas-Bibliothek.
Sie können optional alle Importaufrufe von Pandas durch die modin pandas-Bibliothek ersetzen. Diese Bibliothek optimiert die pandas-Datenframes, um die Vorteile des Powerhouse Computing von Snowflake zu nutzen. Diese Änderung würde wie folgt aussehen:
Allerdings können wir diese auch löschen. Beachten Sie, dass der SMA alle Spark-spezifischen Importanweisungen durch solche ersetzt hat, die sich auf Snowpark beziehen. Die endgültige Importzelle würde wie folgt aussehen:
And that’s it for our cleanup. We still have a couple of EWIs in the reporting and visualization cells, but it looks like we should make it. Let’s run this one and see if we get an output.
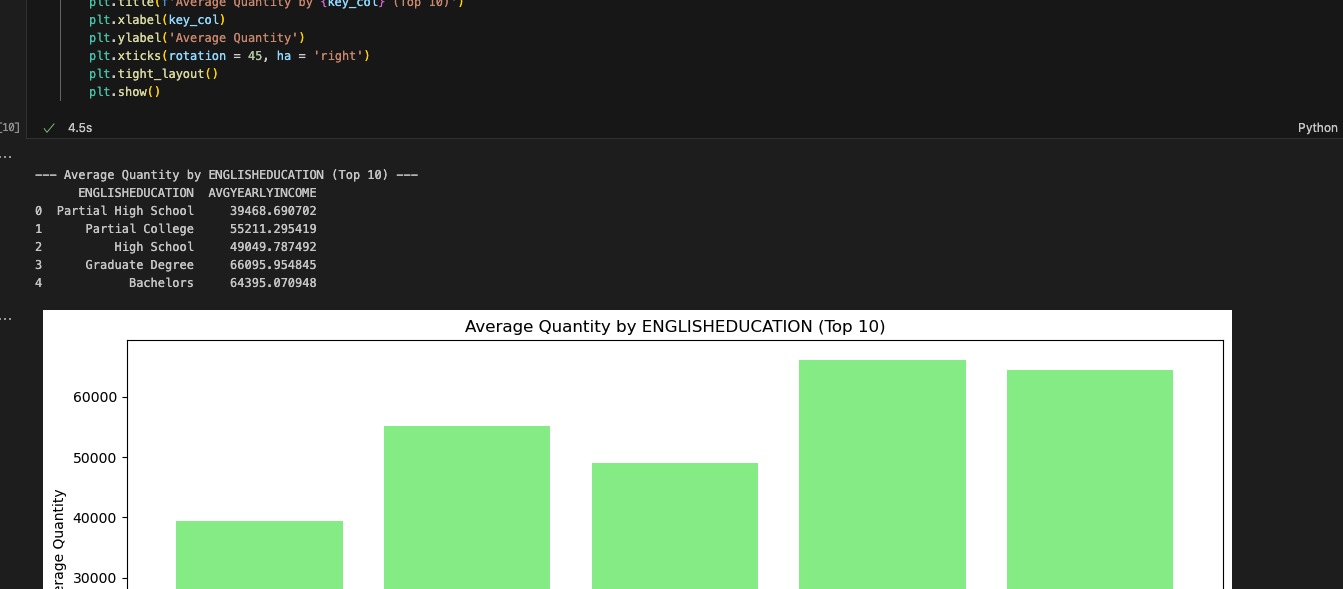
Und das haben wir getan. Die Berichte scheinen mit der Ausgabe des Spark Notebooks übereinzustimmen. Auch wenn die Berichtszellen komplex erscheinen, kann Snowpark mit ihnen arbeiten. Der SMA teilt uns mit, dass es ein Problem geben könnte, aber es scheint keine Probleme zu geben. Weitere Tests würden helfen, aber die erste Runde der einfachen Tests ist bestanden.
Schauen wir uns nun dieses Notebook in Snowsight an. Im Gegensatz zur Pipeline-Datei können wir dies vollständig in Snowsight tun.
Ausführen des Notebooks in Snowsight¶
Nehmen wir die Version des Notebooks, die wir gerade haben (nachdem wir die Probleme, die Sitzungsaufrufe und die Ein- und Ausgaben gelöst haben) und laden sie in Snowflake. Um dies zu tun, gehen Sie in SnowSight zum Abschnitt „Notebooks“:
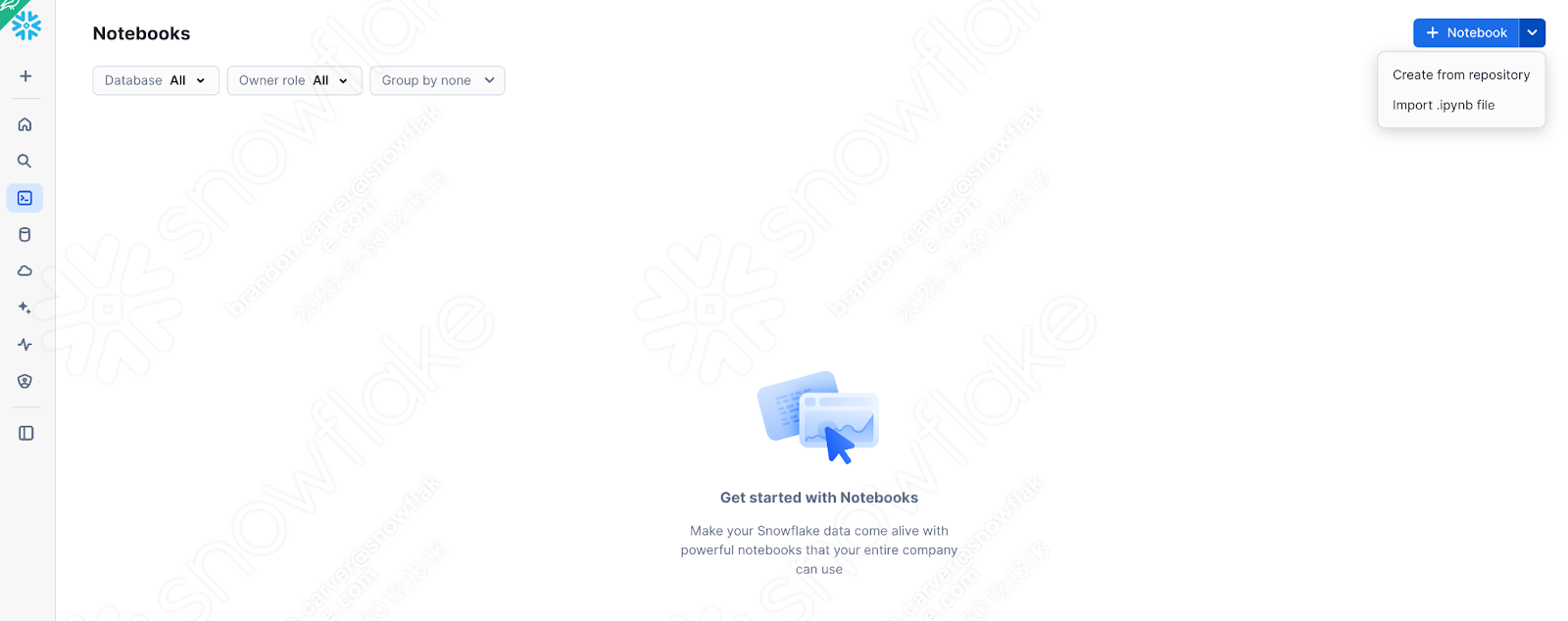
And select down arrow next to the +Notebook button in the top right, and select “Import .ipynb file” (shown above).
Sobald diese importiert wurde, wählen Sie die Notebook-Datei aus, mit der wir in dem Ausgabeverzeichnis arbeiteten, das vom SMA in Ihrem Projektordner erstellt wurde.
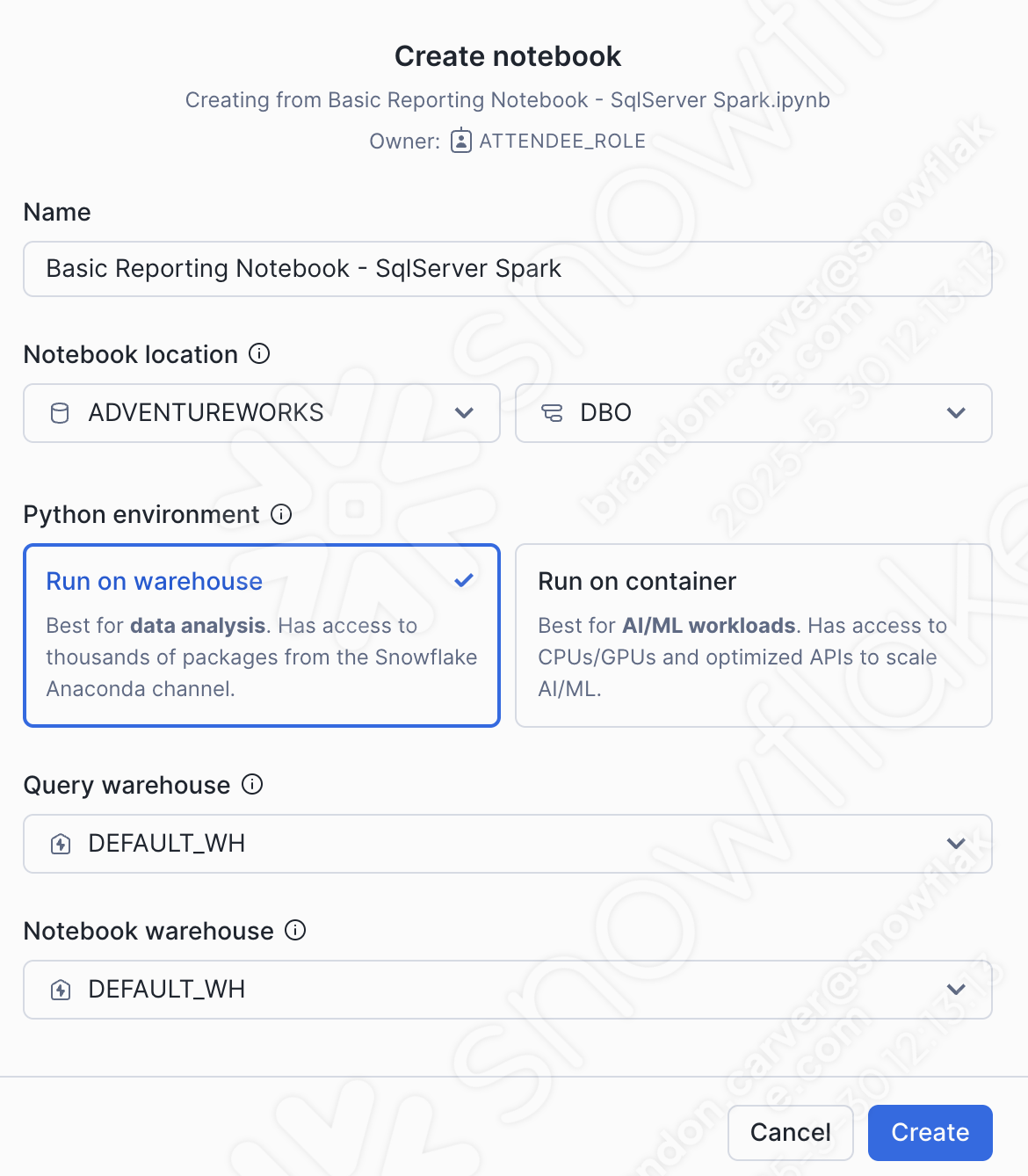
Es öffnet sich ein Dialogfenster zum Erstellen eines Notebooks. Für diesen Upload wählen wir die folgenden Optionen:
Notebook location:
Datenbank: ADVENTUREWORKS
Schema: DBO
Python-Umgebung: Auf Warehouse ausführen
This is not a large notebook with a bunch of ml. This is a basic reporting notebook. We can run this on a warehouse.
Query warehouse: DEFAULT_WH
Notebook warehouse: DEFAULT_WH (you can leave it as the system chosen warehouse (will be a streamlit warehouse)… for this notebook, it will not matter)
Sie können diese Auswahl unten sehen:
Dadurch sollte Ihr Notebook in Snowflake geladen werden und ungefähr so aussehen:
Es gibt ein paar schnelle Überprüfungen/Änderungen, die wir an der Version vornehmen müssen, die wir gerade lokal getestet haben, um sicherzustellen, dass das Notebook in Snowsight läuft:
Ändern der Sitzungsaufrufe, um die aktive Sitzung abzurufen
Sicherstellen dass alle abhängigen Bibliotheken, die wir installieren müssen, verfügbar sind
Let’s start with the first one. It may seem odd to alter the session call again after we spent so much time on it in the first place, but we’re running inside of Snowflake now. You can remove anything associated with reading the session call and replacing it with the “get_active_session” call that is standard at the top of most Snowflake notebooks:
Wir müssen keine Verbindungsparameter angeben oder eine .toml-Datei aktualisieren, da wir bereits verbunden sind. Wir befinden uns in Snowflake.
Lassen Sie uns den alten Code in der Zelle durch den neuen Code ersetzen. Das sieht ungefähr so aus:
Lassen Sie uns nun die für diese Ausführung verfügbaren Pakete verwenden. Es liegt aber nicht an uns herauszufinden, was wir hinzufügen müssen. Das überlassen wir Snowflake. Einer der besten Aspekte der Verwendung eines Notebooks ist, dass wir einzelne Zellen ausführen und sehen können, wie die Ergebnisse aussehen. Lassen Sie uns die Zelle für die Importbibliothek ausführen.
Wenn Sie dies noch nicht getan haben, starten Sie die Sitzung, indem Sie in der rechten oberen Ecke des Bildschirms auf „Start“ klicken:
Wenn Sie die oberste Zelle im Notebook ausführen, werden Sie wahrscheinlich feststellen, dass „matplotlib“ nicht in die Sitzung geladen wurde:
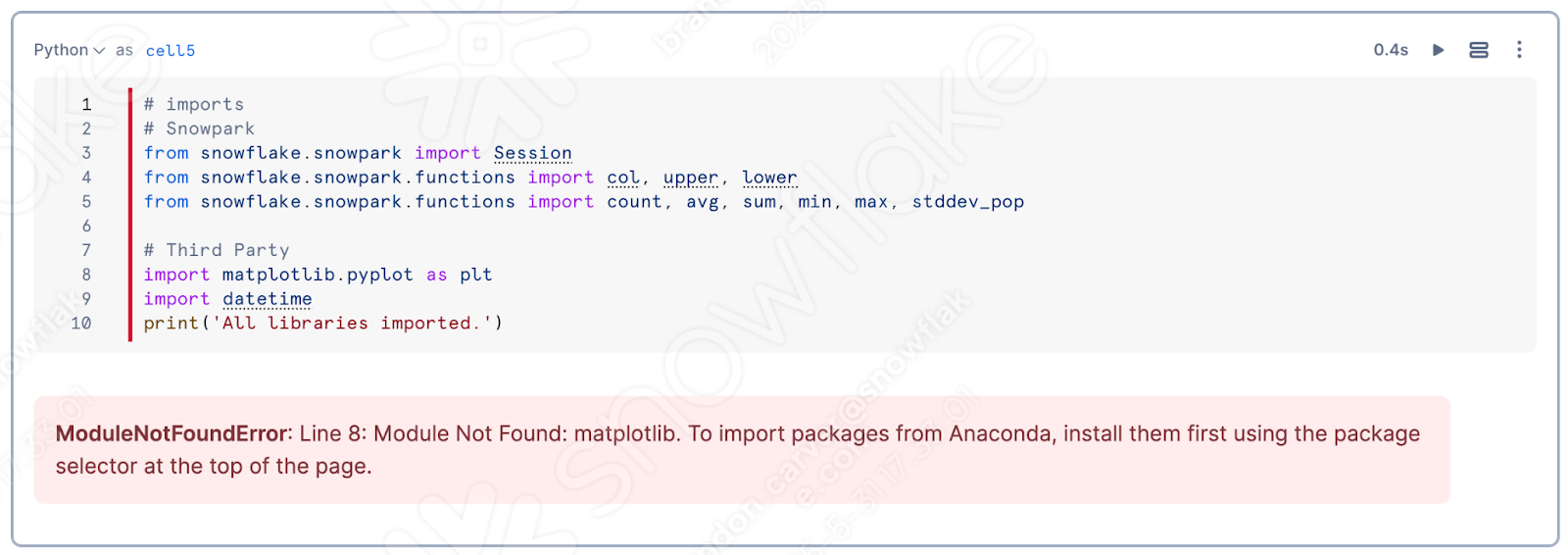
Dies ist eine sehr wichtige Meldung für dieses Notebook. Sie können diese Bibliothek zu Ihrem Notebook/Ihrer Sitzung hinzufügen, indem Sie die Option „Pakete“ oben rechts im Notebook verwenden:
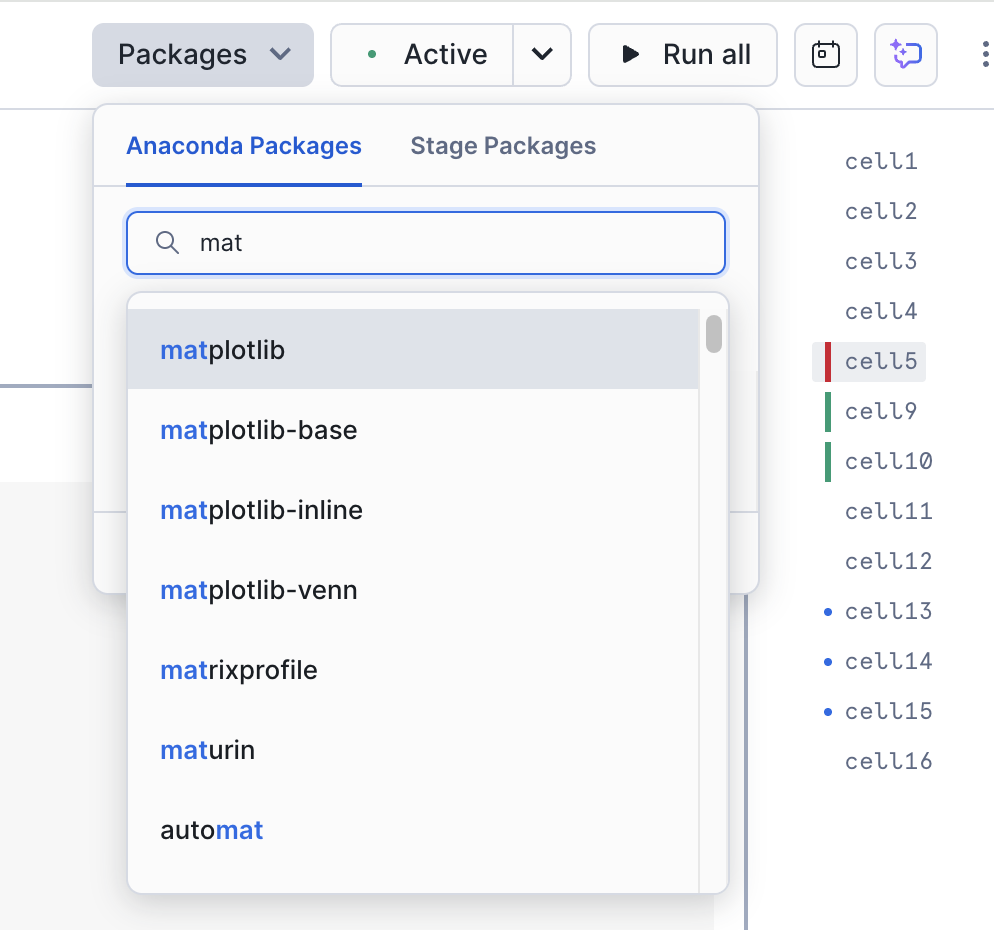
Suchen Sie nach matplotlib, und wählen Sie es aus. Dadurch wird dieses Paket in der Sitzung verfügbar gemacht.
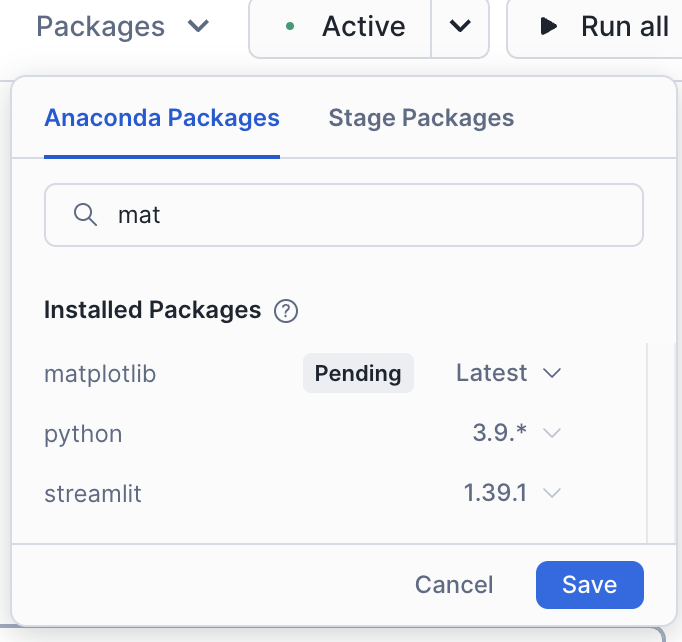
Sobald Sie diese Bibliothek geladen haben, müssen Sie die Sitzung neu starten. Nachdem Sie die Sitzung neu gestartet haben, führen Sie diese erste Zelle erneut aus. Sie werden wahrscheinlich erfahren, dass es dieses Mal erfolgreich war.

Wenn die Pakete geladen, die Sitzung korrigiert und die restlichen Probleme im Code bereits behoben sind: Was können wir tun, um den Rest des Notebooks zu überprüfen? Führen Sie es aus! Sie können alle Zellen im Notebook ausführen, indem Sie in der oberen rechten Ecke des Bildschirms „Alle ausführen“ wählen, und sehen, ob wir einen Fehler erhalten.
Es sieht so aus, als wäre die Ausführung erfolgreich:
Wenn Sie die Ausführung der beiden Notebooks vergleichen, sieht es so aus, als ob der einzige Unterschied darin besteht, dass bei der Snowflake-Version alle Ausgabe-Datensets zuerst gesetzt werden, gefolgt von den Bildern, während sie im Spark Jupyter-Notebook vermischt werden:
Beachten Sie, dass dieser Unterschied kein API-Unterschied ist, sondern ein Unterschied, wie Notebooks in Snowflake dies orchestrieren. Dies ist wahrscheinlich ein Unterschied, den AdventureWorks bereit ist zu akzeptieren.
Schlussfolgerungen¶
Durch die Verwendung des SMA konnten wir die Migration sowohl einer Datenpipeline als auch eines Berichts-Notebooks beschleunigen. Je mehr von jedem Sie haben, desto mehr Wert ist ein Tool wie SMA.
Lassen Sie uns zum Ablauf Bewertung -> Konvertierung -> Validierung zurückkehren, auf den wir immer wieder zurückkommen. Bei dieser Migration tun wir Folgendes:
Einrichten unseres Projekts im SMA
Ausführen der SMA-Bewertungs- und Konvertierungs-Engine für die Codedateien
Überprüfen des Ausgabeberichts vom SMA, um besser zu verstehen, was wir haben
Überprüfen, was vom SMA nicht in VS Code konvertiert werden konnte
Beheben von Problemen und Fehlern
Auflösen von Sitzungsreferenzen
Auflösen von Eingabe-/Ausgabereferenzen
Lokales Ausführen des Codes
Ausführen des Codes in Snowflake
Ausführen der neu migrierten Skripte aus und Validieren des Erfolgs
Snowflake hat viel Zeit darauf verwendet, seine Datenaufnahme- und Data-Engineering-Fähigkeiten zu verbessern, und genauso viel Zeit aufgewendet, um Migrationstools wie SnowConvertund SnowConvert Migration Assistant sowie den Snowpark Migration Accelerator zu verbessern. Jedes dieser Tools wird sich weiter verbessern. Wenn Sie Vorschläge für ein Migrationstool haben, wenden Sie sich an uns. Diese Teams sind immer auf der Suche nach zusätzlichem Feedback, um die Tools zu verbessern.