Snowpark Migration Accelerator : Conversion de pipeline¶
SMA a « converti » nos scripts, mais l’a-t-il vraiment fait ? En réalité, il a converti toutes les références de l’API Spark à l’API Snowpark, mais il n’a pas remplacé les connexions qui peuvent exister dans vos pipelines.
La puissance de SMA se trouve dans le rapport d’évaluation, car la conversion est liée à la conversion des références de l’API Spark à l’API Snowpark. Notez que la conversion de ces références ne suffira pas à exécuter un pipeline de données. Vous devrez vous assurer que les connexions du pipeline sont résolues manuellement. SMA ne peut pas présumer connaître les paramètres de connexion ou d’autres éléments qui ne sont probablement pas disponibles pour être exécutés par lui.
Comme pour toute conversion, le traitement du code converti peut se faire de différentes manières. Les étapes suivantes décrivent comment nous vous recommandons d’approcher la sortie de l’outil de conversion. Comme SnowConvert, SMA nécessite une attention particulière à la sortie. Aucune conversion ne sera jamais automatisée à 100 %. Ceci est particulièrement vrai pour SMA. SMA convertissant des références de l’API Spark à l’API Snowpark, vous devrez toujours vérifier comment ces références sont exécutées. Il ne tente pas d’orchestrer l’exécution réussie de tout script ou notebook exécuté par lui.
Nous suivrons donc les étapes suivantes pour traiter la sortie de SMA qui sera légèrement différent de SnowConvert :
Résoudre tous les problèmes : « Problèmes » signifie ici les problèmes générés par SMA. Jetez un coup d’œil au code de sortie. Résolvez les erreurs d’analyse et les erreurs de conversion, et enquêtez sur les avertissements.
Résoudre les appels de session : La façon dont l’appel de session est écrit dans le code de sortie dépend de l’endroit où nous allons exécuter le fichier. Nous allons résoudre ce problème pour exécuter le(s) fichier(s) de code au même emplacement que celui qui devait être exécuté à l’origine, puis pour les exécuter dans Snowflake.
Résoudre l’entrée/les sorties : Les connexions à différentes sources ne peuvent pas être résolues entièrement par SMA. Il existe des différences entre les plateformes, ce que SMA ignorera généralement. Cela dépend également de l’endroit où le fichier sera exécuté.
Nettoyer et tester ! Exécutons le code. Vérifions qu’il fonctionne. Nous procéderons à des smoke tests dans cet atelier, mais il existe des outils pour effectuer des tests et une validation des données plus étendus, dont des points de contrôle Snowpark Python.
Regardons à quoi cela ressemble. Nous allons procéder selon deux approches : la première consiste à exécuter ceci dans Python sur la machine locale (pendant l’exécution du script source). La deuxième consisterait à tout faire dans Snowflake… dans Snowsight, mais pour un pipeline de données lisant une source locale, ce ne sera pas entièrement possible dans Snowsight. Mais ce n’est pas grave. Nous ne convertissons pas l’orchestration de ce script dans cette POC.
Commençons par le fichier de script du pipeline, et accédons au notebook dans la section suivante.
Résoudre les problèmes¶
Ouvrons notre code source et notre code de sortie dans un éditeur de code. Vous pouvez utiliser n’importe quel éditeur de code de votre choix, mais comme cela a été mentionné plusieurs fois, Snowflake vous recommande d’utiliser VS Code avec l’extension Snowflake. Non seulement l’extension Snowflake aide à parcourir les problèmes de SnowConvert, mais peut également exécuter des points de contrôle Snowpark pour Python, ce qui peut aider pour les tests et l’analyse des causes profondes (bien que tout juste hors de portée pour cet atelier).
Ouvrons le répertoire que nous avons créé à l’origine dans l’écran de création du projet (Spark ADW Lab) dans VS Code :
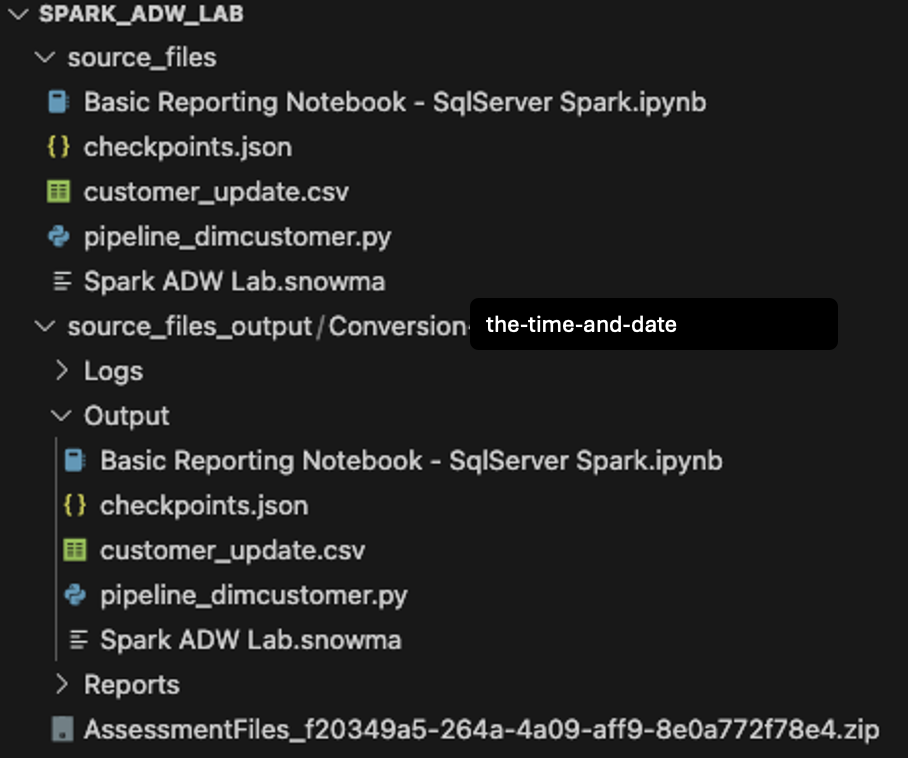
Notez que la structure du répertoire Sortie est la même que celle du répertoire d’entrée. Même le fichier de données sera copié, bien qu’aucune conversion n’ait lieu. Il y aura également quelques fichiers checkpoints.json qui seront créés par SMA. Il s’agit de fichiers json qui contiennent des instructions pour l’extension Snowpark Checkpoints. L’extension Snowflake peut charger des points de contrôle dans le code source et de sortie en fonction des données de ces fichiers. Nous les ignorons pour l’instant.
Enfin, comparons le script python d’entrée au script converti dans le script de sortie.
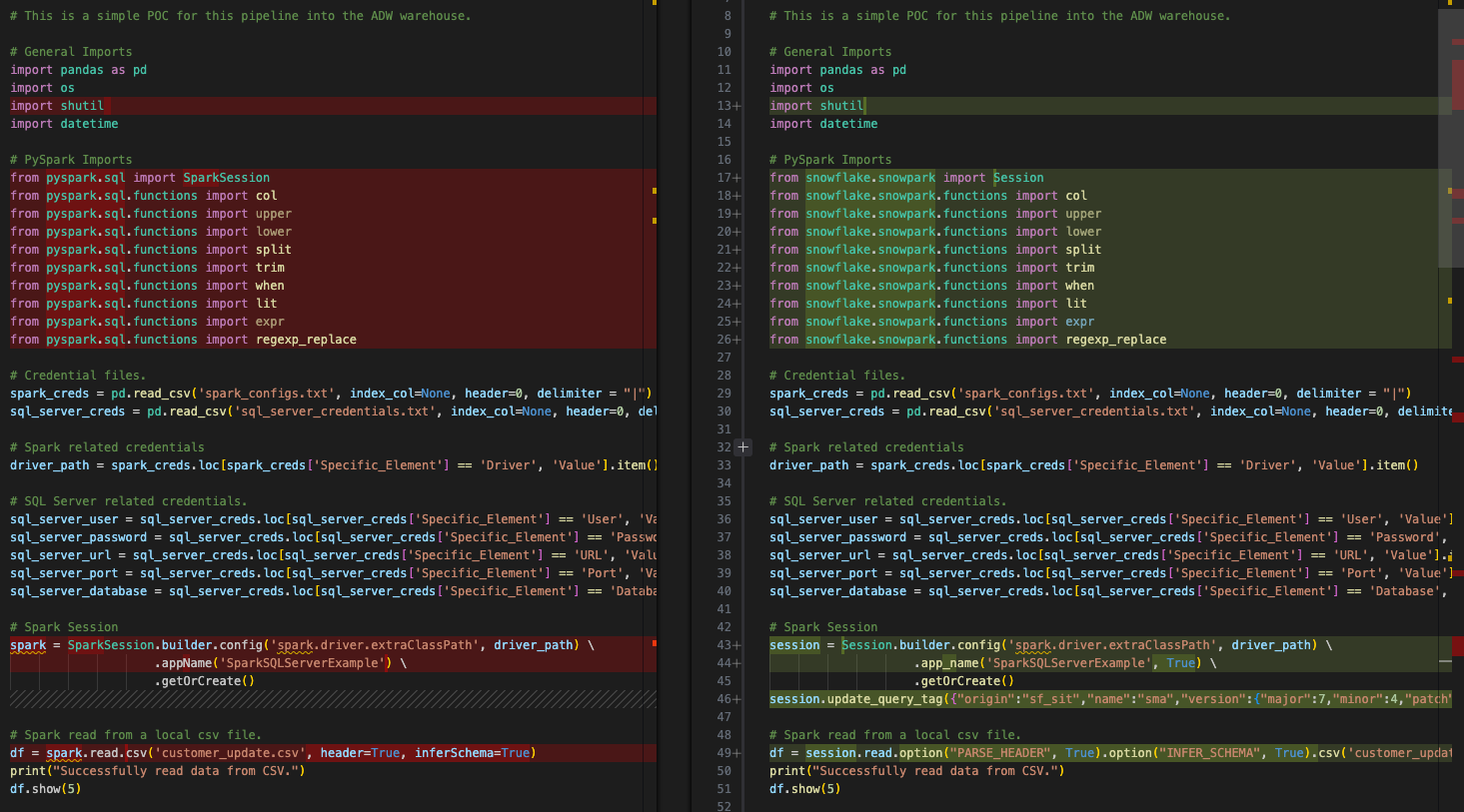
Il s’agit d’une comparaison très simple avec le code original Spark à gauche et le code de sortie compatible Snowpark à droite. Il semble que certaines importations aient été converties, ainsi que le(s) appel(s) de session. Nous pouvons voir un EWI au bas de l’image ci-dessus, mais ce n’est pas le moment de nous y intéresser. Nous devons trouver l’erreur d’analyse avant de faire autre chose.
Nous pouvons rechercher dans le document le code de cette erreur d’analyse qui a été affichée dans l’UI et dans issues.csv : SPRKPY1101.
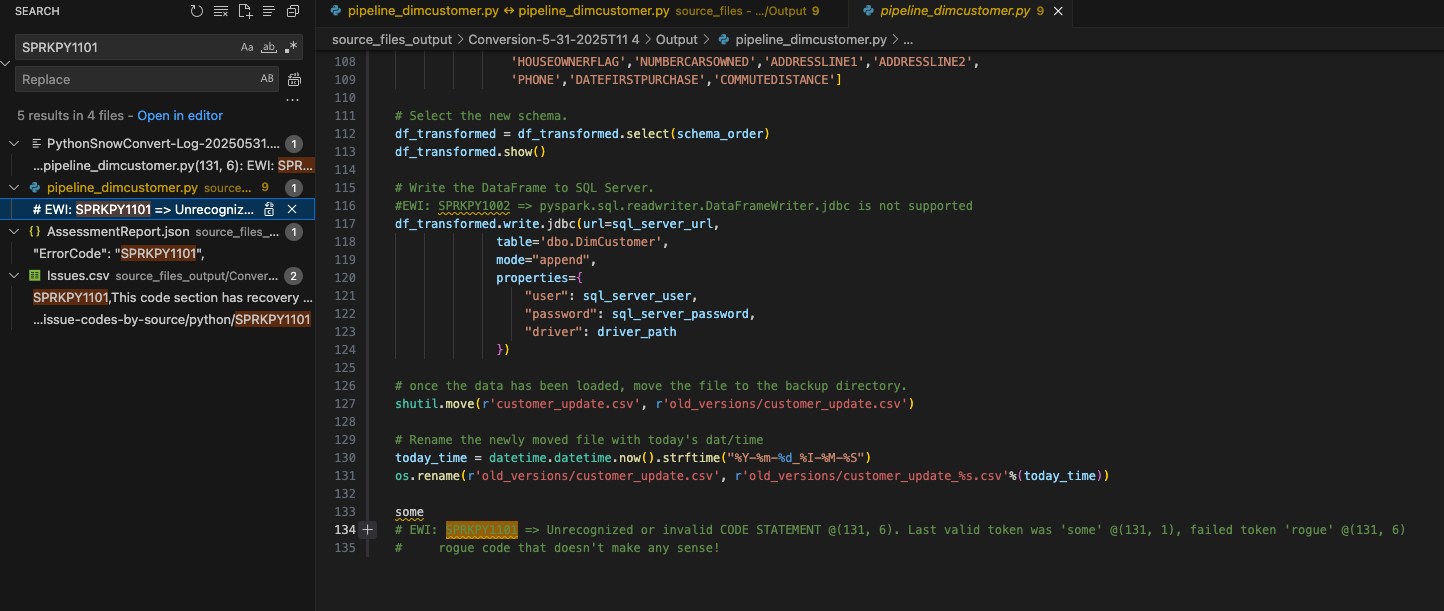
Since I have not filtered the results, the listing of this error code in the issues.csv also comes up in the search and the AssessmentReport.json that is used to build the AssessmentReport.docx summary assessment report. This is the main report that users will navigate through to understand a large workload, but we did not look at it in this lab. (More info on the this report can be found in the SMA documentation.) Let’s choose where this EWI shows up in the pipeline_dimcustomer.py file as shown above.
You can see that this line of code was present at the bottom of the source code.
Il semble que cette erreur d’analyse soit due à… « un code malveillant qui ne veut rien dire ! ». Cette ligne de code se trouve au bas du fichier du pipeline. Il n’est pas inhabituel d’avoir des caractères supplémentaires ou d’autres éléments dans un fichier de code dans le cadre d’une extraction à partir d’une source. Notez que SMA a détecté que ce n’était pas du code Python valide, et qu’il a généré l’erreur d’analyse.
Vous pouvez également voir comment SMA insère le code d’erreur et la description dans le code de sortie sous forme de commentaire là où l’erreur s’est produite. C’est ainsi que tous les messages d’erreur apparaîtront dans la sortie.
Comme il ne s’agit pas de code valide, il se trouve à la fin du fichier, et comme il n’y a rien d’autre qui a été supprimé à la suite de cette erreur, le code original et le commentaire peuvent être supprimés en toute sécurité du fichier de code de sortie.
Nous avons maintenant résolu notre premier problème et également le plus grave. Souriez !
Développons le reste de nos EWIs dans ce fichier. Nous pouvons rechercher « EWI », car nous saurons maintenant que le texte apparaîtra dans le commentaire chaque fois qu’il y aura un code d’erreur. (Nous pouvons également trier le fichier issues.csv et classer les problèmes par gravité… mais ce n’est pas vraiment nécessaire ici.)
Le suivant n’est en fait qu’un avertissement, pas une erreur. Il nous indique qu’une fonction a été utilisée qui n’est pas toujours équivalente dans Spark et Snowpark :
Cependant, la description ici indique que nous n’avons probablement pas à nous en soucier . Seuls deux paramètres sont transmis. Laissons cet EWI en tant que commentaire dans le fichier, afin que nous puissions le vérifier lorsque nous l’exécuterons ultérieurement.
Le dernier de ce fichier est une erreur de conversion indiquant que quelque chose n’est pas pris en charge :

Il s’agit de l’appel d’écriture au pilote spark jdbc pour écrire le dataframe de sortie dans le serveur SQL. Comme cela fait partie de l’étape « résoudre toutes les entrées/sorties » que nous allons traiter après avoir résolu nos problèmes, nous laisserons cela pour plus tard. Notez toutefois que cette erreur doit être résolue. La précédente n’était qu’un avertissement et peut encore fonctionner sans qu’aucune modification ne soit apportée.
Résoudre les appels de session¶
Les appels de session sont convertis par SMA, mais vous devez y porter une attention particulière pour vous assurer qu’ils fonctionnent. Dans notre script de pipeline, il s’agit du code avant et après :

La référence SparkSession a été modifiée en Session. Vous pouvez également voir ce changement de référence en haut de ce fichier dans l’instruction d’importation :

Notez dans l’image ci-dessus, l’affectation de variable de l’appel de session à « spark » n’est pas modifiée. En effet, il s’agit d’une affectation de variable. Il n’est pas nécessaire de modifier cela, mais si vous souhaitez changer le décorateur « spark » en « session », cela correspondrait mieux à ce que recommande Snowpark. (Notez que l’extension VS Code « SMA Assistant » suggérera également ces modifications.)
L’exercice est simple, mais il vaut le coup. Vous pouvez effectuer une recherche et un remplacement à l’aide de la propre capacité de recherche de VS Code pour trouver les références à « spark » dans ce fichier et les remplacer par session. Vous pouvez en voir le résultat dans l’image ci-dessous. Les références à la variable « spark » dans le code converti ont été remplacées par « session » :

Nous pouvons également supprimer autre chose de cet appel de session. Étant donné que nous n’exécuterons plus « spark », nous n’avons pas besoin de spécifier le chemin pour le pilote spark. Nous pouvons donc supprimer entièrement la fonction de configuration de l’appel de session comme suit :
Might as well convert it to a single line. The SMA couldn’t be sure we didn’t need that driver (although that seems logical), so it did not remove it. But now that we have our session call is complete.
(Notez que SMA ajoute également une « balise de requête » à la session. Cette fonction a pour but de résoudre les problèmes liés à cette session ou aux requêtes ultérieures, mais il est totalement facultatif de la laisser ou de la supprimer.)
Notes sur les appels de session¶
Croyez-le ou non, c’est tout ce que nous devons modifier dans le code pour l’appel de session, mais ce n’est pas tout ce que nous devons faire pour créer la session. Cela renvoie à la question d’origine selon laquelle beaucoup de choses dépendent de l’endroit où vous souhaitez exécuter ces fichiers. Ces appels de session spark originaux utilisaient une configuration qui a été configurée ailleurs. Si vous regardez l’appel de session Spark d’origine, il recherche un fichier de configuration qui est lu dans un emplacement de dataframe pandas au début de ce fichier de script (c’est également vrai pour notre fichier notebook).
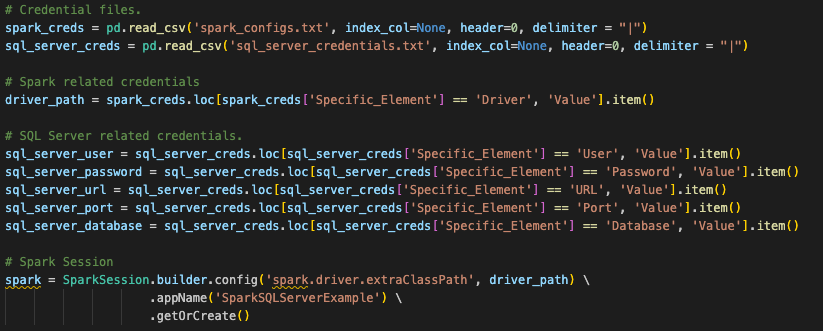
Snowpark can function the same way, and this conversion assumes that is how this user will run this code. However, for the existing session call to work, the user would have to load all of the information for their Snowflake account into the local (or at least accessible) connections.toml file on this machine, and that the account they are attempting to connect to is set as the default. You can learn more about updating the connections.toml file in the Snowflake/Snowpark documentation, but the idea behind it is that there is an accessible location that has the credentials. When a snowpark session is created, it is going to check this… unless the connection parameters are explicitly passed to the session call.
La méthode standard pour ce faire consiste à saisir les paramètres de connexion directement sous forme de chaînes et de les appeler avec la session :
AdventureWorks appears to have referenced a file with these credentials and called it. Assuming there is a similar file called “snowflake_credentials.txt” that is accessible, then the syntax that would match that could look something like:
For the purpose of the time limit on this lab, the first option may make more sense. There’s more on this in the Snowpark documentation.
Notez que pour que notre fichier notebook s’exécute à l’intérieur de Snowflake en utilisant Snowsight, vous n’auriez pas besoin de faire tout cela. Il vous suffit d’appeler la session active et de l’exécuter.
Il est maintenant temps de s’intéresser au composant le plus critique de cette migration, à savoir la résolution des références des entrées/des sorties.
Résolution des entrées et des sorties¶
Résolvons maintenant nos entrées et sorties. Notez que cela va varier selon que vous exécutez les fichiers localement ou sur Snowflake. Pour le script python, essayons de voir ce que nous y gagnons/y perdons en les exécutant directement dans Snowsight : vous ne pouvez pas exécuter toute l’opération dans Snowsight (du moins pas actuellement). Le fichier csv local n’est pas accessible depuis Snowsight. Vous devrez charger manuellement le fichier .csv dans une zone de préparation. Ce ne sera probablement pas une solution idéale, mais nous pouvons tester la conversion avec ça.
Nous allons donc d’abord préparer ce fichier pour qu’il soit exécuté/orchestré localement, puis pour qu’il soit exécuté dans Snowflake.
Pour résoudre les entrées et les sorties du script de pipeline, nous devons d’abord les identifier. C’est assez simple. Ce script semble :
accéder à un fichier local
charger le résultat dans le serveur SQL (mais à présent Snowflake)
déplacer le fichier pour faire place au suivant
Plutôt simple. Nous devons donc remplacer chaque composant du code qui effectue ces opérations. Commençons par accéder au fichier local.
Comme cela a été mentionné au début de ce chapitre, nous vous conseillons fortement de réarchitecturer le système de point de vente et les outils d’orchestration utilisés pour exécuter ce script python, afin de placer le fichier de sortie dans un emplacement de stockage Cloud. Vous pouvez alors transformer cet emplacement en table externe, et voila… vous êtes dans Snowflake. Cependant, l’architecture actuelle indique que ce fichier ne se trouve pas dans un emplacement de stockage Cloud et restera là où il se trouve. Nous devons donc créer un moyen pour Snowflake d’accéder à ce fichier en préservant la logique existante.
Il existe différentes possibilités pour cela, mais nous allons créer une zone de préparation interne et déplacer le fichier dans la zone de préparation avec le script. Nous devrons alors déplacer le fichier dans le système de fichiers local, et aussi le déplacer dans la zone de préparation. Tout cela peut se faire avec Snowpark. Décomposons les étapes :
accéder à un fichier local : Créer une zone de préparation interne (s’il n’en existe pas déjà une) -> Charger le fichier dans la zone -> Lire le fichier dans un dataframe
charger le résultat dans le serveur SQL : Charger les données transformées dans une table dans Snowflake
déplacer le fichier pour faire place au suivant : Déplacer le fichier local -> Déplacer le fichier dans la zone de préparation.
Examinons le code qui peut effectuer chacune de ces opérations.
Accéder à un fichier accessible localement¶
Ce code source dans Spark ressemble à ceci :
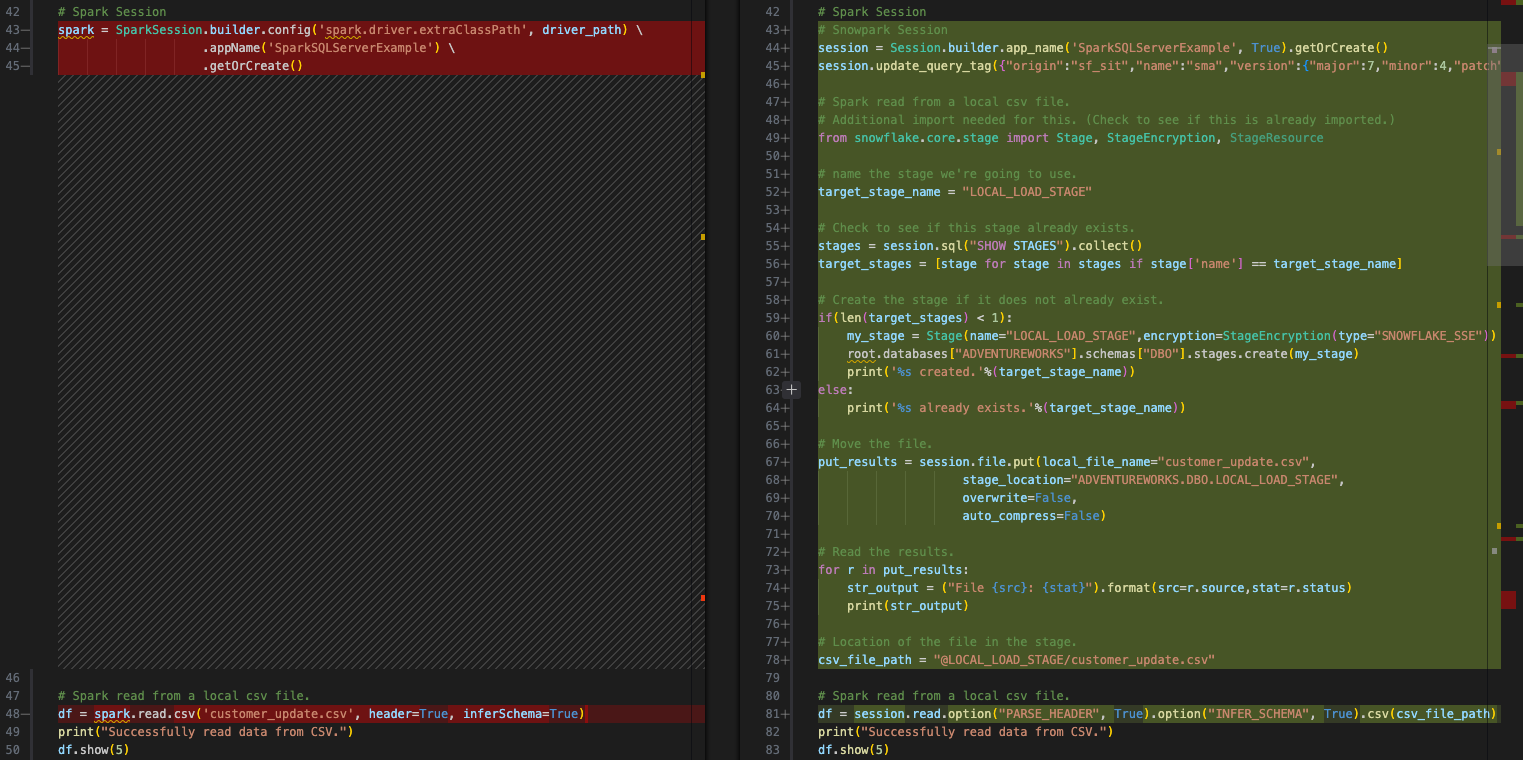
Et le code snowpark transformé (par SMA) ressemble à ceci :
Nous pouvons remplacer cette valeur par du code qui effectue les étapes ci-dessus :
Create an internal stage (if one does not exist already). We will create a stage called “LOCAL_LOAD_STAGE” and go through a few steps to make sure that the stage is r
Charger le fichier dans la zone de préparation.
Lire le fichier dans un dataframe. Il s’agit de la partie que SMA convertit effectivement. Nous devons spécifier que l’emplacement du fichier est maintenant la zone de préparation interne.
Le résultat associé ressemblerait à ceci :
Passons à l’étape suivante.
Charger le résultat dans Snowflake¶
Le script original a écrit le dataframe dans le serveur SQL. Nous allons maintenant le charger dans Snowflake. La conversion est beaucoup plus simple. Le dataframe est déjà un dataframe Snowpark. C’est l’un des avantages de Snowflake. Maintenant que les données sont accessibles à Snowflake, tout se passe à l’intérieur de Snowflake.
Notez qu’il peut être nécessaire d’écrire dans une table temporaire pour effectuer des tests/validations, mais qu’il s’agit du comportement dans le script original.
Déplacer le fichier pour faire place au suivant¶
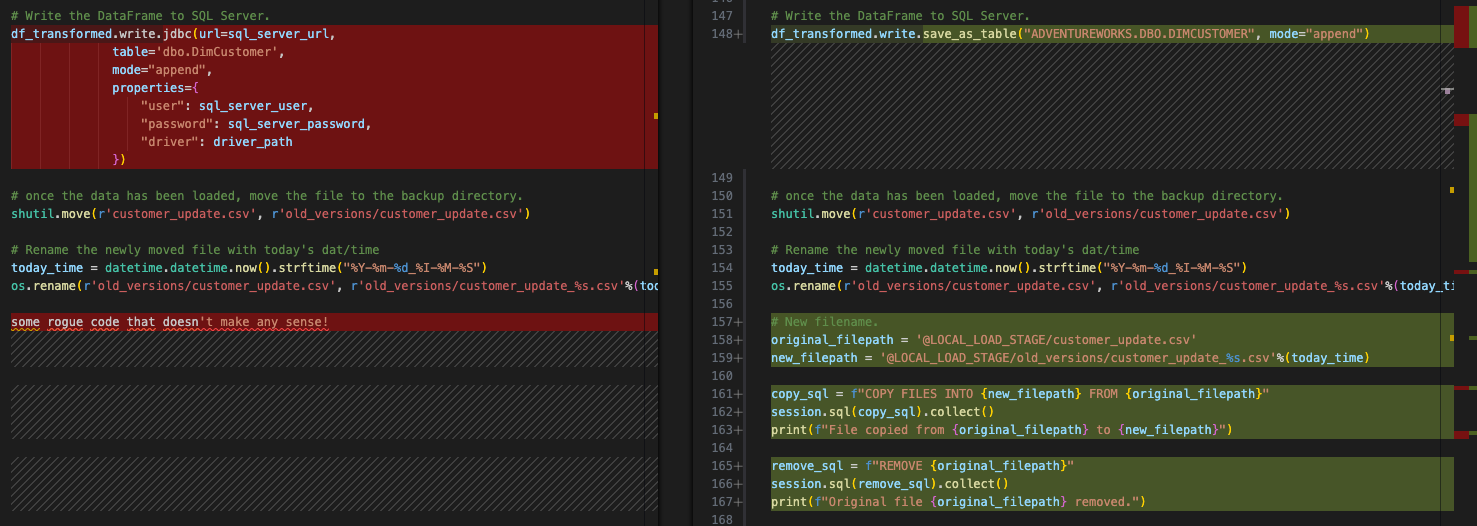
C’est le comportement dans le script original. Nous n’avons pas réellement besoin que cela se produise dans Snowflake, mais nous pouvons présenter exactement les mêmes fonctionnalités dans la zone de préparation. Ceci se fait avec une commande os dans le système de fichiers original. Cela ne dépend pas de Spark et restera ainsi. Mais pour émuler ce comportement dans Snowpark, nous devons déplacer ce fichier de la zone de préparation vers un nouveau répertoire.
Cela peut se faire simplement avec le code python suivant :
Notez que cela ne remplacerait aucun partie du code existant. Étant donné que nous voulons déjà conserver le mouvement existant de déplacement du code spark vers Snowpark, nous laissons la référence os. La version finale ressemblera à ceci :
Maintenant, nous avons le même mouvement complètement exécuté. À présent, effectuons notre dernier nettoyage et testons ce script.
Nettoyer et tester¶
Nous n’avons jamais examiné nos appels d’importation et nous avons des fichiers de configuration qui ne sont absolument pas nécessaires. Nous pouvons laisser les références aux fichiers de configuration et exécuter le script. En fait, si ces fichiers de configuration sont toujours accessibles, le code s’exécutera toujours. Mais si nous examinons de près nos instructions d’importation, nous pouvons aussi bien les supprimer. Ces fichiers sont représentés par tout le code entre les instructions d’importation et l’appel de session :
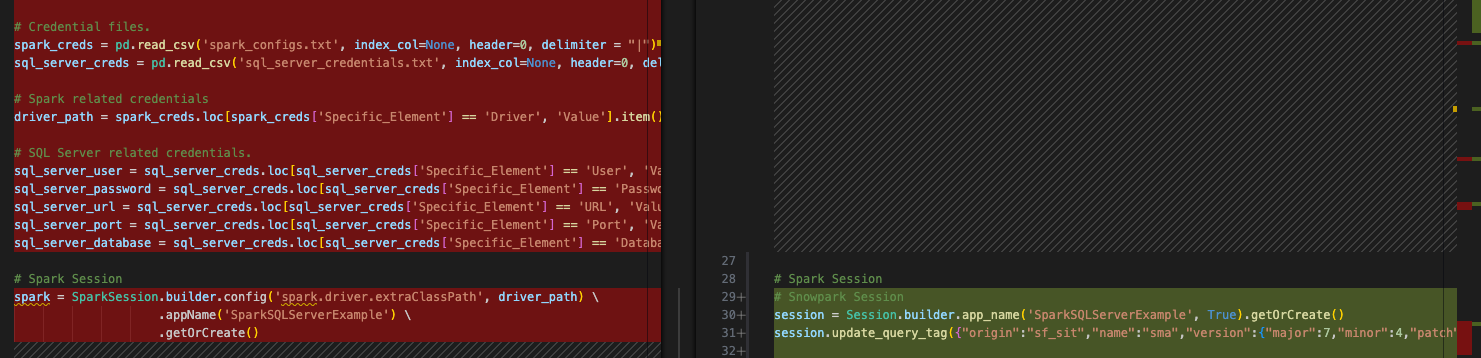
Il y a plusieurs autres choses que nous devons faire :
Vérifier que toutes nos importations sont encore nécessaires. Nous pouvons les laisser pour l’instant. S’il y a une erreur, nous pouvons la corriger.
Il y a également une EWI que nous avons laissé en tant qu’avertissement à vérifier. Nous voulons donc nous assurer que nous inspectons cette sortie.
We need to make sure that our file system behavior mirrors that of the expected file system for the POS system. To do this, we should move the customer_update.csv file into the root folder you chose when first launching VS Code.
Create a directory called “old_versions” in that same directory. This should allow the os operations to run.
Enfin, si vous n’êtes pas à l’aise à l’idée d’exécuter le code directement dans la table de production, vous pouvez créer une copie de cette table pour ce test, et pointer la charge vers cette copie. Remplacez l’instruction Load par l’instruction ci-dessous. Comme il s’agit d’un atelier, n’hésitez pas à écrire dans la table de « production » :
Nous sommes maintenant prêts à effectuer le test. Nous pouvons exécuter ce script en Python sur une table de test et voir s’il échoue. Alors, exécutons-le !
Horrible ! Le script a échoué avec l’erreur suivante :

Il semble que la façon dont nous faisons référence à un identificateur n’est pas ce que Snowpark souhaitait. Le code qui a échoué se trouve exactement à l’endroit où e trouve l’EWI restante :

Vous pouvez consulter la documentation sur le lien fourni par l’erreur, mais pour gagner du temps, Snowpark a besoin que cette variable soit explicitement un littéral. Nous devons effectuer le remplacement suivant :
Cela devrait résoudre cette erreur. Notez qu’il y aura toujours des différences fonctionnelles entre les plateformes source et cible. Les outils de conversion comme SMA souhaitent rendre ces différences aussi évidentes que possible. Notez toutefois qu’aucune conversion n’est entièrement automatique.
Exécutons-la à nouveau. Cette fois… c’est bon !

Nous pouvons écrire des requêtes en python pour valider cela, mais pourquoi n’irions-nous pas simplement dans Snowflake (car c’est ce que nous sommes sur le point de faire de toute façon).
Accédez au compte Snowflake que vous avez utilisé pour exécuter ces scripts. Il doit s’agir du même compte que celui que vous avez utilisé pour charger la base de données depuis le serveur SQL (et si vous ne l’avez pas encore fait, les scripts ci-dessus ne fonctionneront pas de toute façon car les données n’ont pas encore été migrées).
You can quickly check this by seeing if the stage was created with the file:
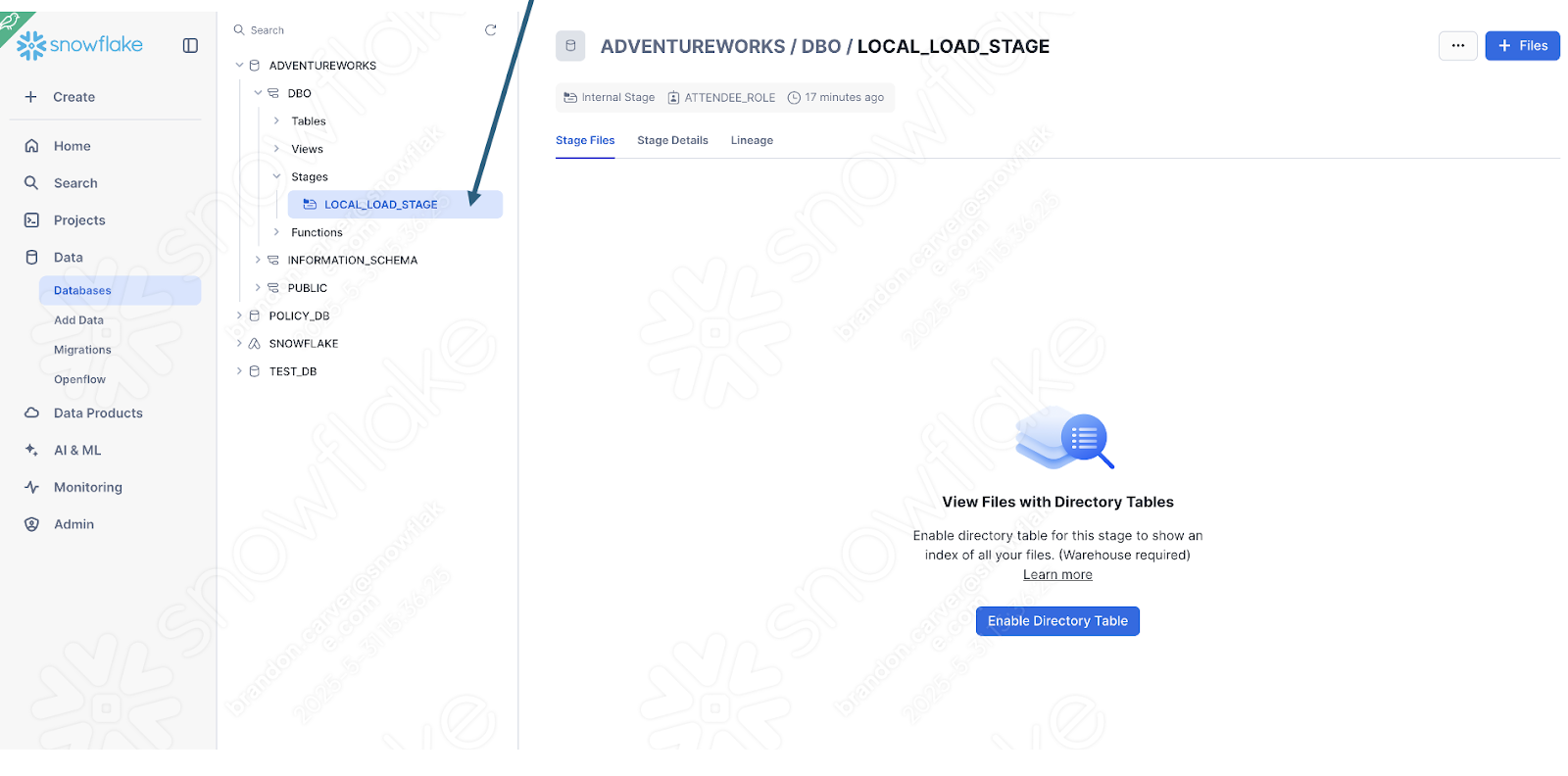
Enable the directory table view to see if the old_versions folder is in there:
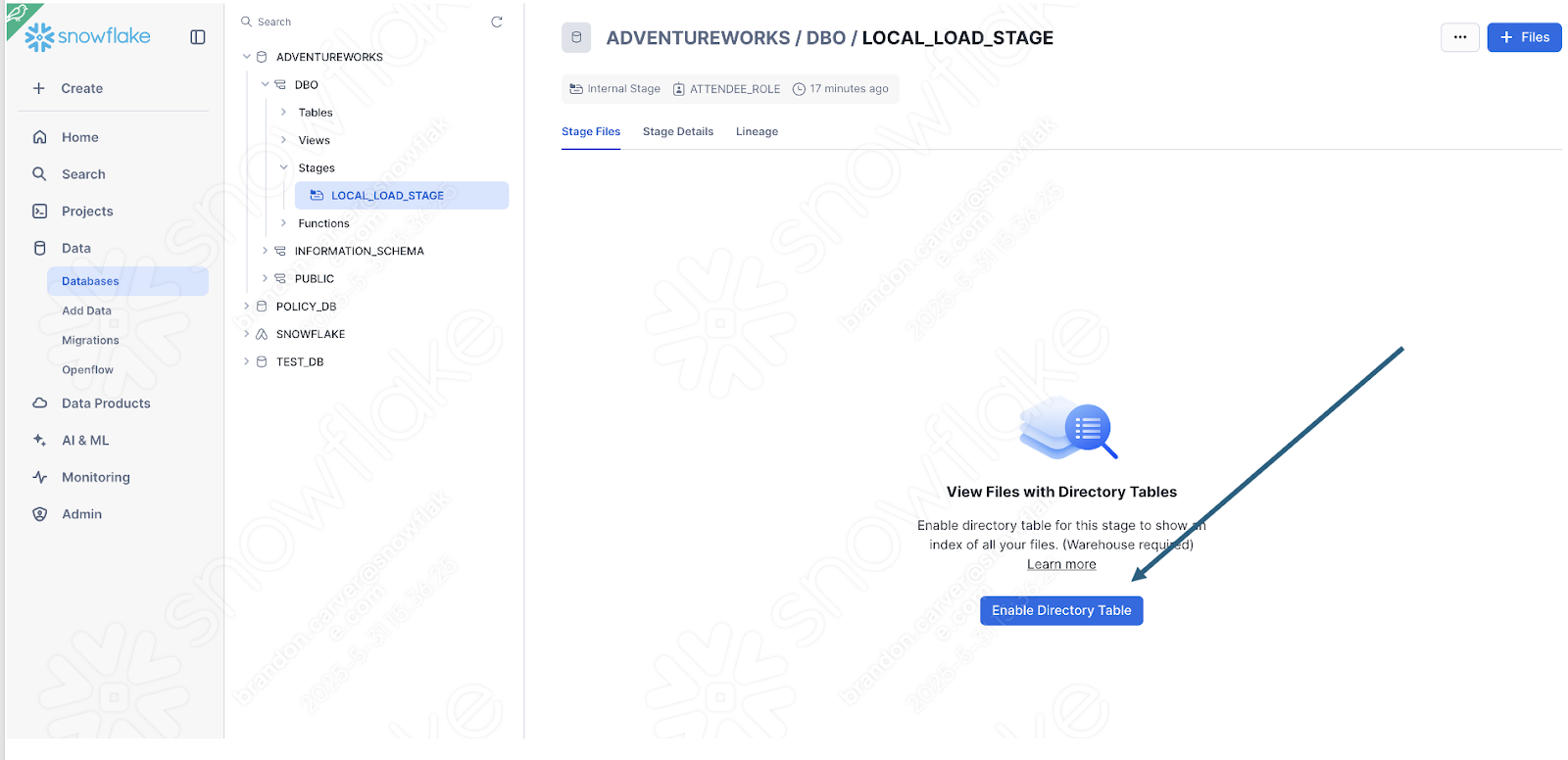
Et c’est :
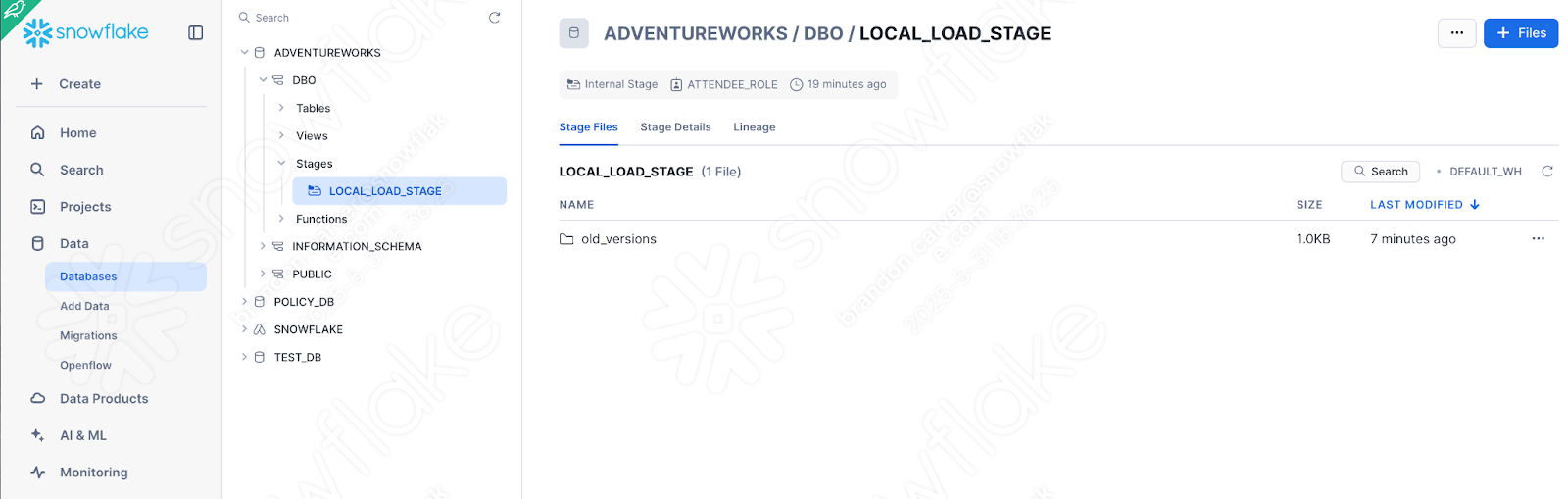
Puisqu’il s’agissait du dernier élément de notre script, on dirait que nous avons réussi !
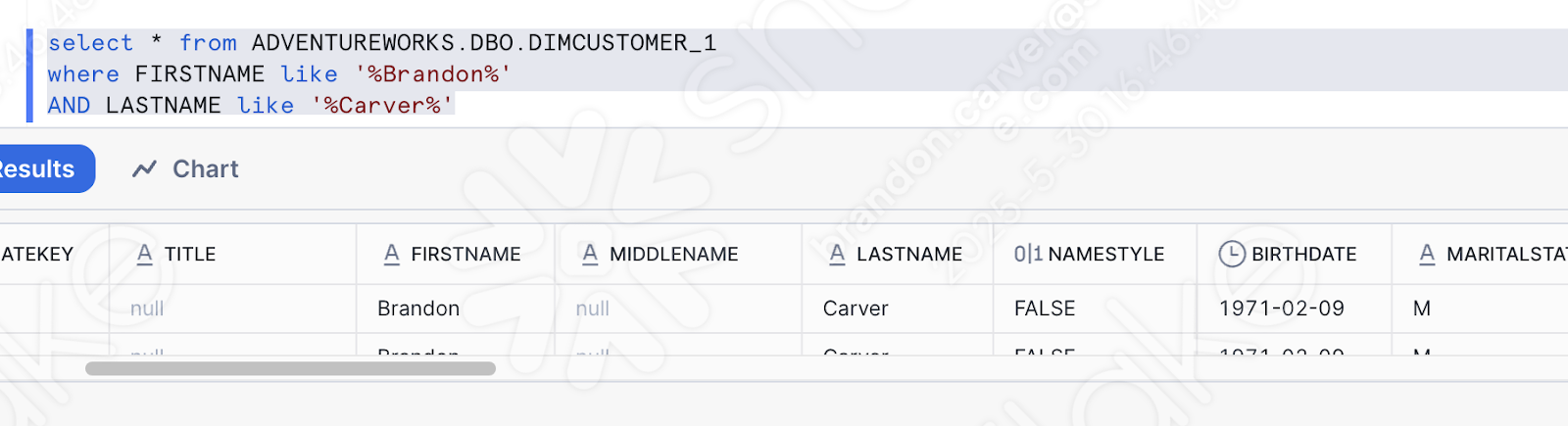
Nous pouvons également simplement valider le fait que les données ont été chargées en interrogeant simplement la table des données que nous avons chargées. Vous pouvez ouvrir une nouvelle feuille de calcul et simplement écrire cette requête :
C’est l’un des noms qui vient d’être chargé. Et il semble que notre pipeline a fonctionné :
Exécution du script de pipeline dans Snowsight¶
Jetons un coup d’œil rapide sur le flux que nous tentons de convertir dans Spark :
accès à un fichier local
chargement du résultat dans le serveur SQL
déplacement du fichier pour faire place au suivant
Ce flux ne peut pas être exécuté entièrement à partir de Snowsight. Snowsight n’a pas accès à un système de fichiers local. Ici, il serait recommandé de déplacer l’exportation du POS vers un data lake… ou de choisir toute autre option qui serait accessible via Snowsight.
Nous pouvons cependant examiner de plus près comment Snowpark gère la logique de transformation en exécutant le script Python dans Snowflake. Si vous avez déjà effectué les modifications recommandées ci-dessus, vous pouvez exécuter le corps du script dans une feuille de calcul Python dans Snowflake.
Pour ce faire, connectez-vous d’abord à votre compte Snowflake et accédez à la section des feuilles de calcul. Dans cette feuille de calcul, créez une nouvelle feuille de calcul Python :

Indiquez la base de données, le schéma, le rôle et l’entrepôt que vous souhaitez utiliser :
Nous n’avons pas à gérer notre appel de session. Vous verrez un modèle généré dans la fenêtre de la feuille de calcul :

Commençons par regrouper nos appels d’importation. Après avoir préparé le script précédent pour l’utilisation, nous devons disposer de l’ensemble suivant d’importations :
Nous n’avons besoin que des importations de Snowpark. Nous ne déplacerons pas les fichiers dans un système de fichiers. Nous pouvons conserver la référence datetime si nous souhaitons déplacer le fichier dans la zone de préparation. (Faisons-le.)
Collez les importations de Snowpark (plus datetime) dans la feuille de calcul python sous les autres importations déjà présentes. Notez que “col” est déjà importé, vous pouvez donc en supprimer l’un des éléments suivants :
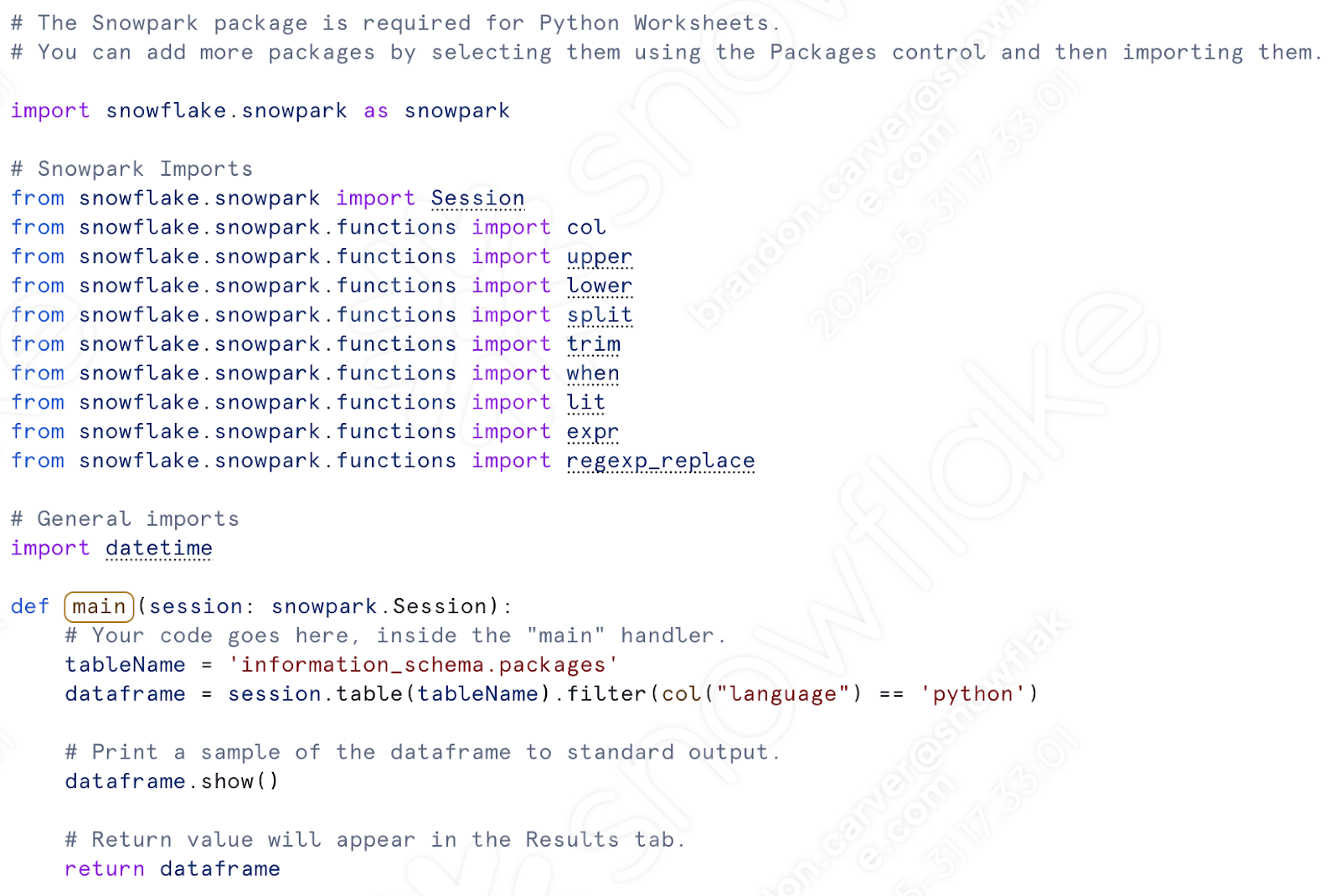
Under the “def main” call, let’s paste in all of our transformation code. This will include everything from the assignment of the csv location to the writing of the dataframe to a table.
De là :

À là :

Nous pouvons également rajouter du code qui déplace les fichiers dans la zone de préparation. Cette partie :
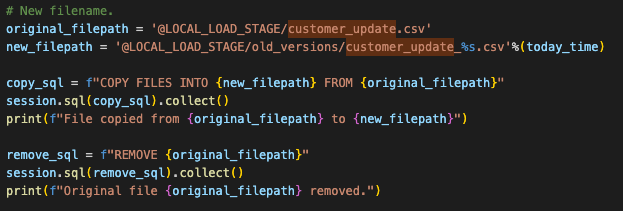
Before you can run the code though, you will have to manually create the stage and move the file into the stage. We can add the create stage statement into the script, but we would still need to manually load the file into the stage.
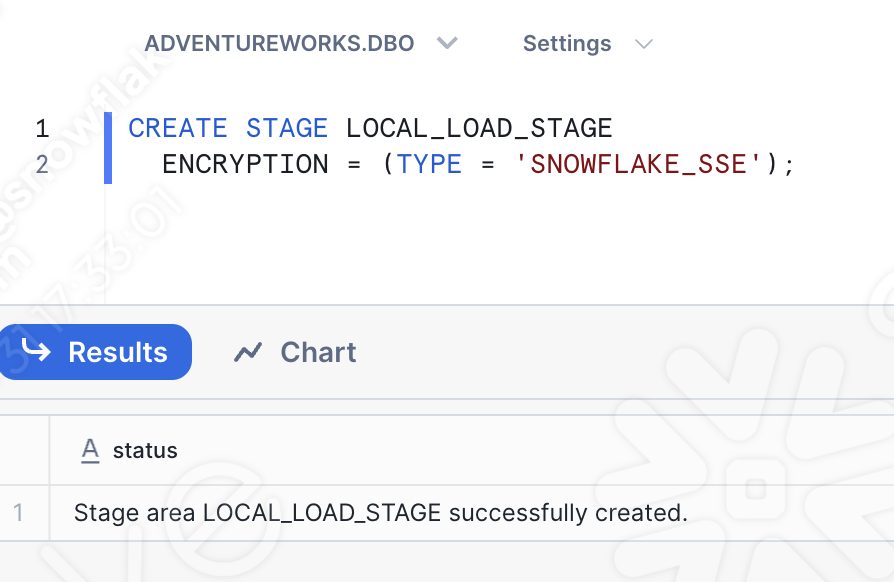
Ainsi, si vous ouvrez une autre feuille de calcul (cette fois-ci, une feuille de calcul SQL), vous pouvez exécuter une instruction SQL de base qui créera la zone de préparation :
Assurez-vous de sélectionner la base de données, le schéma, le rôle et l’entrepôt corrects :
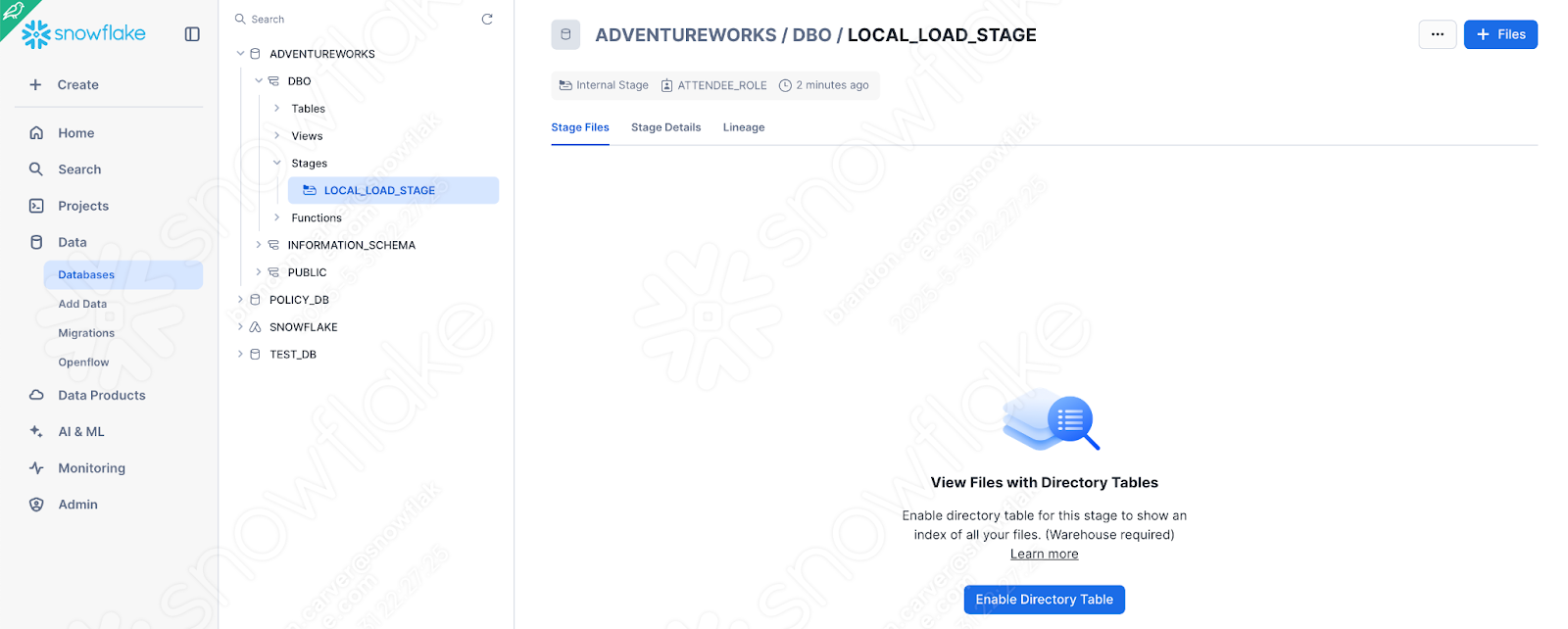
You can also create an internal stage directly in the Snowsight UI. Now that the stage exists, we can manually load the file of interest into the stage. Navigate to the Databases section of the Snowsight UI, and find the stage we just created in the appropriate database.schema:
Ajoutons notre fichier csv en sélectionnant l’option +Fichiers dans le coin supérieur droit de la fenêtre. Le menu Charger vos fichiers s’ouvre :
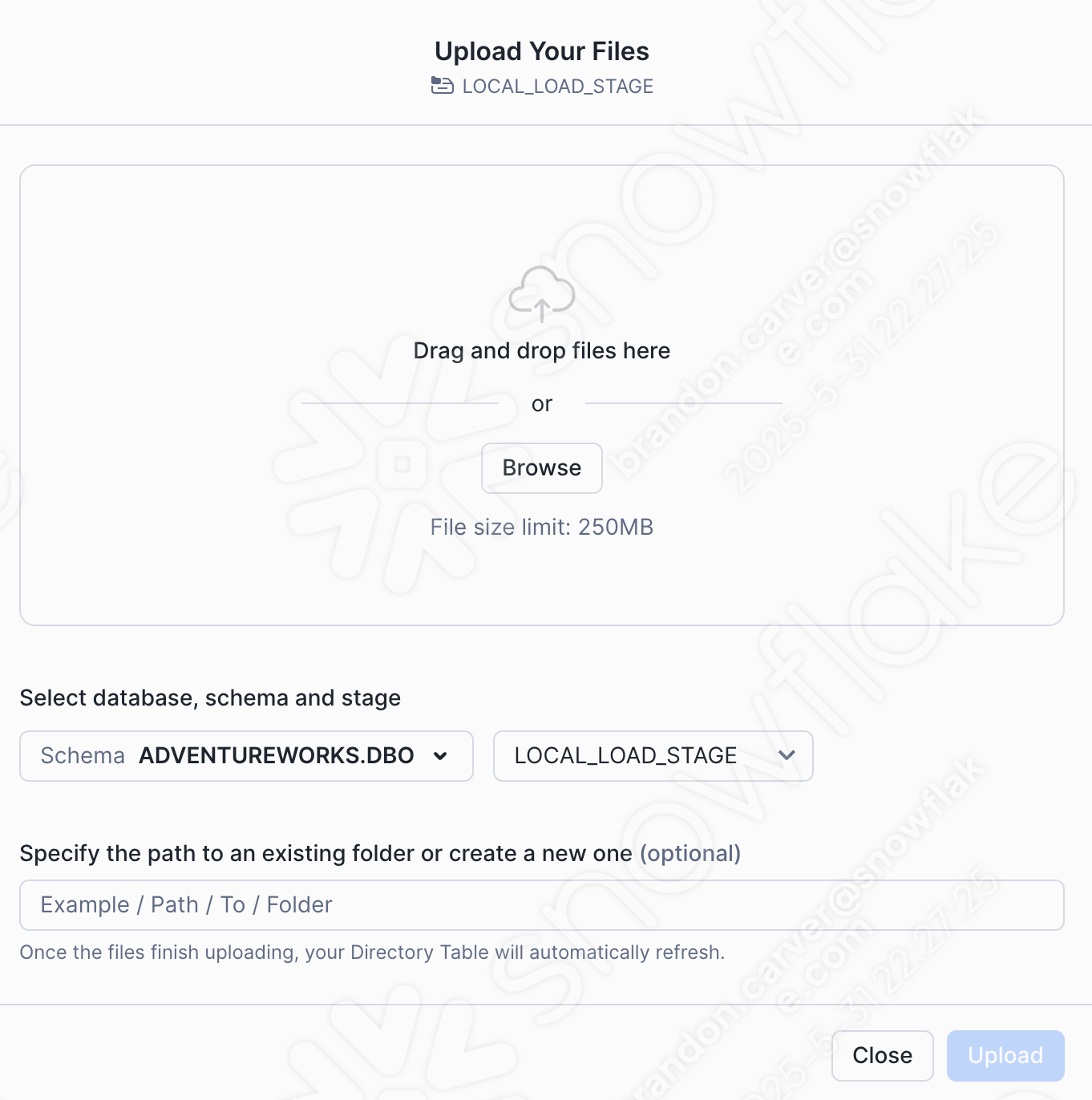
Drag and drop or browse to our project directory and load the customer_update.csv file into the stage:
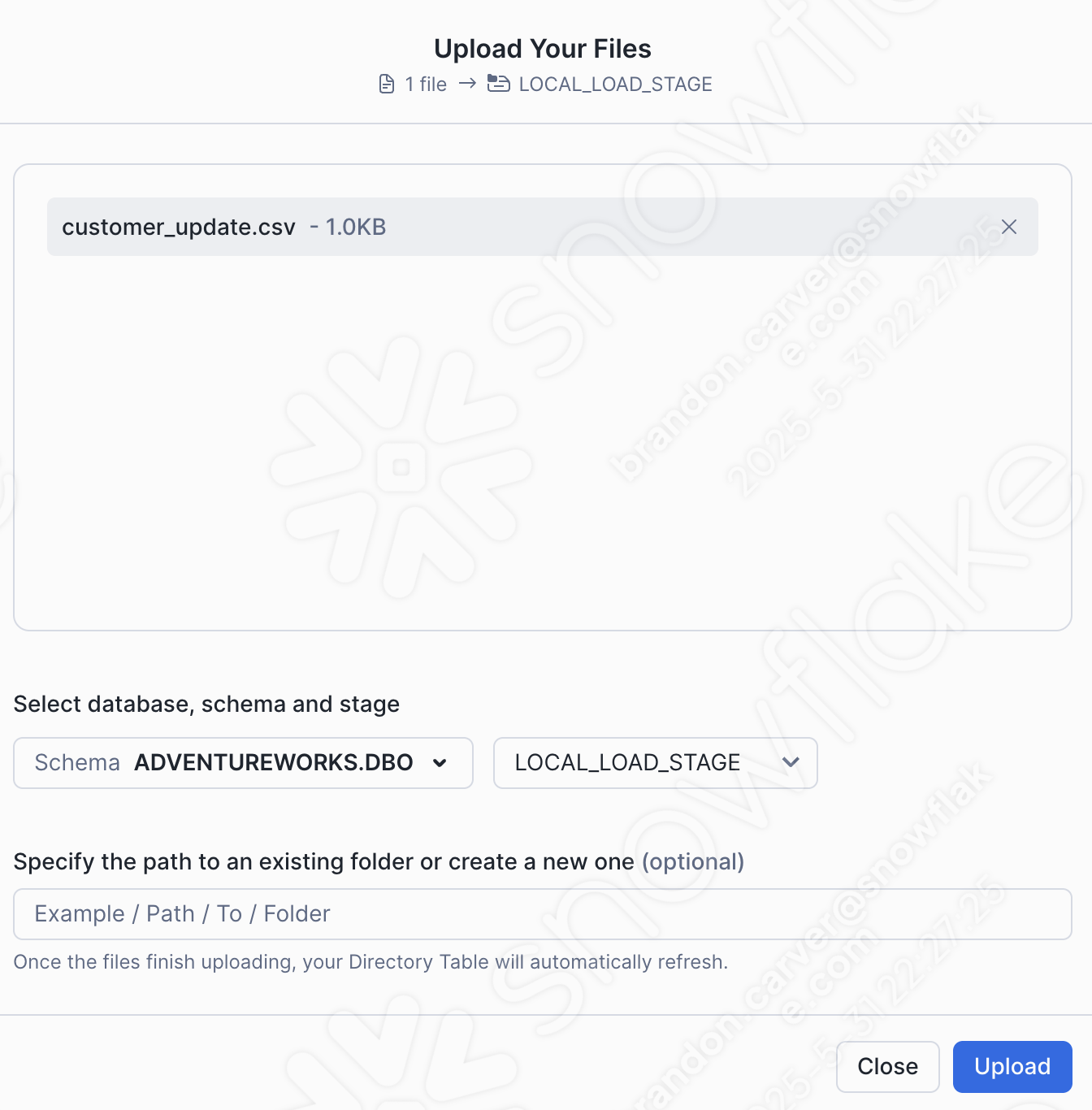
Sélectionnez Charger dans le coin inférieur droit de l’écran. Vous serez redirigé vers l’écran de la zone de préparation. Pour voir les fichiers, vous devez sélectionner Activer la table du répertoire :
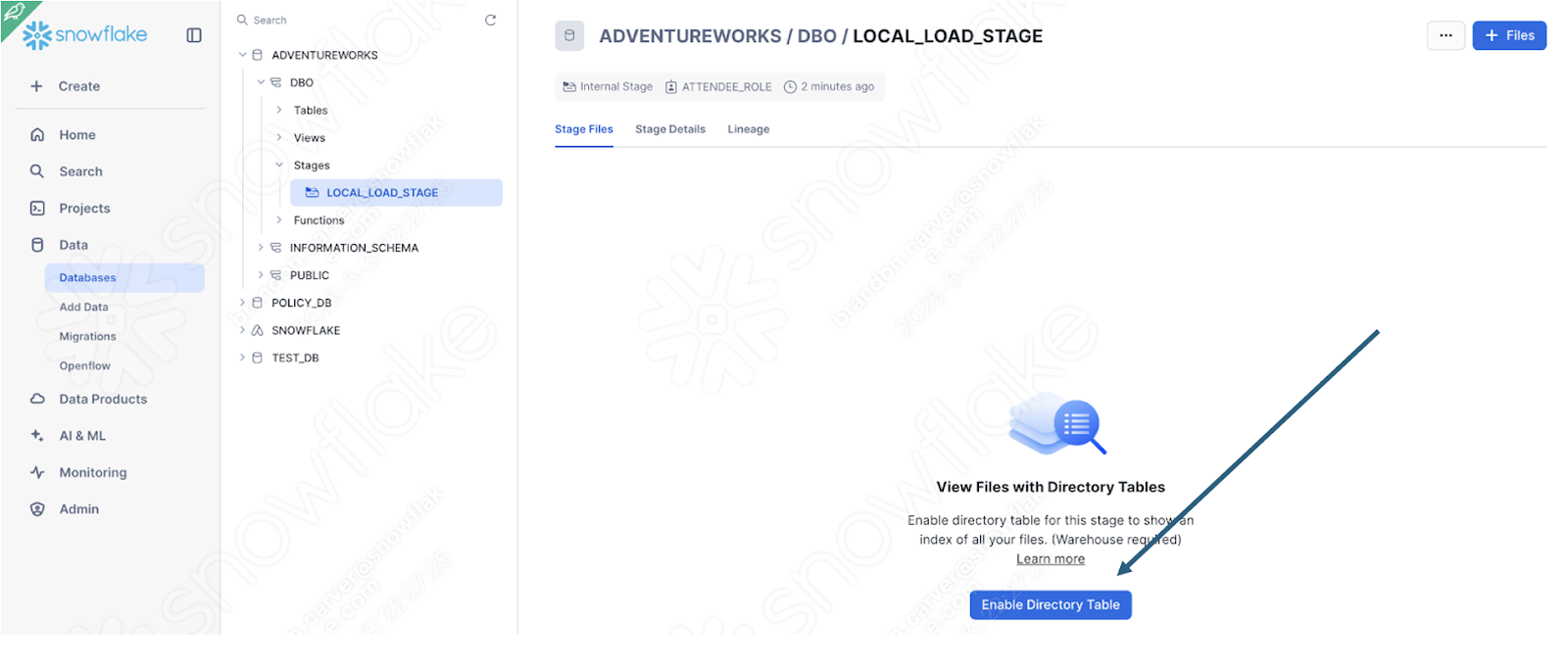
Et maintenant… notre fichier apparaît dans la zone de préparation :

Bien sûr, ce n’est plus vraiment un pipeline. Mais au moins, nous pouvons exécuter la connexion dans Snowflake. Exécutez le reste du code que vous avez déplacé dans la feuille de calcul. Cet utilisateur a réussi la première fois, mais cela n’est pas garanti la deuxième fois :
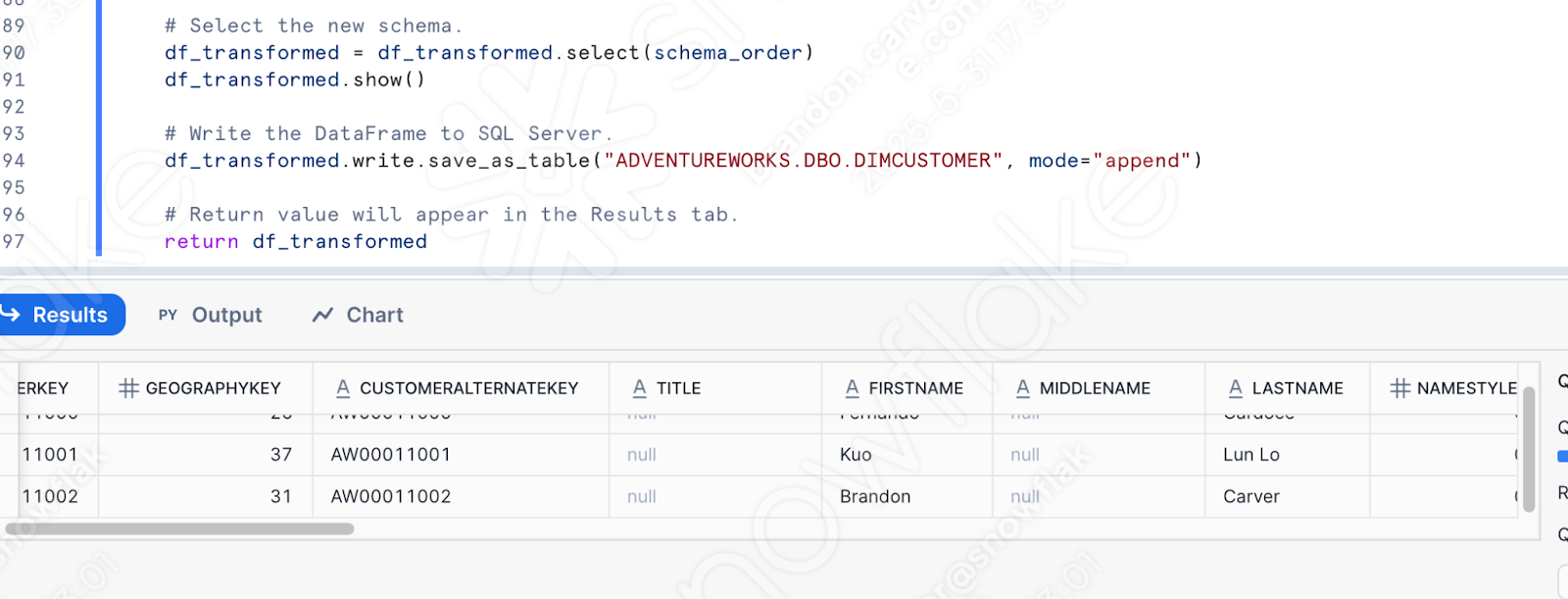
Notez qu’une fois que vous avez défini cette fonction dans Snowflake, vous pouvez l’appeler d’une autre manière. Si AdventureWorks remplace à 100 % son POS, alors il peut être utile d’avoir la logique de transformation dans Snowflake, en particulier si l’orchestration et le déplacement de fichiers seront entièrement gérés ailleurs. Cela permet à Snowpark de se concentrer sur l’endroit où il excelle dans la logique de transformation.
Conclusion¶
Et c’est tout pour le fichier de script. Ce n’est pas le meilleur exemple de pipeline, mais il est difficile de savoir comment traiter la sortie de SMA :
Résoudre tous les problèmes
Résoudre les appels de session
Résoudre les entrées/sorties
Nettoyer et tester !
Passons maintenant au notebook de rapports.