Snowpark Migration Accelerator: conversão de pipelines¶
O SMA “converteu” nossos scripts, mas será mesmo? O que ele fez, na verdade, foi converter todas as referências à API do Spark para a API do Snowpark, mas ele não substituiu as conexões que possam existir em seus pipelines.
O poder do SMA reside nos relatórios de avaliação que ele gera, já que a conversão está atrelada à conversão de referências à API do Spark para a API do Snowpark. Observe que a conversão dessas referências não será suficiente para executar nenhum pipeline de dados. Você precisará garantir que as conexões do pipeline sejam resolvidas manualmente. O SMA não pode presumir conhecer os parâmetros de conexão ou outros elementos que provavelmente não estão disponíveis para serem executados por meio dele.
Como em qualquer conversão, é possível lidar com o código convertido de várias maneiras. As etapas a seguir são como recomendamos que você aborde a saída da ferramenta de conversão. Assim como o SnowConvert, o SMA requer atenção à saída. Nenhuma conversão será 100% automatizada. Isso é particularmente verdadeiro para o SMA. Como o SMA converte referências à API do Spark para a API do Snowpark, você sempre precisará verificar como essas referências estão sendo executadas. Ele não tenta orquestrar a execução bem-sucedida de nenhum script ou notebook executado por meio dele.
Portanto, seguiremos estas etapas para analisar a saída do SMA, que será ligeiramente diferente da saída do SnowConvert:
Resolver todos os problemas: «problemas» aqui significa os problemas gerados pelo SMA. Analise o código de saída. Resolva os erros de análise e conversão e investigue os avisos.
Resolver as chamadas de sessão: a forma como a chamada de sessão é escrita no código de saída depende de onde vamos executar o arquivo. Vamos resolver isso para executar os arquivos de código na mesma localização em que seriam executados originalmente e, em seguida, para executá-los no Snowflake.
Resolver as entradas/saídas: não é possível resolver as conexões com diferentes fontes completamente pelo SMA. Existem diferenças entre as plataformas, e o SMA geralmente ignora isso. Isso também é afetado por onde o arquivo será executado.
Limpar e testar: vamos executar o código. Veja se funciona. Neste laboratório, faremos testes básicos, mas existem ferramentas para realizar testes e validações de dados mais extensivos, incluindo o Snowpark Python Checkpoints.
Então, vamos dar uma olhada em como isso funciona. Faremos isso com duas abordagens: a primeira é executar isso em Python na máquina local (enquanto o script de origem está sendo executado). A segunda seria fazer tudo no Snowflake… no Snowsight, mas para um pipeline de dados que lê de uma fonte local, isso não será 100% possível no Snowsight. Mas tudo bem. Não estamos convertendo a orquestração deste script neste POC.
Vamos começar com o arquivo de script do pipeline e, na próxima seção, abordaremos o notebook.
Resolver problemas¶
Vamos abrir nosso código-fonte e nosso código de saída em um editor de código. Você pode usar qualquer editor de código de sua preferência, mas, como já foi mencionado diversas vezes, a Snowflake recomenda o uso do VS Code com a extensão Snowflake. A extensão Snowflake não só ajuda a navegar pelos problemas do SnowConvert, como também pode executar Snowpark Checkpoints para Python, o que auxilia nos testes e na análise da causa raiz (embora esteja um pouco fora do escopo deste laboratório).
Vamos abrir o diretório que criamos originalmente na tela de criação do projeto (Spark ADW Lab) no código VS:
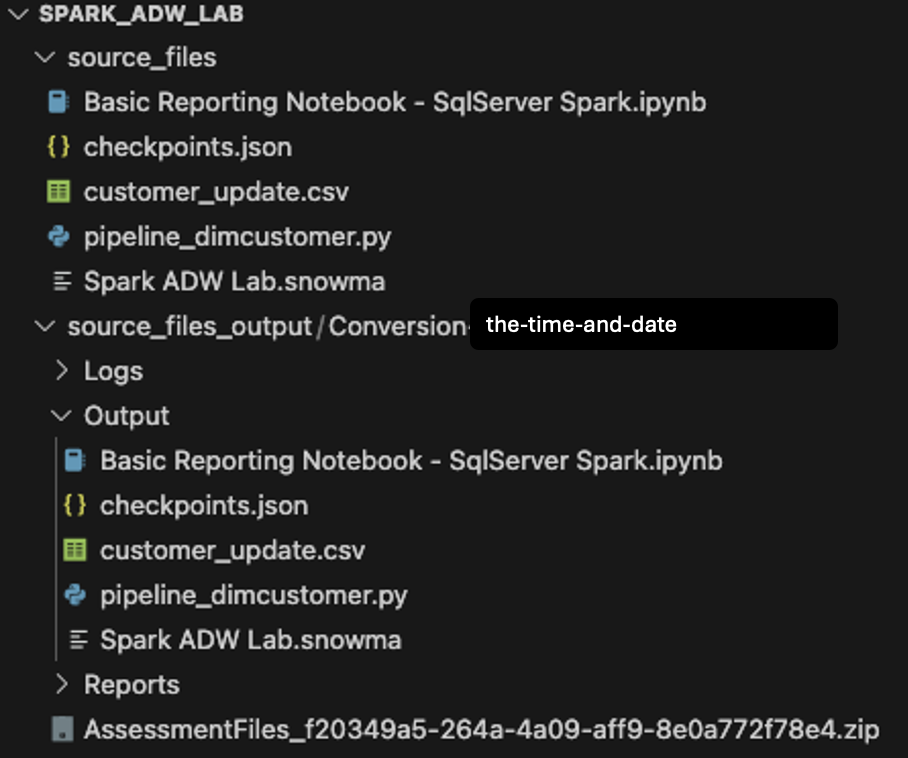
Observe que a estrutura do diretório de saída será a mesma do diretório de entrada. Até mesmo o arquivo de dados será copiado, apesar de nenhuma conversão ocorrer. Também haverá alguns arquivos checkpoints.json criados pelo SMA. Esses são arquivos JSON que contêm instruções para a extensão Snowpark Checkpoints. A extensão Snowflake pode carregar pontos de verificação tanto no código-fonte quanto no código de saída com base nos dados desses arquivos. Vamos ignorá-los por enquanto.
Por fim, vamos comparar o script Python de entrada com o script convertido na saída.
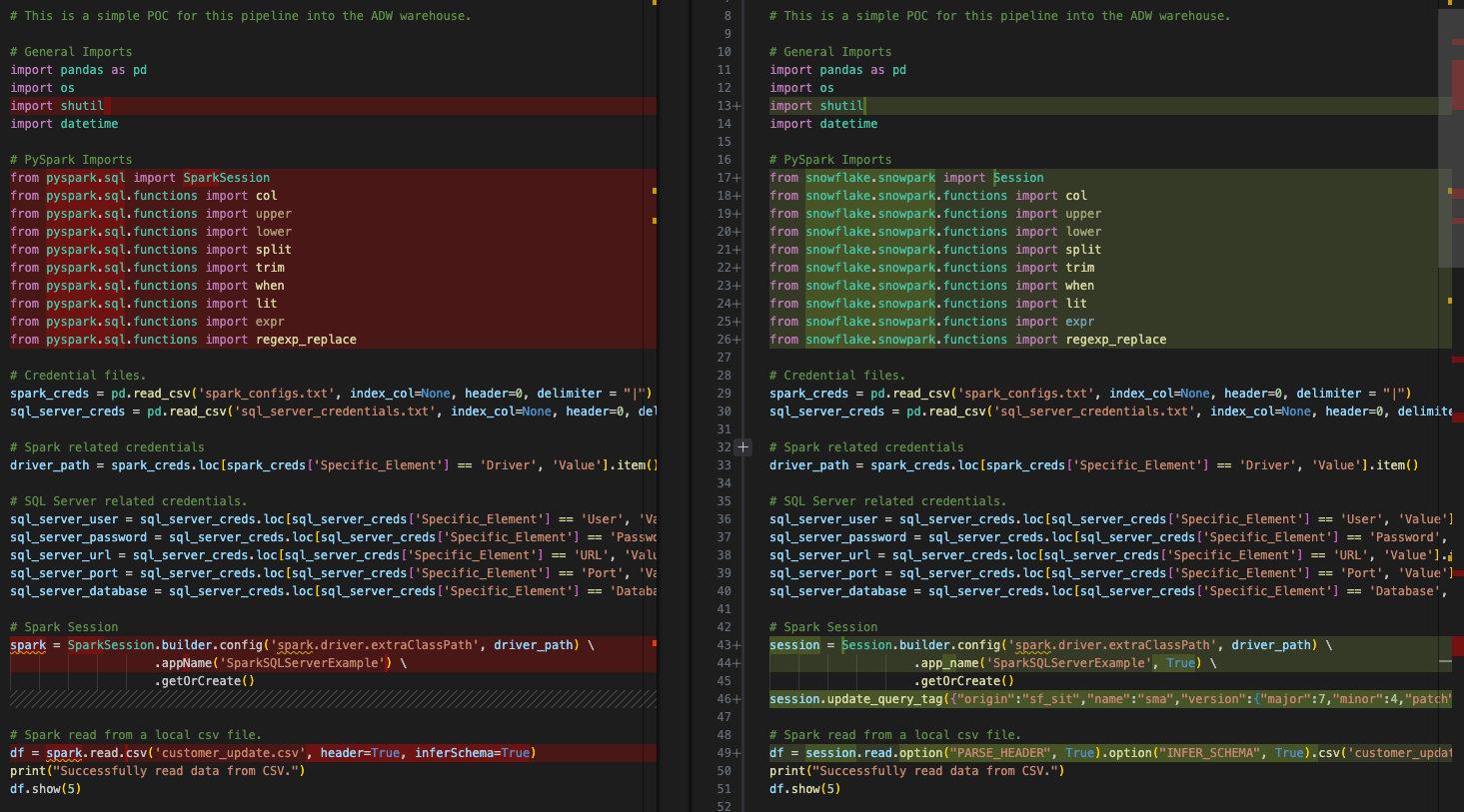
Esta é uma comparação lado a lado bem básica, com o código Spark original à esquerda e o código compatível com Snowpark à direita. Parece que algumas importações foram convertidas, assim como as chamadas de sessão. Podemos ver um EWI na parte inferior da imagem acima, mas não vamos começar por aí. Precisamos encontrar o erro de análise antes de fazer qualquer outra coisa.
Podemos pesquisar no documento o código de erro para esse erro de análise que foi mostrado tanto no UI quanto no issues.csv: SPRKPY1101.
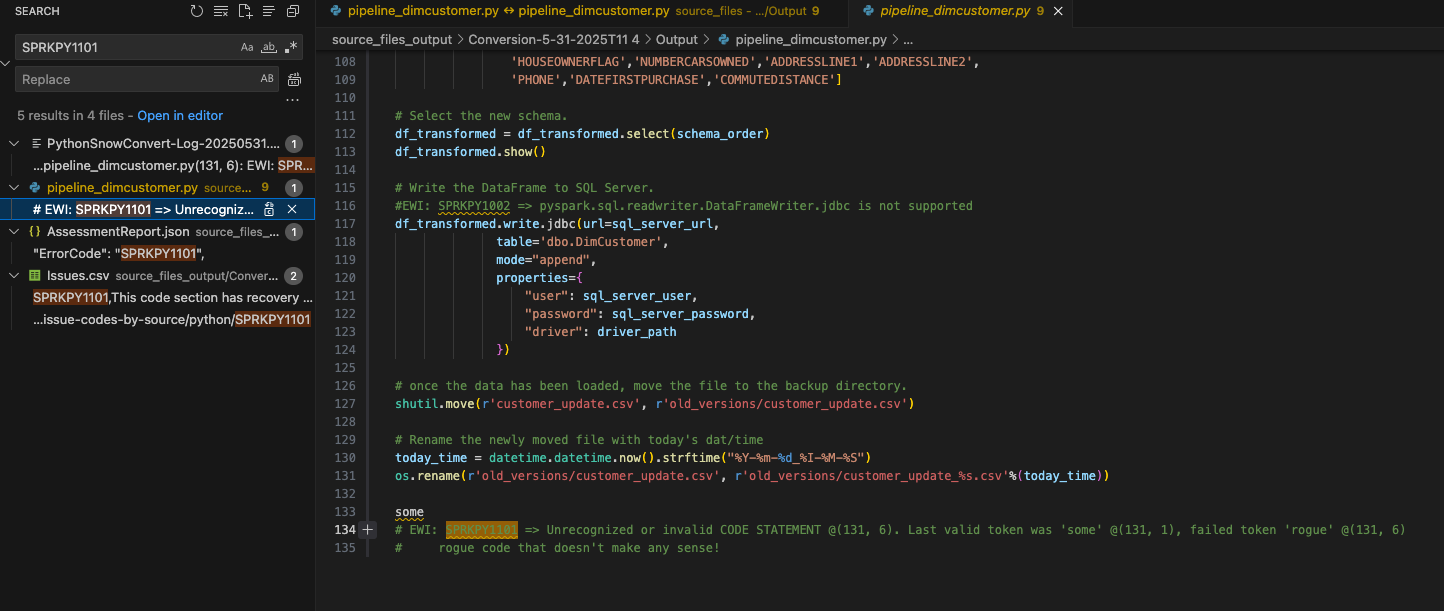
Since I have not filtered the results, the listing of this error code in the issues.csv also comes up in the search and the AssessmentReport.json that is used to build the AssessmentReport.docx summary assessment report. This is the main report that users will navigate through to understand a large workload, but we did not look at it in this lab. (More info on the this report can be found in the SMA documentation.) Let’s choose where this EWI shows up in the pipeline_dimcustomer.py file as shown above.
You can see that this line of code was present at the bottom of the source code.
Parece que esse erro de análise foi causado por… “algum código inválido que não faz sentido!”. Esta linha de código está no fim do arquivo do pipeline. Não é incomum haver caracteres extras ou outros elementos em um arquivo de código como parte de uma extração de uma fonte. Observe que o SMA detectou que este não era um código Python válido e gerou o erro de análise.
Você também pode ver como o SMA insere o código de erro e a descrição no código de saída como um comentário onde o erro ocorreu. É assim que todas as mensagens de erro aparecerão na saída.
Como este não é um código válido, ele está no final do arquivo e nada mais foi removido como resultado deste erro; o código original e o comentário podem ser removidos com segurança do arquivo de código de saída.
E agora resolvemos nosso primeiro e mais sério problema. Anime-se.
Vamos analisar o restante dos nossos EWIs neste arquivo. Podemos procurar por “EWI” porque agora sabemos que esse texto aparecerá no comentário sempre que houver um código de erro. Como alternativa, poderíamos classificar o arquivo issues.csv e ordenar os problemas por gravidade, mas isso não é realmente necessário aqui.
O próximo é, na verdade, apenas um aviso, não um erro. Ele nos informa que foi utilizada uma função que nem sempre é equivalente no Spark e no Snowpark:
A descrição aqui, no entanto, indica que provavelmente não precisamos nos preocupar com isso. Há apenas dois parâmetros sendo passados. Vamos deixar este EWI como um comentário no arquivo, para que saibamos que devemos verificá-lo quando executarmos o arquivo posteriormente.
O último para este arquivo é um erro de conversão dizendo que algo não é compatível:

Esta é a chamada de gravação para o driver JDBC do Spark para gravar o dataframe de saída no SQL Server. Como isso faz parte da etapa de “resolver todas as entradas/saídas” que abordaremos após solucionarmos nossos problemas, vamos deixar isso para depois. Observe, no entanto, que esse erro deve ser resolvido. O anterior era apenas um aviso e pode funcionar mesmo sem nenhuma alteração.
Resolução das chamadas de sessão¶
As chamadas de sessão são convertidas pelo SMA, mas você deve prestar atenção especial a elas para garantir que estejam funcionando corretamente. Em nosso script de pipeline, este é o código antes e depois:

A referência do SparkSession foi alterada para Session. Você também pode ver essa alteração de referência perto do início deste arquivo na instrução de importação:

Observe na imagem acima que a atribuição da variável da chamada de sessão para “spark” não foi alterada. Isso ocorre porque se trata de uma atribuição de variável. Não é necessário alterá-la, mas se você quiser alterar o decorador “spark” para “session”, isso estará mais de acordo com o que o Snowpark recomenda. Observe que a extensão “Assistente do SMA” do VS Code também sugerirá essas alterações.
Este é um exercício simples, mas vale a pena fazer. Você pode usar a função de busca do VS Code para localizar e substituir as referências a “spark” neste arquivo e substituí-las por “session”. Você pode ver o resultado disso na imagem abaixo. As referências à variável “spark” no código convertido foram substituídas por “session”:

Também podemos remover outro objeto desta chamada de sessão. Como não vamos mais executar “spark”, não precisamos especificar o caminho para o driver spark. Portanto, podemos remover completamente a função de configuração da chamada de sessão assim:
Might as well convert it to a single line. The SMA couldn’t be sure we didn’t need that driver (although that seems logical), so it did not remove it. But now that we have our session call is complete.
Observe que o SMA também adiciona uma “tag de consulta” à sessão. Isso serve para ajudar na solução de problemas com essa sessão ou consulta posteriormente, mas é completamente opcional manter ou remover essa tag.
Notas sobre as chamadas de sessão¶
Acredite ou não, isso é tudo o que precisamos alterar no código para a chamada de sessão, mas não é tudo o que precisamos fazer para criar a sessão. Isso se refere à pergunta original de que muito disso depende de onde você deseja executar esses arquivos. Essas chamadas de sessão Spark originais usavam uma configuração que foi definida em outro lugar. Se você observar a chamada de sessão Spark original, verá que ela procura um arquivo de configuração que está sendo lido em um dataframe do pandas no início deste arquivo de script (isso também se aplica ao nosso arquivo de notebook).
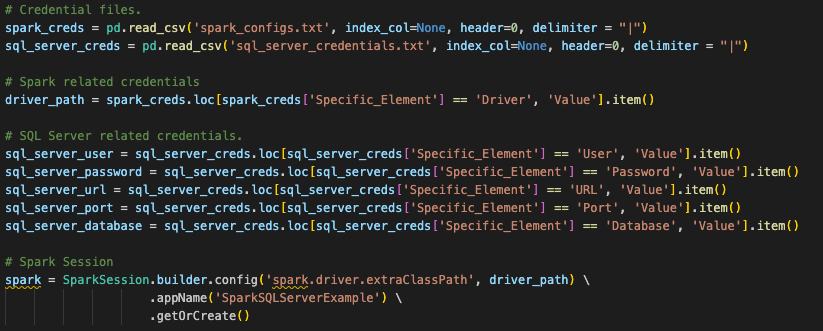
Snowpark can function the same way, and this conversion assumes that is how this user will run this code. However, for the existing session call to work, the user would have to load all of the information for their Snowflake account into the local (or at least accessible) connections.toml file on this machine, and that the account they are attempting to connect to is set as the default. You can learn more about updating the connections.toml file in the Snowflake/Snowpark documentation, but the idea behind it is that there is an accessible location that has the credentials. When a snowpark session is created, it is going to check this… unless the connection parameters are explicitly passed to the session call.
A maneira padrão de fazer isso é inserir os parâmetros de conexão diretamente como cadeias de caracteres e chamá-los com a sessão:
AdventureWorks appears to have referenced a file with these credentials and called it. Assuming there is a similar file called “snowflake_credentials.txt” that is accessible, then the syntax that would match that could look something like:
For the purpose of the time limit on this lab, the first option may make more sense. There’s more on this in the Snowpark documentation.
Observe que, para que nosso arquivo de notebook seja executado dentro do Snowflake usando o Snowsight, você não precisaria fazer nada disso. Você simplesmente chamaria a sessão ativa e a executaria.
Agora é hora do componente mais crítico desta migração: resolver quaisquer referências de entrada/saída.
Resolução de entradas e saídas¶
Vamos resolver nossas entradas e saídas agora. Observe que isso pode variar dependendo se você está executando os arquivos localmente ou no Snowflake. Para o script Python, vamos verificar o que ganhamos/perdemos ao executá-lo diretamente no Snowsight: você não pode executar toda a operação no Snowsight (pelo menos não no momento). O arquivo .csv local não é acessível pelo Snowsight. Você terá que carregar o arquivo .csv em uma área de preparação manualmente. Essa provavelmente não é a solução ideal, mas podemos testar a conversão dessa forma.
Primeiro vamos preparar este arquivo para ser executado/orquestrado localmente e, em seguida, para ser executado no Snowflake.
Para resolver as entradas e saídas do script do pipeline, precisamos primeiro identificá-las. Elas são bem simples. Este script parece:
acessar um arquivo local
carregar o resultado no SQL Server (mas agora, Snowflake)
mover o arquivo para liberar espaço para o próximo
Simples o suficiente. Portanto, precisamos substituir cada componente do código que realiza essas ações. Vamos começar acessando o arquivo local.
Como mencionado no início, seria recomendável reestruturar o sistema de ponto de venda e as ferramentas de orquestração utilizadas para executar este script Python, de modo a colocar o arquivo de saída em um local de armazenamento em nuvem. Em seguida, você poderia transformar esse local em uma tabela externa e pronto… você estaria no Snowflake. No entanto, a arquitetura atual indica que este arquivo não está em um local de armazenamento em nuvem e permanecerá onde está; portanto, precisamos criar uma maneira para o Snowflake acessar o arquivo preservando a lógica existente.
Temos opções para fazer isso, mas criaremos uma área de preparação interna e moveremos o arquivo para a área de preparação com o script. Em seguida, precisaríamos mover o arquivo no sistema de arquivos local e também movê-lo para a área de preparação. Tudo isso pode ser feito com o Snowpark. Vamos analisar passo a passo:
acesso a um arquivo local: Crie uma área de preparação interna (se ainda não existir) -> Carregue o arquivo na área de preparação -> Leia o arquivo em um dataframe
carregamento do resultado no SQL Server: Carregar os dados transformados em uma tabela no Snowflake
move o arquivo para liberar espaço para o próximo: Mova o arquivo local -> Mova o arquivo na área de preparação.
Vamos analisar o código que pode fazer cada uma dessas ações.
Acessar um arquivo acessível localmente¶
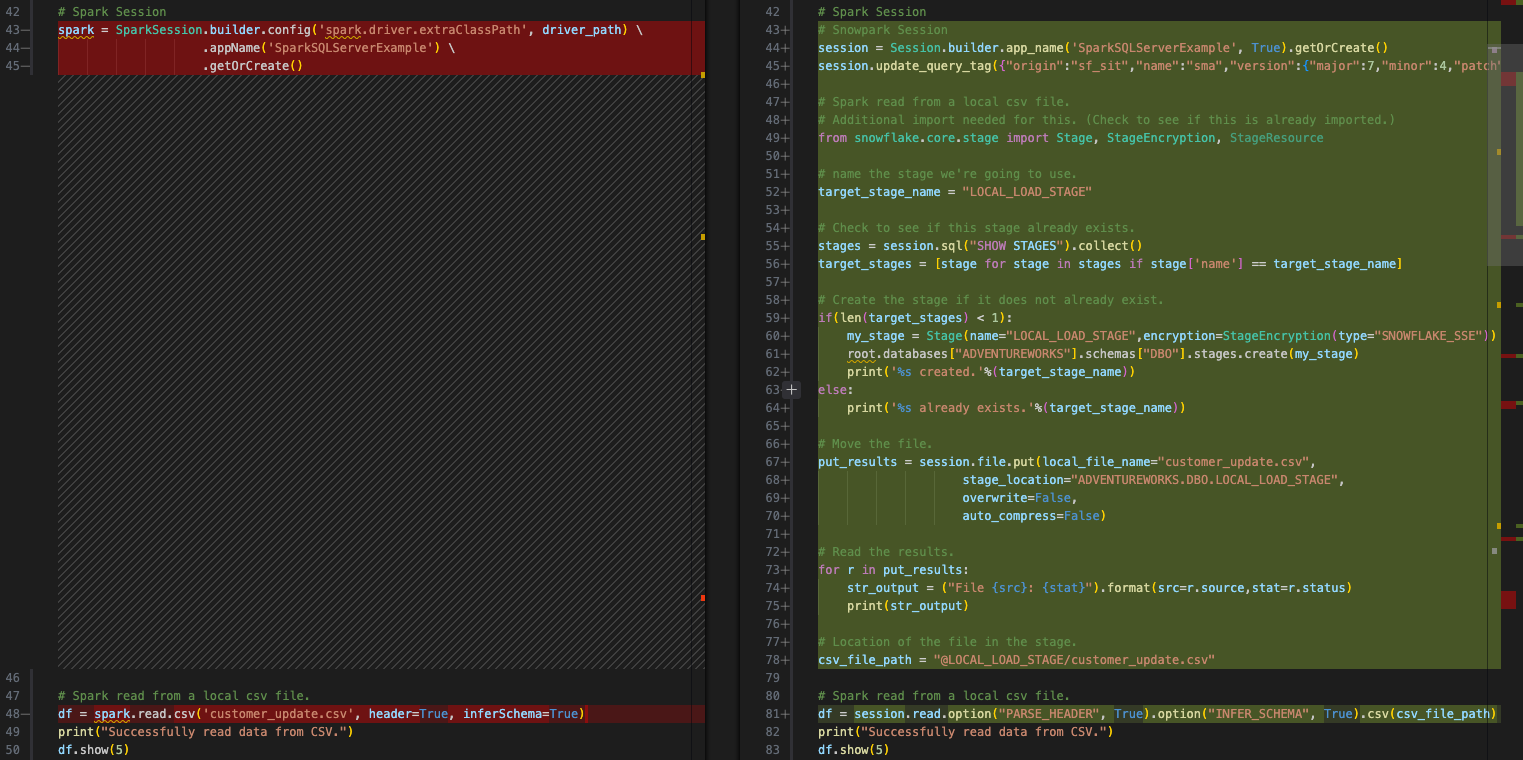
Esse código-fonte no Spark é semelhante a isto:
E o código do Snowflake transformado (pelo SMA) se parece com isto:
Podemos substituir isso por este código que executa as etapas acima:
Create an internal stage (if one does not exist already). We will create a stage called “LOCAL_LOAD_STAGE” and go through a few steps to make sure that the stage is r
Carregue o arquivo na área de preparação.
Leia o arquivo em um dataframe. Esta é a parte que o SMA realmente converteu. Precisamos especificar que a localização do arquivo agora é a área de preparação interna.
O resultado disso seria algo como:
Vamos ao próximo passo.
Carregamento do resultado no Snowflake¶
O script original gravou o dataframe no SQL Server. Agora vamos carregá-lo no Snowflake. Essa é uma conversão muito mais simples. O dataframe já é um dataframe do Snowpark. Essa é uma das vantagens do Snowflake. Agora que os dados estão acessíveis ao Snowflake, tudo acontece dentro dele.
Observe que podemos querer gravar em uma tabela temporária para fazer alguns testes/validações, mas este é o comportamento no script original.
Mover o arquivo para liberar espaço para o próximo¶
Este é o comportamento no script original. Não precisamos realmente fazer isso no Snowflake, mas podemos demonstrar a mesma funcionalidade na área de preparação. Isso é feito com um comando os no sistema de arquivos original. Isso não depende do Spark e permanecerá o mesmo. Mas para emular esse comportamento no Snowpark, precisaríamos mover esse arquivo da área de preparação para um novo diretório.
Isso pode ser feito de forma simples com o seguinte código Python:
Observe que isso não substituirá nenhum código existente. Como já queremos manter a movimentação existente do código Spark para o Snowpark, manteremos a referência ao os. A versão final ficará assim:
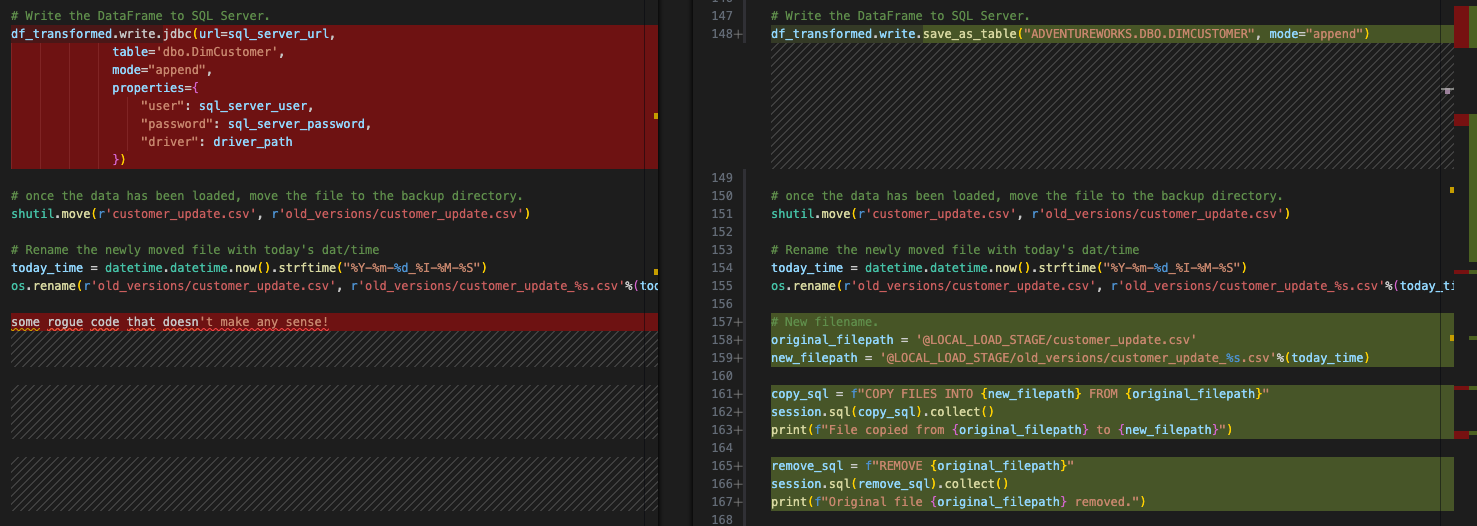
Agora temos a mesma movimentação completamente concluída. Agora vamos fazer nossa limpeza final e testar esse script.
Limpar e testar¶
Nunca analisamos nossas chamadas de importação e temos arquivos de configuração que não são necessários. Poderíamos manter as referências aos arquivos de configuração e executar o script. Na verdade, supondo que esses arquivos de configuração ainda estejam acessíveis, o código ainda será executado. Mas, se analisarmos atentamente nossas instruções de importação, podemos removê-las. Esses arquivos são representados por todo o código entre as instruções de importação e a chamada da sessão:
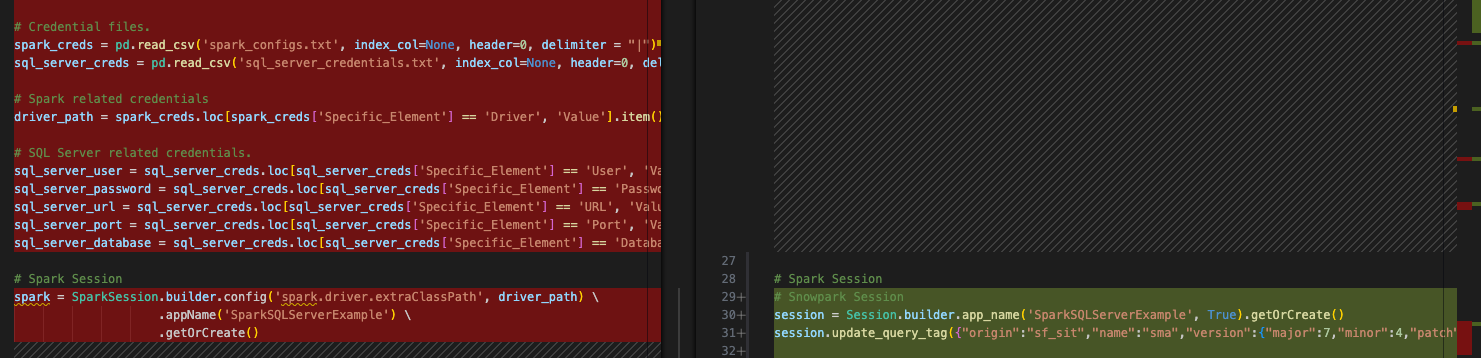
Há algumas outras ações que devemos realizar:
Verifique se todas as nossas importações ainda são necessárias. Podemos deixá-las por enquanto. Se houver um erro, podemos corrigi-lo.
Também temos um EWI que deixamos lá como um aviso para verificar. Portanto, precisamos garantir que vamos inspecionar essa saída.
We need to make sure that our file system behavior mirrors that of the expected file system for the POS system. To do this, we should move the customer_update.csv file into the root folder you chose when first launching VS Code.
Create a directory called “old_versions” in that same directory. This should allow the os operations to run.
Por fim, se você não se sentir confortável em executar o código diretamente na tabela de produção, crie uma cópia da tabela para esse teste e direcione o carregamento para essa cópia. Substitua a instrução de carregamento pela seguinte. Como se trata de um laboratório, fique à vontade para gravar na tabela “production”:
Agora estamos finalmente prontos para testar. Podemos executar este script em Python em uma tabela de teste e ver se ele falha. Então execute!
Trágico! O script falhou com o seguinte erro:

Parece que a forma como estamos referenciando um identificador não é a que a Snowpark esperava. O código que falhou está exatamente na mesma localização em que o EWI restante está:

Você pode consultar a documentação no link fornecido pelo erro, mas, para economizar tempo, o Snowpark precisa que essa variável seja explicitamente um literal. Precisamos fazer a seguinte substituição:
Isso deve resolver esse erro. Observe que sempre haverá algumas diferenças funcionais entre as plataformas de origem e destino. Ferramentas de conversão como o SMA tentam tornar essas diferenças o mais óbvias possível. Mas lembre-se de que nenhuma conversão é 100% automatizada.
Vamos executar novamente. Desta vez… sucesso!

Podemos escrever algumas consultas em Python para validar isso, mas por que não acessamos o Snowflake (já que é o que faremos de qualquer forma)?
Navegue até a sua conta Snowflake que você usou para executar esses scripts. Deve ser a mesma que você usou para carregar o banco de dados do SQL Server (e se você não fez isso, os scripts acima não funcionarão, pois os dados ainda não foram migrados).
You can quickly check this by seeing if the stage was created with the file:
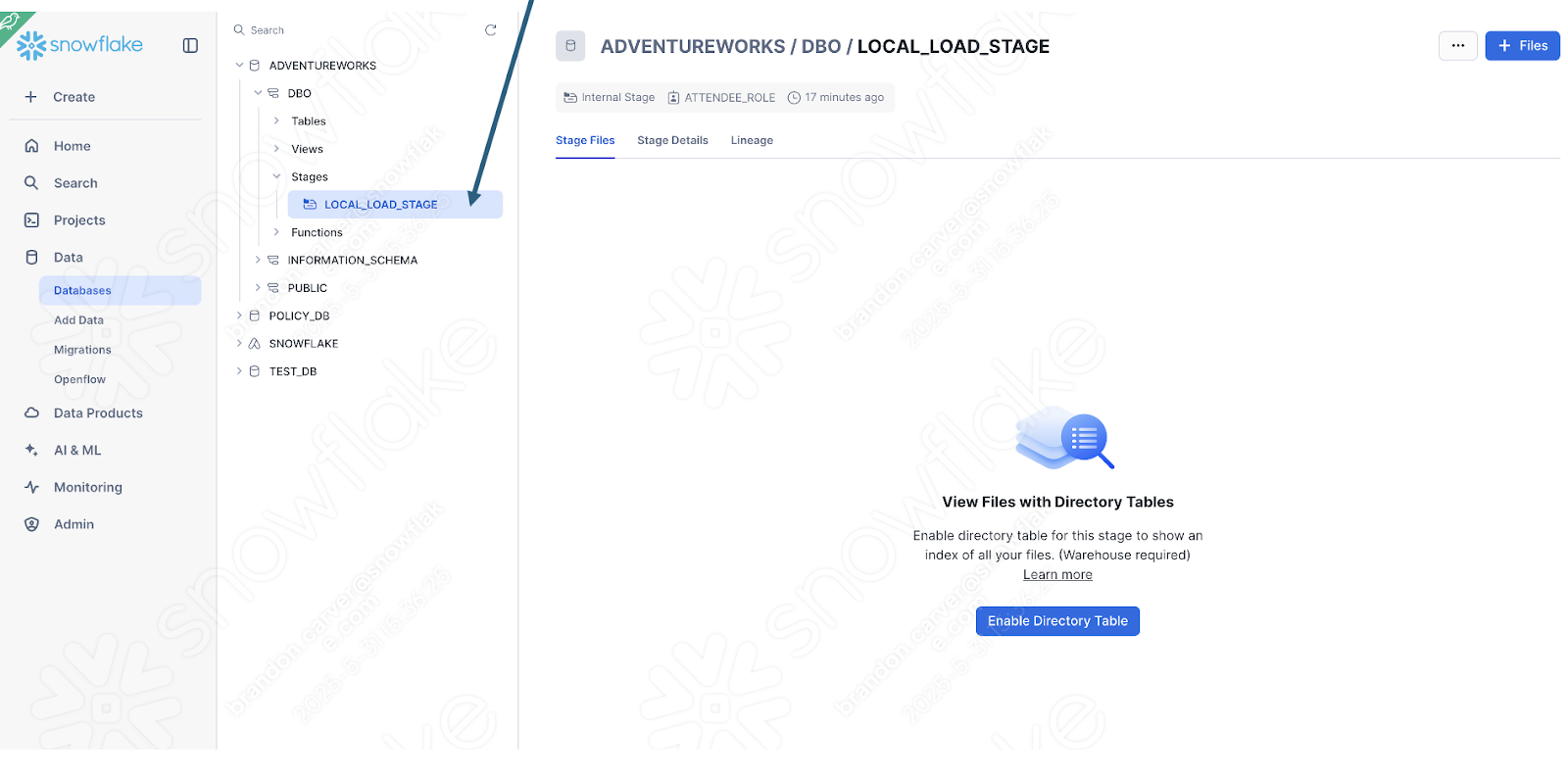
Enable the directory table view to see if the old_versions folder is in there:
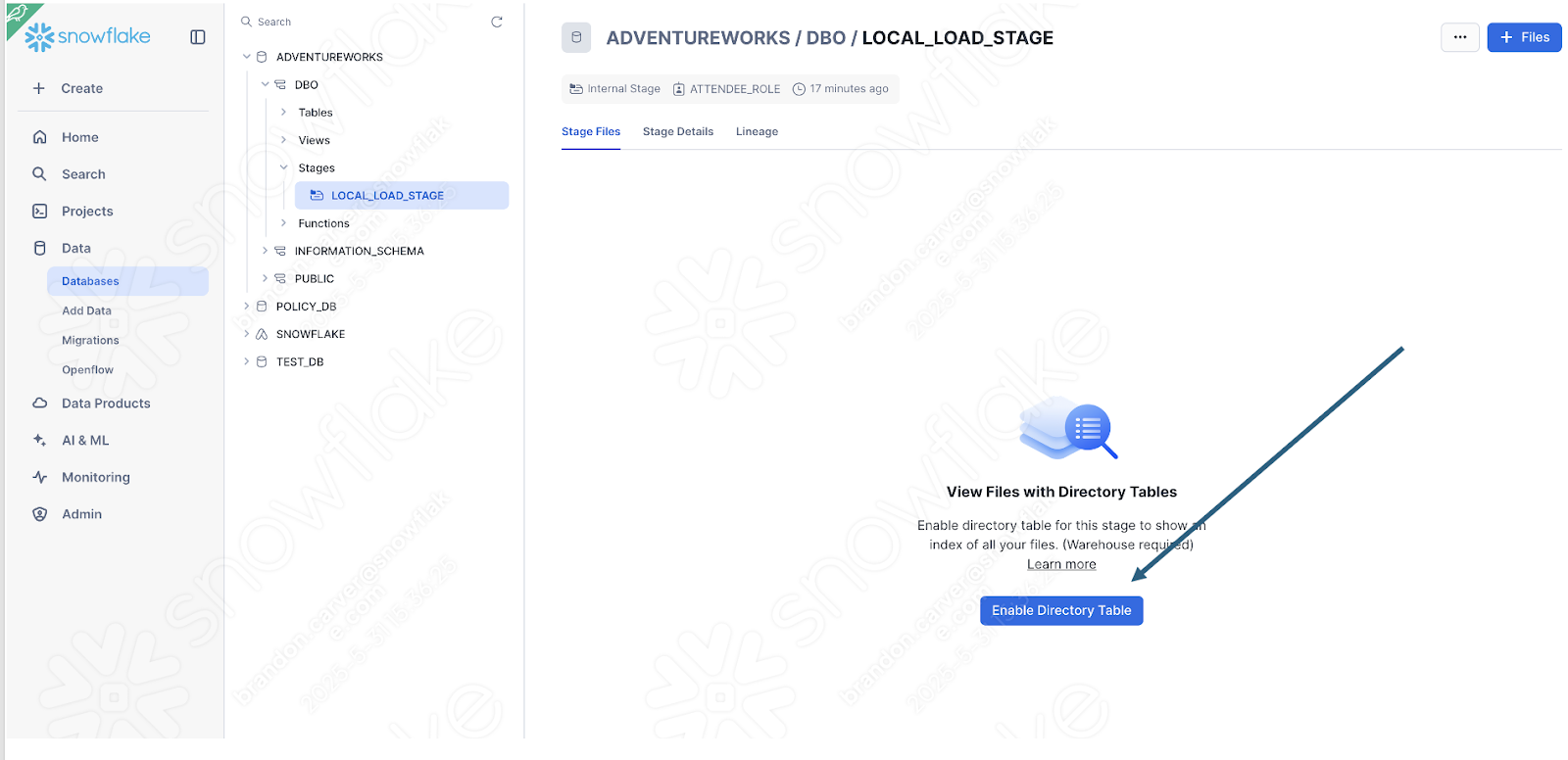
E é:
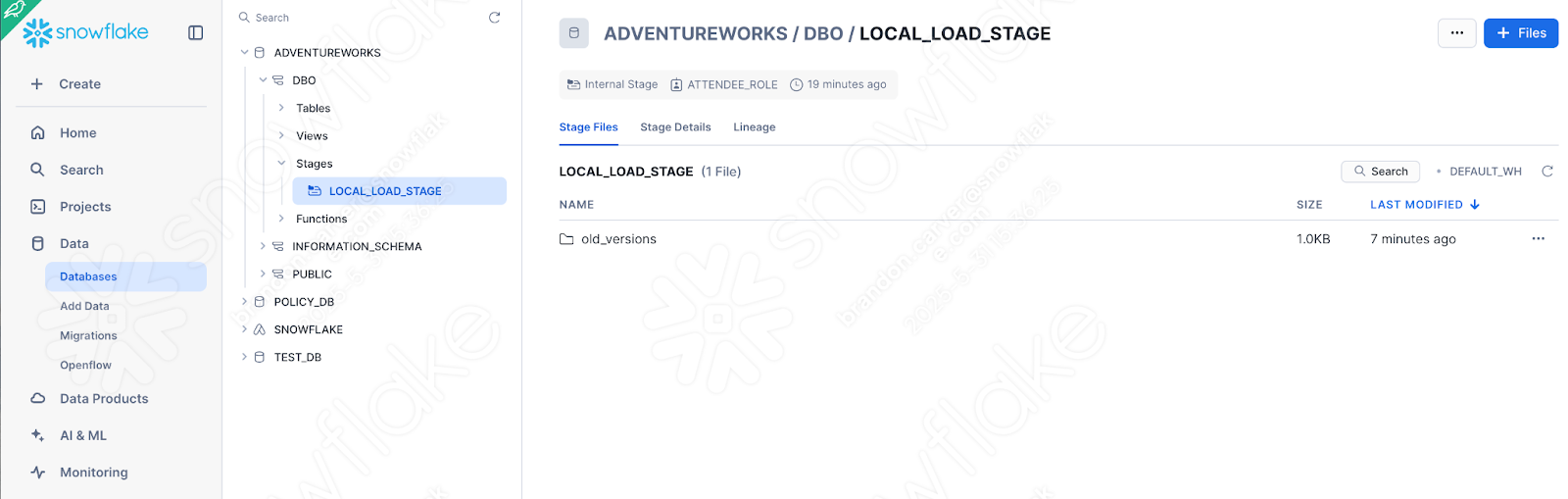
Como esse foi o último elemento do nosso script, parece que está tudo certo!
Também podemos simplesmente validar se os dados foram carregados consultando a tabela para obter os dados que enviamos. Você pode abrir uma nova planilha e simplesmente escrever esta consulta:
Este é um dos nomes que acabou de ser carregado. E parece que nosso pipeline funcionou:
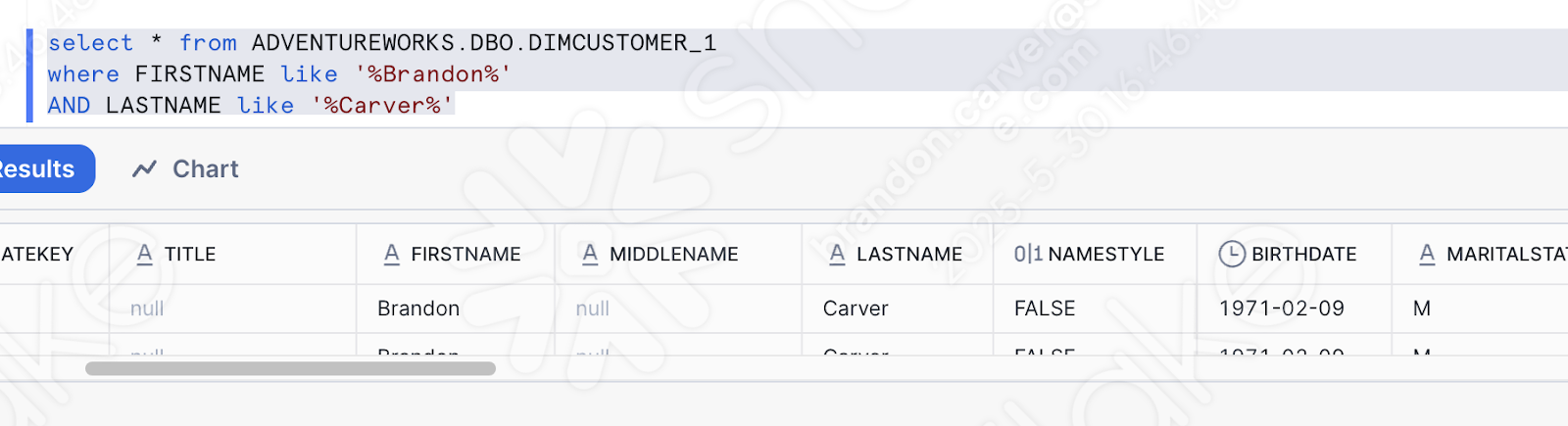
Execução do script do pipeline no Snowsight¶
Vamos dar uma olhada rápida no fluxo que estamos tentando converter, que era executado no Spark:
acesso a um arquivo local
carregamento do resultado no SQL Server
movimentação do arquivo para abrir caminho para o próximo
Não é possível executar este fluxo inteiramente de dentro do Snowsight. O Snowsight não tem acesso a um sistema de arquivos local. A recomendação aqui seria mover a exportação do POS para um data lake… ou qualquer outra opção que seja acessível via Snowsight.
Podemos, no entanto, analisar mais detalhadamente como o Snowpark lida com a lógica de transformação executando o script Python no Snowflake. Se você já fez as alterações recomendadas acima, pode executar o corpo do script em uma planilha Python no Snowflake.
Para fazer isso, primeiro faça login na sua conta Snowflake e navegue até a seção de planilhas. Nesta planilha, crie uma nova planilha Python:

Especifique o banco de dados, o esquema, a função e o warehouse que você gostaria de usar:
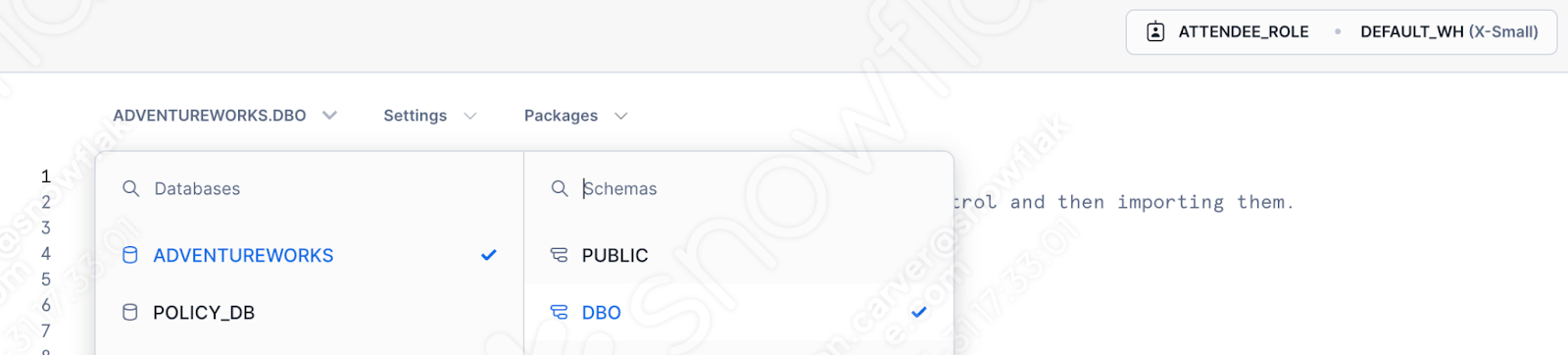
Agora não precisamos lidar com nossa chamada de sessão. Você verá um modelo gerado na janela da planilha:

Vamos começar trazendo nossas chamadas de importação. Depois de preparar o script anterior para uso, devemos ter o seguinte conjunto de importações:
Precisamos apenas das importações do Snowpark. Não vamos mover arquivos no sistema de arquivos. Poderemos manter a referência de data e hora se quisermos mover o arquivo na área de preparação. Vamos fazer isso.
Cole as importações do Snowpark (mais a data e hora) na planilha do Python, abaixo das outras importações que já estão presentes. Observe que «col» já está importado, então você pode remover uma delas:
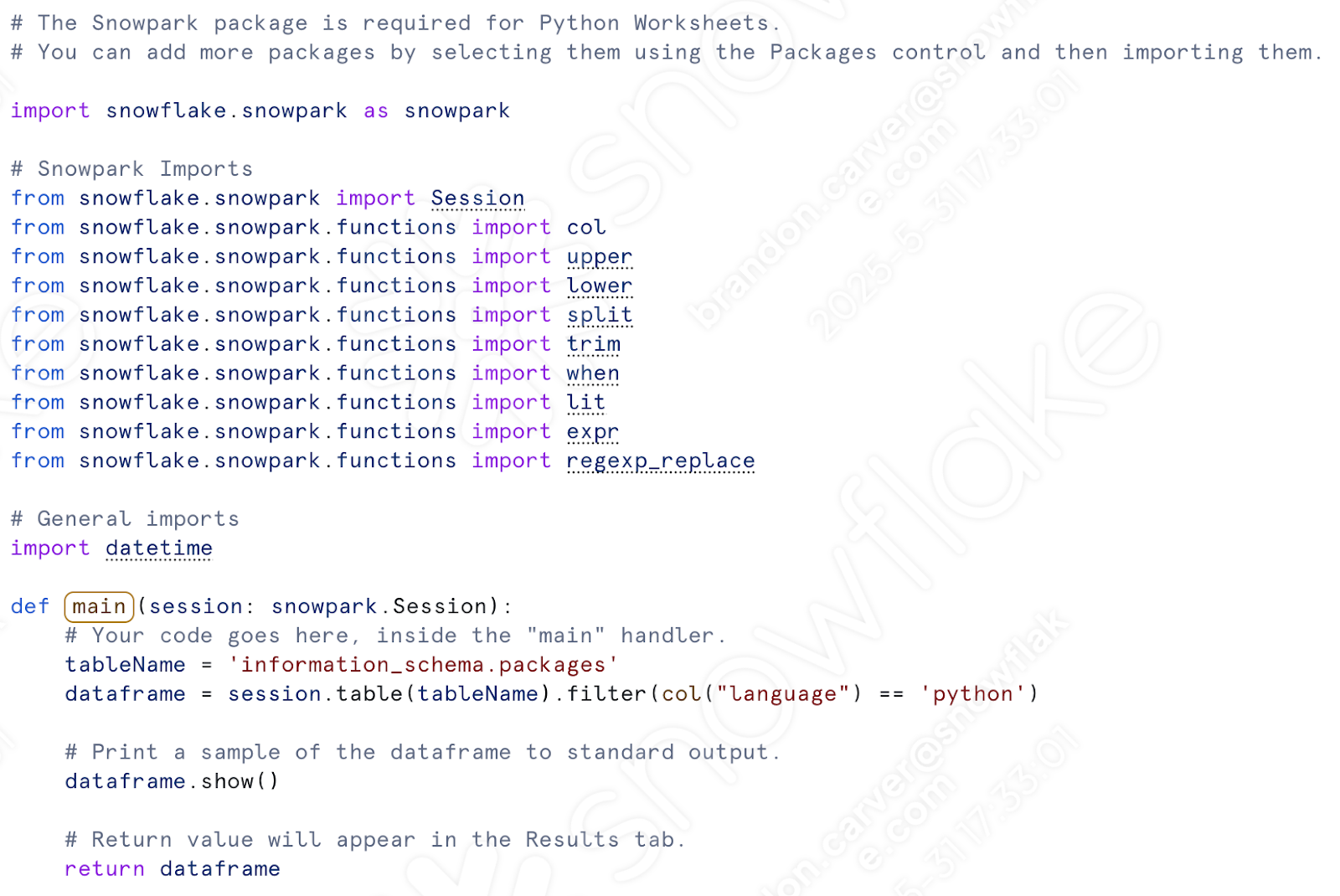
Under the “def main” call, let’s paste in all of our transformation code. This will include everything from the assignment of the csv location to the writing of the dataframe to a table.
Daqui:

Até aqui:

Também podemos adicionar novamente o código que move os arquivos dentro da área de preparação. Esta parte:
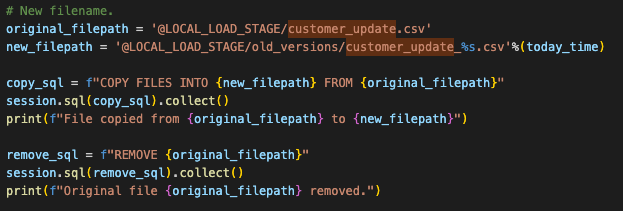
Before you can run the code though, you will have to manually create the stage and move the file into the stage. We can add the create stage statement into the script, but we would still need to manually load the file into the stage.
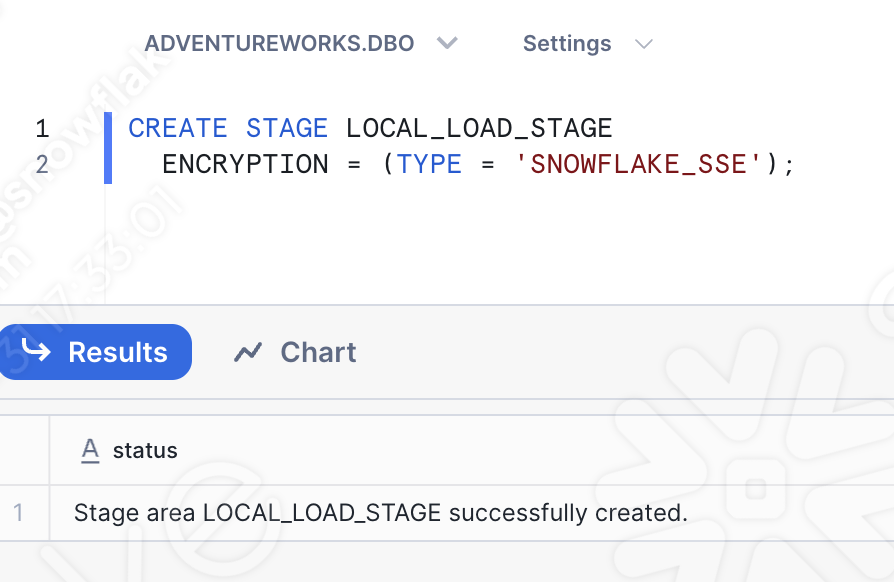
Portanto, se você abrir outra planilha (desta vez… uma planilha SQL), poderá executar uma instrução SQL básica que criará a área de preparação:
Certifique-se de selecionar o banco de dados, o esquema, a função e o warehouse corretos:
You can also create an internal stage directly in the Snowsight UI. Now that the stage exists, we can manually load the file of interest into the stage. Navigate to the Databases section of the Snowsight UI, and find the stage we just created in the appropriate database.schema:
Vamos adicionar nosso arquivo CSV selecionando a opção +Files no canto superior direito da janela. Isso iniciará o menu Upload Your Files:
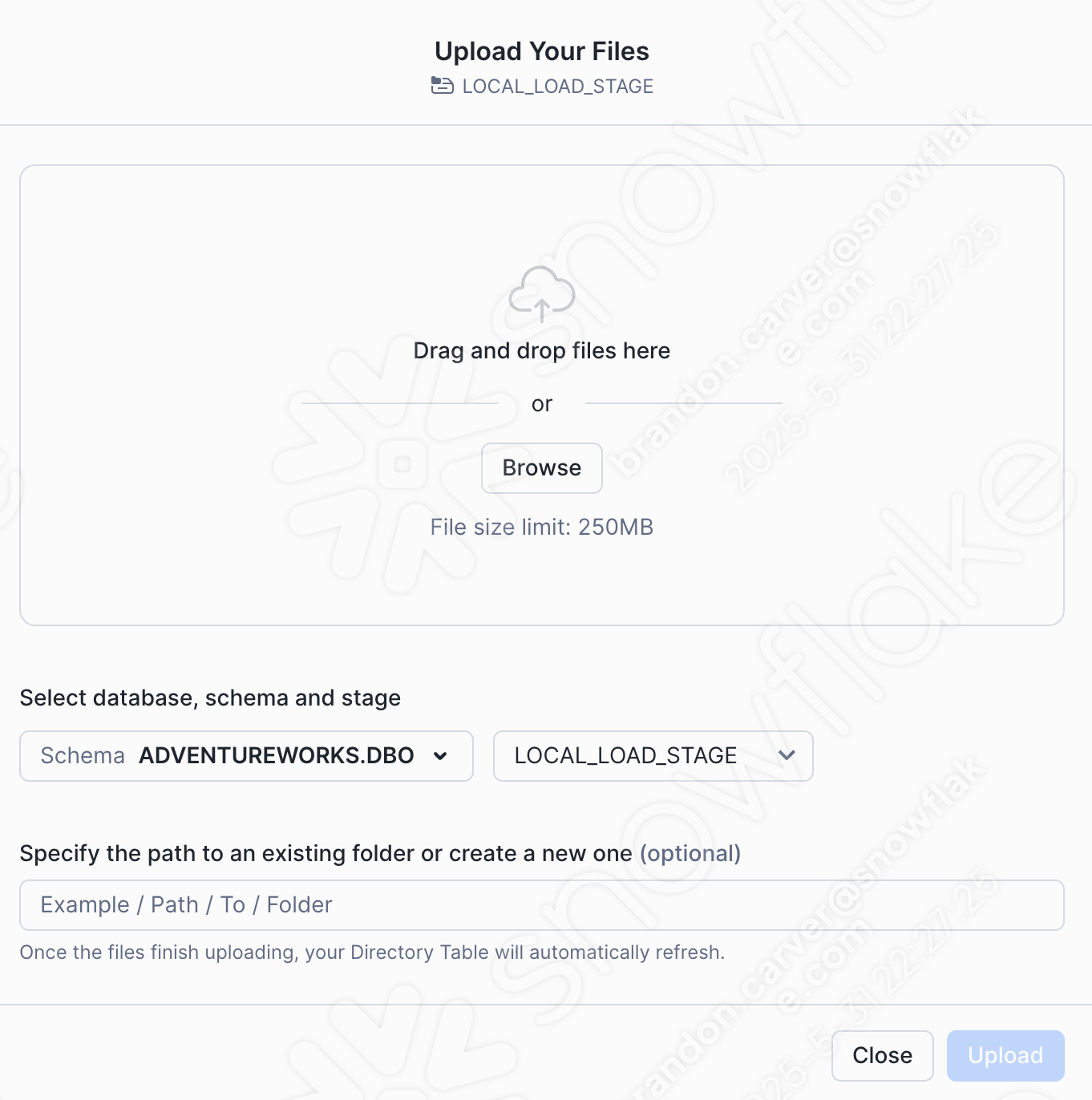
Drag and drop or browse to our project directory and load the customer_update.csv file into the stage:
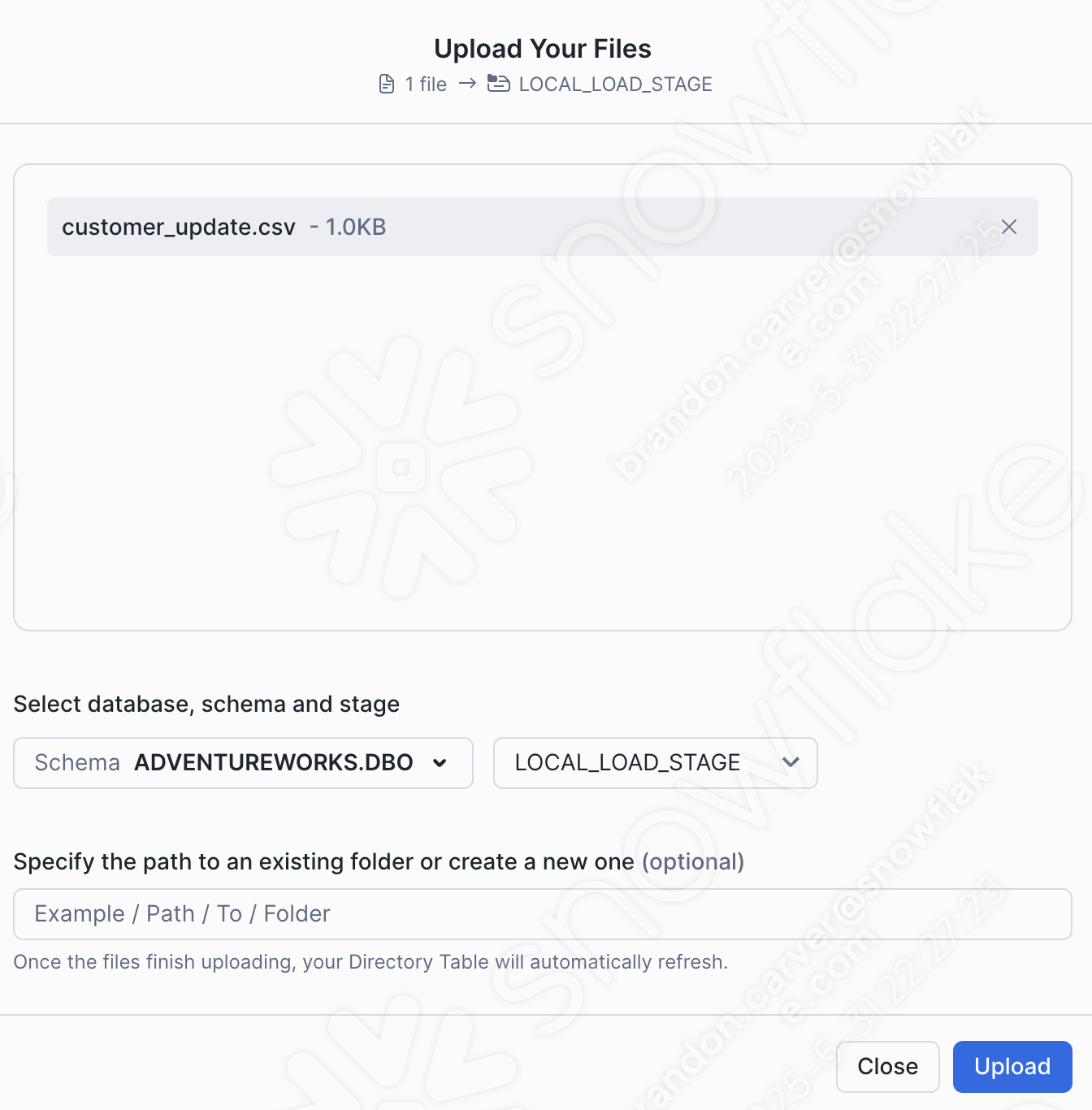
Selecione Upload no canto inferior direito da tela. Você será redirecionado para a tela da área de preparação. Para visualizar os arquivos, você precisará selecionar Enable Directory Table:
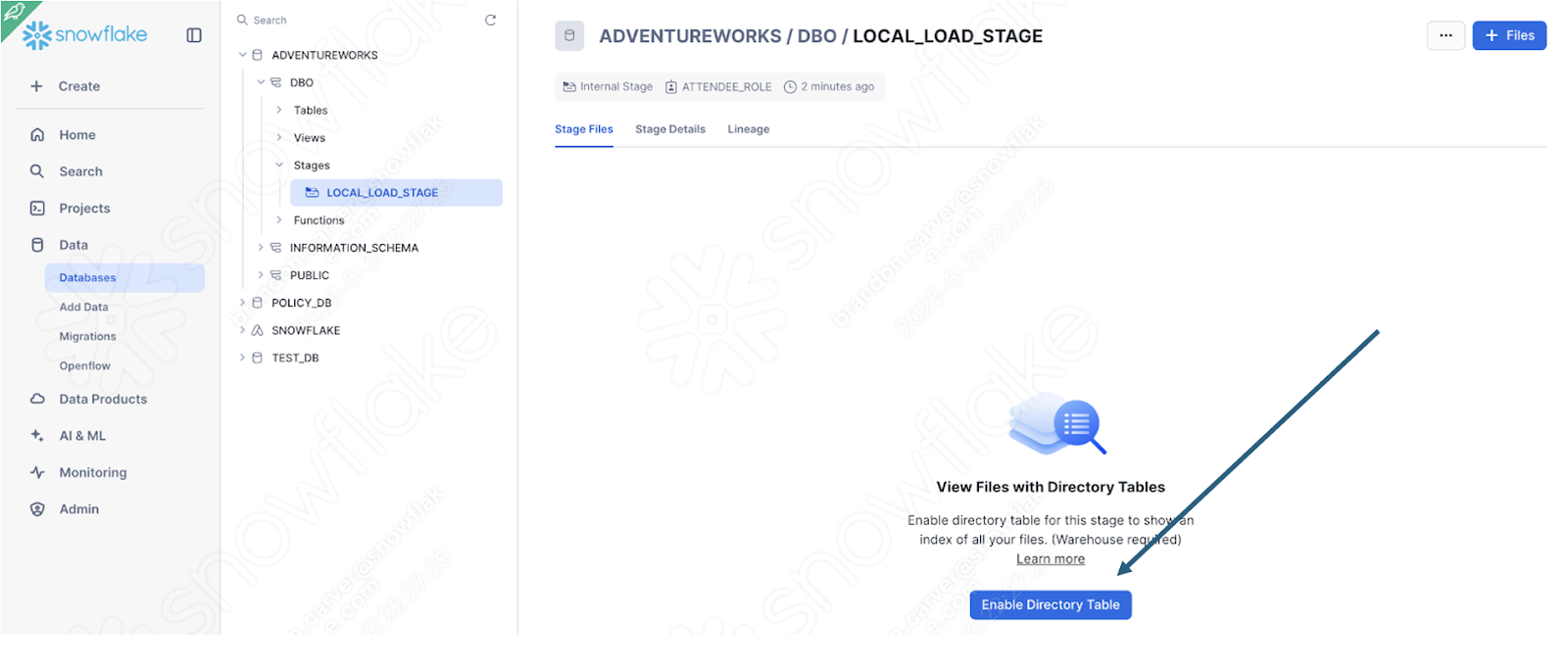
E agora… nosso arquivo aparece na área de preparação:

Isso não é mais exatamente um pipeline, é claro. Mas pelo menos podemos executar o login no Snowflake. Execute o restante do código que você moveu para a planilha. Este usuário teve sucesso na primeira vez, mas isso não garante o sucesso na segunda:
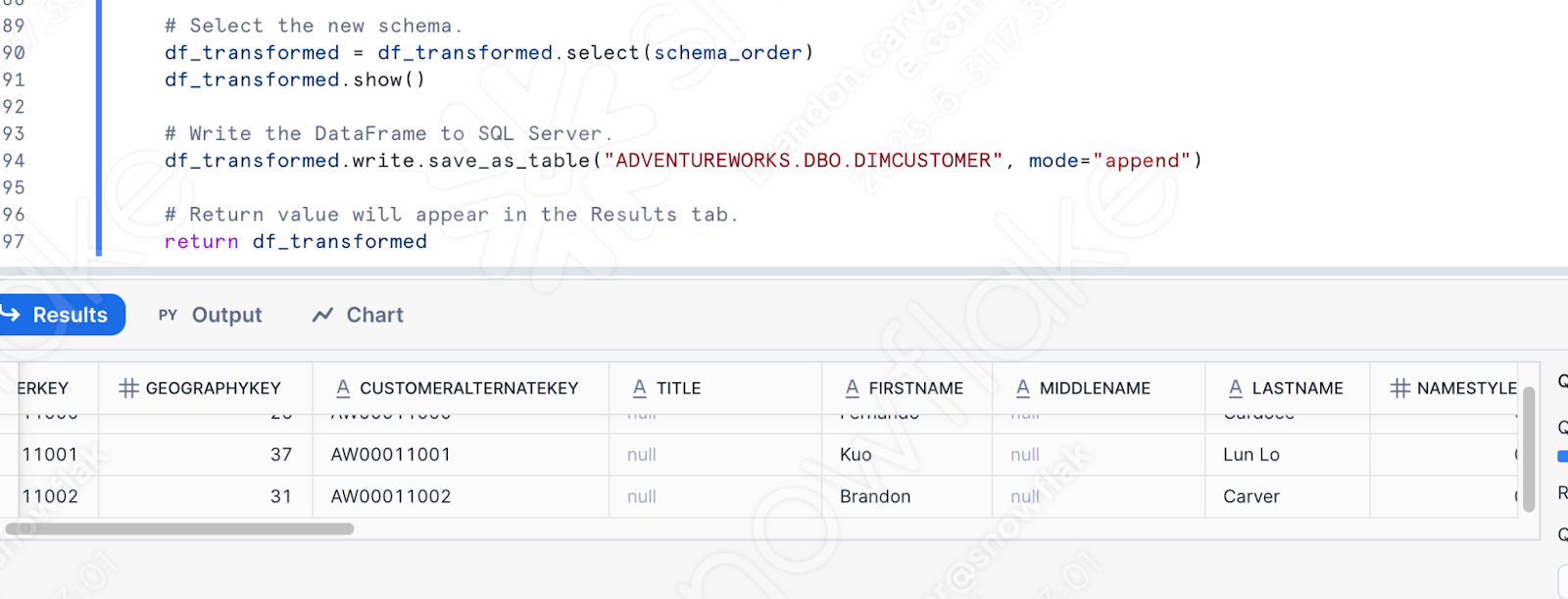
Observe que, depois de definir essa função no Snowflake, você pode chamá-la de outras maneiras. Se o AdventureWorks está substituindo 100% o POS, pode fazer sentido ter a lógica de transformação no Snowflake, especialmente se a orquestração e a movimentação de arquivos forem tratadas em outro lugar. Isso permite que o Snowpark se concentre onde ele se destaca na lógica de transformação.
Conclusão¶
E isso é tudo para o arquivo de script. Não é o melhor exemplo de um pipeline, mas aborda de forma clara como lidar com a saída do SMA:
Resolver todos os problemas
Resolver as chamadas de sessão
Resolver as entradas/saídas
Limpar e testar!
Vamos passar para o notebook de relatórios.