Snowpark Migration Accelerator: 파이프라인 변환¶
SMA가 스크립트를 “변환”했다고 하지만 정말로 그럴까요? 실제로 SMA는 Spark API의 모든 참조를 Snowpark API로 변환했지만, 파이프라인에 존재할 수 있는 연결을 대체한 것은 아닙니다.
SMA의 핵심 기능은 평가 보고에 있습니다. 이러한 변환은 Spark API의 참조를 Snowpark API로 변환하는 작업에 국한되어 있기 때문입니다. 이러한 참조 변환만으로는 데이터 파이프라인을 실행하기에 충분하지 않습니다. 파이프라인의 연결은 수동으로 해결해야 합니다. SMA는 연결 매개 변수 또는 실행에 사용될 가능성이 없는 기타 요소를 알고 있다고 가정할 수 없습니다.
다른 변환과 마찬가지로, 변환된 코드를 다양한 방법으로 처리할 수 있습니다. 다음 단계는 변환 도구의 출력에 접근하는 권장 방법입니다. SnowConvert와 마찬가지로, SMA는 출력에 주의를 기울여야 합니다. 어떤 변환도 100% 자동화되지는 않습니다. 특히 SMA의 경우에 더욱 그렇습니다. SMA는 Spark API의 참조를 Snowpark API로 변환하므로 해당 참조가 실행되는 방법을 항상 확인해야 합니다. SMA는 실행되는 스크립트 또는 노트북의 성공적인 실행을 오케스트레이션하려고 시도하지 않습니다.
따라서 다음 단계에 따라 SnowConvert와는 약간 다른 SMA의 출력을 살펴보겠습니다.
모든 문제 해결: 여기서 “문제”는 SMA에 의해 생성된 문제를 의미합니다. 출력 코드를 살펴봅니다. 구문 분석 오류 및 변환 오류를 해결하고 경고를 조사합니다.
세션 호출 해결: 세션 호출이 출력 코드에 작성되는 방식은 파일을 실행할 위치에 따라 다릅니다. 원래 실행하려고 했던 위치와 동일한 위치에서 코드 파일을 실행한 다음 Snowflake에서 실행하여 해결합니다.
입력 및 출력 해결: 다른 소스에 대한 연결은 SMA가 완전히 해결할 수 없습니다. 플랫폼마다 차이가 있으며, SMA는 일반적으로 이를 무시합니다. 또한 파일이 실행될 위치에 따라 영향을 받습니다.
정리 및 테스트: 코드를 실행해 보고, 작동하는지 확인합니다. 이 랩에서는 스모크 테스트를 진행하지만, Snowpark Python Checkpoints를 비롯해 더 광범위한 테스트 및 데이터 유효성 검사를 수행할 수 있는 도구가 있습니다.
이제 어떻게 진행되는지 살펴보겠습니다. 두 가지 접근 방식을 사용해 보겠습니다. 첫 번째는 소스 스크립트가 실행 중이므로 로컬 컴퓨터에서 Python으로 실행하는 것입니다. 두 번째는 Snowflake에서 모든 작업을 수행하는 것이지만, 로컬 소스에서 데이터를 읽어오는 데이터 파이프라인의 경우 Snowsight에서 100% 구현하기는 어렵습니다. 그래도 괜찮습니다. 이 POC에서는 이 스크립트의 오케스트레이션을 변환하지 않기 때문입니다.
먼저, 파이프라인 스크립트 파일부터 살펴보고 다음 섹션에서 노트북을 살펴보겠습니다.
문제 해결¶
코드 편집기에서 소스와 출력 코드를 엽니다. 원하는 코드 편집기를 사용할 수 있지만, 여러 번 언급했듯이 Snowflake는 **Snowflake 확장 프로그램을 사용하는 VS Code**를 사용하는 것을 권장합니다. Snowflake 확장 프로그램은 SnowConvert의 문제를 해결하는 데 도움이 될 뿐만 아니라 Python용 **Snowpark Checkpoints**도 실행할 수 있어 테스트 및 근본 원인 분석에 도움이 됩니다(이 랩의 범위를 약간 벗어남).
VS Code의 프로젝트 생성 화면에서 처음 만든 디렉터리를 열어 보겠습니다(Spark ADW Lab).
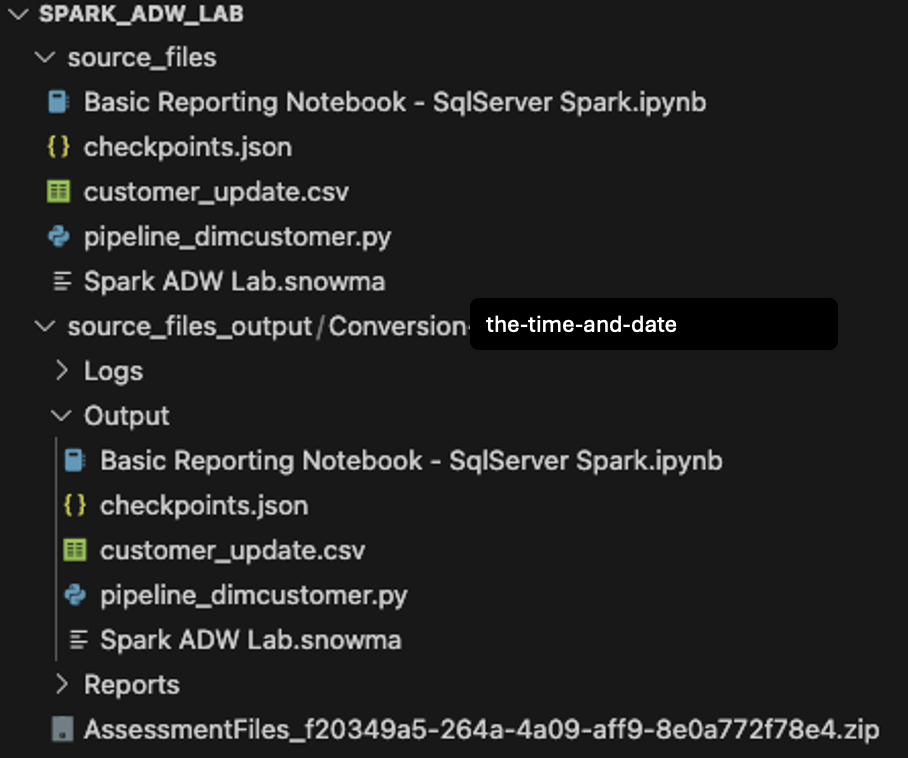
출력 디렉터리 구조는 입력 디렉터리와 동일합니다. 변환이 수행되지 않더라도 데이터 파일도 복사됩니다. SMA가 생성하는 몇 가지 checkpoints.json 파일도 있습니다. Snowpark Checkpoints 확장 프로그램에 대한 지침이 포함된 json 파일입니다. Snowflake 확장 프로그램은 해당 파일의 데이터를 기반으로 소스 코드와 출력 코드 모두에 검사점을 로드할 수 있습니다. 지금은 무시하겠습니다.
마지막으로, 입력 Python 스크립트와 출력 스크립트에서 변환된 스크립트를 비교해 보겠습니다.
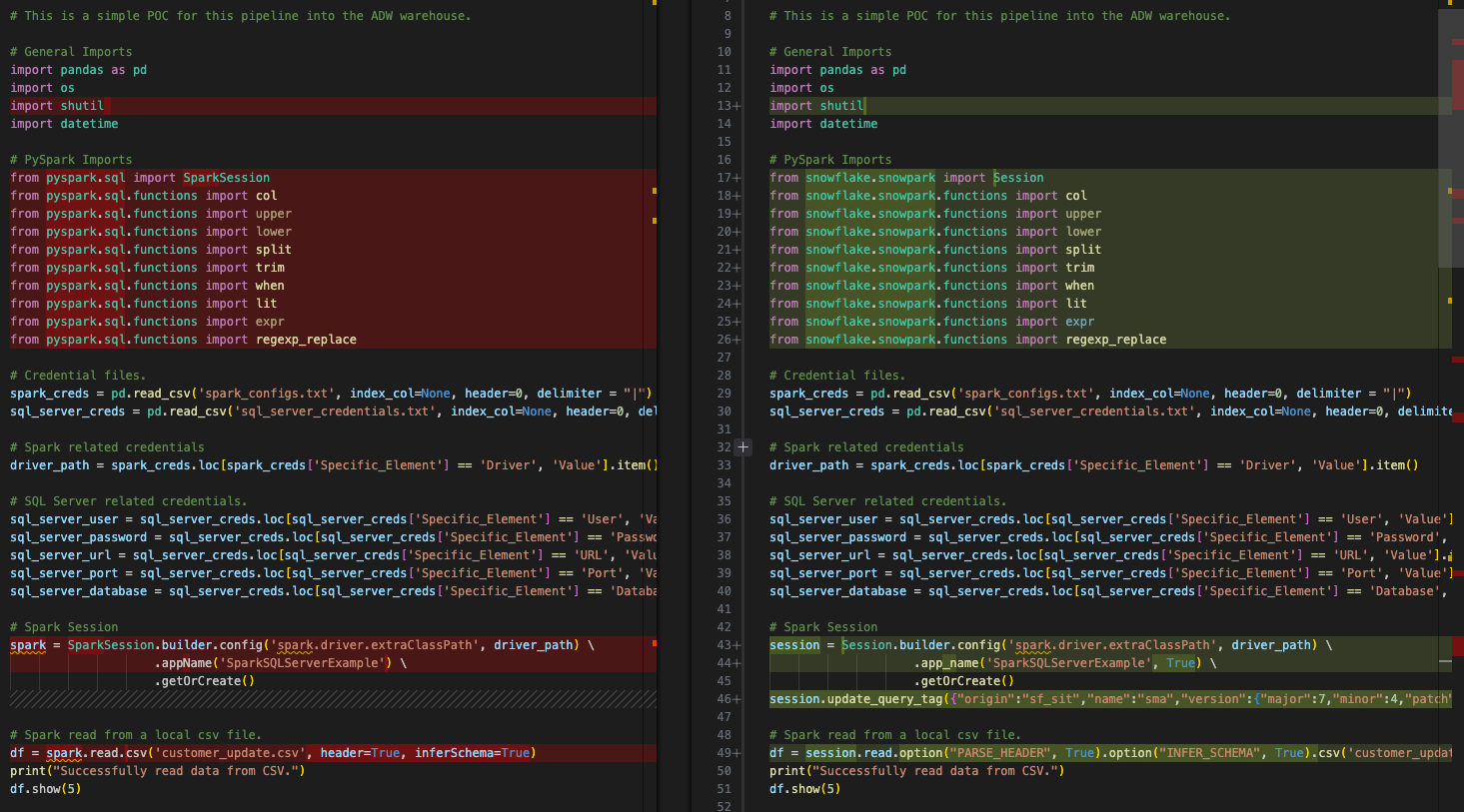
왼쪽의 원본 Spark 코드와 오른쪽의 출력 Snowpark 호환 코드를 기본적으로 나란히 비교한 것입니다. 일부 가져오기 호출 및 세션 호출이 변환된 것 같습니다. 위의 이미지 하단에 EWI가 있지만, 여기서 시작하지는 않겠습니다. 다른 작업을 수행하기 전에 구문 분석 오류를 찾아야 합니다.
문서에서 구문 분석 오류에 대한 오류 코드를 검색할 수 있습니다. 이는 UI 및 issues.csv: SPRKPY1101 모두에 표시되어 있습니다.
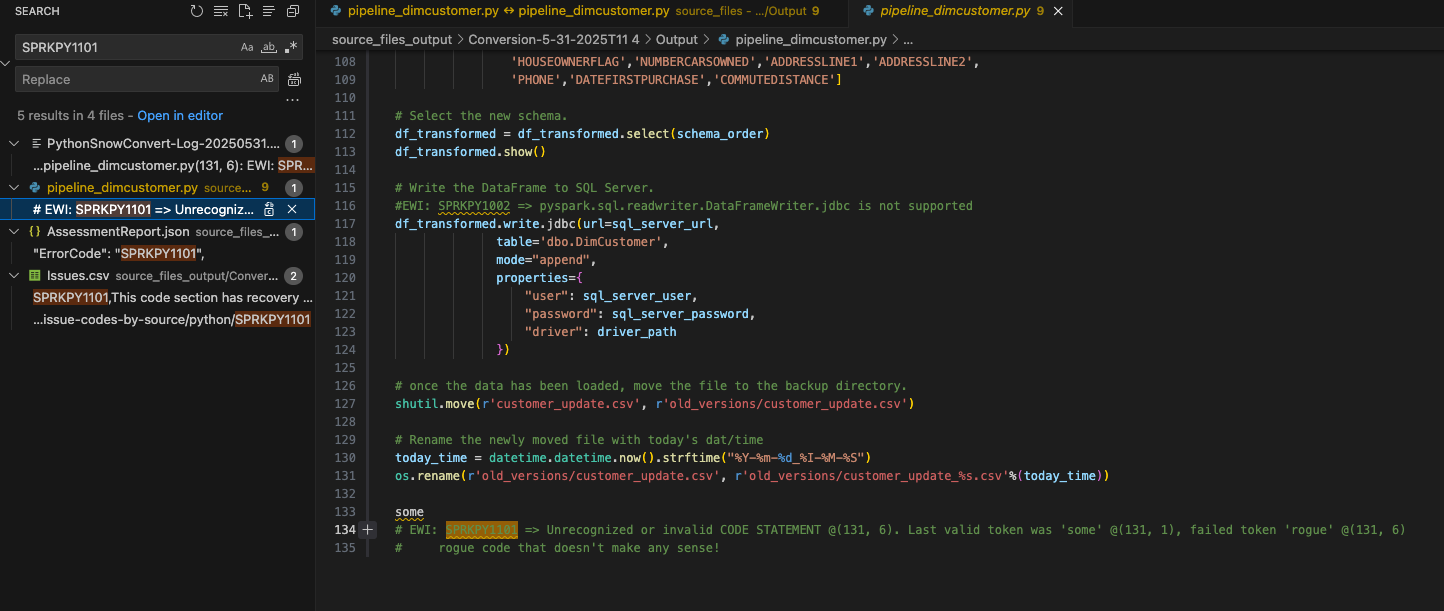
Since I have not filtered the results, the listing of this error code in the issues.csv also comes up in the search and the AssessmentReport.json that is used to build the AssessmentReport.docx summary assessment report. This is the main report that users will navigate through to understand a large workload, but we did not look at it in this lab. (More info on the this report can be found in the SMA documentation.) Let’s choose where this EWI shows up in the pipeline_dimcustomer.py file as shown above.
You can see that this line of code was present at the bottom of the source code.
이 구문 분석 오류는 “some rogue code that doesn’t make any sense!”로 인해 발생한 것으로 보입니다. 이 코드 줄은 파이프라인 파일의 하단에 있습니다. 소스에서 추출한 코드 파일에 추가 문자나 기타 요소가 있는 것은 드문 일이 아닙니다. SMA는 이 코드가 유효한 Python 코드가 아님을 감지하고 구문 분석 오류를 생성했습니다.
또한 SMA는 오류 코드와 설명을 출력 코드 내 오류가 발생한 곳에 주석으로 삽입했습니다. 모든 오류 메시지가 출력에 표시되는 방식입니다.
이 코드는 유효한 코드가 아니고 파일의 끝에 있으며 이 오류로 인해 제거된 다른 코드는 없으므로, 출력 코드 파일에서 원본 코드와 설명을 안전하게 제거할 수 있습니다.
이제 가장 시급하고 심각한 문제가 해결되었습니다. 다행이네요.
이제 이 파일의 나머지 EWIs를 살펴보겠습니다. 이제 오류 코드가 있을 때마다 주석에 텍스트가 표시되는 것을 알고 있으므로, “EWI”를 검색하면 됩니다. (또는 issues.csv 파일을 정렬하고 심각도별로 문제를 정렬할 수도 있지만 여기서는 그럴 필요가 없습니다.)
다음은 실제 오류가 아닌 단순한 경고입니다. Spark와 Snowpark에서 항상 상응하지 않는 함수가 사용되었음을 알려줍니다.
하지만 여기 설명을 보면 이에 대해 걱정할 필요가 없다는 것을 알 수 있습니다. 두 개의 매개 변수만 전달되기 때문입니다. 나중에 파일을 실행할 때 확인할 수 있도록 EWI를 파일에 주석으로 남겨두겠습니다.
이 파일의 마지막 오류는 지원되지 않는 항목이 있음을 나타내는 변환 오류입니다.

이 오류는 출력 데이터 프레임을 SQL Server에 쓰기 위해 spark jdbc 드라이버에 대해 write 호출을 수행합니다. 이는 문제를 해결한 후 처리할 “모든 입력 및 출력 해결” 단계에 해당하므로, 나중에 처리하겠습니다. 그러나 이 오류는 해결해야 합니다. 이전의 오류는 경고에 불과했으며 변경 없이도 문제 없이 작동할 수 있습니다.
세션 호출 해결¶
세션 호출은 SMA에 의해 변환되지만, 제대로 작동하는지 확인하기 위해 특히 주의해야 합니다. 파이프라인 스크립트에서 전후 코드는 다음과 같습니다.

SparkSession 참조가 Session으로 변경되었습니다. import 문에서도 이 파일의 상단 근처에서 참조가 변경된 것을 확인할 수 있습니다.

위 이미지에서 볼 수 있듯이, session 호출의 “spark”에 대한 변수 할당은 변경되지 않았습니다. 이는 변수 할당이기 때문입니다. 이를 변경할 필요는 없지만, “spark” 데코레이터를 “session”으로 변경하려면 Snowpark에서 권장하는 방식에 더 적합할 것입니다. (참고로 VS Code 확장 프로그램 “SMA Assistant”에서도 이러한 변경 사항을 제안합니다.)
이는 간단한 연습이지만 수행할 가치가 있습니다. VS Code의 자체 검색 기능을 통해 찾기 및 바꾸기를 수행하여 이 파일에서 “spark” 참조를 찾아 session으로 대체할 수 있습니다. 결과는 아래 이미지에서 확인할 수 있습니다. 변환된 코드에서 “spark” 변수에 대한 참조가 “session”으로 대체되었습니다.

이 세션 호출에서 다른 항목을 제거할 수도 있습니다. 더 이상 “spark”를 실행하지 않으므로 spark 드라이버의 드라이버 경로를 지정할 필요가 없습니다. 따라서 다음과 같이 session 호출에서 config 함수를 완전히 제거할 수 있습니다.
Might as well convert it to a single line. The SMA couldn’t be sure we didn’t need that driver (although that seems logical), so it did not remove it. But now that we have our session call is complete.
(SMA는 세션에 “쿼리 태그”도 추가합니다. 이는 나중에 이 세션 또는 쿼리의 문제를 해결하는 데 도움이 되지만, 그대로 남겨두거나 제거하는 것은 전적으로 선택 사항입니다.)
세션 호출에 대한 참고 사항¶
믿거나 말거나, session 호출을 위한 코드에서 변경해야 할 것은 이것뿐입니다. 하지만 세션을 생성하기 위해 해야 할 작업은 이것이 전부는 아닙니다. 여기서는 파일을 실행할 위치에 따라 많은 부분이 달라진다는 원래의 질문을 되새겨 봐야 합니다. 원본 spark session 호출은 다른 곳에서 설정된 구성을 사용했습니다. 원본 spark session 호출을 살펴보면 이 스크립트 파일의 시작 부분에서 pandas DataFrame 위치로 읽어오는 구성 파일을 찾고 있습니다(실제로 노트북 파일에서도 마찬가지임).
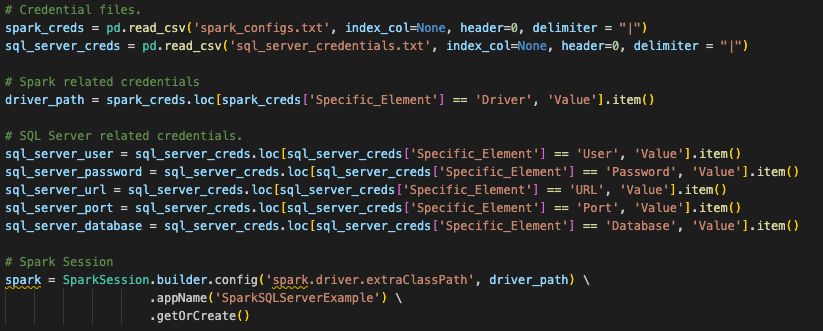
Snowpark can function the same way, and this conversion assumes that is how this user will run this code. However, for the existing session call to work, the user would have to load all of the information for their Snowflake account into the local (or at least accessible) connections.toml file on this machine, and that the account they are attempting to connect to is set as the default. You can learn more about updating the connections.toml file in the Snowflake/Snowpark documentation, but the idea behind it is that there is an accessible location that has the credentials. When a snowpark session is created, it is going to check this… unless the connection parameters are explicitly passed to the session call.
이 작업을 수행하는 표준 방법은 연결 매개 변수를 문자열로 직접 입력하고 세션으로 호출하는 것입니다.
AdventureWorks appears to have referenced a file with these credentials and called it. Assuming there is a similar file called ‘snowflake_credentials.txt’ that is accessible, then the syntax that would match that could look something like:
For the purpose of the time limit on this lab, the first option may make more sense. There’s more on this in the Snowpark documentation.
Snowsight를 사용하여 Snowflake 내에서 노트북 파일을 실행하려면 이 작업을 수행할 필요가 없습니다. 활성 세션을 호출하고 실행하기만 하면 됩니다.
이제 이 마이그레이션의 가장 중요한 구성 요소인 입력 및 출력 참조를 해결할 차례입니다.
입력 및 출력 해결¶
이제 입력과 출력을 해결하겠습니다. 파일을 로컬에서 실행하는지, 아니면 Snowflake에서 실행하는지에 따라 결과가 달라집니다. Python 스크립트의 경우, Snowsight 내에서 직접 실행할 때의 장단점을 확인해 보겠습니다. **Snowsight에서는 전체 작업을 실행할 수는 없습니다**(적어도 현재는 실행되지 않음). Snowsight에서는 로컬 csv 파일에 액세스할 수 없습니다. .csv 파일을 스테이지에 수동으로 로드해야 합니다. 이상적인 해결책이 아닐 수 있지만, 이렇게 하면 변환을 테스트할 수 있습니다.
먼저 이 파일을 로컬에서 실행 및 오케스트레이션한 후 Snowflake에서 실행할 수 있도록 준비하겠습니다.
파이프라인 스크립트의 입력 및 출력을 해결하려면 먼저 이를 식별해야 합니다. 매우 간단합니다. 이 스크립트는 다음을 수행하는 것으로 보입니다.
로컬 파일에 액세스
결과를 SQL Server에 로드(단, 현재는 Snowflake에)
다음 파일을 위한 공간을 만들기 위해 파일 이동
매우 간단합니다. 따라서 이러한 작업을 수행하는 코드의 각 구성 요소를 바꿔야 합니다. 로컬 파일에 액세스하는 작업부터 시작해 보겠습니다.
이 문서의 시작 부분에서 언급했듯이, 출력 파일을 클라우드 저장소 위치에 저장하기 위해 이 Python 스크립트를 실행하는 데 사용되는 POS 시스템과 오케스트레이션 도구를 다시 설계하는 것이 매우 좋습니다. 그런 다음 해당 위치를 외부 테이블로 변환하여 Snowflake에 배치하면 됩니다. 그러나 현재 아키텍처에서는 이 파일이 클라우드 저장소 위치에 있지 않고 그대로 유지되므로, Snowflake가 기존 논리를 유지하면서 이 파일에 액세스할 수 있는 방법을 만들어야 합니다.
이를 수행할 수 있는 옵션이 있지만, 내부 스테이지를 생성하고 스크립트를 사용하여 파일을 스테이징으로 이동시키겠습니다. 그런 다음 로컬 파일 시스템에서 파일을 이동하고 스테이지에서도 이동해야 합니다. 이 모든 작업을 Snowpark에서 수행할 수 있습니다. 자세히 살펴보겠습니다.
로컬 파일에 액세스: 내부 스테이지 만들기(아직 존재하지 않는 경우) -> 파일을 스테이지에 로드 -> 파일을 DataFrame으로 읽어오기
결과를 SQL Server에 로드: 변환된 데이터를 Snowflake의 테이블에 로드
다음 파일을 위한 공간을 만들기 위해 파일 이동 로컬 파일 이동 -> 스테이지에서 파일 이동.
각 작업을 수행할 수 있는 코드를 살펴보겠습니다.
로컬에서 액세스 가능한 파일에 액세스¶
Spark의 이 소스 코드는 다음과 같습니다.
그리고 (SMA에 의해) 변환된 Snowpark 코드는 다음과 같습니다.
위의 단계를 수행하는 코드로 이를 대체할 수 있습니다.
Create an internal stage (if one does not exist already). We will create a stage called ‘LOCAL_LOAD_STAGE’ and go through a few steps to make sure that the stage is r
파일을 스테이지에 로드합니다.
파일을 DataFrame으로 읽어옵니다. 이 부분은 SMA가 실제로 변환한 것입니다. 이제 파일의 위치가 내부 스테이지임을 지정해야 합니다.
결과는 다음과 같습니다.
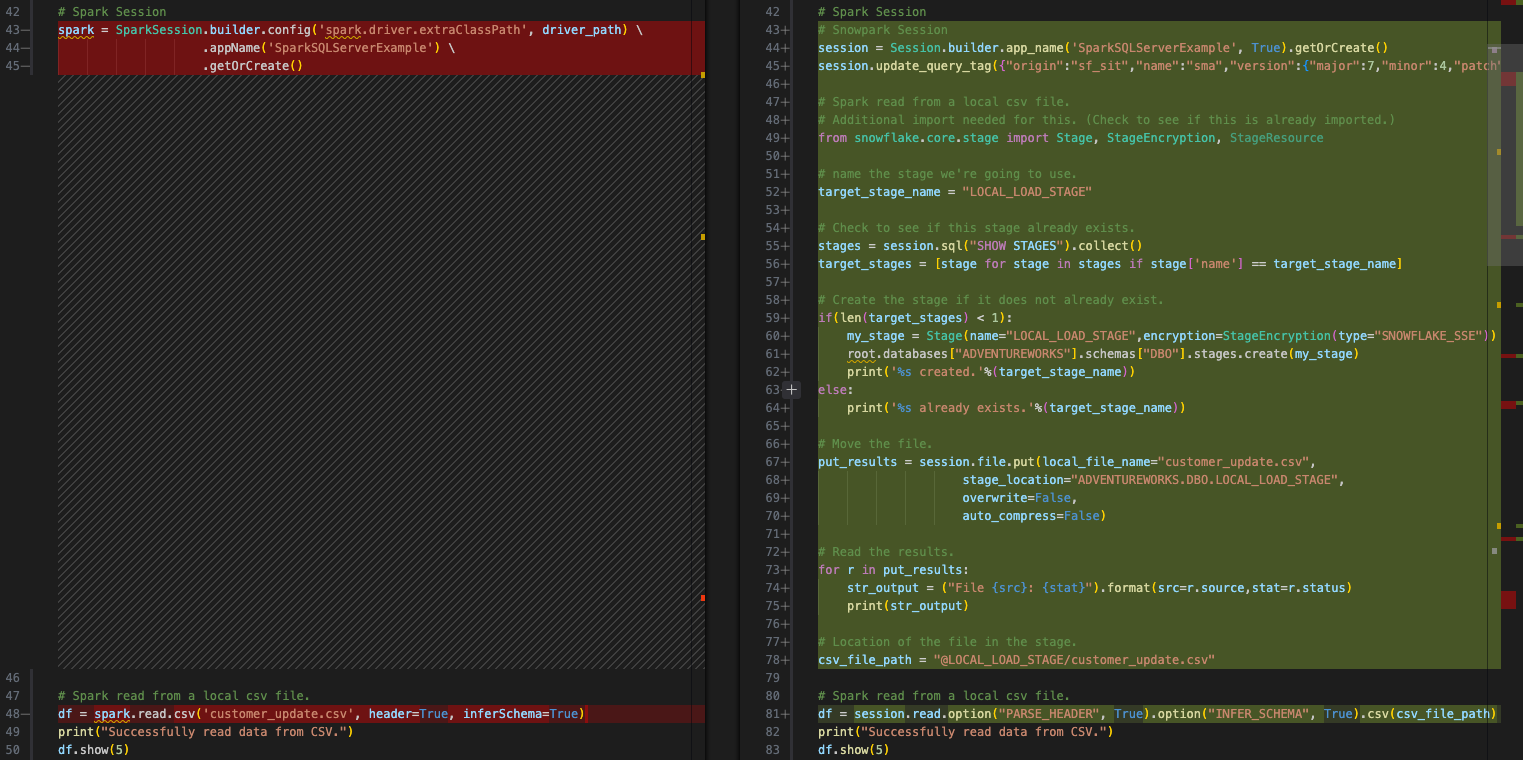
다음 단계로 넘어가 보겠습니다.
결과를 Snowflake에 로드¶
원본 스크립트에서는 SQL Server에 DataFrame을 작성했습니다. 이제 Snowflake에 로드하겠습니다. 이는 훨씬 간단한 변환입니다. DataFrame은 이미 Snowpark DataFrame입니다. 이는 Snowflake의 장점 중 하나입니다. 이제 Snowflake에서 데이터에 액세스할 수 있으므로 모든 작업이 Snowflake 내에서 이루어집니다.
일부 테스트 및 유효성 검사를 수행하기 위해 임시 테이블에 작성할 수 있지만, 이는 원본 스크립트의 동작입니다.
다음 파일을 위한 공간을 만들기 위해 파일 이동¶
이는 원본 스크립트의 동작입니다. Snowflake에서 이 작업을 수행할 필요는 없지만 스테이지에서 똑같은 기능을 구현할 수는 있습니다. 이 작업은 원본 파일 시스템에서 os 명령으로 수행됩니다. 이는 Spark에 종속되지 않으며 동일하게 유지됩니다. 그러나 Snowpark에서 이 동작을 에뮬레이트하려면 스테이지에서 이 파일을 새 디렉터리로 이동해야 합니다.
이 작업은 다음 Python 코드로 간단히 수행할 수 있습니다.
이는 기존 코드를 대체하지 않습니다. 기존에 Spark 코드를 Snowpark로 이동시키는 작업을 유지하기로 했으므로, OS 참조는 그대로 두겠습니다. 최종 버전은 다음과 같습니다.
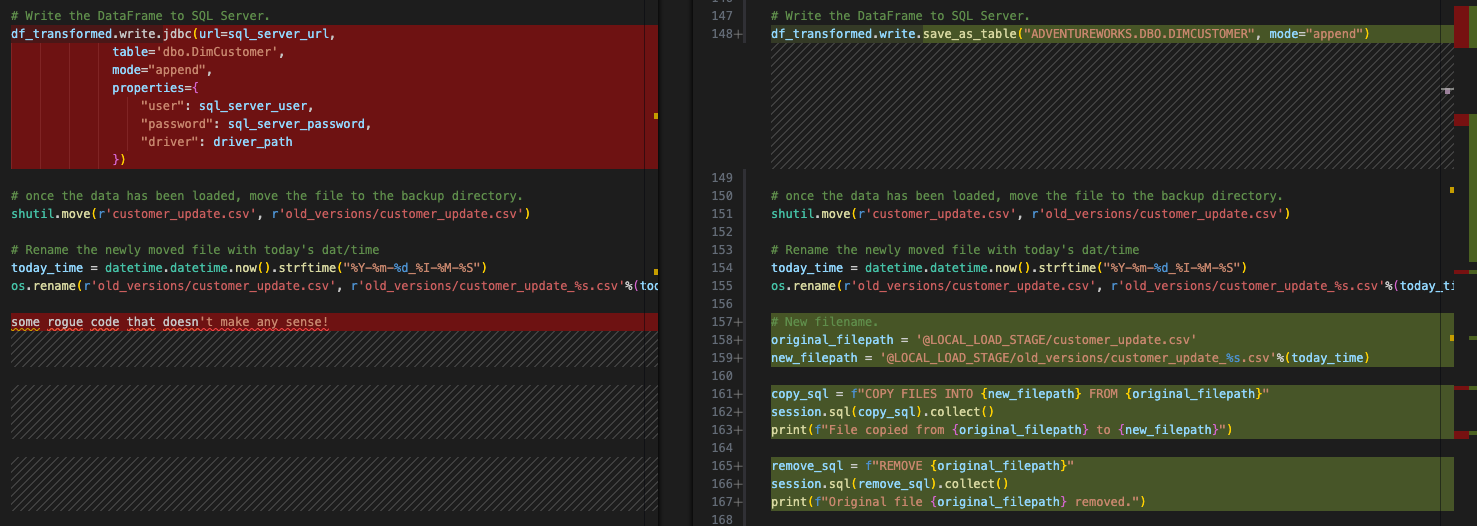
이제 동일한 작업이 완전히 완료되었습니다. 이제 마지막 정리를 수행하고 이 스크립트를 테스트해 보겠습니다.
정리 및 테스트¶
import 호출을 살펴본 적이 없으므로, 전혀 필요하지 않은 구성 파일도 있습니다. 구성 파일에 대한 참조를 남겨두고 스크립트를 실행할 수 있습니다. 사실, 이러한 구성 파일에 여전히 액세스할 수 있다고 가정하면 코드가 계속 실행됩니다. 그러나 import 문을 자세히 살펴보면 해당 문을 제거하는 것이 좋습니다. 이러한 파일은 import 문과 session 호출 사이의 모든 코드로 표현됩니다.
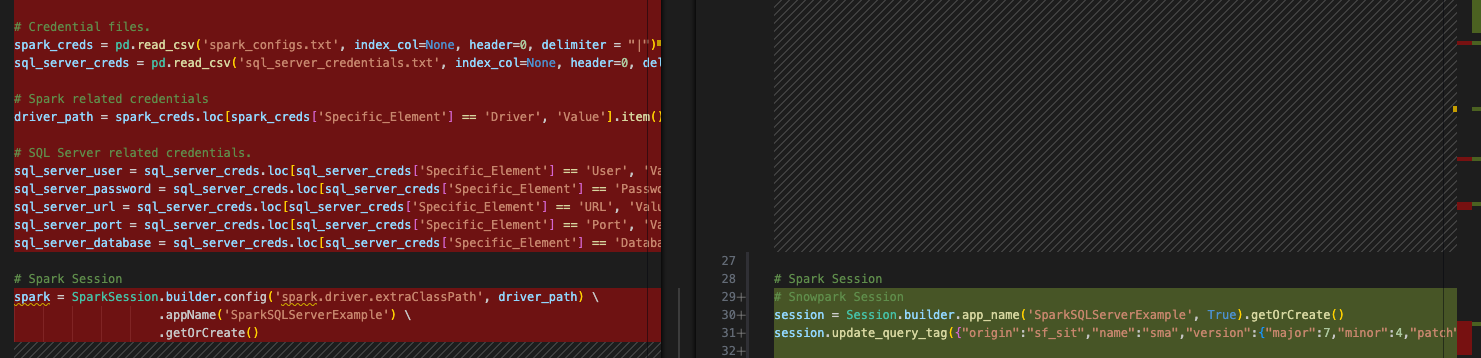
다음과 같은 몇 가지 다른 작업을 수행해야 합니다.
모든 가져오기가 여전히 필요한지 확인합니다. 지금은 그대로 두면 됩니다. 오류가 발생하면 해결할 수 있습니다.
또한 경고로 남겨둔 EWI가 하나 있습니다. 따라서 해당 출력을 검사해야 합니다.
We need to make sure that our file system behavior mirrors that of the expected file system for the POS system. To do this, we should move the customer_update.csv file into the root folder you chose when first launching VS Code.
Create a directory called “old_versions” in that same directory. This should allow the os operations to run.
마지막으로, 코드를 프로덕션 테이블로 직접 실행하는 것이 불편하다면 이 테스트를 위해 해당 테이블의 복사본을 만들고 해당 복사본에 대한 로드를 지정할 수 있습니다. load 문을 아래의 문으로 바꿉니다. 이는 랩이므로 “production” 테이블에 자유롭게 작성합니다.
이제 테스트할 준비가 되었습니다. Python에서 이 스크립트를 테스트 테이블에 실행하여 실패 여부를 확인할 수 있습니다. 그러니 실행하세요.
안타깝습니다. 스크립트가 다음 오류로 인해 실패했습니다.

식별자를 참조하는 방식이 Snowpark에서 원하는 방식이 아닌 것 같습니다. 실패한 코드는 나머지 EWI가 있는 위치에 있습니다.

오류를 통해 제공된 링크의 설명서를 참조할 수 있지만, 시간을 절약하기 위해 Snowpark에서는 이 변수가 명시적으로 리터럴이어야 합니다. 다음과 같이 대체해야 합니다.
이 오류를 처리해야 합니다. 소스 플랫폼과 대상 플랫폼 간에는 항상 기능적 차이가 일부 있다는 점에 유의합니다. SMA와 같은 변환 도구는 이러한 차이를 최대한 명확히 보여주려고 합니다. 그러나 어떤 변환도 100% 자동화되지는 않습니다.
다시 실행해 보겠습니다. 이번에는 성공입니다.

이를 확인하기 위해 Python으로 몇 가지 쿼리를 작성할 수 있지만, 그냥 Snowflake로 이동하는 것이 어떨까요? (어차피 곧 그렇게 할 것이기 때문입니다.)
해당 스크립트를 실행하는 데 사용한 Snowflake 계정으로 이동합니다. SQL Server에서 데이터베이스를 로드하는 데 사용한 계정과 동일해야 합니다. 그렇지 않은 경우 데이터가 아직 마이그레이션되지 않았으므로 위의 스크립트는 작동하지 않습니다.
You can quickly check this by seeing if the stage was created with the file:
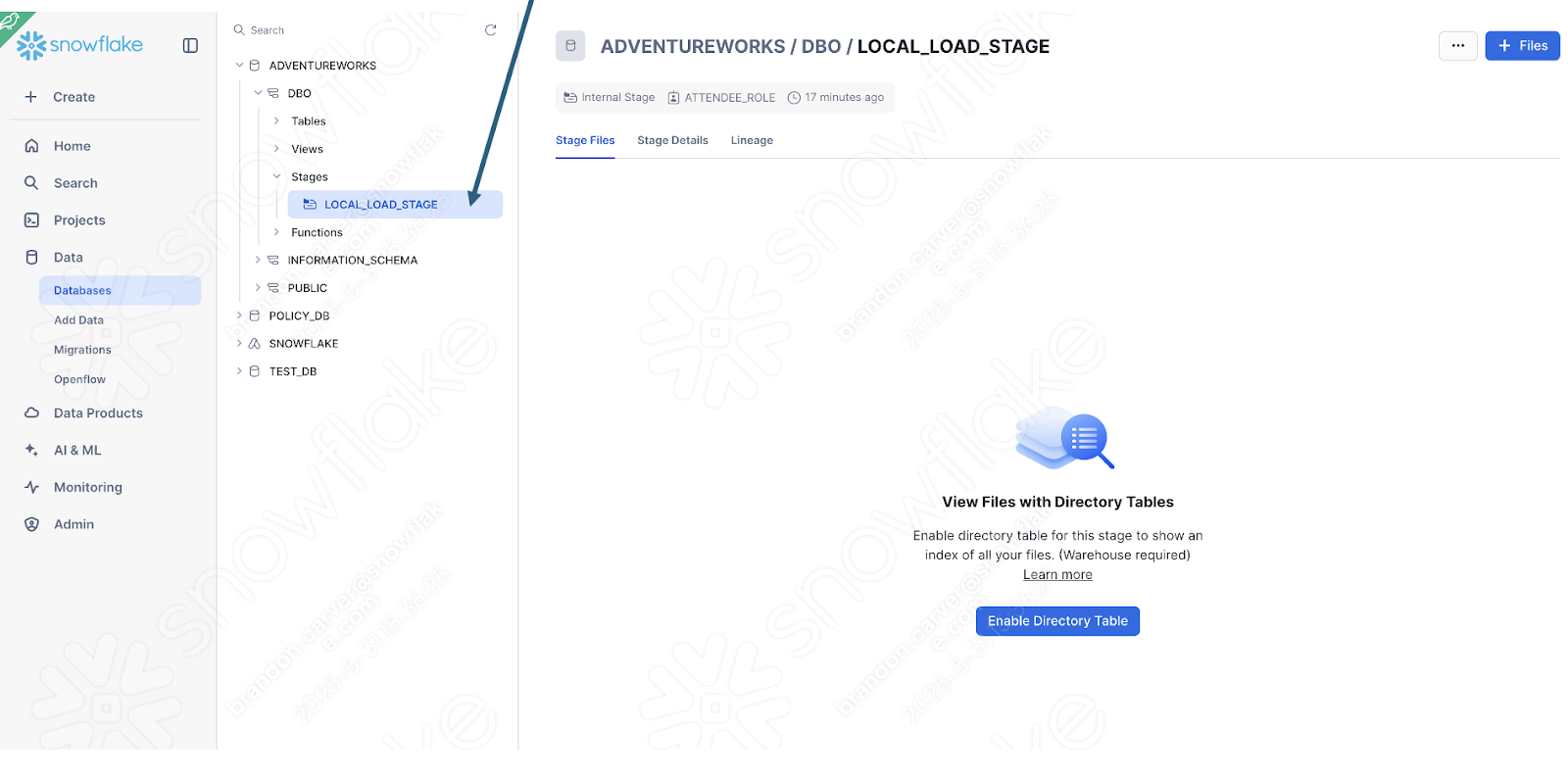
Enable the directory table view to see if the old_versions folder is in there:
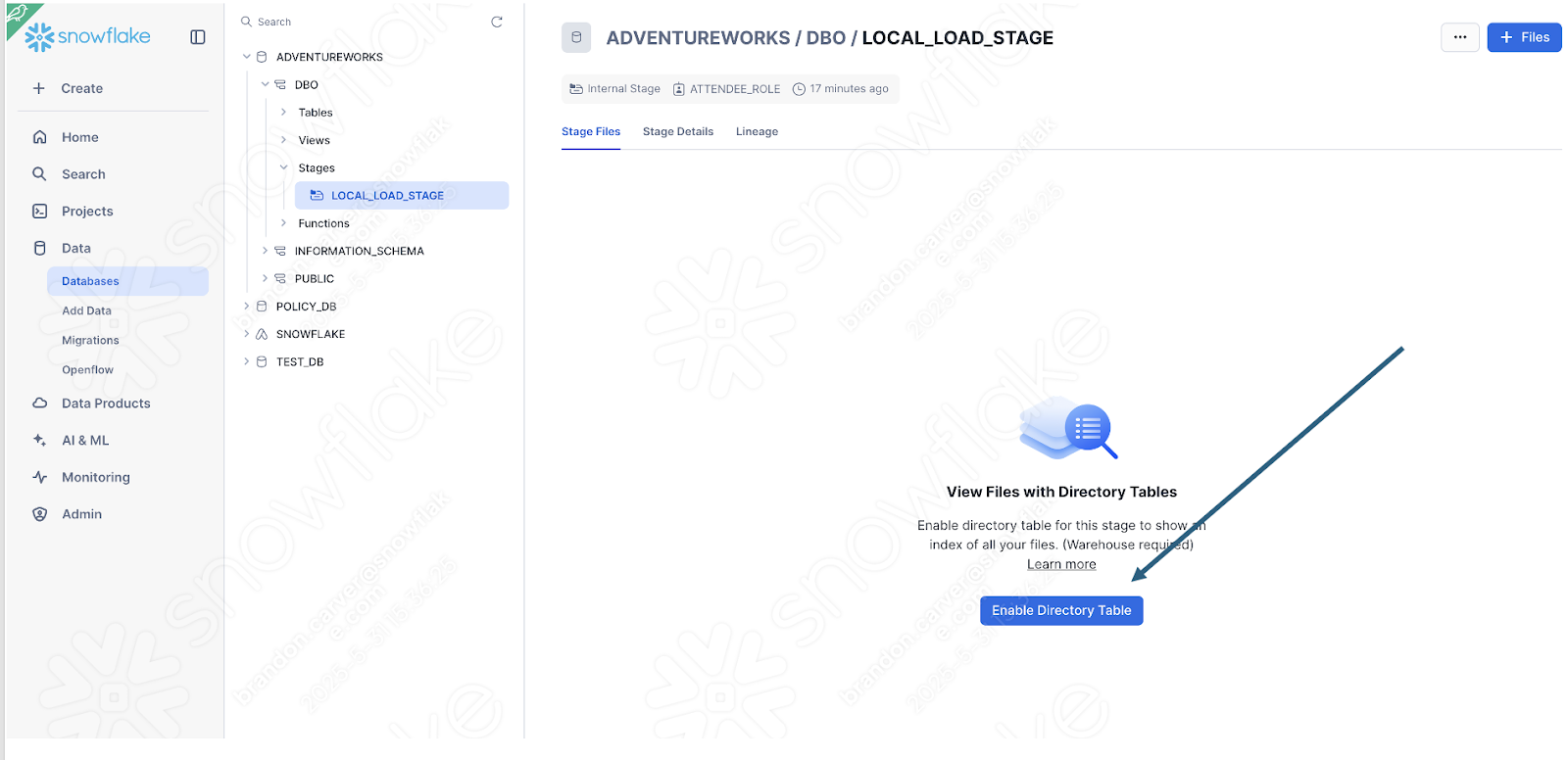
다음과 같습니다.
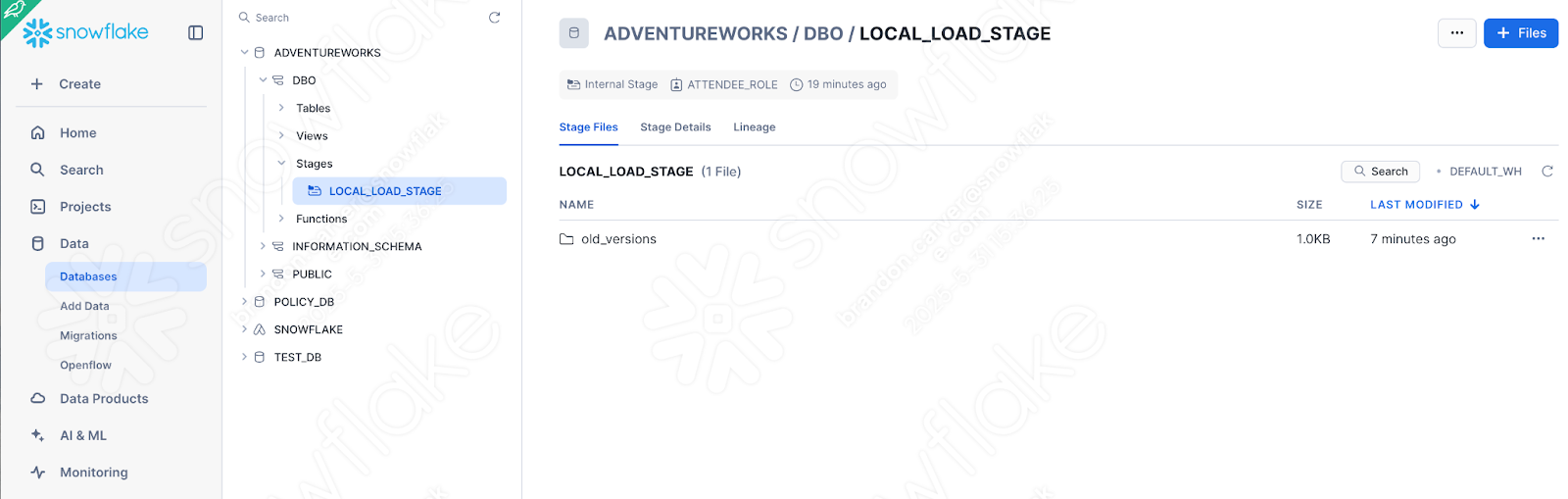
이것이 스크립트의 마지막 요소였기 때문에 이제 다 된 것 같습니다.
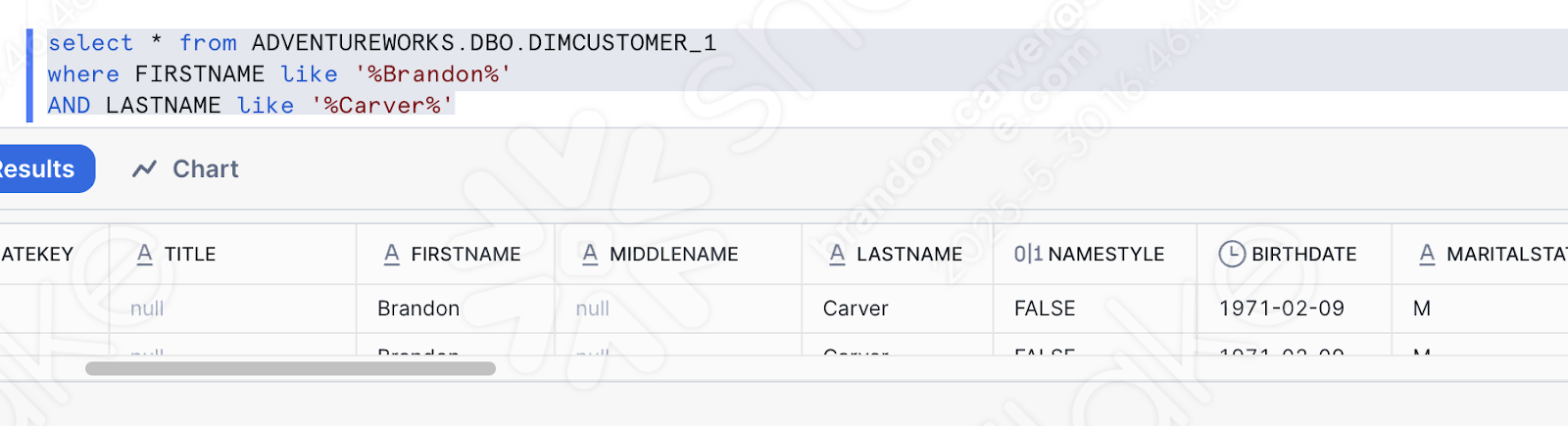
테이블에 업로드한 데이터를 쿼리하여 데이터가 로드되었는지 간단히 확인할 수도 있습니다. 새 워크시트를 열고 다음 쿼리를 작성하기만 하면 됩니다.
이것은 방금 로드된 이름 중 하나입니다. 파이프라인이 제대로 작동한 것 같습니다.
Snowsight에서 파이프라인 스크립트 실행¶
변환하려는 흐름이 Spark에서 어떻게 수행되었는지 살펴보겠습니다.
로컬 파일에 액세스
결과를 SQL Server에 로드하기
다음 파일을 위한 공간을 만들기 위해 파일 이동하기
이 흐름은 Snowsight 내에서 완전히 실행할 수는 없습니다. Snowsight는 로컬 파일 시스템에 액세스할 수 없습니다. 여기서는 POS에서 데이터 레이크로 내보내기를 이동하거나 Snowsight를 통해 액세스할 수 있는 다른 여러 옵션을 사용하는 것이 좋습니다.
그러나 Snowflake에서 Python 스크립트를 실행하여 Snowpark가 변환 논리를 처리하는 방법을 더 자세히 살펴볼 수 있습니다. 위에서 권장하는 변경 사항을 이미 수행한 경우 Snowflake의 Python 워크시트에서 스크립트 본문을 실행할 수 있습니다.
이를 수행하려면 먼저 Snowflake 계정에 로그인하고 워크시트 섹션으로 이동합니다. 이 워크시트에서 새 Python 워크시트를 만듭니다.

사용할 데이터베이스, 스키마, 역할, 웨어하우스를 지정합니다.
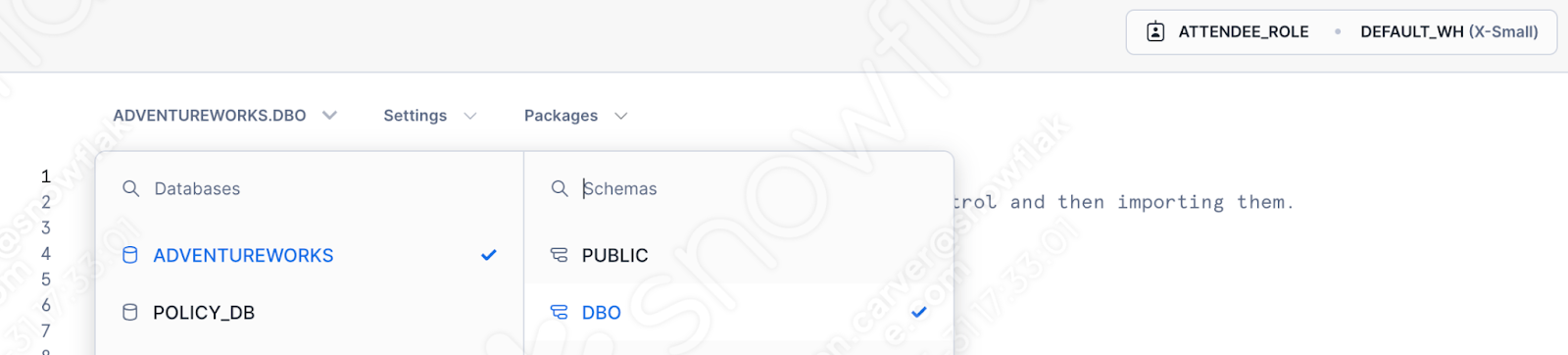
이제 세션 호출을 처리할 필요가 없습니다. 워크시트 창에 생성된 템플릿이 표시됩니다.

먼저 import 호출을 가져와 보겠습니다. 이전 스크립트를 사용할 준비가 되면 다음과 같은 가져오기 세트가 있어야 합니다.
여기서는 Snowpark import만 필요합니다. 파일 시스템에서 파일을 이동하지 않습니다. 스테이지에서 파일을 이동하려는 경우 datetime 참조를 유지하면 됩니다. (해봅시다.)
Python 워크시트의 Snowpark import(및 datetime)를 이미 있는 다른 import 아래에 붙여넣습니다. ‘col’은 이미 가져왔으므로 다음 중 하나를 제거할 수 있습니다.
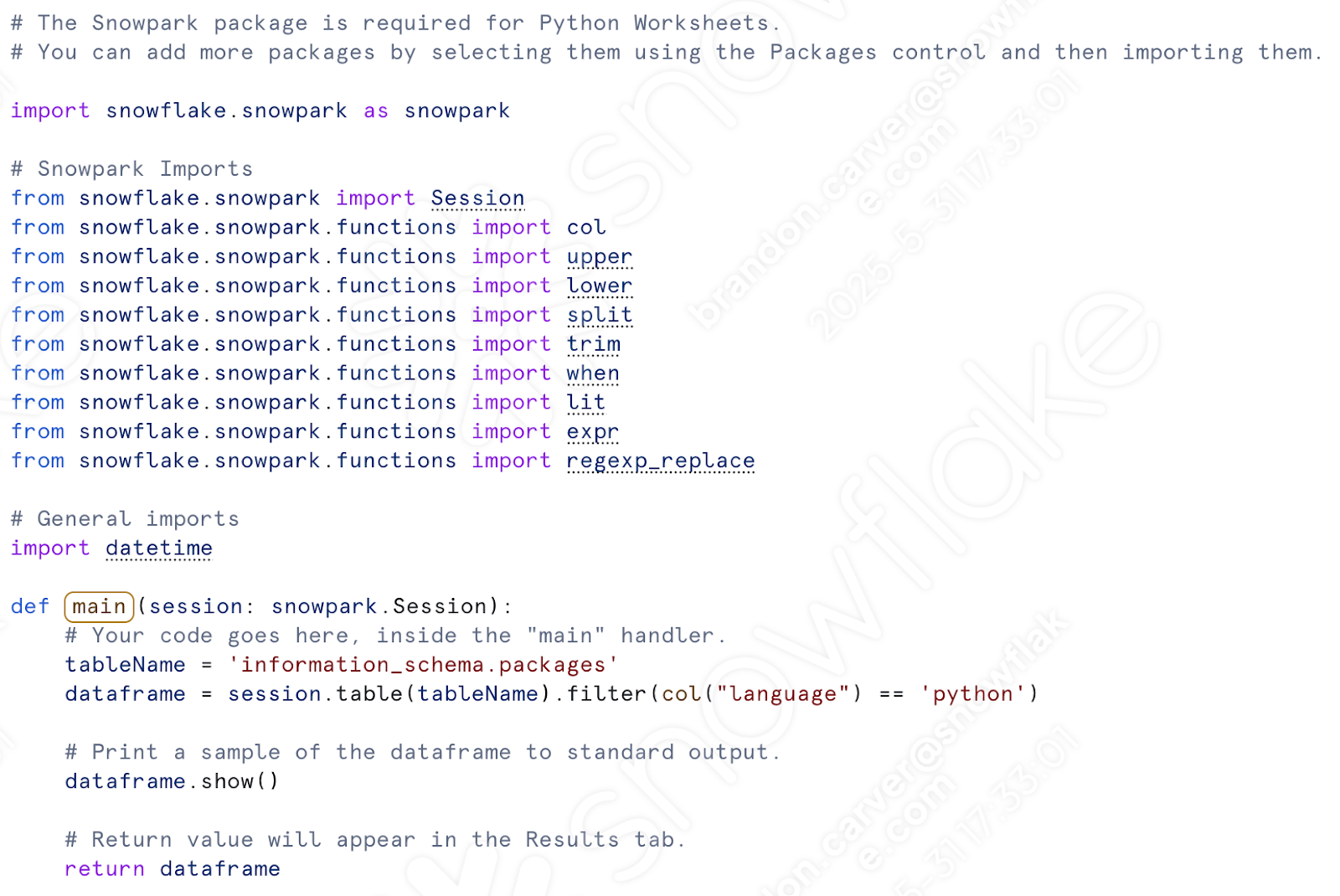
Under the “def main” call, let’s paste in all of our transformation code. This will include everything from the assignment of the csv location to the writing of the dataframe to a table.
여기에서:

여기로:

스테이지에서 파일을 이동하는 코드를 다시 추가할 수도 있습니다. 이 부분은 다음과 같습니다.
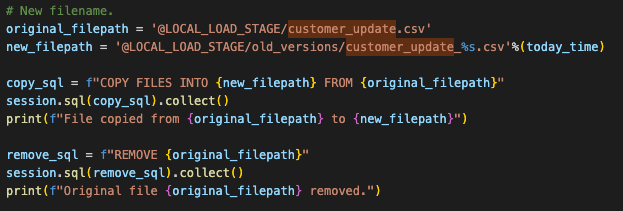
Before you can run the code though, you will have to manually create the stage and move the file into the stage. We can add the create stage statement into the script, but we would still need to manually load the file into the stage.
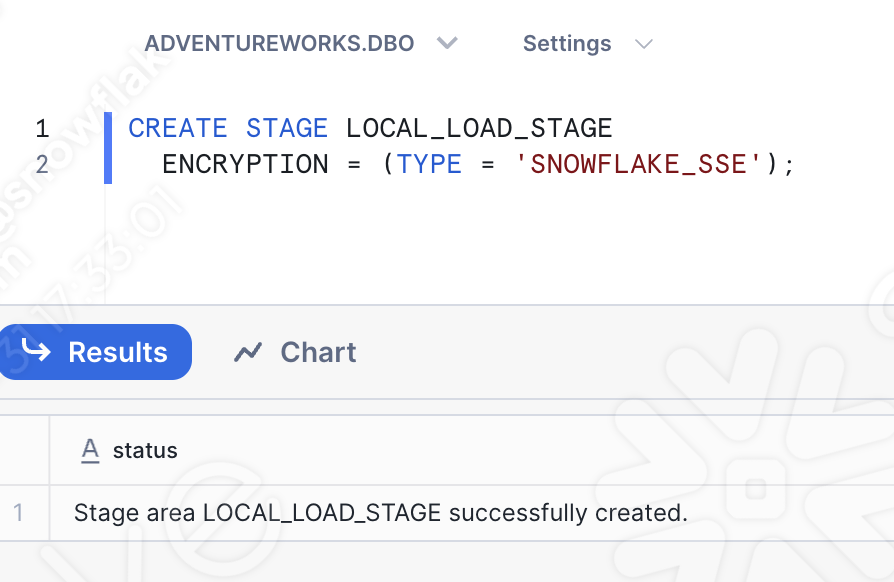
따라서 다른 워크시트(이번에는 sql 워크시트)를 열면 스테이지를 생성하는 기본 SQL 문을 실행할 수 있습니다.
적합한 데이터베이스, 스키마, 역할, 웨어하우스를 선택해야 합니다.
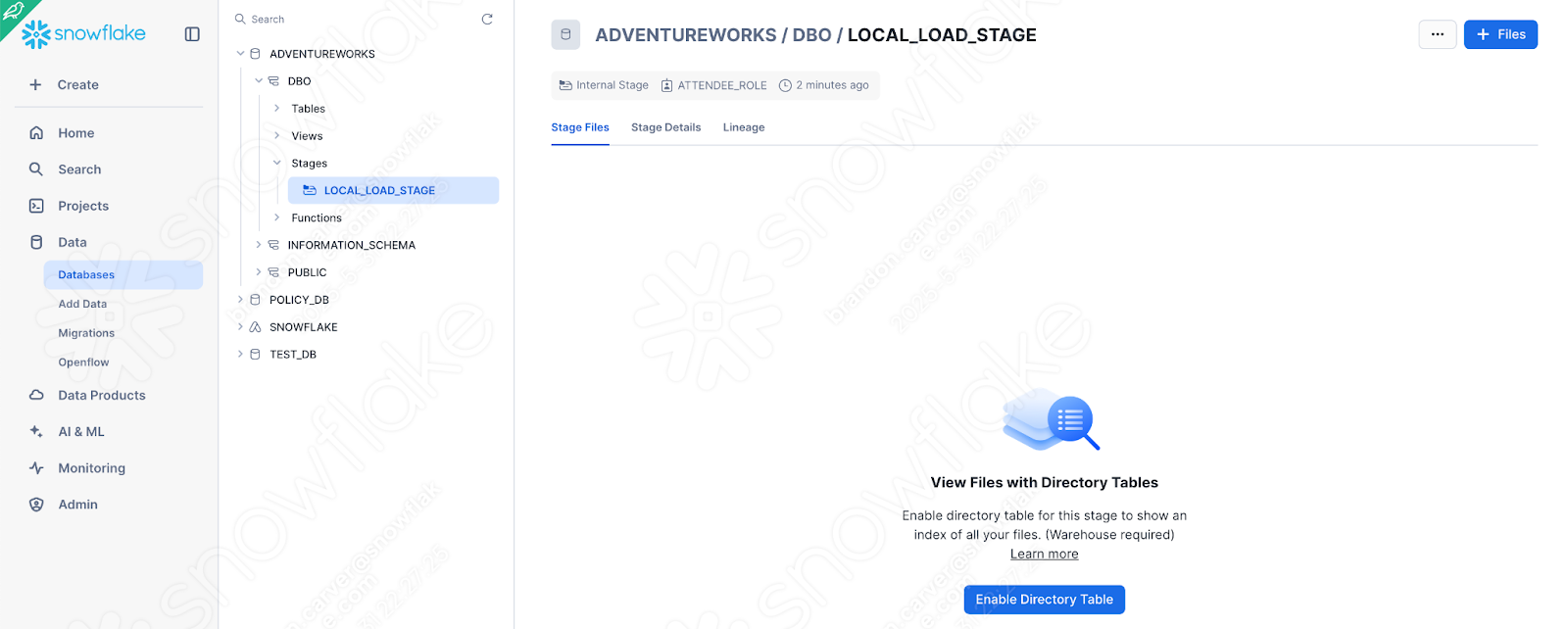
You can also create an internal stage directly in the Snowsight UI. Now that the stage exists, we can manually load the file of interest into the stage. Navigate to the Databases section of the Snowsight UI, and find the stage we just created in the appropriate database.schema:
창의 오른쪽 상단에서 +Files 옵션을 선택하여 csv 파일을 추가해 보겠습니다. 그러면 파일 업로드 메뉴가 시작됩니다.
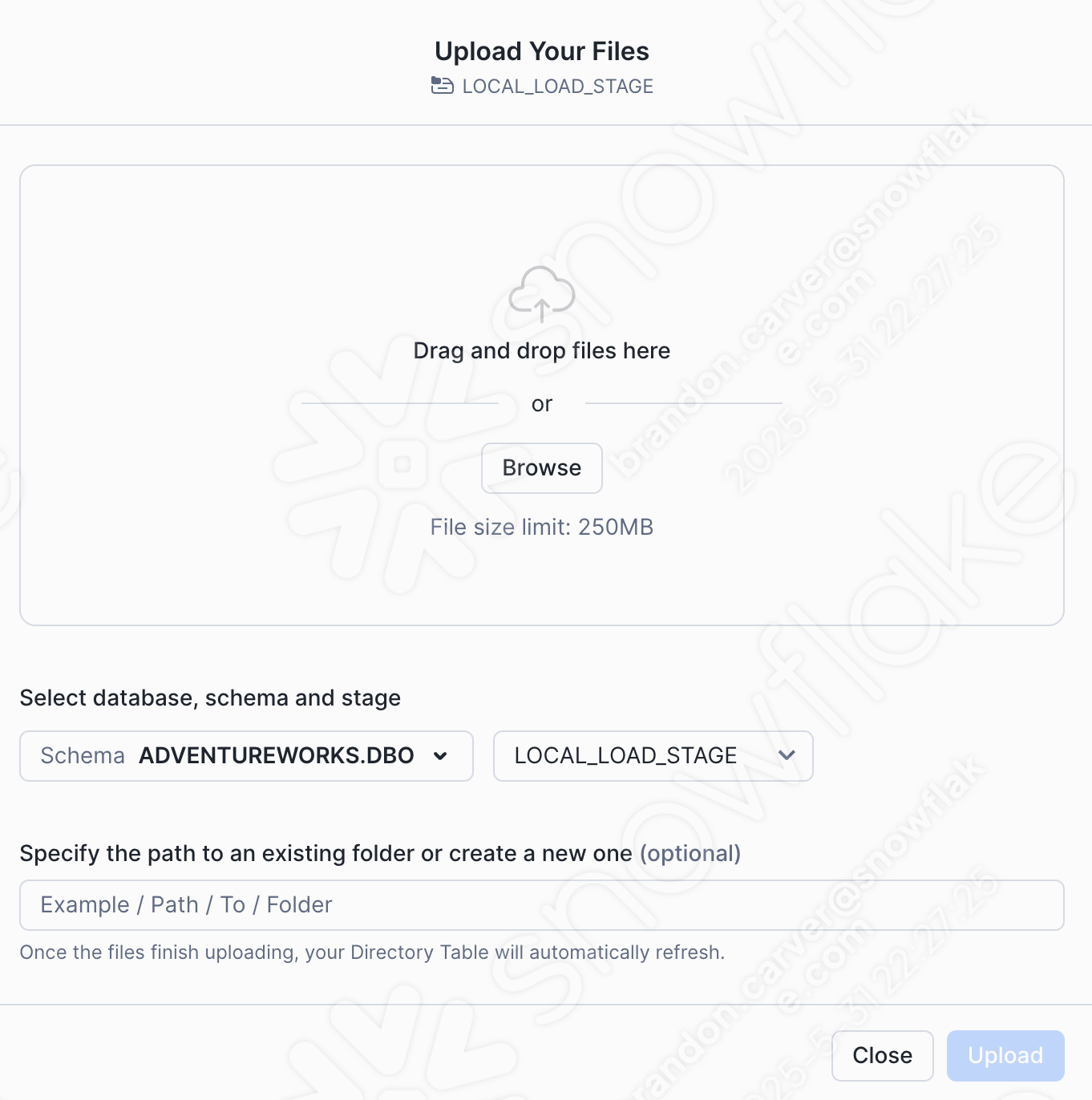
Drag and drop or browse to our project directory and load the customer_update.csv file into the stage:
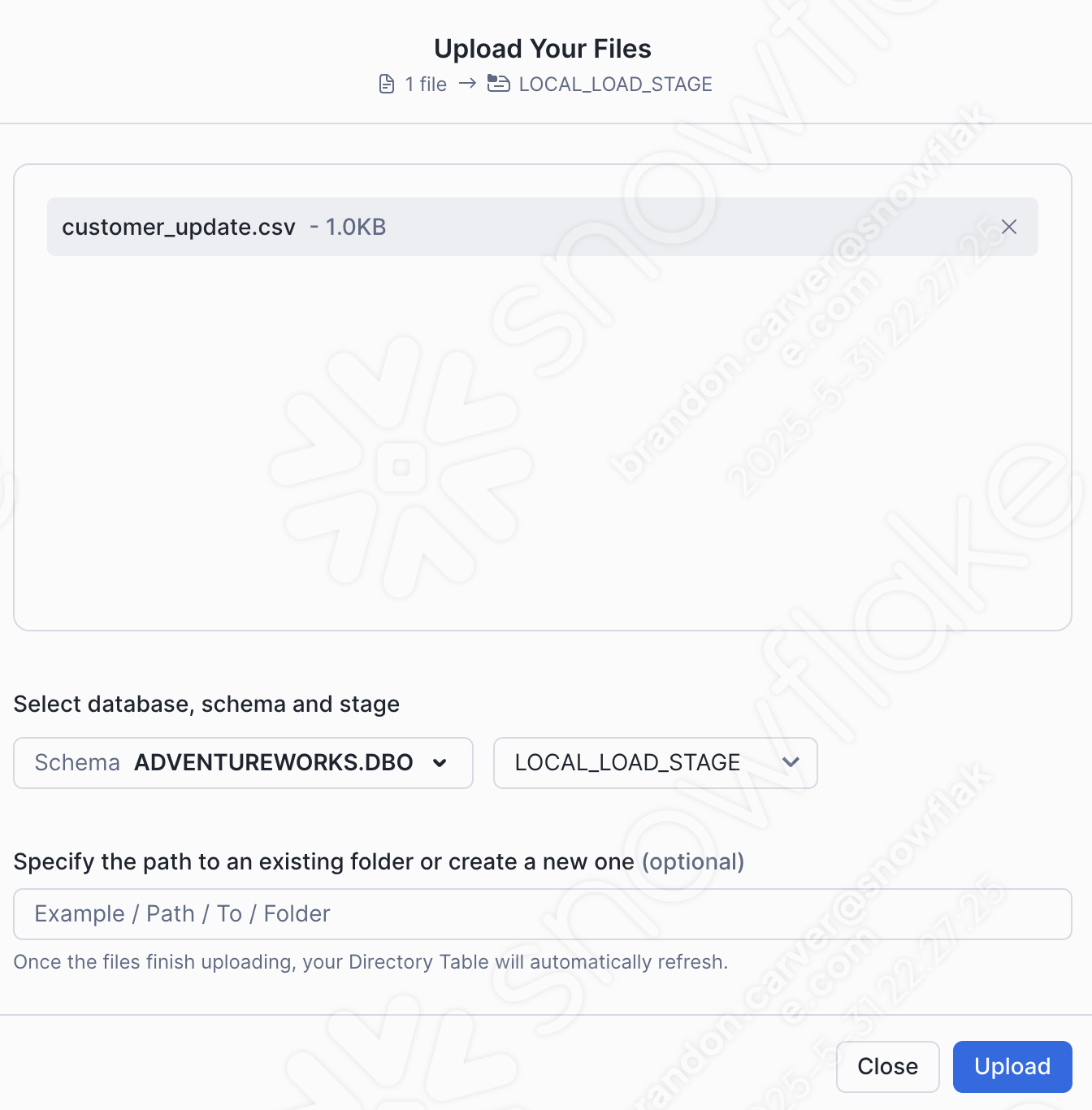
화면의 오른쪽 하단에서 Upload를 선택합니다. 스테이지 화면으로 돌아갑니다. 파일을 보려면 Enable Directory Table을 선택해야 합니다.
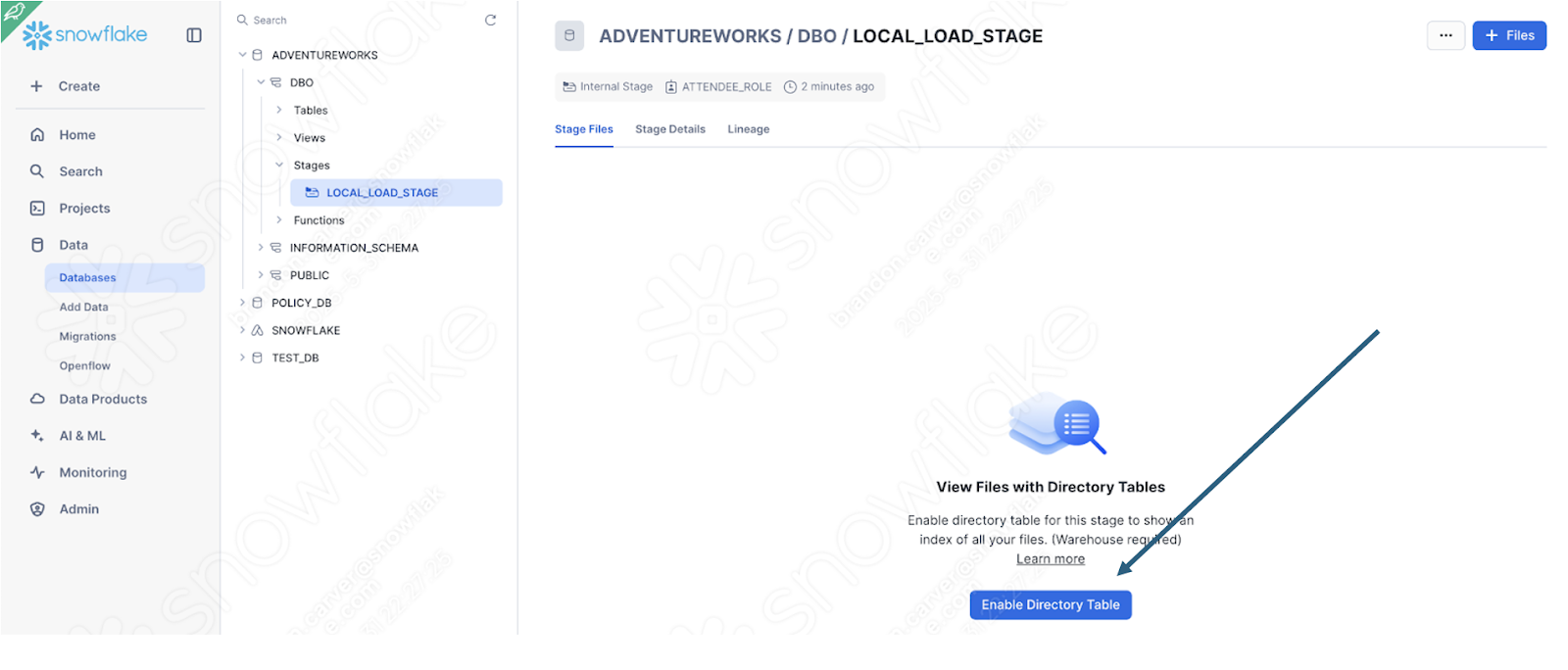
이제 파일이 스테이지에 나타납니다.

물론 이제 더 이상 파이프라인이 아닙니다. 그러나 최소한 Snowflake에서 로그인을 실행할 수 있습니다. 워크시트로 이동한 나머지 코드를 실행합니다. 이 사용자는 처음에는 성공했지만, 두 번째에는 성공이 보장되지 않습니다.
Snowflake에서 이 함수를 정의한 후에는 다른 방법으로 호출할 수 있습니다. AdventureWorks가 해당 POS를 100% 대체하는 경우, 특히 오케스트레이션 및 파일 이동이 완전히 다른 곳에서 처리되는 경우 Snowflake에 변환 논리를 사용하는 것이 합리적일 수 있습니다. 이를 통해 Snowpark는 변환 논리에서 뛰어난 부분에 집중할 수 있습니다.
결론¶
스크립트 파일에 대한 설명은 여기까지입니다. 파이프라인의 가장 좋은 예는 아니지만, SMA의 출력을 처리하는 방법을 명확하게 다룹니다.
모든 문제 해결
세션 호출 해결
입력 및 출력 해결
정리 및 테스트
이제 보고 노트북으로 넘어가 보겠습니다.