Snowpark Migration Accelerator:パイプラインの変換¶
SMAがスクリプトを「変換」しましたが、本当にそうでしょうか。実際に行ったのは、Spark APIからSnowpark APIへのすべての参照の変換です。行っていないことは、パイプライン内に存在する可能性のある接続の置き換えです。
SMAの利点は、その評価報告にあります。変換が、Spark APIからSnowpark APIへの参照の変換に結びついているからです。これらの参照の変換だけでは、データパイプラインを実行することはできないことに注意してください。パイプラインの接続が手動で解決されるようにする必要があります。SMAは、接続パラメーターや、それを通して実行できない可能性が高いその他の要素を推測して知ることはできません。
どんな変換でも同じですが、変換されたコードを扱うにはさまざまな方法があります。以下のステップは、変換ツールの出力にどのようにアプローチするかを 推奨 するものです。SnowConvertのように、SMAは出力に注意を払う必要があります。変換が100%自動化されることはありません。これは特にSMAに当てはまります。SMAはSpark APIからSnowpark APIに参照を変換しているので、それらの参照がどのように実行されているかを常にチェックする必要があります。また、スクリプトやノートブックが正常に実行されるように調整を試みません。
そこで、以下の手順に従って、SnowConvertとは若干異なるSMAの出力を処理することになります。
すべての問題の解決 :ここでの「問題」とは、SMAによって発生した問題を意味します。出力コードを見てみましょう。解析エラーや変換エラーを解決し、警告を調査します。
セッションコールの解決 :セッションコールをどのように出力コードに書くかは、ファイルを実行する場所によって異なります。コードファイルを元々実行しようとしていたのと同じ場所で実行し、その後Snowflakeで実行することで、この問題を解決します。
入出力の解決 :異なるソースへの接続は、SMAで完全に解決することはできません。プラットフォームには違いがあり、SMAは通常それらを無視します。これは、ファイルを実行する場所にも影響されます。
クリーンアップとテスト :コードを実行してみます。うまくいくかどうか見てみます。このラボではスモークテストを行いますが、Snowpark Python Checkpointsなど、より広範なテストやデータ検証を行うツールもあります。
では、これがどのようなものか見てみましょう。2つのアプローチを行います。最初のアプローチは、(ソーススクリプトが実行されている)ローカルマシンのPythonでこれを実行することです。もう1つは、すべてをSnowflakeのSnowsightで行うことですが、ローカルソースから読み込むデータパイプラインの場合、Snowsightで完全にできるわけではありません。でも大丈夫です。今回のPOCでは、このスクリプトのオーケストレーションは変換していません。
パイプラインスクリプトファイルから始めて、次のセクションでノートブックに取りかかります。
問題を解決する¶
ソースと出力コードをコードエディターで開きます。お好きなコードエディタを使用できますが、何度も述べたように、Snowflakeでは VS CodeとSnowflake拡張機能 を使用することをお勧めします。Snowflake拡張機能は、SnowConvertから問題をナビゲートしてくれるだけでなく、Pythonの Snowpark Checkpoints を実行することもできます。これは、テストと根本原因分析に役立ちます(このラボの範囲外ですが)。
プロジェクト作成画面(Spark ADW Lab)で作成した元のディレクトリを、VS Codeで開きます。
なお、Output ディレクトリ構造は入力ディレクトリと同じになります。変換が行われていないにもかかわらず、データファイルもコピーされます。また、 checkpoints.json ファイルがSMAでいくつか作成されます。これらは、Snowpark Checkpoints拡張機能の指示を含むjsonファイルです。Snowflake拡張機能は、これらのファイルのデータに基づいて、ソースコードと出力コードの両方にチェックポイントをロードすることができます。今は無視します。
最後に、入力されたpythonスクリプトと出力スクリプトで変換されたものを比較してみます。
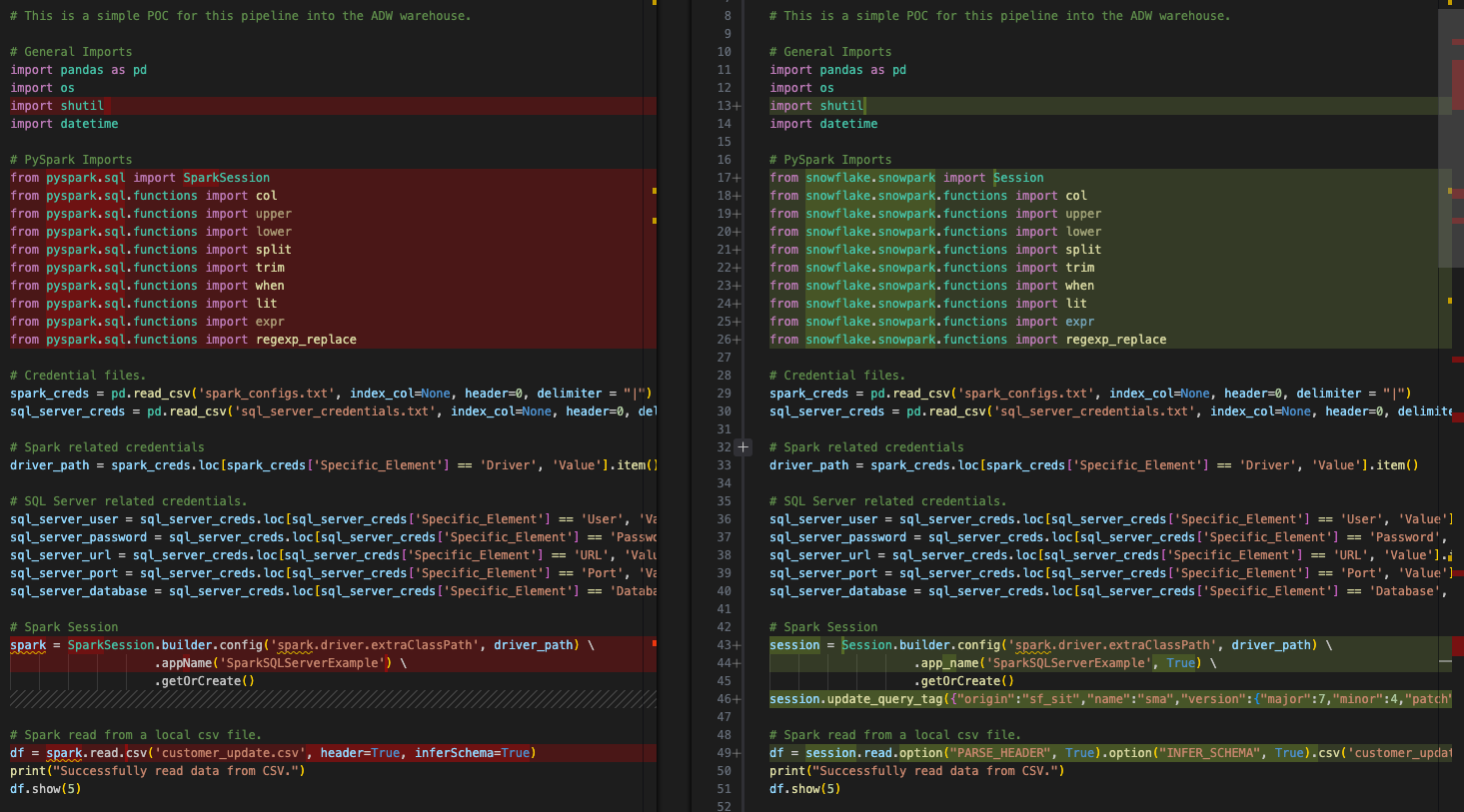
これは、基本的な対象比較で、左がオリジナルのSparkコードで、右が出力されたSnowpark互換コードです。いくつかのインポートがセッションコールと同様に変換されたようです。上の画像の下の方にEWIがありますが、それは脇に置きます。他のことをする前に、解析エラーを見つける必要があります。
UIとissues.csvの両方で表示された解析エラーのエラーコードをドキュメントから検索することができます( SPRKPY1101 )。
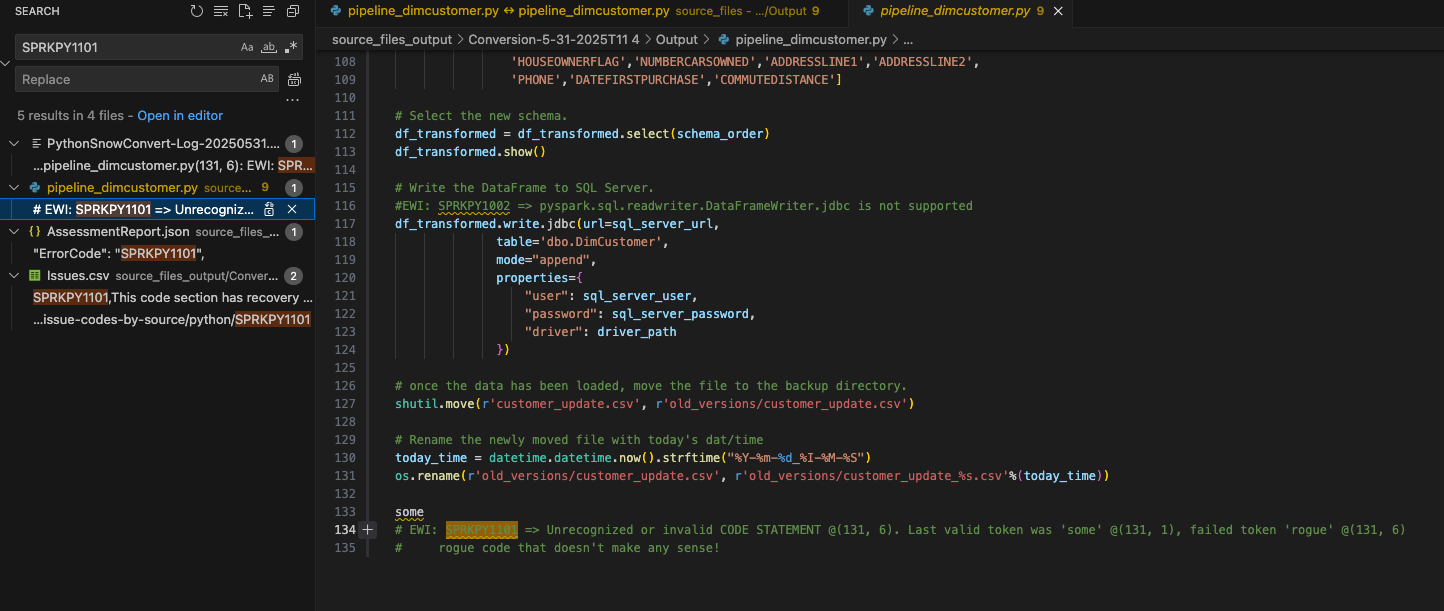
Since I have not filtered the results, the listing of this error code in the issues.csv also comes up in the search and the AssessmentReport.json that is used to build the AssessmentReport.docx summary assessment report. This is the main report that users will navigate through to understand a large workload, but we did not look at it in this lab. (More info on the this report can be found in the SMA documentation.) Let’s choose where this EWI shows up in the pipeline_dimcustomer.py file as shown above.
You can see that this line of code was present at the bottom of the source code.
どうやらこの解析エラーの原因は、「意味のない不正なコード」だったようです。このコード行はパイプラインファイルの一番下にあります。ソースからの抽出の一部として、コードファイルに余分な文字やその他の要素があることは珍しいことではありません。SMAはこれが有効なPythonコードでないことを検出し、解析エラーを生成したことに注意してください。
また、SMAがエラーが発生した箇所にエラーコードと説明文の両方をコメントとして出力コードに挿入しているのもわかります。すべてのエラーメッセージはこのように出力されます。
これは有効なコードではなく、ファイルの末尾にあり、このエラーの結果削除されたものは他に何もないので、元のコードとコメントは出力コードファイルから安全に削除できます。
これで、最初の、そして最も深刻な問題を解決しました。喜びましょう。
このファイルの残りのEWIsに取り組みます。エラーコードが発生するたびに、そのテキストがコメントに表示されることがわかっているので、「EWI」を検索することができます。(別の方法として、issue.csvファイルをソートし、深刻度順に並べることもできますが、ここではその必要はありません)。
次はエラーではなく警告です。SparkとSnowparkでは必ずしも同等ではない関数が使われていたことを教えてくれています。
しかし、この説明を読む限り、おそらく心配する必要はありません。渡されるパラメーターは2つだけです。このEWIはファイル内にコメントとして残しておきましょう。後でファイルを実行するときにチェックすることができます。
このファイルの最後のものは、何かがサポートされていないということを示す変換エラーです。

これは、出力データフレームをSQL Serverに書き込むためのspark jdbcドライバーへの書き込みコールです。これは「すべての入出力の解決」ステップの一部であり、問題を解決した後に処理することになるので、後回しにしておきます。ただし、このエラーは解決する必要があることに注意してください。前のものは単なる警告であり、変更を加えなくても機能する可能性があります。
セッションコールの解決¶
セッションコールはSMAによって変換されますが、機能するかどうかを確認するために、特に注意を払う必要があります。パイプラインスクリプトでは、これが前と後のコードです。

SparkSession参照は、Sessionに変更されています。このファイルのインポートステートメントでも、先頭付近で参照が変更されているのがわかります。

上の画像では、セッションコールの「spark」への変数割り当ては変更されていません。これは変数割り当てだからです。これを変更する必要はありませんが、もし「spark」デコレーターを「session」に変更したいのであれば、その方がSnowparkが推奨しているものに近くなります。(なお、VS Code Extensionの「SMA Assistant」は、これらの変更も提案してくれます)。
これは簡単な演習ですが、やる価値はあります。VS Codeの検索機能を使って、このファイル内の「spark」を検索し、セッションに置き換えることができます。その結果が下の画像です。変換後のコードで「spark」変数への参照が「session」に置き換えられています。

また、このセッションコールから別のものを取り除くこともできます。もう「spark」を実行するつもりはないので、sparkドライバーのドライバーパスを指定する必要はありません。そこで、次のようにセッションコールからconfig関数を完全に取り除くことができます。
Might as well convert it to a single line. The SMA couldn’t be sure we didn’t need that driver (although that seems logical), so it did not remove it. But now that we have our session call is complete.
(SMAは、セッションに「クエリタグ」も追加することに注意してください。これは、このセッションやクエリに関する問題のトラブルシューティングに役立てるためですが、残すか削除するかは完全に任意です)。
セッションコールに関するメモ¶
信じられないかもしれませんが、セッションコールのコードで変更する必要があるのはこれだけです。ただし、セッションを作成するためのすべてではありません。最初の質問に戻りますが、大部分はこれらのファイルをどこで実行したいかに依存します。これらの元のSparkセッションコールは、別の場所で設定された構成を使用していました。元のSparkセッションコールを見ると、このスクリプトファイルの最初にあるpandas dataframeの場所に読み込まれる構成ファイルを探しています(これは実際にノートブックファイルにも当てはまります)。
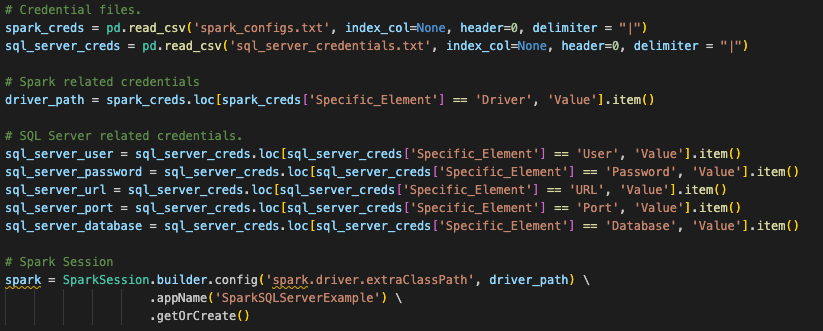
Snowpark can function the same way, and this conversion assumes that is how this user will run this code. However, for the existing session call to work, the user would have to load all of the information for their Snowflake account into the local (or at least accessible) connections.toml file on this machine, and that the account they are attempting to connect to is set as the default. You can learn more about updating the connections.toml file in the Snowflake/Snowpark documentation, but the idea behind it is that there is an accessible location that has the credentials. When a snowpark session is created, it is going to check this… unless the connection parameters are explicitly passed to the session call.
これを行う標準的な方法は、接続パラメーターを文字列として直接入力し、セッションで呼び出すことです。
AdventureWorks appears to have referenced a file with these credentials and called it. Assuming there is a similar file called 'snowflake_credentials.txt' that is accessible, then the syntax that would match that could look something like:
For the purpose of the time limit on this lab, the first option may make more sense. There’s more on this in the Snowpark documentation.
Snowsightを使ってSnowflakeの中でノートブックファイルを実行する場合は、このような作業は必要ないことに注意してください。アクティブなセッションを呼び出して実行するだけです。
さて、いよいよこの移行で最も重要な要素、入出力参照の解決です。
入出力の解決¶
では、入出力を解決しましょう。Pythonスクリプトの場合、Snowsightの内部で直接実行することで何が得られるかまたは失われるかを確認しましょう。 Snowsightで全ての操作を実行することはできません (少なくとも現在は)。ローカルcsvファイルはSnowsightからアクセスできません。.csvファイルを手動でステージにロードする必要があります。これは理想的な解決策ではないでしょうが、こうすることで変換をテストすることができます。
そこで、まずこのファイルをローカルで実行/オーケストレーションできるように準備し、次にSnowflakeで実行できるようにします。
パイプラインスクリプトの入力と出力を解決するには、まずそれらを特定する必要があります。とてもシンプルです。このスクリプトは以下のようです。
ローカルファイルにアクセスする
結果をSQL Server(ただし現在はSnowflake)にロードする
次のファイルのためにファイルを移動する
十分にシンプルです。そのため、そのようなことをするコードの各コンポーネントを置き換える必要があります。ローカルファイルへのアクセスから始めます。
冒頭で述べたように、販売時点情報管理システムと、このPythonスクリプトを実行するために使用されるオーケストレーションツールを再設計し、出力ファイルをクラウドストレージの場所に置くことを強くお勧めします。そして、その場所を外部テーブルに変えれば、Snowflakeに入れることができます。しかし、現在のアーキテクチャでは、このファイルはクラウドストレージにはなく、そのままの場所にあります。そのため、Snowflakeが既存のロジックを保持するこのファイルにアクセスできるようにする必要があります。
そのためのオプションもありますが、ここでは内部ステージを作り、スクリプトのあるステージにファイルを移動させることにします。その場合、ローカルファイルシステム内のファイルを移動させ、ステージ内でも移動させる必要があります。これはすべてSnowparkでできます。プロセスを分解してみます。
ローカルファイルにアクセスする:内部ステージを作成する(まだステージが存在しない場合) -> ファイルをステージに読み込む -> ファイルをデータフレームに読み込む
その結果をSQL Server にロードする:変換されたデータをSnowflakeのテーブルにロードする
次のファイルのためにファイルを移動する:ローカルファイルを移動する -> ステージ内にファイルを移動する
これらのことができるコードを見てみます。
ローカルでアクセス可能なファイルにアクセスする¶
このSparkのソースコードは次のようになります。
そして、変形したSnowparkのコード(SMA)は次のようになります。
これを、上記の手順を実行するコードに置き換えることができます。
Create an internal stage (if one does not exist already). We will create a stage called 'LOCAL_LOAD_STAGE' and go through a few steps to make sure that the stage is r
ステージにファイルをロードします。
ファイルをデータフレームに読み込みます。これは、SMAが実際に変換した部分です。ファイルの場所が内部ステージになったことを指定する必要があります。
その結果はこうなります。
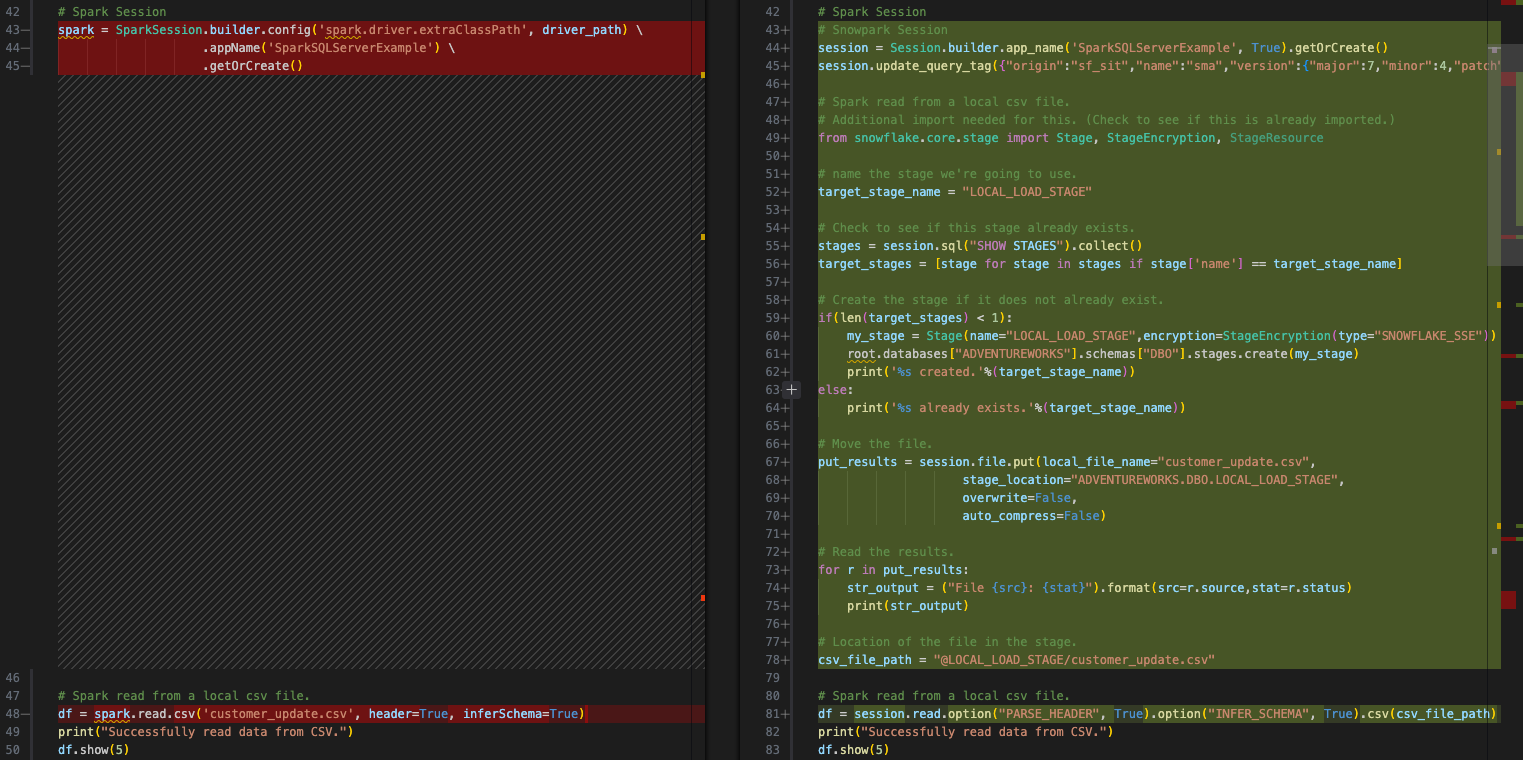
次のステップに進みます。
結果をSnowflakeにロードする¶
オリジナルのスクリプトは、SQL Serverにデータフレームを書き込みました。では、Snowflakeにロードしてみましょう。これはよりシンプルな変換です。データフレームはすでにSnowparkのデータフレームです。これがSnowflakeの長所のひとつです。データにSnowflakeがアクセスできるようになったので、すべてがSnowflakeの内部で行われます。
テストや検証を行うために一時的なテーブルに書き込みたいかもしれませんが、これは元のスクリプトの動作であることに注意してください。
ファイルを移動して、次のファイルの場所を確保します。¶
これはオリジナルのスクリプトでの動作です。Snowflakeでこれを実現する必要はありませんが、ステージでまったく同じ機能を見せることはできます。これは、オリジナルのファイルシステムでosコマンドを使って行われます。それはSparkに依存せず、そのまま変わりません。しかし、snowparkでこの動作をエミュレートするには、ステージ内のこのファイルを新しいディレクトリに移動する必要があります。
これは以下のPythonコードで簡単にできます。
なお、これは既存のコードを置き換えるものではありません。sparkコードをsnowparkに移動させるという既存の動きは維持したいので、osの参照は残すことにします。最終的にはこのようになります。
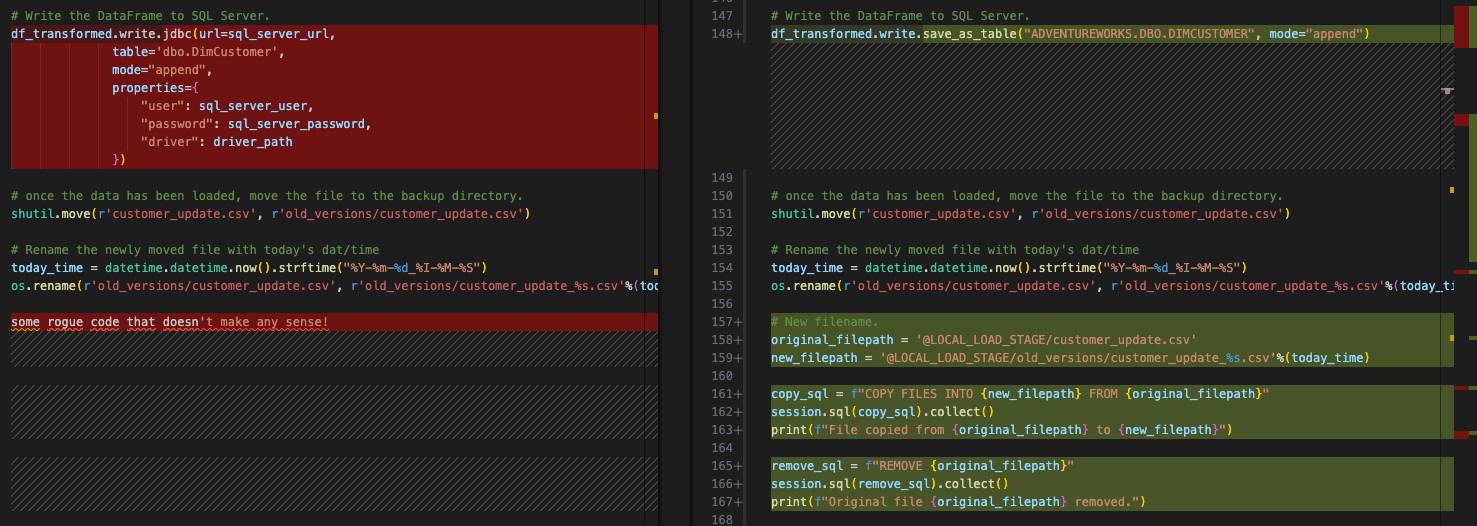
これで同じモーションが完全に完成しました。では、最後のクリーンアップをして、このスクリプトをテストしてみましょう。
クリーンアップとテスト¶
インポートコールをまったく見ておらず、まったく必要のない構成ファイルもあります。構成ファイルへの参照を残して、スクリプトを実行することもできます。実際、これらの構成ファイルがまだアクセス可能であれば、コードはまだ実行できます。しかし、インポートステートメントをよく見るのであれば、削除した方がいいでしょう。これらのファイルは、インポートステートメントとセッションコールの間のすべてのコードで表されます。
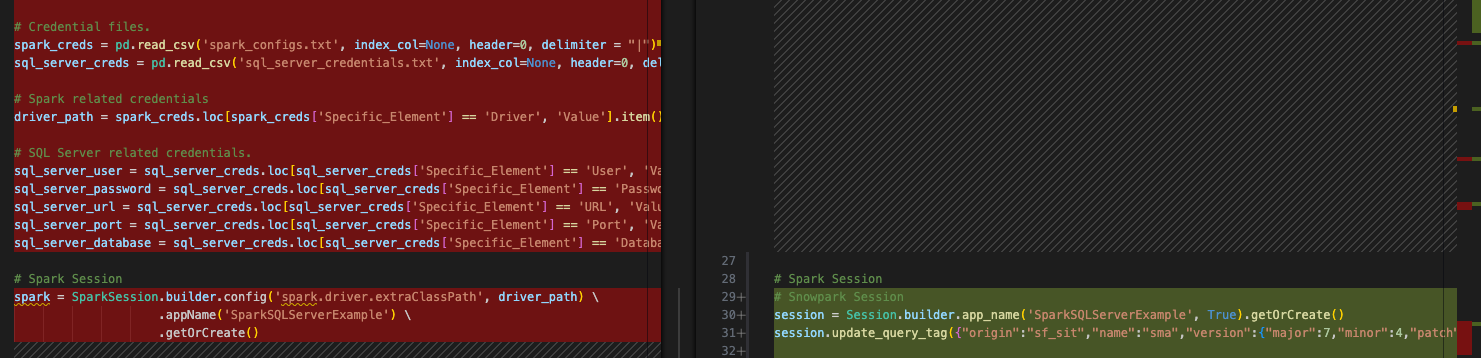
他にもいくつかやるべきことがあります。
すべてのインポートがまだ必要であることを確認します。今は置いておきます。エラーがあれば、それに対処できます。
また、チェックするよう警告するために置いておいたEWIが1つあります。そのため、その出力を確実に検査するようにしたいです。
We need to make sure that our file system behavior mirrors that of the expected file system for the POS system. To do this, we should move the customer_update.csv file into the root folder you chose when first launching VS Code.
Create a directory called “old_versions” in that same directory. This should allow the os operations to run.
最後に、実稼働のテーブルに直接コードを実行することに抵抗がある場合は、このテスト用にテーブルのコピーを作成し、ロードをそのコピーに向けることができます。ロードステートメントを以下のものに置き換えます。これはラボなので、「実稼働」テーブルに自由に書き込んでください。
これでようやくテストする準備が整いました。Pythonでこのスクリプトをテスト用のテーブルに実行し、失敗するかどうかを確認することができます。では、実行してください。
残念です。スクリプトは以下のエラーで失敗しました。

識別子を参照する方法が、Snowparkが必要とする方法ではないようです。失敗したコードは、残りのEWIがある場所と同じところにあります。

エラーによって提供されたリンクでドキュメントを参照することもできますが、時間の都合上、Snowparkはこの変数を明示的にリテラルにする必要があります。次のような入れ替えが必要です。
これでこのエラーは解消されるはずです。ソースプラットフォームとターゲットプラットフォームの間には、常に機能的な違いがあることに注意してください。SMAのような変換ツールは、こうした違いをできるだけ明白にしようとします。しかし、100%自動化された変換は存在しません。
もう一度実行します。今回は成功です。

これを検証するためにPythonでクエリを書くこともできますが、Snowflakeで行いましょう(これからやろうとしていることなので)。
これらのスクリプトを実行するために、使用しているSnowflakeアカウントに移動します。このスクリプトは、SQL Serverからデータベースをロードする際に使用したものと同じでなければなりません(ロードしていない場合は、データがまだ移行されていないため、上記のスクリプトは動作しません)。
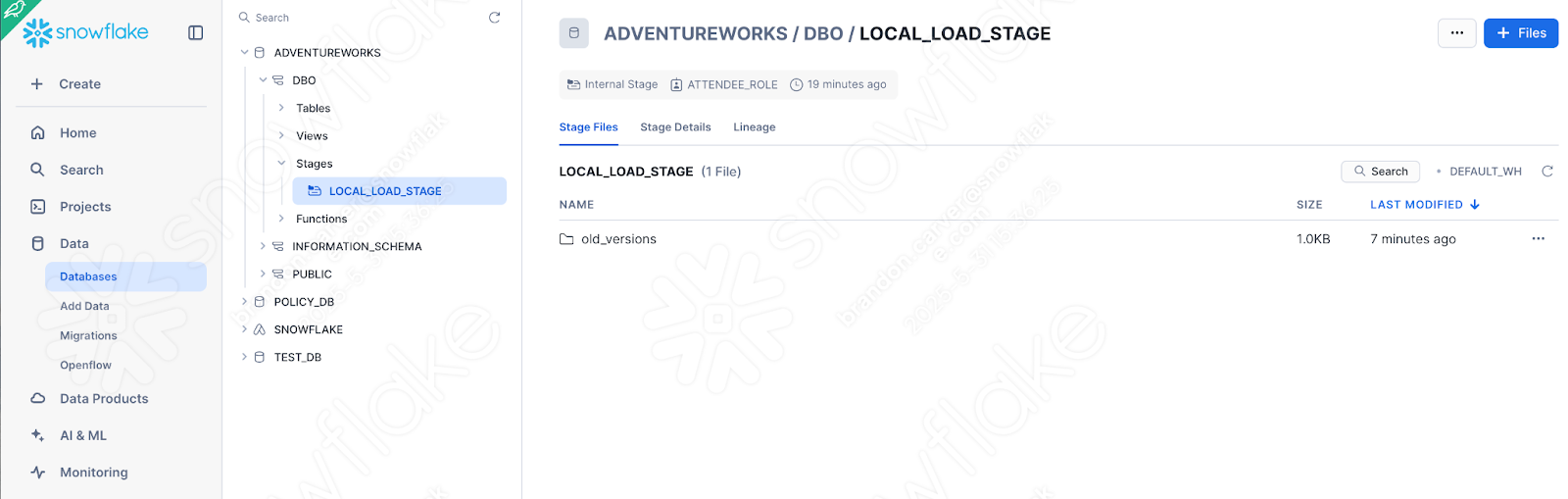
You can quickly check this by seeing if the stage was created with the file:
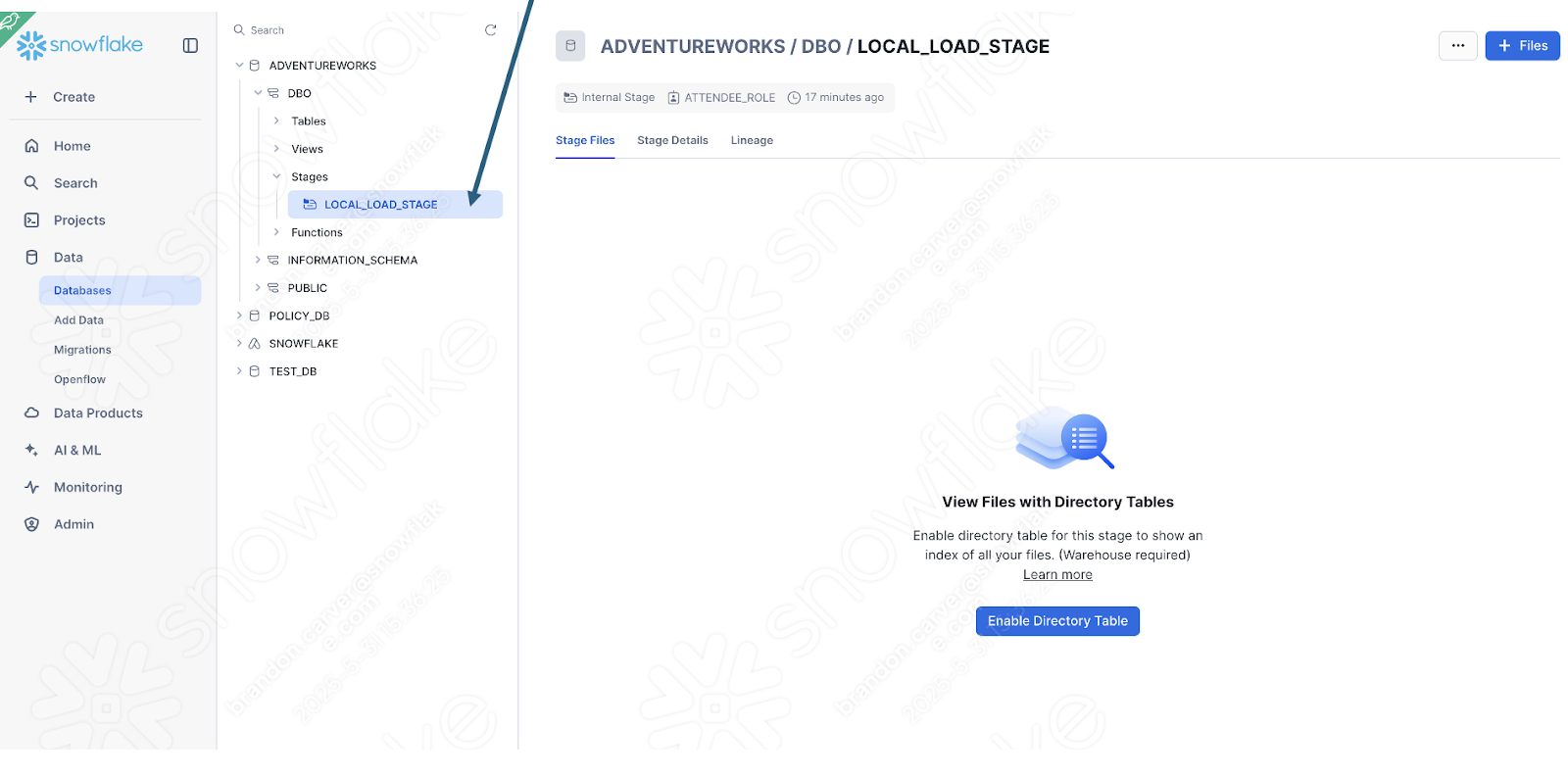
Enable the directory table view to see if the old_versions folder is in there:
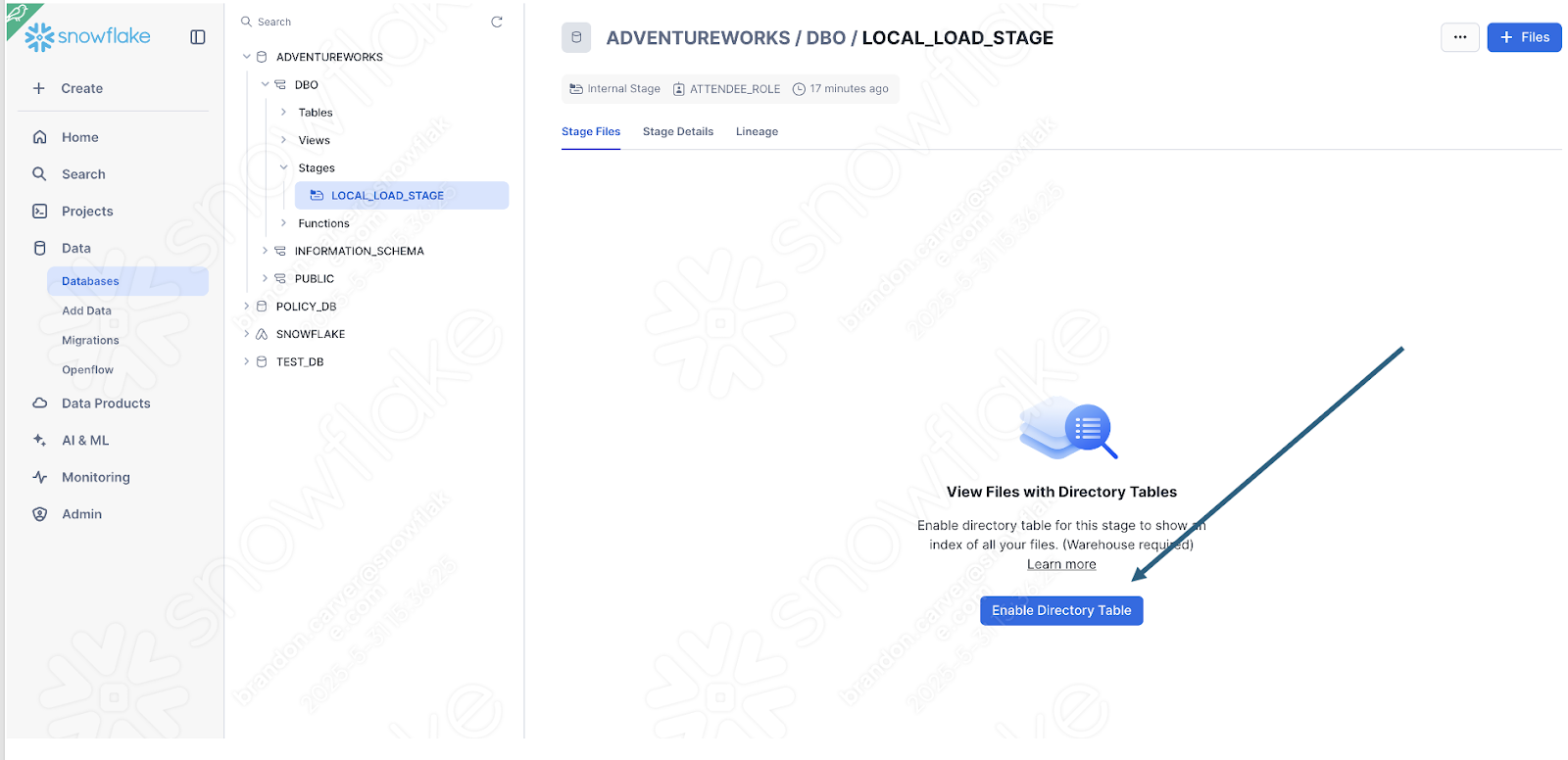
そのようです。
これがスクリプトの最後の要素だったので、問題なさそうです。
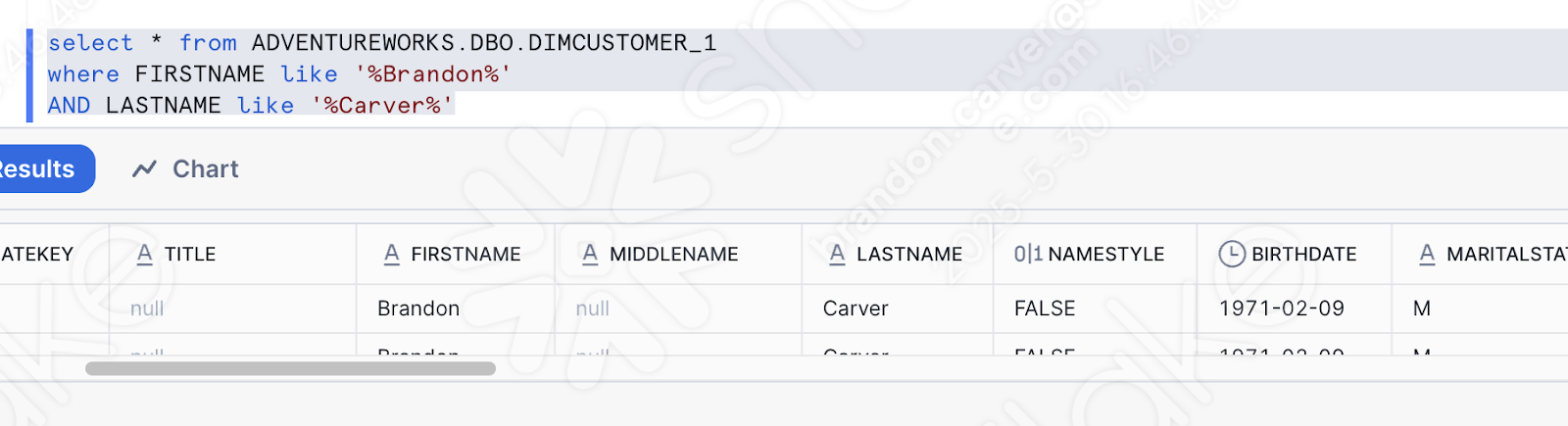
また、単純にアップロードしたデータをテーブルに問い合わせることで、データがロードされたことを検証することもできます。新しいワークシートを開き、このクエリを書くだけでいいです。
これは、今読み込まれた名前のひとつです。そして、パイプラインは機能したようです。
Snowsightでパイプラインスクリプトを実行する¶
変換しようとしているフローがSparkで行っていたことを簡単に振り返ってみます。
ローカルファイルにアクセスする
その結果をSQL Serverにロードする
ファイルを移動して、次のファイルの場所を確保する
このフローは、Snowsightから完全に実行することはできません。Snowsightはローカルファイルシステムにアクセスできません。ここでお勧めしたいのは、POSからデータレイクにエクスポートすることです。あるいは、Snowsightからアクセスできる他のオプションもあります。
しかし、SnowflakeでPythonスクリプトを実行することで、Snowparkがどのように変換ロジックを処理するかを詳しく見ることができます。上記の推奨される変更をすでに行っている場合、SnowflakeのPythonワークシートでスクリプト本体を実行することができます。
これを行うには、まずSnowflakeアカウントにログインし、ワークシートセクションに移動します。このワークシートで、新しいPythonワークシートを作成します。

使用するデータベース、スキーマ、ロール、ウェアハウスを指定します。
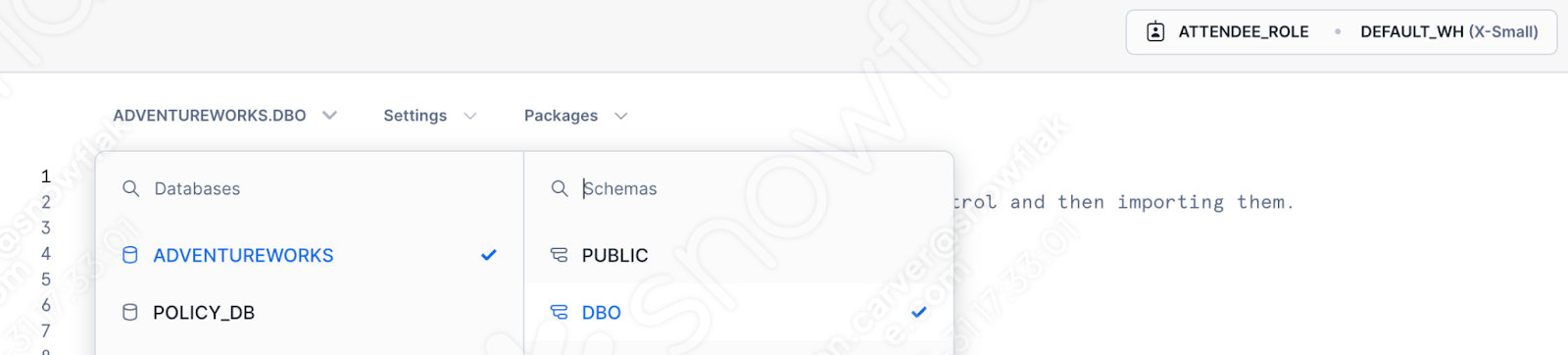
これでセッションコールに対処する必要はなくなりました。ワークシートウィンドウにテンプレートが生成されるのが見えます。

まずはインポートコールを持ってくることから始めます。先ほどのスクリプトを使えるようにしたら、次のようなインポートができるはずです。
必要なのはSnowparkのインポートだけです。ファイルシステム上でファイルを移動することはありません。ステージ内でファイルを移動させたい場合は、日時の参照を保持することができます。(行いましょう)。
Snowparkのインポート(とdatetime)をPythonワークシートのすでに存在するその他のインポートの下に貼り付けます。「col」はすでにインポートされているので、どちらかを削除すればよいことに注意してください。
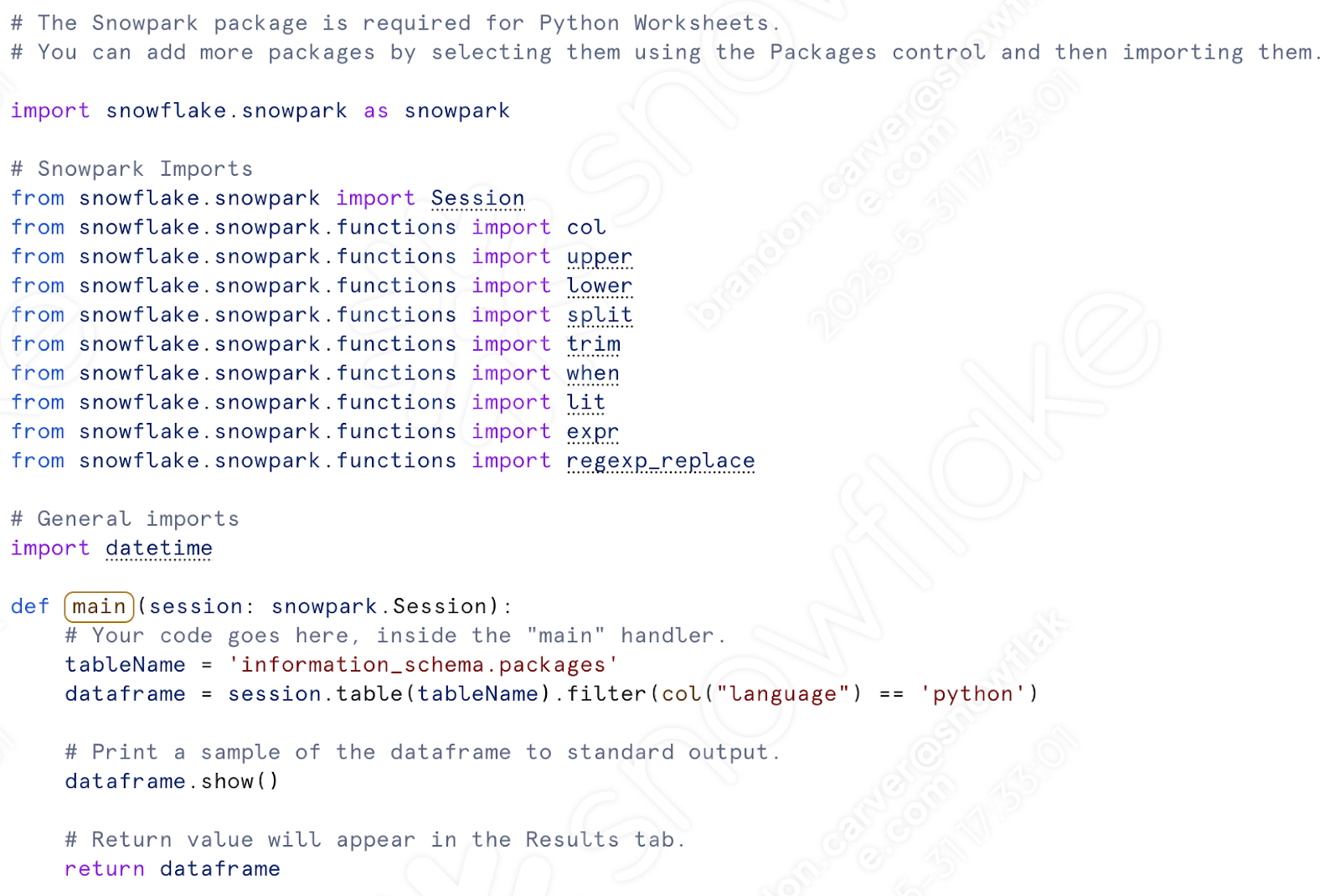
Under the “def main” call, let’s paste in all of our transformation code. This will include everything from the assignment of the csv location to the writing of the dataframe to a table.
ここから:

ここに:

また、ステージ内でファイルを移動させるコードを追加することもできます。この部分です。
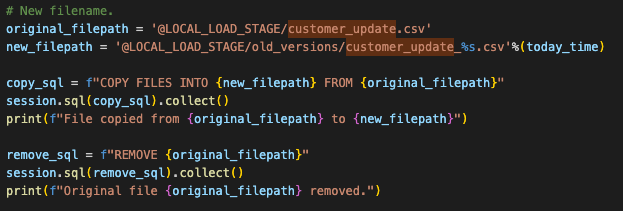
Before you can run the code though, you will have to manually create the stage and move the file into the stage. We can add the create stage statement into the script, but we would still need to manually load the file into the stage.
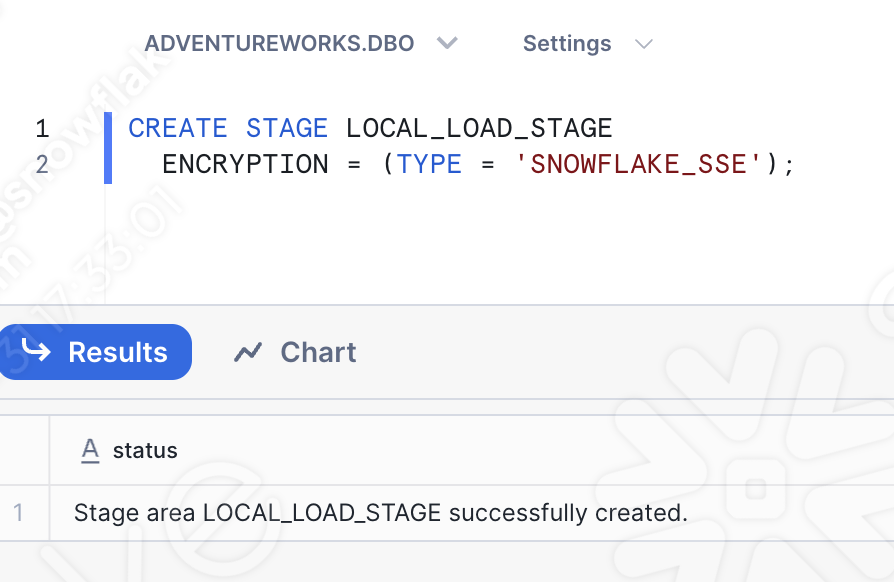
そこで、別のワークシート(今回はSQLワークシート)を開き、ステージを作成する基本的なSQLステートメントを実行できます。
正しいデータベース、スキーマ、ロール、ウェアハウスを選択してください。
You can also create an internal stage directly in the Snowsight UI. Now that the stage exists, we can manually load the file of interest into the stage. Navigate to the Databases section of the Snowsight UI, and find the stage we just created in the appropriate database.schema:
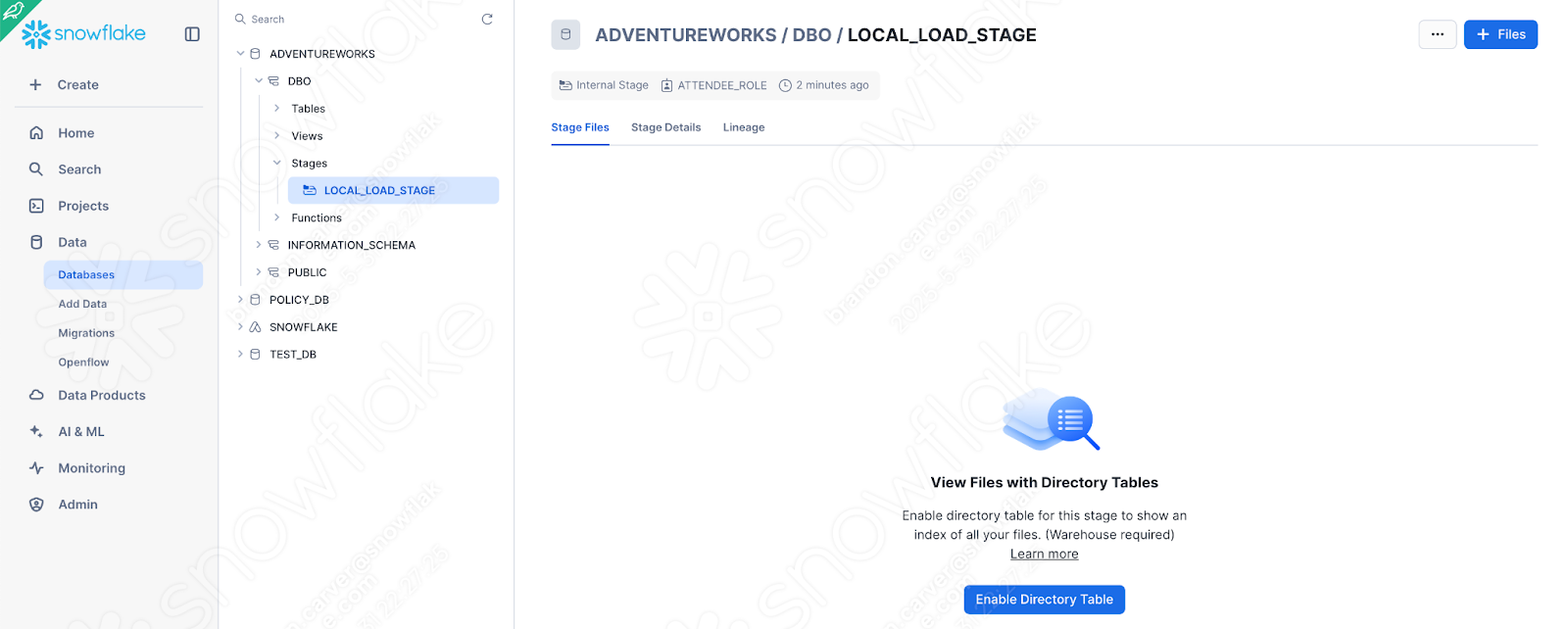
ウィンドウの右上にある+Filesオプションを選択してcsvファイルを追加します。アップロードメニューが表示されます。
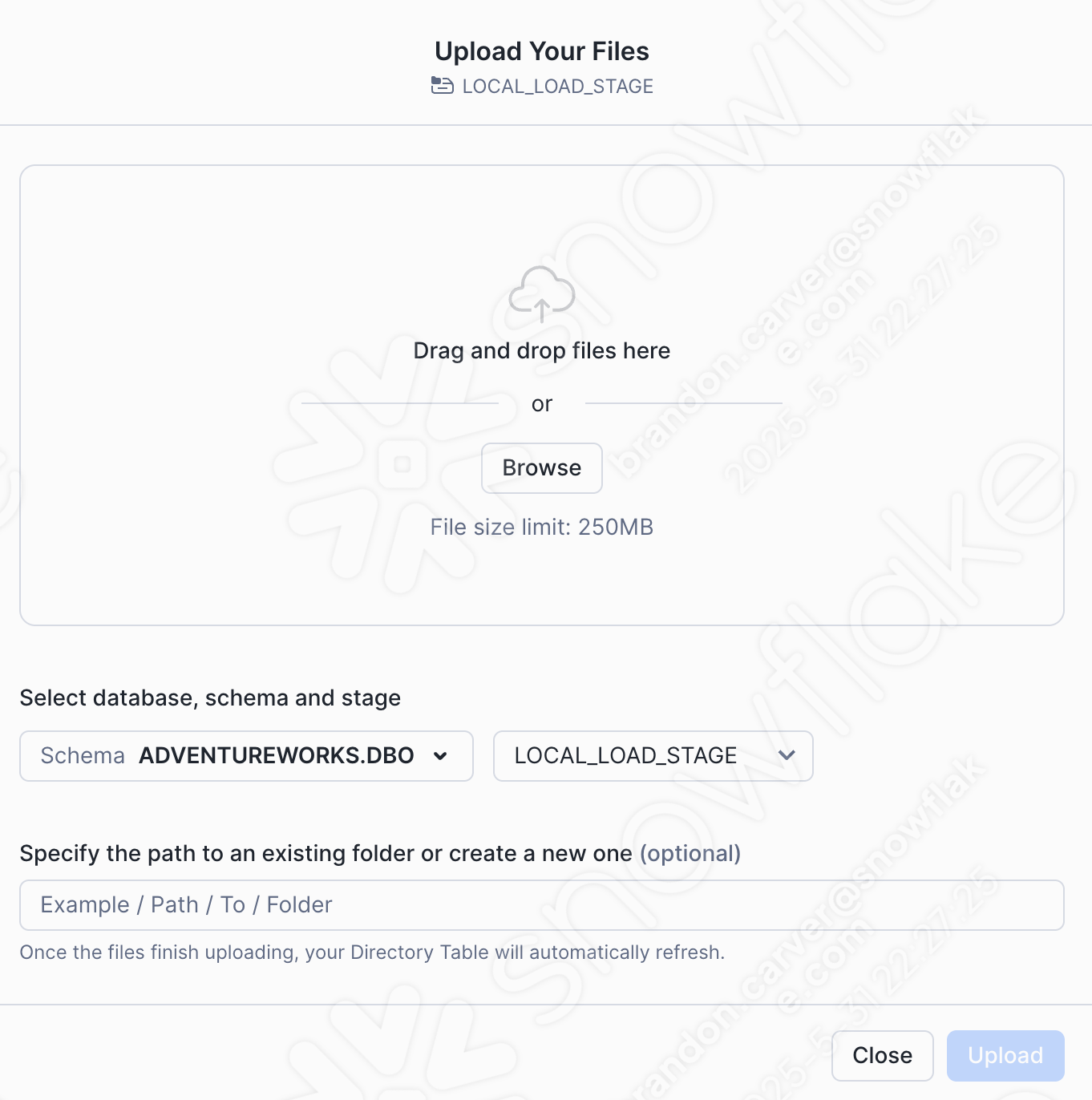
Drag and drop or browse to our project directory and load the customer_update.csv file into the stage:
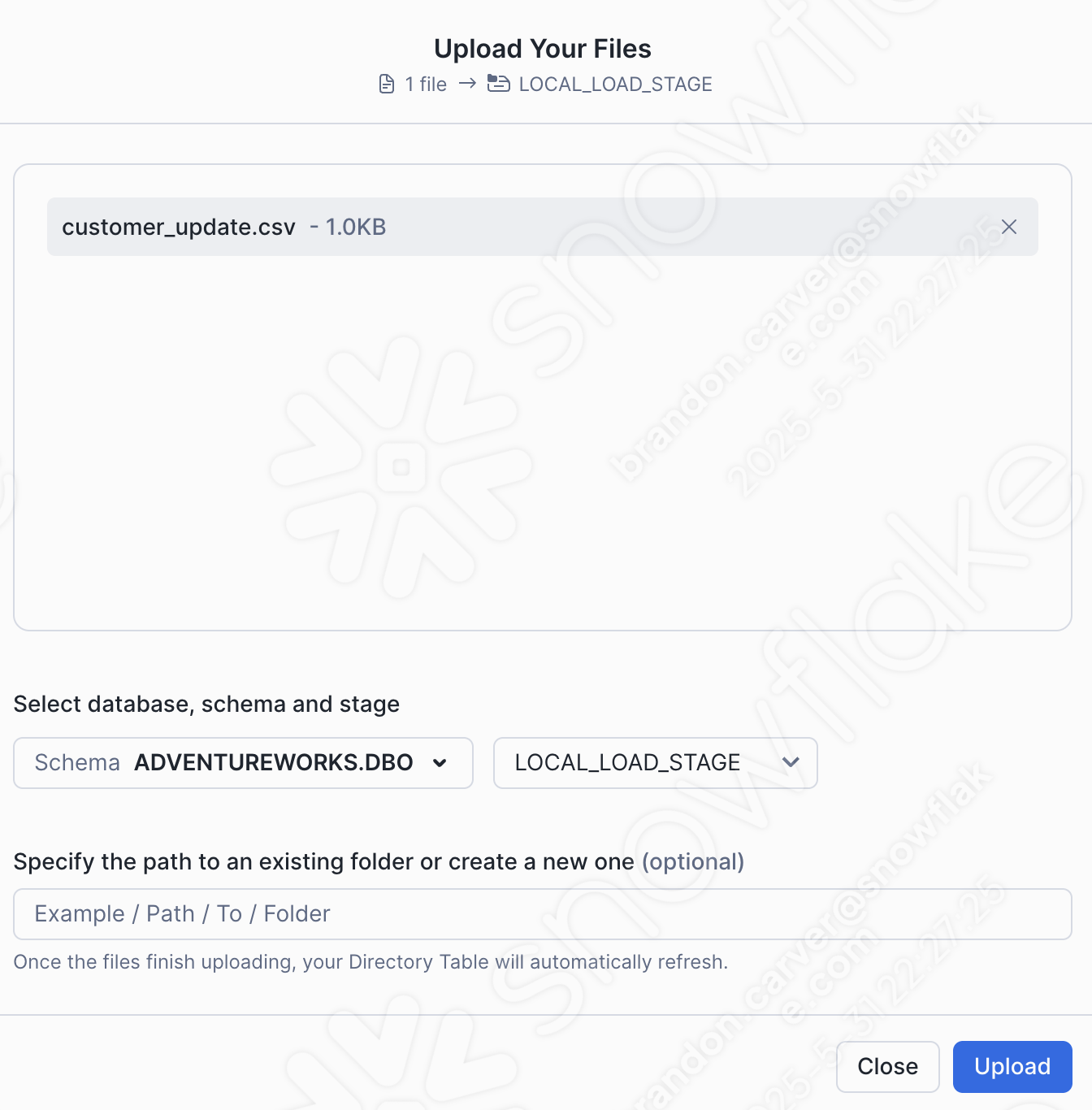
画面右下のUploadを選択します。ステージ画面に戻ります。ファイルを表示するには、Enable Directory Tableを選択する必要があります。
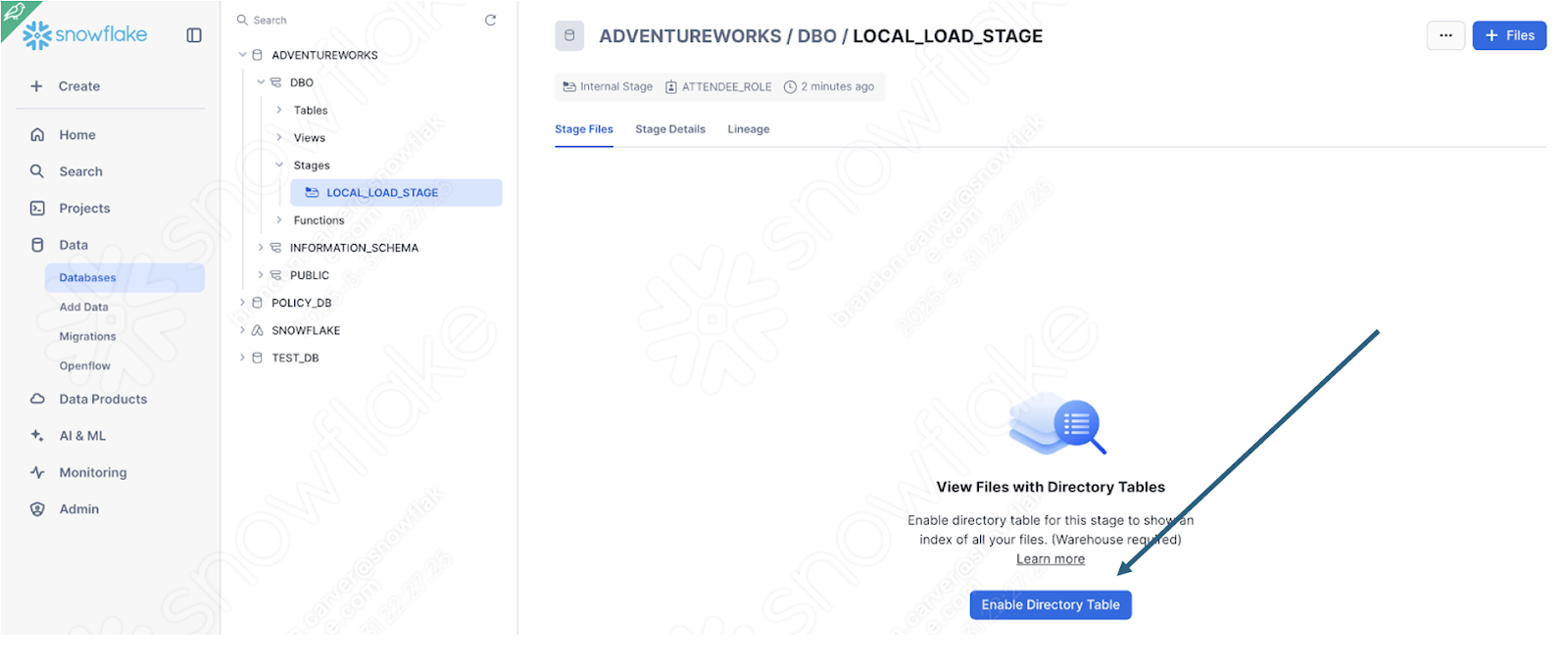
そして、ファイルがステージに表示されました。

もちろん、これはもうパイプラインとは言えません。しかし、少なくともSnowflakeでログインを実行することはできます。ワークシートに移動した残りのコードを実行します。このユーザーは1回目は成功しましたが、2回目の成功を保証するものではありません。
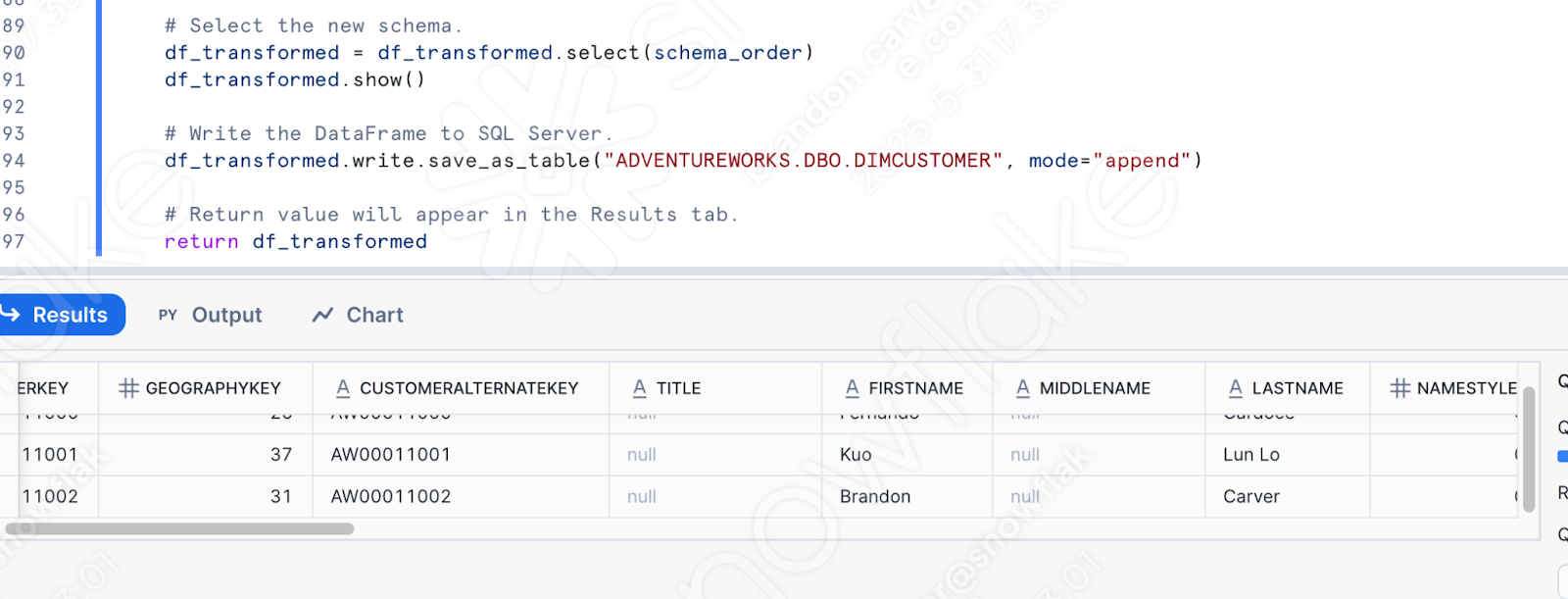
Snowflakeでこの関数を定義したら、他の方法で呼び出すことができることに注意してください。AdventureWorksがPOSを100%置き換えるのであれば、変換ロジックをSnowflakeに持たせることは理にかなっているかもしれません。特にオーケストレーションとファイル移動が全く別の場所で処理される場合です。これにより、Snowparkは得意とする変換ロジックに集中することができます。
結論¶
スクリプトファイルについては以上です。パイプラインの最良の例とは言えませんが、SMAの出力への対応については詳細です。
すべての問題の解決
セッションコールの解決
入出力の解決
クリーンアップとテスト
レポートノートブックに移りましょう。