Snowpark Migration Accelerator: conversão de notebooks¶
Vamos acessar o Notebook de relatórios em nossa base de código: Notebook de relatórios básicos – SqlServer Spark.ipynb. Vamos percorrer um conjunto de etapas semelhante ao que fizemos com o script do pipeline.
Resolver todos os problemas: «problemas» aqui significa os problemas gerados pelo SMA. Analise o código de saída. Resolva os erros de análise e conversão e investigue os avisos.
Resolver as chamadas de sessão: a forma como a chamada de sessão é escrita no código de saída depende de onde vamos executar o arquivo. Vamos resolver isso para executar os arquivos de código na mesma localização em que seriam executados originalmente e, em seguida, para executá-los no Snowflake.
Resolver as entradas/saídas: não é possível resolver as conexões com diferentes fontes completamente pelo SMA. Existem diferenças entre as plataformas, e o SMA geralmente ignora isso. Isso também é afetado por onde o arquivo será executado.
Limpar e testar: vamos executar o código. Veja se funciona. Neste laboratório, faremos testes básicos, mas existem ferramentas para realizar testes e validações de dados mais extensivos, incluindo o Snowpark Python Checkpoints.
Vamos começar.
Resolver todos os problemas¶
Vamos analisar os problemas presentes no notebook.
(Observe que você pode abrir o notebook no VS Code, mas para visualizá-lo corretamente, talvez queira instalar a extensão Jupyter para VS Code. Como alternativa, você pode abri-lo no Jupyter, mas a Snowflake ainda recomenda o VS Code com a extensão Snowflake instalada).
Você pode usar o recurso de comparação para visualizar ambos lado a lado, como fizemos com o arquivo de pipeline, embora ele se pareça mais com um JSON se você fizer isso:
Observe que existem apenas dois EWIs exclusivos neste notebook. Você pode retornar à barra de pesquisa para encontrá-los, mas como este é muito curto, também é possível simplesmente… rolar para baixo. Estes são os problemas exclusivos:
SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.jdbc is not supported. This is a similar issue to the one we saw in the pipeline file, but that was a write call. This is a read call to the SQL Server database. We will resolve this in a bit.
SPRKPY1068 => «pyspark.sql.dataframe.DataFrame.toPandas is not supported if there are columns of type ArrayType, but it has a workaround. See documentation for more info. This is another warning. If we pass an array to this function in Snowpark, it may not work. Let’s keep an eye on this when we test it.
E é isso para o notebook… e nossos problemas. Resolvemos um erro de análise sintática, reconhecemos que teremos que corrigir as entradas/saídas e há algumas diferenças funcionais em potencial que devemos observar. Vamos para a próxima etapa: resolução das chamadas de sessão.
Resolver as chamadas de sessão¶
Para atualizar as chamadas de sessão no notebook de relatório, precisamos localizar a célula com a chamada de sessão. Fica assim:

Agora vamos fazer o que já fizemos para o nosso arquivo de pipeline:
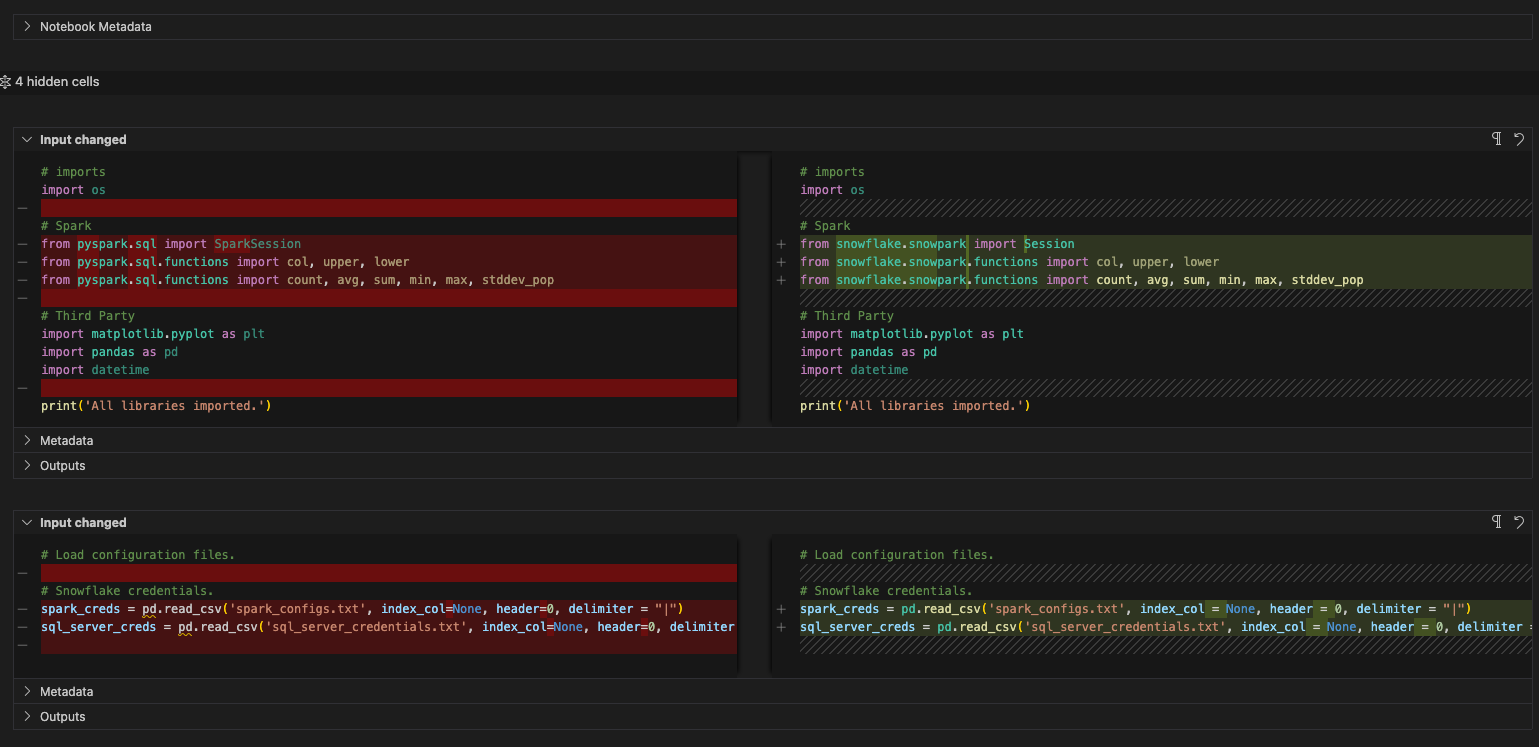
Altere todas as referências à variável de sessão «spark» para «session» (observe que isso ocorre em todo o notebook).
Remova a função de configuração com o driver spark.
O antes e o depois ficarão assim:
Observe que há outro código nesta célula. Esse código:
Estamos quase prontos para lidar com a instrução de leitura, mas ainda não chegamos lá. Vamos mover tudo isso para outra célula. Crie uma nova célula abaixo desta e mova este código para ela. Ficará assim:

Is this all we need for the session call? No. Recall (and possibly review) the previous page under Notes on Session Calls. You will either need to make sure that your connection.toml file has your connection information or you will need to explicitly specify the connection parameters you intend to use in the session.
Resolução das entradas/saídas¶
Vamos resolver nossas entradas e saídas agora. Observe que isso pode variar dependendo se você está executando os arquivos localmente ou no Snowflake; mas, para o notebook, tudo pode ser executado localmente ou no Snowflake. O código será um pouco mais simples, pois nem precisaremos chamar uma sessão. Vamos apenas… obter a sessão ativa. Assim como no arquivo de pipeline, faremos isso em duas partes: uma para ser executada/orquestrada localmente e outra para ser executada no Snowflake.
Trabalhar com as entradas e saídas no notebook de relatório será consideravelmente mais simples do que foi para o pipeline. Não há leitura de um arquivo local nem movimentação de dados entre arquivos. Há simplesmente uma leitura de uma tabela no SQL Server que agora é uma leitura de uma tabela no Snowflake. Como não acessaremos o SQL Server, podemos descartar qualquer referência às propriedades do SQL Server. E é possível substituir a instrução de leitura por uma instrução de tabela no Snowflake. O antes e o depois desta célula devem ser assim:
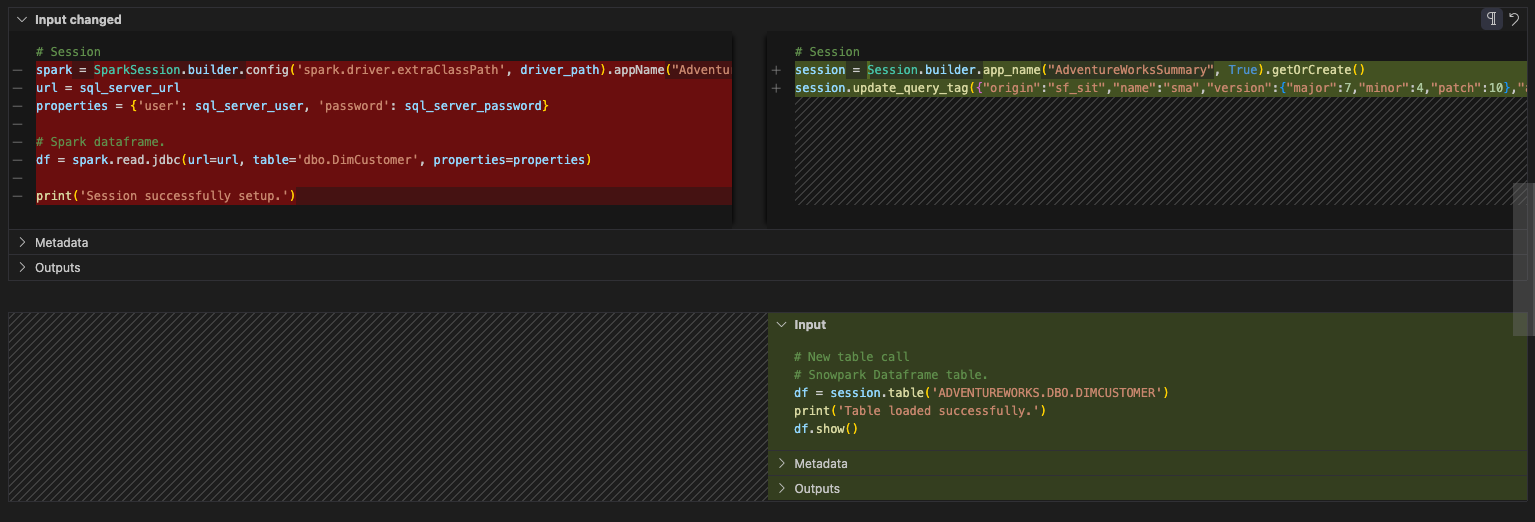
Na verdade, é isso. Vamos passar para a parte de limpeza e teste do arquivo notebook.
Limpar e testar¶
Let’s do some clean up (like we did previously for the pipeline file). We never looked at our import calls and we have config files that are not necessary at all. Let’s start by removing the references to the config files. This will be each of the cells between the import statements and the session call.
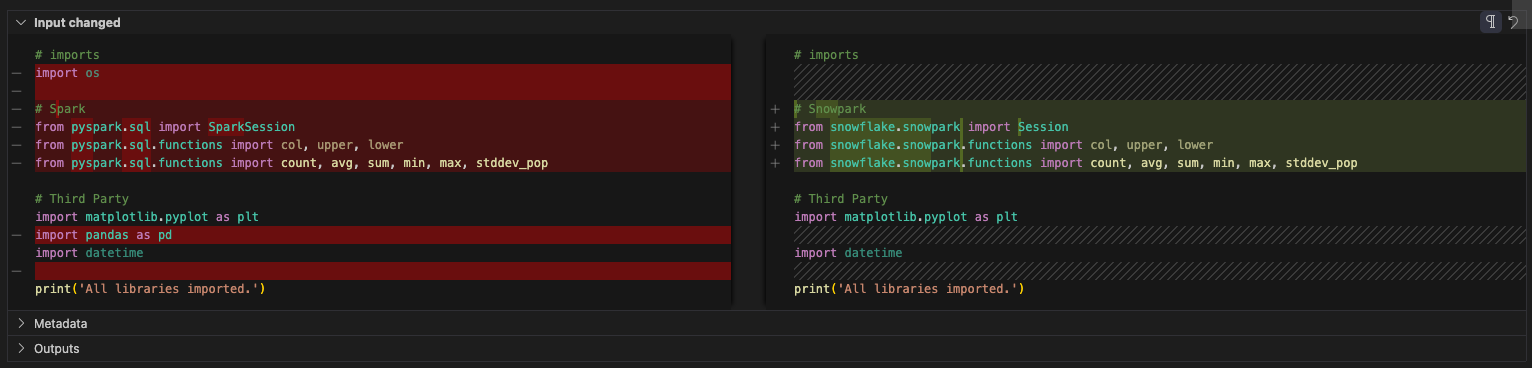
Agora vamos analisar nossas importações. A referência ao SO pode ser excluída (parece que isso também não era utilizado no arquivo original). Há uma referência ao pandas. Não parece haver mais nenhum uso do pandas neste notebook agora que os arquivos de configuração são referenciados. Há uma referência toPandas como parte da API do dataframe Snowpark na seção de relatórios, mas isso não faz parte da biblioteca pandas.
Como opção, você pode substituir todas as chamadas de importação para pandas pela biblioteca modin pandas. Essa biblioteca otimizará os dataframes pandas para aproveitar o grande poder computacional do Snowflake. Essa alteração ficaria assim:
Dito isso, podemos excluir este também. Observe que o SMA substituiu todas as instruções de importação específicas do Spark por aquelas relacionadas ao Snowpark. A célula de importação final ficaria assim:
And that’s it for our cleanup. We still have a couple of EWIs in the reporting and visualization cells, but it looks like we should make it. Let’s run this one and see if we get an output.
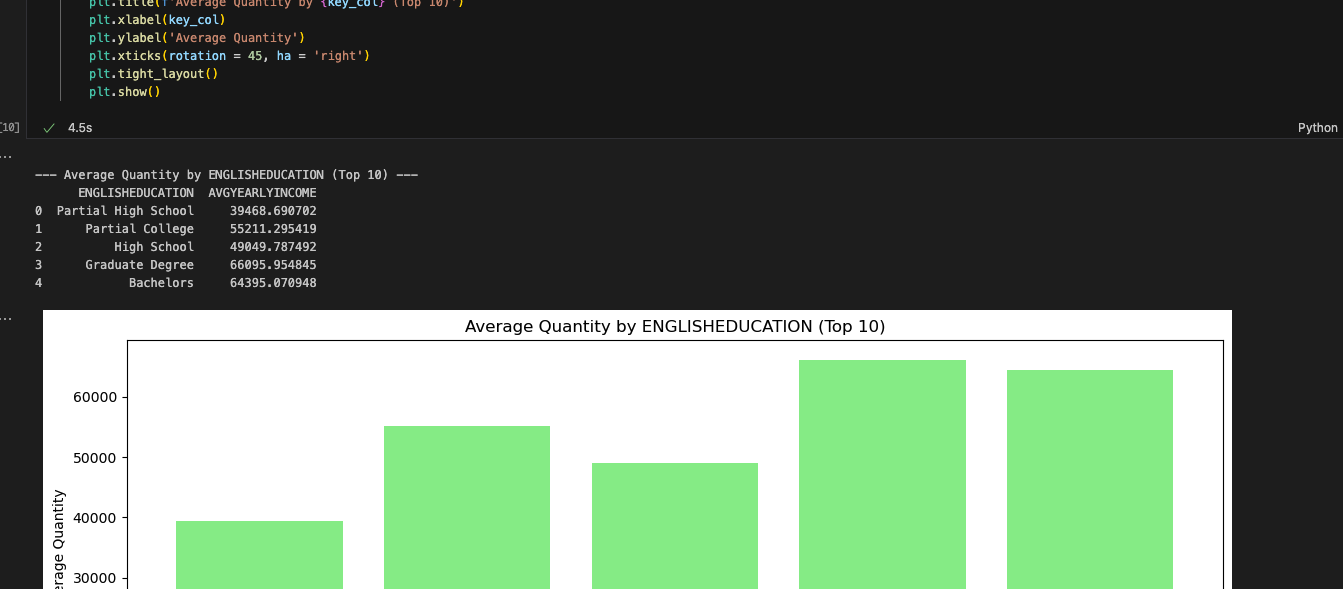
E conseguimos. Os relatórios parecem corresponder ao que foi gerado pelo Spark Notebook. Embora as células de relatório parecessem complexas, o Snowpark consegue trabalhar com elas. O SMA indicaria se pudesse haver um problema, mas aparentemente não há nenhum. Mais testes seriam úteis, mas nossa primeira rodada de testes rápidos foi concluída com sucesso.
Agora, vamos analisar este notebook no Snowsight. Ao contrário do arquivo de pipeline, podemos fazer tudo isso no Snowsight.
Execução do notebook no Snowsight¶
Vamos pegar a versão do notebook que temos agora (após termos trabalhado nos problemas, nas chamadas de sessão e nas entradas e saídas) e carregá-la no Snowflake. Para isso, acesse a seção de notebooks em SnowSight:
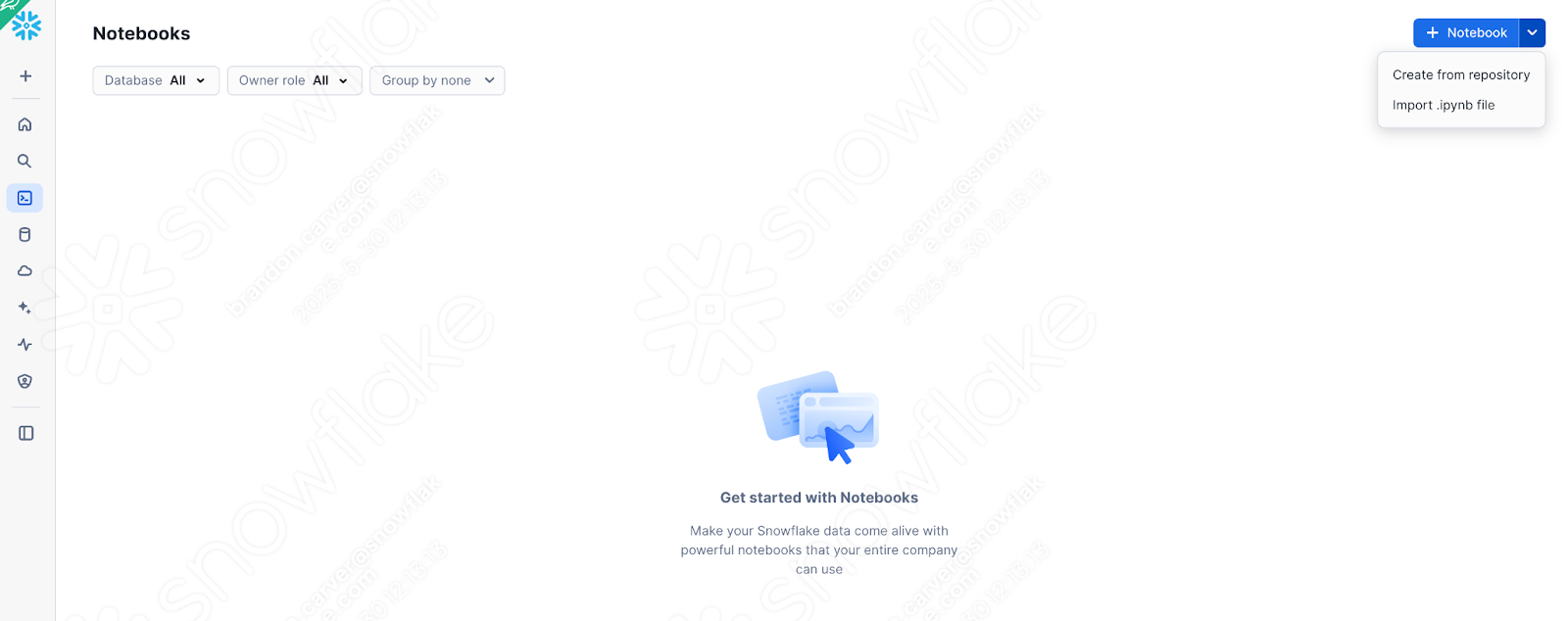
And select down arrow next to the +Notebook button in the top right, and select “Import .ipynb file” (shown above).
Após a importação, escolha o arquivo de notebook com o qual estávamos trabalhando no diretório de saída criado pelo SMA na pasta do seu projeto.
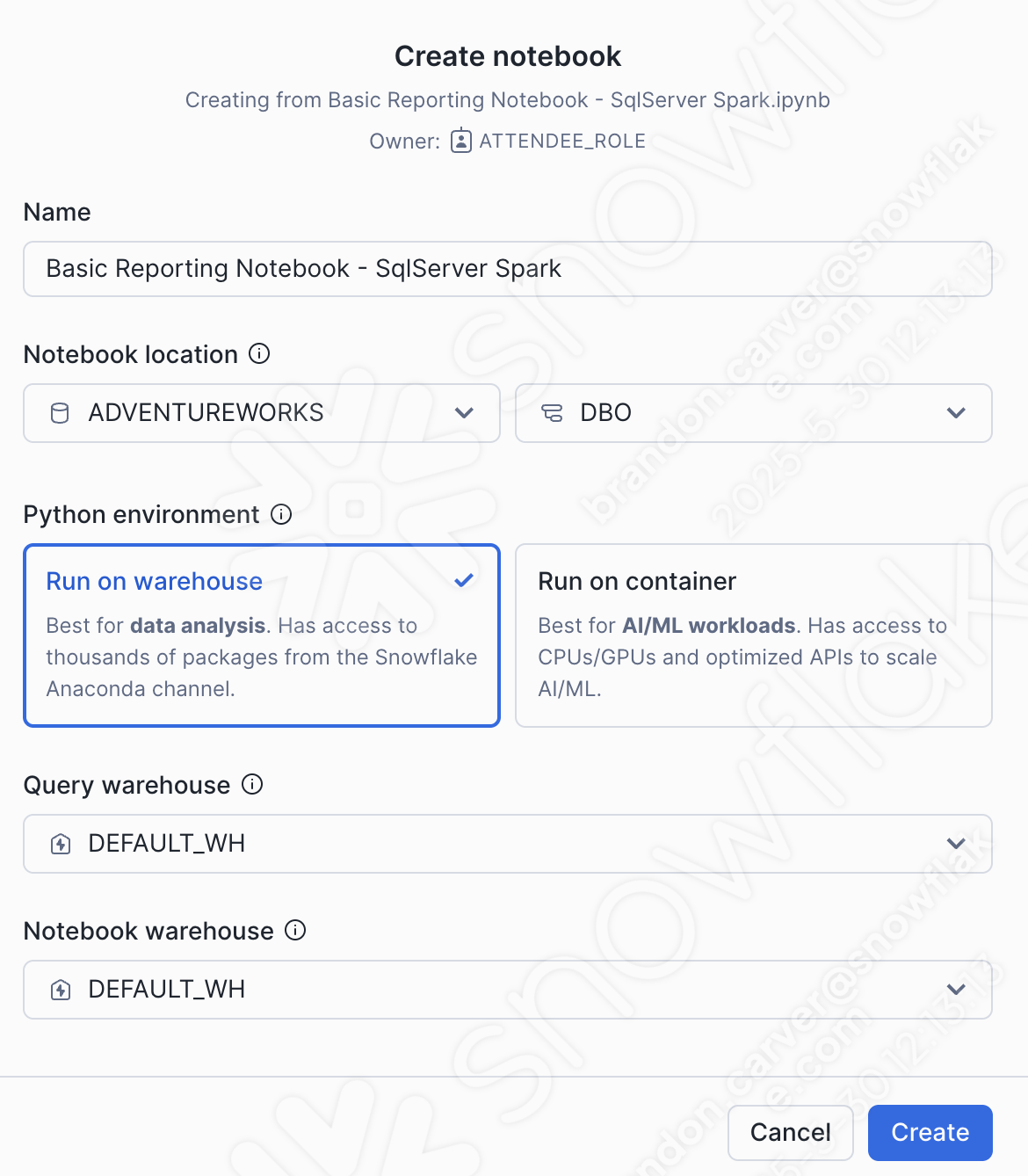
Uma janela de diálogo para criar notebook será aberta. Para este upload, escolheremos as seguintes opções:
Notebook location:
Banco de dados: ADVENTUREWORKS
Esquema: DBO
Ambiente Python: executar no warehouse
This is not a large notebook with a bunch of ml. This is a basic reporting notebook. We can run this on a warehouse.
Query warehouse: DEFAULT_WH
Notebook warehouse: DEFAULT_WH (you can leave it as the system chosen warehouse (will be a streamlit warehouse)… for this notebook, it will not matter)
Você pode ver essas seleções abaixo:
Isso deve carregar seu notebook no Snowflake, e ele ficará com esta aparência:
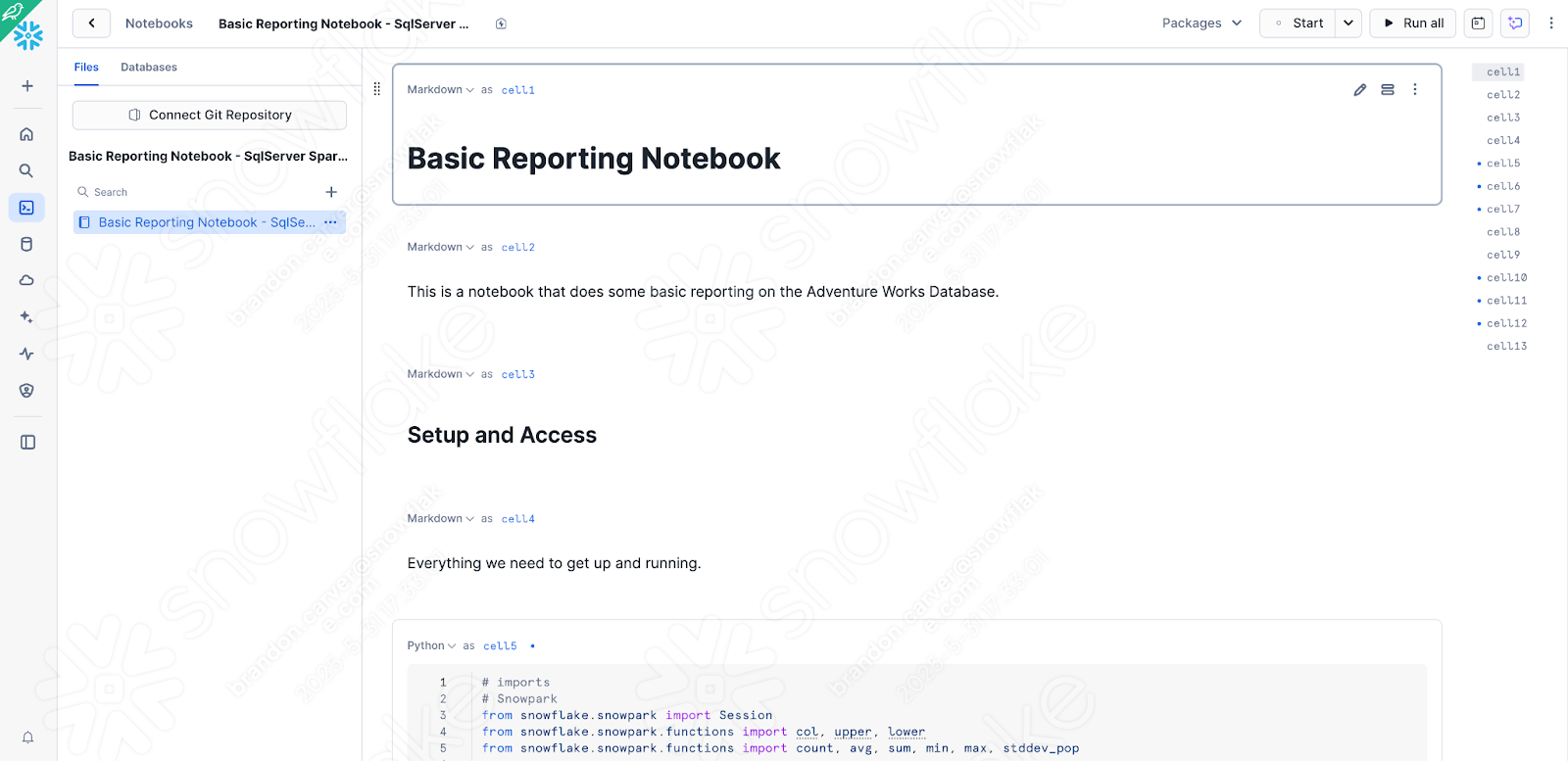
Há algumas verificações/alterações rápidas que precisamos fazer em relação à versão que acabamos de testar localmente para garantir que o notebook seja executado no Snowsight:
Alterar as chamadas de sessão para recuperar a sessão ativa
Garantir que todas as bibliotecas dependentes que precisamos instalar estejam disponíveis
Let’s start with the first one. It may seem odd to alter the session call again after we spent so much time on it in the first place, but we’re running inside of Snowflake now. You can remove anything associated with reading the session call and replacing it with the “get_active_session” call that is standard at the top of most Snowflake notebooks:
Não precisamos especificar parâmetros de conexão nem atualizar um arquivo .toml, porque já estamos conectados. Estamos no Snowflake.
Vamos substituir o código antigo na célula pelo código novo. O resultado será algo com esta aparência:
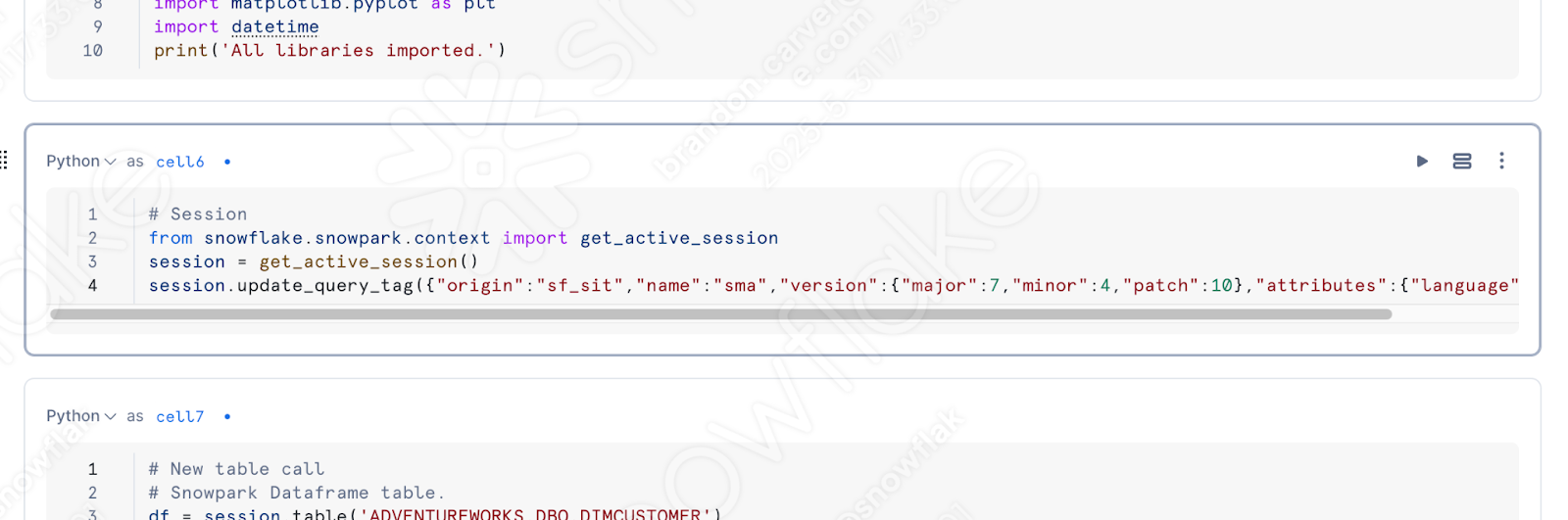
Agora, vamos verificar os pacotes disponíveis para esta execução, mas sem a necessidade de descobrirmos o que precisamos adicionar. Vamos deixar o Snowflake. Uma das melhores vantagens de usar um notebook é poder executar células individuais e ver os resultados. Vamos executar nossa célula de biblioteca de importação.
Se você ainda não fez isso, inicie a sessão clicando no canto superior direito da tela, onde está escrito «Start»:
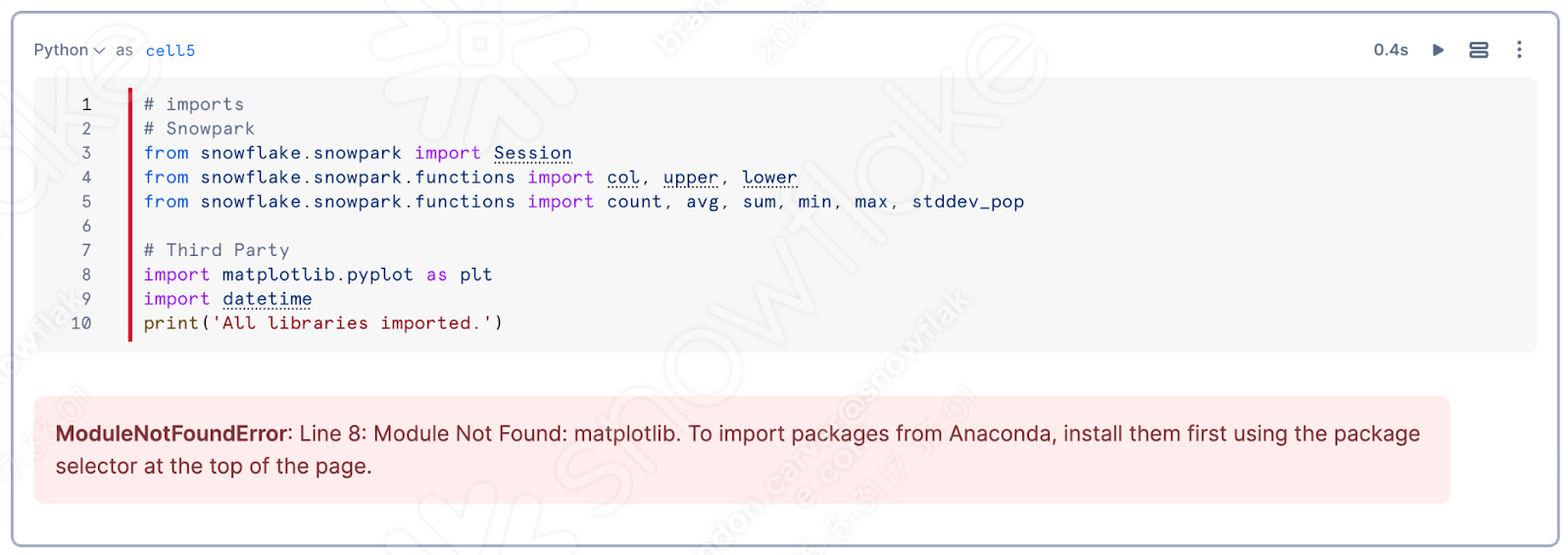
Se você executar a célula superior do notebook, provavelmente descobrirá que o matplotlib não está carregado na sessão:
Isto é algo muito importante para este notebook. Você pode adicionar essa biblioteca ao seu notebook/sessão usando a opção “Packages” no canto superior direito do notebook:
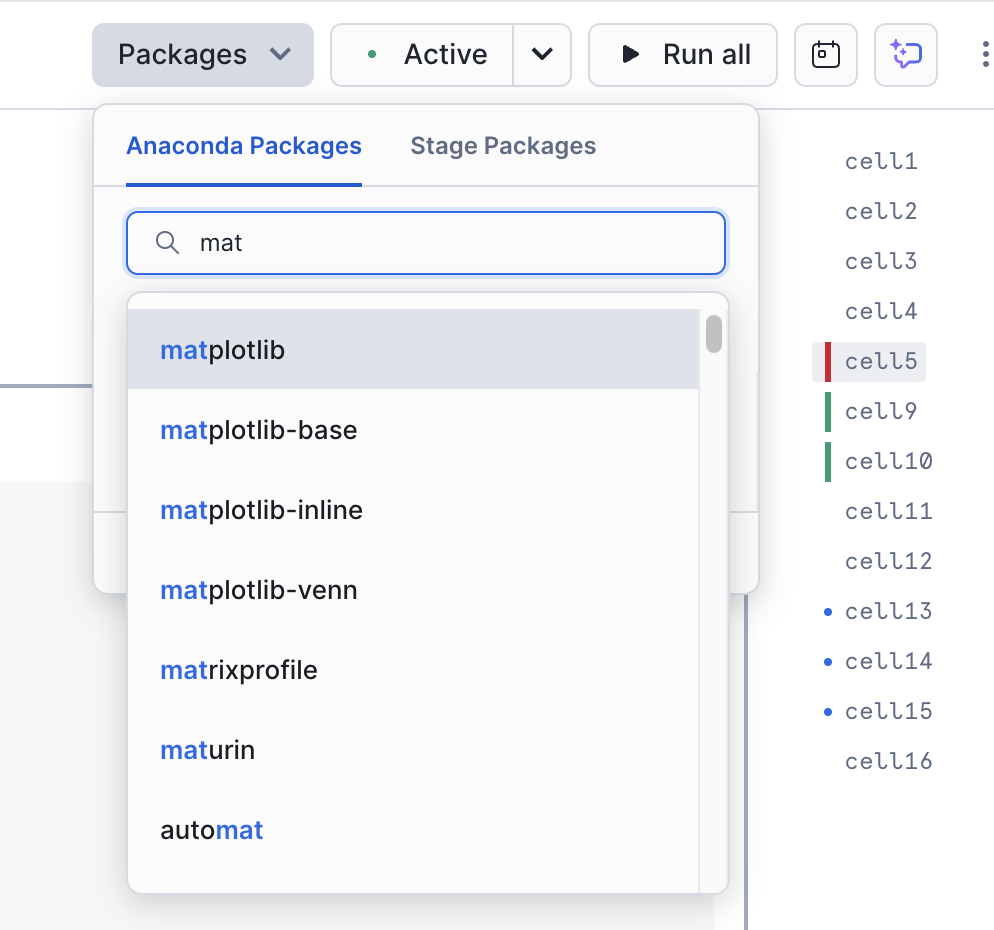
Procure por matplotlib e selecione-o. Isso disponibilizará este pacote na sessão.
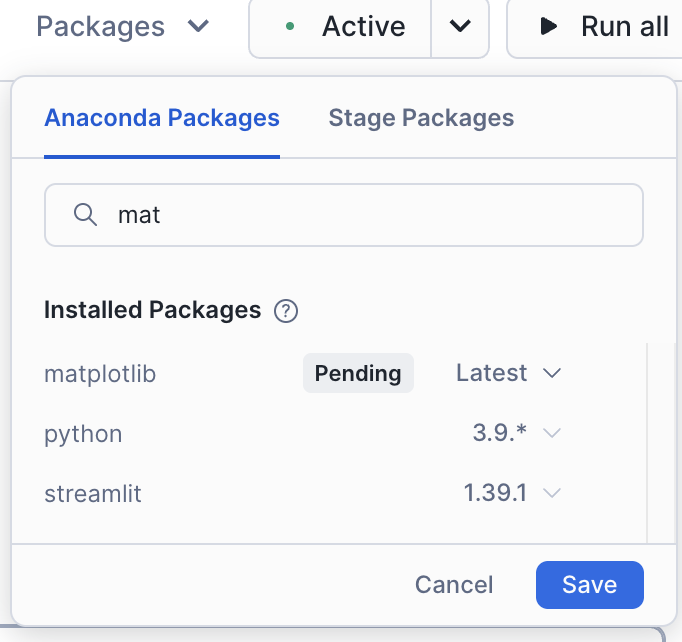
Depois de carregar esta biblioteca, você precisará reiniciar a sessão. Após reiniciar a sessão, execute a primeira célula novamente. Você provavelmente verá uma mensagem informando que a operação foi bem-sucedida desta vez.

Com os pacotes carregados, a sessão corrigida e os demais problemas no código já resolvidos, o que podemos fazer para verificar o restante do notebook? Executá-lo! Você pode executar todas as células do notebook selecionando “Run all” no canto superior direito da tela e verificar se ocorre algum erro.
Parece que a execução foi bem-sucedida:
Se você comparar a execução dos dois notebooks, parece que a única diferença é que a versão do Snowflake colocou todos os conjuntos de dados de saída primeiro, seguidos pelas imagens, enquanto no Spark Jupyter Notebook eles estão misturados:
Observe que essa diferença não é uma diferença na API, mas sim em como os notebooks no Snowflake orquestram isso. Essa é provavelmente uma diferença que o AdventureWorks está disposto a aceitar!
Conclusões¶
Ao utilizar o SMA, conseguimos acelerar a migração tanto de um pipeline de dados quanto de um notebook de relatórios. Quanto mais de cada um você tiver, mais valor uma ferramenta como o SMA poderá fornecer.
Vamos voltar ao fluxo de avaliação -> conversão -> validação ao qual sempre retornamos. Nesta migração, nós:
Configuramos nosso projeto no SMA
Executamos o mecanismo de avaliação e conversão do SMA nos arquivos de código
Revisamos os relatórios de saída do SMA para entender melhor o que temos
Revisamos o que não pôde ser convertido pelo SMA no VS Code
Resolvemos problemas e erros
Resolvemos referências de sessão
Resolvemos referências de entrada/saída
Executamos o código localmente
Executamos o código no Snowflake
Executamos os scripts recém-migrados e validamos o sucesso deles
A Snowflake investiu muito tempo aprimorando os recursos de ingestão e de engenharia de dados, assim como passou tempo aprimorando ferramentas de migração como o SnowConvert, o assistente de migração do SnowConvert e o Snowpark Migration Accelerator. Cada uma dessas ferramentas continuará a ser aprimorada. Entre em contato caso tenha alguma sugestão para as ferramentas de migração. Essas equipes estão sempre em busca de mais feedback para aprimorar as ferramentas.