Snowpark Migration Accelerator: Pipeline-Konvertierung¶
Der SMA hat unsere Skripte „konvertiert“, aber ist das wirklich der Fall? Tatsächlich wurden alle Referenzen aus der Spark API zur Snowpark API konvertiert, aber was nicht getan wurde, ist, die Verbindungen zu ersetzen, die möglicherweise in Ihren Pipelines vorhanden sind.
Die Stärke des SMA liegt in dem erstellten Bewertungsbericht, da die Konvertierung an die Konvertierung von Referenzen aus der Spark API zur Snowpark API gebunden ist. Beachten Sie, dass die Konvertierung dieser Referenzen nicht ausreicht, um eine Datenpipeline zu betreiben. Sie müssen sicherstellen, dass die Verbindungen der Pipeline manuell aufgelöst werden. Der SMA kann nicht davon ausgehen, dass Verbindungsparameter oder andere Elemente bekannt sind, die wahrscheinlich nicht für die Ausführung verfügbar sind.
Wie bei jeder Konvertierung kann auch der konvertierte Code auf verschiedene Weisen verarbeitet werden. Die folgenden Schritte sind die Empfehlung, die Sie für die Ausgabe des Konvertierungstools verwenden sollten. Genau wie SnowConvert erfordert der SMA, dass der Ausgabe Aufmerksamkeit geschenkt wird. Keine Konvertierung wird jemals zu 100 % automatisiert sein. Dies gilt insbesondere für den SMA. Da der SMA Referenzen aus der Spark API zur Snowpark APIkonvertiert, müssen Sie immer überprüfen, wie diese Referenzen ausgeführt werden. Er versucht nicht, die erfolgreiche Ausführung eines Skripts oder Notebooks zu orchestrieren, das darüber ausgeführt wird.
Wir werden also die folgenden Schritte ausführen, um die Ausgabe des SMA durchzugehen, was sich etwas von SnowConvert unterscheiden wird:
Alle Probleme lösen: „Probleme“ bezeichnet hier die Probleme, die durch den SMA erzeugt werden. Werfen Sie einen Blick auf den Ausgabecode. Beheben Sie Parsing-Fehler und Konvertierungsfehler, und untersuchen Sie die Warnungen.
Sitzungsaufrufe auflösen: Wie der Sitzungsaufruf im Ausgabecode geschrieben wird, hängt davon ab, wo die Datei ausgeführt werden soll. Wir werden das Problem lösen, um die Codedateien an dem gleichen Speicherort auszuführen, an dem sie ursprünglich ausgeführt werden sollten, und um sie anschließend in Snowflake auszuführen.
Ein-/Ausgaben auflösen: Verbindungen zu verschiedenen Quellen können nicht vollständig durch den SMA aufgelöst werden. Es gibt Unterschiede zwischen den Plattformen, und der SMA wird dies in der Regel ignorieren. Dies wird auch davon beeinflusst, wo die Datei ausgeführt werden soll.
** Bereinigen und Testen **! Lassen Sie uns den Code ausführen. Überprüfen Sie, ob es funktioniert. Wir werden in diesen praktischen Übungen einfache Tests durchführen, aber es gibt Tools, mit denen Sie umfangreichere Tests und Datenvalidierungen durchführen können, einschließlich Snowpark Python Checkpoints.
Schauen wir uns also an, wie das aussieht. Wir werden dies mit zwei Ansätzen tun: Der erste Ansatz besteht darin, dies in Python auf dem lokalen Rechner auszuführen (wenn das Quellskript ausgeführt wird). Der zweite Ansatz wäre, alles in Snowflake zu tun … in Snowsight, aber für eine Datenpipeline, die aus einer lokalen Quelle liest, wird dies in Snowsight nicht zu 100 % möglich sein. Das ist aber in Ordnung. Wir konvertieren die Orchestrierung dieses Skripts nicht in dieses POC.
Beginnen wir mit der Pipeline-Skriptdatei und kommen im nächsten Abschnitt zum Notebook.
Probleme beheben¶
Lassen Sie uns unseren Quellcode und unseren Ausgabecode in einem Code-Editor öffnen. Sie können einen Code-Editor Ihrer Wahl verwenden, aber wie bereits erwähnt, würde Snowflake die Verwendung von VS Code mit der Snowflake-Erweiterung empfehlen. Die Snowflake-Erweiterung hilft nicht nur bei der Navigation durch die Probleme von SnowConvert, sondern kann auch Snowpark-Checkpoints für Python ausführen, was bei Tests und Ursachenanalysen hilfreich wäre (wenn auch der Bereich dieser praktischen Übungen nicht spezifiziert ist).
Lassen Sie uns das Verzeichnis öffnen, das wir ursprünglich im Bildschirm für die Projekterstellung (Spark ADW Lab) in VS Code erstellt haben:
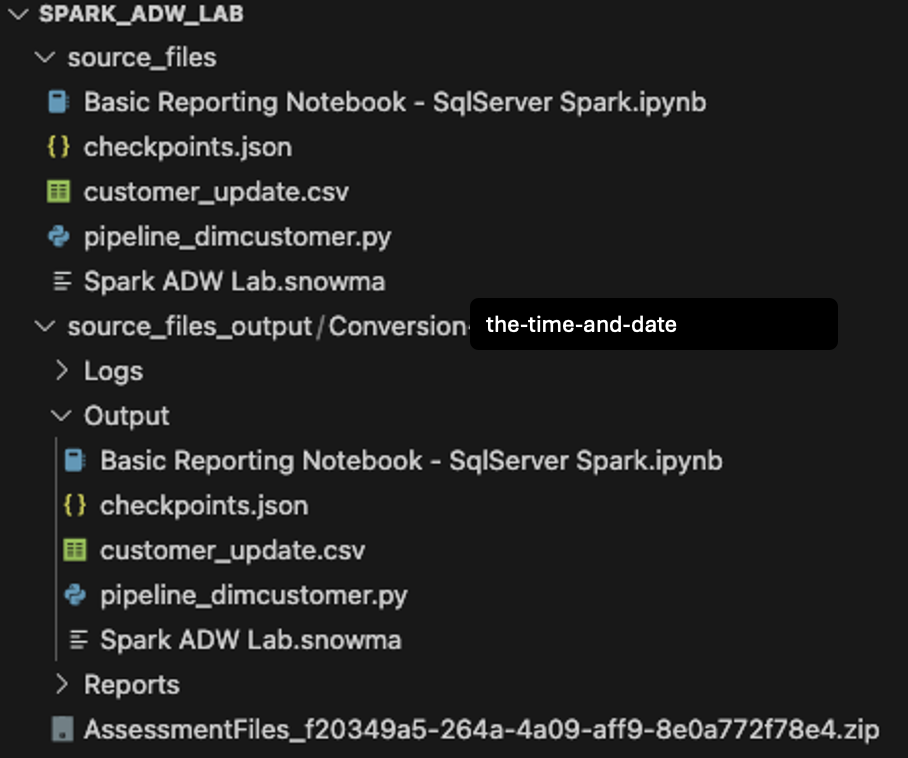
Beachten Sie, dass die Verzeichnisstruktur Ausgabe dieselbe ist wie die des Eingabeverzeichnisses. Sogar die Datendatei wird mit kopiert, obwohl keine Konvertierung stattfindet. Es wird auch ein paar checkpoints.json-Dateien geben, die vom SMA erstellt werden. Dies sind JSON-Dateien, die Anweisungen für die Snowpark Checkpoints-Erweiterung enthalten. Die Snowflake-Erweiterung kann auf der Grundlage der Daten in diesen Dateien Checkpoints sowohl in den Quell- als auch in den Ausgabecode laden. Wir werden sie vorerst ignorieren.
Vergleichen wir zum Schluss das Eingabe-Python-Skript mit dem konvertierten Skript im Ausgabeskript.
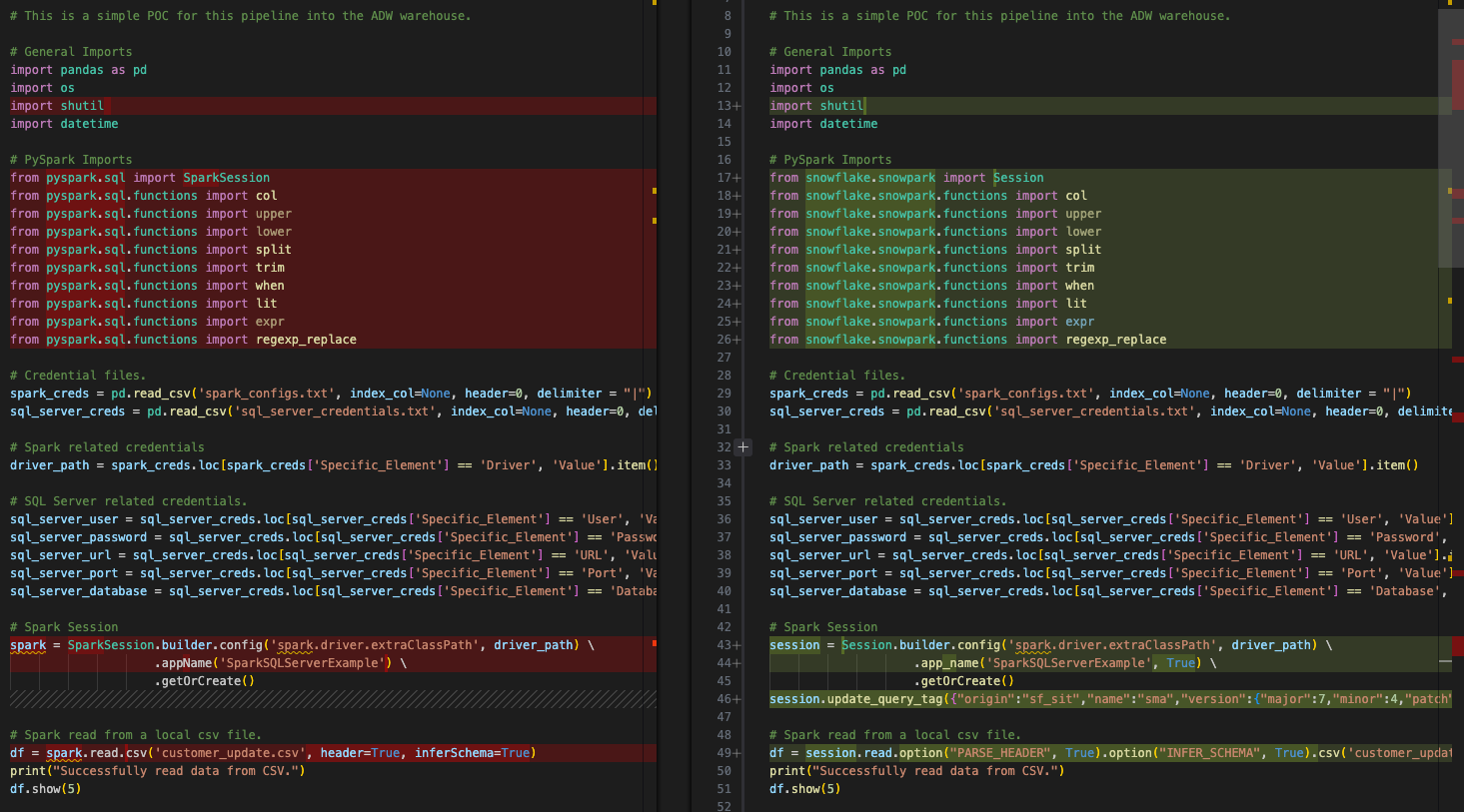
Dies ist ein sehr einfacher Vergleich mit dem ursprünglichen Spark-Code auf der linken Seite und dem ausgegebenen Snowpark-kompatiblen Code auf der rechten Seite. Es sieht so aus, als ob einige Importe sowie die Sitzungsaufrufe konvertiert wurden. Wir können eine EWI am unteren Rand des obigen Bildes sehen, aber wir beginnen dort nicht. Wir müssen den Parsing-Fehler finden, bevor wir etwas anderes tun können.
Wir können das Dokument nach dem Fehlercode für diesen Parsing-Fehler durchsuchen, der sowohl in der UI und in der Datei „issues.csv“: SPRKPY1101 angezeigt wurde.
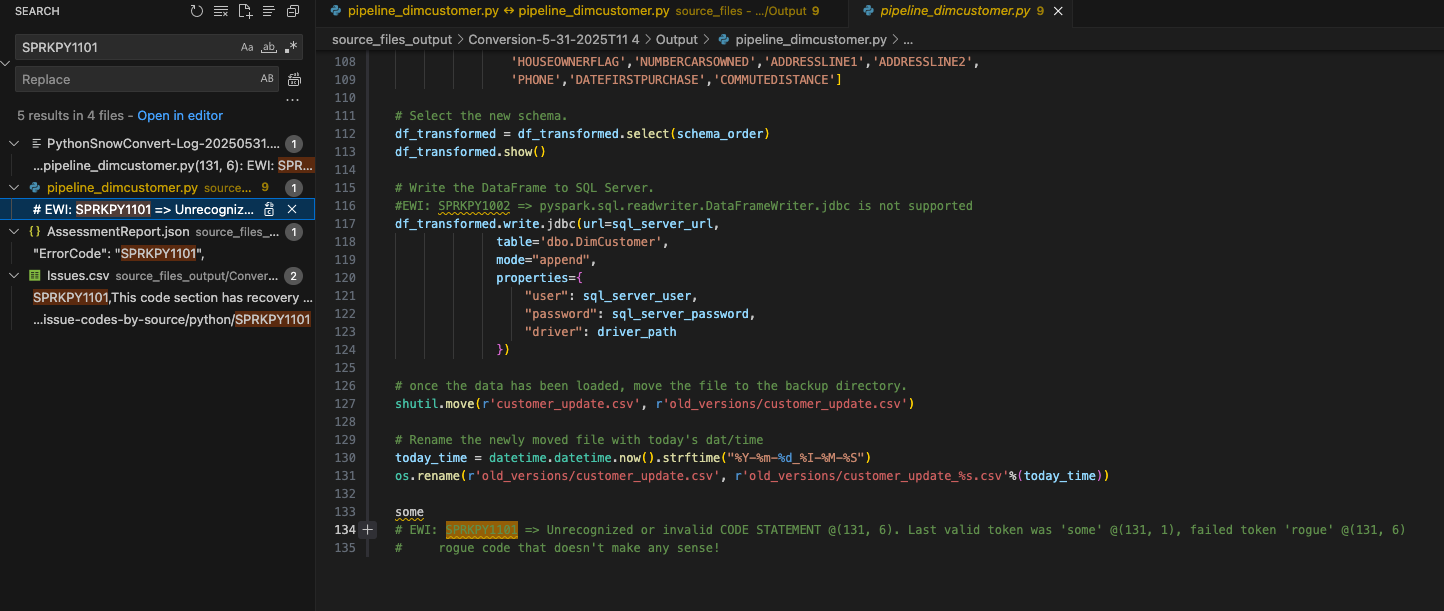
Since I have not filtered the results, the listing of this error code in the issues.csv also comes up in the search and the AssessmentReport.json that is used to build the AssessmentReport.docx summary assessment report. This is the main report that users will navigate through to understand a large workload, but we did not look at it in this lab. (More info on the this report can be found in the SMA documentation.) Let’s choose where this EWI shows up in the pipeline_dimcustomer.py file as shown above.
You can see that this line of code was present at the bottom of the source code.
Es sieht so aus, als ob dieser Parsing-Fehler auf … „einen Fehlercode, der keinen Sinn ergibt!“ zurückzuführen war. Diese Codezeile befindet sich am Ende der Pipeline-Datei. Es ist nicht ungewöhnlich, dass eine Codedatei zusätzliche Zeichen oder andere Elemente im Rahmen einer Extraktion aus einer Quelle enthält. Beachten Sie, dass der SMA erkannte, dass dies kein gültiger Python-Code war und dieser den Parsing-Fehler erzeugte.
Sie können auch sehen, wie der SMA sowohl den Fehlercode als auch die Beschreibung als Kommentar in den Ausgabecode einfügt, wo der Fehler aufgetreten ist. So werden alle Fehlermeldungen in der Ausgabe angezeigt.
Da dies kein gültiger Code ist, befindet er sich am Ende der Datei und nichts weiter wurde als Ergebnis dieses Fehlers entfernt. Der ursprüngliche Code und der Kommentar können sicher aus der Ausgabecodedatei entfernt werden.
Jetzt haben wir unser erstes und schwerwiegendstes Problem gelöst. Seien Sie gespannt.
Lassen Sie uns den Rest der EWIs in dieser Datei durcharbeiten. Wir können nach „EWI“ suchen, weil wir jetzt wissen, dass bei jedem Fehlercode ein Text im Kommentar erscheint. (Alternativ dazu könnten wir die Datei „issues.csv“ sortieren und die Probleme nach Schweregrad sortieren, aber das ist hier nicht wirklich notwendig.)
Der nächste ist eigentlich nur eine Warnung, kein Fehler. Das zeigt uns, dass eine Funktion verwendet wurde, die in Spark und Snowpark nicht immer gleichwertig ist:
Die Beschreibung hier verdeutlicht jedoch, dass wir uns darüber wahrscheinlich keine Gedanken machen müssen. Es werden nur zwei Parameter übergeben. Belassen wir diese EWI als Kommentar in der Datei, damit wir wissen, dass wir darauf achten müssen, wenn wir die Datei später ausführen.
Der letzte Fehler für diese Datei ist ein Konvertierungsfehler, der besagt, dass etwas nicht unterstützt wird:

Dies ist der Schreibaufruf für den Spark-Jdbc-Treiber, um den Ausgabe-Datenframe in SQL Server zu schreiben. Da dies Bestandteil des Schritts „Alle Ein-/Ausgaben auflösen“ ist, mit dem wir uns befassen werden, nachdem wir unsere Probleme behoben haben, behalten wir dies für später bei. Beachten Sie jedoch, dass dieser Fehler behoben werden muss. Der vorherige Fehler war nur eine Warnung und funktioniert möglicherweise auch ohne Änderungen.
Auflösen der Sitzungsaufrufe¶
Die Sitzungsaufrufe werden durch den SMA konvertiert, aber Sie sollten ihnen besondere Aufmerksamkeit schenken, um sicherzustellen, dass sie funktionsfähig sind. In unserem Pipeline-Skript ist dies der Vorher-Nachher-Code:

Die SparkSession-Referenz wurde in „Sitzung“ geändert. Sie können diese Referenzänderung am Anfang dieser Datei auch in der Importanweisung sehen:

Beachten Sie, dass in der obigen Abbildung die Variablenzuweisung des Sitzungsaufrufs für „spark“ nicht geändert wird. Das liegt daran, dass es sich um eine Variablenzuweisung handelt. Es ist nicht notwendig, dies zu ändern, aber wenn Sie den „spark“-Decorator in „Sitzung“ ändern möchten, würde dies besser den Empfehlungen von Snowpark entsprechen. (Beachten Sie, dass die VS Code-Erweiterung „SMA Assistant“ ebenfalls diese Änderungen vorschlagen wird.)
Dies ist eine einfache Übung, die sich aber lohnt. Sie können den Vorgang „Suchen und Ersetzen“ unter Verwendung der eigenen Suchfunktion von VS Code durchführen, um die Verweise auf „spark“ in dieser Datei zu finden und sie durch „session“ zu ersetzen. Sie können das Ergebnis in der Abbildung unten sehen. Die Verweise auf die Variable „spark“ im konvertierten Code wurden durch „session“ ersetzt:

Wir können auch etwas anderes aus diesem Sitzungsaufruf entfernen. Da wir „spark“ nicht mehr ausführen werden, müssen wir den Treiberpfad für den spark-Treiber nicht mehr angeben. So können wir die Konfigurationsfunktion wie folgt vollständig aus dem Sitzungsaufruf entfernen:
Might as well convert it to a single line. The SMA couldn’t be sure we didn’t need that driver (although that seems logical), so it did not remove it. But now that we have our session call is complete.
(Beachten Sie, dass der SMA der Sitzung außerdem ein „Abfrage-Tag“ hinzufügt. Dies dient dazu, später Probleme mit dieser Sitzung oder Abfrage zu beheben. Dies ist jedoch völlig optional, diese Möglichkeit zu nutzen oder zu entfernen.)
Hinweise zu den Sitzungsaufrufen¶
Ob Sie es glauben oder nicht: Das ist alles, was wir im Code für den Sitzungsaufruf ändern müssen, aber das ist nicht alles, was wir tun müssen, um die Sitzung zu erstellen. Dies bezieht sich auf die ursprüngliche Frage, dass ein Großteil davon abhängig ist, wo Sie diese Dateien ausführen möchten. Diese ursprünglichen spark-Sitzungsaufrufe verwendeten eine Konfiguration, die an anderer Stelle eingerichtet wurde. Wenn Sie sich den ursprünglichen Spark-Sitzungsaufruf ansehen, sucht dieser nach einer Konfigurationsdatei, die zu Beginn dieser Skriptdatei in einen pandas-Datenframe-Speicherort eingelesen wird (dies gilt tatsächlich auch für unsere Notebook-Datei).
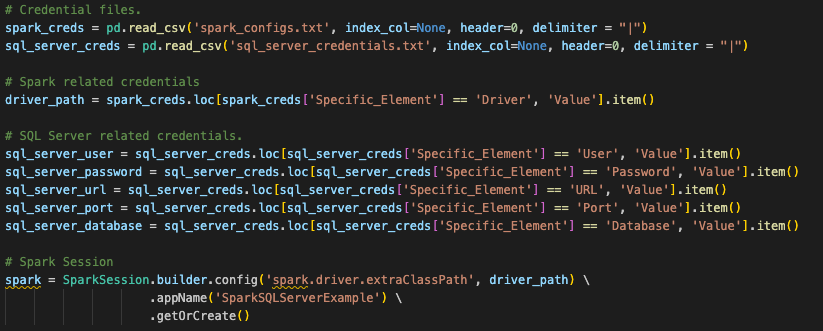
Snowpark can function the same way, and this conversion assumes that is how this user will run this code. However, for the existing session call to work, the user would have to load all of the information for their Snowflake account into the local (or at least accessible) connections.toml file on this machine, and that the account they are attempting to connect to is set as the default. You can learn more about updating the connections.toml file in the Snowflake/Snowpark documentation, but the idea behind it is that there is an accessible location that has the credentials. When a snowpark session is created, it is going to check this… unless the connection parameters are explicitly passed to the session call.
Standardmäßig werden die Verbindungsparameter direkt als Zeichenfolgen eingegeben und mit der Sitzung aufgerufen:
AdventureWorks appears to have referenced a file with these credentials and called it. Assuming there is a similar file called ‚snowflake_credentials.txt‘ that is accessible, then the syntax that would match that could look something like:
For the purpose of the time limit on this lab, the first option may make more sense. There’s more on this in the Snowpark documentation.
Beachten Sie, dass Sie nichts davon tun müssen, damit unsere Notebook-Datei innerhalb von Snowflake mit Snowsight ausgeführt wird. Sie würden einfach die aktive Sitzung aufrufen und sie ausführen.
Jetzt ist es Zeit für die kritischste Komponente dieser Migration – nämlich alle Eingabe-/Ausgabereferenzen aufzulösen.
Auflösen der Eingaben und Ausgaben¶
Lassen Sie uns nun unsere Ein- und Ausgaben auflösen. Beachten Sie, dass dies davon abweicht, ob Sie die Dateien lokal oder in Snowflake ausführen. Für das Python-Skript stellen wir sicher, was wir gewinnen/verlieren, wenn wir direkt innerhalb von Snowsight ausführen: Sie können nicht den gesamten Vorgang in Snowsight ausführen (zumindest nicht derzeit). Die lokale CSV-Datei ist nicht über Snowsight zugänglich. Sie müssen die CSV-Datei manuell in einen Stagingbereich laden. Dies wird wahrscheinlich keine ideale Lösung sein, aber wir können die Konvertierung damit testen.
Wir bereiten diese Datei also zunächst so vor, dass sie lokal ausgeführt/orchestriert und dann in Snowflake ausgeführt werden kann.
Um die Eingaben und Ausgaben des Pipeline-Skripts auflösen zu können, müssen wir sie zunächst identifizieren. Sie sind recht einfach. Dieses Skript scheint Folgendes tun zu können:
Zugreifen auf eine lokale Datei
Laden des Ergebnisses in SQL Server (aber jetzt Snowflake)
Verschieben der Datei, um Platz für die nächste zu machen
Ganz einfach. Wir müssen also jede Komponente des Codes ersetzen, die diese Aufgaben erledigt. Beginnen wir mit dem Zugriff auf die lokale Datei.
Wie bereits zu Beginn erwähnt, wäre es dringend empfohlen, das Point-of-Sale-System und die Orchestrierungstools, die zur Ausführung dieses Python-Skripts verwendet werden, neu zu gestalten, um die Ausgabedatei in einen Cloudspeicherort zu speichern. Dann könnten Sie diesen Speicherort in eine externe Tabelle umwandeln, und siehe da, Sie befinden sich in Snowflake. Die aktuelle Architektur besagt jedoch, dass sich diese Datei nicht in einem Cloudspeicherort befindet und dort bleibt, wo sie ist. Daher müssen wir eine Möglichkeit finden, wie Snowflake auf diese Datei zugreifen kann, und dabei die bestehende Logik beibehalten.
Wir haben Optionen dafür, aber wir werden einen internen Stagingbereich erstellen und die Datei mit dem Skript in den Stagingbereich verschieben. Wir müssten dann die Datei im lokalen Dateisystem und auch im Stagingbereich verschieben. Dies ist alles mit Snowpark möglich. Schauen wir uns das genauer an:
Zugreifen auf eine lokale Datei: Erstellen Sie einen internen Stagingbereich (falls noch nicht vorhanden) -> Laden Sie die Datei in den Stagingbereich -> Lesen Sie die Datei in einen Datenframe
Laden des Ergebnisses in SQL Server: Laden Sie die transformierten Daten in eine Tabelle in Snowflake
Verschieben der Datei, um Platz für die nächste zu machen: Verschieben Sie die lokale Datei -> Verschieben Sie die Datei in den Stagingbereich.
Schauen wir uns den Code an, der jede dieser Aufgaben erledigen kann.
Zugreifen auf eine lokal zugängliche Datei¶
Dieser Quellcode in Spark sieht wie folgt aus:
Der transformierte Snowpark-Code (durch SMA) sieht wie folgt aus:
Wir können das durch diesen Code ersetzen, der die oben genannten Schritte ausführt:
Create an internal stage (if one does not exist already). We will create a stage called ‚LOCAL_LOAD_STAGE‘ and go through a few steps to make sure that the stage is r
Laden Sie die Datei in den Stagingbereich.
Lesen Sie die Datei in einen Datenframe. Dies ist der Teil, den der SMA tatsächlich konvertiert hat. Wir müssen angeben, dass der Speicherort der Datei jetzt der interne Stagingbereich ist.
Das Ergebnis würde wie folgt aussehen:
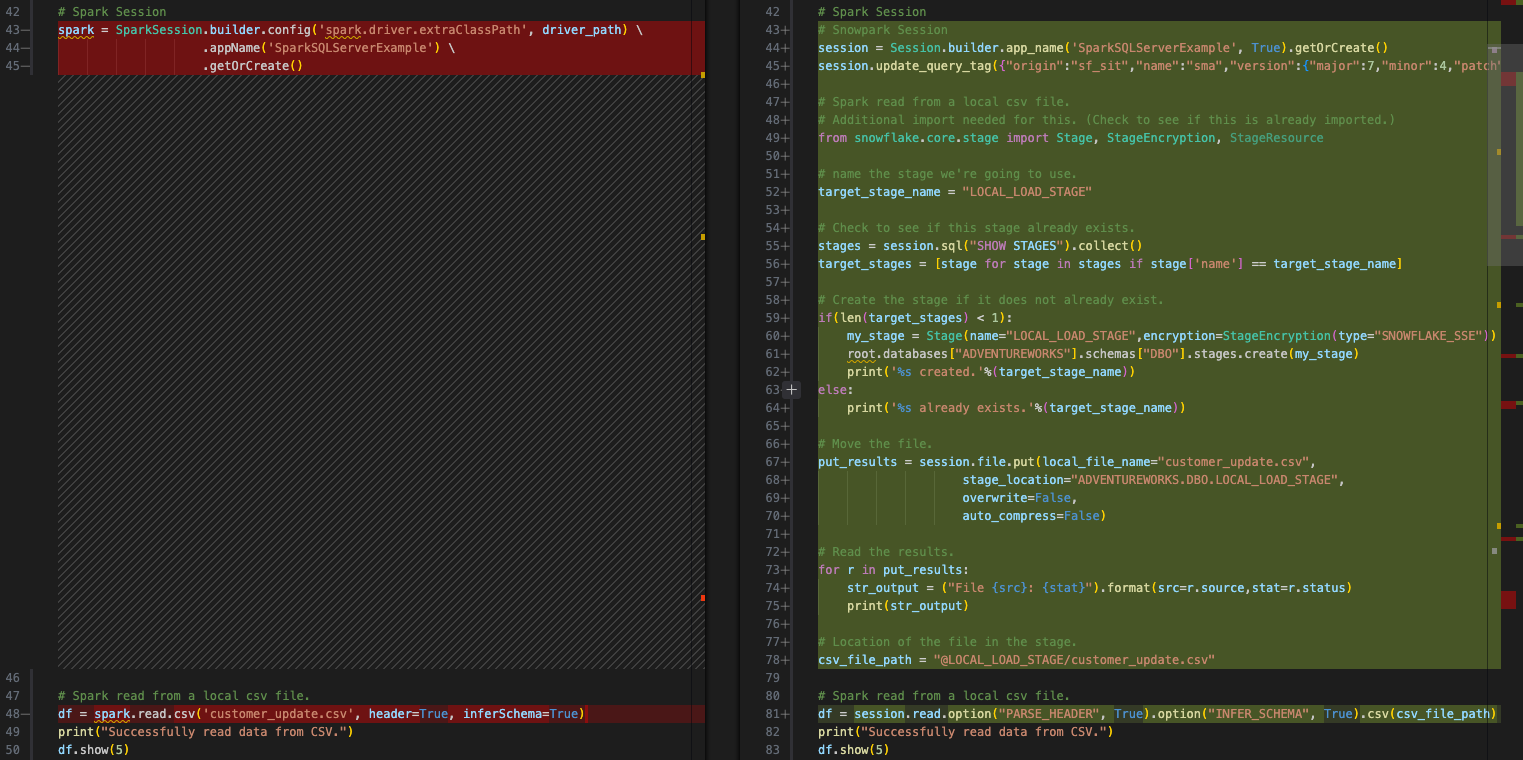
Lassen Sie uns zum nächsten Schritt übergehen.
Laden des Ergebnisses in Snowflake¶
Das ursprüngliche Skript hat den Datenframe in SQL Server geschrieben. Jetzt werden wir diesen in Snowflake laden. Dies ist eine viel einfachere Konvertierung. Der Datenframe ist bereits ein Snowpark-Datenframe. Dies ist einer der Vorteile von Snowflake. Da die Daten nun für Snowflake zugänglich sind, geschieht alles innerhalb von Snowflake.
Beachten Sie, dass wir möglicherweise in eine temporäre Tabelle schreiben möchten, um einige Tests/Validierungen durchzuführen, aber dies das Verhalten im ursprünglichen Skript ist.
Verschieben der Datei, um Platz für die nächste zu machen¶
Dies ist das Verhalten im ursprünglichen Skript. Wir müssen dies nicht wirklich in Snowflake erreichen, aber wir können es tun, um die genau gleiche Funktionalität im Stagingbereich zu demonstrieren. Dies geschieht mit einem BS-Befehl im ursprünglichen Dateisystem. Das hängt nicht von Spark ab und wird gleich bleiben. Um dieses Verhalten in Snowpark zu emulieren, müssten wir diese Datei im Stagingbereich in ein neues Verzeichnis verschieben.
Dies kann mit dem folgenden Python-Code einfach erledigt werden:
Beachten Sie, dass dies keinen der vorhandenen Codes ersetzen würde. Da wir bereits die bestehende Aktion zum Verschieben des Spark-Codes in Snowpark beibehalten möchten, werden wir die BS-Referenz so belassen. Die endgültige Version wird wie folgt aussehen:
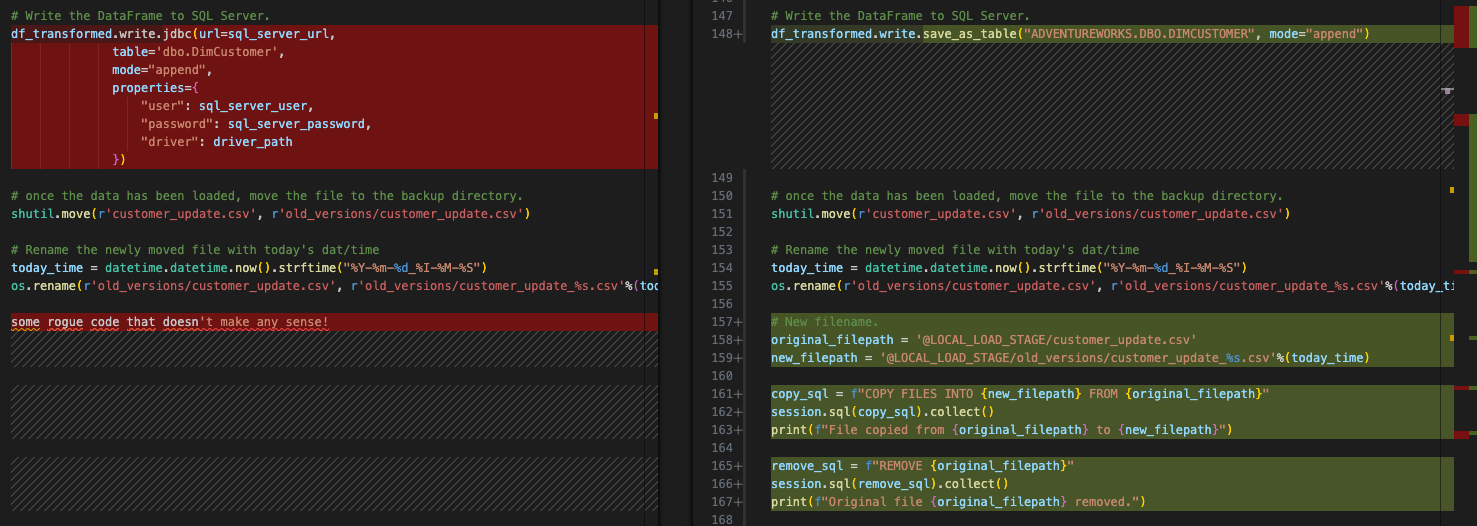
Jetzt haben wir die gleiche Aktion vollständig ausgeführt. Lassen Sie uns nun unsere letzte Bereinigung durchführen und dieses Skript testen.
Bereinigen und Testen¶
Wir haben uns unsere Importaufrufe nie angesehen und wir haben Konfigurationsdateien, die überhaupt nicht notwendig sind. Wir könnten die Verweise auf die Konfigurationsdateien so belassen und das Skript ausführen. Wenn diese Konfigurationsdateien noch zugänglich sind, wird der Code trotzdem ausgeführt. Aber wenn wir uns unsere Importanweisungen genau ansehen, können wir sie auch entfernen. Diese Dateien werden durch den gesamten Code zwischen den Importanweisungen und dem Sitzungsaufruf dargestellt:
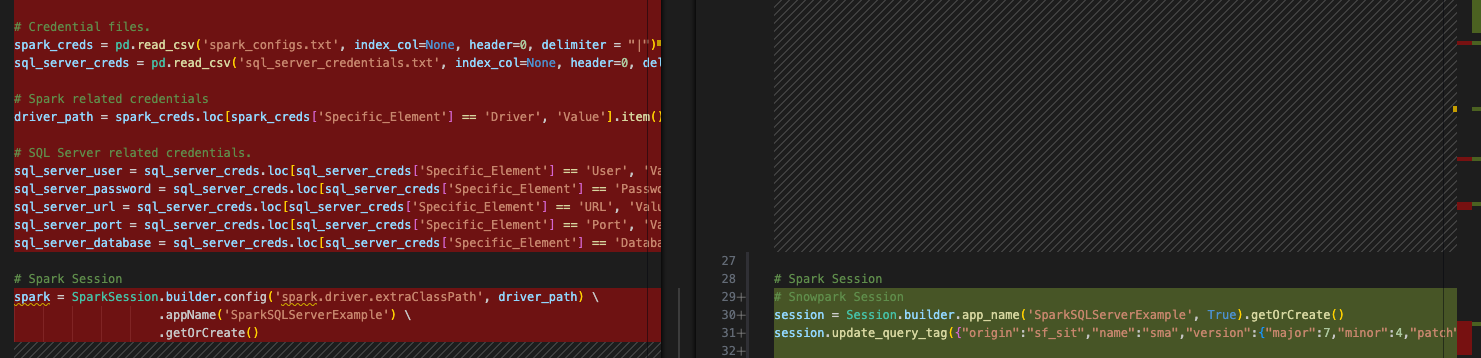
Es gibt noch ein paar andere Dinge, die wir tun sollten:
Prüfen Sie, ob alle unsere Importe immer noch erforderlich sind. Wir können sie vorerst so belassen. Wenn es einen Fehler gibt, können wir ihn beheben.
Wir haben auch eine EWI, die wir dort als Warnung gelassen haben, um sie zu überprüfen. Wir möchten also sicherstellen, dass wir diese Ausgabe prüfen.
We need to make sure that our file system behavior mirrors that of the expected file system for the POS system. To do this, we should move the customer_update.csv file into the root folder you chose when first launching VS Code.
Create a directory called “old_versions” in that same directory. This should allow the os operations to run.
Wenn Sie nicht damit vertraut sind, den Code direkt in die Produktionstabelle auszuführen, können Sie schließlich eine Kopie dieser Tabelle für diesen Test erstellen und das Laden auf diese Kopie verweisen. Ersetzen Sie die Ladeanweisung durch die unten stehende. Da es sich um praktische Übungen handelt, können Sie einfach in die Tabelle „production“ schreiben:
Jetzt sind wir schließlich bereit, dies zu testen. Wir können dieses Skript in Python für eine Testtabelle ausführen und sehen, ob dieses fehlschlägt. Beginnen wir mit der Ausführung!
Tragisch! Das Skript ist mit dem folgenden Fehler fehlgeschlagen:

Es sieht so aus, als ob die Art und Weise, wie wir einen Bezeichner referenzieren, nicht so ist, wie Snowpark es gewünscht hat. Der Code, der fehlgeschlagen ist, befindet sich genau an der Stelle, an der die verbleibende EWI ist:

Sie könnten auf die Dokumentation über den Link verweisen, der vom Fehler bereitgestellt wird, aber aus Zeitgründen benötigt Snowpark diese Variable ausdrücklich als Literal. Wir müssen die folgende Ersetzung vornehmen:
Dies sollte diesen Fehler beheben. Beachten Sie, dass es immer einige funktionale Unterschiede zwischen einer Quell- und einer Zielplattform geben wird. Konvertierungstools wie SMA möchten diese Unterschiede so offensichtlich wie möglich machen. Beachten Sie jedoch, dass keine Konvertierung zu 100 % automatisiert ist.
Lassen Sie es uns noch einmal ausführen. Dieses Mal mit Erfolg!

Wir können einige Abfragen in Python schreiben, um dies zu überprüfen, aber warum tun wir das nicht einfach in Snowflake (weil dies das ist, was wir sowieso tun werden)?
Navigieren Sie zu Ihrem Snowflake-Konto, das Sie für die Ausführung dieser Skripte verwendet haben. Dies sollte dasselbe sein, das Sie zum Laden der Datenbank von SQL Server verwendet haben (und wenn Sie das nicht getan haben, funktionieren die obigen Skripte sowieso nicht, da die Daten noch nicht migriert wurden).
You can quickly check this by seeing if the stage was created with the file:
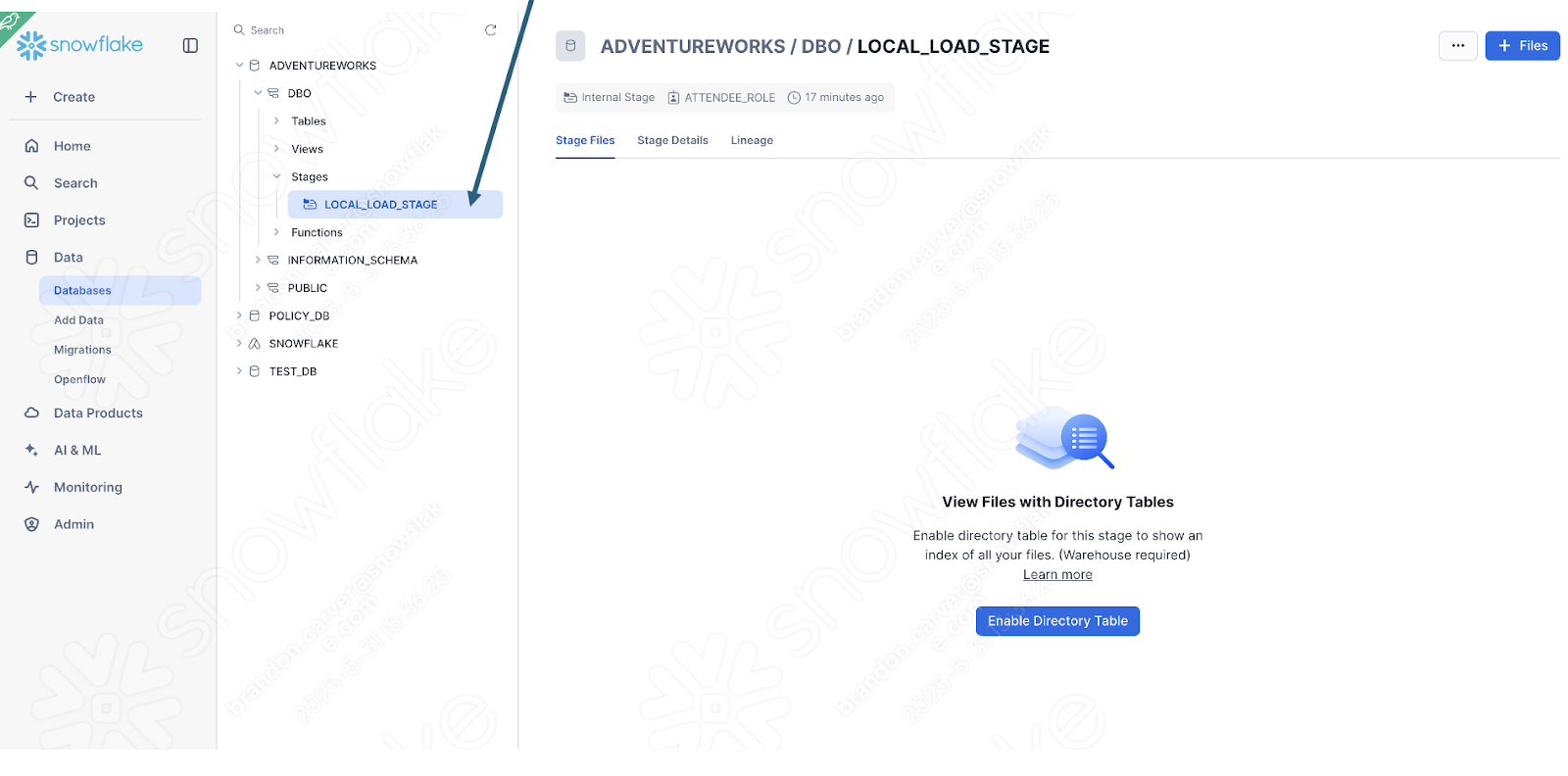
Enable the directory table view to see if the old_versions folder is in there:
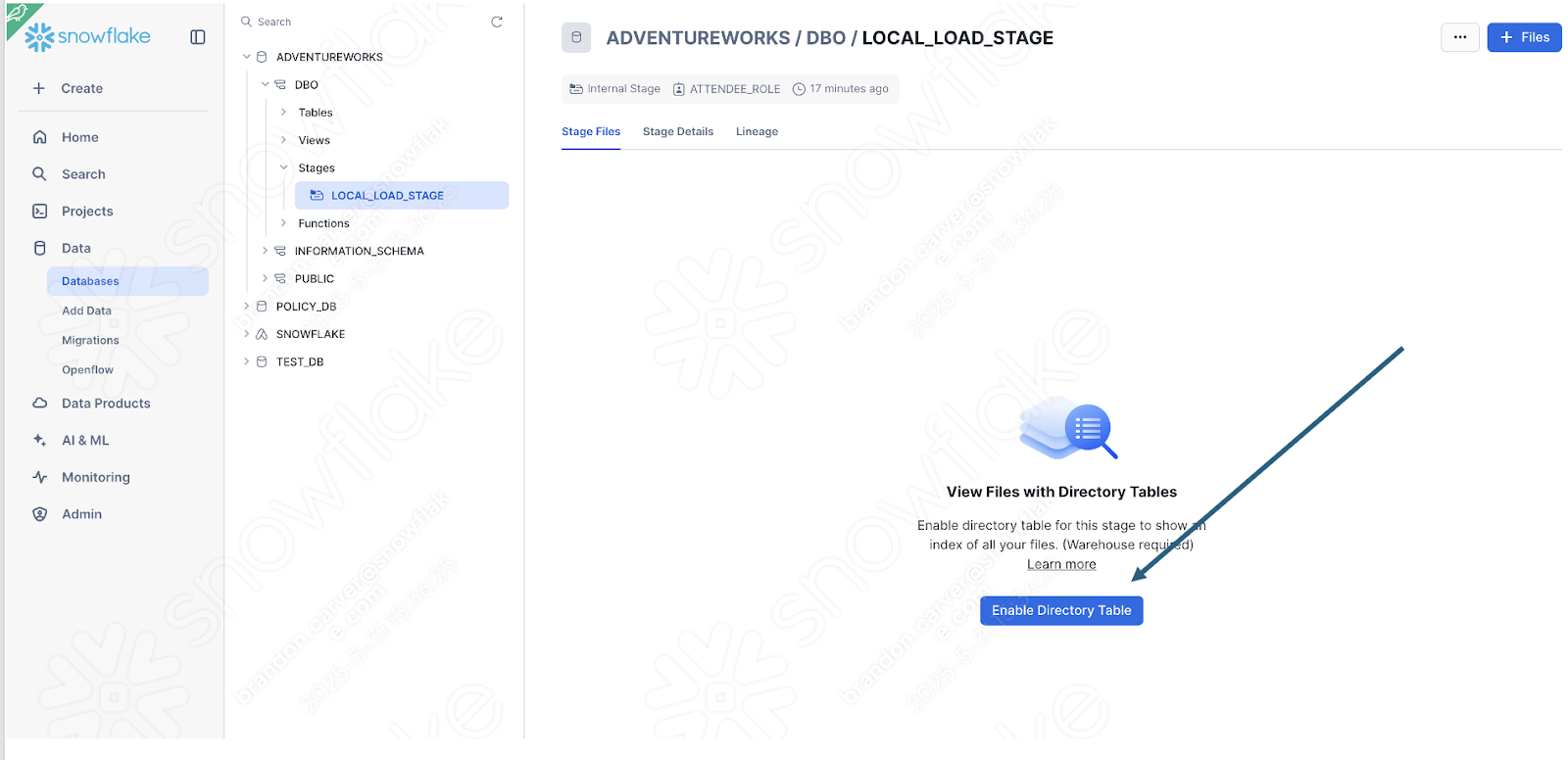
Und es ist:
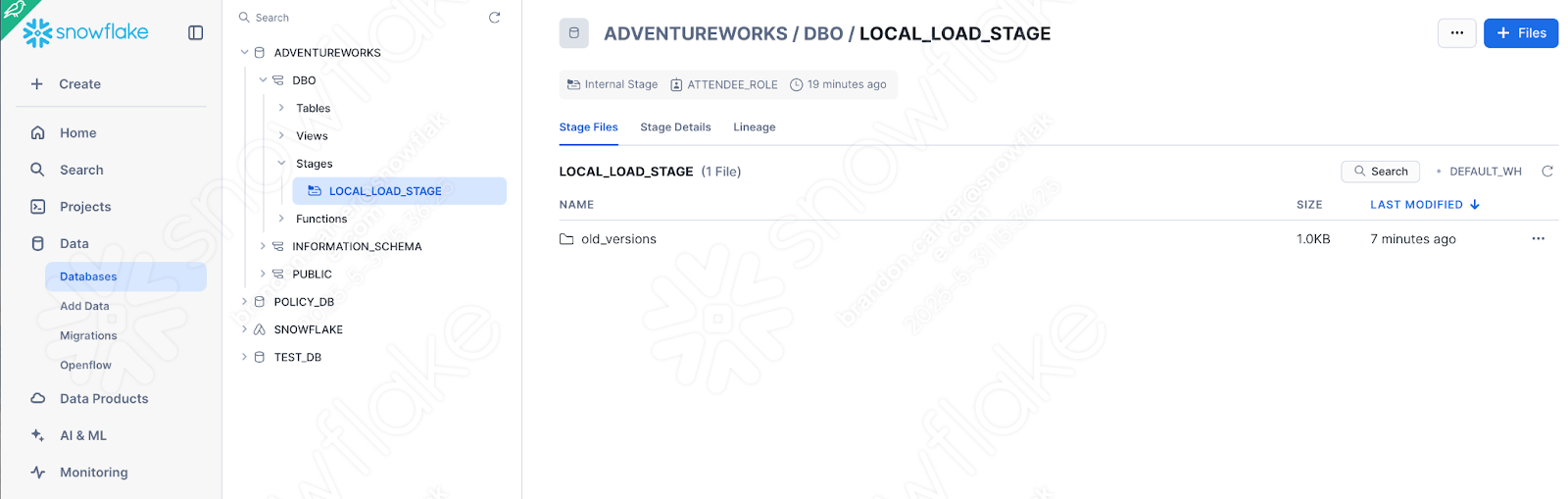
Da dies das letzte Element unseres Skripts war, sieht es so aus, als wären wir gut vorangekommen.
Wir können auch einfach überprüfen, ob die Daten geladen wurden, indem wir einfach die Tabelle nach den von uns hochgeladenen Daten abfragen. Sie können ein neues Arbeitsblatt öffnen und einfach diese Abfrage schreiben:
Dies ist einer der Namen, die gerade geladen wurden. Und es sieht so aus, als ob unsere Pipeline funktioniert hätte:
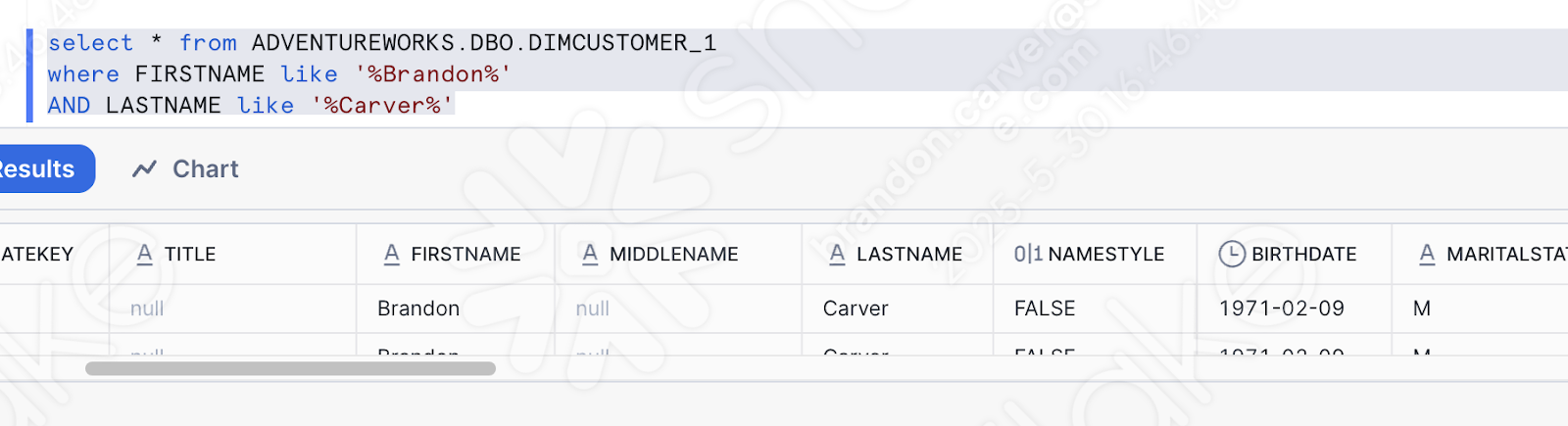
Ausführen des Pipeline-Skripts in Snowsight¶
Werfen wir einen kurzen Blick zurück auf den Ablauf, den wir in Spark ausführen möchten:
Zugreifen auf eine lokale Datei
Laden des Ergebnisses in SQL Server
Verschieben der Datei, um Platz für die nächste zu machen
Dieser Workflow kann nicht vollständig aus Snowsight heraus ausgeführt werden. Snowsight hat keinen Zugriff auf ein lokales Dateisystem. Die Empfehlung wäre hier, den Export vom POS zu einem Data Lake zu verschieben oder eine Reihe anderer Optionen, die über Snowsight zugänglich wären.
Wir können uns jedoch genauer ansehen, wie Snowpark die Transformationslogik handhabt, indem wir das Python-Skript in Snowflake ausführen. Wenn Sie die oben empfohlenen Änderungen bereits vorgenommen haben, können Sie den Textteil des Skripts in einem Python-Arbeitsblatt in Snowflake ausführen.
Melden Sie sich dazu zunächst bei Ihrem Snowflake-Konto an, und navigieren Sie zum Abschnitt „Arbeitsblätter“. Erstellen Sie in diesem Arbeitsblatt ein neues Python-Arbeitsblatt:

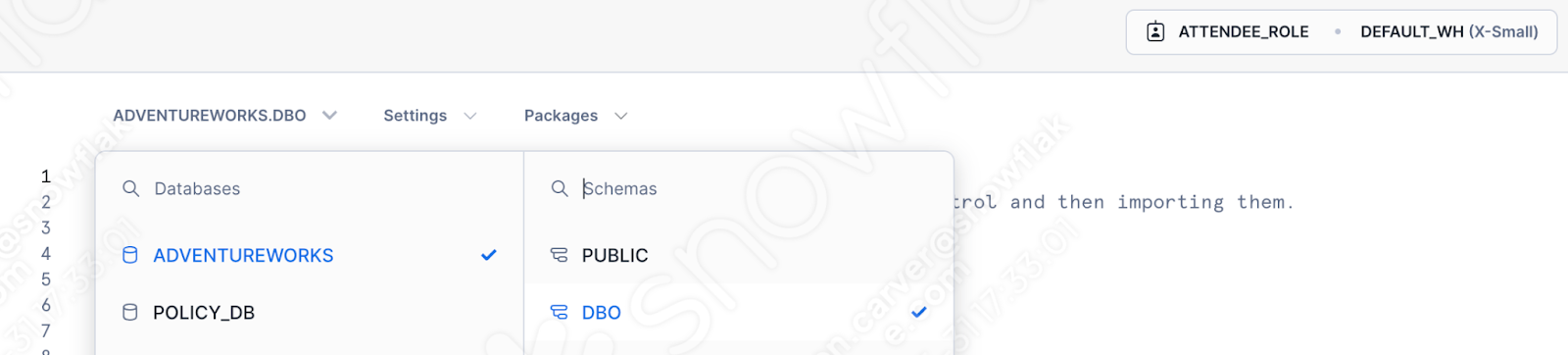
Geben Sie die Datenbank, das Schema, die Rolle und das Warehouse an, das bzw. die Sie verwenden möchten:
Jetzt müssen wir uns nicht mehr mit unserem Sitzungsaufruf befassen. Im Arbeitsblattfenster wird eine erstellte Vorlage angezeigt:

Beginnen wir damit, unsere Importaufrufe zu übertragen. Nachdem das vorherige Skript einsatzbereit ist, sollten wir den folgenden Satz von Importen haben:
Wir benötigen nur die Snowpark-Importe. Wir werden keine Dateien in einem Dateisystem verschieben. Wir könnten die datetime-Referenz beibehalten, wenn wir die Datei im Stagingbereich verschieben möchten. (Lassen Sie uns dies tun.)
Fügen Sie die Snowpark-Importe (+ datetime) in das Python-Arbeitsblatt unter den anderen Importen ein, die bereits vorhanden sind. Beachten Sie, dass „col“ bereits importiert wurde, sodass Sie eines davon entfernen können:
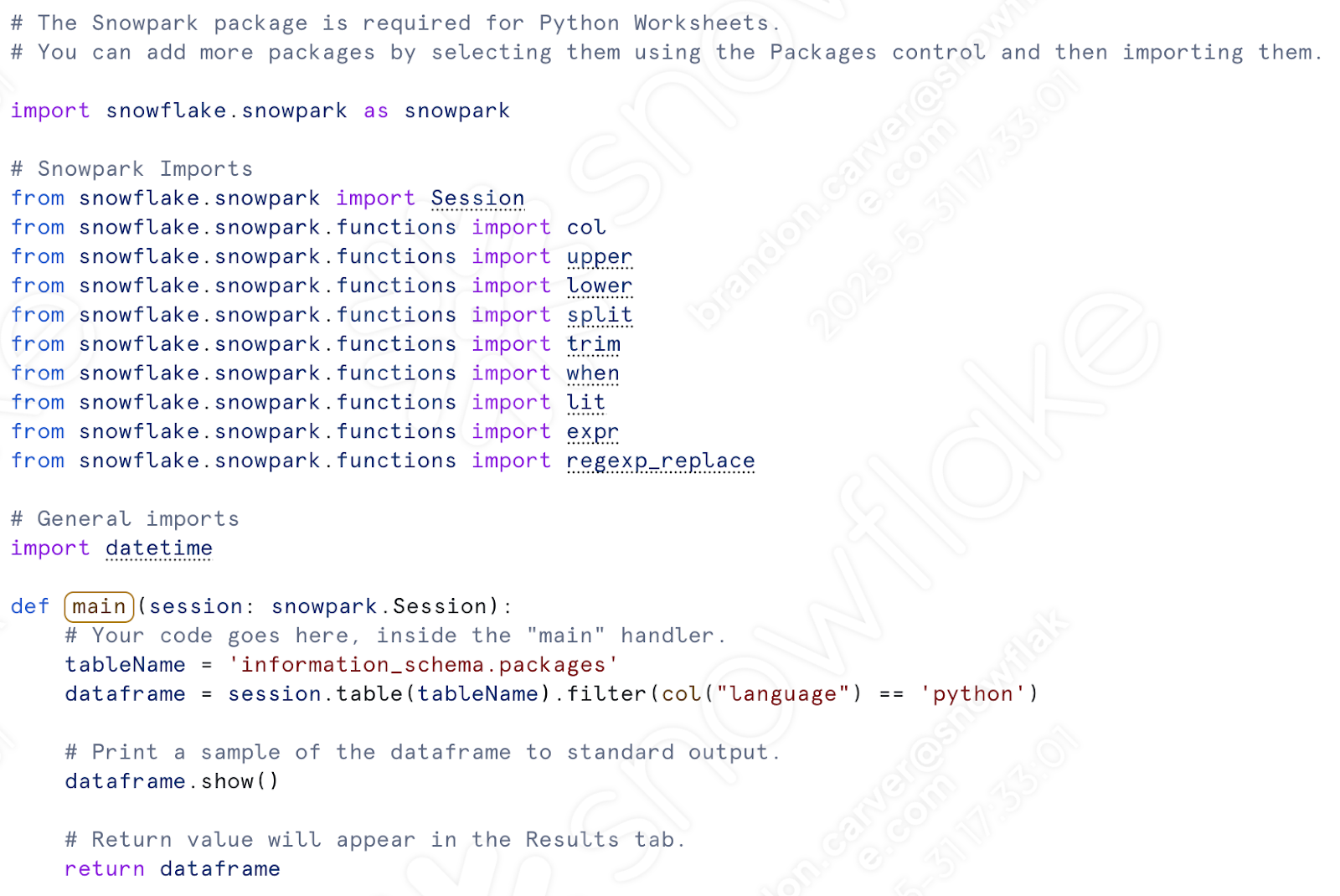
Under the “def main” call, let’s paste in all of our transformation code. This will include everything from the assignment of the csv location to the writing of the dataframe to a table.
Von hier:

Hierher:

Wir können in dem Code, der die Dateien im Stagingbereich verschiebt, auch zurück hinzufügen. Dieser Teil:
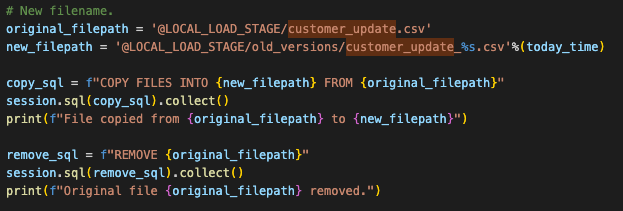
Before you can run the code though, you will have to manually create the stage and move the file into the stage. We can add the create stage statement into the script, but we would still need to manually load the file into the stage.
Wenn Sie also ein anderes Arbeitsblatt öffnen (dieses Mal ein SQL-Arbeitsblatt), können Sie eine grundlegende SQL-Anweisung ausführen, die den Stagingbereich erstellt:
Stellen Sie sicher, dass Sie die richtige Datenbank, das richtige Schema, die richtige Rolle und das richtige Warehouse auswählen:
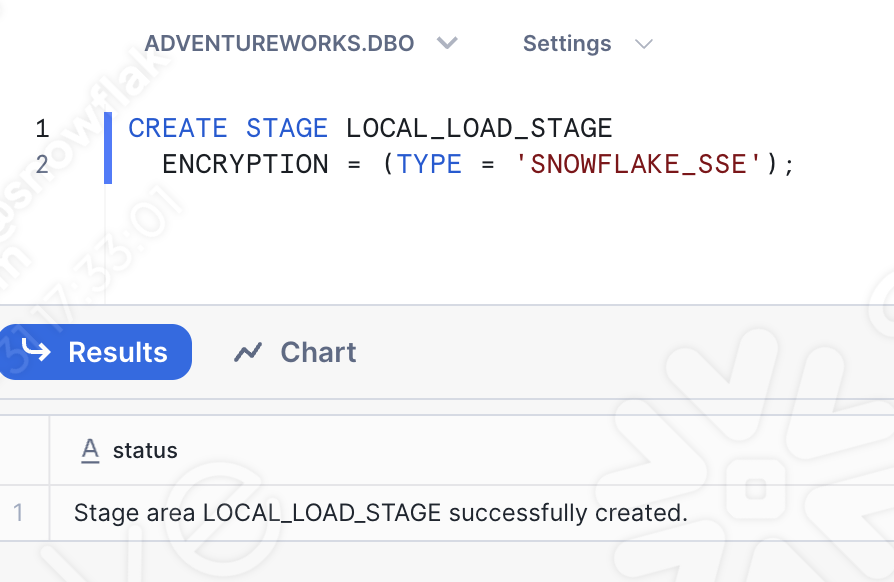
You can also create an internal stage directly in the Snowsight UI. Now that the stage exists, we can manually load the file of interest into the stage. Navigate to the Databases section of the Snowsight UI, and find the stage we just created in the appropriate database.schema:
Fügen wir unsere CSV-Datei hinzu, indem wir die Option „+Files“ in der oberen rechten Ecke des Fensters auswählen. Dadurch wird das Menü zum Hochladen Ihrer Dateien gestartet:
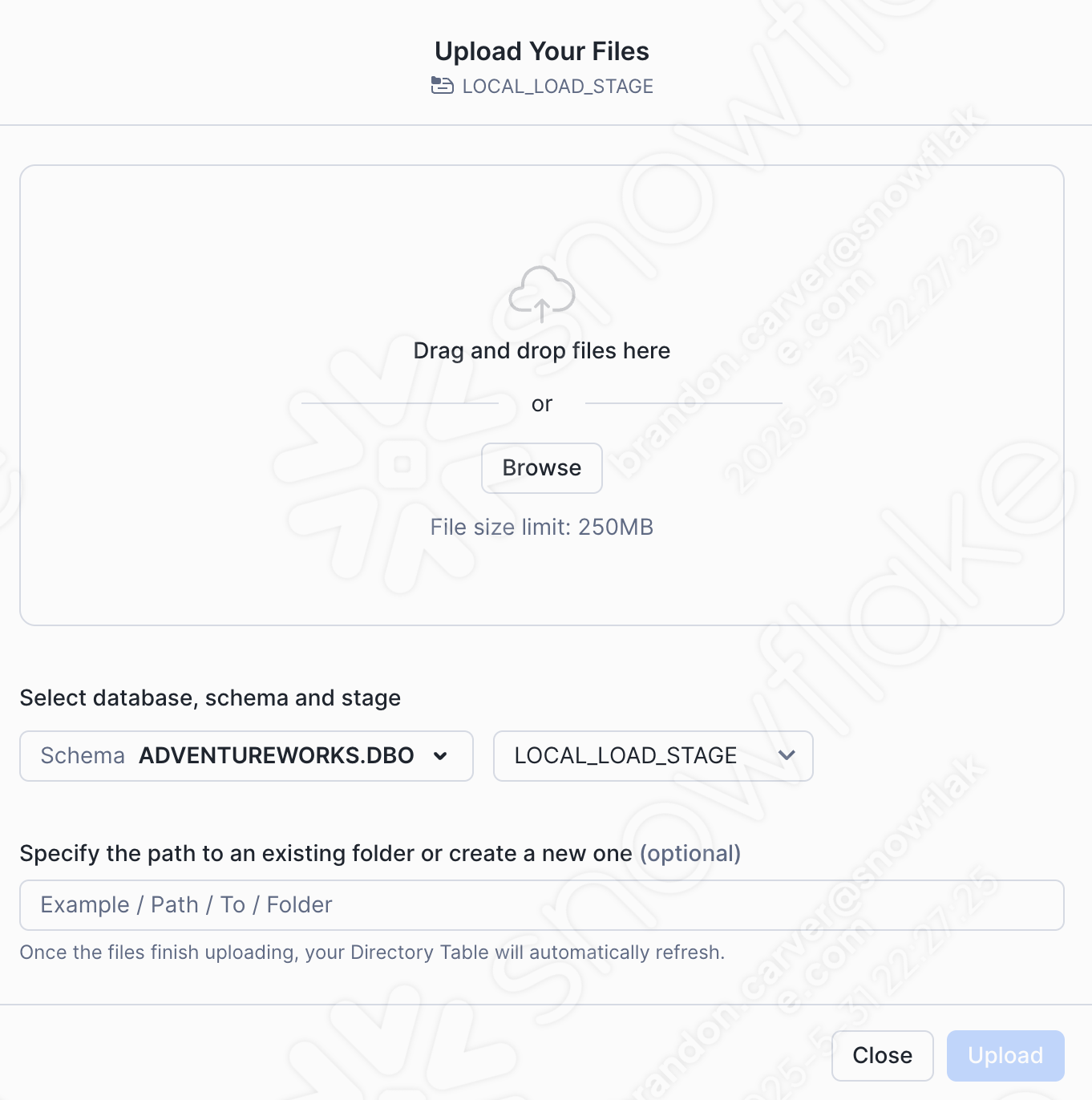
Drag and drop or browse to our project directory and load the customer_update.csv file into the stage:
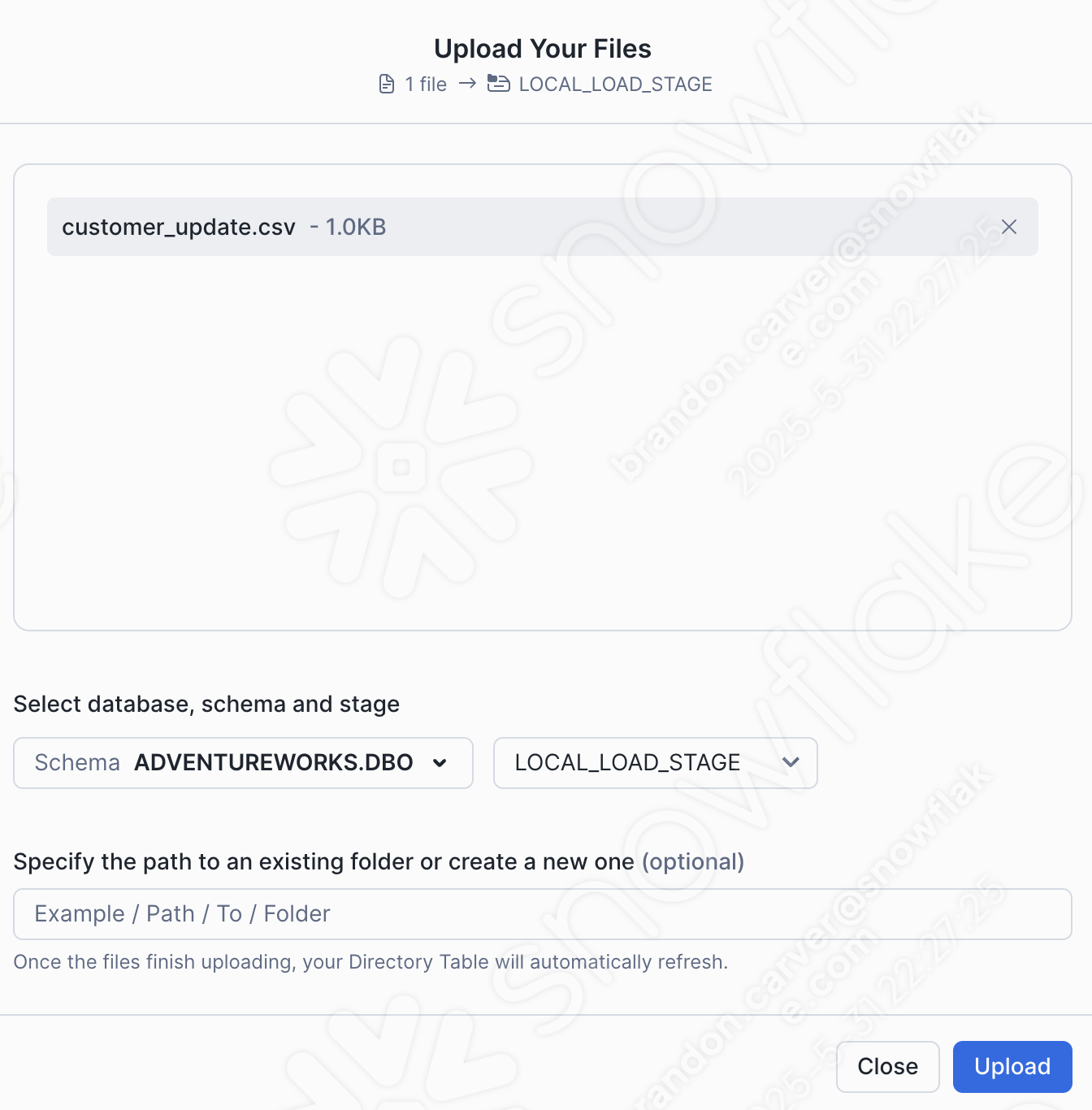
Wählen Sie in der unteren rechten Ecke des Bildschirms die Option „Upload“ aus. Sie kehren zum Stagingbereichsbildschirm zurück. Um die Dateien anzuzeigen, müssen Sie die Option „Enable Directory Table“ auswählen:
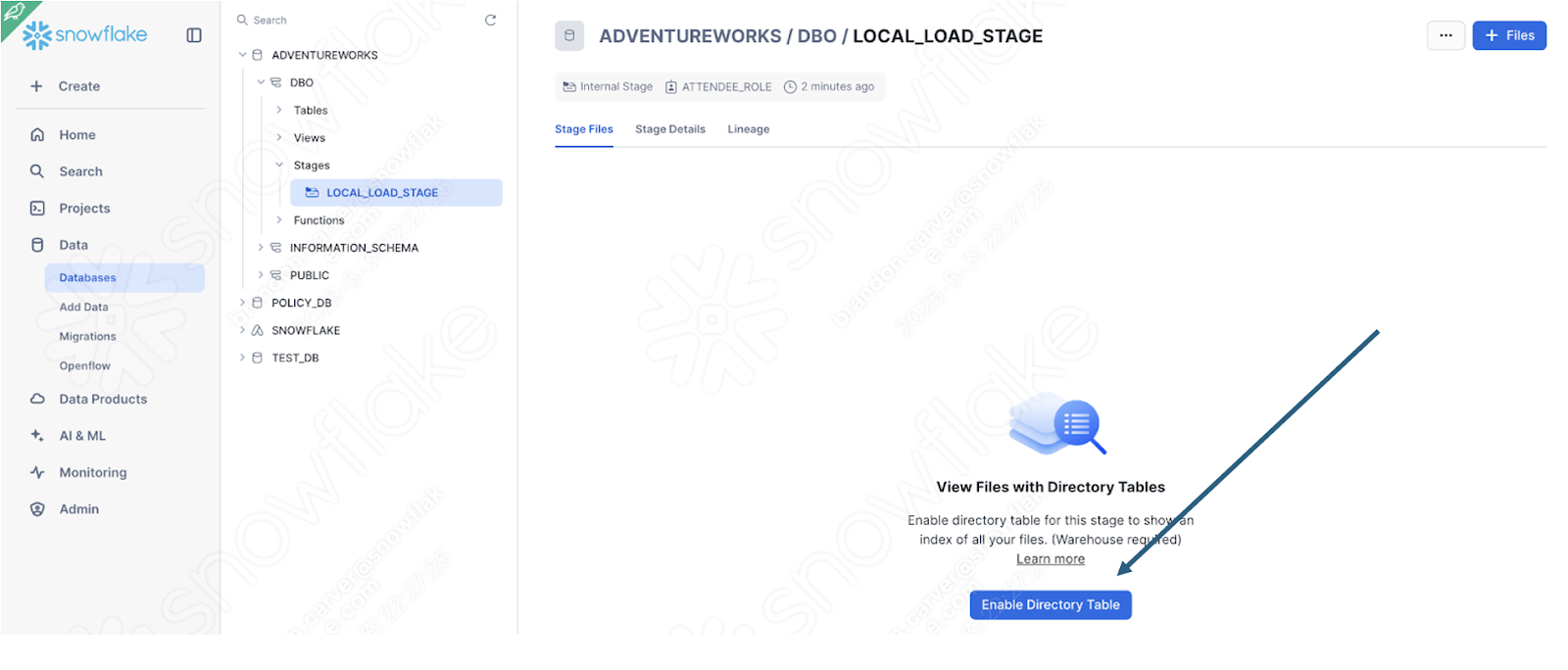
Und jetzt erscheint unsere Datei im Stagingbereich:

Dies ist natürlich nicht mehr wirklich eine Pipeline. Aber zumindest können wir die Anmeldung in Snowflake ausführen. Führen Sie den Rest des Codes aus, den Sie in das Arbeitsblatt verschoben haben. Dieser Benutzende hatte beim ersten Mal Erfolg, aber das ist keine Garantie für den Erfolg beim zweiten Mal:
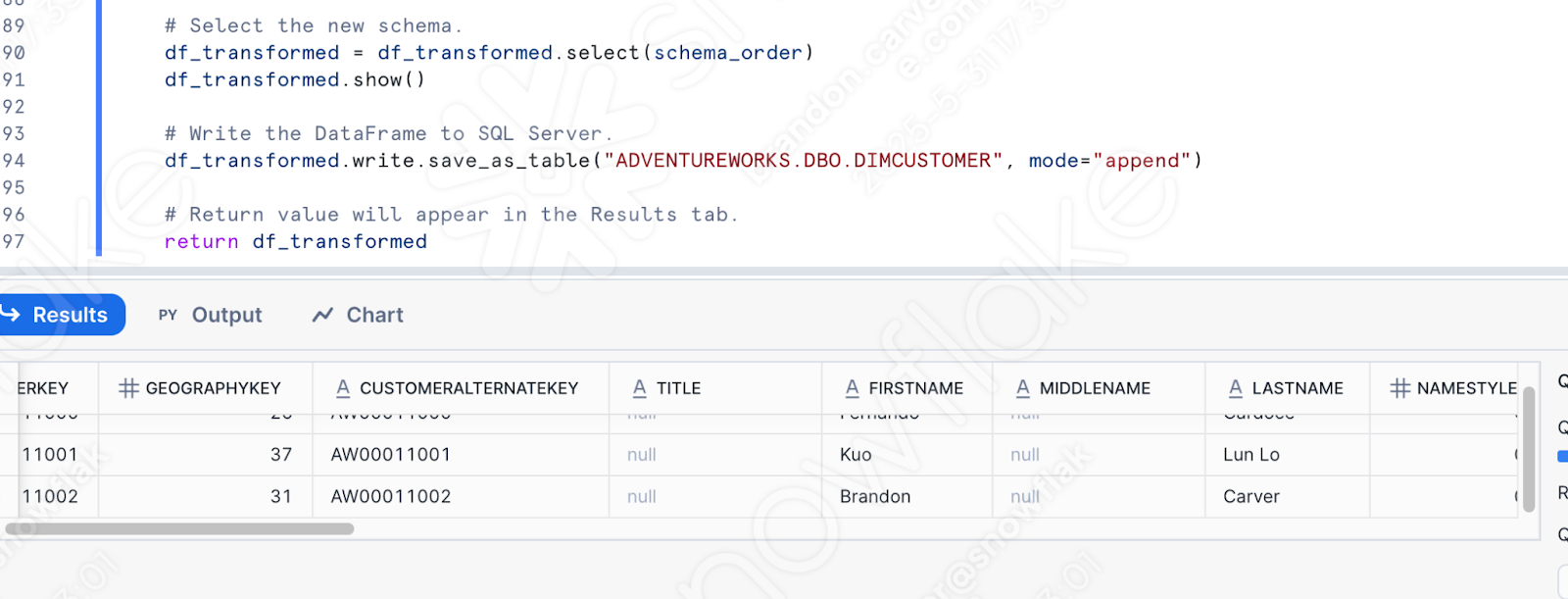
Beachten Sie, dass Sie diese Funktion, sobald Sie sie in Snowflake definiert haben, auf andere Weise aufrufen können. Wenn AdventureWorks zu 100 % deren POS ersetzt, dann kann es sinnvoll sein, die Transformationslogik in Snowflake zu verwenden, insbesondere wenn die Orchestrierung und Dateiverschiebung komplett an einem anderen Ort durchgeführt werden. So kann sich Snowpark auf die Features der Transformationslogik konzentrieren.
Fazit¶
Das war’s für die Skriptdatei. Es ist nicht das beste Beispiel für eine Pipeline, aber es ist stark davon abhängig, wie mit der Ausgabe des SMA umgegangen werden soll:
Alle Probleme lösen
Sitzungsaufrufe auflösen
Ein-/Ausgaben auflösen
Bereinigen und Testen!
Im Weiteren werden wir mit dem Notebook für die Berichterstellung fortfahren.